
Intelligent Sensors for dc Fault Location Scheme Based on Optimized Intelligent Architecture for HVdc Systems

 ,
,  ,
,
Abstract
:1. Introduction
- Our initial goal is to create a learning-based algorithm that relies on only one end of the communication link for fault location. Hence, eliminating reliance on the communication link.
- In general, a signal detected by a sensor is invariably interfered with by the surrounding environment or modified by the detecting equipment during the detection process, increasing failure chances. The DWT-based signal analysis model is used to eliminate interference from the observed signal to improve signal analysis and recognition.
- The energy or norm of the current and voltage signals at each frequency band gives a unique signature for different fault locations and has been found to be robust against noise. Therefore, it is used as an extracted feature for pattern recognition.
- The proposed algorithm must be able to locate internal faults with high fault impedances at further distances.
2. Proposed Framework
2.1. Feedforward Neural Network (FFNN)
2.2. Backpropagation Algorithm
2.3. Levenberg–Marquardt Backpropagation
2.4. Parameter Optimization
2.4.1. Black-Box Settings
2.4.2. Gaussian Process (GP)
2.4.3. Acquisition Function
2.4.4. Implementation of Proposed Framework
3. System Model
Model Output
4. Data Processing
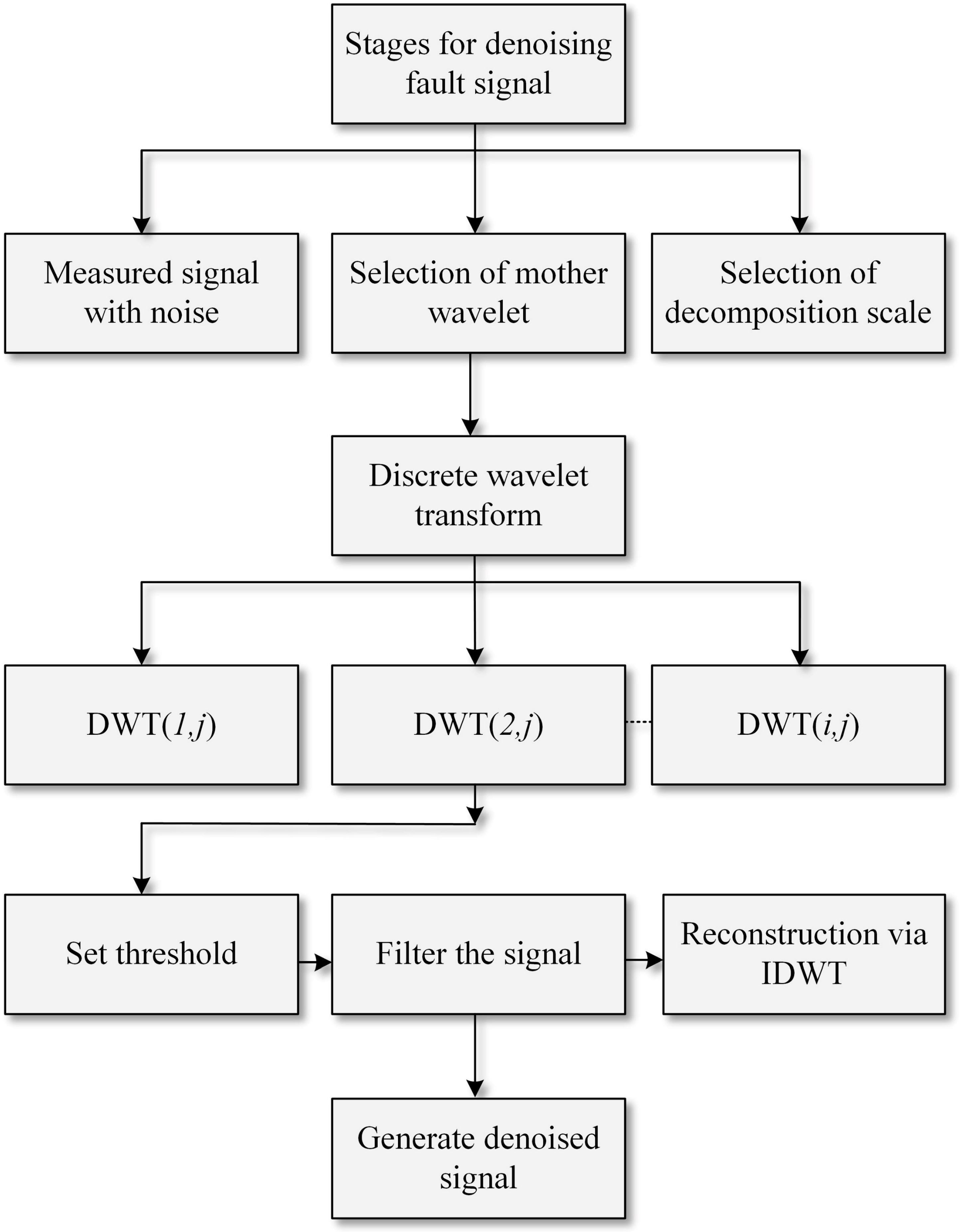
4.1. Signal Processing
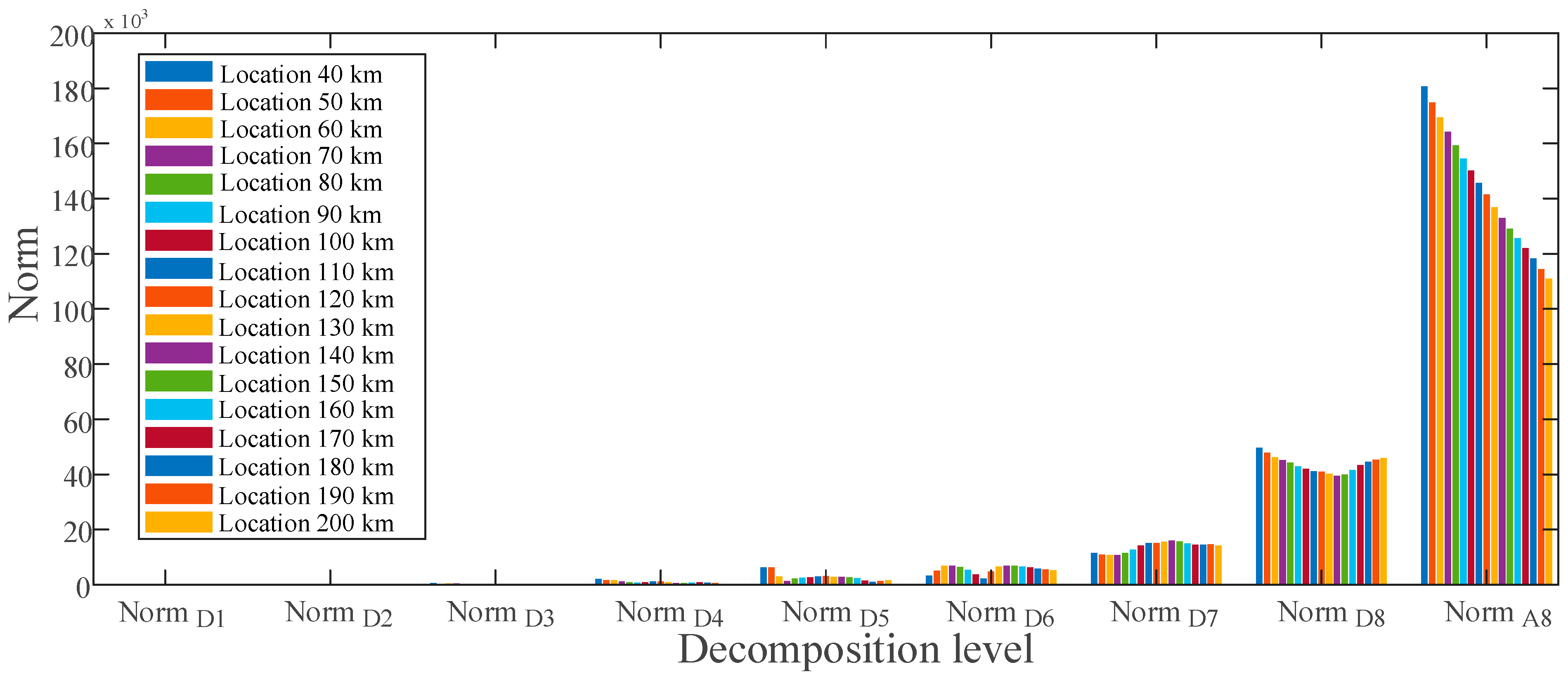
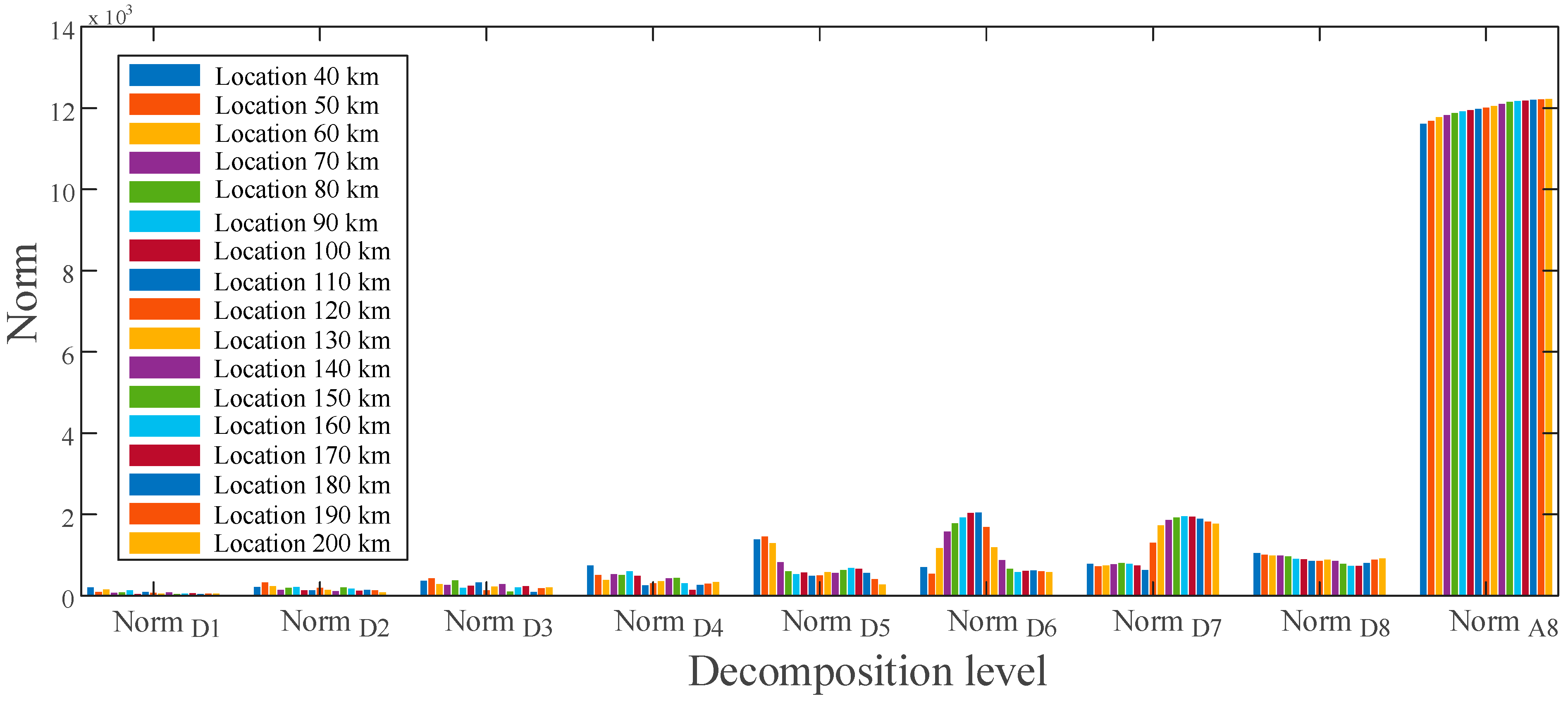
4.1.1. Setting Numbers of Decomposition Layers
4.1.2. Selection of Mother Wavelet Function
4.1.3. Set the Threshold and Filter the Signal
4.2. Feature Extraction Set-Up
4.2.1. Feature Extraction Results
4.2.2. Training Set-Up
5. Simulation Results and Discussions
- A.
- Metric for Evaluation and Testing Set-Up
5.1. Case 1 (Fault Location)
5.2. Case 2 (Fint)
5.3. Case 3 (Noisy Events)
5.4. Case 4 (Comparison with Existing Methods)
6. Comparison and Analysis
6.1. Non-AI-Based Methods
6.2. AI-Based Methods
7. Conclusions
- The wavelet coefficient energies of voltage and current over 10 ms are calculated and denoised during the learning phase for feature extraction. This leads to fewer features yet is robust for the learning model.
