
A Novel Integration of Face-Recognition Algorithms with a Soft Voting Scheme for Efficiently Tracking Missing Person in Challenging Large-Gathering Scenarios

 ,
,  , ,
, ,  , ,
, ,  and
and
Abstract
:1. Introduction
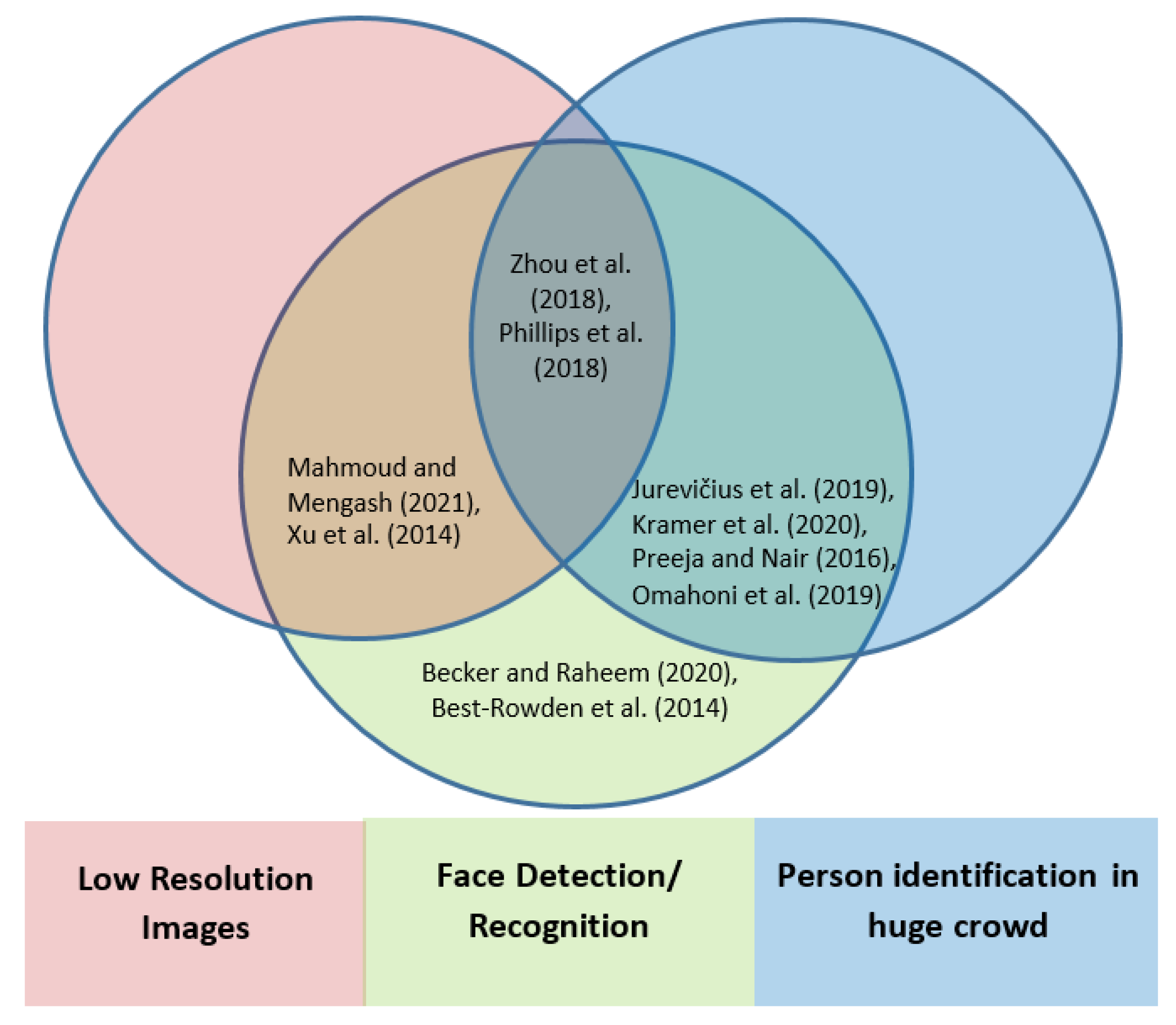
2. Related Work
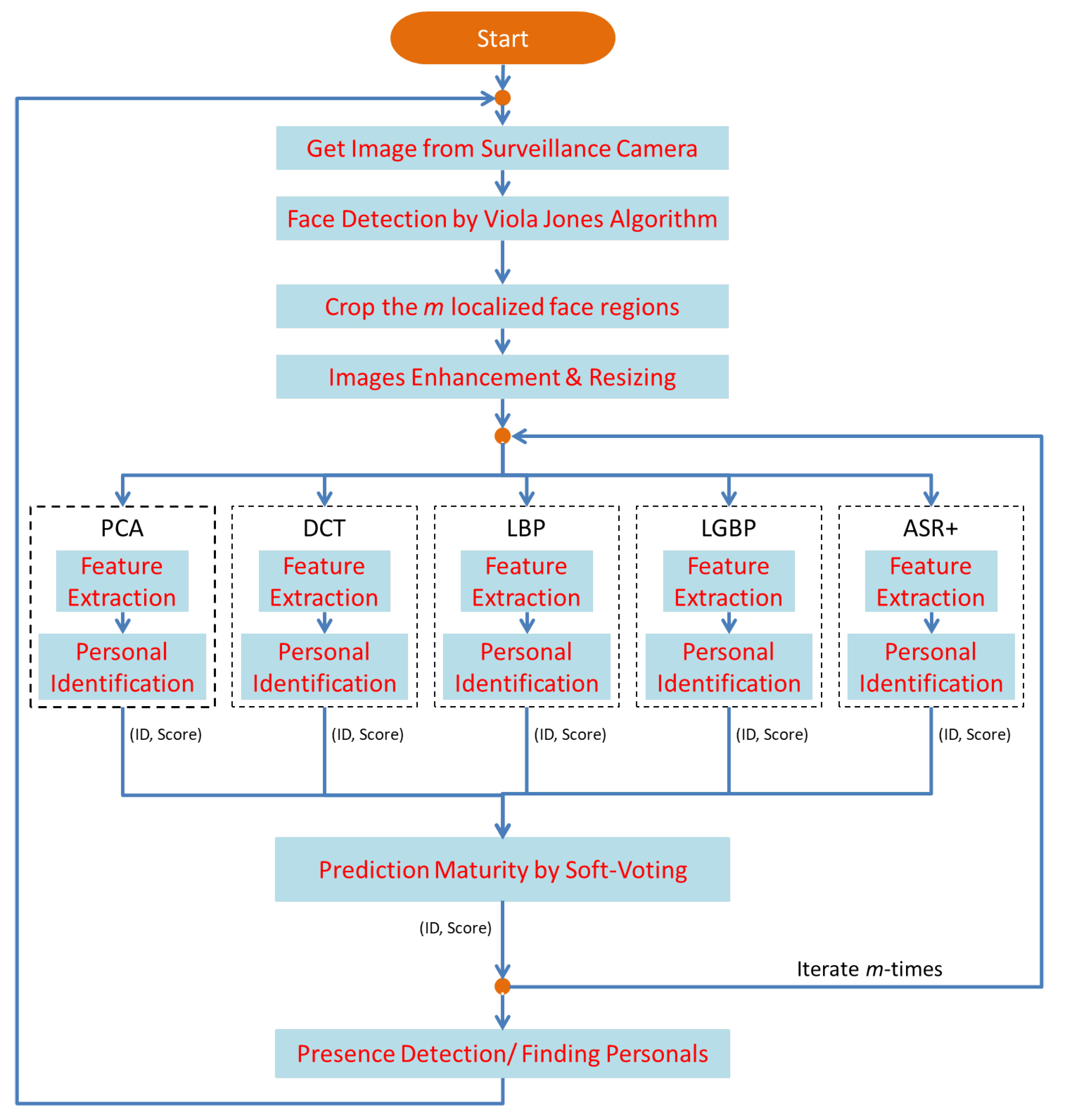
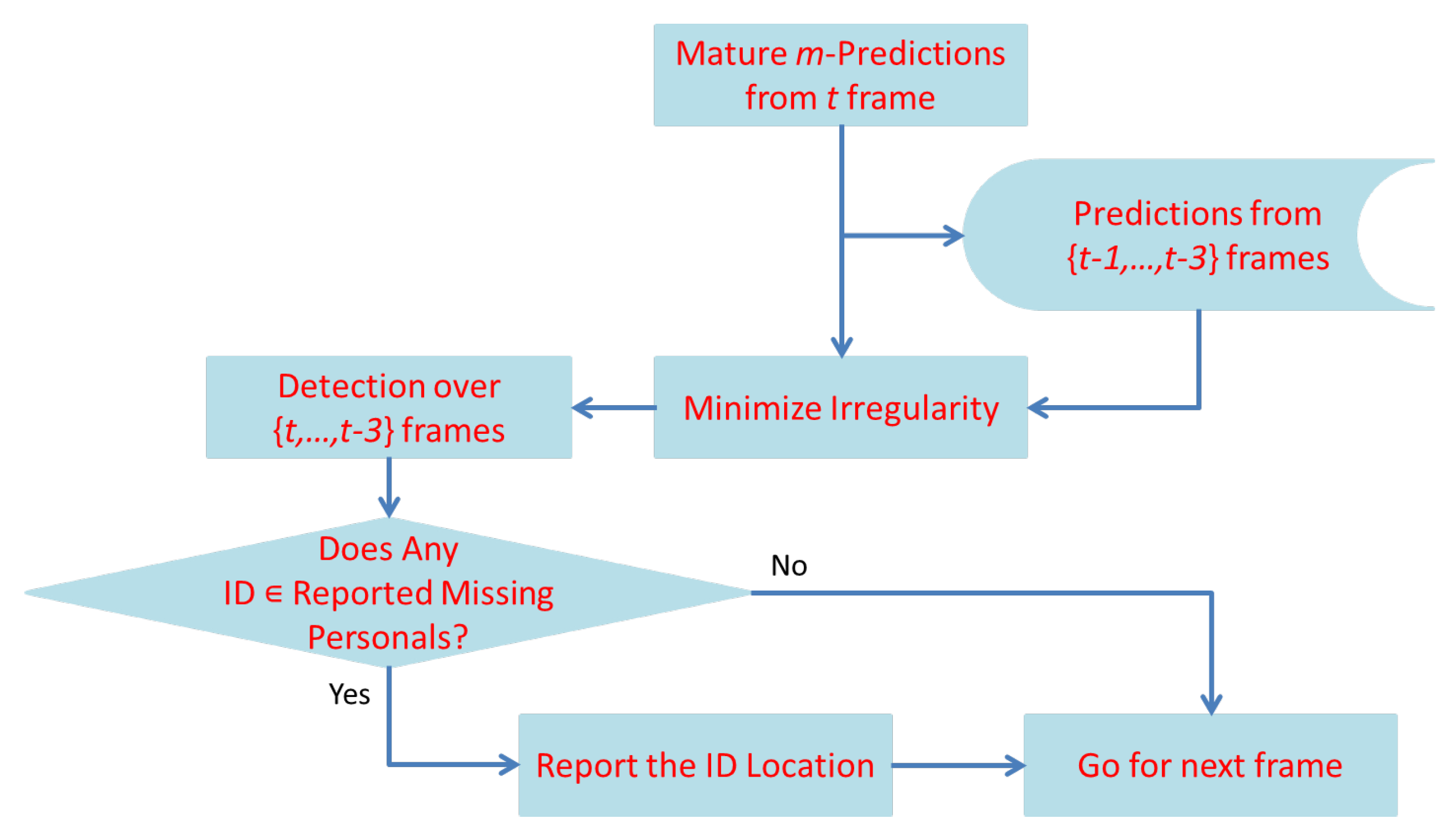
3. Proposed Methodology
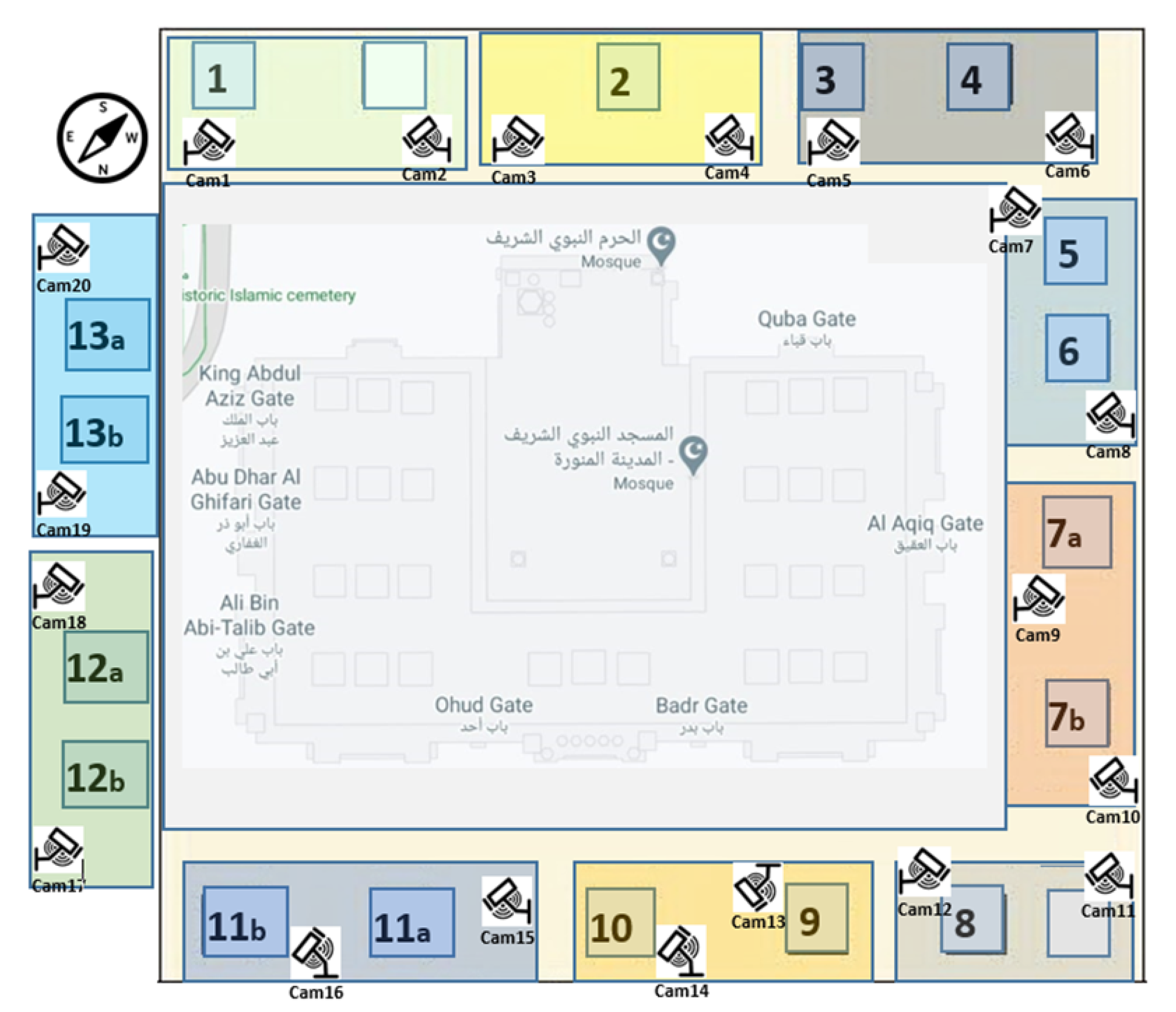
3.1. Cameras Setup and Spatial Distribution of Al-Nabvi Mosque
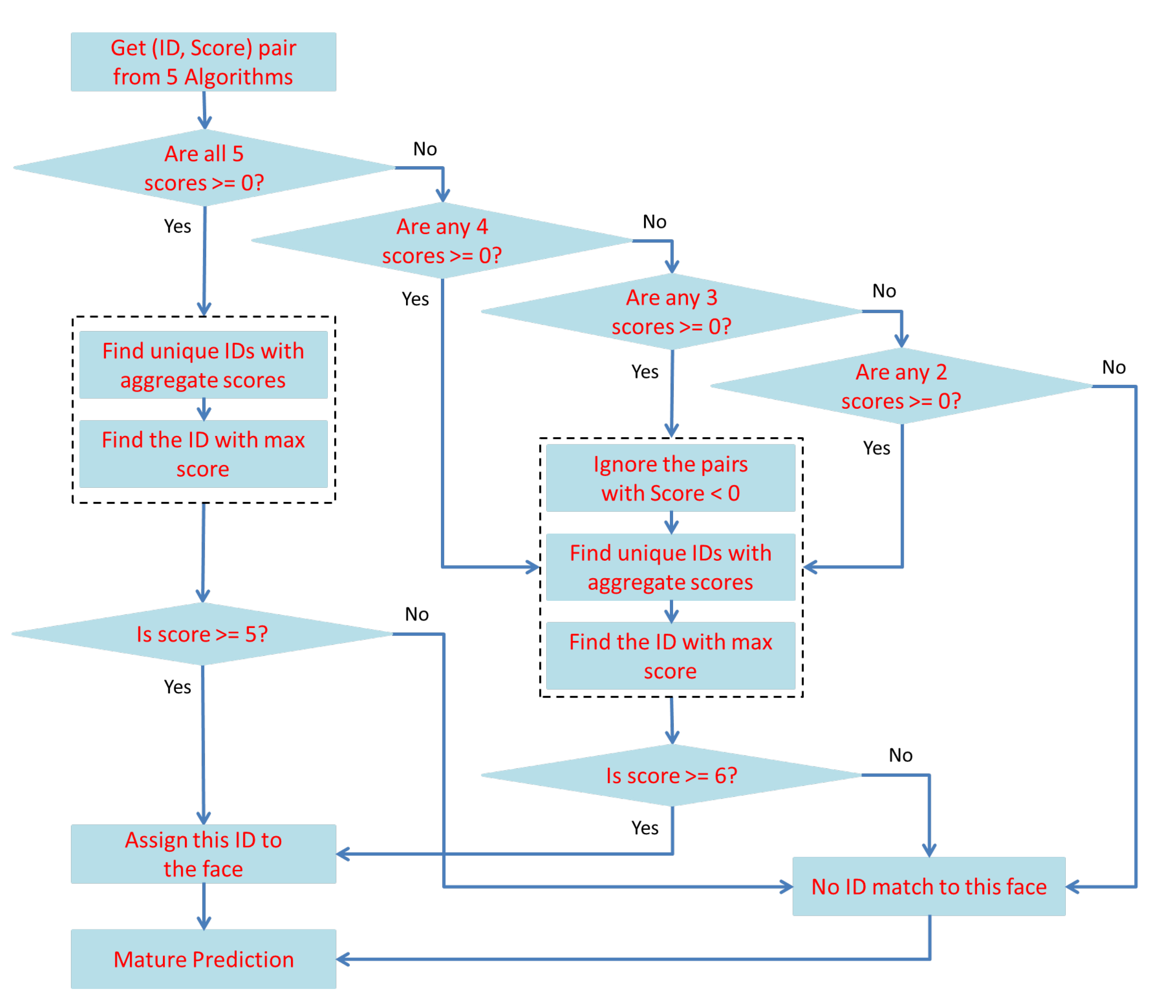
3.2. Integration of Face-Recognition Algorithms with a Soft Voting Scheme
| Algorithm 1 Proposed tracking workflow |
|
4. Results
4.1. Dataset
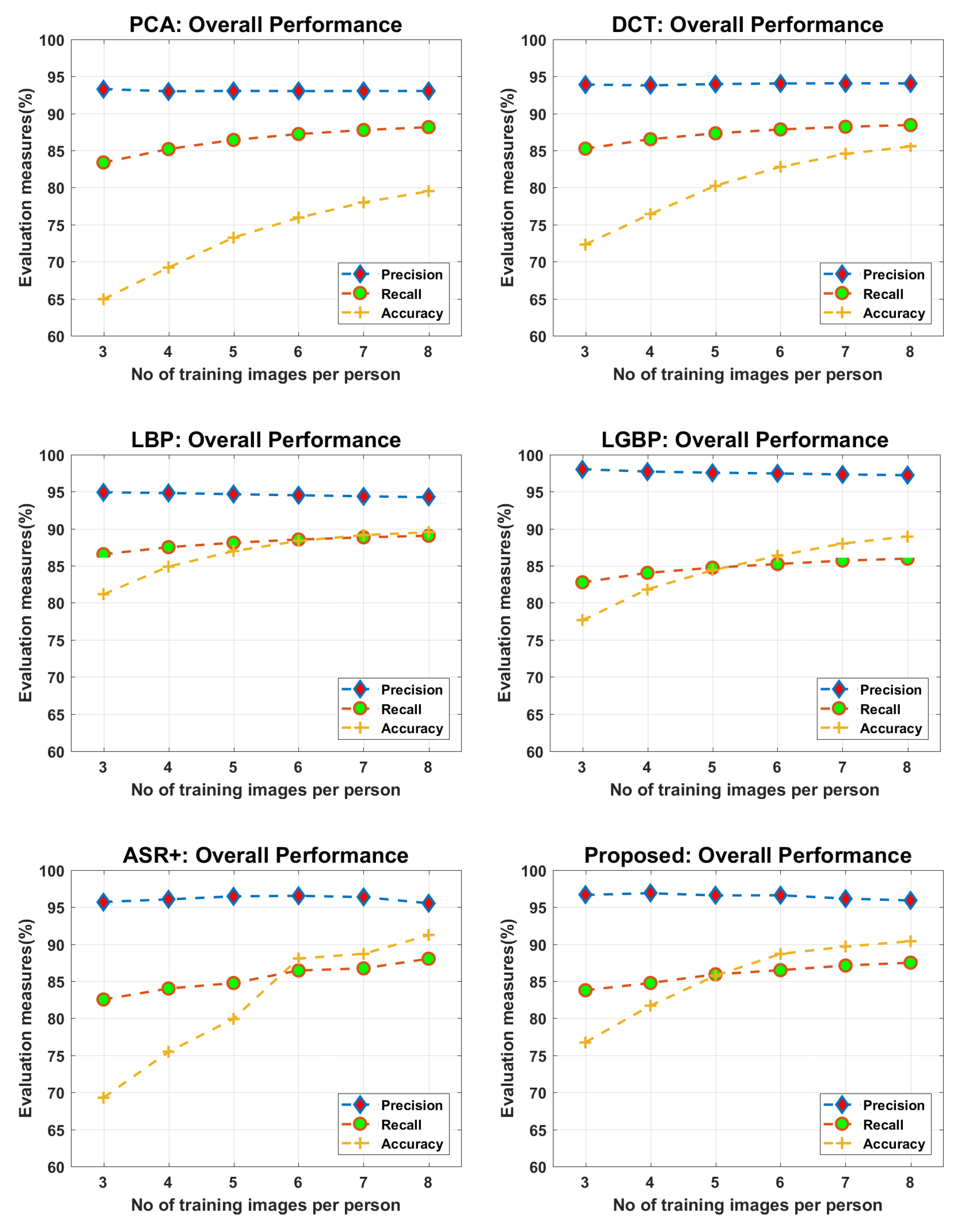
4.2. Face Recognition
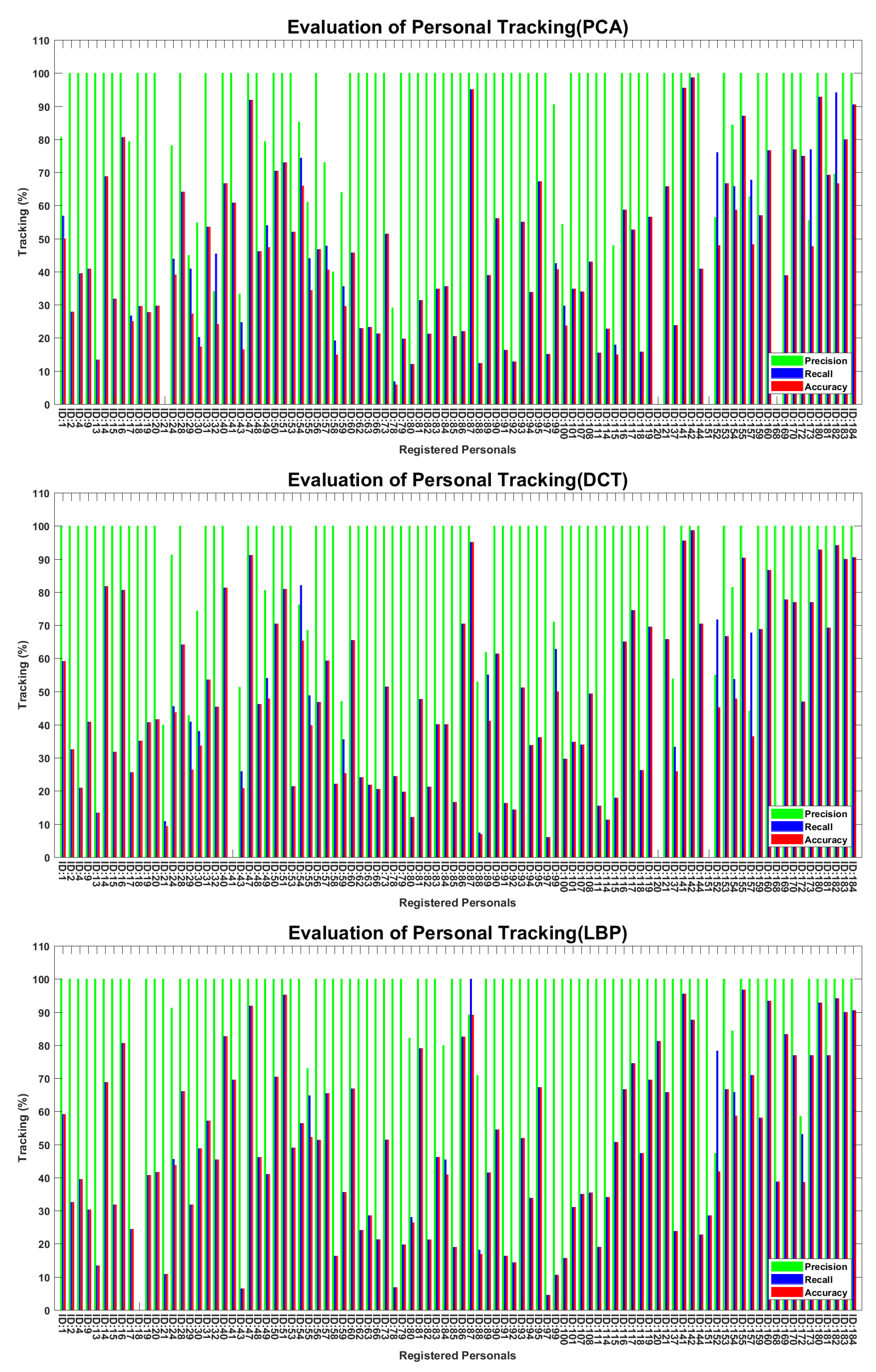
4.2.1. Face Recognition Using Principal Component Analysis (PCA)
4.2.2. Face Recognition via Discrete Cosine Transform (DCT)
4.2.3. Face Recognition via Local Binary Patterns (LBP)
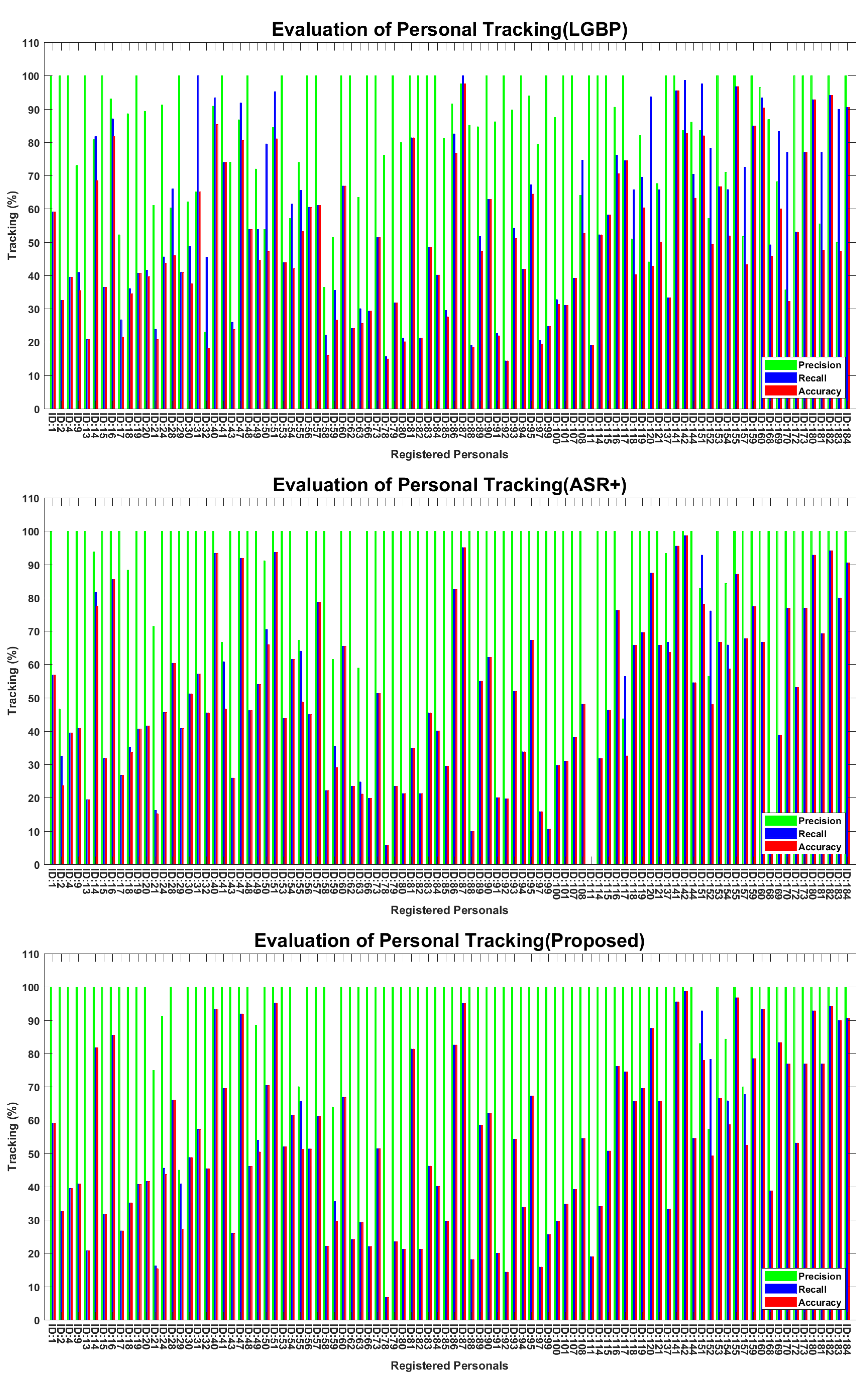
4.2.4. Face Recognition via Local Gabor Binary Pattern Histogram Sequence (LGBPHS)
