
MAFF-Net: Multi-Attention Guided Feature Fusion Network for Change Detection in Remote Sensing Images


Abstract
:1. Introduction
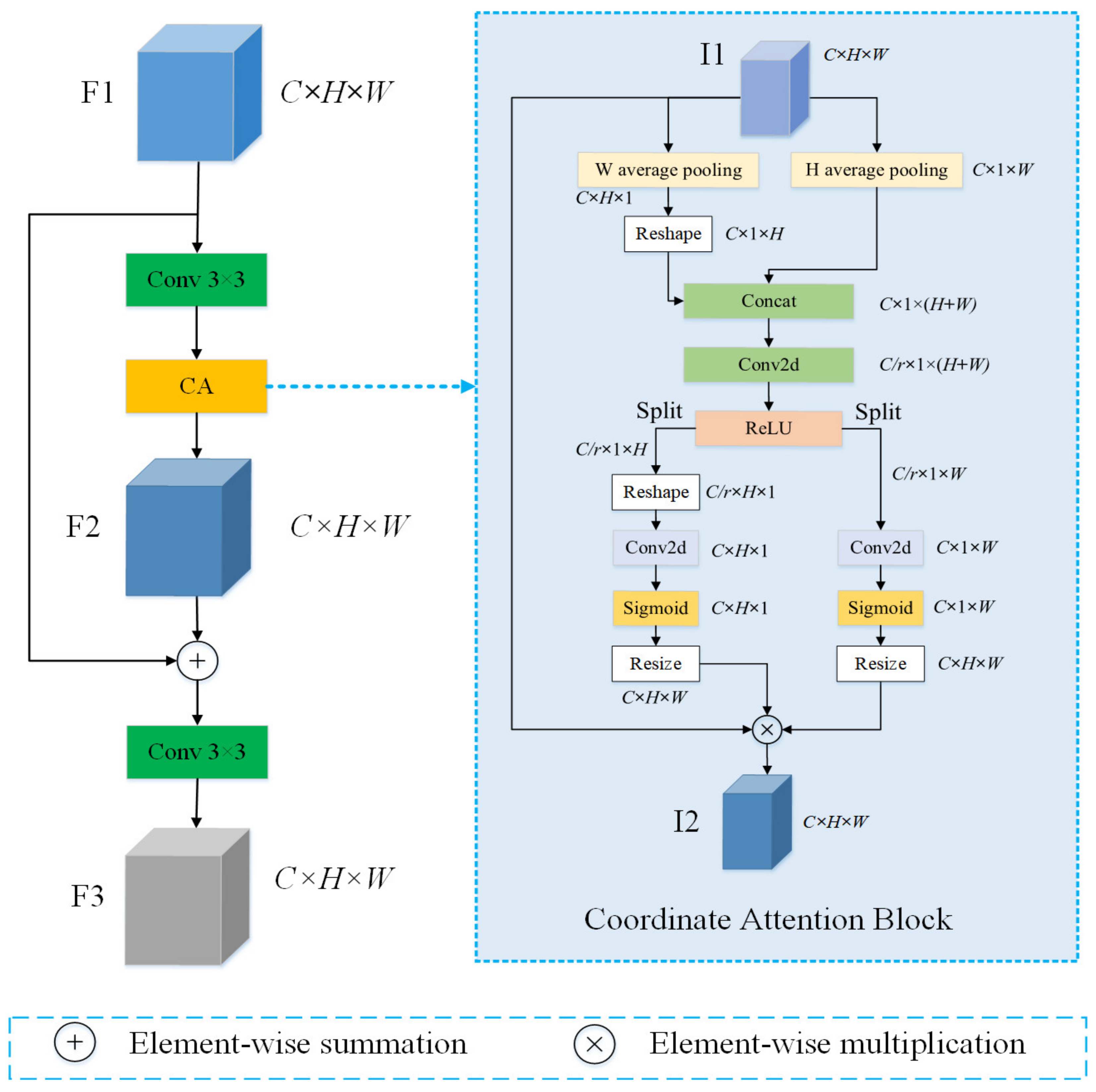
- We propose the Feature Enhancement Module (FEM), which solves the problem that the features extracted from the backbone network have much interference information and the feature representation is not clear enough. The FEM captures not only cross-channel information but also direction-aware and location-sensitive information, which helps the model to locate the region of interest more accurately and enhance the representation of changing region features.
