
Path Generator with Unpaired Samples Employing Generative Adversarial Networks


Abstract
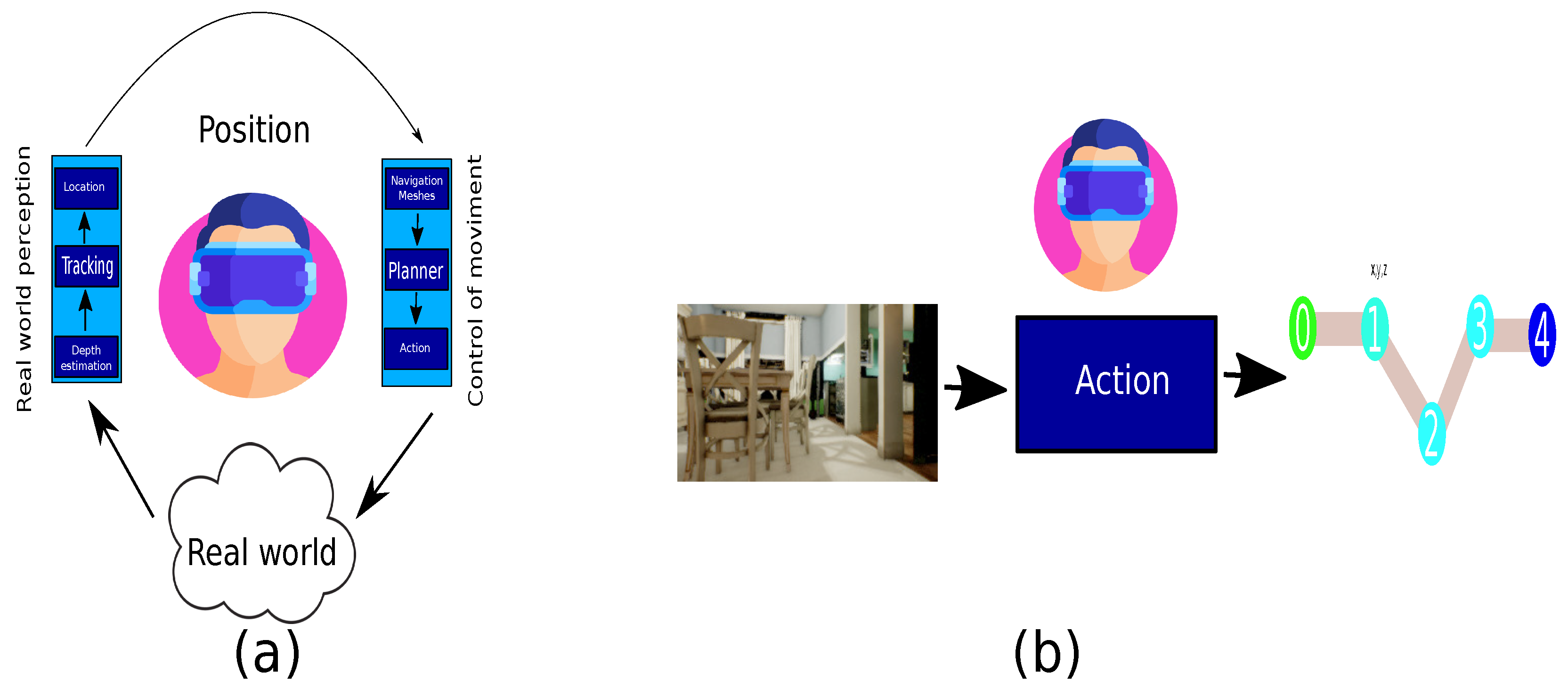
:1. Introduction
2. Background and Research Gaps
3. Proposed Work
4. Experimental Phase and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, K.; Billinghurst, M.; Bruder, G.; Duh, H.B.L.; Welch, G.F. Revisiting Trends in Augmented Reality Research: A Review of the 2nd Decade of ISMAR (2008–2017). IEEE Trans. Vis. Comput. Graph. 2018, 24, 2947–2962. [Google Scholar] [CrossRef]
- Hernández, J.D.; Sobti, S.; Sciola, A.; Moll, M.; Kavraki, L.E. Increasing Robot Autonomy via Motion Planning and an Augmented Reality Interface. IEEE Robot. Autom. Lett. 2020, 5, 1017–1023. [Google Scholar] [CrossRef]
- Kularbphettong, K.; Vichivanives, R.; Roonrakwit, P. Student Learning Achievement through Augmented Reality in Science Subjects. In Proceedings of the 2019 11th International Conference on Education Technology and Computers, Amsterdam, Netherlands, 28–31 October 2019; Association for Computing Machinery: New York, NY, USA, 2019. ICETC 2019. pp. 228–232. [Google Scholar] [CrossRef]
- Serrano Vergel, R.; Morillo Tena, P.; Casas Yrurzum, S.; Cruz-Neira, C. A Comparative Evaluation of a Virtual Reality Table and a HoloLens-Based Augmented Reality System for Anatomy Training. IEEE Trans. Hum.-Mach. Syst. 2020, 50, 337–348. [Google Scholar] [CrossRef]
- Qian, L.; Wu, J.Y.; DiMaio, S.P.; Navab, N.; Kazanzides, P. A Review of Augmented Reality in Robotic-Assisted Surgery. IEEE Trans. Med. Robot. Bionics 2020, 2, 1–16. [Google Scholar] [CrossRef]
- Zhou, F.; Duh, H.B.L.; Billinghurst, M. Trends in augmented reality tracking, interaction and display: A review of ten years of ISMAR. In Proceedings of the 2008 7th IEEE/ACM International Symposium on Mixed and Augmented Reality, Cambridge, UK, 15–18 September 2008; pp. 193–202. [Google Scholar] [CrossRef] [Green Version]
- Kent, L.; Snider, C.; Gopsill, J.; Hicks, B. Mixed reality in design prototyping: A systematic review. Des. Stud. 2021, 77, 101046. [Google Scholar] [CrossRef]
- Speicher, M.; Hall, B.D.; Nebeling, M. What is Mixed Reality? In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems (CHI ’19), Glasgow, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–15. [Google Scholar] [CrossRef]
- Lee, L.H.; Braud, T.; Hosio, S.; Hui, P. Towards Augmented Reality Driven Human-City Interaction: Current Research on Mobile Headsets and Future Challenges. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Costanza, E.; Kunz, A.; Fjeld, M. Mixed Reality: A Survey. In Human Machine Interaction: Research Results of the MMI Program; Lalanne, D., Kohlas, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 47–68. [Google Scholar] [CrossRef]
- Evans, D. How the Next Evolution of the Internet Is Changing Everything—Networking, Cloud, and Cybersecurity Solutions, CISCO. 2011. Available online: https://www.cisco.com/c/dam/en_us/about/ac79/docs/innov/IoT_IBSG_0411FINAL.pdf (accessed on 2 June 2022).
