Author Contributions
Conceptualization, X.J.; methodology, X.J.; software, Y.Z.; validation, Y.Z.; data curation, Y.Z.; writing—original draft, Y.Z.; writing—review and editing, X.J., Y.G., Z.F. and H.F.; funding acquisition, Z.F. All authors have read and agreed to the published version of the manuscript.
Figure 1.
The estimated trajectories of sequences 09 and 10 from the KITTI Odometry dataset. We took the stride as four, that is, only one in every four frames was used for trajectory computing, to simulate fast moving. As shown, our model still worked well in fast-moving scenes.
Figure 1.
The estimated trajectories of sequences 09 and 10 from the KITTI Odometry dataset. We took the stride as four, that is, only one in every four frames was used for trajectory computing, to simulate fast moving. As shown, our model still worked well in fast-moving scenes.
Figure 2.
System overview. The FlowNet predicts optical flows between adjacent frames. Afterward, we use the forward–backward flow consistency score map to select the corresponding point pairs set, denoted as A. Meanwhile, another matching point pairs set B is created by the traditional key point extraction and matching algorithm. The AvgFlow estimation module judges how fast the scene motion is. Moreover, in the loss function of the optical flow network, the Euclidean distance between A and B is added as the supervisory signal.
Figure 2.
System overview. The FlowNet predicts optical flows between adjacent frames. Afterward, we use the forward–backward flow consistency score map to select the corresponding point pairs set, denoted as A. Meanwhile, another matching point pairs set B is created by the traditional key point extraction and matching algorithm. The AvgFlow estimation module judges how fast the scene motion is. Moreover, in the loss function of the optical flow network, the Euclidean distance between A and B is added as the supervisory signal.
Figure 3.
The yellow point has two corresponding points, that is, the red one and the purple one, generated by the traditional method and the flow network, respectively.
Figure 3.
The yellow point has two corresponding points, that is, the red one and the purple one, generated by the traditional method and the flow network, respectively.
Figure 4.
Coordinate mapping. Traditional matching is used as the benchmark, and matching point pairs are selected by coordinate mapping.
Figure 4.
Coordinate mapping. Traditional matching is used as the benchmark, and matching point pairs are selected by coordinate mapping.
Figure 5.
Number of matched corresponding point pairs using SURF+FLANN. As shown, when the movement gets faster (the larger the stride is), the number of found matches decreases.
Figure 5.
Number of matched corresponding point pairs using SURF+FLANN. As shown, when the movement gets faster (the larger the stride is), the number of found matches decreases.
Figure 6.
As the motion increases, the number of matches found by SURF+FLANN decreases from 353 to 50.
Figure 6.
As the motion increases, the number of matches found by SURF+FLANN decreases from 353 to 50.
Figure 7.
The left image shows the estimated trajectories in a normal-motion scene (stride = 1). The right image shows a small-amplitude-motion scene (stride = 2) of sequence 09 in the KITTI dataset.
Figure 7.
The left image shows the estimated trajectories in a normal-motion scene (stride = 1). The right image shows a small-amplitude-motion scene (stride = 2) of sequence 09 in the KITTI dataset.
Figure 8.
The upper image shows the estimated trajectories of a normal-motion scene (stride = 1). The lower image shows the results from a small-amplitude-motion scene (stride = 2) in sequence 10 of the KITTI dataset.
Figure 8.
The upper image shows the estimated trajectories of a normal-motion scene (stride = 1). The lower image shows the results from a small-amplitude-motion scene (stride = 2) in sequence 10 of the KITTI dataset.
