

Multiscale Cascaded Attention Network for Saliency Detection Based on ResNet

Abstract
:1. Introduction
- (1)
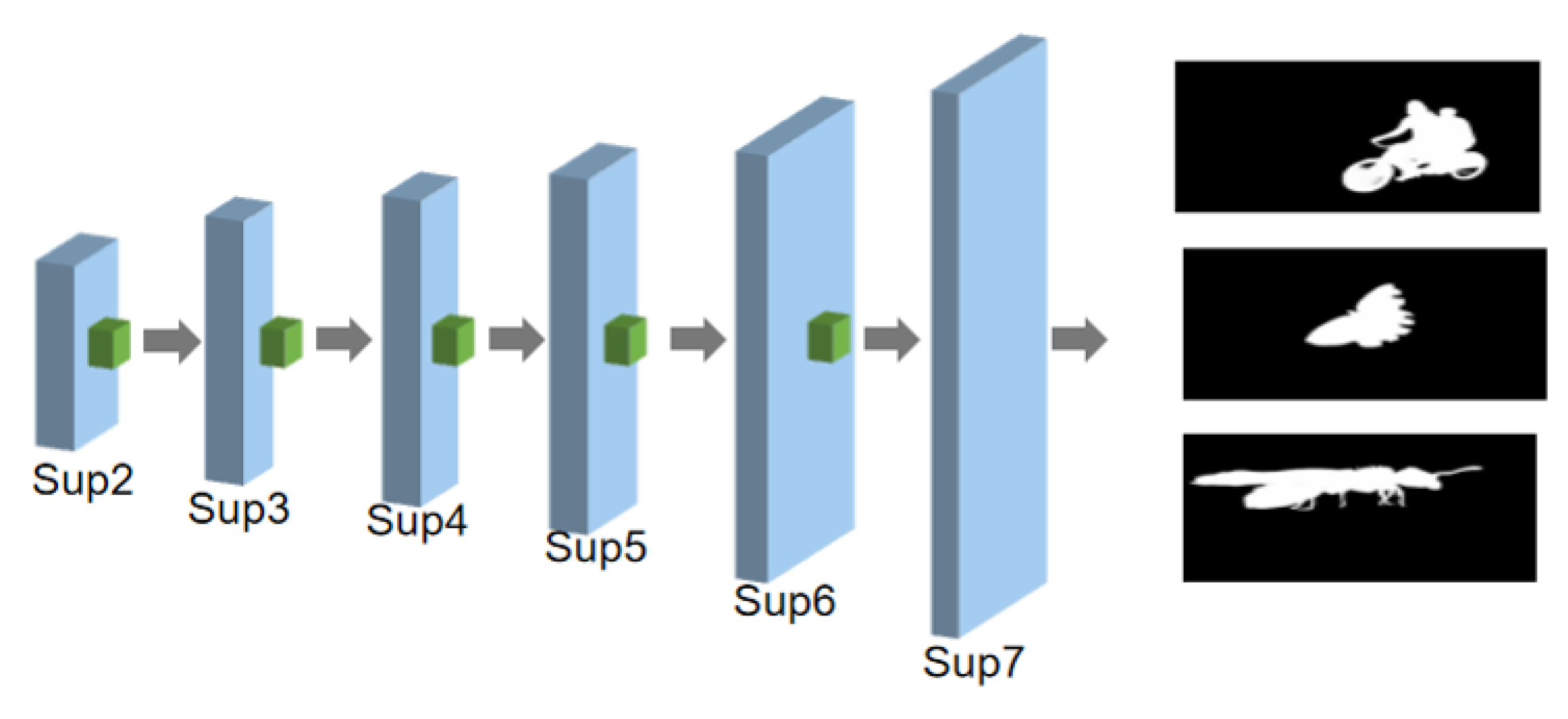
- We employ a multiscale cascade block and a lightweight channel attention module between the typical encoding–decoding networks for optimizing the performance of image saliency detection based on ResNet34.
- (2)
- A multiscale cascaded attention model is devised to rationally use the multiscale extraction module for high-level semantic features of the image, while the attention module is used for the joint refinement of low- and high-level semantic features to enhance the precision of saliency detection.
