
XDecompo: Explainable Decomposition Approach in Convolutional Neural Networks for Tumour Image Classification


Abstract
:1. Introduction
- Propose a new model, XDecompo (the developed code is available at (https://github.com/Asmaa-AbbasHassan/XDecompo accessed on 14 November 2022)), using an affinity propagation-based class decomposition mechanism to robustly and automatically learn the class boundaries in the downstream tasks.
- Investigate the generalisation capability of XDecompo in coping with different medical image datasets.
- Demonstrate the effective performance of XDecompo in feature transferability.
- Validate the robustness of XDecompo using a post hoc explainable AI method for feature visualisation, compared to state-of-the-art related models.
2. Related Work
3. Explainability AI in Medical Imaging
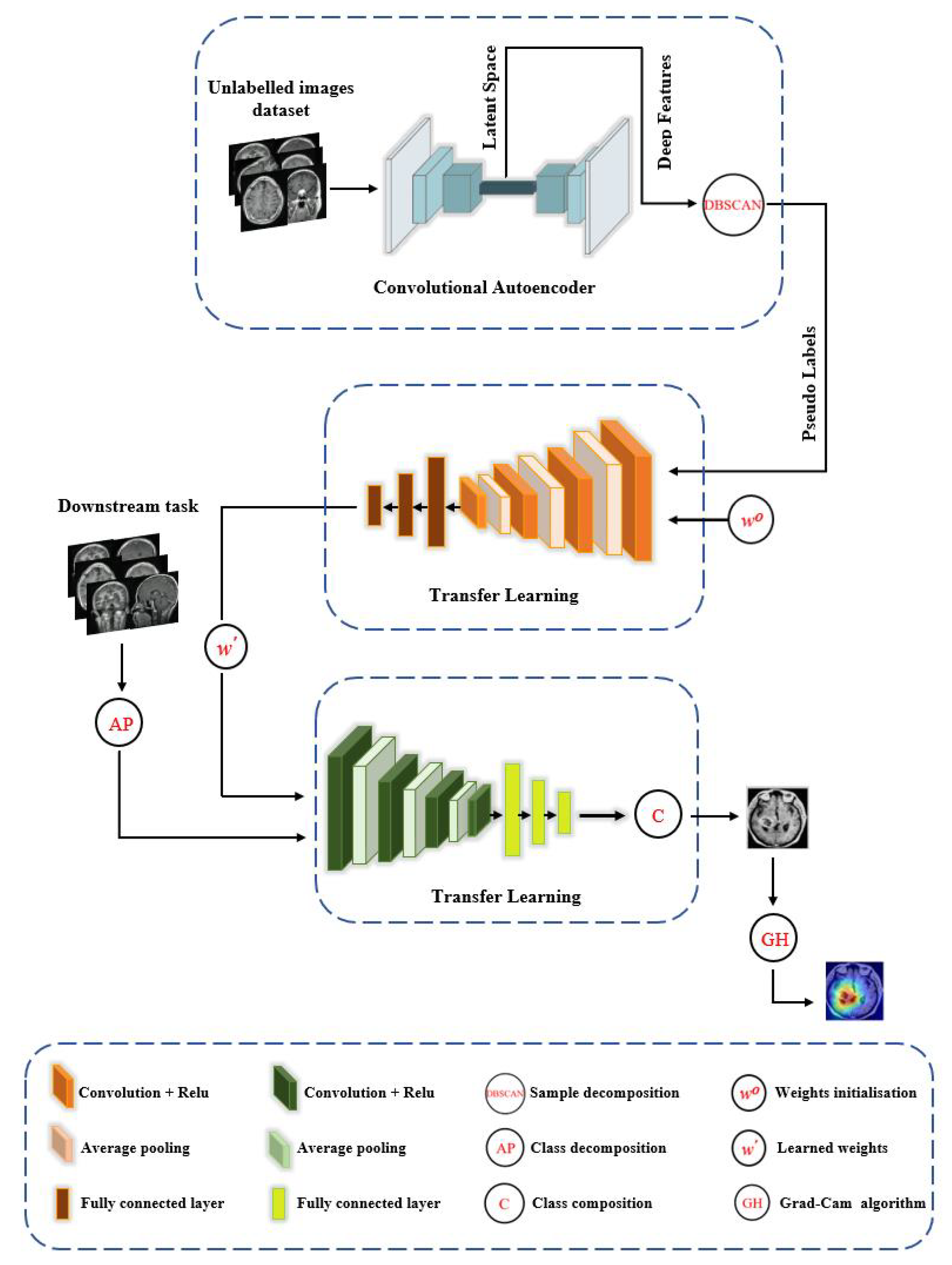
XDecompo Model
- Pseudo-Labels: Extraction of deep local features from a huge number of unlabelled images using convolutional neural networks with a sample decomposition approach. We used the density-based spatial clustering of applications with the noise (DBSCAN) method [52] as a clustering algorithm for