
Improved Agricultural Field Segmentation in Satellite Imagery Using TL-ResUNet Architecture
 , , , and
, , , and
Abstract
:1. Introduction
2. Related Works
3. Datasets
3.1. Labeled DeepGlobe Data
3.2. Defence Science and Technology Laboratory (Dstl) Dataset
3.3. LandCoverNet
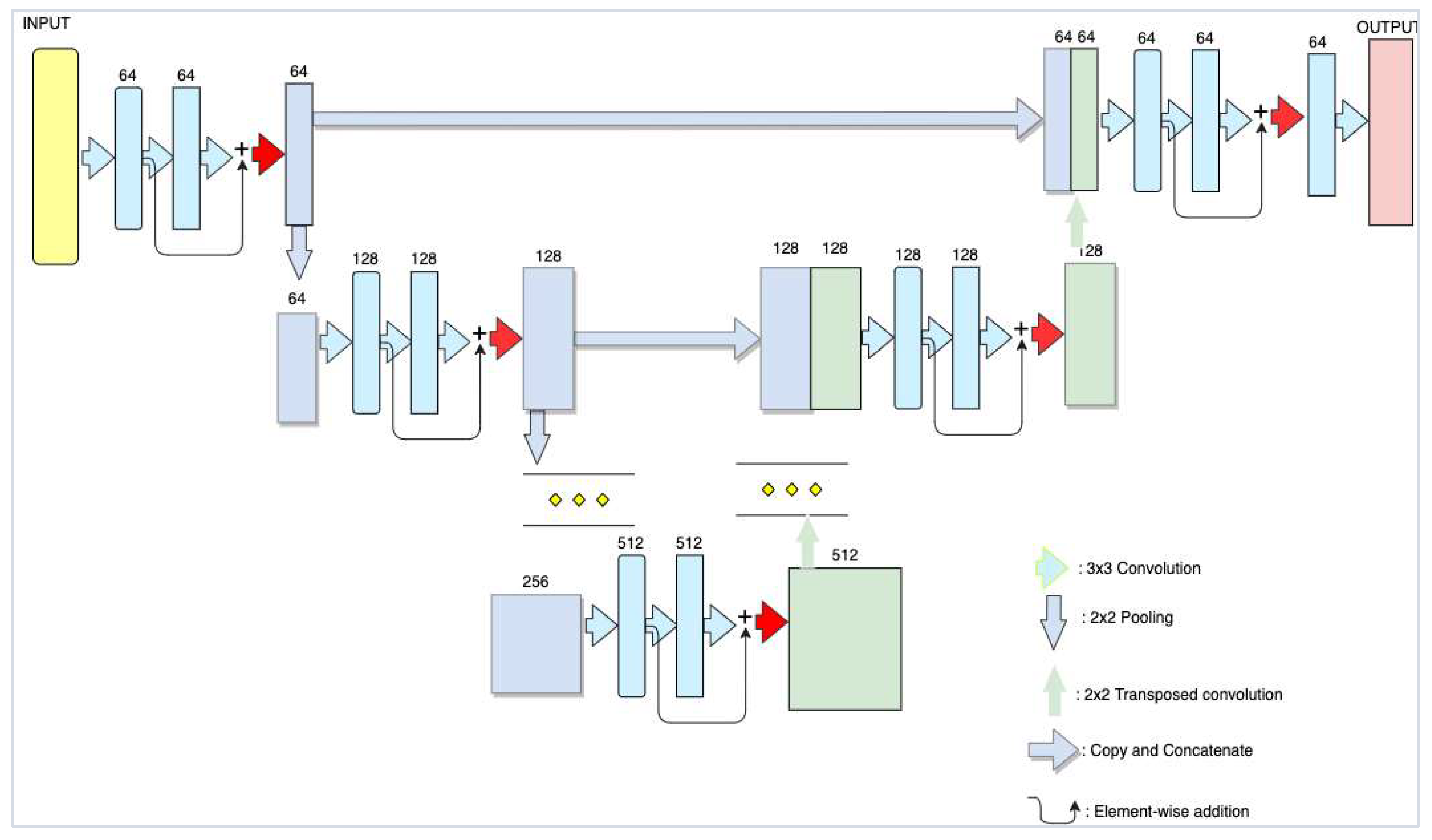
4. Proposed Architecture