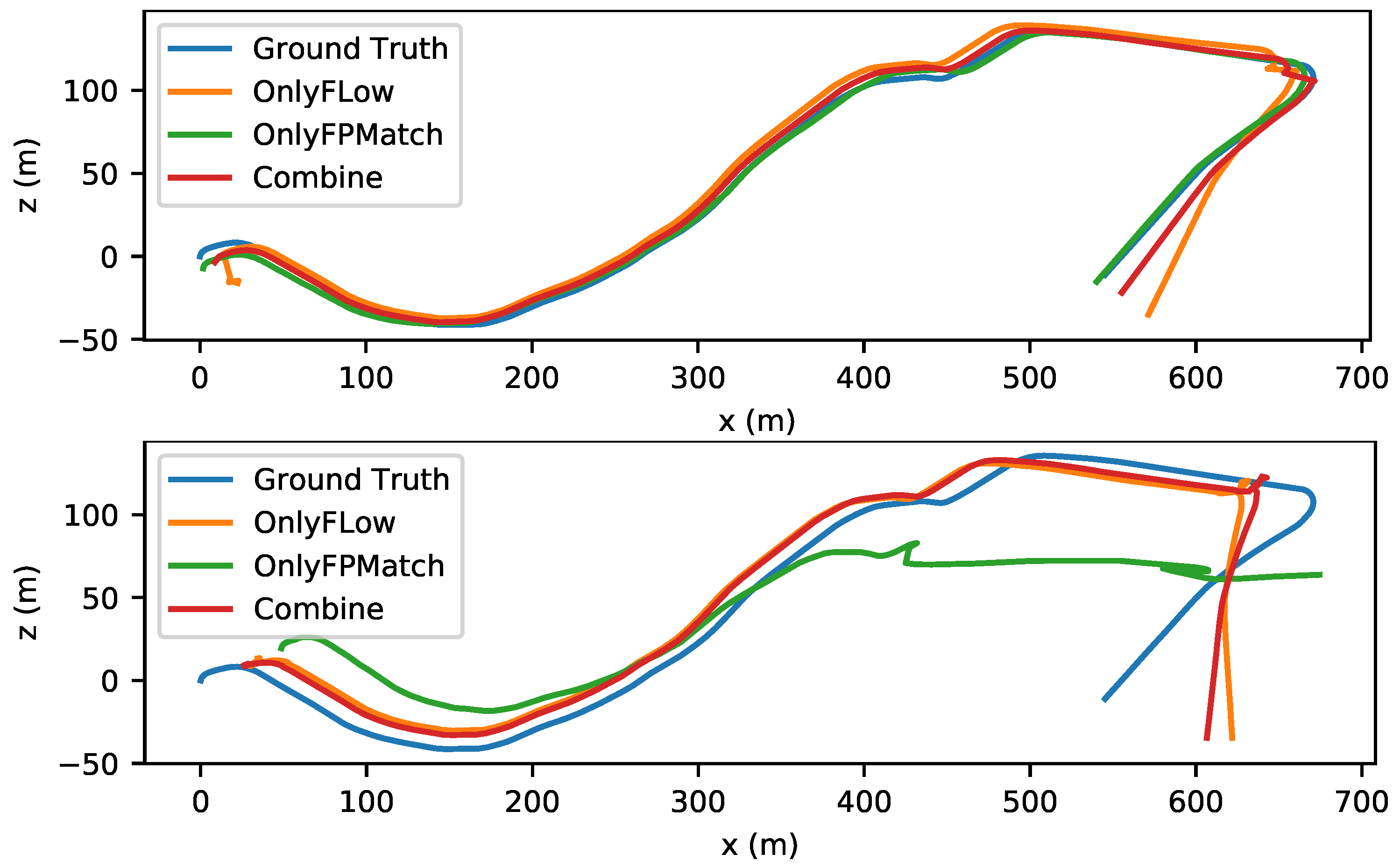
Figure 9.
The left image shows the estimated trajectories in a medium-amplitude-motion scene (stride = 3). The right image shows the results from a large-amplitude-motion scene (stride = 4) of sequence 09 in the KITTI dataset.
Figure 9.
The left image shows the estimated trajectories in a medium-amplitude-motion scene (stride = 3). The right image shows the results from a large-amplitude-motion scene (stride = 4) of sequence 09 in the KITTI dataset.