- A comprehensive training dataset is collected to train the multilayer FFNN model for different fault locations by varying fault impedance.
- The performance of this model is then evaluated on data points that are not included in the training dataset. The study results show that the fault location can be calculated using the FFNN for fault resistance up to 485 Ω.
- Because the signal and Gaussian noise are integrated into the FFNN training sets, the influence of the noise-contained environment is reduced.
- Due to plug-and-play capability, the suggested intelligent algorithm is tailored for a multi-vendor-based fault location estimation strategy in meshed MT-HVdc grids.
- The case studies show that the proposed scheme performs well against many variables, such as different fault resistances, transmission line lengths, and non-ideal noise events. Thus, that makes it feasible for practical application in the MT-HVdc grid.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fairley, P. China’s ambitious plan to build the world’s biggest supergrid. IEEE Spectr. 2019, 1, 35–41. [Google Scholar]
- He, Z.-Y.; Liao, K.; Li, X.-P.; Lin, S.; Yang, J.-W.; Mai, R.-K. Natural frequency-based line fault location in HVDC lines. IEEE Trans. Power Deliv. 2014, 29, 851–859. [Google Scholar] [CrossRef]
- Suonan, J.; Gao, S.; Song, G.; Jiao, Z.; Kang, X. A novel fault-location method for HVDC transmission lines. IEEE Trans. Power Deliv. 2009, 25, 1203–1209. [Google Scholar] [CrossRef]
- Zhang, M.; Li, J.; Li, Y.; Xu, R. Deep learning for short-term voltage stability assessment of power systems. IEEE Access 2021, 9, 29711–29718. [Google Scholar] [CrossRef]
- Xiao, D.; Chen, H.; Wei, C.; Bai, X. Statistical Measure for Risk-Seeking Stochastic Wind Power Offering Strategies in Electricity Markets. J. Mod. Power Syst. Clean Energy 2021, 10, 1437–1442. [Google Scholar] [CrossRef]
- Nsaif, Y.M.; Hossain Lipu, M.S.; Hussain, A.; Ayob, A.; Yusof, Y.; Zainuri, M.A.A. A Novel Fault Detection and Classification Strategy for Photovoltaic Distribution Network Using Improved Hilbert–Huang Transform and Ensemble Learning Technique. Sustainability 2022, 14, 11749. [Google Scholar] [CrossRef]
- Zhang, C.; Song, G.; Wang, T.; Yang, L. Single-ended traveling wave fault location method in DC transmission line based on wave front information. IEEE Trans. Power Deliv. 2019, 34, 2028–2038. [Google Scholar] [CrossRef]
- Hamidi, R.J.; Livani, H. Traveling-wave-based fault-location algorithm for hybrid multiterminal circuits. IEEE Trans. Power Deliv. 2016, 32, 135–144. [Google Scholar] [CrossRef]
- Ahmadimanesh, A.; Shahrtash, S.M. Transient-based fault-location method for multiterminal lines employing S-transform. IEEE Trans. Power Deliv. 2013, 28, 1373–1380. [Google Scholar] [CrossRef]
- Perveen, R.; Mohanty, S.R.; Kishor, N. Fault location in VSC-HVDC section for grid integrated offshore wind farm by EMD. In Proceedings of the 18th Mediterranean Electrotechnical Conference (MELECON), Lemesos, Cyprus, 18–20 April 2016; IEEE: Lemesos, Cyprus, 2016; pp. 1–5. [Google Scholar]
- Farshad, M.; Sadeh, J. Accurate single-phase fault-location method for transmission lines based on k-nearest neighbor algorithm using one-end voltage. IEEE Trans. Power Deliv. 2012, 27, 2360–2367. [Google Scholar] [CrossRef]