- (3)
- To solve the problem of blurred edges that has been neglected in many existing methods, we applied the edge refinement module to the output layer image for clear edge refinement.
2. Related Work
2.1. Traditional Saliency Detection Methods
2.2. Deep-Learning-Based Saliency-Detection Methods
3. Proposed Method
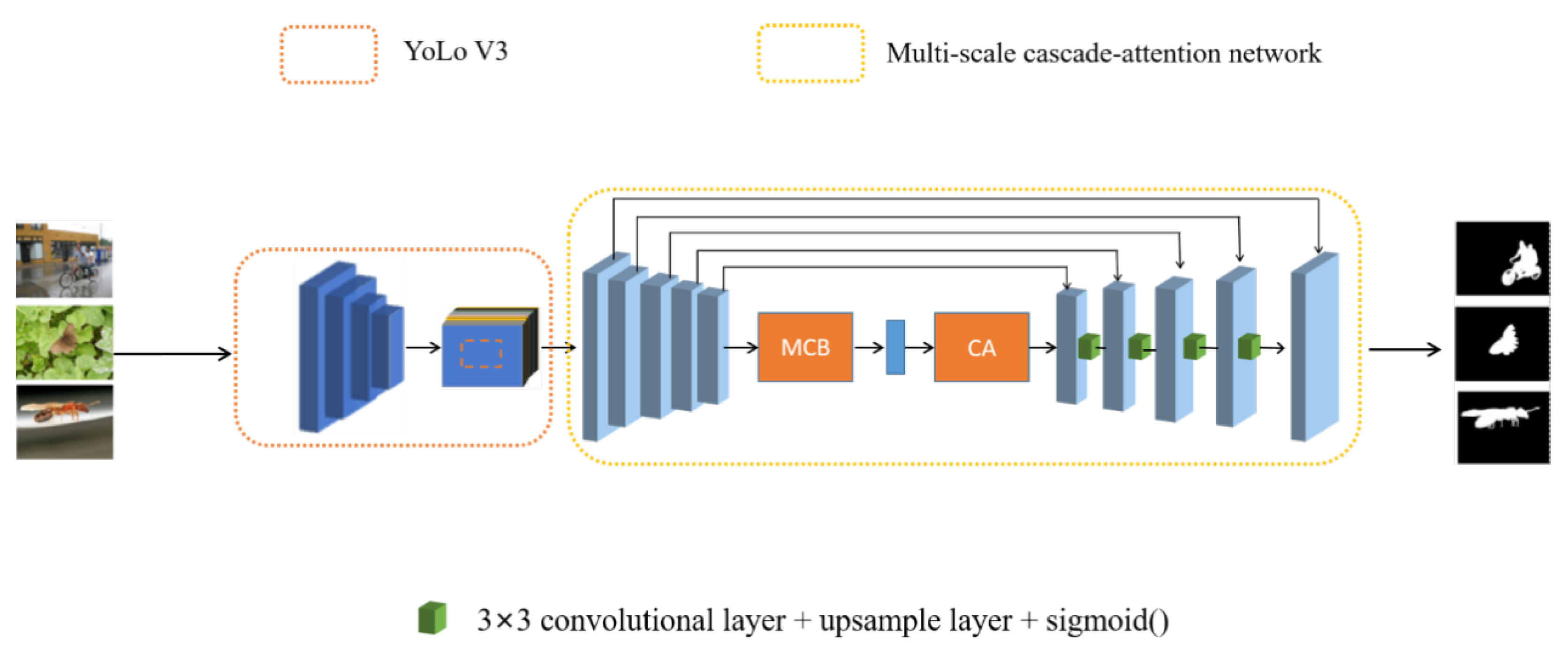
3.1. Network Architecture
3.1.1. Object Locking and Extraction from Images
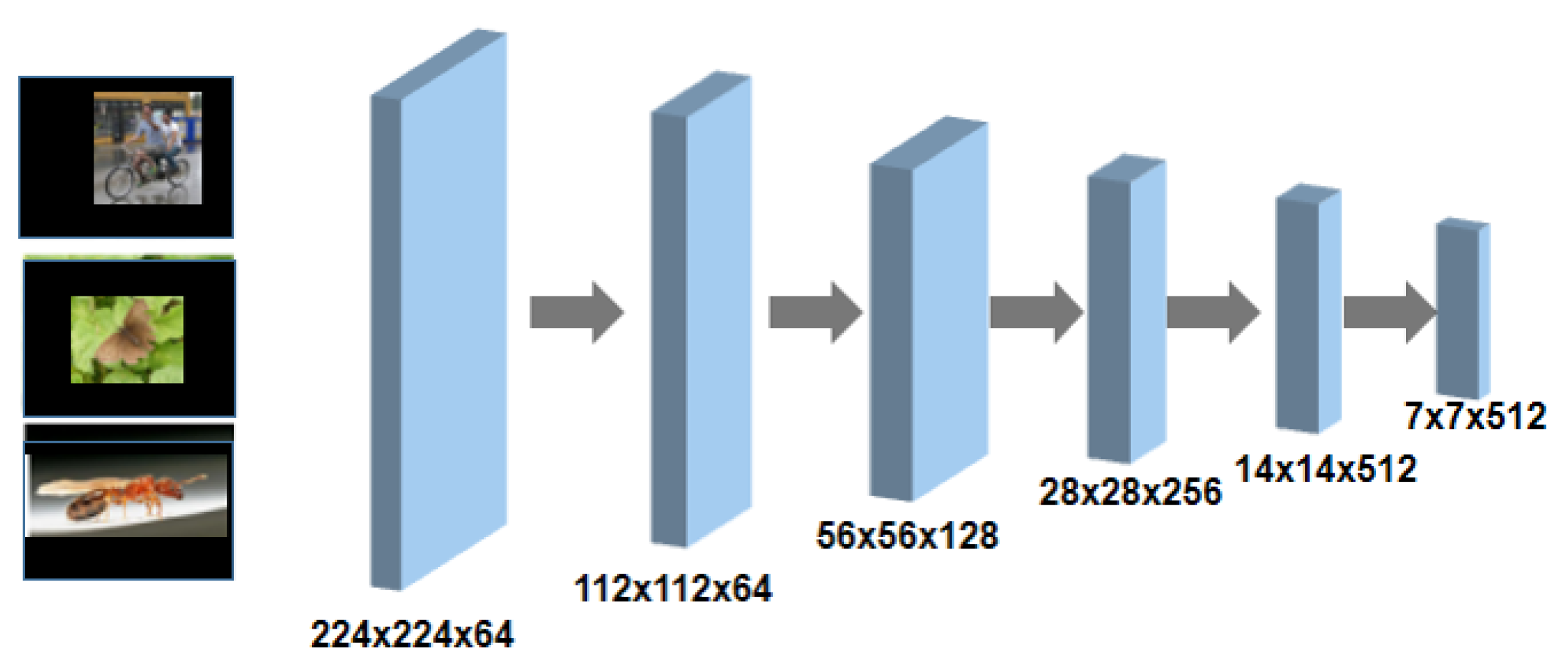
3.1.2. Feature Encoder Module
3.1.3. Contextual Feature Extraction Module
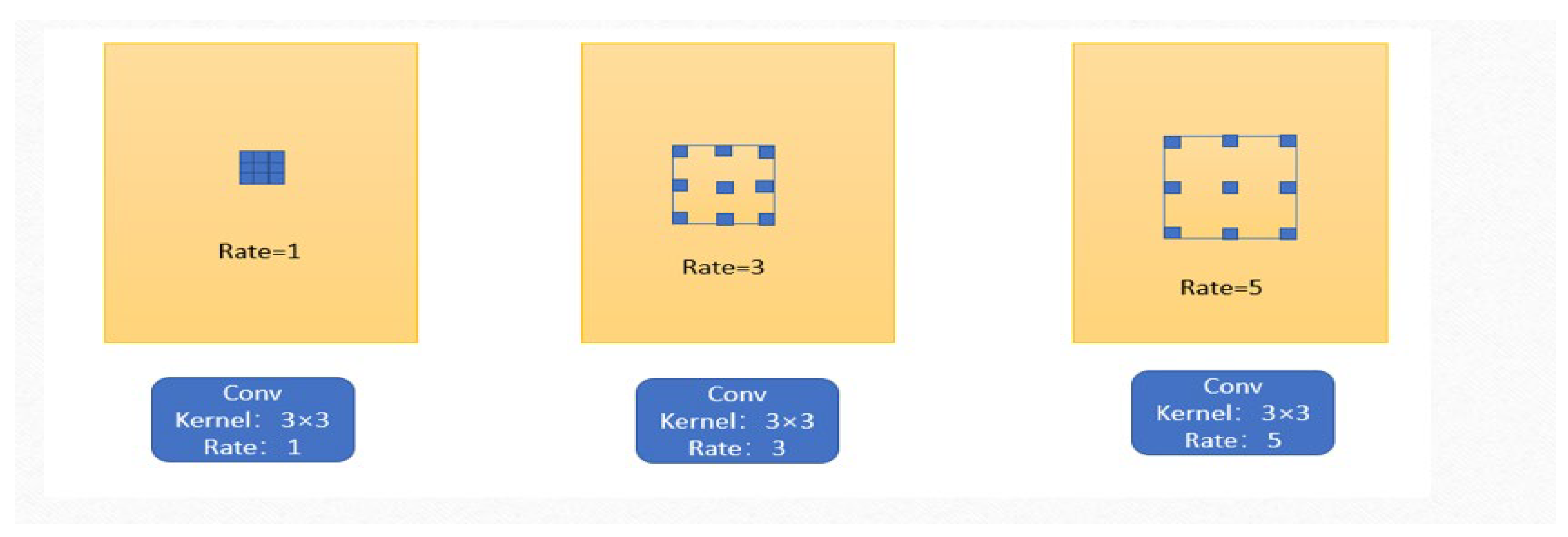
- (1)
- Dilated Convolution
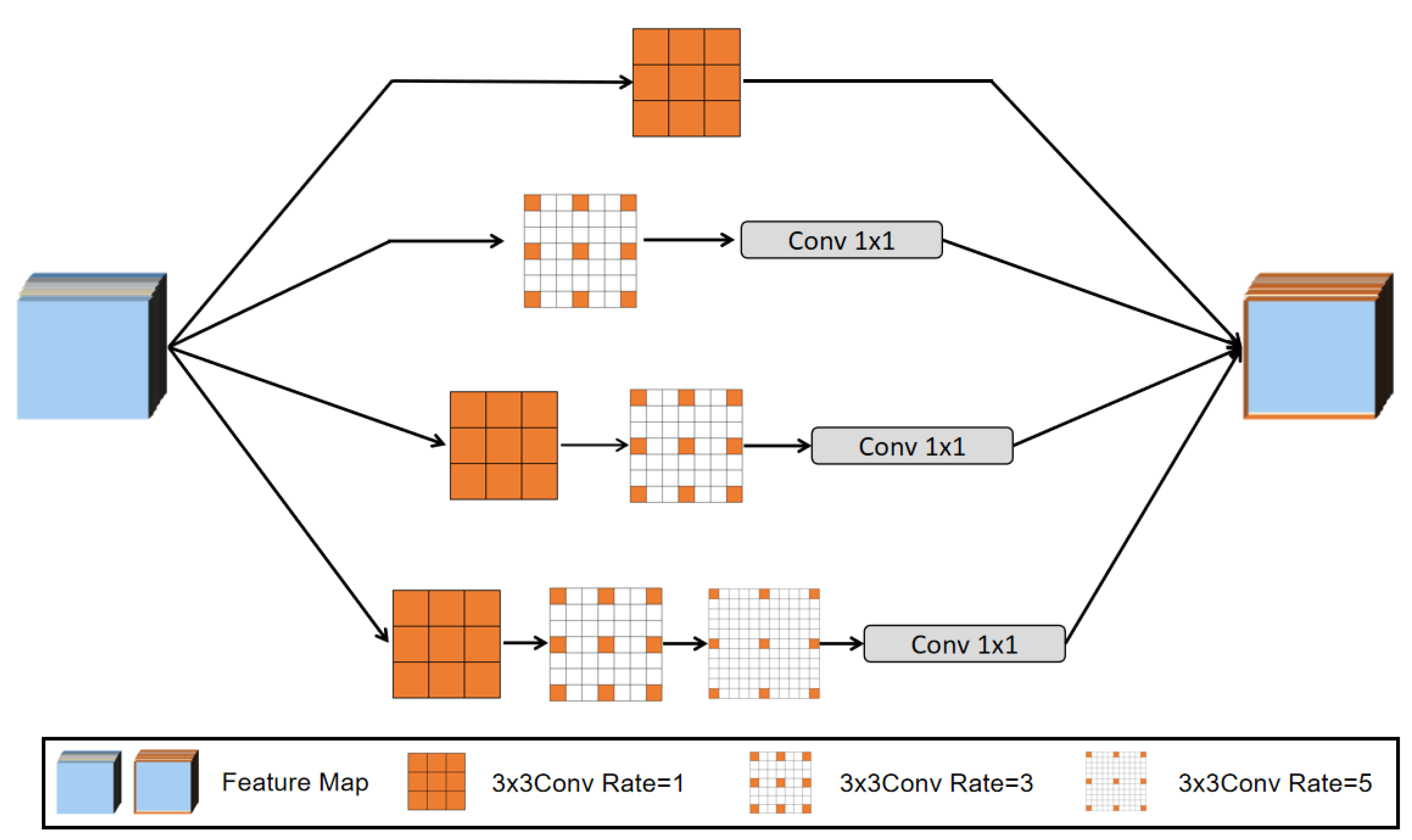
- (2)
- Multiscale Cascade Block (MCB)
- (3)
- Channel Attention (CA) Module
3.1.4. Feature Decoder Module
3.2. Loss Function
4. Experiments
4.1. Implementation Details
4.2. Qualitative Analysis
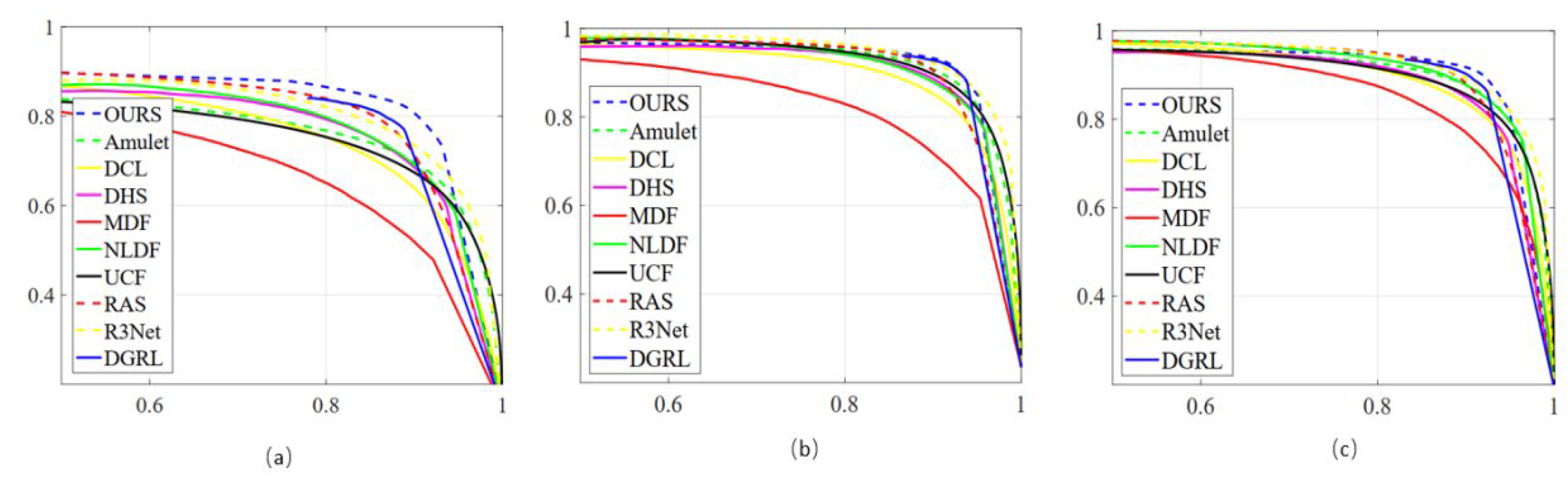
4.3. Quantitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jian, M.; Wang, J.; Yu, H.; Wang, G.; Meng, X.; Yang, L.; Dong, J.; Yin, Y. Visual saliency detection by integrating spatial position prior of object with background cues. Expert Syst. Appl. 2021, 168, 114219. [Google Scholar] [CrossRef]
- Jian, M.W.; Wang, J.; Dong, J.Y.; Cui, C.R.; Nie, X.S.; Yin, Y.L. Saliency detection using multiple low-level priors and a prop-agation mechanism. Multimed. Tools Appl. 2020, 79, 33465–33482. [Google Scholar] [CrossRef]
- Lu, X.; Jian, M.; Wang, X.; Yu, H.; Dong, J.; Lam, K.-M. Visual saliency detection via combining center prior and U-Net. Multimedia Syst. 2022, 28, 1689–1698. [Google Scholar] [CrossRef]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Le Meur, O.; Le Callet, P.; Barba, D.; Thoreau, D. A coherent computational approach to model bottom-up visual attention. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 802–817. [Google Scholar] [CrossRef] [Green Version]
