
Enhancing Crop Yield Prediction Utilizing Machine Learning on Satellite-Based Vegetation Health Indices


Abstract
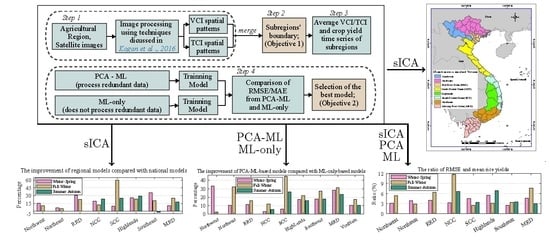
:
1. Introduction
2. The Proposed Crop Yield Prediction Framework
2.1. Step 1: Generation of VCI and TCI Data from Satellite Data
2.2. Step 2: sICA-Based Determination of Subregions
2.3. Step 3: Preparation of Predictor and Response Variables
2.3.1. Determining the Average VCI/TCI Time Series (Predictor Data) for Each Subregion
2.3.2. Determining Detrending Average Crop Production Time Series (Response Data) for Each Subregion
2.3.3. Splitting Predictor/Response Data into Training and Test Datasets
2.4. Step 4: Development of Crop Yield Prediction Models
2.4.1. Training the Model
2.4.2. Testing the Models
3. A Case Study of Vietnam’s Rice Production
3.1. Vietnam: Background
3.2. Generation of VCI and TCI Data from Satellite Data (Step 1)
3.3. sICA-Based Determination of Subregions (Step 2)
3.3.1. The Number of Independent Components of sICA
3.3.2. Spatial Patterns of the VCI and TCI
3.3.3. Resulting Subregions Based on Combining the Spatial Patterns of VCI and TCI
3.4. Preparation of Predictor and Response Data for Each Subregion (Step 3)
3.4.1. Detrending Average Rice Production Time Series (Response Data) for Subregions
3.4.2. Average VCI/TCI Time Series (Predictor Data) for Subregions
3.4.3. A Training Dataset and a Test Dataset for Each Rice Season
3.5. Development of Rice Yield Prediction Models (Step 4)
3.5.1. Comparing the Performance of PCA-Ml with ML-Only
3.5.2. Analyzing the Effectiveness of Splitting Regions into Subregions
3.5.3. Analysing the Effectiveness of the Proposed Framework in General
4. Discussion: Strengths and Limitations of the Proposed Framework
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Holzworth, D.P.; Snow, V.; Janssen, S.; Athanasiadis, I.N.; Donatelli, M.; Hoogenboom, G.; White, J.W.; Thorburn, P. Agricultural production systems modelling and software: Current status and future prospects. Environ. Model. Softw. 2015, 72, 276–286. [Google Scholar] [CrossRef]
- Louhichi, K.; Janssen, S.; Kanellopoulos, A.; Li, H.; Borkowski, N.; Flichman, G.; Hengsdijk, H.; Zander, P.; Blanco, M.; Stokstad, G.; et al. A generic Farming System Simulator. Environmental and Agricultural Modelling: Integrated Approaches for Policy Impact Assessmen. In Environmental and Agricultural Modelling: Integrated Approaches for Policy Impact Assessmen; Springer Academic Publishing: Berlin/Heidelberg, Germany, 2010. [Google Scholar] [CrossRef]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep gaussian process for crop yield prediction based on remote sensing data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Number 1. [Google Scholar]
- Wang, A.X.; Tran, C.; Desai, N.; Lobell, D.; Ermon, S. Deep transfer learning for crop yield prediction with remote sensing data. In Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies, San Jose, CA, USA, 20–22 June 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Wassmann, R.; Jagadish, S.; Sumfleth, K.; Pathak, H.; Howell, G.; Ismail, A.; Serraj, R.; Redona, E.; Singh, R.; Heuer, S. Regional vulnerability of climate change impacts on Asian rice production and scope for adaptation. Adv. Agron. 2009, 102, 91–133. [Google Scholar] [CrossRef]
- Guo, W.W.; Xue, H. An incorporative statistic and neural approach for crop yield modelling and forecasting. Neural Comput. Appl. 2012, 21, 109–117. [Google Scholar] [CrossRef]
- Qian, B.; De Jong, R.; Warren, R.; Chipanshi, A.; Hill, H. Statistical spring wheat yield forecasting for the Canadian prairie provinces. Agric. For. Meteorol. 2009, 149, 1022–1031. [Google Scholar] [CrossRef]