4.2.5. Face Recognition via Adaptive Sparse Representations of Random Patches (ASR+)
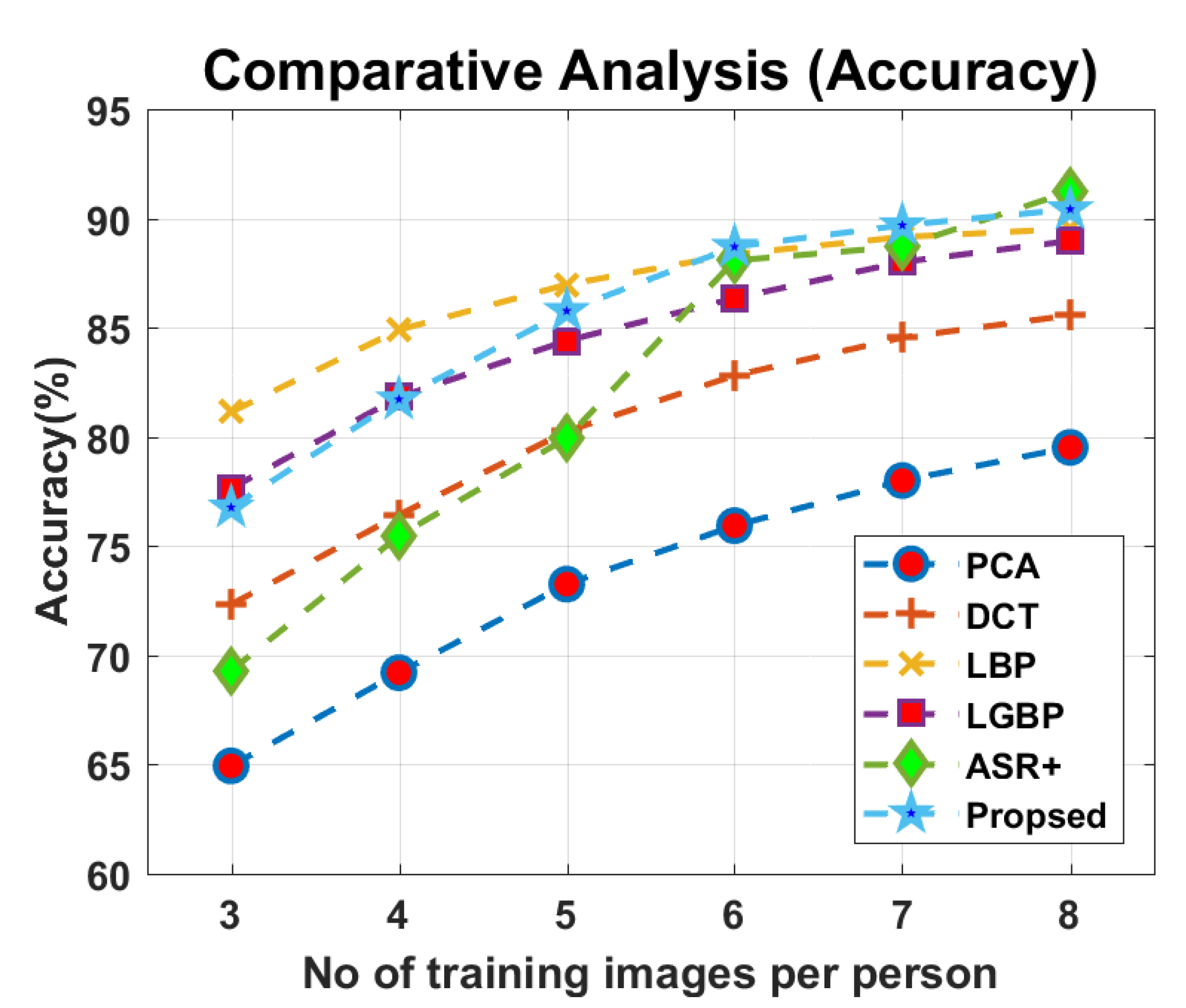
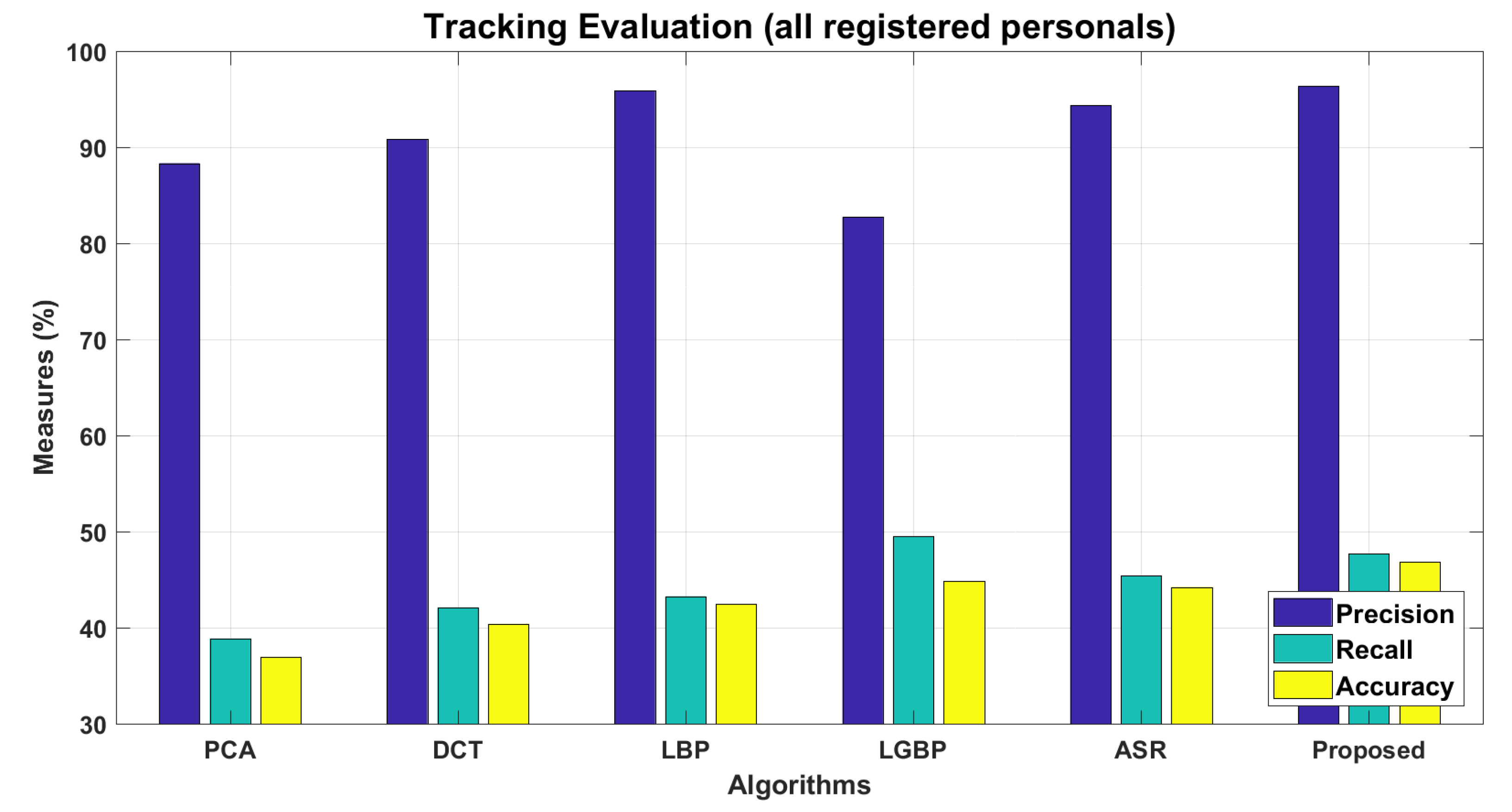
4.2.6. Face Recognition via Integrating the Tested Approaches in Parallel
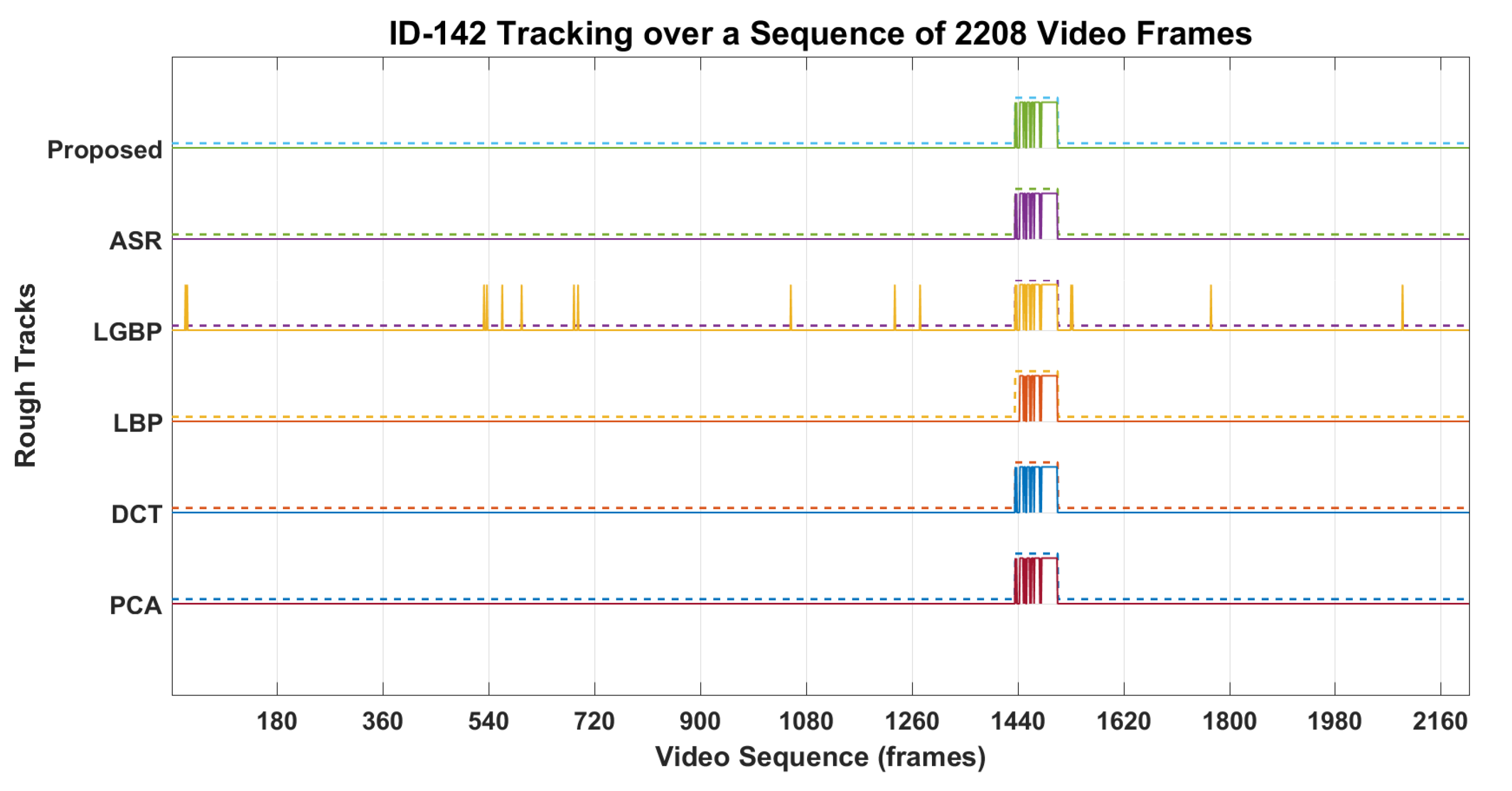
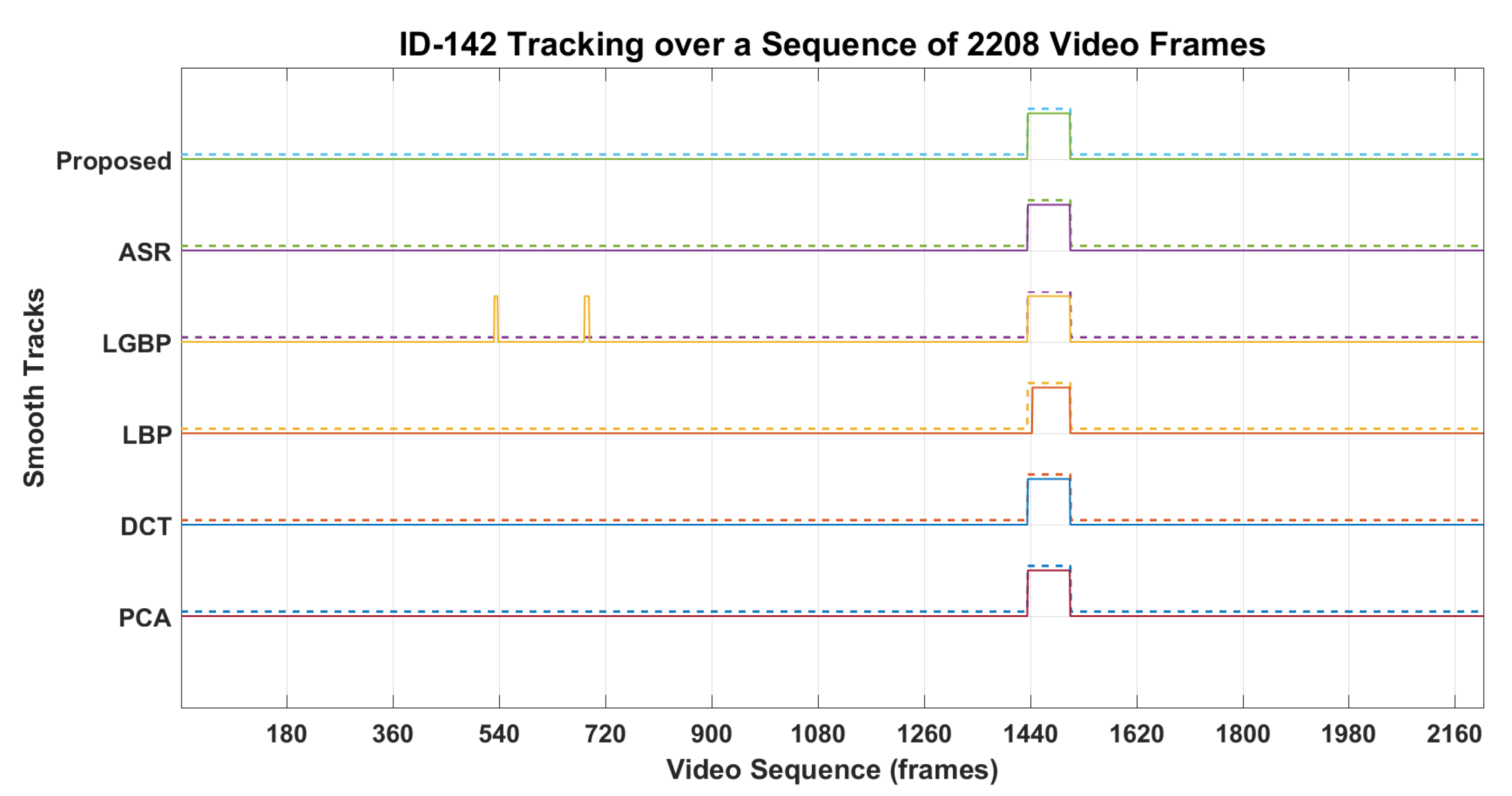
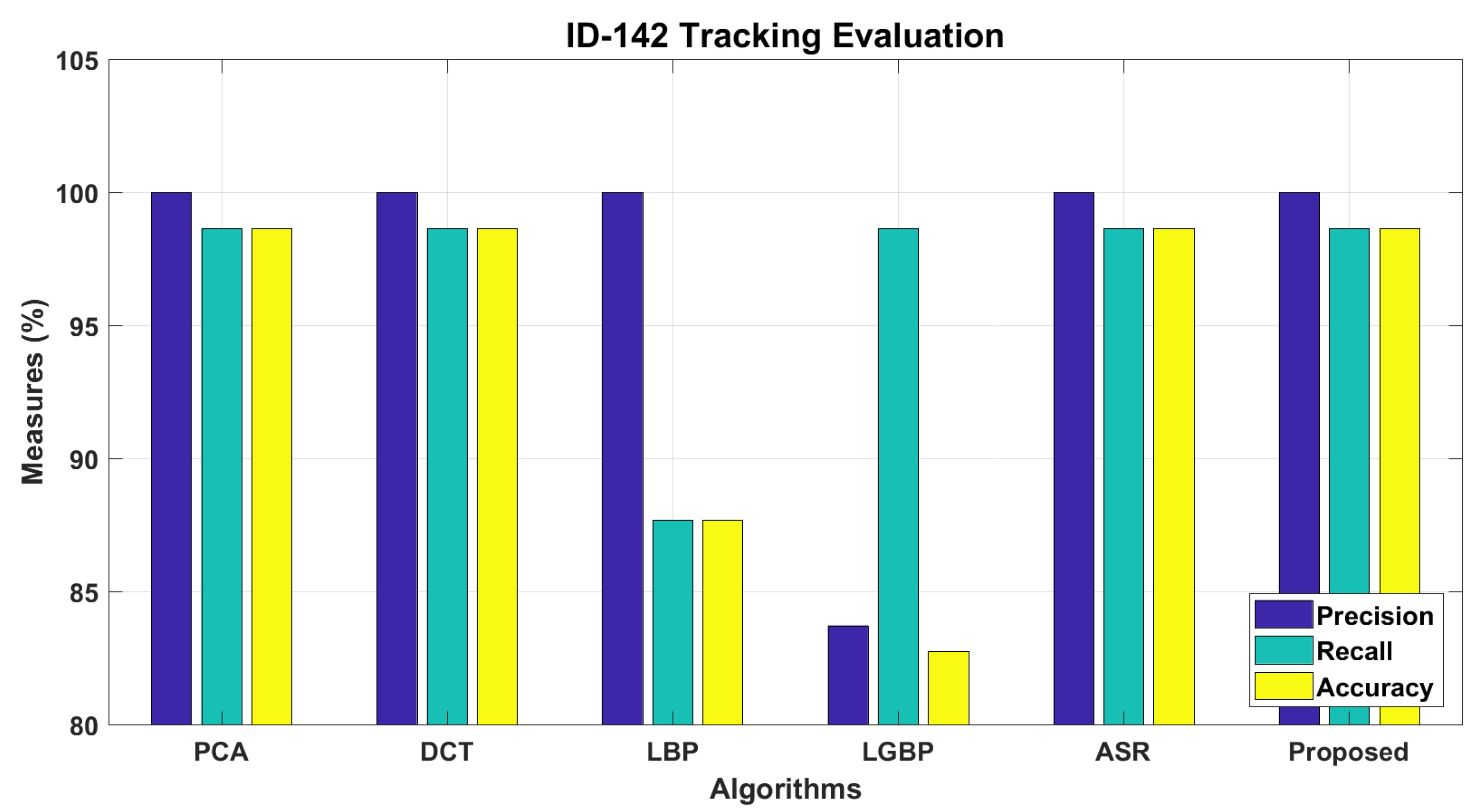
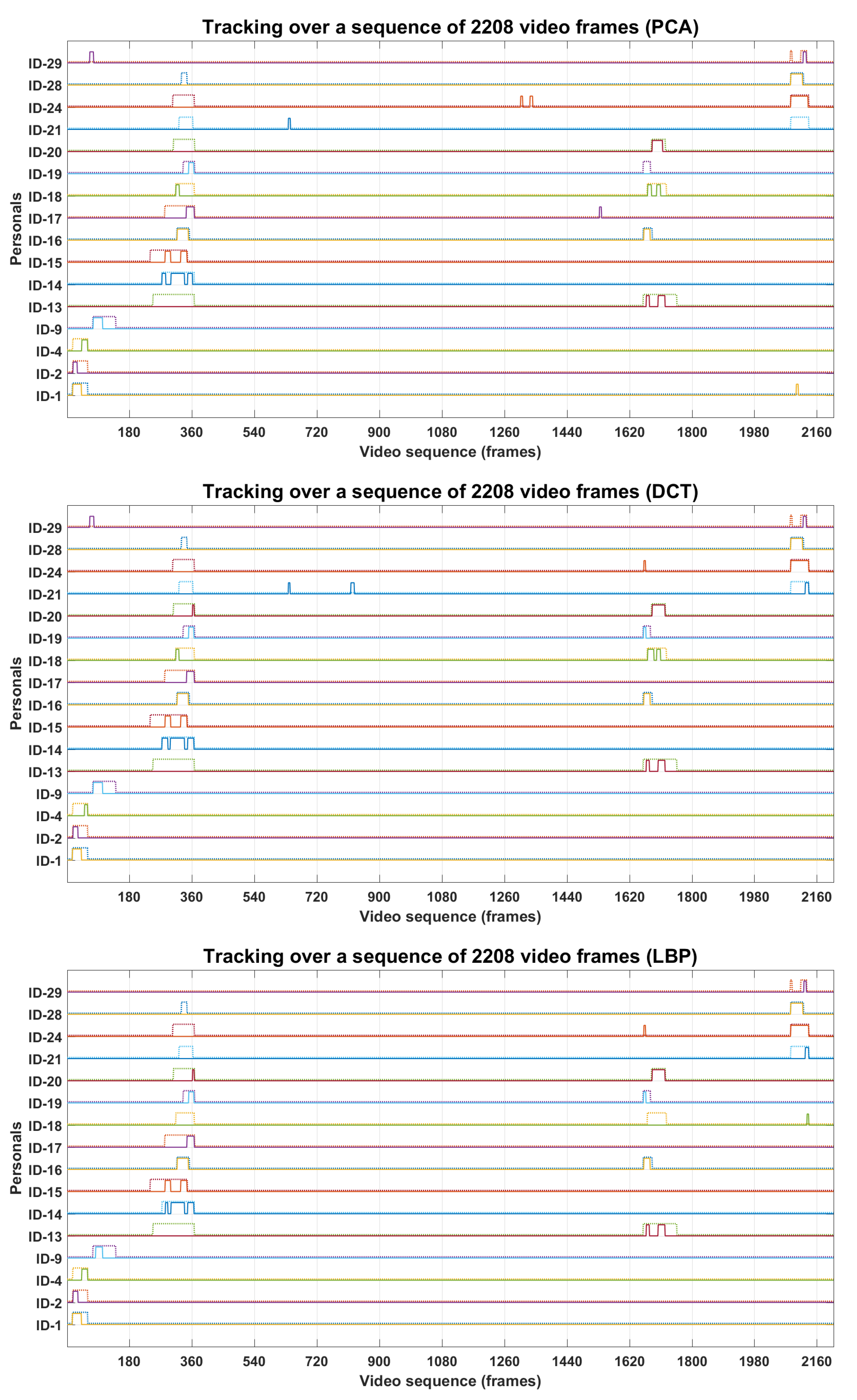
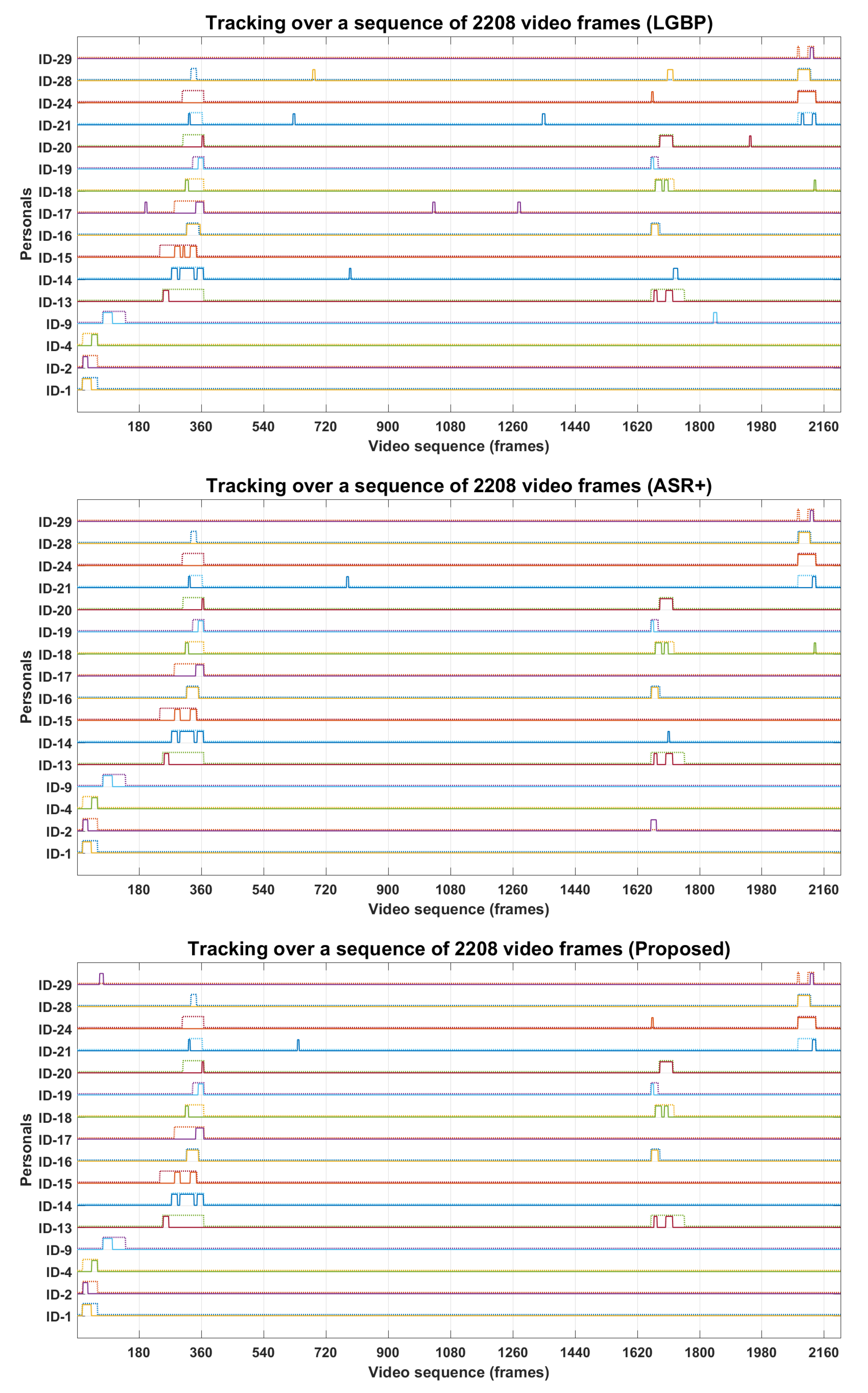
4.3. Personal Identification and Tracking
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Kumar, N.; Berg, A.C.; Belhumeur, P.N.; Nayar, S.K. Attribute and simile classifiers for face verification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision. IEEE, Kyoto, Japan, 29 September–2 October 2009; pp. 365–372. [Google Scholar]
- Pasztor, E.; Carmichael, O.T. Learning low-level vision. Int. J. Comput. Vis. 2000, 40, 25–47. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Large-scale celebfaces attributes (celeba) dataset. Retrieved August 2018, 15, 11. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Zangeneh, E.; Rahmati, M.; Mohsenzadeh, Y. Low resolution face recognition using a two-branch deep convolutional neural network architecture. Expert Syst. Appl. 2020, 139, 112854. [Google Scholar] [CrossRef]
- Li, P.; Prieto, L.; Mery, D.; Flynn, P. Face recognition in low quality images: A survey. arXiv 2018, arXiv:1805.11519. [Google Scholar]
- Jurevičius, R.; Goranin, N.; Janulevičius, J.; Nugaras, J.; Suzdalev, I.; Lapusinskij, A. Method for real time face recognition application in unmanned aerial vehicles. Aviation 2019, 23, 65–70. [Google Scholar] [CrossRef] [Green Version]
- Kramer, R.S.; Hardy, S.C.; Ritchie, K.L. Searching for faces in crowd chokepoint videos. Appl. Cogn. Psychol. 2020, 34, 343–356. [Google Scholar] [CrossRef]
- Best-Rowden, L.; Bisht, S.; Klontz, J.C.; Jain, A.K. Unconstrained face recognition: Establishing baseline human performance via crowdsourcing. In Proceedings of the IEEE International Joint Conference on Biometrics, Clearwater, FL, USA, 29 September–2 October 2014; pp. 1–8. [Google Scholar]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Xu, X.; Liu, W.Q.; Li, L. Low resolution face recognition in surveillance systems. J. Comput.Commun. 