- Mathe, S.; Sminchisescu, C. Dynamic Eye Movement Datasets and Learnt Saliency Models for Visual Action Recognition. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 842–856. [Google Scholar] [CrossRef]
- Mathe, S.; Sminchisescu, C. Action from still image dataset and inverse optimal control to learn task specific visual scanpaths. Adv. Neural Inf. Process. Syst. 2013, 26, 1923–1931. [Google Scholar]
- Mathe, S.; Sminchisescu, C. Actions in the Eye: Dynamic Gaze Datasets and Learnt Saliency Models for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1408–1424. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Tong, M.H.; Marks, T.K.; Shan, H.; Cottrell, G.W. SUN: A Bayesian framework for saliency using natural statistics. J. Vis. 2008, 8, 32. [Google Scholar] [CrossRef] [Green Version]
- Hou, X.; Zhang, L. Saliency Detection: A Spectral Residual Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Bruce, N.; Tsotsos, J. Saliency based on information maximization. Adv. Neural Inf. Process. Syst. 2005, 18, 155–162. [Google Scholar]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. Adv. Neural Inf. Process. Syst. 2006, 19, 545–552. [Google Scholar]
- Gao, D.; Vasconcelos, N. Discriminant saliency for visual recognition from cluttered scenes. Adv. Neural Inf. Process. Syst. 2004, 17, 481–488. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to Predict Where Humans Look. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2010; pp. 2106–2113. [Google Scholar]