- Alvarez, R. Predicting average regional yield and production of wheat in the Argentine Pampas by an artificial neural network approach. Eur. J. Agron. 2009, 30, 70–77. [Google Scholar] [CrossRef]
- Prasad, A.K.; Chai, L.; Singh, R.P.; Kafatos, M. Crop yield estimation model for Iowa using remote sensing and surface parameters. Int. J. Appl. Earth Obs. Geoinf. 2006, 8, 26–33. [Google Scholar] [CrossRef]
- Kogan, F.; Kussul, N.; Adamenko, T.; Skakun, S.; Kravchenko, O.; Kryvobok, O.; Shelestov, A.; Kolotii, A.; Kussul, O.; Lavrenyuk, A. Winter wheat yield forecasting in Ukraine based on Earth observation, meteorological data and biophysical models. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 192–203. [Google Scholar] [CrossRef]
- Kogan, F.; Guo, W.; Yang, W.; Harlan, S. Space-based vegetation health for wheat yield modeling and prediction in Australia. J. Appl. Remote Sens. 2018, 12, 026002. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. For. Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Anderson, M.C.; Hain, C.R.; Jurecka, F.; Trnka, M.; Hlavinka, P.; Dulaney, W.; Otkin, J.A.; Johnson, D.; Gao, F. Relationships between the evaporative stress index and winter wheat and spring barley yield anomalies in the Czech Republic. Clim. Res. 2016, 70, 215–230. [Google Scholar] [CrossRef] [Green Version]
- Bhojani, S.H.; Bhatt, N. Wheat crop yield prediction using new activation functions in neural network. Neural Comput. Appl. 2020, 32, 13941–13951. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. For. Meteorol. 2016, 218, 74–84. [Google Scholar] [CrossRef]
- Pryzant, R.; Ermon, S.; Lobell, D. Monitoring ethiopian wheat fungus with satellite imagery and deep feature learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 39–47. [Google Scholar] [CrossRef]
- Filippi, P.; Jones, E.J.; Wimalathunge, N.S.; Somarathna, P.D.; Pozza, L.E.; Ugbaje, S.U.; Jephcott, T.G.; Paterson, S.E.; Whelan, B.M.; Bishop, T.F. An approach to forecast grain crop yield using multi-layered, multi-farm data sets and machine learning. Precis. Agric. 2019, 20, 1015–1029. [Google Scholar] [CrossRef]
- Saeed, U.; Dempewolf, J.; Becker-Reshef, I.; Khan, A.; Ahmad, A.; Wajid, S.A. Forecasting wheat yield from weather data and MODIS NDVI using Random Forests for Punjab province, Pakistan. Int. J. Remote Sens. 2017, 38, 4831–4854. [Google Scholar] [CrossRef]
- Oguntunde, P.G.; Lischeid, G.; Dietrich, O. Relationship between rice yield and climate variables in southwest Nigeria using multiple linear regression and support vector machine analysis. Int. J. Biometeorol. 2018, 62, 459–469. [Google Scholar] [CrossRef] [PubMed]
- Park, J.K.; Das, A.; Park, J.H. Integrated model for predicting rice yield with climate change. Int. Agrophys. 2018, 32, 203–215. [Google Scholar] [CrossRef]
- Rahman, A.; Roytman, L.; Krakauer, N.Y.; Nizamuddin, M.; Goldberg, M. Use of vegetation health data for estimation of Aus rice yield in Bangladesh. Sensors 2009, 9, 2968–2975. [Google Scholar] [CrossRef]
- Rahman, A.; Khan, K.; Krakauer, N.Y.; Roytman, L.; Kogan, F. Using AVHRR-based vegetation health indices for estimation of potato yield in Bangladesh. Civ. Environ. Eng. 2012, 2, 3. [Google Scholar] [CrossRef] [Green Version]
- Abbas, F.; Afzaal, H.; Farooque, A.; Tang, S. Crop yield prediction through proximal sensing and machine learning algorithms. Agronomy 2020, 10, 1046. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. For. Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Mladenova, I.E.; Bolten, J.D.; Crow, W.T.; Anderson, M.C.; Hain, C.R.; Johnson, D.M.; Mueller, R. Intercomparison of soil moisture, evaporative stress, and vegetation indices for estimating corn and soybean yields over the US. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1328–1343. [Google Scholar] [CrossRef]
