
Multi-Sensor Fault Diagnosis Based on Time Series in an Intelligent Mechanical System

Abstract
:1. Introduction
- The previous idea of designing fault diagnosis algorithms based on special equipment characteristics is abandoned. Considering that the completion of tasks in industrial automation systems is usually time-based, the data from sensors have time series characteristics. Time series features can reflect the changes in industrial control processes, so we propose a fault diagnosis algorithm based on the time series features of intelligent mechanical system data. The algorithm is a fault diagnosis method applicable to multi-component complex mechanical systems, not only to one component;
- The fault diagnosis algorithm is divided into fault identification and root cause analysis. This paper adopts a fault identification algorithm suitable for multi-dimensional long-time series prediction to solve the prediction difficulties caused by many sampling data sources and high sampling accuracy in industrial control systems;
- After a certain fault is determined, a method for analyzing the fault cause of the multi-equipment system is designed to locate the fault location and help system maintenance personnel to eliminate the fault.
2. Related Work
2.1. Domain-Oriented Multi-Sensor Fault Diagnosis Methods
2.1.1. Fault Diagnosis Based on Signal Analysis
2.1.2. Fault Pattern Recognition and Diagnosis Methods
2.2. Non-Domain Multi-Fault Diagnosis Methods
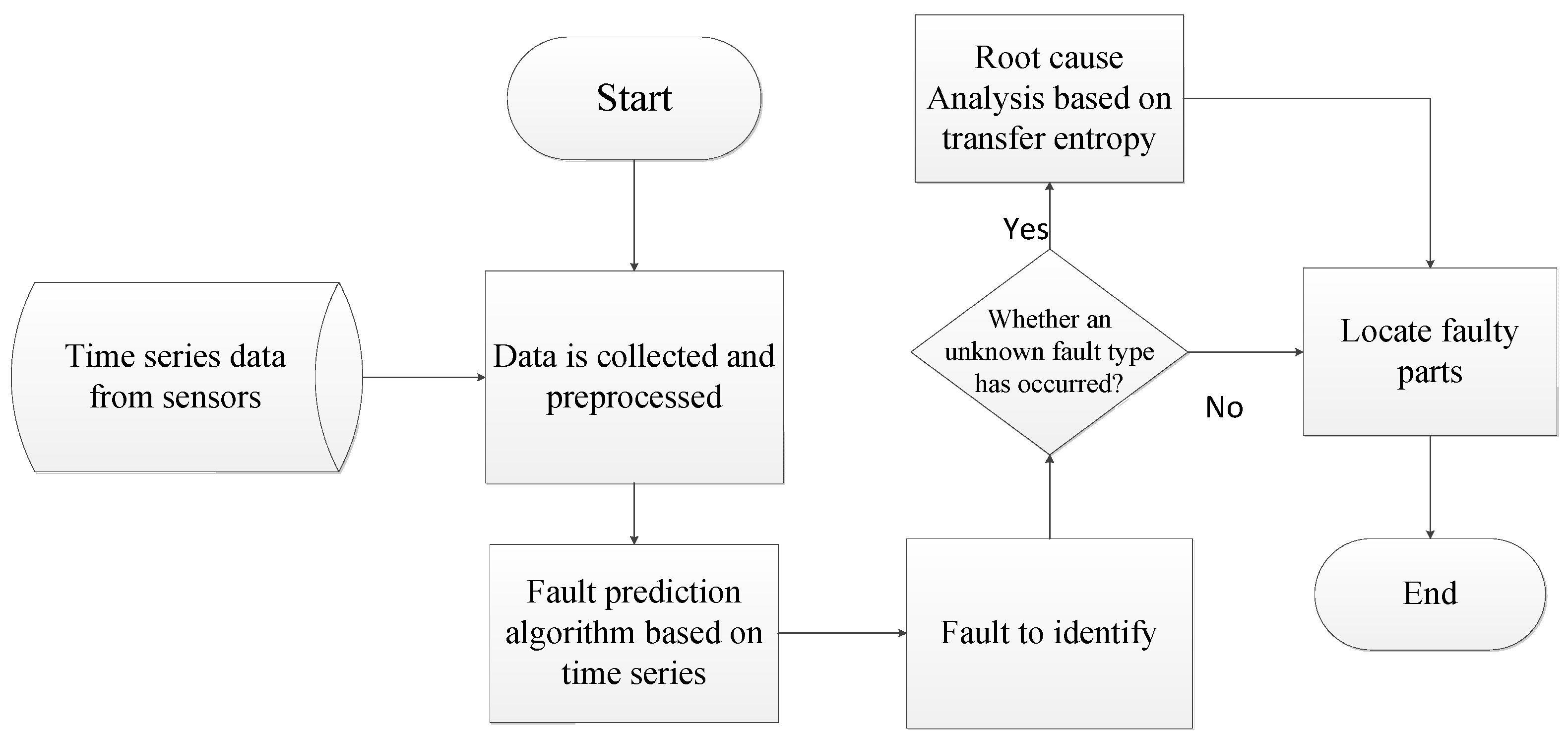
3. Core Idea
3.1. Problem Description
- Q1:
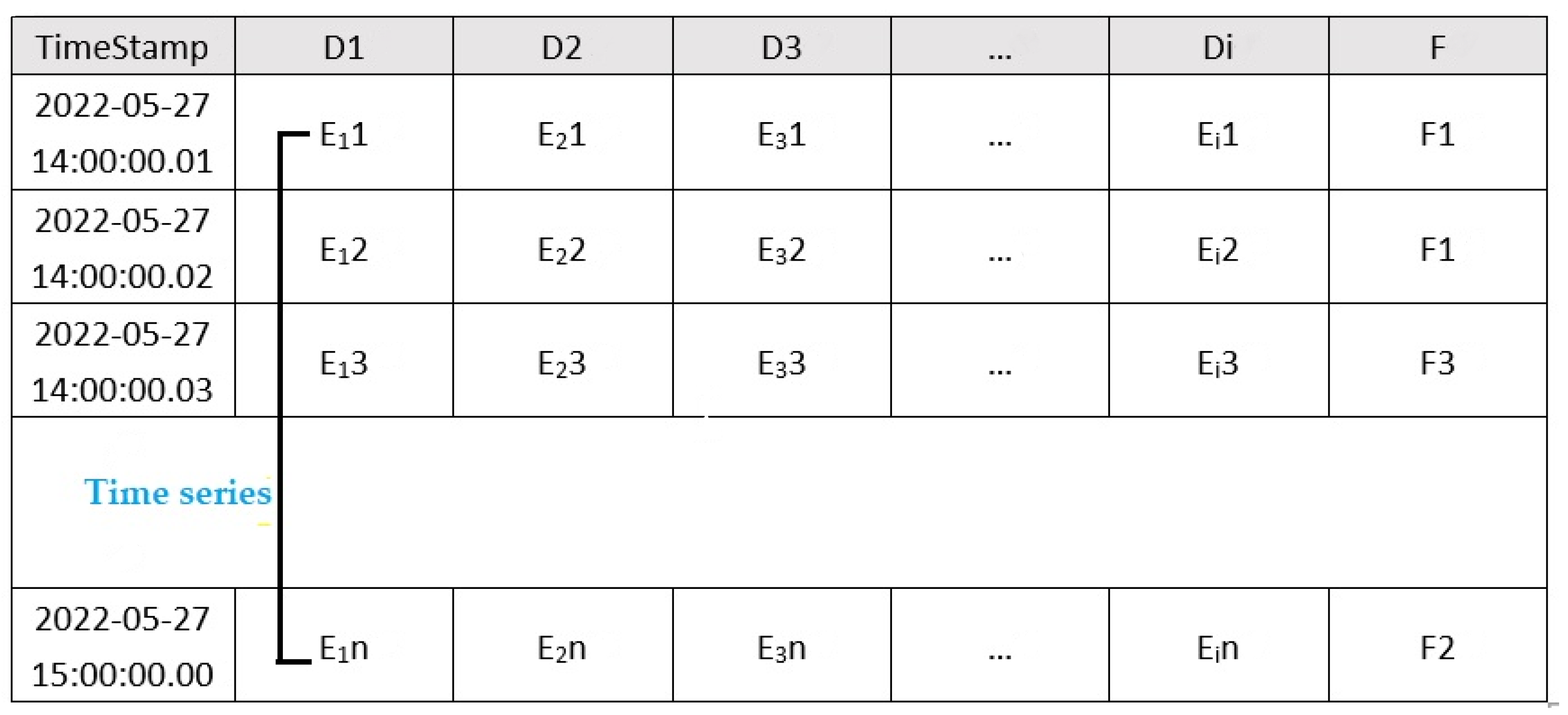
- In the process of industrial control, the sampling frequency of the sensor is usually in the microsecond level, so the time series formed by the sampling data of an information source is usually relatively long. Therefore, how to identify the faults in a long time series is the first problem to be solved;
- Q2:
- Industrial automation systems are usually composed of multiple components, and there are various connections between the parts, so there is also a relationship between the sensor data. For example, if two components are running in sequence, once the first running component fails, the data for the latter running component will inevitably have problems. Therefore, when analyzing the cause of the failure, we must consider how to explore the relationship between the components to find the actual cause.
3.2. Overview of Our Model
4. Fault Diagnosis Algorithm Based on Multi-Dimensional Time Series
4.1. Multi-Dimensional Time Series Fault Identification Based on the Autoformer Algorithm
4.1.1. Sequence Decomposition Module
4.1.2. Encoder and Decoder
- The stacked autocorrelation mechanism of the seasonal components and the periodic nature of the sequences are used to aggregate subsequences with similar processes in different periods.