the annotation of pseudo-labels. DBSCAN is an unsupervised clustering algorithm that can cluster any type of data containing noise and outliers, without prior knowledge of the number of clusters.
- Pretext Training: Using an ImageNet pre-trained network, such as ResNet-50, to classify pseudo-labelled images and achieve coarse transfer learning; where all layers were learnt as a deep-tuning mode to construct the feature space. The CNN model was trained with a cross-entropy loss function based on a mini-batch of stochastic gradient descent (mSGD) [53] to optimise the model during training.
- Downstream Training: Utilisation of learned convolutional features with a novel class decomposition approach to solve a new task (i.e., downstream training) in a small dataset.
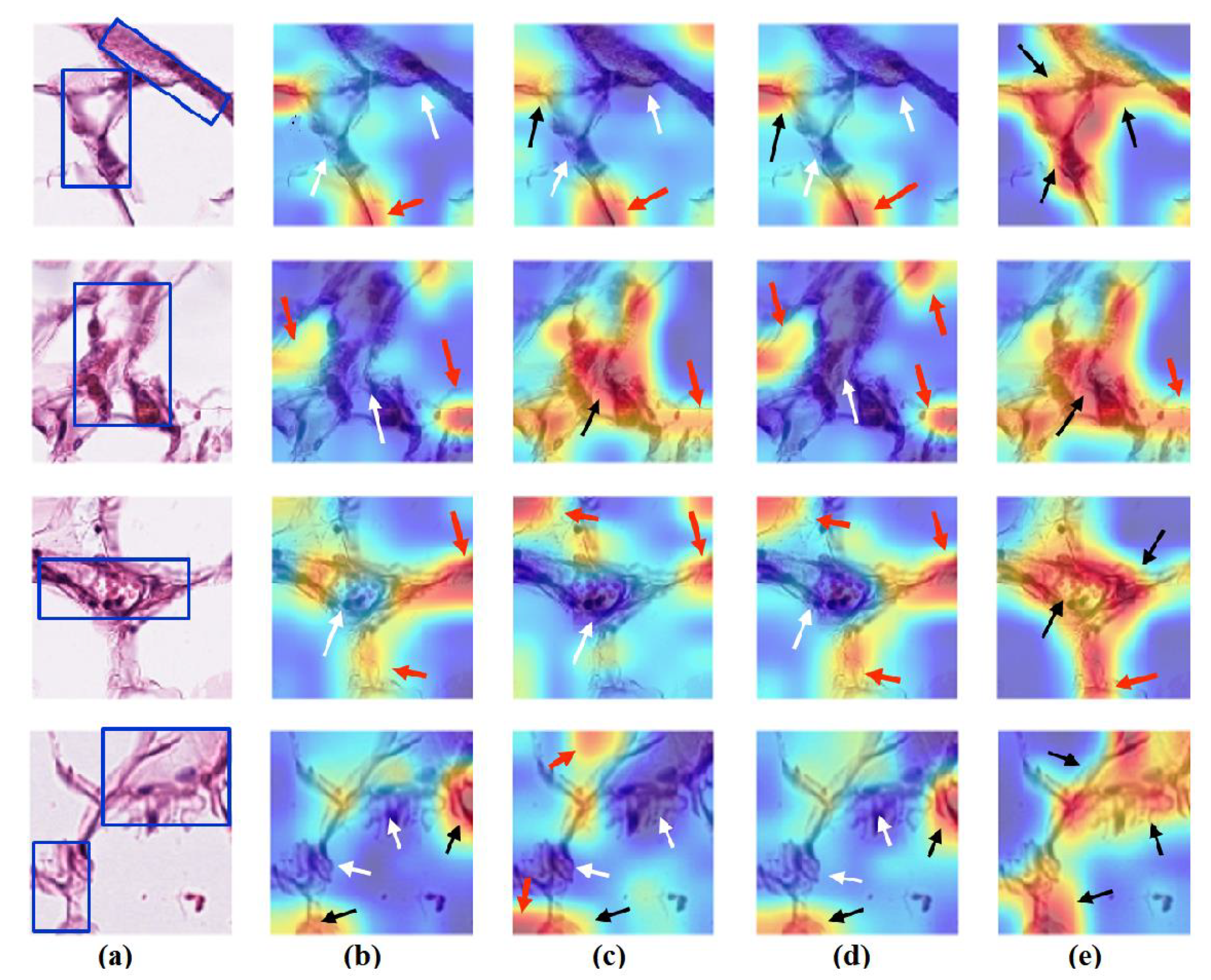
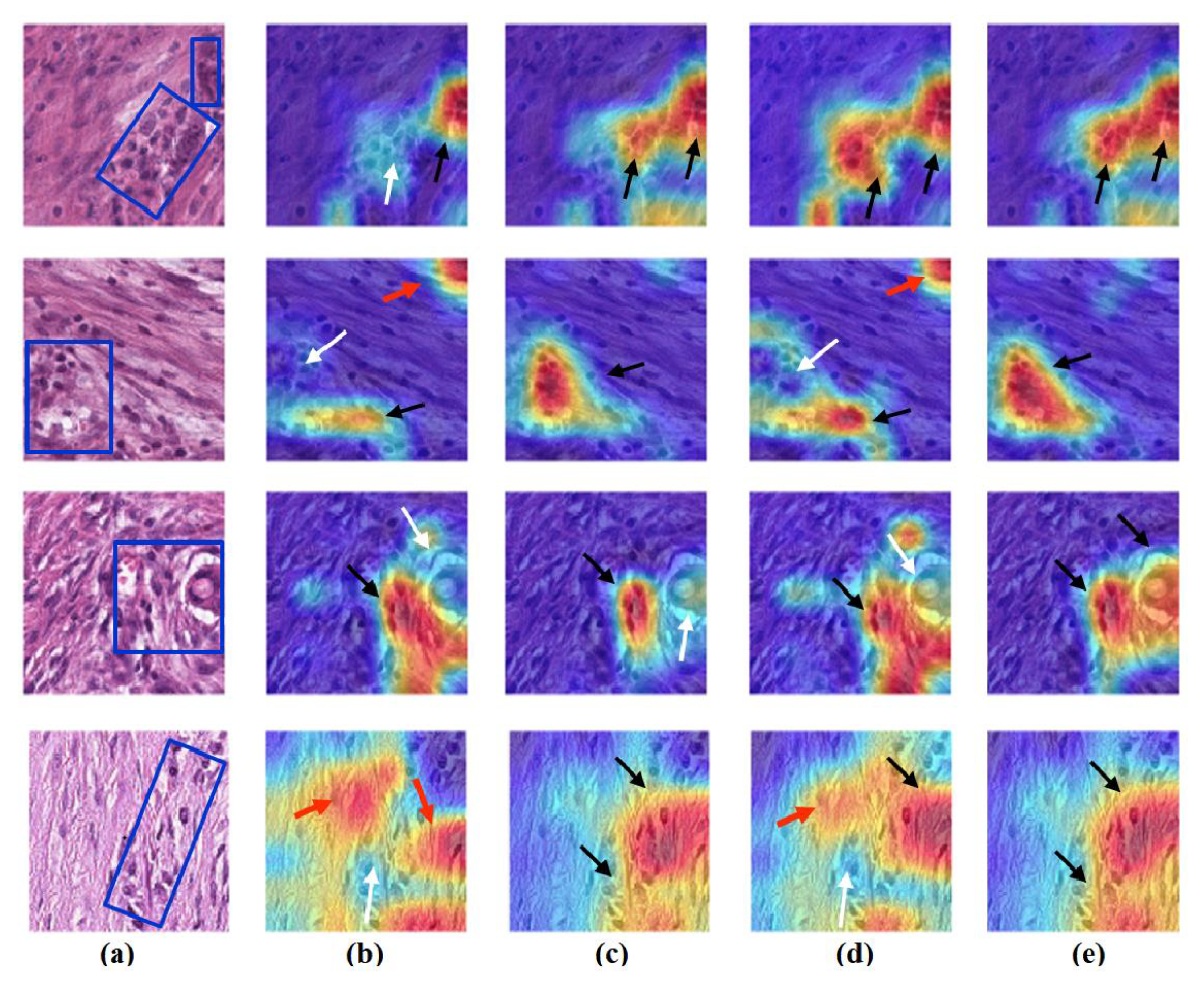
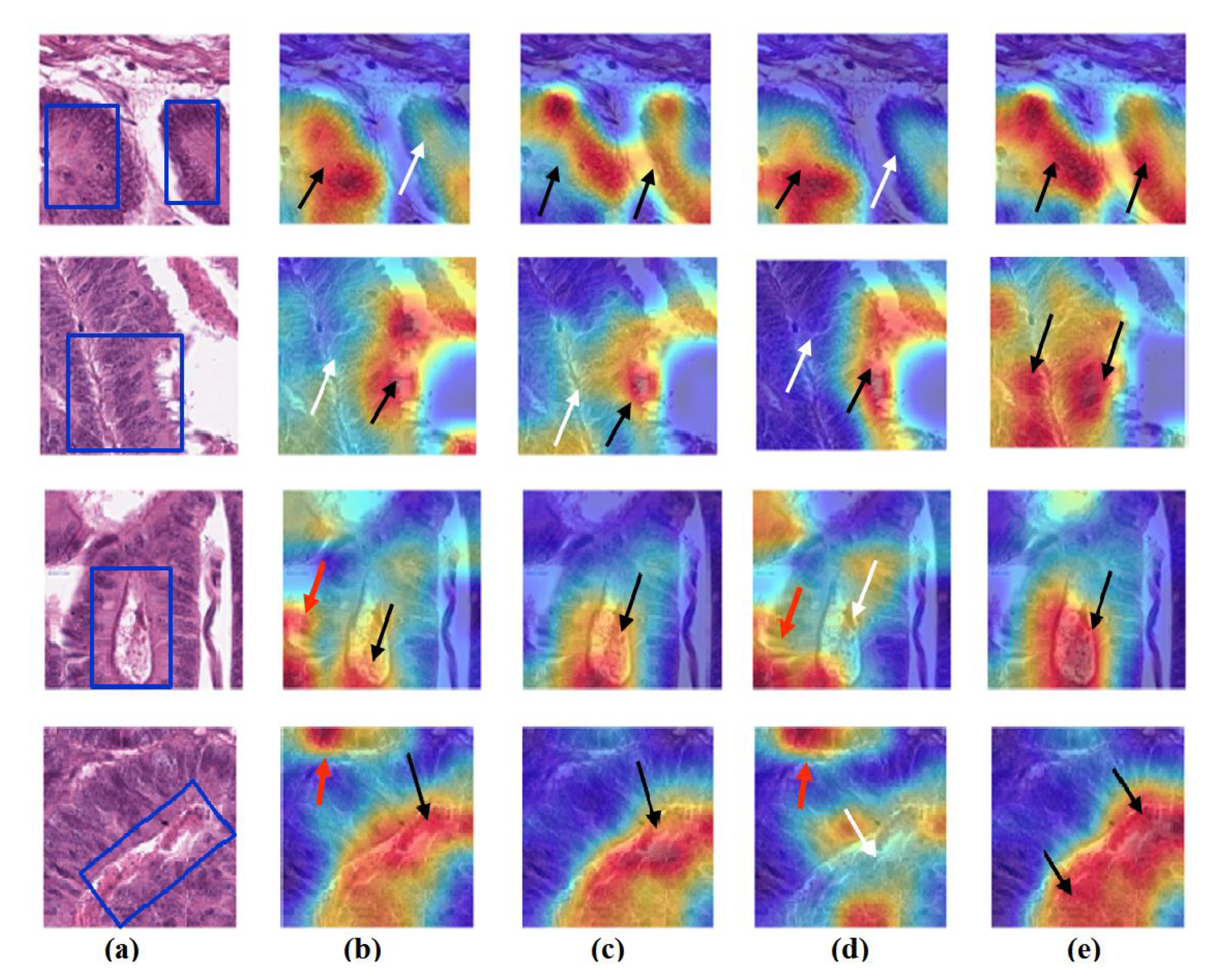
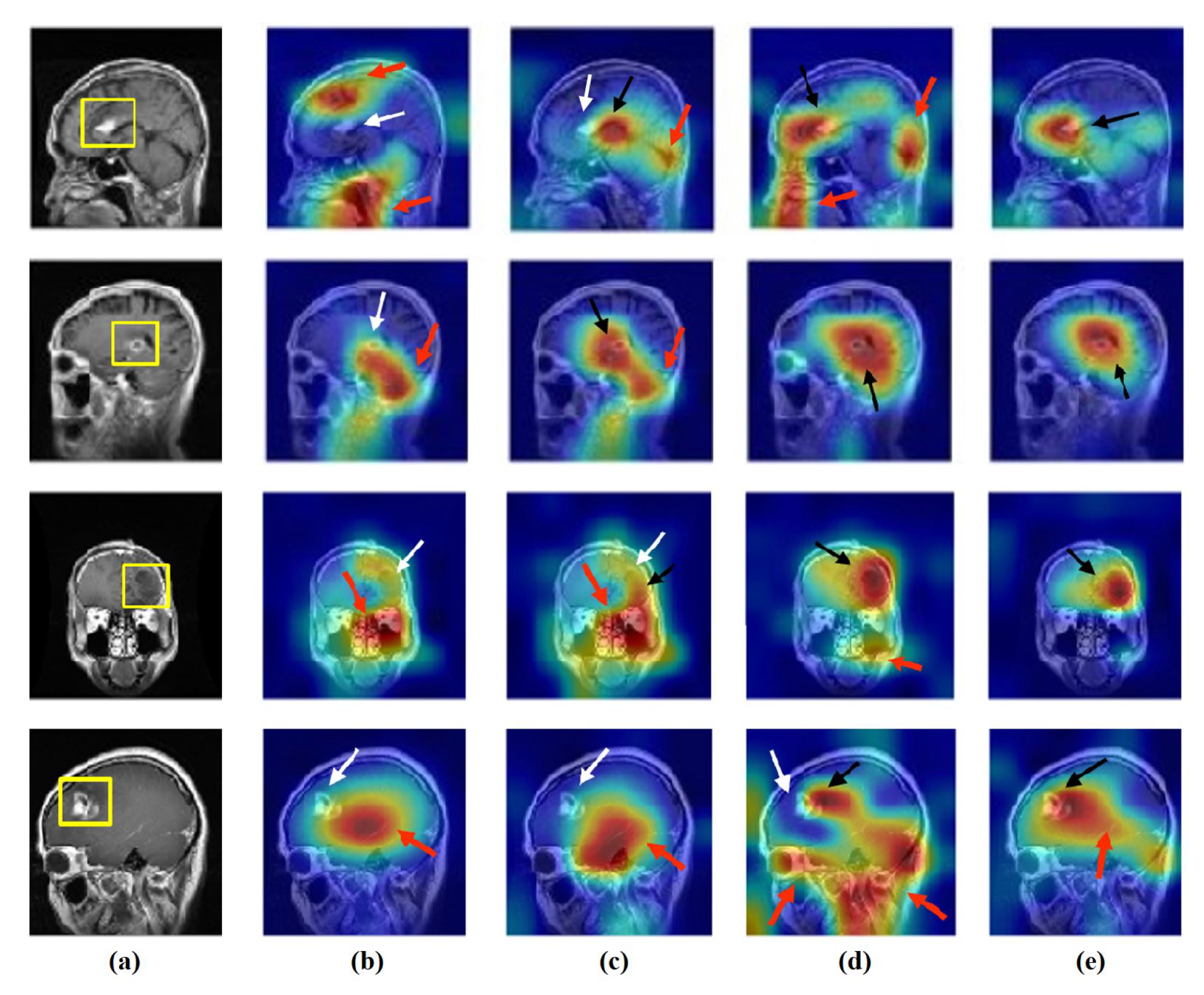
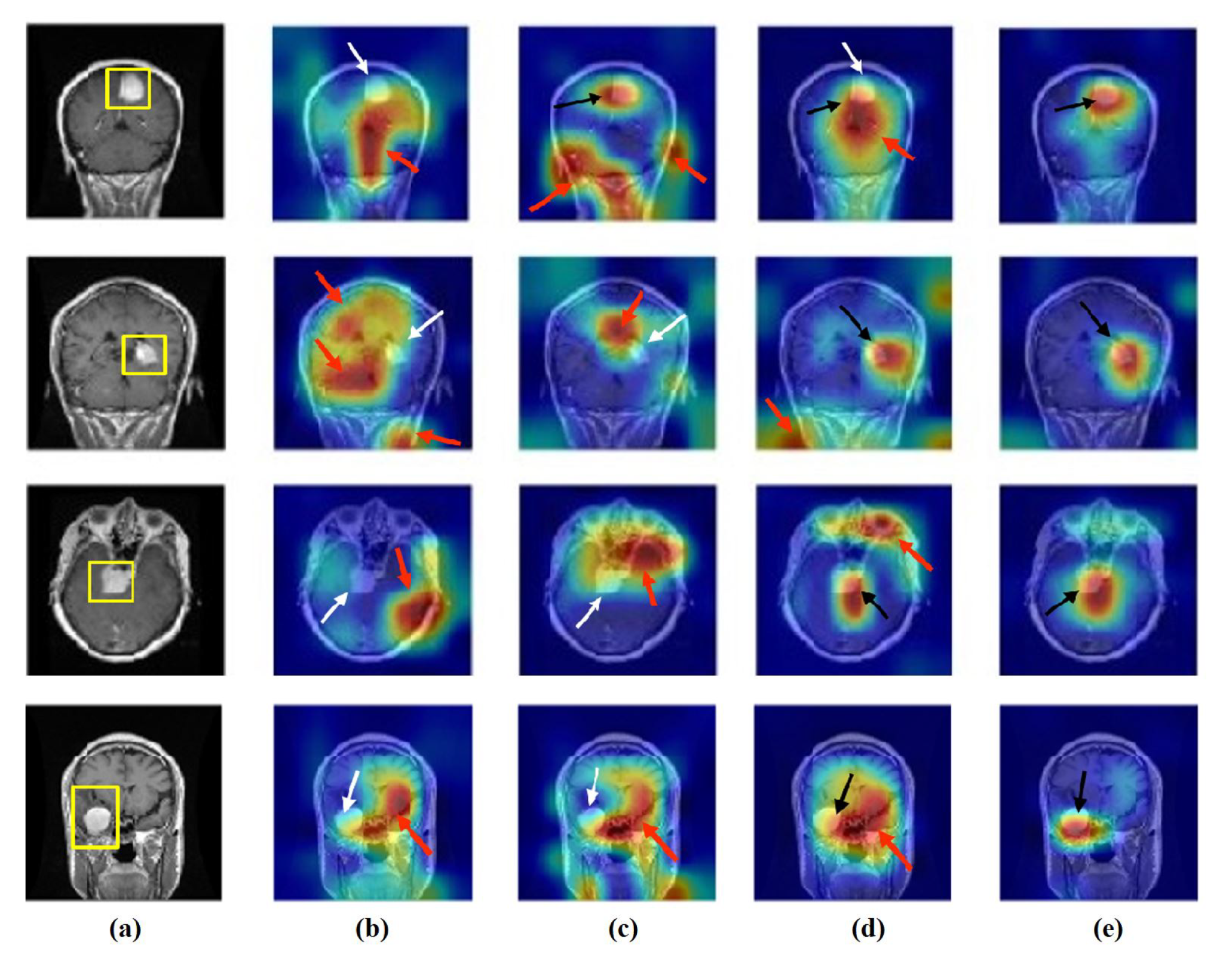
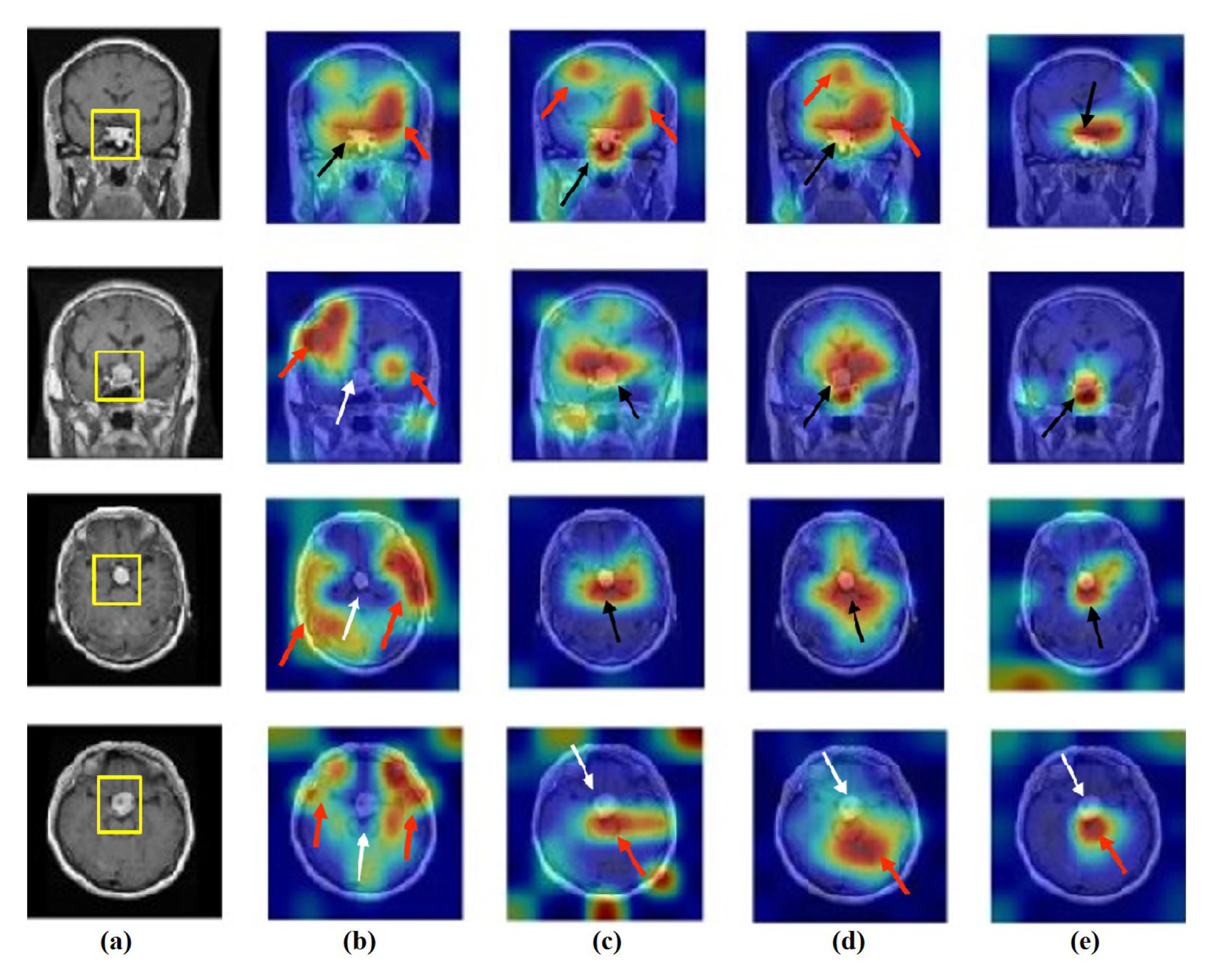
- Feature Visualisation: Explanation and demonstration of the speciality of features learned/transferred by XDecompo, we used the Grad-CAM algorithm [51] as one of the most efficient interpretation techniques for computer vision tasks. It estimates the location of particular patterns in the input image, which guides the prediction of the XDecompo model, and highlights the patterns through an activation heatmap [54]. Grad-CAM is a generalisation of CAM that does not require a particular CNN architecture, contrary to CAM which requires an architecture that applies global average pooling to the final convolutional feature maps.
4. Experimental Setup and Results
4.1. Datasets Description
- Colorectal cancer images dataset, the labelled and unlabelled datasets were used from [58]; from the NCT Biobank, (National Center for Tumor Diseases, Heidelberg, Germany), and the UMM pathology archive (University Medical Center Mannheim, Mannheim, Germany). The dataset “NCT-CRC-HE-100K” [58] was used as unlabelled samples. With a total of 100,000 samples of (CRC) and normal tissue, all images are 224 × 224 pixels at 0.5 microns per pixel, the dataset divides into nine classes: Adipose tissue, background, debris, tumour epithelium, smooth muscle, normal colon mucosa, cancer-associated stroma, mucus, and lymphocytes.