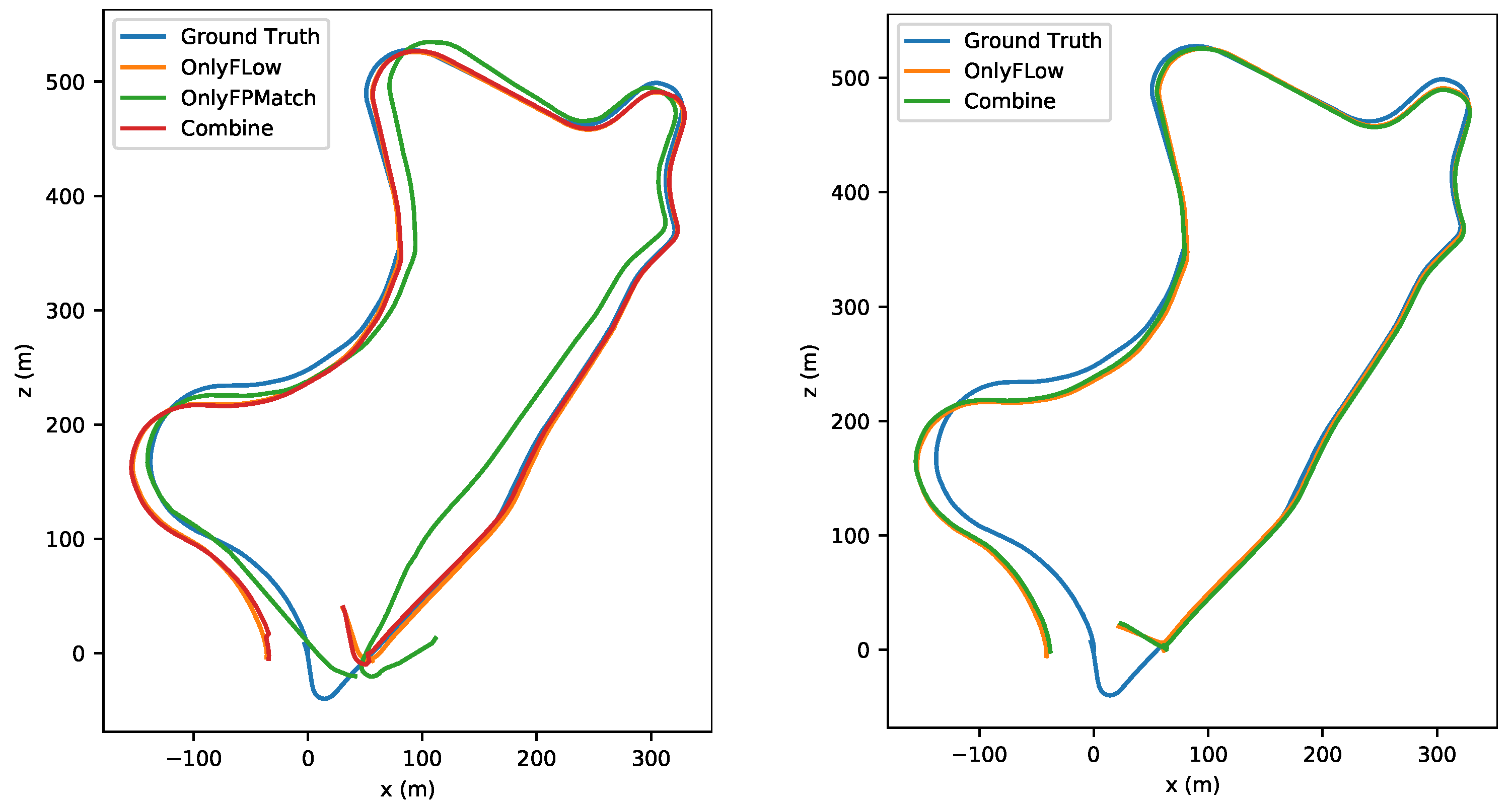
Figure 10.