2014, 2, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Liu, D.; Huang, T. Survey of face detection on low-quality images. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 769–773. [Google Scholar]
- Phillips, P.J.; Yates, A.N.; Hu, Y.; Hahn, C.A.; Noyes, E.; Jackson, K.; Cavazos, J.G.; Jeckeln, G.; Ranjan, R.; Sankaranarayanan, S.; et al. Face recognition accuracy of forensic examiners, superrecognizers, and face recognition algorithms. Proc. Nat. Acad. Sci. USA 2018, 115, 6171–6176. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Preeja, P.; Nair, R.S. A Survey on Multiple Face Detection and Tracking in Crowds. Int. J. Innov. Eng. Technol. (IJIET) 2016, 7, 211–216. [Google Scholar]
- Mahmoud, H.A.H.; Mengash, H.A. A novel technique for automated concealed face detection in surveillance videos. Pers. Ubiquitous Comput. 2021, 25, 129–140. [Google Scholar] [CrossRef] [PubMed]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep learning vs. traditional computer vision. In Science and Information Conference; Springer: Cham, Switzerland, 2019; pp. 128–144. [Google Scholar]
- Becker, D.V.; Rheem, H. Searching for a face in the crowd: Pitfalls and unexplored possibilities. Atten. Percept. Psychophys. 2020, 82, 626–636. [Google Scholar] [CrossRef] [PubMed]
- Nadeem, A.; Rizwan, K.; Syed, T.A.; Alkhodre, A.; Mehmood, A. Spatio-temporal modeling and application for efficient online reporting and tracking of lost items during Huge Crowd Gatherings. Int. J. Comput. Digit. Syst. 2020, 9, 1155–1163. [Google Scholar] [CrossRef]
- Nadeem, A.; Rizwan, K.; Mehmood, A.; Qadeer, N.; Noor, F.; AlZahrani, A. A Smart City Application Design for Efficiently Tracking Missing Person in Large Gatherings in Madinah Using Emerging IoT Technologies. In Proceedings of the 2021 Mohammad Ali Jinnah University International Conference on Computing (MAJICC), Karachi, Pakistan, 15–17 July 2021; pp. 1–7. [Google Scholar]