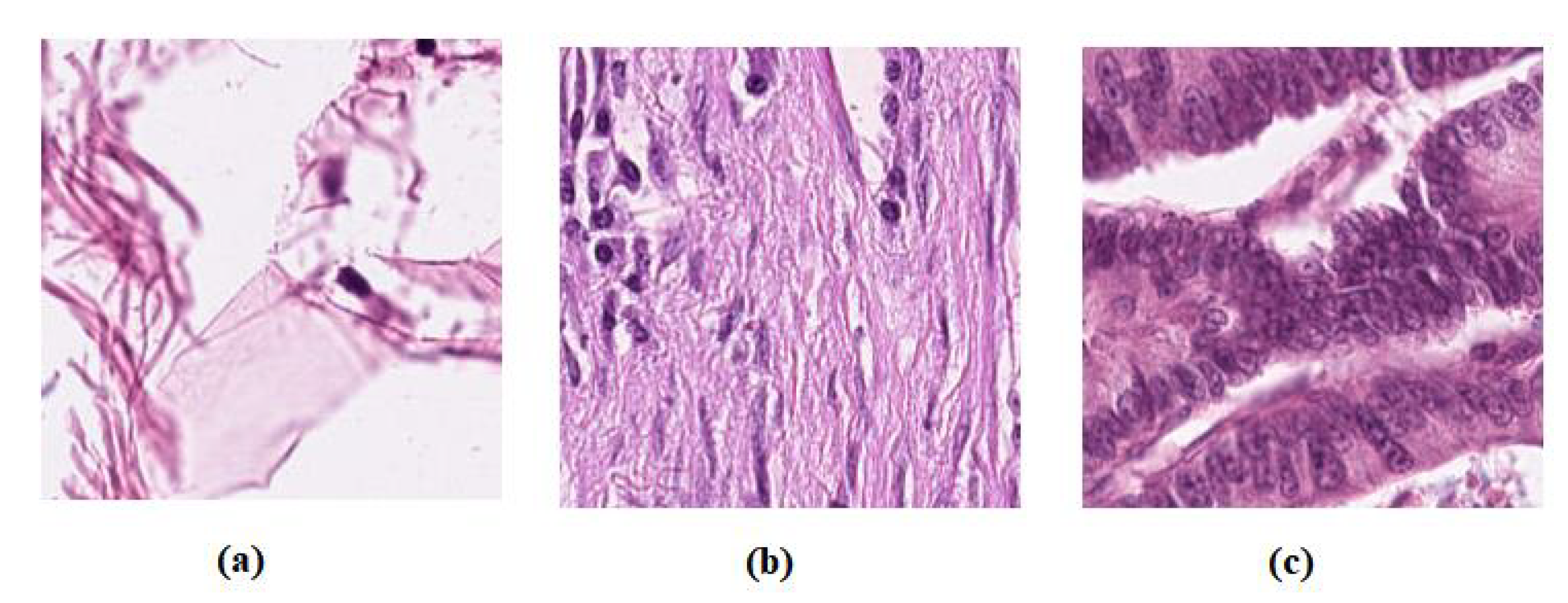
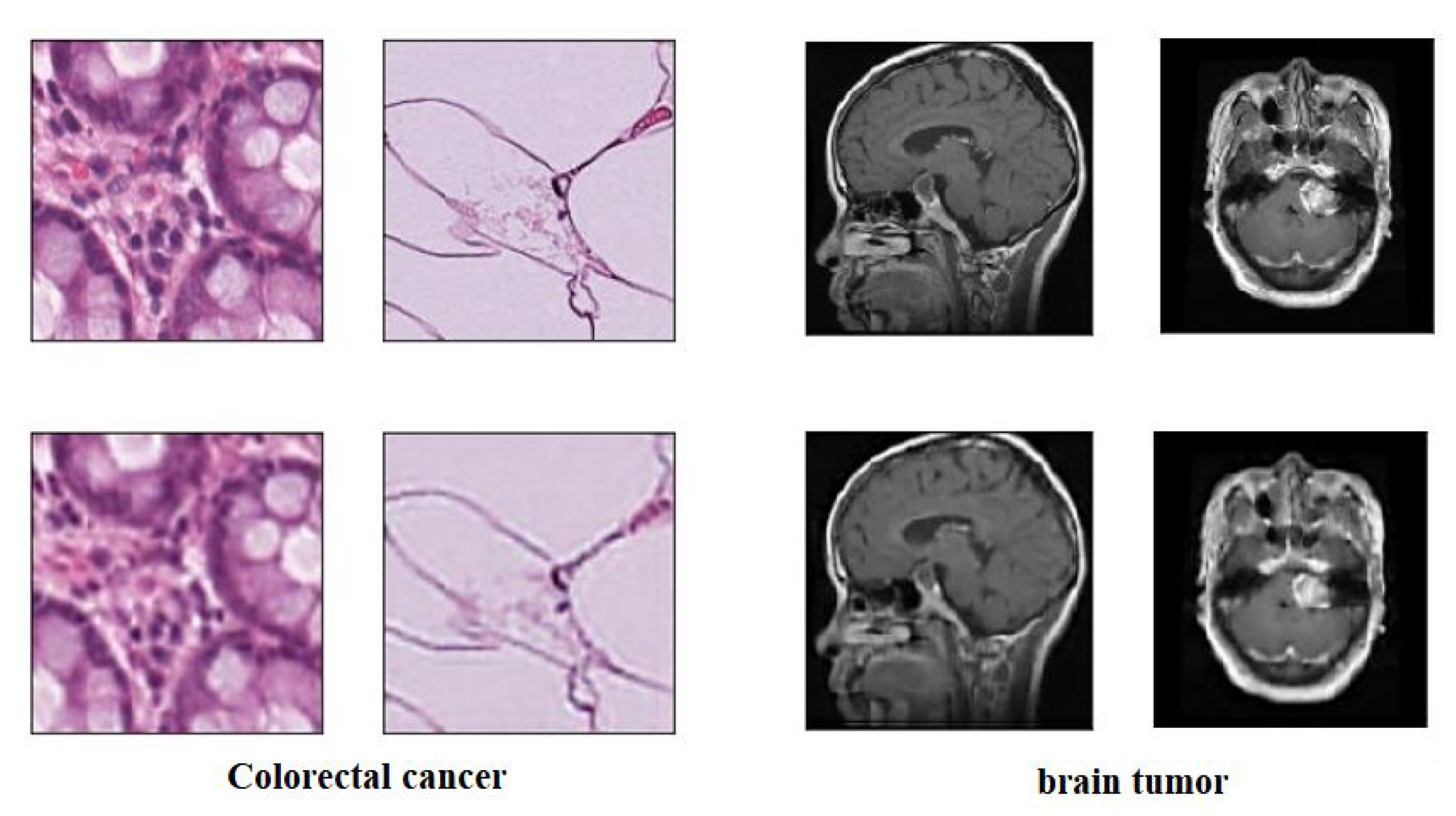
- The dataset “CRC-VAL-HE-7K” [58] was used as a labelled dataset, a set of 7180 image patches divided into nine unbalanced classes, and all images are 224 × 224 pixels at 0.5 microns per pixel. In our experiment, we only used three classes, Adipose (ADI), stroma (STR) and tumour epithelium (TUM), which contain 1338, 421, and 1233, respectively. Then, the dataseet was divided into three groups: 60% for training, 20% for validation, and 20% for testing, see Table 1. Figure 2 shows example images from the test set. Note that there is no overlap with the cases in the unlabelled images, NCT-CRC-HE-100K.
- Brain tumour images dataset, we have used a public brain tumour dataset as unlabelled samples that contains a total of 253 images and divided into two classes: 155 tumours and 98 without tumours. The dataset is available for download at: (https://www.kaggle.com/datasets/navoneel/brain-mri-images-for-brain-tumor-detection access on 14 November 2022). We applied many data-augmentation techniques to generate more samples in each class, such as reflection, shifting, wrapping, and rotation with various angles. This process resulted in 45,960 brain tumour images.
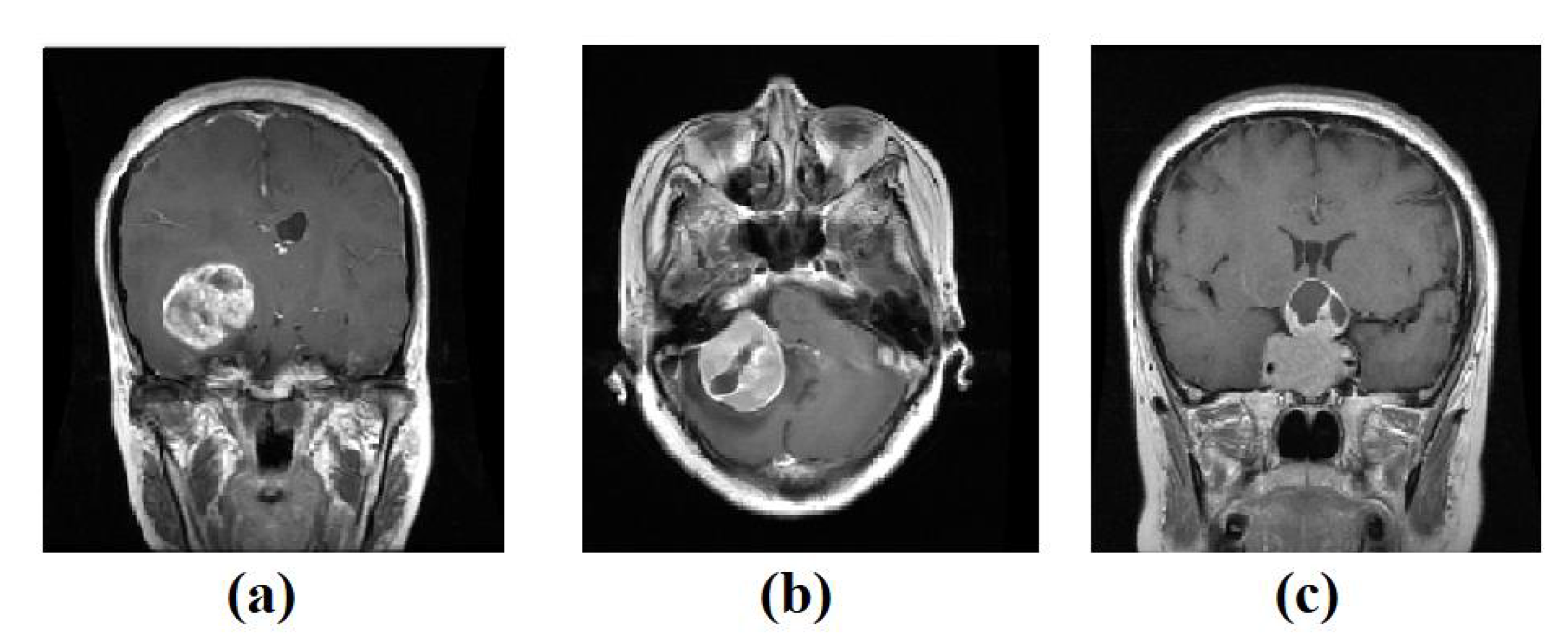
- For the labelled dataset, we have used a set of 3064 brain tumours from Nanfang and General Hospitals, Tianjin Medical University, China: 1426 glioma, 708 meningiomas, and 930 pituitary tumour, available from [59], all images with size 400 × 400 pixels. The training set was randomly divided into 60% to fit the model, 20% for validation, and 20% as a test set, see Table 2. Figure 3 shows examples of images from the test set.Table 1. The distribution of Colorectal cancer dataset.