- Blanco-Novoa, O.; Fernandez-Carames, T.M.; Fraga-Lamas, P.; Vilar-Montesinos, M.A. A Practical Evaluation of Commercial Industrial Augmented Reality Systems in an Industry 4.0 Shipyard. IEEE Access 2018, 6, 8201–8218. [Google Scholar] [CrossRef]
- Nowacki, P.; Woda, M. Capabilities of ARCore and ARKit Platforms for AR/VR Applications. In Engineering in Dependability of Computer Systems and Networks. DepCoS-RELCOMEX 2019. Advances in Intelligent Systems and Computing; Zamojski, W., Mazurkiewicz, J., Sugier, J., Walkowiak, T., Kacprzyk, J., Eds.; Springer: Cham, Germany, 2019; pp. 358–370. [Google Scholar] [CrossRef]
- Wang, A.I. Systematic literature review on health effects of playing Pokémon Go. Entertain. Comput. 2021, 38, 100411. [Google Scholar] [CrossRef]
- Richards, K.; Wong, K.; Khan, M. Augmented reality game related injuries. New Horizons Clin. Case Rep. 2017, 2, 27. [Google Scholar] [CrossRef] [Green Version]
- Mao, R.; Gao, H.; Guo, L. A novel collision-free navigation approach for multiple nonholonomic robots based on Orca and linear MPC. Math. Probl. Eng. 2020, 2020, 1–16. [Google Scholar] [CrossRef]
- Ajani, T.S.; Imoize, A.L.; Atayero, A.A. An Overview of Machine Learning within Embedded and Mobile Devices–Optimizations and Applications. Sensors 2021, 21, 4412. [Google Scholar] [CrossRef] [PubMed]
- Hasinoff, S.W.; Sharlet, D.; Geiss, R.; Adams, A.; Barron, J.T.; Kainz, F.; Chen, J.; Levoy, M. Burst Photography for High Dynamic Range and Low-Light Imaging on Mobile Cameras. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, Quebec, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Tripathy, S.; Kannala, J.; Rahtu, E. Learning Image-to-Image Translation Using Paired and Unpaired Training Samples; Springer: Berlin/Heidelberg, Germany, 2019; pp. 51–66. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks; IEEE International Conference on Computer Vision (ICCV); Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Leven, D.; Sharir, M. An Efficient and Simple Motion Planning Algorithm for a Ladder Moving in Two-Dimensional Space amidst Polygonal Barriers (Extended Abstract). In Proceedings of the First Annual Symposium on Computational Geometry (SCG ’85), Baltimore, Maryland, USA, 5–7 June 1985; Association for Computing Machinery: New York, NY, USA, 1985; pp. 221–227. [Google Scholar] [CrossRef]
- Schwartz, J.T.; Sharir, M. On the “piano movers” problem. II. General techniques for computing topological properties of real algebraic manifolds. Adv. Appl. Math. 1983, 4, 298–351. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Tang, B.; Chen, L.; Song, S.; Tong, X. Learning a Deep Cascaded Neural Network for Multiple Motion Commands Prediction in Autonomous Driving. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7585–7596. [Google Scholar] [CrossRef]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Proceedings of the FSR, First Online, 3 November 2017. [Google Scholar]