- Azhar, I.; Sharif, M.; Raza, M.; Khan, M.A.; Yong, H.S. A Decision Support System for Face Sketch Synthesis Using Deep Learning and Artificial Intelligence. Sensors 2021, 21, 8178. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Javed, M.; Alhaisoni, M.; Tariq, U.; Kadry, S.; Choi, J.; Nam, Y. Human Gait Recognition Using Deep Learning and Improved Ant Colony Optimization. Comput. Mater. Cont. 2022, 70, 2113–2130. [Google Scholar] [CrossRef]
- Hussain, N.; Khan, M.A.; Kadry, S.; Tariq, U.; Mostafa, R.; Choi, J.I.; Nam, Y. Intelligent deep learning and improved whale optimization algorithm based framework for object recognition. Hum. Cent. Comput. Inf. Sci. 2021, 11, 34. [Google Scholar]
- Rajnoha, M.; Mezina, A.; Burget, R. Multi-frame labeled faces database: Towards face super-resolution from realistic video sequences. Appl. Sci. 2020, 10, 7213. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference/ System | Input/Environment Constraints | Techniques/Methodology/ Application/Goal/Dataset | ||
|---|---|---|---|---|
| Huge Crowd | Face-Detection (D)/ Recognition (R) | Low Resolution | ||
| [8] | Yes | (R) | NA |
|
| [9] | Yes | (R) | NA |
|
| [10] | Yes | (R) | NA |