Class Name Training Validate Test Total ADI 856 214 268 1338 STR 270 67 84 421 TUM 789 197 247 1233 Table 2. The distribution of Brain tumour dataset.Class Name Training Validation Test Total glioma 855 285 286 1426 meningioma 424 141 143 708 pituitary_tumour 558 186 186 930

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.2. Self-Supervised Training on Unlabelled Images
4.3. Downstream Class-Decomposition of 4S-DT and XDecompo
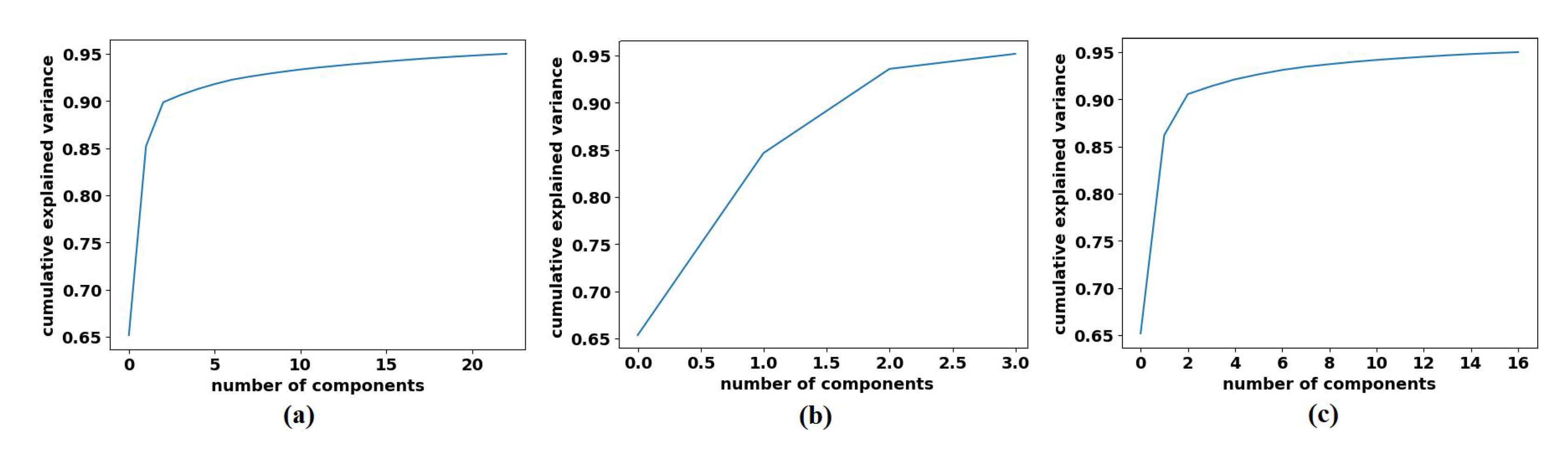
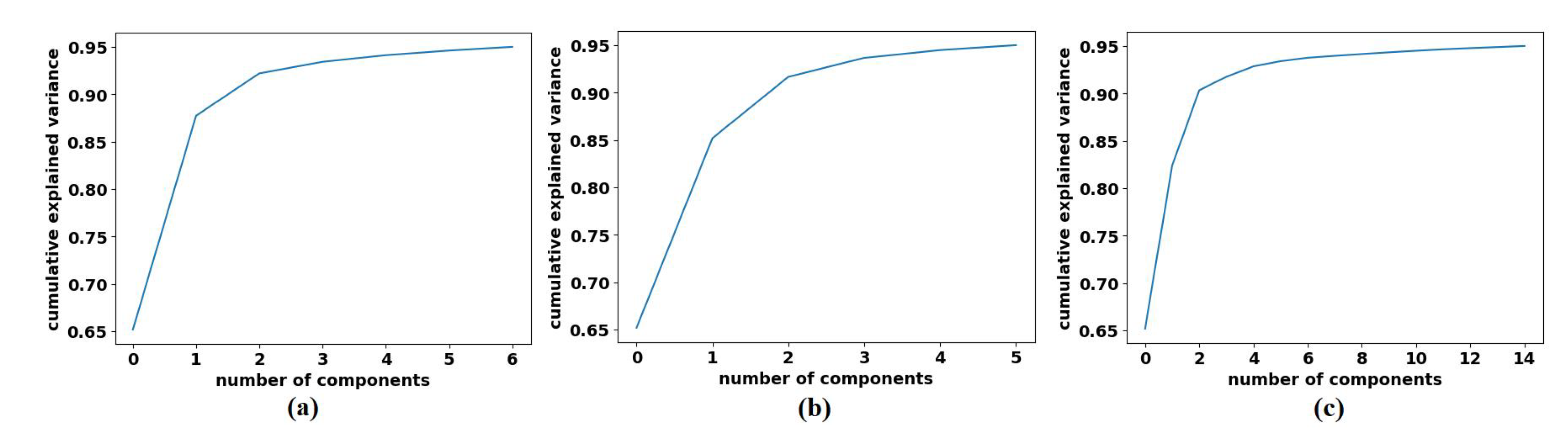
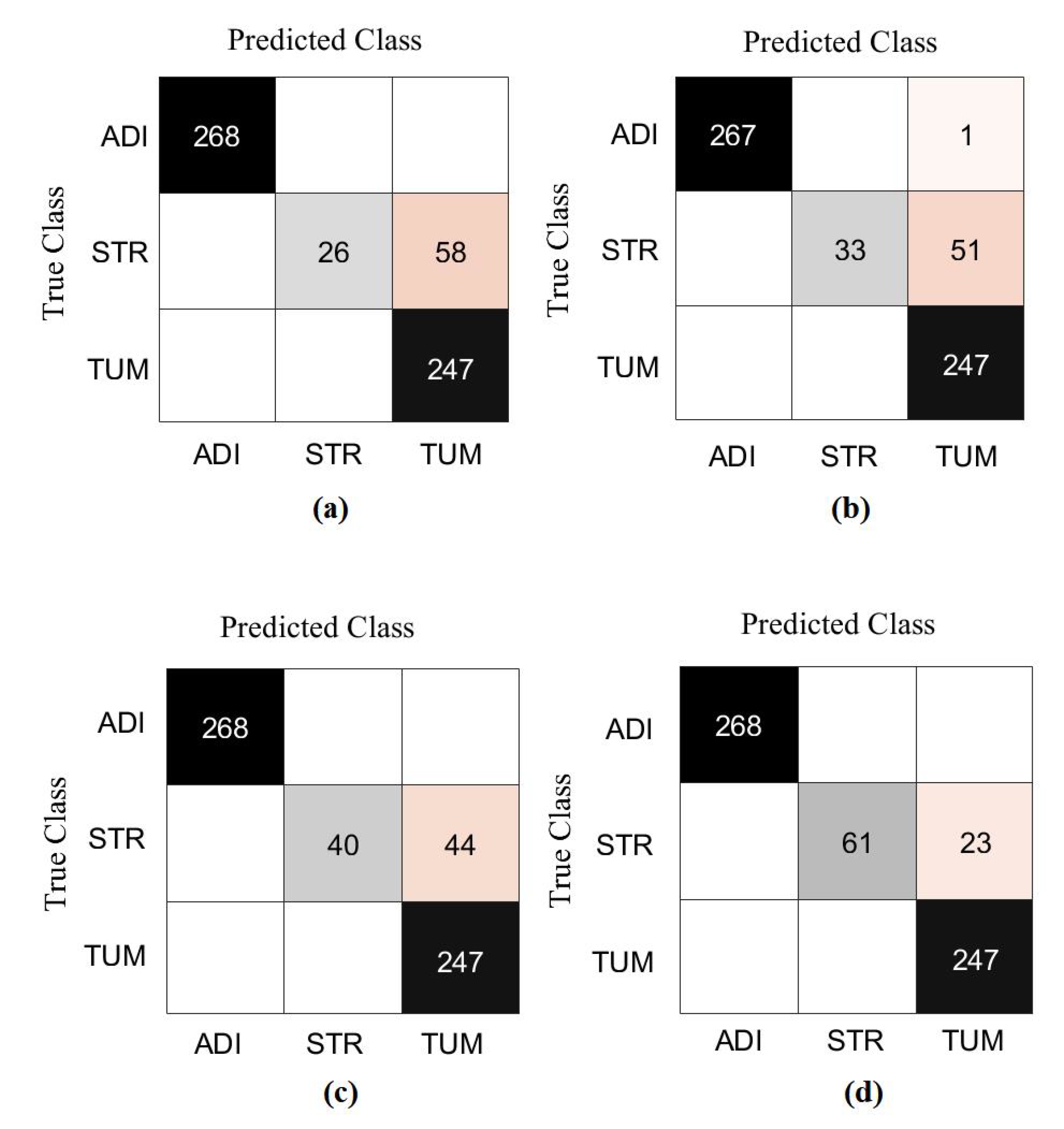
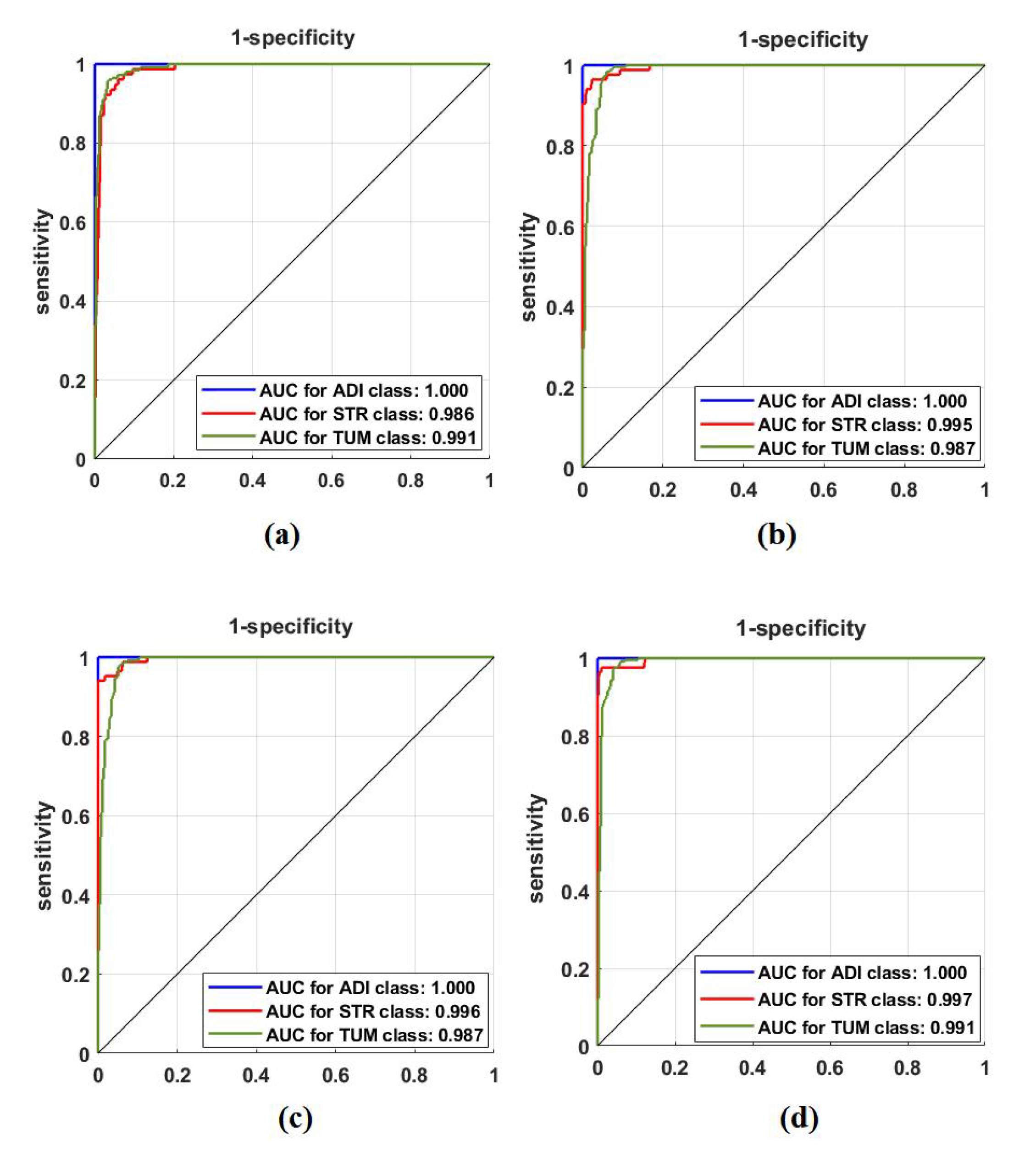
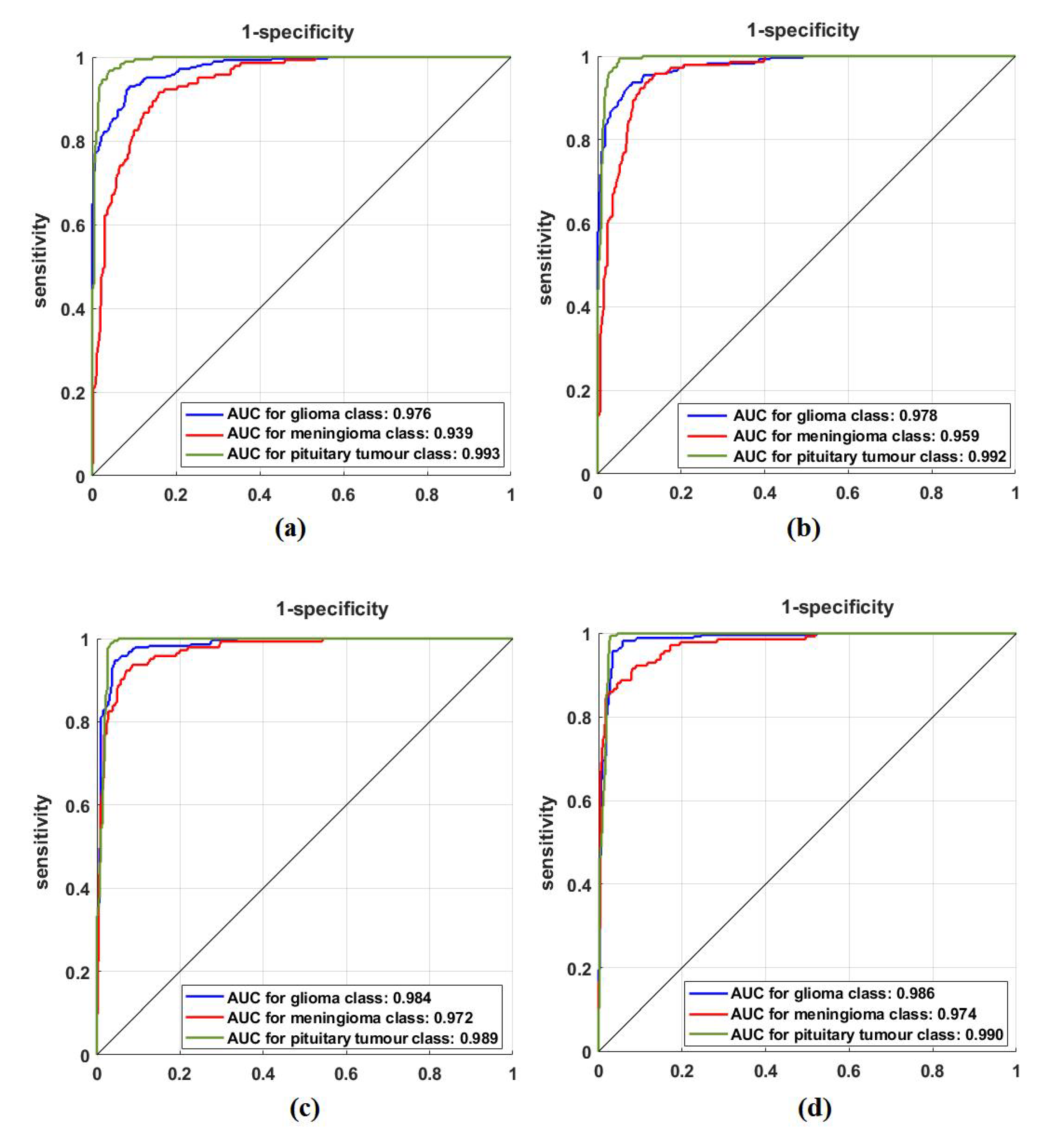
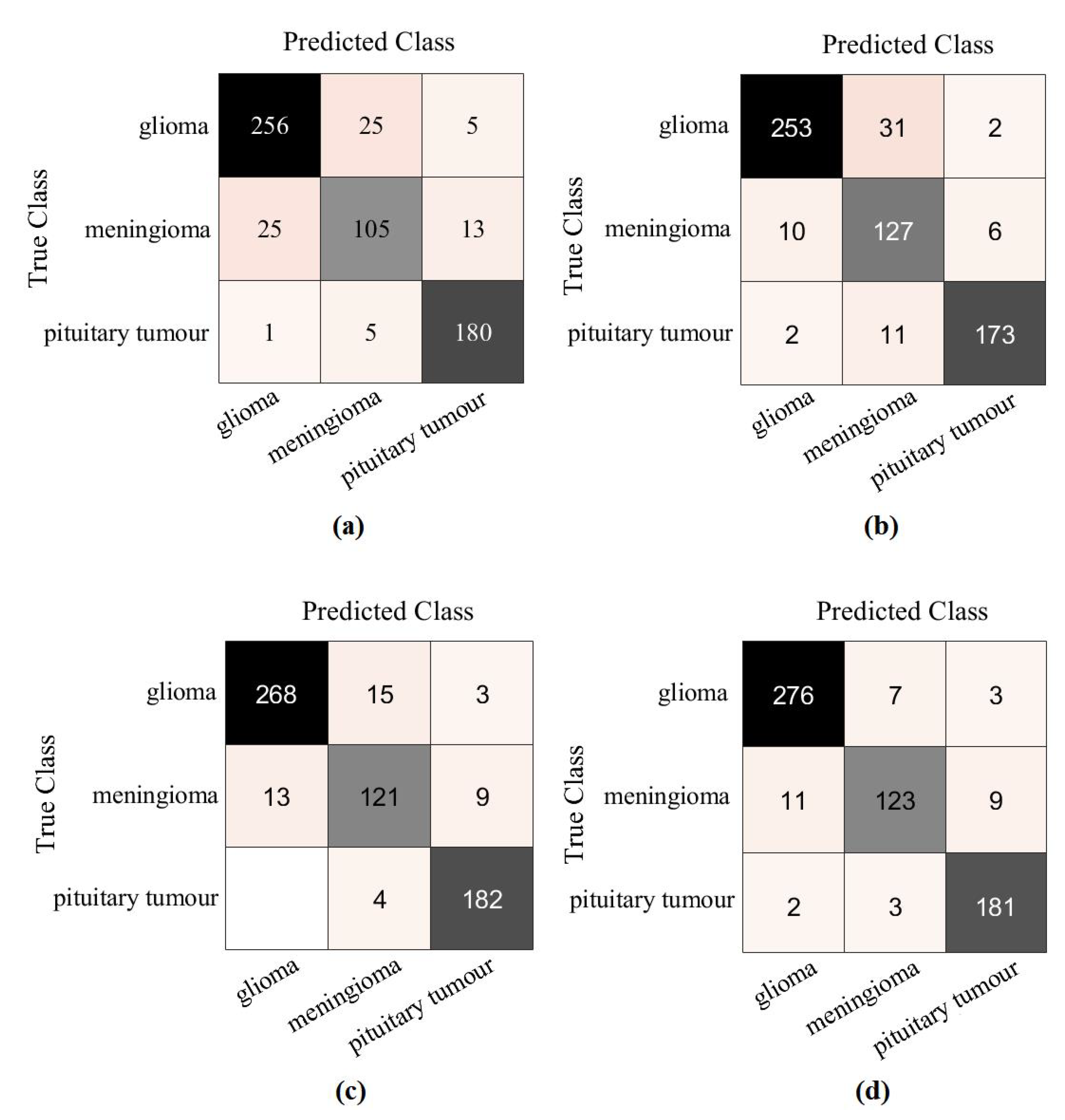
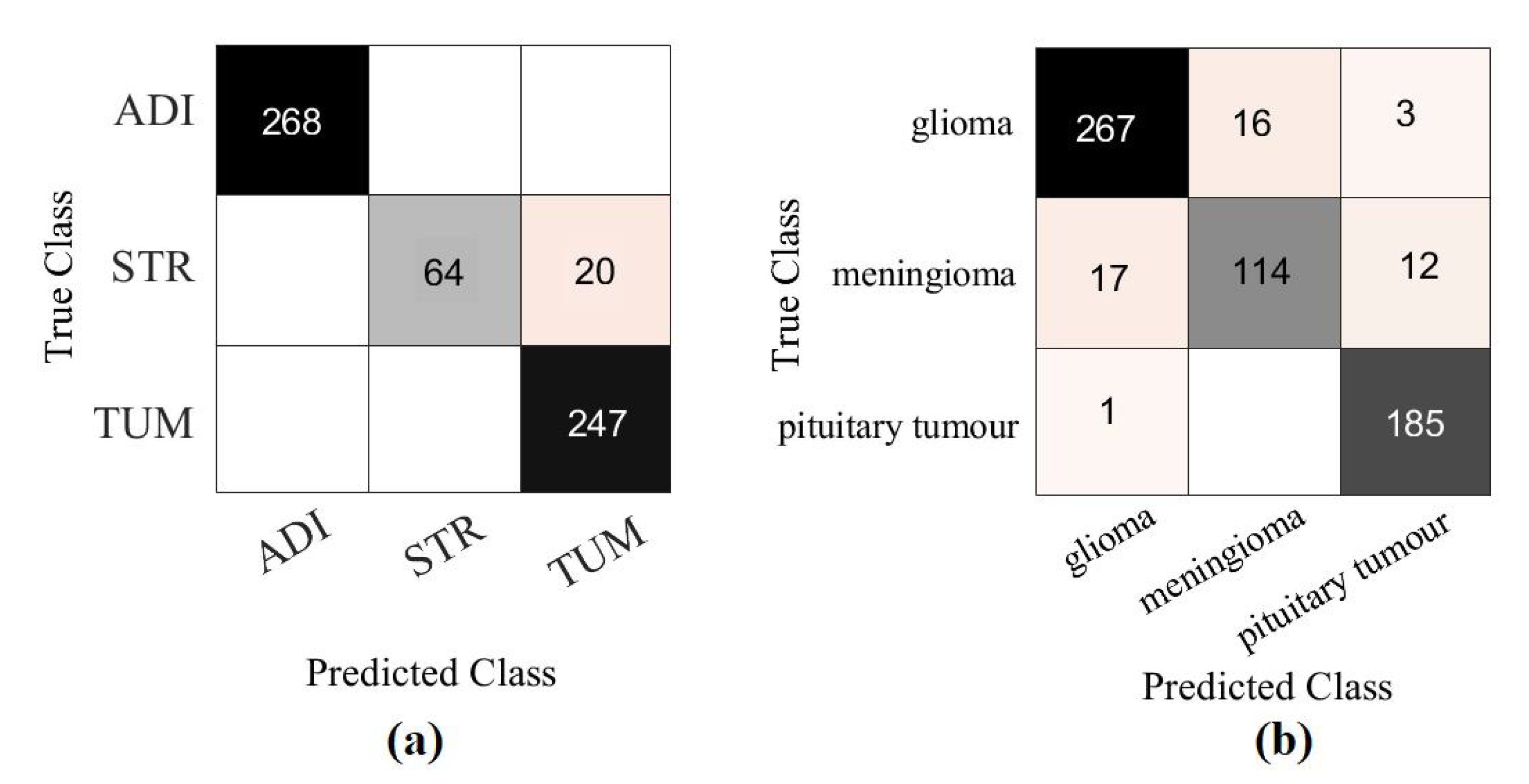
4.4. Classification Performance on CRC Dataset
4.5. Classification Performance on Brain Tumour Dataset
4.6. Feature Visualisation
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sirinukunwattana, K.; Raza, S.E.A.; Tsang, Y.W.; Snead, D.R.; Cree, I.A.; Rajpoot, N.M. Locality sensitive deep learning for detection and classification of nuclei in routine colon cancer histology images. IEEE Trans. Med. Imaging 2016, 35, 1196–1206. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, A.K.; Nandal, A.; Dhaka, A.; Koundal, D.; Bogatinoska, D.C.; Alyami, H. Enhanced watershed segmentation algorithm-based modified ResNet50 model for brain tumor detection. BioMed Res. Int. 2022, 2022, 7348344. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, S.A.; Raza, S.E.A.; Hussain, L.; Malibari, A.A.; Nour, M.K.; Rehman, A.U.; Al-Wesabi, F.N.; Hilal, A.M. Intelligent Ultra-Light Deep Learning Model for Multi-Class Brain Tumor Detection. Appl. Sci. 2022, 12, 3715. [Google Scholar] [CrossRef]
- Zadeh Shirazi, A.; Fornaciari, E.; McDonnell, M.D.; Yaghoobi, M.; Cevallos, Y.; Tello-Oquendo, L.; Inca, D.; Gomez, G.A. The application of deep convolutional neural networks to brain cancer images: A survey. J. Pers. Med. 2020, 10, 224. [Google Scholar] [CrossRef] [PubMed]
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep learning applications in medical image analysis. IEEE Access 2017, 6, 9375–9389. [Google Scholar] [CrossRef]
- Lundervold, A.S.; Lundervold, A. An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 2019, 29, 102–127. [Google Scholar] [CrossRef]
- Zahoor, M.M.; Qureshi, S.A.; Khan, A.; Rehman, A.u.; Rafique, M. A novel dual-channel brain tumor detection system for MR images using dynamic and static features with conventional machine learning techniques. Waves Random Complex Media 2022, 1–20. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Anwar, S.M.; Majid, M.; Qayyum, A.; Awais, M.; Alnowami, M.; Khan, M.K. Medical image analysis using convolutional neural networks: A review. J. Med. Syst. 2018, 42, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Al-Amidie, M.; Al-Asadi, A.; Humaidi, A.J.; Al-Shamma, O.; Fadhel, M.A.; Zhang, J.; Santamaría, J.; Duan, Y. Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data. Cancers 2021, 13, 1590. [Google Scholar] [CrossRef]
- Abbas, A.; Abdelsamea, M.M. Learning transformations for automated classification of manifestation of tuberculosis using convolutional neural network. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; pp. 122–126. [Google Scholar]
- Lu, J.; Behbood, V.; Hao, P.; Zuo, H.; Xue, S.; Zhang, G. Transfer learning using computational intelligence: A survey. Knowl.-Based Syst. 2015, 80, 14–23. [Google Scholar] [CrossRef]
- Delalleau, O.; Bengio, Y. Shallow vs. deep sum-product networks. Adv. Neural Inf. Process. Syst. 2011, 24, 14–23. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, high performance convolutional neural networks for image classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Abbas, A.; Abdelsamea, M.M.; Gaber, M.M. 4S-DT: Self-Supervised Super Sample Decomposition for Transfer Learning With Application to COVID-19 Detection. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2798–2808. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, E.; Uhl, A.; Häfner, M. Colonic polyp classification with convolutional neural networks. In Proceedings of the 2016 IEEE 29th International Symposium on Computer-Based Medical Systems (CBMS), Belfast and Dublin, Ireland, 20–24 June 2016; pp. 253–258. [Google Scholar]