- Ren, G.; Yu, Y.; Liu, H.; Stathaki, T. Dynamic Knowledge Distillation with Noise Elimination for RGB-D Salient Object Detection. Sensors 2022, 22, 6188. [Google Scholar] [CrossRef]
- Duan, F.; Wu, Y.; Guan, H.; Wu, C. Saliency Detection of Light Field Images by Fusing Focus Degree and GrabCut. Sensors 2022, 22, 7411. [Google Scholar] [CrossRef]
- Yang, J.; Wang, L.; Li, Y. Feature Refine Network for Salient Object Detection. Sensors 2022, 22, 4490. [Google Scholar] [CrossRef]
- Achanta, R.; Estrada, F.; Wils, P.; Süsstrunk, S. Salient Region Detection and Segmentation. In International Conference on Computer Vision Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 66–75. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [Green Version]
- Goferman, S.; Zelnik-Manor, L.; Tal, A. Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1915–1926. [Google Scholar] [CrossRef] [Green Version]
- Aiello, W.; Chung, F.; Lu, L. A Random Graph Model for Massive Graphs. In Proceedings of the Thirty-Second Annual ACM Symposium on Theory of Computing, Portland, OR, USA, 21–23 May 2000; pp. 171–180. [Google Scholar]
- Jian, M.; Lam, K.-M.; Dong, J.; Shen, L. Visual-Patch-Attention-Aware Saliency Detection. IEEE Trans. Cybern. 2014, 45, 1575–1586. [Google Scholar] [CrossRef]
- Jian, M.; Zhang, W.; Yu, H.; Cui, C.; Nie, X.; Zhang, H.; Yin, Y. Saliency detection based on directional patches extraction and principal local color contrast. J. Vis. Commun. Image Represent. 2018, 57, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Ma, Q.; Zhang, L. Spatio-temporal saliency detection using phase spectrum of quaternion fourier transform. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Achanta, R.; Susstrunk, S. Saliency Detection Using Maximum Symmetric Surround. In Proceedings of the IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2653–2656. [Google Scholar] [CrossRef] [Green Version]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network. In Neural Networks for Perception; Academic Press: Cambridge, MA, USA, 1992; pp. 65–93. [Google Scholar]
- Ren, W.; Zhang, J.; Pan, J.; Liu, S.; Ren, J.S.; Du, J.; Cao, X.; Yang, M.-H. Deblurring Dynamic Scenes via Spatially Varying Recurrent Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3974–3987. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2016, 128, 240–259. [Google Scholar] [CrossRef]
- Fan, B.; Zhou, J.; Feng, W.; Pu, H.; Yang, Y.; Kong, Q.; Wu, F.; Liu, H. Learning Semantic-Aware Local Features for Long Term Visual Localization. IEEE Trans. Image Process. 2022, 31, 4842–4855. [Google Scholar] [CrossRef] [PubMed]
- Fan, B.; Yang, Y.; Feng, W.; Wu, F.; Lu, J.; Liu, H. Seeing through Darkness: Visual Localization at Night via Weakly Supervised Learning of Domain Invariant Features. IEEE Trans. Multimedia 2022, 1. [Google Scholar] [CrossRef]
- Luo, A.; Li, X.; Yang, F.; Jiao, Z.; Cheng, H.; Lyu, S. Cascade Graph Neural Networks for RGB-D Salient Object Detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 8–14 September 2020; pp. 346–364. [Google Scholar] [CrossRef]
- Feng, M.; Lu, H.; Ding, E. Attentive Feedback Network for Boundary-Aware Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1623–1632. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple Pooling-Based Design for Realtime Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3917–3926. [Google Scholar]