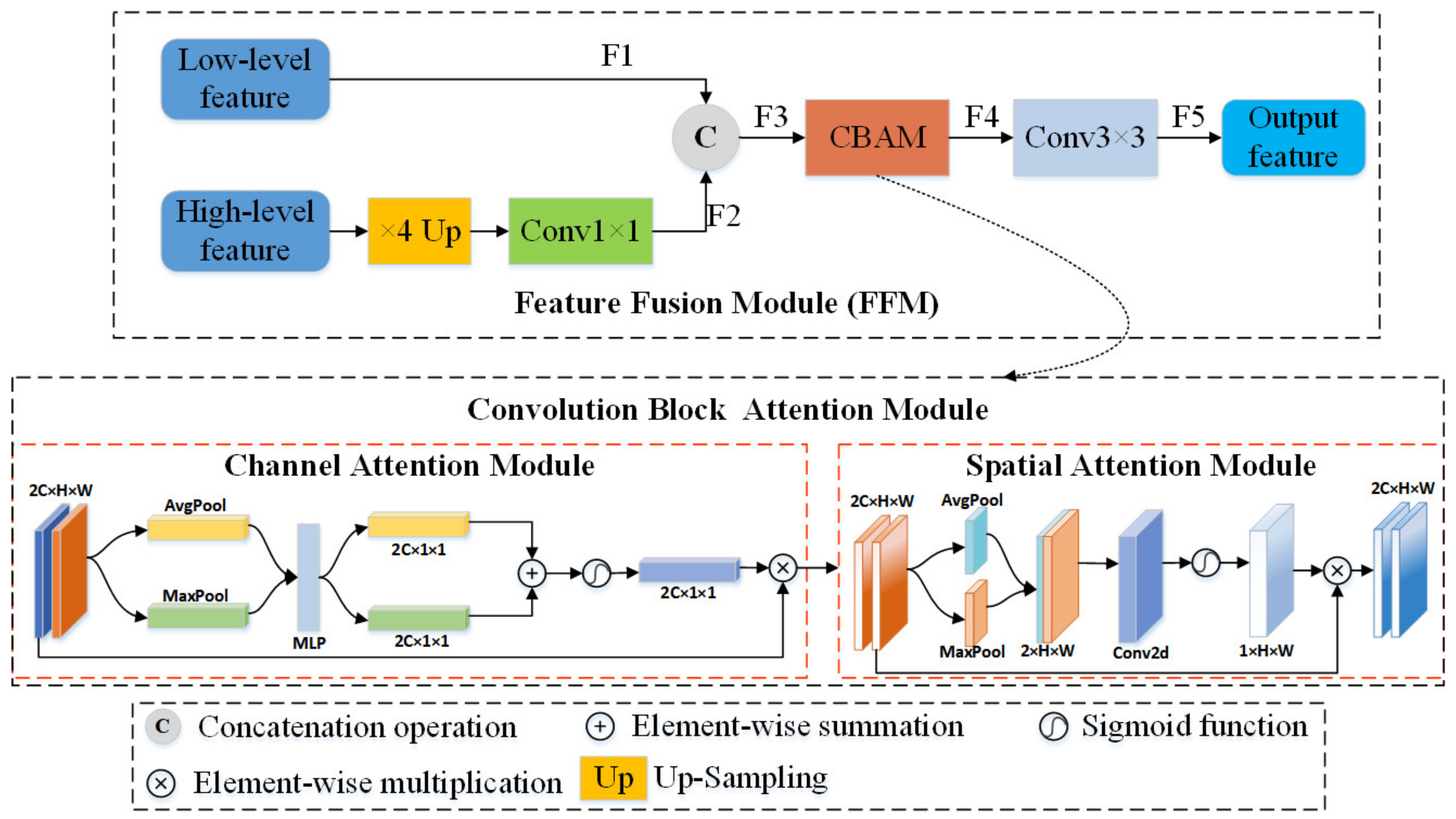
- To solve the problem of inadequate feature fusion and insufficient feature communication in different layers or scales, we designed the attention-based Feature Fusion Module (FFM), which is divided into FFM_ S1 and FFM_S2 according to the input feature maps. FFM_S1 fuses the high-level feature maps with the low-level feature maps by a cross-layer approach. This cross-layer feature fusion approach is of great benefit to highlight the spatial consistency of objects. FFM_S2 fuses two feature maps of the same scale, and it should be noted that one is the feature map of T1 and one is the feature map of T2. The role of FFM_S2 is to fully fuse the feature maps of the bi-temporal image pairs to obtain a better change map.