- Haj-Hassan, H.; Chaddad, A.; Harkouss, Y.; Desrosiers, C.; Toews, M.; Tanougast, C. Classifications of multispectral colorectal cancer tissues using convolution neural network. J. Pathol. Inform. 2017, 8, 1. [Google Scholar] [CrossRef]
- Wang, W.; Tian, J.; Zhang, C.; Luo, Y.; Wang, X.; Li, J. An improved deep learning approach and its applications on colonic polyp images detection. BMC Med. Imaging 2020, 20, 1–14. [Google Scholar] [CrossRef]
- Ponzio, F.; Macii, E.; Ficarra, E.; Di Cataldo, S. Colorectal cancer classification using deep convolutional networks. In Proceedings of the 11th International Joint Conference on Biomedical Engineering Systems and Technologies, Funchal, Madeira, Portugal, 19 January 2018; Volume 2, pp. 58–66. [Google Scholar]
- Kokkalla, S.; Kakarla, J.; Venkateswarlu, I.B.; Singh, M. Three-class brain tumor classification using deep dense inception residual network. Soft Comput. 2021, 25, 8721–8729. [Google Scholar] [CrossRef]
- Deepak, S.; Ameer, P. Brain tumor classification using deep CNN features via transfer learning. Comput. Biol. Med. 2019, 111, 103345. [Google Scholar] [CrossRef] [PubMed]
- Alqudah, A.M.; Alquraan, H.; Qasmieh, I.A.; Alqudah, A.; Al-Sharu, W. Brain Tumor Classification Using Deep Learning Technique—A Comparison between Cropped, Uncropped, and Segmented Lesion Images with Different Sizes. arXiv 2020, arXiv:2001.08844. [Google Scholar] [CrossRef]
- Abd El Kader, I.; Xu, G.; Shuai, Z.; Saminu, S.; Javaid, I.; Salim Ahmad, I. Differential deep convolutional neural network model for brain tumor classification. Brain Sci. 2021, 11, 352. [Google Scholar] [CrossRef] [PubMed]
- Sajjad, M.; Khan, S.; Muhammad, K.; Wu, W.; Ullah, A.; Baik, S.W. Multi-grade brain tumor classification using deep CNN with extensive data augmentation. J. Comput. Sci. 2019, 30, 174–182. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Special issue on learning from imbalanced data sets. ACM Sigkdd Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Stefanowski, J. Overlapping, rare examples and class decomposition in learning classifiers from imbalanced data. In Emerging Paradigms in Machine Learning; Springer: Berlin/Heidelberg, Germany, 2013; pp. 277–306. [Google Scholar]
- Mugova, N.P.; Abdelsamea, M.M.; Gaber, M.M. On The Effect Of Decomposition Granularity On DeTraC For COVID-19 Detection Using Chest X-Ray Images. In Proceedings of the ECMS, Online, 31 May–2 June 2021; pp. 29–34. [Google Scholar]
- Abbas, A.; Abdelsamea, M.M.; Gaber, M.M. Detrac: Transfer learning of class decomposed medical images in convolutional neural networks. IEEE Access 2020, 8, 74901–74913. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef]
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Self-supervised learning for medical image analysis using image context restoration. Med. Image Anal. 2019, 58, 101539. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Gunning, D.; Stefik, M.; Choi, J.; Miller, T.; Stumpf, S.; Yang, G.Z. XAI—Explainable artificial intelligence. Sci. Robot. 2019, 4, eaay7120. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Oord, A.v.d.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1721–1730. [Google Scholar]
- Zintgraf, L.M.; Cohen, T.S.; Adel, T.; Welling, M. Visualizing deep neural network decisions: Prediction difference analysis. arXiv 2017, arXiv:1702.04595. [Google Scholar]
- Jetley, S.; Lord, N.A.; Lee, N.; Torr, P.H.S. Learn To Pay Attention. arXiv 2018, arXiv:1804.02391. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the kdd, Portland, OR, USA, 2 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Chen, M.; Shi, X.; Zhang, Y.; Wu, D.; Guizani, M. Deep features learning for medical image analysis with convolutional autoencoder neural network. IEEE Trans. Big Data 2017, 7, 750–758. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Abdelsamea, M.M.; Zidan, U.; Senousy, Z.; Gaber, M.M.; Rakha, E.; Ilyas, M. A survey on artificial intelligence in histopathology image analysis. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1474. [Google Scholar] [CrossRef]