- Samantaray, S. A systematic fuzzy rule based approach for fault classification in transmission lines. Appl. Soft Comput. 2013, 13, 928–938. [Google Scholar] [CrossRef]
- Ola, S.R.; Saraswat, A.; Goyal, S.K.; Jhajharia, S.; Rathore, B.; Mahela, O.P. Wigner distribution function and alienation coefficient-based transmission line protection scheme. IET Gener. Transm. Distrib. 2020, 14, 1842–1853. [Google Scholar] [CrossRef]
- Ram Ola, S.; Saraswat, A.; Goyal, S.K.; Jhajharia, S.; Khan, B.; Mahela, O.P.; Haes Alhelou, H.; Siano, P. A protection scheme for a power system with solar energy penetration. Appl. Sci. 2020, 10, 1516. [Google Scholar] [CrossRef] [Green Version]
- Samantaray, S.; Dash, P.; Panda, G. Fault classification and location using HS-transform and radial basis function neural network. Electr. Power Syst. Res. 2006, 76, 897–905. [Google Scholar] [CrossRef]
- Salat, R.; Osowski, S. Accurate fault location in the power transmission line using support vector machine approach. IEEE Trans. Power Syst. 2004, 19, 979–986. [Google Scholar] [CrossRef]
- Luo, G.; Yao, C.; Tan, Y.; Liu, Y. Transient signal identification of HVDC transmission lines based on wavelet entropy and SVM. J. Eng. 2019, 2019, 2414–2419. [Google Scholar] [CrossRef]
- Malathi, V.; Marimuthu, N.; Baskar, S. Intelligent approaches using support vector machine and extreme learning machine for transmission line protection. Neurocomputing 2010, 73, 2160–2167. [Google Scholar] [CrossRef]
- Farshad, M. Detection and classification of internal faults in bipolar HVDC transmission lines based on K-means data description method. Int. J. Electr. Power Energy Syst. 2019, 104, 615–625. [Google Scholar] [CrossRef]
- Ekici, S.; Yildirim, S.; Poyraz, M. Energy and entropy-based feature extraction for locating fault on transmission lines by using neural network and wavelet packet decomposition. Expert Syst. Appl. 2008, 34, 2937–2944. [Google Scholar] [CrossRef]
- Jayamaha, D.; Lidula, N.; Rajapakse, A.D. Wavelet-multi resolution analysis based ANN architecture for fault detection and localization in DC microgrids. IEEE Access 2019, 7, 145371–145384. [Google Scholar] [CrossRef]
- Merlin, V.L.; dos Santos, R.C.; Le Blond, S.; Coury, D.V. Efficient and robust ANN-based method for an improved protection of VSC-HVDC systems. IET Renew. Power Gener. 2018, 12, 1555–1562. [Google Scholar] [CrossRef]
- Karmacharya, I.M.; Gokaraju, R. Fault location in ungrounded photovoltaic system using wavelets and ANN. IEEE Trans. Power Deliv. 2017, 33, 549–559. [Google Scholar] [CrossRef]
- Torun, H.M.; Swaminathan, M.; Davis, A.K.; Bellaredj, M.L.F. A global Bayesian optimization algorithm and its application to integrated system design. IEEE Trans. Very Large Scale Integr. Syst. 2018, 26, 792–802. [Google Scholar] [CrossRef]
- Chen, P.; Merrick, B.M.; Brazil, T.J. Bayesian optimization for broadband high-efficiency power amplifier designs. IEEE Trans. Microw. Theory Tech. 2015, 63, 4263–4272. [Google Scholar] [CrossRef]
- Park, S.J.; Bae, B.; Kim, J.; Swaminathan, M. Application of machine learning for optimization of 3-D integrated circuits and systems. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 1856–1865. [Google Scholar] [CrossRef]
- Lv, C.; Xing, Y.; Zhang, J.; Na, X.; Li, Y.; Liu, T.; Cao, D.; Wang, F.-Y. Levenberg–Marquardt backpropagation training of multilayer neural networks for state estimation of a safety-critical cyber-physical system. IEEE Trans. Ind. Inform. 2017, 14, 3436–3446. [Google Scholar] [CrossRef] [Green Version]