- An accumulation operation on the trend-cyclical component is used to gradually extract trend information from the predicted latent variables (the last one). Assuming we have M decoding layers, the internal details of the i-th decoding layer are as follows:
4.1.3. Autocorrelation Mechanism
4.1.4. Fault Identification Module
4.2. Failure Root Cause Analysis
- For each failure, the set of elements should be able to explain the error as much as possible;
- For each failure, the set of elements should conform to Occam’s razor and should be as concise as possible in form;
- Of all the dimensions, the most unexpected dimension and the element where the true and expected values differ most should be found.
| Algorithm 1: Calculate frequent item sets algorithm. |
| Input: A transaction database D A minimum support threshold S An optional parameter N indicates the maximum length an itemset could reach; Output: frequent item sets ;
|
5. Experimental Results and Analysis
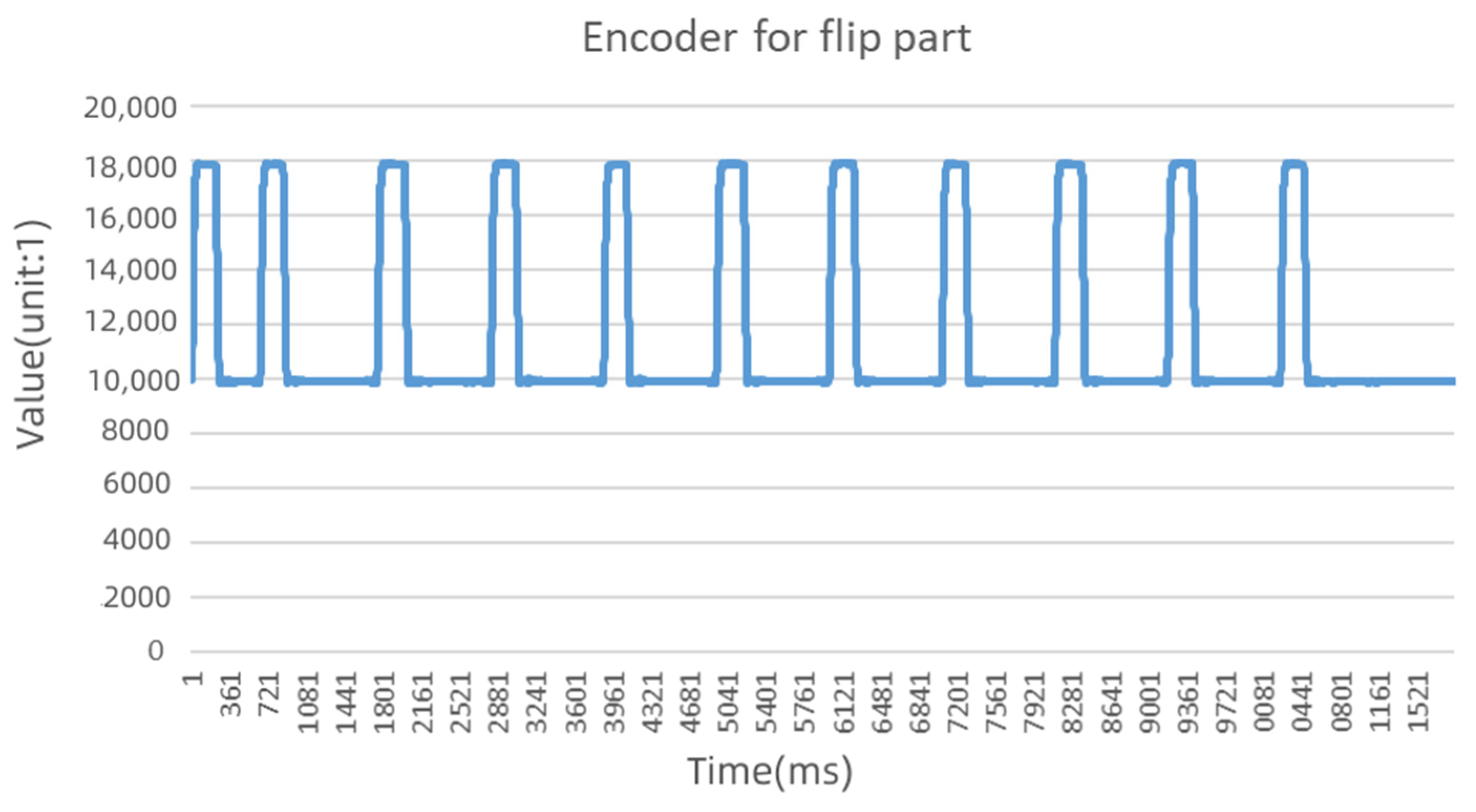
5.1. Data Set
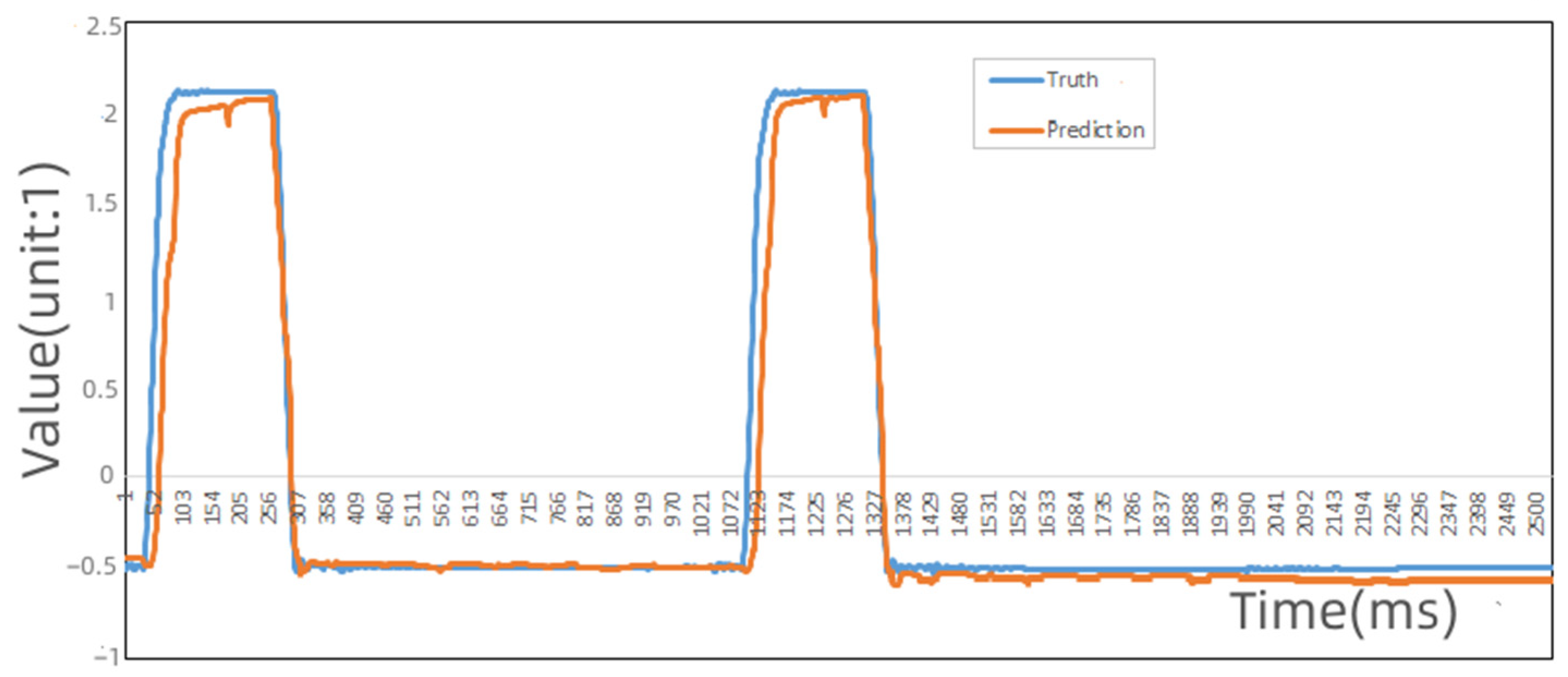
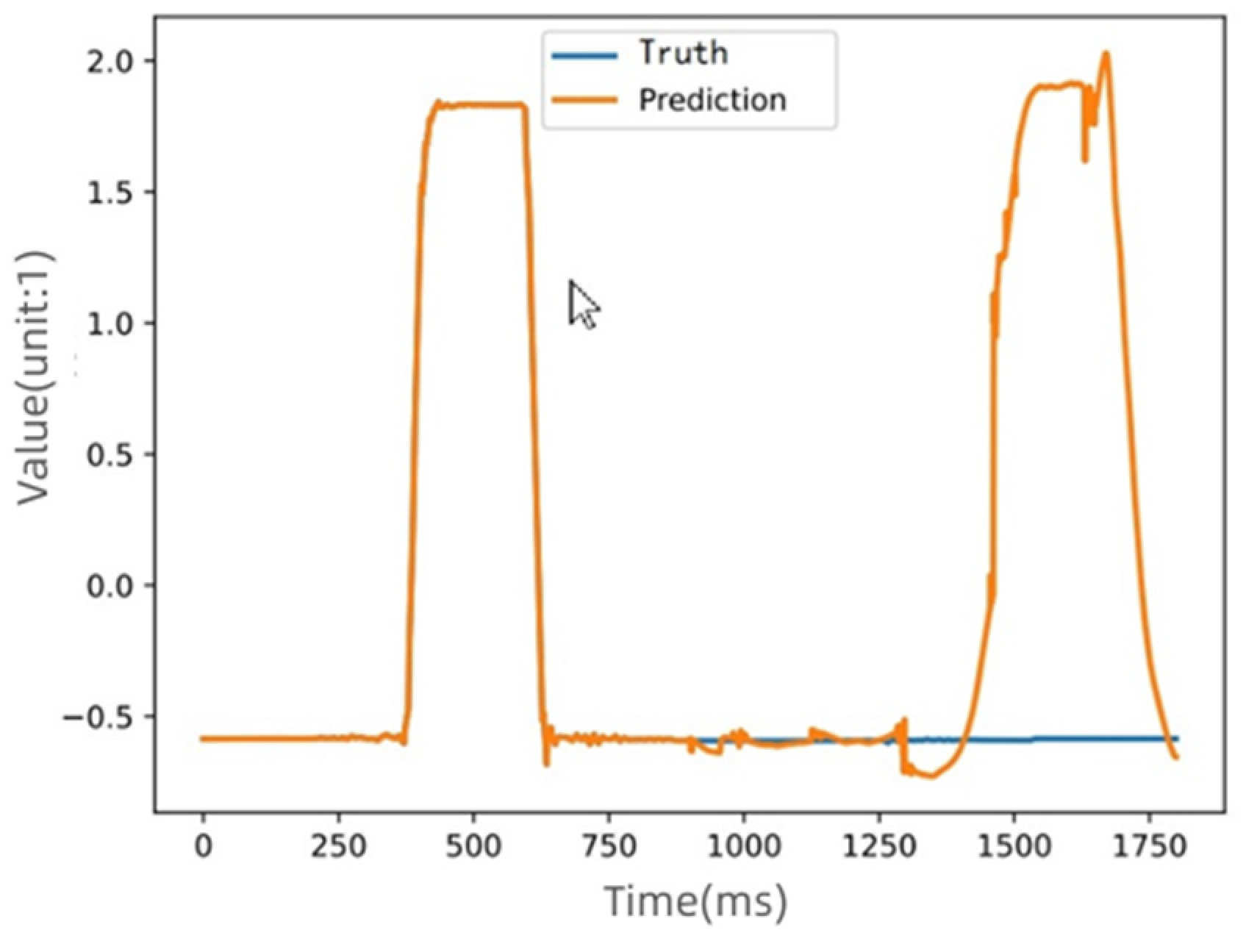
5.2. Experimental Results of the Multi-Dimensional Time Series Fault Identification
5.3. Experimental Results of the Multi-Dimensional Sequence Root Cause Determination
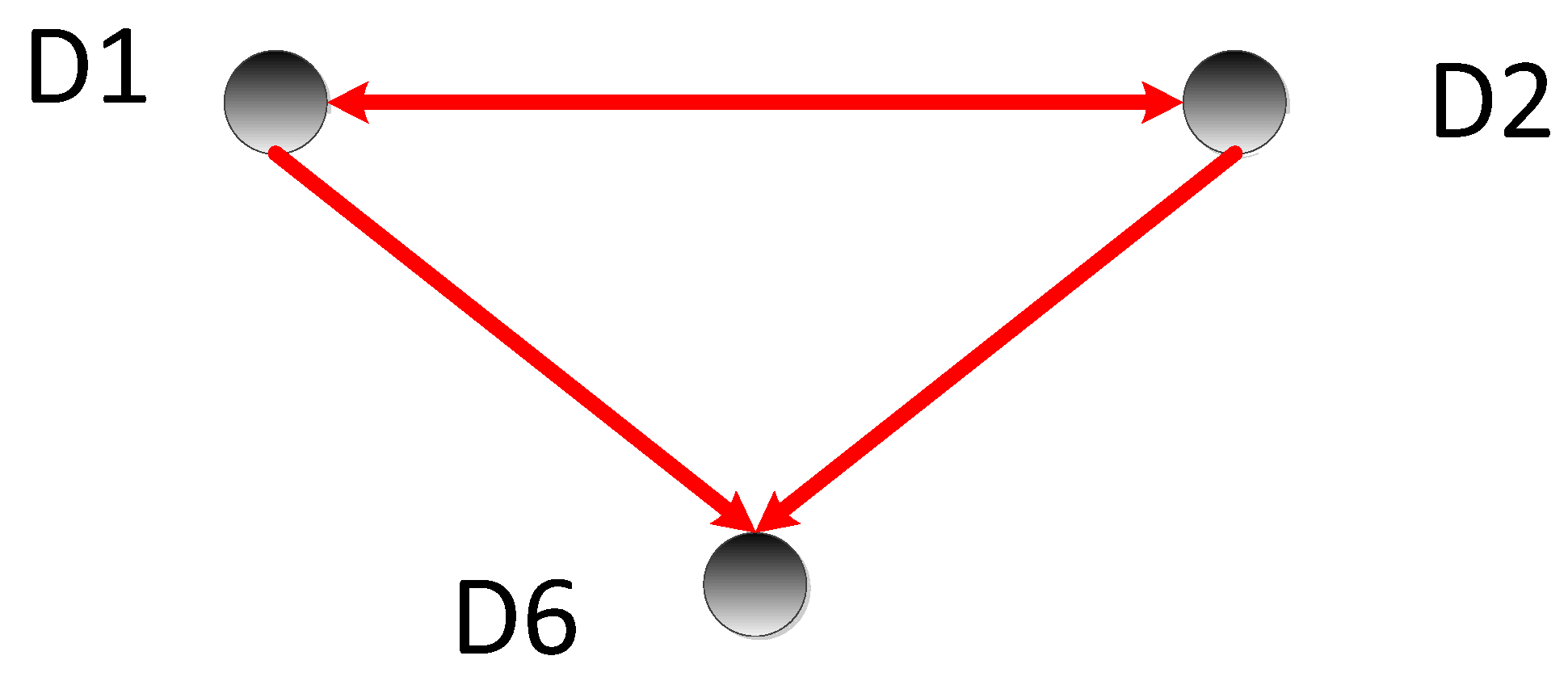