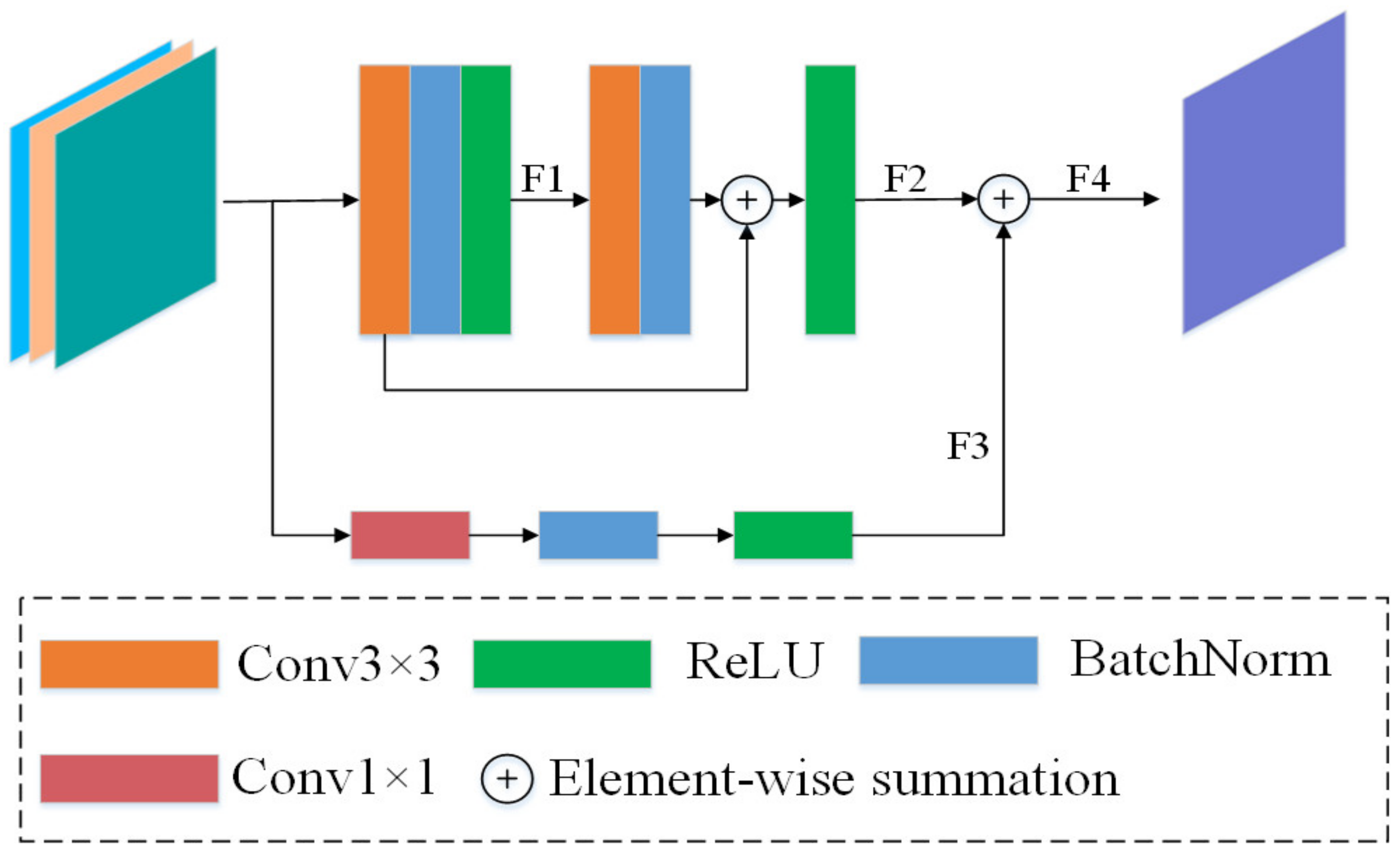
- We propose a Refinement Residual Block (RRB) using a residual structure, which can compensate for the shortcomings of using a single convolutional kernel to refine the feature representation method.
2. Methodology
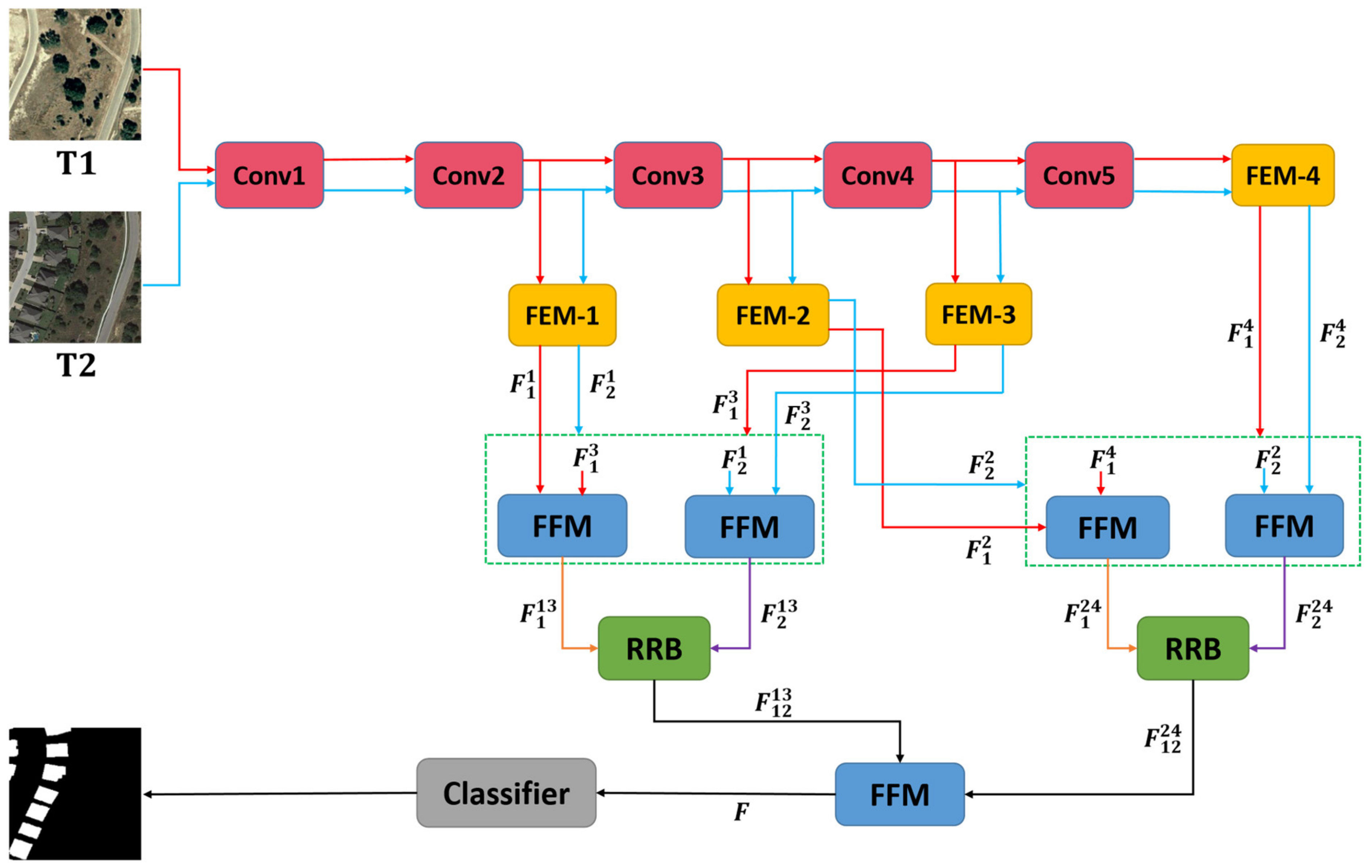
2.1. Network Architecture
2.2. Feature Enhancement Module
2.3. Feature Fusion Module
2.3.1. Channel Attention Module
2.3.2. Spatial Attention Module