|
| [13] | No | (D) | Yes |
|
| [14] | Yes | (D) | YES |
|
| [15] | Yes | (D) | No |
|
| [16] | No | (D) | No |
|
| [18] | Yes | (R) | YES |
|
| [24] | Yes | (R) | Yes |
|
| Rank | Prediction Score | Description |
|---|---|---|
| Rank 5 | 5 | Strongly recommended match to a particular registered person. |
| Rank 4 | 4 | Recommended match to a particular registered person. |
| Rank 3 | 3 | Strongly suggested match to a particular registered person. |
| Rank 2 | 2 | Suggested match to a particular registered person. |
| Rank 1 | 1 | Weakly suggested match to a particular registered person. |
| No Rank | 0 | No match suggested due to confusion (i.e., NM-1). |
| No Rank | −1, −2 | No match recommended (i.e., NM-2). |
| Rank | Are All 5 Scores ≥ 0 ? Minimum Aggregate Score | Are Any 4 Scores ≥ 0 ? Minimum Aggregate Score | Are Any 3 Scores ≥ 0 ? Minimum Aggregate Score | Are Any 2 Scores ≥ 0 ? Minimum Aggregate Score |
|---|---|---|---|---|
| Rank 5 | 21 | |||
| Rank 4 | 16 | 18 | ||
| Rank 3 | 11 | 16 | 13 | |
| Rank 2 | 6 | 11 | 11 | 8 |
| Rank 1 | 5 | 6 | 6 | 6 |