The upper image shows the estimated trajectories of a medium-amplitude-motion scene (stride = 3). The lower image shows the results from a large-amplitude-motion scene (stride = 4) in sequence 10 of the KITTI dataset.
Figure 10.
The upper image shows the estimated trajectories of a medium-amplitude-motion scene (stride = 3). The lower image shows the results from a large-amplitude-motion scene (stride = 4) in sequence 10 of the KITTI dataset.
Table 1.
We randomly selected two adjacent images for SIFT and SURF evaluation; point A refers to the number of feature points extracted from the previous image and point B refers to the number of feature points extracted from the latter image.
Table 1.
We randomly selected two adjacent images for SIFT and SURF evaluation; point A refers to the number of feature points extracted from the previous image and point B refers to the number of feature points extracted from the latter image.
| | SURF | SIFT |
|---|
| Execution speed (ms) | 20.7 | 33.8 |
| Point A | 1390 | 934 |
| Point B | 1413 | 905 |
| Match numbers | 784 | 495 |
| Accuracy rate (%) | 86 | 88 |
Table 2.
Compared with recent works, our method produced fairly good camera pose prediction in a normal-motion scene (stride = 1). ORB-SLAM2 contained no loopback detection.
Table 2.
Compared with recent works, our method produced fairly good camera pose prediction in a normal-motion scene (stride = 1). ORB-SLAM2 contained no loopback detection.
| | Seq.09 | Seq.10 |
|---|
| | T (%) | R (/100 m) | T (%) | R (/100 m) |
|---|
| ORB-SLAM2 [4] | 9.31 | 0.26 | 2.66 | 0.39 |
| SfM-Learner [19] | 11.34 | 4.08 | 15.26 | 4.08 |
| Deep-VO-Feat [44] | 9.07 | 3.80 | 9.60 | 3.41 |
| SAEVO [45] | 8.13 | 2.95 | 6.76 | 2.42 |
| CC [21] | 7.71 | 2.32 | 9.87 | 4.47 |
| SC-SfMLearner [5] | 7.60 | 2.19 | 10.77 | 4.63 |
| TrainFlow [6] | 6.93 | 0.44 | 4.66 | 0.62 |
| Ours | 4.29 | 0.43 | 2.46 | 0.49 |
Table 3.
The VO results on small-amplitude-motion scene (stride = 2). R (/100 m) and T (%) refer to the rotation error and the average translation error.
Table 3.
The VO results on small-amplitude-motion scene (stride = 2). R (/100 m) and T (%) refer to the rotation error and the average translation error.
| | Seq.09 | Seq.10 |
|---|
| | T (%) | R (/100 m) | T (%) | R (/100 m) |
|---|
| ORB-SLAM2 [4] | 11.12 | 0.33 | 2.97 | 0.36 |
| SfM-Learner [19] | 24.75 | 7.79 | 25.09 | 11.39 |
| Deep-VO-Feat [44] | 20.54 | 6.33 | 16.81 | 7.59 |
| CC [21] | 24.49 | 6.58 | 19.49 | 10.13 |
| SC-SfMLearner [5] | 33.35 | 8.21 | 27.21 | 14.04 |
| TrainFlow [6] | 7.02 | 0.45 | 4.94 | 0.64 |
| Ours | 4.52 | 0.45 | 2.66 | 0.68 |
Table 4.
The VO results on medium-amplitude-motion scene (stride = 3). As we can see, ORB-SLAM2 was hard to initialize and lost track, while our approach outperformed the others by a clear margin.
Table 4.
The VO results on medium-amplitude-motion scene (stride = 3). As we can see, ORB-SLAM2 was hard to initialize and lost track, while our approach outperformed the others by a clear margin.
| | Seq.09 | Seq.10 |
|---|
| | T (%) | R (/100 m) | T (%) | R (/100 m) |
|---|
| ORB-SLAM2 [4] | X | X | X | X |
| SfM-Learner [19] | 49.62 | 13.69 | 33.55 | 16.21 |
| Deep-VO-Feat [44] | 41.24 | 10.80 | 24.17 | 11.31 |
| CC [21] | 41.99 | 11.47 | 30.08 | 14.68 |
| SC-SfMLearner [5] | 52.05 | 14.39 | 37.22 | 18.91 |
| TrainFlow [6] | 7.21 | 0.56 | 11.43 | 2.57 |
| Ours | 5.36 | 0.56 | 6.21 | 1.68 |
Table 5.