2.4. Refinement Residual Block
2.5. Loss Function
3. Experiments and Results
3.1. Datasets and Settings
3.2. Evaluation Metrics and Settings
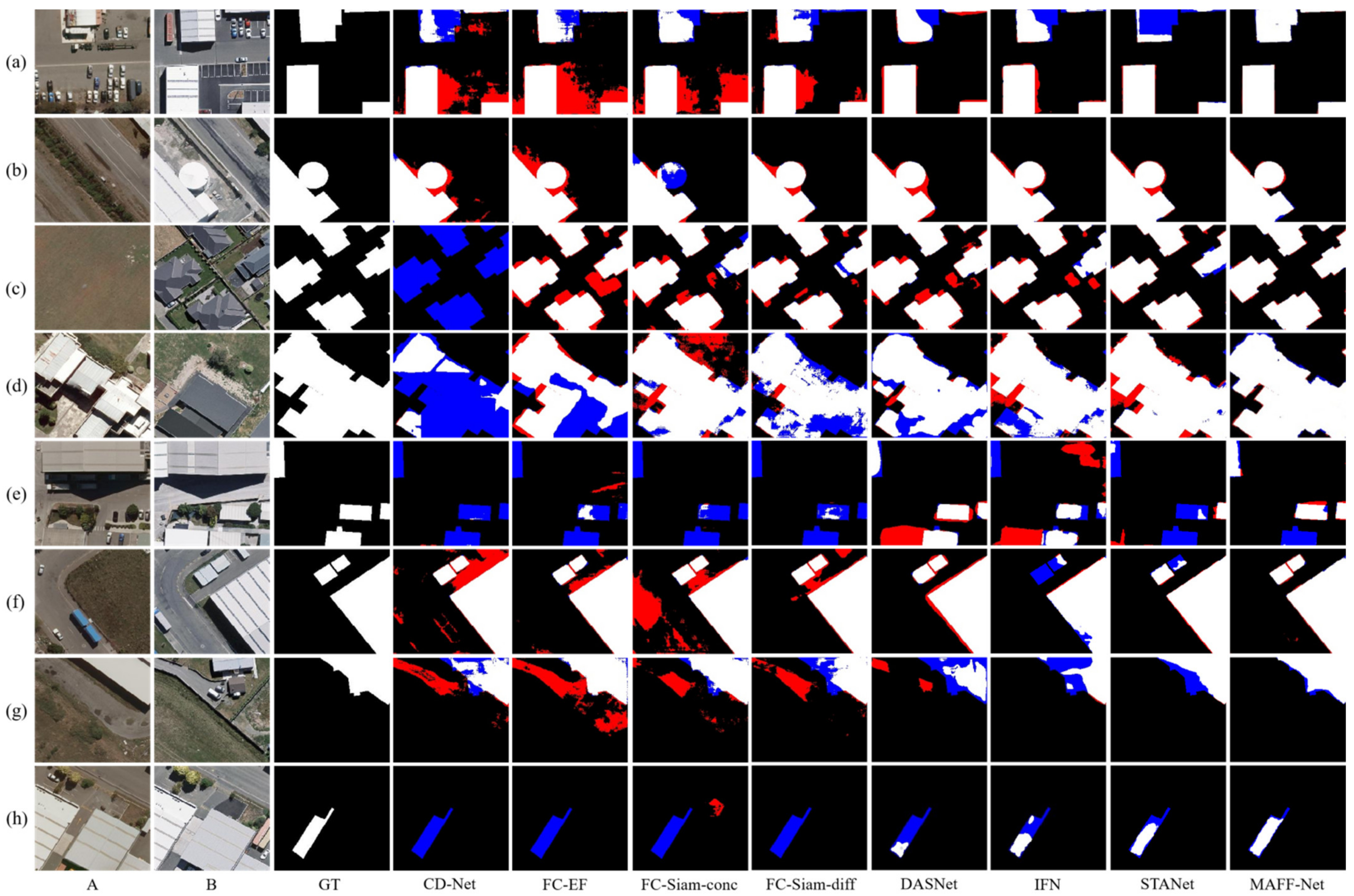
3.3. Comparison of Experimental Results
3.3.1. Comparison Methods
- CD-Net [62] combines the multi-sensor fusion SLAM and fast density 3D reconstruction for coarse alignment of image pairs followed by deep learning methods for pixel-level CD.