4.1. Modified ResUNet Architecture
4.2. ResNet Architecture
4.3. Evaluation Metrics
4.4. Loss Functions
5. Experimental Results
5.1. Model Training
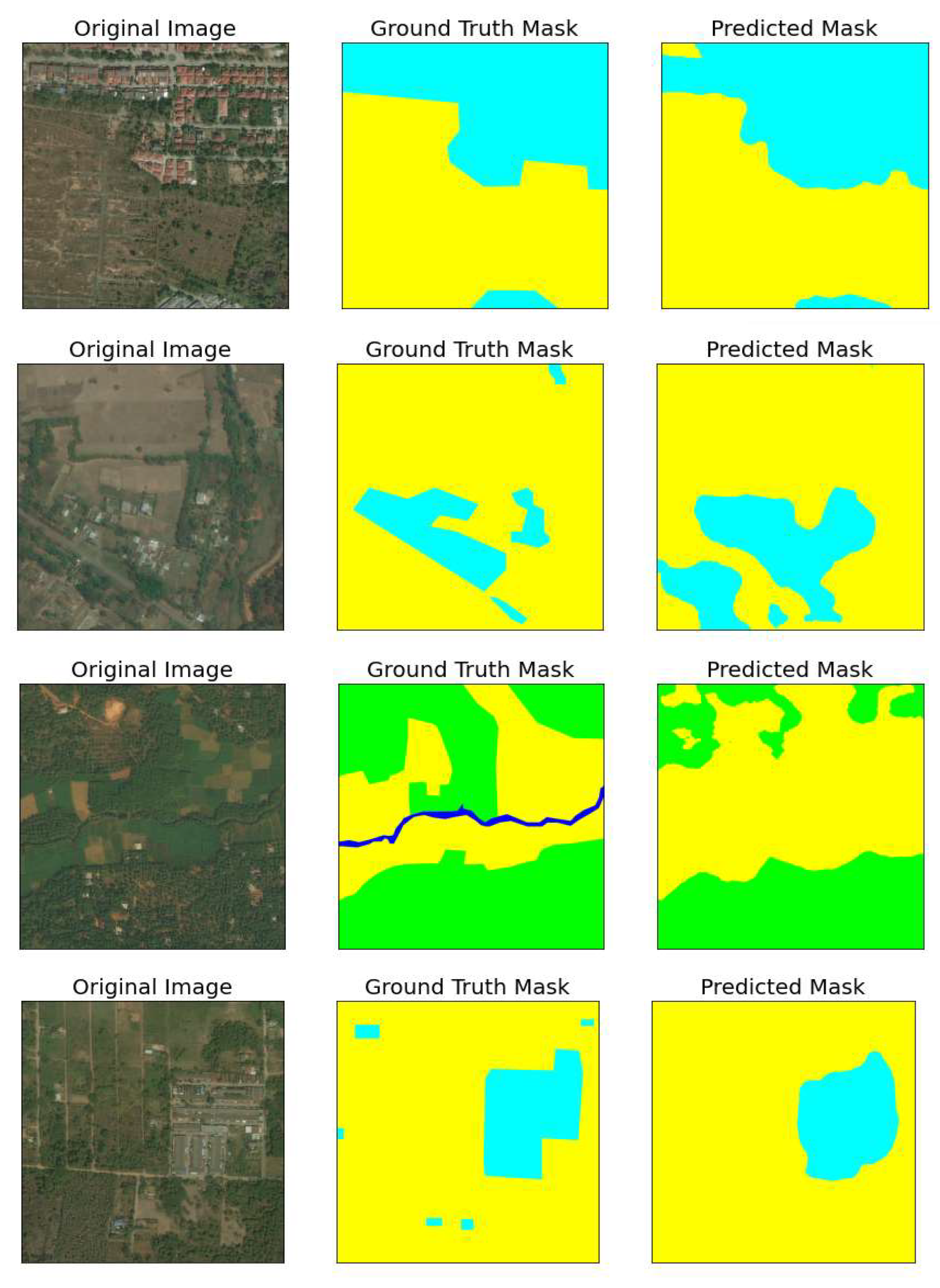
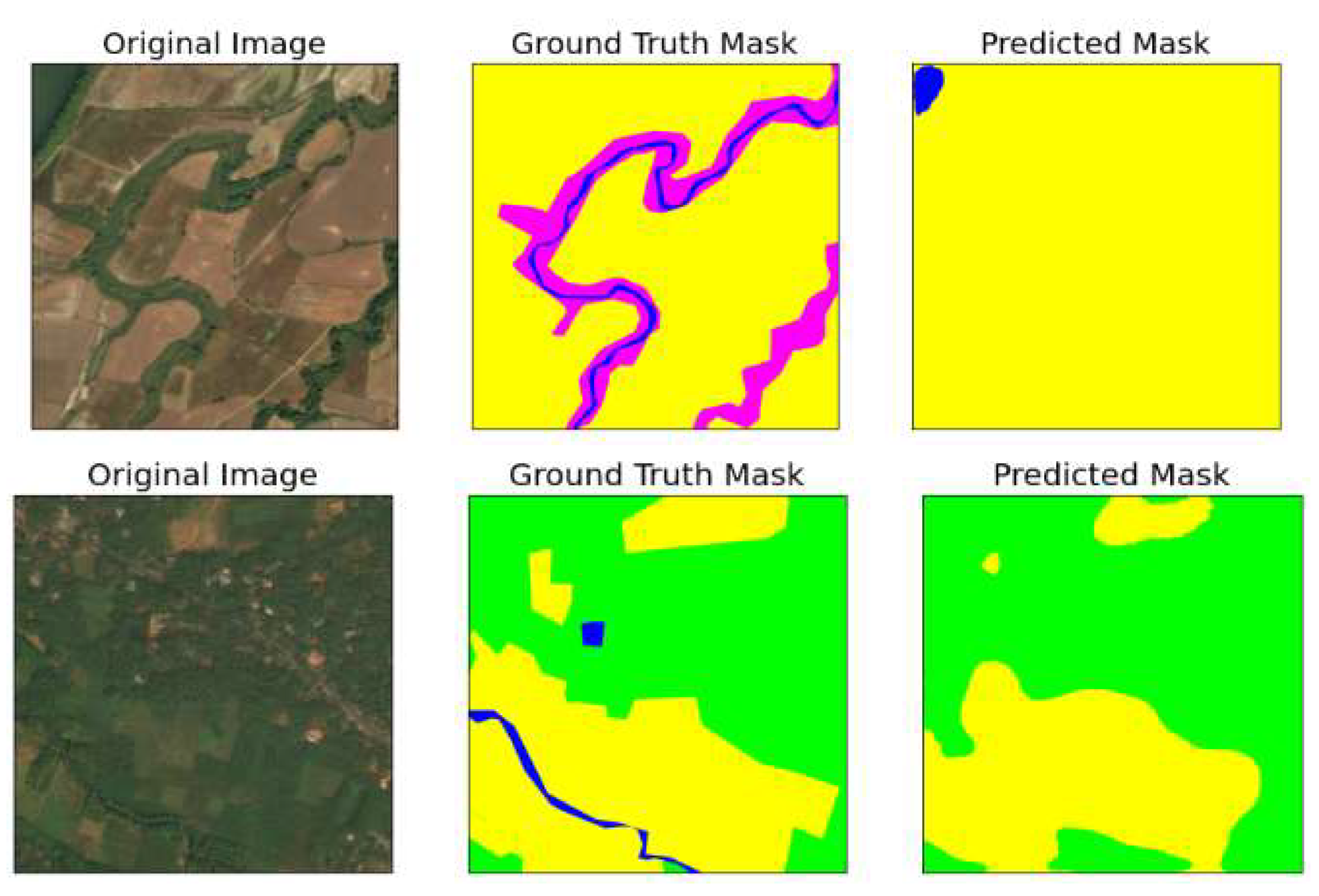
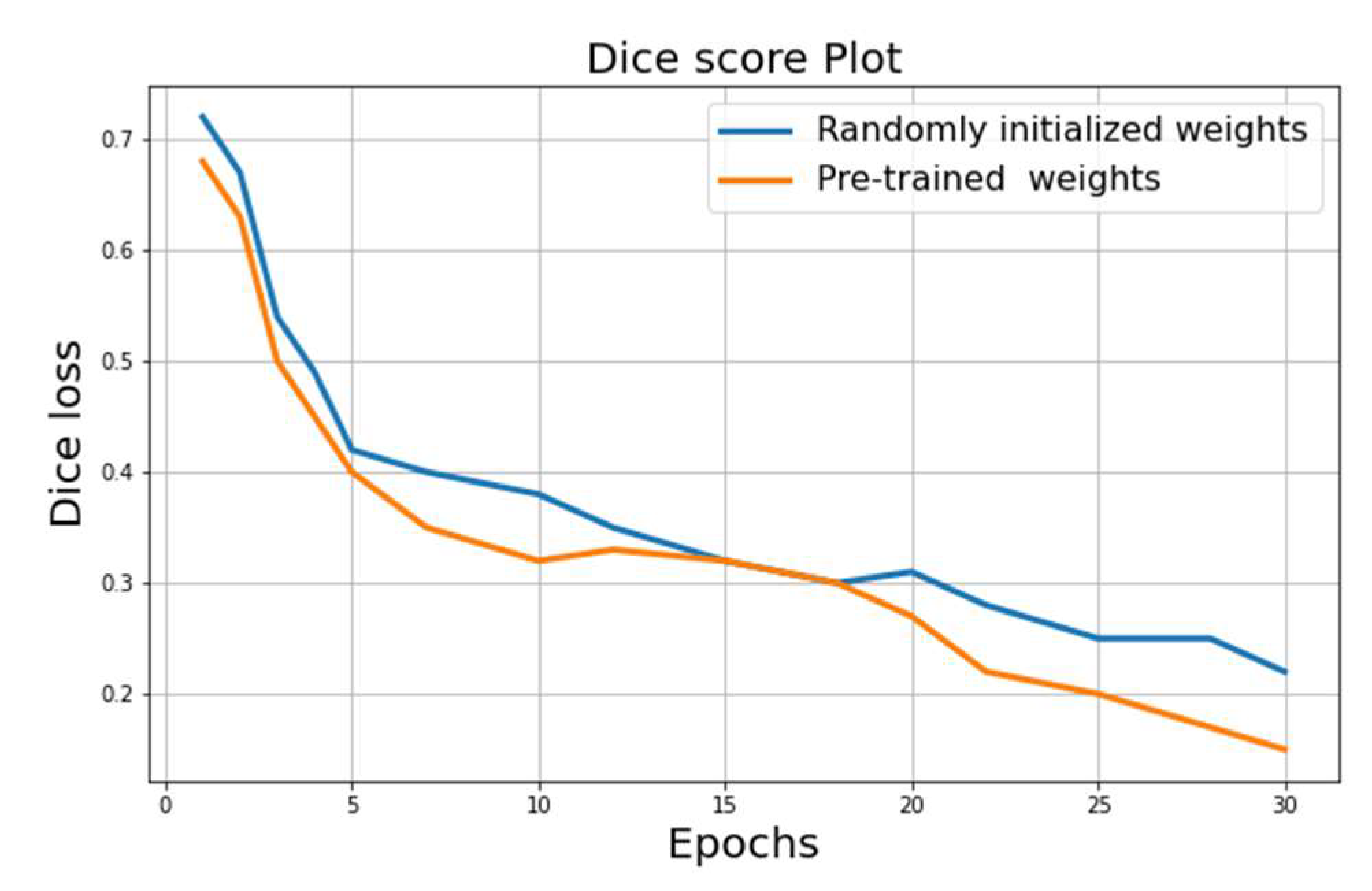
5.2. Results
- (1)
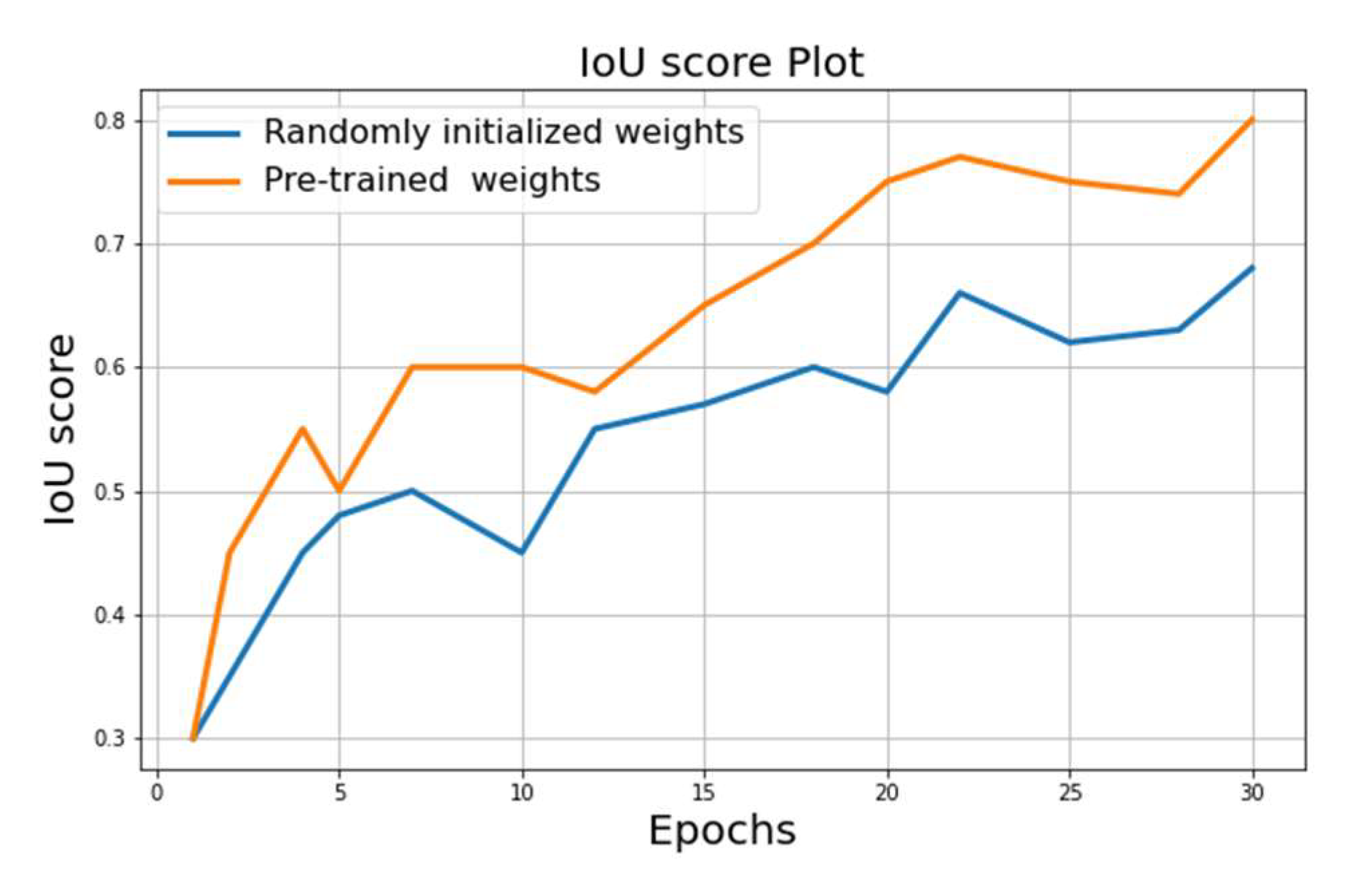
- Best score on randomly initialized weights: IoU = 0.68;
- (2)
- Best score on the encoder pre-trained weights on ImageNet: IoU = 0.81.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Shafaey, M.A.; Salem, M.A.M.; Ebied, H.M.; Al-Berry, M.N.; Tolba, M.F. Deep Learning for Satellite Image Classification; Springer: Berlin/Heidelberg, Germany, 2019; Volume 2019, pp. 383–391. [Google Scholar]
- Alias, B.; Karthika, R.; Parameswaran, L. Classification of high resolution remote sensing images using deep learning techniques. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore Karnataka, India, 19–22 September 2018. [Google Scholar]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Irons, J.R.; Dwyer, J.L.; Barsi, J.A. The next Landsat satellite: The Landsat Data Continuity Mission. Remote Sens. Environ. 2012, 122, 11–21. [Google Scholar] [CrossRef] [Green Version]
- Johnson, K.; Koperski, K. WorldView-3 SWIR land use-land cover mineral classification: Cuprite, Nevada. Remote Sens. GIS 2017. Available online: https://www.researchgate.net/project/Remote-Sensing-and-GIS-4 (accessed on 22 July 2022).