- Soualhi, A.; Makdessi, M.; German, R.; Echeverría, F.R.; Razik, H.; Sari, A.; Venet, P.; Clerc, G. Heath monitoring of capacitors and supercapacitors using the neo-fuzzy neural approach. IEEE Trans. Ind. Inform. 2017, 14, 24–34. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef]
- Sadiq, M.T.; Yu, X.; Yuan, Z.; Aziz, M.Z.; Siuly, S.; Ding, W. Toward the development of versatile brain–computer interfaces. IEEE Trans. Artif. Intell. 2021, 2, 314–328. [Google Scholar] [CrossRef]
- Sharifzadeh, M.; Sikinioti-Lock, A.; Shah, N. Machine-learning methods for integrated renewable power generation: A comparative study of artificial neural networks, support vector regression, and Gaussian Process Regression. Renew. Sustain. Energy Rev. 2019, 108, 513–538. [Google Scholar] [CrossRef]
- Bull, A.D. Convergence rates of efficient global optimization algorithms. J. Mach. Learn. Res. 2011, 12, 2879–2904. [Google Scholar]
- Leterme, W.; Ahmed, N.; Beerten, J.; Ängquist, L.; Van Hertem, D.; Norrga, S. A New HVDC Grid Test System for HVDC Grid Dynamics and Protection Studies in EMT-Type Software. In Proceedings of the 11th IET International Conference on AC and DC Power Transmission, Birmingham, AL, USA, 10–12 February 2015; IET, 2015; pp. 1–7. [Google Scholar]
- Wang, M.-H.; Lu, S.-D.; Liao, R.-M. Fault diagnosis for power cables based on convolutional neural network with chaotic system and discrete wavelet transform. IEEE Trans. Power Deliv. 2021, 21, 2285–2294. [Google Scholar] [CrossRef]
- Ukil, A.; Yeap, Y.M.; Satpathi, K. Fault Analysis and Protection System Design for DC Grids; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Nanayakkara, O.K.; Rajapakse, A.D.; Wachal, R. Traveling-wave-based line fault location in star-connected multiterminal HVDC systems. IEEE Trans. Power Deliv. 2012, 27, 2286–2294. [Google Scholar] [CrossRef]
- Nanayakkara, O.K.; Rajapakse, A.D.; Wachal, R. Location of DC line faults in conventional HVDC systems with segments of cables and overhead lines using terminal measurements. IEEE Trans. Power Deliv. 2011, 27, 279–288. [Google Scholar] [CrossRef]
- Azizi, S.; Sanaye-Pasand, M.; Abedini, M.; Hasani, A. A traveling-wave-based methodology for wide-area fault location in multiterminal DC systems. IEEE Trans. Power Deliv. 2014, 29, 2552–2560. [Google Scholar] [CrossRef]
- Tzelepis, D.; Psaras, V.; Tsotsopoulou, E.; Mirsaeidi, S.; Dyśko, A.; Hong, Q.; Dong, X.; Blair, S.M.; Nikolaidis, V.C.; Papaspiliotopoulos, V. Voltage and current measuring technologies for high voltage direct current supergrids: A technology review identifying the options for protection, fault location and automation applications. IEEE Access 2020, 8, 203398–203428. [Google Scholar] [CrossRef]
- Ashouri, M.; da Silva, F.F.; Bak, C.L. On the application of modal transient analysis for online fault localization in HVDC cable bundles. IEEE Trans. Power Deliv. 2019, 35, 1365–1378. [Google Scholar] [CrossRef]
- Hadaeghi, A.; Samet, H.; Ghanbari, T. Multi extreme learning machine approach for fault location in multi-terminal high-voltage direct current systems. Comput. Electr. Eng. 2019, 78, 313–327. [Google Scholar] [CrossRef]