- FC-EF [38] refers to early fusion with full convolution. It concatenates the two input images before feeding them into the network, treating them as different channels of one image. It is then fed into a standard U-Net.
- FC-Siam-conc [38] connects three feature maps from the two encoder branches and the corresponding layer of the decoder.
- FC-Siam-diff [38] first finds the absolute value of the difference between the feature maps of the two decoder branches and then makes a skip-connection to the corresponding layer of the decoder.
- DASNet [44] is a CD model based on a dual-attentive fully convolutional twin neural network and proposes a weighted double-margin contrastive loss (WDMC) to be able to solve the sample imbalance problem.
- IFN [45] first uses the two Siamese network architectures as the raw images feature extraction network. To enhance the integrity of change map boundaries and internal densities, multi-level depth features are fused with image difference map features by an attention mechanism.
- STANet [42] proposes a new spatial-temporal attention neural network based on twin networks. The network exploits spatial-temporal dependence and designs a CD self-attentive mechanism to model spatial-temporal relations. A new HR remote sensing image dataset, LEVIR-CD, is also proposed.
3.3.2. CDD Dataset
3.3.3. LEVIR-CD Dataset
3.3.4. WHU-CD Dataset
3.4. Ablation Study
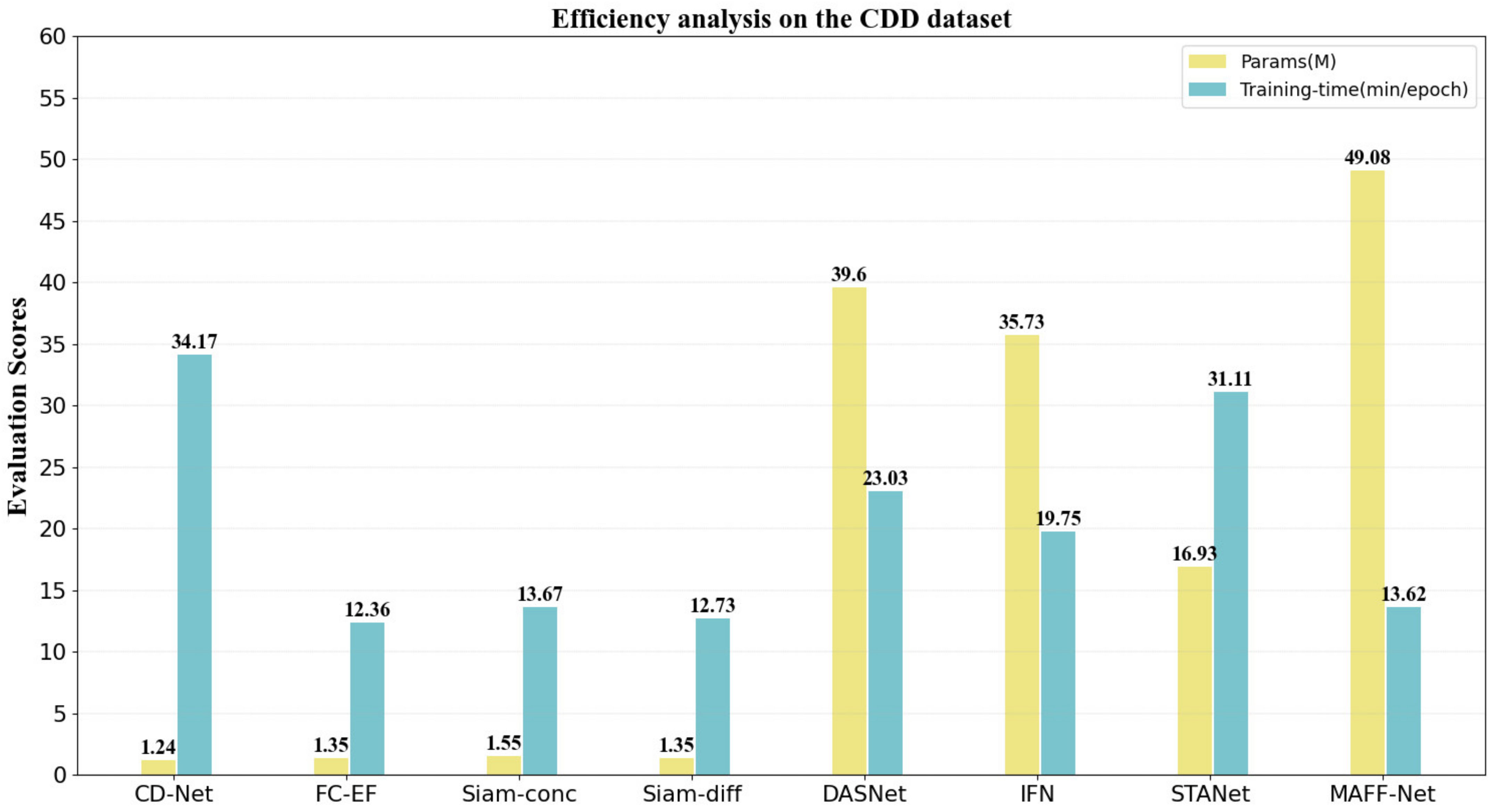
3.5. Efficiency Analysis of the Proposed Network
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CD | change detection |
| HR | high resolution |
| SOTA | state of the art |
| VHR | very high resolution |
| CNN | convolutional neural network |
| FCN | fully convolutional network |
| CA | coordinate attention |
| RRB | refinement residual block |
| FEM | feature enhancement module |
| FFM | feature fusion module |
| GT | ground truth |
| OA | overall accuracy |
| CD-Net | change detection network |
| FC-EF | fully convolutional early fusion |
| FC-Siam-conc | fully convolutional Siamese concatenation |
| FC-Siam-diff | fully convolutional Siamese difference |
| DASNet | dual attentive fully convolutional siamese networks |
| IFN | image fusion network |
| STANet | a spatial-temporal attention-based method |
| MAFF-Net | multi-attention guided feature fusion network |
References
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Radke, R.J.; Andra, S.; Al-Kofahi, O.; Roysam, B. Image change detection algorithms: A systematic survey. IEEE Trans. Image Process. 2005, 14, 294–307. [Google Scholar] [CrossRef]
- Tison, C.; Nicolas, J.M.; Tupin, F.; Maître, H. A new statistical model for Markovian classification of urban areas in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2046–2057. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A Deep Multitask Learning Framework Coupling Semantic Segmentation and Fully Convolutional LSTM Networks for Urban Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7651–7668. [Google Scholar] [CrossRef]
- Yang, J.; Weisberg, P.J.; Bristow, N.A. Landsat remote sensing approaches for monitoring long-term tree cover dynamics in semi-arid woodlands: Comparison of vegetation indices and spectral mixture analysis. Remote Sens. Environ. 2012, 119, 62–71. [Google Scholar] [CrossRef]
- Isaienkov, K.; Yushchuk, M.; Khramtsov, V.; Seliverstov, O. Deep Learning for Regular Change Detection in Ukrainian Forest Ecosystem With Sentinel-2. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2021, 14, 364–376. [Google Scholar] [CrossRef]
- Khan, S.H.; He, X.; Porikli, F.; Bennamoun, M. Forest Change Detection in Incomplete Satellite Images with Deep Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5407–5423. [Google Scholar] [CrossRef]