- Macenko, M.; Niethammer, M.; Marron, J.S.; Borland, D.; Woosley, J.T.; Guan, X.; Schmitt, C.; Thomas, N.E. A method for normalizing histology slides for quantitative analysis. In Proceedings of the 2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Boston, MA, USA, 28 June–1 July 2009; pp. 1107–1110. [Google Scholar]
- Badža, M.M.; Barjaktarović, M.Č. Classification of brain tumors from MRI images using a convolutional neural network. Appl. Sci. 2020, 10, 1999. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dudani, S. The distance-weighted k-nearest neighbor rule. IEEE Trans. Syst. Man Cybern. 1978, 8, 311–313. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3 December 2012; pp. 1097–1105. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Philip, S.Y.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Peng, T.; Boxberg, M.; Weichert, W.; Navab, N.; Marr, C. Multi-task learning of a deep k-nearest neighbour network for histopathological image classification and retrieval. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–17 October 2019; Springer: Cham, Switzerland, 2019; pp. 676–684. [Google Scholar]
- Ghosh, S.; Bandyopadhyay, A.; Sahay, S.; Ghosh, R.; Kundu, I.; Santosh, K. Colorectal histology tumor detection using ensemble deep neural network. Eng. Appl. Artif. Intell. 2021, 100, 104202. [Google Scholar] [CrossRef]
- Li, X.; Jonnagaddala, J.; Cen, M.; Zhang, H.; Xu, S. Colorectal cancer survival prediction using deep distribution based multiple-instance learning. Entropy 2022, 24, 1669. [Google Scholar] [CrossRef]
- Kather, J.N.; Krisam, J.; Charoentong, P.; Luedde, T.; Herpel, E.; Weis, C.A.; Gaiser, T.; Marx, A.; Valous, N.A.; Ferber, D.; et al. Predicting survival from colorectal cancer histology slides using deep learning: A retrospective multicenter study. PLoS Med. 2019, 16, e1002730. [Google Scholar] [CrossRef]
- Abiwinanda, N.; Hanif, M.; Hesaputra, S.T.; Handayani, A.; Mengko, T.R. Brain tumor classification using convolutional neural network. In Proceedings of the World Congress on Medical Physics and Biomedical Engineering 2018, Prague, Czech Republic, 3–8 June 2018; Springer: Singapore, 2019; pp. 183–189. [Google Scholar]
- Cheng, J.; Huang, W.; Cao, S.; Yang, R.; Yang, W.; Yun, Z.; Wang, Z.; Feng, Q. Enhanced performance of brain tumor classification via tumor region augmentation and partition. PLoS ONE 2015, 10, e0140381. [Google Scholar] [CrossRef]
- Pashaei, A.; Sajedi, H.; Jazayeri, N. Brain Tumor Classification via Convolutional Neural Network and Extreme Learning Machines. In Proceedings of the 2018 8th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 25–26 October 2018; pp. 314–319. [Google Scholar] [CrossRef]
- Tazin, T.; Sarker, S.; Gupta, P.; Ayaz, F.I.; Islam, S.; Monirujjaman Khan, M.; Bourouis, S.; Idris, S.A.; Alshazly, H. A robust and novel approach for brain tumor classification using convolutional neural network. Comput. Intell. Neurosci. 2021, 2021, 2392395. [Google Scholar] [CrossRef]
- Afshar, P.; Plataniotis, K.N.; Mohammadi, A. Capsule networks for brain tumor classification based on MRI images and coarse tumor boundaries. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1368–1372. [Google Scholar]


















| Layer Name | ResNet-50 | Filter Size | Stride | Padding | # Filter |
|---|---|---|---|---|---|
| Conv5-1 | res5c- branch2a | 1 × 1 × 2048 | 1 | 0 | 512 |
| Conv5-2 | res5c- branch2b | 3 × 3 × 512 | 1 | 1 | 512 |
| Conv5-3 | res5c- branch2c | 1 × 1 × 512 | 1 | 0 | 2048 |
| FC | Fully Connected | 1 × 1 | - | - | 2048 |
| AE Model | Dataset | # Labels | ACC (%) | |
|---|---|---|---|---|
| SAE | Colorectal cancer | 4.5 | 8 | 75.80 |
| Brain tumour | 4.2 | 6 | 79.12 | |
| CAE | Colorectal cancer | 4 | 4 | 87.36 |