| No Rank | 4 | 5 | 5 | 5 |
| No Rank | 0–3 | 0–4 | 0–4 | 0–4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nadeem, A.; Ashraf, M.; Rizwan, K.; Qadeer, N.; AlZahrani, A.; Mehmood, A.; Abbasi, Q.H. A Novel Integration of Face-Recognition Algorithms with a Soft Voting Scheme for Efficiently Tracking Missing Person in Challenging Large-Gathering Scenarios. Sensors 2022, 22, 1153. https://doi.org/10.3390/s22031153
Nadeem A, Ashraf M, Rizwan K, Qadeer N, AlZahrani A, Mehmood A, Abbasi QH. A Novel Integration of Face-Recognition Algorithms with a Soft Voting Scheme for Efficiently Tracking Missing Person in Challenging Large-Gathering Scenarios. Sensors. 2022; 22(3):1153. https://doi.org/10.3390/s22031153
Chicago/Turabian StyleNadeem, Adnan, Muhammad Ashraf, Kashif Rizwan, Nauman Qadeer, Ali AlZahrani, Amir Mehmood, and Qammer H. Abbasi. 2022. "A Novel Integration of Face-Recognition Algorithms with a Soft Voting Scheme for Efficiently Tracking Missing Person in Challenging Large-Gathering Scenarios" Sensors 22, no. 3: 1153. https://doi.org/10.3390/s22031153