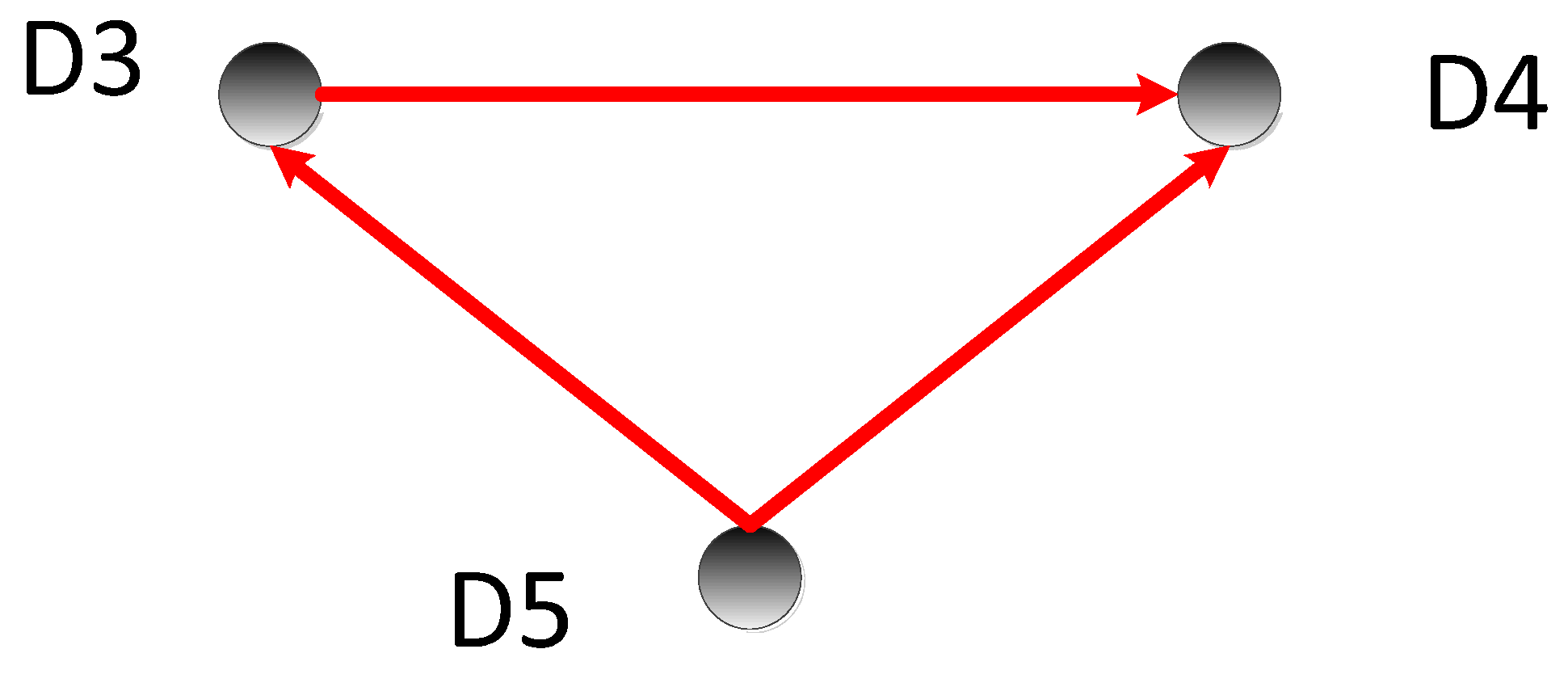
5.3.1. Calculate the Transfer Entropy Matrix T
5.3.2. Fault Location and Cause Analysis
6. Conclusions
- In order to overcome the fact that the integration of different fault diagnosis algorithms would bring suffering to the system performance due to the variety of each component, this article studied fault diagnosis algorithms that could be generalized for different components. In this article, the time series behavior of components was studied, and the time series-based fault diagnosis algorithm was used to replace the diagnosis algorithm based on the physical characteristics of components. In this paper, we adopted a multidimensional time series fault identification algorithm based on the Autoformer algorithm, which can better solve the prediction problem of multidimensional long-term series.
- Because multiple components often affect each other, they can bring uncertainty to the analysis of the cause of failure. To address this problem, our second research direction was to analyze the component relationships for a better root cause analysis of faults. In this paper, we designed a transfer entropy-based root cause analysis method, which can identify the causal relationships between components and thus more accurately uncover the causes of failures.