- Sublime, J.; Kalinicheva, E. Automatic post-disaster damage mapping using deep-learning techniques for change detection: Case study of the Tohoku tsunami. Remote Sens. 2019, 11, 1123. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Hu, L.; Zhang, Y.; Li, Y. MRA-SNet: Siamese Networks of Multiscale Residual and Attention for Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 4528. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS-J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Wang, L.; Li, H. Soft-change detection in optical satellite images. IEEE Trans. Geosci. Remote Sens. Lett. 2011, 8, 879–883. [Google Scholar]
- Quarmby, N.A.; Cushnie, J.L. Monitoring urban land cover changes at the urban fringe from SPOT HRV imagery in south-east England. Int. J. Remote Sens. 1989, 10, 953–963. [Google Scholar] [CrossRef]
- Howarth, P.J.; Wickwareg, M. Procedures for change detection using Landsat digital data. Int. J. Remote Sens. 1981, 2, 277–291. [Google Scholar] [CrossRef]
- Ludeke, A.K.; Maggio, R.C.; Reid, L.M. An analysis of anthropogcnic deforcstation usinglogistic regression and GIS. J. Environ. Manag. 1990, 31, 247–259. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, R. Multi-temporal remote sensing change detection based on independent component analysis. Int. J. Remote Sens. 2006, 27, 2055–2061. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Conradsen, K.; Simpson, J.J. Multivariate alteration detection (MAD) and MAF postprocessing in multispectral, bitemporal image data: New approaches to change detection studies. Remote Sens. Environ. 1998, 64, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, A.A. The Regularized Iteratively Reweighted MAD Method for Change Detection in Multi- and Hyperspectral Data. IEEE Trans. Image Process. 2007, 16, 463–478. [Google Scholar] [CrossRef] [Green Version]
- Bovolo, F.; Bruzzone, L. A theoretical framework for unsupervised change detection based on change vector analysis in the polar domain. IEEE Trans. Geosci. Remote Sens. 2007, 45, 218–236. [Google Scholar] [CrossRef] [Green Version]
- Bovolo, F.; Marchesi, S.; Member, S. A framework for automatic and unsupervised detection of multiple changes in multitemporal images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2196–2212. [Google Scholar] [CrossRef]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Du, P. Hierarchical unsupervised change detection in multitemporal hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 244–260. [Google Scholar]
- Liu, S.; Bruzzone, L.; Bovolo, F.; Zanetti, M.; Du, P. Sequential spectral change vector analysis for iteratively discovering and detecting multiple changes in hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4363–4378. [Google Scholar] [CrossRef]
- Thonfeld, F.; Feilhauer, H.; Braun, M.; Menz, G. Robust change vector analysis (RCVA) for multi-sensor very high resolution optical satellite data. Int. J. Appl. Earth Obs. Geoinf. 2016, 50, 131–140. [Google Scholar] [CrossRef]
- Blaschke, T.; Hay, G.J.; Kelly, M.; Lang, S.; Hofmann, P.; Addink, E.; Feitosa, R.; Meer, F.; Werff, H.; Coillie, F.; et al. Geographic object-based image analysis–Towards a new paradigm. ISPRS-J. Photogramm. Remote Sens. 2014, 87, 180–191. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Li, M.; Blaschke, T.; Ma, X.; Tiede, D.; Cheng, L.; Chen, D. Object-based change detection in urban areas: The effects of segmentation strategy, scale, and feature space on unsupervised methods. Remote Sens. 2016, 8, 761. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Peng, D.; Huang, X. Object-based change detection for VHR images based on multiscale uncertainty analysis. IEEE Geosci. Remote Sens. Lett. 2017, 15, 13–17. [Google Scholar] [CrossRef]