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land–Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Musaev, M.; Khujayorov, I.; Ochilov, M. Image Approach to Speech Recognition on CNN. In Proceedings of the 2019 3rd International Symposium on Computer Science and Intelligent Control (ISCSIC 2019), Amsterdam, The Netherlands, 25–27 September 2019; Article 57. pp. 1–6. [Google Scholar] [CrossRef]
- Mukhamadiyev, A.; Khujayarov, I.; Djuraev, O.; Cho, J. Automatic Speech Recognition Method Based on Deep Learning Approaches for Uzbek Language. Sensors 2022, 22, 3683. [Google Scholar] [CrossRef] [PubMed]
- Valikhujaev, Y.; Abdusalomov, A.; Cho, Y. Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Kuchkorov, T.A.; Urmanov, S.N.; Nosirov, K.K.; Kyamakya, K. Perspectives of deep learning based satellite imagery analysis and efficient training of the U-Net architecture for land-use classification. In World Scientific Proceedings Series on Computer Engineering and Information Science, Developments of Artificial Intelligence Technologies in Computation and Robotics; World Scientific: Singapore, 2020; pp. 1041–1048. [Google Scholar]
- Bengana, N.; Heikkilä, J. Improving land cover segmentation across satellites using domain adaptation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1399–1410. [Google Scholar] [CrossRef]
- Tian, C.; Li, C.; Shi, J. Dense fusion classmate network for land cover classification. In Proceedings of the IEEE/CVF Conference on Computing and Vision Pattern Recognition Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; p. 262. [Google Scholar]
- Chhor, G.; Aramburu, C.B.; Bougdal-Lambert, I. Satellite Image Segmentation for Building Detection using U-net. Comput. Sci. Semant. Sch. 2017, 15, 114–120. [Google Scholar]
- Karwowska, K.; Wierzbicki, D. Improving Spatial Resolution of Satellite Imagery Using Generative Adversarial Networks and Window Functions. Remote Sens. 2022, 14, 6285. [Google Scholar] [CrossRef]
- Wafa, R.; Khan, M.Q.; Malik, F.; Abdusalomov, A.B.; Cho, Y.I.; Odarchenko, R. The Impact of Agile Methodology on Project Success, with a Moderating Role of Person’s Job Fit in the IT Industry of Pakistan. Appl. Sci. 2022, 12, 10698. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Mukhiddinov, M.; Djuraev, O.; Khamdamov, U.; Whangbo, T.K. Automatic Salient Object Extraction Based on Locally Adaptive Thresholding to Generate Tactile Graphics. Appl. Sci. 2020, 10, 3350. [Google Scholar] [CrossRef]
- Sevak, J.S.; Kapadia, A.D.; Chavda, J.B.; Shah, A.; Rahevar, M. Survey on semantic image segmentation techniques. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 306–313. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computing and Vision Pattern Recognition 2017, Honolulu, HI, USA, 21–26 June 2017; pp. 2261–2269. [Google Scholar]
- Kuo, T.S.; Tseng, K.S.; Yan, J.; Liu, Y.C.; Wang, Y.C.F. Deep aggregation net for land cover classification. In Proceedings of the IEEE/CVF Conference on Computing and Vision Pattern Recognition Workshops 2018, Salt Lake City, UT, USA, 18–22 June 2018; p. 247. [Google Scholar]
- Su, R.; Chen, R. Land cover change detection via semantic segmentation. arXiv 2019, arXiv:1911.12903. [Google Scholar]
- Lee, S.; Park, S.; Son, S.; Han, J.; Kim, S.; Kim, J. Land cover segmentation of aerial imagery using SegNet. Earth Resour. Environ. Remote Sens./GIS Appl. X. SPIE 2019, 11156, 313–318. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ulmas, P.; Liiv, I. Segmentation of satellite imagery using U-net models for land cover classification. arXiv 2020, arXiv:2003.02899. [Google Scholar]
- Sharifzadeh, S.; Tata, J.; Sharifzadeh, H.; Tan, B. Farm Area Segmentation in Satellite Images Using DeepLabv3+ Neural Networks. In Data Management Technologies and Applications, DATA 2019; Hammoudi, S., Quix, C., Bernardino, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1255. [Google Scholar] [CrossRef]
- Kutlimuratov, A.; Abdusalomov, A.; Whangbo, T.K. Evolving Hierarchical and Tag Information via the Deeply Enhanced Weighted Non-Negative Matrix Factorization of Rating Predictions. Symmetry 2020, 12, 1930. [Google Scholar] [CrossRef]
- Sertel, E.; Ekim, B.; Osgouei, P.E.; Kabadayi, M.E. Land Use and Land Cover Mapping Using Deep Learning Based Segmentation Approaches and VHR Worldview-3 Images. Remote Sens. 2022, 14, 4558. [Google Scholar] [CrossRef]
- Nivaggioli, A.; Randrianarivo, H. Weakly Supervised Semantic Segmentation of Satellite Images. Clinical Orthopaedics and Related Research. 2019. Available online: http://arxiv.org/abs/1904.03983 (accessed on 22 July 2022).
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly Supervised Deep Learning for Segmentation of Remote Sensing Imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Dstl Satellite Imagery Feature Detection. Available online: https://www.kaggle.com/competitions/dstl-satellite-imagery-feature-detection/data (accessed on 22 July 2022).