The VO results on large amplitude motion scene (stride = 4). Compared with recent works, our method produced fairly good camera pose prediction in the large-amplitude-motion scene (stride = 4).
Table 5.
The VO results on large amplitude motion scene (stride = 4). Compared with recent works, our method produced fairly good camera pose prediction in the large-amplitude-motion scene (stride = 4).
| | Seq.09 | Seq.10 |
|---|
| | T (%) | R (/100 m) | T (%) | R (/100 m) |
|---|
| ORB-SLAM2 [4] | X | X | X | X |
| SfM-Learner [19] | 61.24 | 18.32 | 38.94 | 19.62 |
| Deep-VO-Feat [44] | 42.33 | 11.88 | 25.83 | 11.58 |
| CC [21] | 51.45 | 14.39 | 34.97 | 17.09 |
| SC-SfMLearner [5] | 59.32 | 17.91 | 42.25 | 21.04 |
| TrainFlow [6] | 7.72 | 1.14 | 17.30 | 5.94 |
| Ours | 5.65 | 1.04 | 14.55 | 6.24 |
Table 6.
Ablation Study. “Only Flow” means only FlowNet and the principle of forward–backward flow consistency was used to recover the camera pose. “Only FPMatch” means SURF and FlANN were used to recover the camera pose. “Combine” means the combination of the two approaches was used to recover camera pose.
Table 6.
Ablation Study. “Only Flow” means only FlowNet and the principle of forward–backward flow consistency was used to recover the camera pose. “Only FPMatch” means SURF and FlANN were used to recover the camera pose. “Combine” means the combination of the two approaches was used to recover camera pose.
| | Error | Only Flow | Only FPMatch | Combine |
|---|
| 09 (stride = 1) | T error (%) | 4.41 | 3.80 | 4.29 |
| R error (/100 m) | 0.53 | 0.48 | 0.43 |
| ATE | 17.19 | 15.02 | 14.98 |
| 09 (stride = 2) | T error (%) | 4.72 | 6.13 | 4.52 |
| R error (/100 m) | 0.50 | 1.03 | 0.45 |
| ATE | 18.51 | 27.14 | 17.95 |
| 09 (stride = 3) | T error (%) | 5.39 | 15.10 | 5.36 |
| R error (/100 m) | 0.62 | 15.07 | 0.56 |
| ATE | 22.12 | 30.39 | 21.58 |
| 09 (stride = 4) | T error (%) | 5.83 | X (track loss) | 5.65 |
| R error (/100 m) | 1.10 | X (track loss) | 1.04 |
| ATE | 24.42 | X (track loss) | 23.98 |
| 10 (stride = 1) | T error (%) | 2.83 | 2.89 | 2.46 |
| R error (/100 m) | 0.65 | 0.63 | 0.49 |
| ATE | 4.67 | 4.62 | 4.46 |
| 10 (stride = 2) | T error (%) | 2.77 | 2.77 | 2.66 |
| R error (/100 m) | 0.44 | 1.04 | 0.68 |
| ATE | 4.72 | 4.93 | 4.39 |
| 10 (stride = 3) | T error (%) | 5.72 | 4.85 | 6.21 |
| R error (/100 m) | 1.96 | 2.93 | 1.68 |
| ATE | 15.75 | 9.09 | 8.87 |
| 10 (stride = 4) | T error (%) | 16.33 | 24.16 | 14.55 |
| R error (/100 m) | 6.39 | 27.14 | 6.24 |
| ATE | 34.55 | 65.20 | 28.53 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}