- Lobell, D.B.; Hammer, G.L.; McLean, G.; Messina, C.; Roberts, M.J.; Schlenker, W. The critical role of extreme heat for maize production in the United States. Nat. Clim. Chang. 2013, 3, 497–501. [Google Scholar] [CrossRef]
- Kang, Y.; Ozdogan, M.; Zhu, X.; Ye, Z.; Hain, C.; Anderson, M. Comparative assessment of environmental variables and machine learning algorithms for maize yield prediction in the US Midwest. Environ. Res. Lett. 2020, 15, 064005. [Google Scholar] [CrossRef]
- Peng, B.; Guan, K.; Pan, M.; Li, Y. Benefits of seasonal climate prediction and satellite data for forecasting US maize yield. Geophys. Res. Lett. 2018, 45, 9662–9671. [Google Scholar] [CrossRef]
- Bussay, A.; van der Velde, M.; Fumagalli, D.; Seguini, L. Improving operational maize yield forecasting in Hungary. Agric. Syst. 2015, 141, 94–106. [Google Scholar] [CrossRef]
- Pede, T.; Mountrakis, G.; Shaw, S.B. Improving corn yield prediction across the US Corn Belt by replacing air temperature with daily MODIS land surface temperature. Agric. For. Meteorol. 2019, 276, 107615. [Google Scholar] [CrossRef]
- Li, Y.; Guan, K.; Yu, A.; Peng, B.; Zhao, L.; Li, B.; Peng, J. Toward building a transparent statistical model for improving crop yield prediction: Modeling rainfed corn in the US. Field Crop. Res. 2019, 234, 55–65. [Google Scholar] [CrossRef]
- Kogan, F.; Popova, Z.; Alexandrov, P. Early forecasting corn yield using field experiment dataset and Vegetation health indices in Pleven region, north Bulgaria. Ecol. Ind. 2016, 9, 76–80. [Google Scholar] [CrossRef]
- Nguyen, L.H.; Zhu, J.; Lin, Z.; Du, H.; Yang, Z.; Guo, W.; Jin, F. Spatial-temporal multi-task learning for within-field cotton yield prediction. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2019; pp. 343–354. [Google Scholar]
- Sharifi, A. Yield prediction with machine learning algorithms and satellite images. J. Sci. Food Agric. 2021, 101, 891–896. [Google Scholar] [CrossRef] [PubMed]
- Pagani, V.; Guarneri, T.; Fumagalli, D.; Movedi, E.; Testi, L.; Klein, T.; Calanca, P.; Villalobos, F.; Lopez-Bernal, A.; Niemeyer, S.; et al. Improving cereal yield forecasts in Europe–The impact of weather extremes. Eur. J. Agron. 2017, 89, 97–106. [Google Scholar] [CrossRef]
- Kouadio, L.; Deo, R.C.; Byrareddy, V.; Adamowski, J.F.; Mushtaq, S.; Nguyen, V.P. Artificial intelligence approach for the prediction of Robusta coffee yield using soil fertility properties. Comput. Electron. Agric. 2018, 155, 324–338. [Google Scholar] [CrossRef]
- Chipanshi, A.; Zhang, Y.; Kouadio, L.; Newlands, N.; Davidson, A.; Hill, H.; Warren, R.; Qian, B.; Daneshfar, B.; Bedard, F.; et al. Evaluation of the Integrated Canadian Crop Yield Forecaster (ICCYF) model for in-season prediction of crop yield across the Canadian agricultural landscape. Agric. For. Meteorol. 2015, 206, 137–150. [Google Scholar] [CrossRef] [Green Version]
- Boogaard, H.; Van Diepen, C.; Rotter, R.; Cabrera, J.; Van Laar, H. WOFOST 7.1; User’s Guide for the WOFOST 7.1 Crop Growth Simulation Model and WOFOST Control Center 1.5; Technical Report; SC-DLO: Wageningen, The Netherlands, 1998. [Google Scholar]
- Williams, J.; Jones, C.; Dyke, P.T. A modeling approach to determining the relationship between erosion and soil productivity. Trans. ASAE 1984, 27, 129–0144. [Google Scholar] [CrossRef]
- Ritchie, J. Description and Performance of CERES Wheat: A User-Oriented Wheat Yield Model; USDA-ARS: Washington, DC, USA, 1985; pp. 159–175.