- Zhang, C.; Li, G.; Cui, W. High-resolution remote sensing image change detection by statistical-object-based method. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2018, 11, 2440–2447. [Google Scholar] [CrossRef]
- Gil-Yepes, J.L.; Ruiz, L.A.; Recio, J.A.; Balaguer-Beser, Á.; Hermosilla, T. Description and validation of a new set of object-based temporal geostatistical features for land-use/land-cover change detection. ISPRS J. Photogramm. Remote Sens. 2016, 121, 77–91. [Google Scholar] [CrossRef]
- Qin, Y.; Niu, Z.; Chen, F.; Li, B.; Ban, Y. Object-based land cover change detection for cross-sensor images. Int. J. Remote Sens. 2013, 34, 6723–6737. [Google Scholar] [CrossRef]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning sentiment-specific word embedding for twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–25 June 2014; pp. 1555–1565. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.A.; Rush, A.M. Character-aware neural language models. In Proceedings of the Thirtieth AAAI Conference on Artifcial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2741–2749. [Google Scholar]
- Lei, T.; Zhang, Q.; Xue, D.; Chen, T.; Meng, H.; Nandi, A.K. End-to-end Change Detection Using a Symmetric Fully Convolutional Network for Landslide Mapping. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brighton, UK, 12–17 May 2019; pp. 3027–3031. [Google Scholar]
- Li, X.; Yuan, Z.; Wang, Q. Unsupervised Deep Noise Modeling for Hyperspectral Image Change Detection. Remote Sens. 2019, 11, 258. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q.; Chen, K.; Zhou, G.; Sun, X. Change Capsule Network for Optical Remote Sensing Image Change Detection. Remote Sens. 2021, 13, 2646. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A.; Gousseau, Y. High Resolution Semantic Change Detection. arXiv 2018, arXiv:1810.08452v1. [Google Scholar]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide Inventory Mapping from Bi-temporal Images Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, S.; Li, Y.; Zhang, Y. Coarse-to-Fine Satellite Images Change Detection Framework via Boundary-Aware Attentive Network. Sensors 2020, 20, 6735. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection With Transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual attentive fully convolutional siamese networks for change detection of high resolution satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1194–1206. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtually, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Zhang, Y.; Fu, L.; Li, Y.; Zhang, Y. HDFNet: Hierarchical Dynamic Fusion Network for Change Detection in Optical Aerial Images. Remote Sens. 2021, 13, 1440. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014; pp. 1–10. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Yang, L.; Chen, Y.; Song, S.; Li, F.; Huang, G. Deep Siamese Networks Based Change Detection with Remote Sensing Images. Remote Sens. 2021, 13, 3394. [Google Scholar] [CrossRef]