- Livani, H.; Evrenosoglu, C.Y. A single-ended fault location method for segmented HVDC transmission line. Electr. Power Syst. Res. 2014, 107, 190–198. [Google Scholar] [CrossRef]
- Tzelepis, D.; Dyśko, A.; Fusiek, G.; Niewczas, P.; Mirsaeidi, S.; Booth, C.; Dong, X. Advanced fault location in MTDC networks utilising optically-multiplexed current measurements and machine learning approach. Int. J. Electr. Power Energy Syst. 2018, 97, 319–333. [Google Scholar] [CrossRef] [Green Version]
- Tsotsopoulou, E.; Karagiannis, X.; Papadopoulos, P.; Dyśko, A.; Yazdani-Asrami, M.; Booth, C.; Tzelepis, D. Time-domain protection of superconducting cables based on artificial intelligence classifiers. IEEE Access 2022, 10, 10124–10138. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LMBP Algorithm for the Fault Location Process |
|---|
|
| Station | Rated dc Voltage [kV] | Rated Capacity [MVA] | Arm Capacitance Carm (µF) | Arm Inductance Larm [mH] | Arm Resistance Rarm [Ω] | Bus Filter Reactor [mH] |
|---|---|---|---|---|---|---|
| MMC1 | ±320 | 900 | 29.3 | 84.8 | 0.885 | 10 |
| MMC2 | ±320 | 900 | 29.3 | 84.8 | 0.885 | 10 |
| MMC3 | ±320 | 900 | 29.3 | 84.8 | 0.885 | 10 |
| MMC4 | ±320 | 1200 | 39.0 | 63.6 | 0.67 | 10 |
| dc System | Link12 | Link13 | Link34 | Link24 |
|---|---|---|---|---|
| Length [km] | 100 | 200 | 100 | 150 |
| Inductance [mH] | 100 | 100 | 100 | 100 |
| ac system | AC 1 | AC 2 | AC 3 | AC 4 |
| Rated voltage [kV] | 400 | 400 | 400 | 400 |
| Reactance Xac [Ω] | 17.7 | 17.7 | 17.7 | 13.4 |
| Resistance Rac [Ω] | 1.77 | 1.77 | 1.77 | 1.34 |
| Transformer µk [pu] | 0.15 | 0.15 | 0.15 | 0.15 |
| Cable | Outer Radius [mm] | [Ωm] | Єre1 [-] | µre1 [-] | Link34 |
|---|---|---|---|---|---|
| Core | 19.5 | 1.7 × 10−8 | -- | 1 | |
| Insulation | 48.7 | -- | 2.3 | 150 | 1 |
| Sheath | 51.7 | 2.2 × 10−7 | -- | 100 | 1 |
| Insulation | 54.7 | -- | 2.3 | AC4 | 1 |
| Armor | 58.7 | 1.8 × 10−7 | -- | 400 | 10 |
| Insulation | 63.7 | -- | 2.3 | 13.4 | 1 |
| Transient Period | Training Samples | Fault Resistance (Ω) | Fault Distance (km) | Noise (dB) |
|---|---|---|---|---|
| 10 ms | 357 | 0.01, 25, 50, …, 375, 400 | 1, 10, 20, …, 180, 190, 198 | 20, 25, 30 |
| Total faulty sample = 357/each fault type; dc-link faults are first classified into two parts: pole to pole and pole to ground fault. Therefore, total training samples = k = (Fint = 357 ∗ 2) = 714. Fault distance is noted from MMC1 to MMC 3 and MMC1 to MMC2, respectively. | ||||
| Hyperparameters | Range | Fault Location Model |
|---|---|---|
| Learning Rate | [1 × 10−2–1] | 0.010037 |
| Hidden Layers/Neurons (NHL) | [1–40] | 28 |
| Momentum | [0.001–0.005] | 0.0028608 |
| Epochs | [20–1000] | 994 |
| Gradient | [1 × 10−7–10−6] | 1.2925 × 10−7 |
| Validation | [0–6] | 4 |
| Transient Period [10 ms] | Testing Samples | Fault Resistance (Ω) | Fault Distance (km) | Noise (dB) |
|---|---|---|---|---|
| 10 ms | 400 | 10, 35, 60, 85, …, 435, 460, 485 | 5, 15, 25, …, 175, 185, 195 | 20, 25, 45 |
| Total faulty sample = 400/each fault type, Total testing samples = [(400) ∗ 2] = 800, Refer Table 6 for fault distance | ||||
| Fault Type | Total Faults | Max Absolute Error (km) | Max Percentage Error (%) | Overall Absolute Error (km) | Overall Percentage Error (%) |
|---|---|---|---|---|---|
| PTP | 400 | 2.6350 | 1.3174 | 0.9853 | 0.4927 |
| PTG | 400 | 2.6412 | 1.3206 | 1.0723 | 0.5361 |