- Keating, B.A.; Carberry, P.S.; Hammer, G.L.; Probert, M.E.; Robertson, M.J.; Holzworth, D.; Huth, N.I.; Hargreaves, J.N.; Meinke, H.; Hochman, Z.; et al. An overview of APSIM, a model designed for farming systems simulation. Eur. J. Agron. 2003, 18, 267–288. [Google Scholar] [CrossRef] [Green Version]
- Jones, J.W.; Hoogenboom, G.; Porter, C.H.; Boote, K.J.; Batchelor, W.D.; Hunt, L.; Wilkens, P.W.; Singh, U.; Gijsman, A.J.; Ritchie, J.T. The DSSAT cropping system model. Eur. J. Agron. 2003, 18, 235–265. [Google Scholar] [CrossRef]
- Jin, X.; Kumar, L.; Li, Z.; Feng, H.; Xu, X.; Yang, G.; Wang, J. A review of data assimilation of remote sensing and crop models. Eur. J. Agron. 2018, 92, 141–152. [Google Scholar] [CrossRef]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop yield prediction using machine learning: A systematic literature review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, L.; Han, J.; Zha, Y.; Zhu, P. Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crop. Res. 2019, 235, 142–153. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Kogan, F.N. Droughts of the late 1980s in the United States as derived from NOAA polar-orbiting satellite data. Bull. Am. Meteorol. Soc. 1995, 76, 655–668. [Google Scholar] [CrossRef] [Green Version]
- Kogan, F.; Salazar, L.; Roytman, L. Forecasting crop production using satellite-based vegetation health indices in Kansas, USA. Int. J. Remote Sens. 2012, 33, 2798–2814. [Google Scholar] [CrossRef]
- Kogan, F.; Guo, W.; Yang, W. Drought and food security prediction from NOAA new generation of operational satellites. Geomat. Nat. Hazards Risk 2019, 10, 651–666. [Google Scholar] [CrossRef] [Green Version]
- Ali, I.; Greifeneder, F.; Stamenkovic, J.; Neumann, M.; Notarnicola, C. Review of machine learning approaches for biomass and soil moisture retrievals from remote sensing data. Remote Sens. 2015, 7, 16398–16421. [Google Scholar] [CrossRef] [Green Version]
- Teboul, W. Why Use Machine Learning Instead of Traditional Statistics? Retrieved from TowardsDataScience. 2018. Available online: https://towardsdatascience.com/why-use-machine-learning-instead-of-traditional-statistics-334c2213700a (accessed on 9 January 2021).