- Wang, D.; Chen, X.; Jiang, M.; Du, S.; Xu, B.; Wang, J. ADS-Net:An Attention-Based deeply supervised network for remote sensing image change detection. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102348. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Augustus, O.; Vincent, D.; Chris, O. Deconvolution and Checkerboard Artifacts. Distill 2016, 1, e3. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Gulcehre, C.; Moczulski, M.; Denil, M.; Bengio, Y. Noisy activation functions. In Proceedings of the International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 3059–3068. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1857–1866. [Google Scholar]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.; Rubis, A.Y. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. Int. Arch. Photogram. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Simon, S.; Germán, R.; Roberto, A.; Riccardo, G. Street-view change detection with deconvolutional networks. Auton. Robot. 2018, 42, 1301–1322. [Google Scholar] [CrossRef]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Vadera, M.P.; Marlin, B.M. Challenges and Opportunities in Approximate Bayesian Deep Learning for Intelligent IoT Systems. arXiv 2021, arXiv:2112.01675. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | Example Studies |
|---|---|---|
| Traditional CD methods | Pixel-based CD | Wang et al. [11], Quarmby et al. [12], Howarth et al. [13], Ludeke et al. [14], Zhang et al. [15], Nielsen et al. [16], Nielsen et al. [17], Bovolo et al. [18], Bovolo et al. [19], Liu et al. [20], Liu et al. [21], Frank et al. [22] |
| Object-based CD | Ma et al. [24], Zhang et al. [25], Zhang et al. [26], Gil-Yepes et al. [27], Qin et al. [28] | |
| Deep learning CD methods | FC-EF [38], FC-Siam-conc [38], FC-Siam-diff [38], Daudt et al. [39], FCN-PP [40], BA2Net [41], STANet [42], BIT-CD [43], DASNet [44], IFN [45], HDFNet [47] | |
| Method | F1 (%) | Kappa (%) | OA (%) |
|---|---|---|---|
| CDNet | 81.9 | 79.6 | 95.9 |
| FC-EF | 83.0 | 80.8 | 96.0 |
| FC-Siam-conc | 84.0 | 81.9 | 96.3 |
| FC-Siam-diff | 84.8 | 82.8 | 96.4 |
| DASNet | 90.1 | 88.7 | 97.5 |
| IFN | 90.6 | 89.2 | 97.6 |
| STANet | 91.6 | 90.4 | 97.9 |
| MAFF-Net | 96.5 | 96.0 | 99.2 |
| Method | F1 (%) | Kappa (%) | OA (%) |
|---|---|---|---|
| CDNet | 78.0 | 76.9 | 97.8 |
| FC-EF | 80.7 | 79.7 | 98.0 |
| FC-Siam-conc | 82.2 | 81.2 | 98.0 |
| FC-Siam-diff | 83.7 | 82.8 | 98.3 |
| DASNet | 84.6 | 83.7 | 98.4 |
| IFN | 86.2 | 85.4 | 98.6 |
| STANet | 86.5 | 85.9 | 98.9 |
| MAFF-Net | 89.7 | 89.1 | 98.9 |
| Method | F1 (%) | Kappa (%) | OA (%) |
|---|---|---|---|
| CDNet | 80.4 | 79.4 | 98.0 |
| FC-EF | 82.3 | 81.4 | 98.2 |
| FC-Siam-conc | 82.9 | 82.0 | 98.2 |
| FC-Siam-diff | 83.3 | 82.5 | 98.4 |
| DASNet | 90.7 | 90.1 | 99.0 |
| IFN | 88.1 | 87.5 | 98.9 |
| STANet | 89.8 | 89.3 | 99.0 |
| MAFF-Net | 92.4 | 92.1 | 99.4 |
| Model | CDD | LEVIR-CD | WHU-CD | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | FEM | FFM_S1 | RRB | FFM_S2 | F1 | Kappa | OA | F1 | Kappa | OA | F1 | Kappa | OA |
| √ | × | × | × | × | 88.0 | 86.3 | 96.9 | 83.3 | 82.4 | 98.2 | 86.0 | 85.3 | 98.8 |
| √ | √ | × | × | × | 93.6 | 92.7 | 98.4 | 87.0 | 86.3 | 98.6 | 89.9 | 89.3 | 99.0 |
| √ | √ | √ | × | × | 94.6 | 93.8 | 98.7 | 88.2 | 87.6 | 98.7 | 91.4 | 90.9 | 99.1 |
| √ | √ | √ | √ | × | 95.9 | 95.4 | 99.0 | 88.8 | 88.2 | 98.8 | 91.9 | 91.5 | 99.2 |
| √ | √ | √ | √ | √ | 96.5 | 96.0 | 99.2 | 89.7 | 89.1 | 98.7 | 92.4 | 92.1 | 99.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Shi, G.; Li, Y.; Zhao, Z. MAFF-Net: Multi-Attention Guided Feature Fusion Network for Change Detection in Remote Sensing Images. Sensors 2022, 22, 888. https://doi.org/10.3390/s22030888
Ma J, Shi G, Li Y, Zhao Z. MAFF-Net: Multi-Attention Guided Feature Fusion Network for Change Detection in Remote Sensing Images. Sensors. 2022; 22(3):888. https://doi.org/10.3390/s22030888
Chicago/Turabian StyleMa, Jinming, Gang Shi, Yanxiang Li, and Ziyu Zhao. 2022. "MAFF-Net: Multi-Attention Guided Feature Fusion Network for Change Detection in Remote Sensing Images" Sensors 22, no. 3: 888. https://doi.org/10.3390/s22030888