- Li, Q.; Shi, Y.; Huang, X.; Zhu, X.X. Building Footprint Generation by Integrating Convolution Neural Network with Feature Pairwise Conditional Random Field (FPCRF). IEEE Trans. Geosci. Remote Sens. 2020, 58, 7502–7519. [Google Scholar] [CrossRef]
- Alemohammad, H.; Booth, K. LandCoverNet: A global benchmark land cover classification training dataset. arXiv 2020, arXiv:2012.03111. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Nodirov, J.; Abdusalomov, A.B.; Whangbo, T.K. Attention 3D U-Net with Multiple Skip Connections for Segmentation of Brain Tumor Images. Sensors 2022, 22, 6501. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computing and Vision Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kuchkorov, T.; Ochilov, T.; Gaybulloev, E.; Sobitova, N.; Ruzibaev, O. Agro-field Boundary Detection using Mask R-CNN from Satellite and Aerial Images. In Proceedings of the 2021 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 3–5 November 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Kuchkorov, T.; Urmanov, S.; Kuvvatova, M.; Anvarov, I. Satellite image formation and preprocessing methods. In Proceedings of the 2020 International Conference on Information Science and Communications Technologies (ICISCT), Sanya, China, 4–6 December 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K. An improvement for the foreground recognition method using shadow removal technique for indoor environments. Int. J. Wavelets Multiresolution Inf. Process. 2017, 15, 1750039. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K. Detection and Removal of Moving Object Shadows Using Geometry and Color Information for Indoor Video Streams. Appl. Sci. 2019, 9, 5165. [Google Scholar] [CrossRef] [Green Version]
- Farkhod, A.; Abdusalomov, A.; Makhmudov, F.; Cho, Y.I. LDA-Based Topic Modeling Sentiment Analysis Using Topic/Document/Sentence (TDS) Model. Appl. Sci. 2021, 11, 11091. [Google Scholar] [CrossRef]
- Fletcher, S.; Islam, Z. Comparing sets of patterns with the Jaccard index. Australas. J. Inf. Syst. 2018, 22, 220. [Google Scholar] [CrossRef] [Green Version]
- Jakhongir, N.; Abdusalomov, A.; Whangbo, T.K. 3D Volume Reconstruction from MRI Slices based on VTK. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2021; pp. 689–692. [Google Scholar] [CrossRef]
- Umirzakova, S.; Abdusalomov, A.; Whangbo, T.K. Fully Automatic Stroke Symptom Detection Method Based on Facial Features and Moving Hand Differences. In Proceedings of the 2019 International Symposium on Multimedia and Communication Technology (ISMAC), Quezon City, Philippines, 19–21 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Kutlimuratov, A.; Abdusalomov, A.B.; Oteniyazov, R.; Mirzakhalilov, S.; Whangbo, T.K. Modeling and Applying Implicit Dormant Features for Recommendation via Clustering and Deep Factorization. Sensors 2022, 22, 8224. [Google Scholar] [CrossRef]
- Ayvaz, U.; Gürüler, H.; Khan, F.; Ahmed, N.; Whangbo, T.; Abdusalomov, A. Automatic Speaker Recognition Using Mel-Frequency Cepstral Coefficients Through Machine Learning. CMC-Comput. Mater. Contin. 2022, 71, 5511–5521. [Google Scholar] [CrossRef]
- Makhmudov, F.; Mukhiddinov, M.; Abdusalomov, A.; Avazov, K.; Khamdamov, U.; Cho, Y.I. Improvement of the end-to-end scene text recognition method for “text-to-speech” conversion. Int. J. Wavelets Multiresolution Inf. Process. 2020, 18, 2050052. [Google Scholar] [CrossRef]
- Khamdamov, R.; Saliev, E.; Rakhmanov, K. Classification of crops by multispectral satellite images of sentinel 2 based on the analysis of vegetation signatures. J. Phys. Conf. Ser. 2020, 1441, 012143. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An Improvement of the Fire Detection and Classification Method Using YOLOv3 for Surveillance Systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef] [PubMed]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. Automatic Fire Detection and Notification System Based on Improved YOLOv4 for the Blind and Visually Impaired. Sensors 2022, 22, 3307. [Google Scholar] [CrossRef] [PubMed]