| Brain tumour | 2 | 3 | 92.79 |
| k-means clustering | Dataset A | ADI | STR | TUM | ||||||
| # instances | 1070 | 337 | 986 | |||||||
| Dataset B | ADI_1 | ADI_2 | STR_1 | STR_2 | TUM_1 | TUM_2 | ||||
| # instances | 666 | 404 | 171 | 166 | 406 | 580 | ||||
| AP clustering | Dataset B | ADI_1 | ADI_2 | ADI_3 | ADI_4 | STR_1 | STR_2 | TUM_1 | TUM_2 | TUM_3 |
| # instances | 377 | 270 | 222 | 201 | 171 | 166 | 381 | 371 | 234 | |
| data set B | ADI_1 | ADI_2 | ADI_3 | ADI_4 | STR_1 | STR_2 | TUM_1 | TUM_2 | TUM_3 | |
| # instances | 420 | 374 | 127 | 149 | 171 | 166 | 189 | 394 | 403 | |
| k-means clustering | Dataset A | glioma | meningioma | pituitary tumour | |||||
| # instances | 1140 | 565 | 744 | ||||||
| data set B | GLI_1 | GLI_2 | MEN_1 | MEN_2 | PIT_1 | PIT_2 | |||
| # instances | 577 | 563 | 298 | 267 | 426 | 318 | |||
| AP clustering | Dataset B | GLI-1 | GLI-2 | GLI-3 | MEN-1 | MEN-2 | PIT-1 | PIT-2 | PIT-3 |
| # instances | 455 | 529 | 156 | 290 | 275 | 214 | 322 | 208 | |
| Dataset B | GLI-1 | GLI-2 | GLI-3 | MEN-1 | MEN-2 | PIT-1 | PIT-2 | PIT-3 | |
| # instances | 547 | 308 | 285 | 298 | 267 | 311 | 313 | 120 | |
| Layer | ResNet-50 Pre-Trained | DeTraC | 4S-DT | XDecompo | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | SN | SP | ACC | SN | SP | ACC | SN | SP | ACC | SN | SP | |
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| FC | 90.81 | 78.17 | 94.79 | 91.48 | 80.34 | 95.17 | 92.82 | 82.93 | 95.92 | 95.49 | 89.28 | 97.44 |
| Conv5-3 | 90.65 | 77.67 | 94.69 | 92.15 | 81.34 | 95.54 | 92.32 | 81.74 | 95.64 | 94.82 | 87.97 | 97.06 |
| Conv5-2 | 90.65 | 77.67 | 94.69 | 91.65 | 80.51 | 95.26 | 92.98 | 83.33 | 96.02 | 94.99 | 88.36 | 97.15 |
| Conv5-1 | 90.31 | 76.98 | 94.50 | 91.31 | 79.63 | 95.07 | 92.65 | 82.54 | 95.83 | 96.16 | 90.87 | 97.82 |
| Layer | ResNet-50 Pre-Trained | DeTraC | 4S-DT | XDecompo | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | SN | SP | ACC | SN | SP | ACC | SN | SP | ACC | SN | SP | |
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| FC | 87.31 | 86.16 | 93.74 | 89.91 | 88.84 | 94.97 | 91.70 | 90.95 | 95.82 | 92.52 | 91.62 | 96.15 |
| Conv5-3 | 86.29 | 87.01 | 93.75 | 90.24 | 90.21 | 95.36 | 92.52 | 91.99 | 96.32 | 92.19 | 91.71 | 96.03 |
| Conv5-2 | 86.67 | 86.71 | 93.62 | 89.26 | 89.66 | 95.01 | 93.00 | 92.12 | 96.43 | 92.84 | 91.52 | 96.15 |
| Conv5-1 | 87.96 | 86.57 | 93.84 | 89.91 | 90.14 | 95.19 | 92.84 | 92.05 | 96.40 | 94.30 | 93.27 | 97.04 |
| Layer | CRC Dataset | Brain Tumour Dataset | ||||
|---|---|---|---|---|---|---|
| ACC | SN | SP | ACC | SN | SP | |
| (%) | (%) | (%) | (%) | (%) | (%) | |
| FC | 95.49 | 89.28 | 97.44 | 87.31 | 83.50 | 93.20 |
| Conv5-3 | 96.49 | 92.47 | 98.04 | 88.45 | 85.61 | 93.91 |
| Conv5-2 | 96.66 | 92.06 | 98.10 | 89.10 | 86.24 | 94.42 |
| Conv5-1 | 96.68 | 92.06 | 98.20 | 92.03 | 90.84 | 95.88 |
| Ref. | Method | ACC (%) |
|---|---|---|
| [64] | Multitask ResNet-50 | 95.0 |
| [64] | CNN-ResNet-50 | 93.60 |
| [65] | Ensemble DNN | 92.83 |
| [66] | CNN-Xception | 94.4 |
| [67] | CNN-VGG19 | 94.3 |
| XDecompo | 96.16 |
| Ref. | Method | ACC (%) |
|---|---|---|
| [68] | 7-layered CNN | 84.19 |
| [69] | BoW + SVM | 91.28 |
| [70] | CNN + KELM | 93.68 |
| [71] | CNN-transfer learning | 92.00 |
| [72] | CapsNet | 90.89 |
| XDecompo | 94.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, A.; Gaber, M.M.; Abdelsamea, M.M. XDecompo: Explainable Decomposition Approach in Convolutional Neural Networks for Tumour Image Classification. Sensors 2022, 22, 9875. https://doi.org/10.3390/s22249875
Abbas A, Gaber MM, Abdelsamea MM. XDecompo: Explainable Decomposition Approach in Convolutional Neural Networks for Tumour Image Classification. Sensors. 2022; 22(24):9875. https://doi.org/10.3390/s22249875
Chicago/Turabian StyleAbbas, Asmaa, Mohamed Medhat Gaber, and Mohammed M. Abdelsamea. 2022. "XDecompo: Explainable Decomposition Approach in Convolutional Neural Networks for Tumour Image Classification" Sensors 22, no. 24: 9875. https://doi.org/10.3390/s22249875