- Wang, W.; Shen, J. Deep visual attention prediction. IEEE Trans. Image Process. 2017, 27, 2368–2378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cornia, M.; Baraldi, L.; Serra, G.; Cucchiara, R. Predicting Human Eye Fixations via an LSTM-Based Saliency Attentive Model. IEEE Trans. Image Process. 2018, 27, 5142–5154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, L.; Zhao, S.; Bourahla, O.E.F.; Li, X.; Wu, F.; Zhuang, Y. Deep Group-Wise Fully Convolutional Network for Co-Saliency Detection with Graph Propagation. IEEE Trans. Image Process. 2019, 28, 5052–5063. [Google Scholar] [CrossRef]
- Zhu, D.; Dai, L.; Luo, Y.; Zhang, G.; Shao, X.; Itti, L.; Lu, J. MAFL: Multi-Scale Adversarial Feature Learning for Saliency Detection. In Proceedings of the 2018 International Conference on Control and Computer Vision, New York, NY, USA, 15–18 June 2018; pp. 90–95. [Google Scholar]
- He, S.; Lau, R.W.; Liu, W.; Huang, Z.; Yang, Q. SuperCNN: A Superpixelwise Convolutional Neural Networkfor Salient Object Detection. Int. J. Comput. Vis. 2015, 115, 330–344. [Google Scholar] [CrossRef]
- Hou, Q.; Cheng, M.M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P.H. Deeply Supervised Salient Object Detection with Short Connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3203–3321. [Google Scholar]
- Hui, S.; Guo, Q.; Geng, X.; Zhang, C. Multi-Guidance CNNs for Salient Object Detection. ACM Trans. Multimed. Comput. Commun. Appl. 2022. Early Access. [Google Scholar] [CrossRef]
- Liu, N.; Zhang, N.; Wan, K.; Shao, L.; Han, J. Visual Saliency Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4722–4732. [Google Scholar]