- Abdusalomov, A.B.; Mukhiddinov, M.; Kutlimuratov, A.; Whangbo, T.K. Improved Real-Time Fire Warning System Based on Advanced Technologies for Visually Impaired People. Sensors 2022, 22, 7305. [Google Scholar] [CrossRef] [PubMed]
- Abdusalomov, A.B.; Safarov, F.; Rakhimov, M.; Turaev, B.; Whangbo, T.K. Improved Feature Parameter Extraction from Speech Signals Using Machine Learning Algorithm. Sensors 2022, 22, 8122. [Google Scholar] [CrossRef]
- Khan, F.; Tarimer, I.; Alwageed, H.S.; Karadağ, B.C.; Fayaz, M.; Abdusalomov, A.B.; Cho, Y.-I. Effect of Feature Selection on the Accuracy of Music Popularity Classification Using Machine Learning Algorithms. Electronics 2022, 11, 3518. [Google Scholar] [CrossRef]
- Abdusalomov, A.; Whangbo, T.K.; Djuraev, O. A Review on various widely used shadow detection methods to identify a shadow from images. Int. J. Sci. Res. Publ. 2016, 6, 2250–3153. [Google Scholar]
- Akmalbek, A.; Djurayev, A. Robust shadow removal technique for improving image enhancement based on segmentation method. IOSR J. Electron. Commun. Eng. 2016, 11, 17–21. [Google Scholar]
- Farkhod, A.; Abdusalomov, A.B.; Mukhiddinov, M.; Cho, Y.-I. Development of Real-Time Landmark-Based Emotion Recognition CNN for Masked Faces. Sensors 2022, 22, 8704. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class/Color | Pixel Count | Proportion |
|---|---|---|
| Urban | 642.4 M | 9.35% |
| Agriculture | 3898.0 M | 56.76% |
| Rangeland | 701.1 M | 10.21% |
| Forest | 944.4 M | 13.75% |
| Water | 256.9 M | 3.74% |
| Barren | 421.8 M | 6.14% |
| Unknown | 3.0 M | 0.04% |
| Datasets | Number of Classes | Spatial Resolution | Number of Images |
|---|---|---|---|
| DeepGlobe | 7 | 1.24 m | 1146 |
| Dstl | 10 | 1.24 m | 57 |
| LandCoverNet | 7 | 10 m | 1980 |
| Augmented Images | 7 | - | 6517 |
| Total | - | - | 9700 |
| Epoch | Train/Validation | UNet Trained with Randomly Initialized Weights | UNet Trained with Weights Trained on ImageNet without Residual Layers | UNet Trained with Weights Trained on ImageNet |
|---|---|---|---|---|
| 10 | train | 0.51 | 0.52 | 0.54 |
| validation | 0.49 | 0.50 | 0.51 | |
| 20 | train | 0.59 | 0.62 | 0.69 |
| validation | 0.58 | 0.61 | 0.64 | |
| 30 | train | 0.68 | 0.75 | 0.84 |
| validation | 0.68 | 0.74 | 0.81 |
| Algorithms | IoU |
|---|---|
| Baseline | 55.19 |
| ClassmateNet | 69.87 |
| DFCNet | 71.31 |
| DeepLabv3 | 74.52 |
| DeepLabv3+ | 75.6 |
| TL-ResUNet | 81.0 |
| Criterion | DFCNet | DeepLabv3 | DeepLabv3+ | Proposed Method |
|---|---|---|---|---|
| Scene Independence | standard | robust | standard | robust |
| Object Independence | standard | robust | robust | standard |
| Robust to Noise | powerless | robust | standard | robust |
| Robust to Color | standard | standard | powerless | standard |
| Small Land Segmentation | robust | standard | robust | robust |
| Multiple Land Segmentation | standard | powerless | powerless | powerless |
| Processing Time | powerless | standard | robust | robust |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safarov, F.; Temurbek, K.; Jamoljon, D.; Temur, O.; Chedjou, J.C.; Abdusalomov, A.B.; Cho, Y.-I. Improved Agricultural Field Segmentation in Satellite Imagery Using TL-ResUNet Architecture. Sensors 2022, 22, 9784. https://doi.org/10.3390/s22249784
Safarov F, Temurbek K, Jamoljon D, Temur O, Chedjou JC, Abdusalomov AB, Cho Y-I. Improved Agricultural Field Segmentation in Satellite Imagery Using TL-ResUNet Architecture. Sensors. 2022; 22(24):9784. https://doi.org/10.3390/s22249784
Chicago/Turabian StyleSafarov, Furkat, Kuchkorov Temurbek, Djumanov Jamoljon, Ochilov Temur, Jean Chamberlain Chedjou, Akmalbek Bobomirzaevich Abdusalomov, and Young-Im Cho. 2022. "Improved Agricultural Field Segmentation in Satellite Imagery Using TL-ResUNet Architecture" Sensors 22, no. 24: 9784. https://doi.org/10.3390/s22249784