- The current fault prediction algorithm can be further improved in the prediction of long time series and in the optimization of the root cause analysis algorithm based on transfer entropy, such as through the pruning strategy, which is also the direction of future research.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Chen, J.; Zhou, Y.; Ni, G. Early fault diagnosis of rolling bearing based on noise-assisted signal feature enhancement and stochastic resonance for intelligent manufacturing. Int. J. Adv. Manuf. Technol. 2020, 107, 1017–1023. [Google Scholar] [CrossRef]
- Li, C.; Sanchez, R.-V.; Zurita, G.; Cerrada, M.; Cabrera, D.; Vásquez, R.E. Multimodal deep support vector classification with homologous features and its application to gearbox fault diagnosis. Neurocomputing 2015, 168, 119–127. [Google Scholar] [CrossRef]
- Muhammad, S. A Hybrid Feature Model and Deep-Learning-Based Bearing Fault Diagnosis. J. Sens. 2017, 17, 2876. [Google Scholar]
- Ding, X.; He, Q. Energy-Fluctuated Multiscale Feature Learning With Deep ConvNet for Intelligent Spindle Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2017, 66, 1926–1935. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, Z. Diagnosis of the three-phase induction motor using thermal imaging. Infrared Phys. Technol. 2017, 81, 7–16. [Google Scholar] [CrossRef]
- Shao, H.; Hongkai, J.; Xingqiu, L.; Shuaipeng, W. Intelligent Fault Diagnosis of Rolling Bearing Using Deep Wavelet Auto-encoder with Extreme Learning Machine. Knowl. -Based Syst. 2017, 140, 24. [Google Scholar]
- Paiva, P.R.R.; de Freitas, B.I.; Carvalho, L.K.; Basilio, J.C. Online fault diagnosis for smart machines embedded in Industry 4.0 manufacturing systems: A labeled Petri net-based approach. IFAC J. Syst. Control 2021, 16, 100146. [Google Scholar] [CrossRef]
- Soualhi, M.; Nguyen, K.T.P.; Medjaher, K. Pattern recognition method of fault diagnostics based on a new health indicator for smart manufacturing. Mech. Syst. Signal Process. 2020, 142, 106680. [Google Scholar] [CrossRef]
- Zhang, F.; Yan, J.; Fu, P.; Wang, J.; Gao, R.X. Ensemble sparse supervised model for bearing fault diagnosis in smart manufacturing. Robot. Comput. -Integr. Manuf. 2020, 65, 101920. [Google Scholar] [CrossRef]
- Wang, J.; Ye, L.; Gao, R.X.; Li, C.; Zhang, L. Digital Twin for rotating machinery fault diagnosis in smart manufacturing. Int. J. Prod. Res. 2019, 57, 3920–3934. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, W.; Tang, Z.; Chen, Y. Multi-Sensor Data Fusion Using a Relevance Vector Machine Based on an Ant Colony for Gearbox Fault Detection. Sensors 2015, 15, 21857–21875. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Chen, X.H.; Shan, X.L.; Liu, H.G.; Zhou, C.F. A new method of gear fault diagnosis in strong noise based on multi-sensor information fusion. J. Vib. Control 2014, 22, 1077546314542187. [Google Scholar] [CrossRef]
- Seshadrinath, J.; Singh, B.; Panigrahi, B.K. Investigation of Vibration Signatures for Multiple Fault Diagnosis in Variable Frequency Drives Using Complex Wavelets. IEEE Trans. Power Electron. 2013, 29, 936–945. [Google Scholar] [CrossRef]
- Cheng, M.; Zhang, J.; Hang, J. Fault diagnosis of wind turbine based on multi-sensors information fusion technology. IET Renew. Power Gener. 2014, 8, 289–298. [Google Scholar]
- Zhu, D.; Sun, B. Information fusion fault diagnosis method for unmanned underwater vehicle thrusters. IET Electr. Syst. Transp. 2013, 3, 102–111. [Google Scholar] [CrossRef]
- Yuan, X.; Peng, J.; Yang, D.; Hao, R.S. Research on Automatic Monitoring and Fault Diagnosis System of Unmanned Cabin. EPH-Int. J. Sci. Eng. 2017, 3, 1–7. [Google Scholar] [CrossRef]
- Yu, L.; Sun, Y.; Li, K.j.; Xu, M. An improved genetic algorithm based on fuzzy inference theory and its application in distribution network fault location. In Proceedings of the 2016 IEEE 11th Conference on Industrial Electronics and Applications (ICIEA), Hefei, China, 5–7 June 2016; pp. 1411–1415. [Google Scholar]
- Guo, X.-G.; Tian, M.-E.; Li, Q.; Ahn, C.K.; Yang, Y.-H. Multiple-fault diagnosis for spacecraft attitude control systems using RBFNN-based observers. Aerosp. Sci. Technol. 2020, 106, 106195. [Google Scholar] [CrossRef]
- Martínez-Morales, J.D.; Palacios-Hernández, E.R.; Campos-Delgado, D.U. Multiple-fault diagnosis in induction motors through support vector machine classification at variable operating conditions. Electr. Eng. 2018, 100, 59–73. [Google Scholar] [CrossRef]
- Ruan, S.; Yu, F.; Meirina, C.; Pattipati, K.R.; Patterson-Hine, A. Dynamic multiple fault diagnosis with imperfect tests. In Proceedings of the Proceedings AUTOTESTCON 2004, San Antonio, TX, USA, 20–23 September 2004; pp. 395–401. [Google Scholar]
- Le, T.; Hadjicostis, C.N. Max-Product Algorithms for the Generalized Multiple-Fault Diagnosis Problem. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2007, 37, 1607–1621. [Google Scholar]
- Kodali, A.; Singh, S.; Pattipati, K. Dynamic Set-Covering for Real-Time Multiple Fault Diagnosis With Delayed Test Outcomes. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 547–562. [Google Scholar] [CrossRef]