- Hussain, T.; Anwar, A.; Anwar, S.; Petersson, L.; Baik, S.W. Pyramidal Attention for Saliency Detection. arXiv 2022, arXiv:2204.06788. [Google Scholar] [CrossRef]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to Detect Salient Objects with Image-Level Supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 136–145. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Li, G.; Yu, Y. Visual Saliency Based on Multiscale Deep Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Jian, M.; Wang, J.; Yu, H.; Wang, G.-G. Integrating object proposal with attention networks for video saliency detection. Inf. Sci. 2021, 576, 819–830. [Google Scholar] [CrossRef]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Wang, T.; Zhang, L.; Wang, S.; Lu, H.; Yang, G.; Ruan, X.; Borji, A. Detect globally, refine locally: A novel approach to saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3127–3135. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning Pixel-Wise Contextual Attention for Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3089–3098. [Google Scholar]
- Gao, S.-H.; Tan, Y.-Q.; Cheng, M.-M.; Lu, C.; Chen, Y.; Yan, S. Highly Efficient Salient Object Detection with 100K Parameters. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 8–14 September 2020; pp. 702–721. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Implementation | Configuration |
|---|---|
| Operating System | Win10 |
| Python | 3.7 |
| Pytorch | 1.5.0 |
| CUDA | 9.0 |
| GPU | NVIDIA-GTX1080ti |
| Methods | DUTS | ECSSD | HKU-IS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Amulet [8] | 0.778 | 0.657 | 0.085 | 0.915 | 0.841 | 0.059 | 0.895 | 0.813 | 0.052 |