| Average Error | NA | NA | NA | 1.0288 | 0.5144 |
| Fault Location | Fault Resistance (Ω) | Fault Type | dc-Link Fault Location Results | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Predicted Location | Absolute Error | Percentage Error (%) | ||||||||
| PTP | PTG | PTP | PTG | PTP | PTG | |||||
| 5 km of dc link | 10 | PTP | PTG | 5.02021 | 5.03022 | 0.02021 | 0.03022 | 0.01011 | 0.01511 | |
| 110 | PTP | PTG | 5.07141 | 5.08142 | 0.07141 | 0.08142 | 0.03571 | 0.04071 | ||
| 260 | PTP | PTG | 5.63413 | 5.76481 | 0.63413 | 0.76481 | 0.31707 | 0.38241 | ||
| 35 km of dc link | 35 | PTP | PTG | 35.05123 | 35.07134 | 0.05123 | 0.07134 | 0.025615 | 0.03567 | |
| 235 | PTP | PTG | 35.62858 | 36.10184 | 0.62858 | 1.10184 | 0.31429 | 0.55092 | ||
| 285 | PTP | PTG | 35.86144 | 36.31471 | 0.86144 | 1.31471 | 0.43072 | 0.65736 | ||
| 125 km of dc link | 260 | PTP | PTG | 126.67141 | 126.81487 | 1.67141 | 1.81487 | 0.83571 | 0.90744 | |
| 385 | PTP | PTG | 126.76175 | 126.91231 | 1.76175 | 1.91231 | 0.88088 | 0.956155 | ||
| 110 | PTP | PTG | 126.01522 | 126.52812 | 1.01522 | 1.52812 | 0.50761 | 0.76406 | ||
| 185 km of dc link | 260 | PTP | PTG | 186.94571 | 186.75387 | 1.94571 | 1.75387 | 0.972855 | 0.87694 | |
| 385 | PTP | PTG | 183.63147 | 186.93141 | 1.36853 | 1.93141 | 0.68427 | 0.96571 | ||
| 110 | PTP | PTG | 186.34578 | 186.53681 | 1.34578 | 1.53681 | 0.67289 | 0.76841 | ||
| Normal operation | X | X | X | X | NOT APPLICABLE | NOT APPLICABLE | NOT APPLICABLE | |||
| Noise (dB) | Fault Location | Fault Resistance (Ω) | Fault Type | dc-Link Fault Location Results | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Predicted Location | Absolute Error | Percentage Error (%) | ||||||||
| PTP | PTG | PTP | PTG | PTP | PTG | |||||
| 25 | 5 km of dc link | 10 | PTP | PTG | 5.04512 | 5.06727 | 0.04512 | 0.06727 | 0.02256 | 0.03364 |
| 110 | PTP | PTG | 6.01202 | 6.03567 | 1.01202 | 1.03567 | 0.50601 | 0.51784 | ||
| 260 | PTP | PTG | 6.26783 | 6.15872 | 1.26783 | 1.15872 | 0.63392 | 0.57936 | ||
| 20 | 45 km of dc link | 35 | PTP | PTG | 46.06982 | 46.23672 | 1.06982 | 1.23672 | 0.53491 | 0.61836 |
| 235 | PTP | PTG | 46.84612 | 47.03452 | 1.84612 | 2.03452 | 0.92306 | 1.01726 | ||
| 285 | PTP | PTG | 47.03487 | 46.76324 | 2.03487 | 1.76324 | 1.01744 | 0.88162 | ||
| 45 | 155 km of dc link | 260 | PTP | PTG | 156.96342 | 154.06853 | 1.96342 | 0.93147 | 0.98171 | 0.46574 |
| 385 | PTP | PTG | 154.13647 | 153.02356 | 0.86353 | 1.97644 | 0.43177 | 0.98822 | ||
| 110 | PTP | PTG | 154.43628 | 154.36571 | 0.56372 | 0.63429 | 0.28186 | 0.31715 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yousaf, M.Z.; Tahir, M.F.; Raza, A.; Khan, M.A.; Badshah, F. Intelligent Sensors for dc Fault Location Scheme Based on Optimized Intelligent Architecture for HVdc Systems. Sensors 2022, 22, 9936. https://doi.org/10.3390/s22249936
Yousaf MZ, Tahir MF, Raza A, Khan MA, Badshah F. Intelligent Sensors for dc Fault Location Scheme Based on Optimized Intelligent Architecture for HVdc Systems. Sensors. 2022; 22(24):9936. https://doi.org/10.3390/s22249936
Chicago/Turabian StyleYousaf, Muhammad Zain, Muhammad Faizan Tahir, Ali Raza, Muhammad Ahmad Khan, and Fazal Badshah. 2022. "Intelligent Sensors for dc Fault Location Scheme Based on Optimized Intelligent Architecture for HVdc Systems" Sensors 22, no. 24: 9936. https://doi.org/10.3390/s22249936