- Arpaia, P.; Maisto, D.; Manna, C. A Quantum-inspired Evolutionary Algorithm with a competitive variation operator for Multiple-Fault Diagnosis. Appl. Soft Comput. 2011, 11, 4655–4666. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, X.; Du, Z.; Yang, B. Sparsity-aware tight frame learning with adaptive subspace recognition for multiple fault diagnosis. Mech. Syst. Signal Process. 2017, 94, 499–524. [Google Scholar] [CrossRef]
- Jafari-Mamaghani, M.; Tyrcha, J. Transfer Entropy Expressions for a Class of Non-Gaussian Distributions. Entropy 2014, 16, 1743–1755. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Timestamp | D1 | D2 | D3 | D4 | D5 | D6 | F |
|---|---|---|---|---|---|---|---|
| 1 | 9941 | 1,320,661 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 2 | 10,002 | 1,320,722 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 3 | 10,088 | 1,320,808 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 4 | 10,209 | 1,320,929 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 5 | 10,341 | 1,321,061 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 6 | 10,501 | 1,321,221 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 7 | 10,687 | 1,321,407 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 8 | 10,900 | 1,321,620 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 9 | 11,124 | 1,321,844 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 10 | 11,381 | 1,322,101 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 11 | 11,657 | 1,322,377 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 12 | 11,945 | 1,322,665 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 13 | 12,247 | 1,322,967 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 14 | 12,541 | 1,323,261 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 15 | 12,828 | 1,323,548 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 16 | 13,107 | 1,323,827 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 17 | 13,377 | 1,324,097 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| 18 | 13,659 | 1,324,379 | 159,902,125 | 168,834,489 | 437,400 | 1001 | 0 |
| …… | |||||||
| 11,440 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,441 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,442 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,443 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,444 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,445 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,446 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,447 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,448 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,449 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,450 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| 11,451 | 9906 | 1,320,626 | 158,435,308 | 166,383,448 | 437,364 | 1001 | 402 |
| …… | |||||||
| Prediction | Truth | δ |
|---|---|---|
| −0.56658614 | −0.59247607 | 0.02588993 |
| −0.5630873 | −0.59267557 | 0.02958827 |
| −0.901269 | −0.5918989 | −0.3093701 |
| −0.8979537 | −0.59138376 | −0.30656994 |
| −0.901961 | −0.5911302 | −0.3108308 |
| −0.9009461 | −0.5908066 | −0.3101395 |
| −0.90133065 | −0.5907445 | −0.31058615 |
| −0.90918547 | −0.59061235 | −0.31857312 |
| −0.9073556 | −0.5904101 | −0.3169455 |
| −0.89864874 | −0.59022665 | −0.30842209 |
| −0.8890775 | −0.59076995 | −0.29830755 |
| −0.8896758 | −0.5911186 | −0.2985572 |
| −0.8773504 | −0.5912724 | −0.286078 |
| …… | ||
| 0.017941706 | −0.5902468 | 0.608188506 |
| 0.025903054 | −0.5902228 | 0.616125854 |
| 0.033776082 | −0.5901876 | 0.623963682 |
| 0.039482415 | −0.5901555 | 0.629637915 |
| 0.044889383 | −0.59027636 | 0.635165743 |
| 0.04916533 | −0.59035623 | 0.63952156 |
| 0.87285906 | −0.5903951 | 1.46325416 |
| 0.44322592 | −0.590445 | 1.03367092 |
| 0.50573945 | −0.5904538 | 1.09619325 |
| 0.73909134 | −0.59047365 | 1.32956499 |
| 0.05072336 | −0.59050447 | 0.64122783 |
| 0.5027535 | −0.59053236 | 1.09328586 |
| …… | ||
| Sensor | D1 | D2 | D3 | D4 | D5 | D6 |
|---|---|---|---|---|---|---|
| S | 1.236 | 0.73 | 0.012 | 0.012 | 0.006 | 0.898 |
| Frequent Item Sets | Number of Occurrences |
|---|---|
| D6 | 866 |
| D1 | 846 |
| D2 | 844 |
| D1, D2 | 841 |
| D1, D6 | 813 |
| D2, D6 | 811 |
| D1, D2, D6 | 808 |
| Frequent Item Sets | Number of Occurrences |
|---|---|
| D3 | 1357 |
| D4 | 1357 |
| D5 | 1357 |
| D3, D4 | 1357 |
| D3, D5 | 1357 |
| D4, D5 | 1357 |
| D3, D4, D5 | 1357 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Li, Q.; Qian, L.; Wang, M. Multi-Sensor Fault Diagnosis Based on Time Series in an Intelligent Mechanical System. Sensors 2022, 22, 9973. https://doi.org/10.3390/s22249973
Xu Z, Li Q, Qian L, Wang M. Multi-Sensor Fault Diagnosis Based on Time Series in an Intelligent Mechanical System. Sensors. 2022; 22(24):9973. https://doi.org/10.3390/s22249973
Chicago/Turabian StyleXu, Zhuoran, Qianmu Li, Linfang Qian, and Manyi Wang. 2022. "Multi-Sensor Fault Diagnosis Based on Time Series in an Intelligent Mechanical System" Sensors 22, no. 24: 9973. https://doi.org/10.3390/s22249973