| DCL [9] | 0.782 | 0.606 | 0.088 | 0.890 | 0.802 | 0.088 | 0.885 | 0.736 | 0.072 |
| DHS [10] | 0.807 | 0.698 | 0.067 | 0.832 | 0.841 | 0.059 | 0.890 | 0.806 | 0.053 |
| MDF [11] | 0.730 | 0.509 | 0.094 | 0.783 | 0.605 | 0.105 | 0.861 | 0.726 | 0.129 |
| NLDF [12] | 0.812 | 0.710 | 0.066 | 0.905 | 0.839 | 0.063 | 0.902 | 0.838 | 0.045 |
| UCF [13] | 0.771 | 0.588 | 0.117 | 0.911 | 0.789 | 0.078 | 0.886 | 0.751 | 0.074 |
| RAS [14] | 0.831 | 0.727 | 0.060 | 0.920 | 0.809 | 0.056 | 0.913 | 0.821 | 0.045 |
| R3Net [48] | 0.828 | 0.715 | 0.059 | 0.931 | 0.832 | 0.046 | 0.916 | 0.837 | 0.038 |
| DGRL [49] | 0.829 | 0.708 | 0.050 | 0.922 | 0.813 | 0.041 | 0.910 | 0.842 | 0.036 |
| DSS [16] | 0.825 | 0.732 | 0.057 | 0.915 | 0.858 | 0.052 | 0.913 | 0.836 | 0.039 |
| PiCANet [50] | 0.851 | 0.748 | 0.054 | 0.931 | 0.863 | 0.042 | 0.921 | 0.847 | 0.042 |
| CSNet [51] | 0.819 | 0.712 | 0.074 | 0.916 | 0.837 | 0.066 | 0.899 | 0.813 | 0.059 |
| Ours | 0.832 | 0.736 | 0.052 | 0.932 | 0.865 | 0.041 | 0.917 | 0.844 | 0.035 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jian, M.; Jin, H.; Liu, X.; Zhang, L. Multiscale Cascaded Attention Network for Saliency Detection Based on ResNet. Sensors 2022, 22, 9950. https://doi.org/10.3390/s22249950
Jian M, Jin H, Liu X, Zhang L. Multiscale Cascaded Attention Network for Saliency Detection Based on ResNet. Sensors. 2022; 22(24):9950. https://doi.org/10.3390/s22249950
Chicago/Turabian StyleJian, Muwei, Haodong Jin, Xiangyu Liu, and Linsong Zhang. 2022. "Multiscale Cascaded Attention Network for Saliency Detection Based on ResNet" Sensors 22, no. 24: 9950. https://doi.org/10.3390/s22249950