- Kussul, N.; Shelestov, A.; Skakun, S. Grid and sensor web technologies for environmental monitoring. Earth Sci. Inform. 2009, 2, 37–51. [Google Scholar] [CrossRef] [Green Version]
- Kogan, F.N. Operational space technology for global vegetation assessment. Bull. Am. Meteorol. Soc. 2001, 82, 1949–1964. [Google Scholar] [CrossRef]
- Macintosh, A.; EUis, R. Applications and Innovations in Intelligent Systems XIII; Springer: Berlin/Heidelberg, Germany, 2006; p. 209. [Google Scholar]
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley and Sons: New York, NY, USA, 1981. [Google Scholar] [CrossRef]
- Salazar, L.; Kogan, F.; Roytman, L. Using vegetation health indices and partial least squares method for estimation of corn yield. Int. J. Remote Sens. 2008, 29, 175–189. [Google Scholar] [CrossRef]
- Salazar, L.; Kogan, F.; Roytman, L. Use of remote sensing data for estimation of winter wheat yield in the United States. Int. J. Remote Sens. 2007, 28, 3795–3811. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Mkhabela, M.; Bullock, P.; Raj, S.; Wang, S.; Yang, Y. Crop yield forecasting on the Canadian Prairies using MODIS NDVI data. Agric. For. Meteorol. 2011, 151, 385–393. [Google Scholar] [CrossRef]
- Kogan, F.N. Global drought watch from space. Bull. Am. Meteorol. Soc. 1997, 78, 621–636. [Google Scholar] [CrossRef]
- Kogan, F.; Powell, A.; Fedorov, O. Use of Satellite and In-Situ Data to Improve Sustainability; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- McMichael, A.J.; Campbell-Lendrum, D.; Kovats, S.; Edwards, S.; Wilkinson, P.; Wilson, T.; Nicholls, R.; Hales, S.; Tanser, F.; Le Sueur, D.; et al. Chapter 20 Global Climate Change; Citeseer: State College, PA, USA, 2004; p. I545. [Google Scholar]
- Bouveresse, D.J.R.; Moya-González, A.; Ammari, F.; Rutledge, D.N. Two novel methods for the determination of the number of components in independent components analysis models. Chemom. Intell. Lab. Syst. 2012, 112, 24–32. [Google Scholar] [CrossRef]
- Awange, J.L.; Forootan, E.; Kuhn, M.; Kusche, J.; Heck, B. Water storage changes and climate variability within the Nile Basin between 2002 and 2011. Adv. Water Resour. 2014, 73, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Aurélien, G. Hands-on Machine Learning with Scikit-Learn & Tensorflow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Awange, J.; Paláncz, B.; Völgyesi, L. Hybrid Imaging and Visualization; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; p. 9. [Google Scholar]
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Renwick, J.; McGregor, J. Variations of surface temperature and rainfall in Vietnam from 1971 to 2010. Int. J. Climatol. 2014, 34, 249–264. [Google Scholar] [CrossRef]
- Macarof, P.; Bartic, C.; Groza, S.; Stătescu, F. Identification of drought extent using NVSWI and VHI in Iaşi county area, Romania. Aerul si Apa. Componente ale Mediului 2018, 53–60. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VCI ICs | Subregions | TCI ICs | Subregions |
|---|---|---|---|
| VCI IC1 | MRD | TCI IC1 | Southeast + MRD |
| VCI IC2 | Northwest | TCI IC2 | Northwest |
| VCI IC3 | Highlands + Southeast | TCI IC3 | NCC |
| VCI IC4 | Northeast + RRD | TCI IC4 | Northeast+RRD |
| VCI IC5 | NCC + SCC | TCI IC5 | SCC + Highlands |
| No. | Subregions | VCI ICs | TCI ICs |
|---|---|---|---|
| 1 | Northwest | VCI IC2 | TCI IC2 |
| 2 | Northeast | VCI IC4 | TCI IC4 |
| 3 | RRD | VCI IC4 | TCI IC4 |
| 4 | NCC | VCI IC5 | TCI IC3 |
| 5 | SCC | VCI IC5 | TCI IC5 |
| 6 | Highlands | VCI IC3 | TCI IC5 |
| 7 | Southeast | VCI IC3 | TCI IC1 |
| 8 | MRD | VCI IC1 | TCI IC1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pham, H.T.; Awange, J.; Kuhn, M.; Nguyen, B.V.; Bui, L.K. Enhancing Crop Yield Prediction Utilizing Machine Learning on Satellite-Based Vegetation Health Indices. Sensors 2022, 22, 719. https://doi.org/10.3390/s22030719
Pham HT, Awange J, Kuhn M, Nguyen BV, Bui LK. Enhancing Crop Yield Prediction Utilizing Machine Learning on Satellite-Based Vegetation Health Indices. Sensors. 2022; 22(3):719. https://doi.org/10.3390/s22030719
Chicago/Turabian StylePham, Hoa Thi, Joseph Awange, Michael Kuhn, Binh Van Nguyen, and Luyen K. Bui. 2022. "Enhancing Crop Yield Prediction Utilizing Machine Learning on Satellite-Based Vegetation Health Indices" Sensors 22, no. 3: 719. https://doi.org/10.3390/s22030719