- Shamwell, E.J.; Lindgren, K.; Leung, S.; Nothwang, W.D. Unsupervised Deep Visual-Inertial Odometry with Online Error Correction for RGB-D Imagery. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2478–2493. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Luo, S.; Guo, T. Image-to-Image Transfer Makes Chaos to Order. In Proceedings of the 2021 International Conference on Multimedia Retrieval (ICMR ’21), Taipei, Taiwan, 21–24 August 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 236–243. [Google Scholar] [CrossRef]
- Wadhwa, N.; Garg, R.; Jacobs, D.E.; Feldman, B.E.; Kanazawa, N.; Carroll, R.; Movshovitz-Attias, Y.; Barron, J.T.; Pritch, Y.; Levoy, M. Synthetic depth-of-field with a single-camera mobile phone. ACM Trans. Graph. 2018, 37, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Maldonado-Romo, J.; Aldape-Pérez, M.; Rodríguez-Molina, A. Analysis of Depth and Semantic 373 Mask for Perceiving a Physical Environment Using Virtual Samples Generated by a GAN. IEEE Access 2022, 10, 5595–5607. [Google Scholar] [CrossRef]
- Wu, T.; Luo, A.; Huang, R.; Cheng, H.; Zhao, Y. End-to-End Driving Model for Steering Control of Autonomous Vehicles with Future Spatiotemporal Features. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 950–955. [Google Scholar] [CrossRef]
- Chen, X.; Xu, C.; Yang, X.; Song, L.; Tao, D. Gated-GAN: Adversarial Gated Networks for Multi-Collection Style Transfer. IEEE Trans. Image Process. 2019, 28, 546–560. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, X.; Tian, Y.; Qi, Z. RPD-GAN: Learning to Draw Realistic Paintings With Generative Adversarial Network. IEEE Trans. Image Process. 2020, 29, 8706–8720. [Google Scholar] [CrossRef]
- Mignotte, M. Segmentation by Fusion of Histogram-Based K-Means Clusters in Different Color Spaces. IEEE Trans. Image Process. 2008, 17, 780–787. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Ribeiro, A. Hierarchical Clustering Given Confidence Intervals of Metric Distances. IEEE Trans. Signal Process. 2018, 66, 2600–2615. [Google Scholar] [CrossRef]
- Wang, W.; Gao, H.; Yi, Q.; Zheng, K.; Gu, T. An Improved RRT* Path Planning Algorithm for Service Robot. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; Volume 1, pp. 1824–1828. [Google Scholar] [CrossRef]
- Zabarankin, M.; Uryasev, S.; Murphey, R. Aircraft routing under the risk of detection. Nav. Res. Logist. (NRL) 2006, 53, 728–747. [Google Scholar] [CrossRef]
- Xue, Y.; Sun, J.Q. Solving the Path Planning Problem in Mobile Robotics with the Multi-Objective Evolutionary Algorithm. Appl. Sci. 2018, 8, 1425. [Google Scholar] [CrossRef] [Green Version]
- Maldonado-Romo, J.; Aldape-Pérez, M.; Rodríguez-Molina, A. Path planning generator with metadata through a domain change by Gan between physical and Virtual Environments. Sensors 2021, 21, 7667. [Google Scholar] [CrossRef] [PubMed]
- Poghosyan, A.; Sarukhanyan, H. Short-term memory with read-only unit in neural image caption generator. In Proceedings of the 2017 Computer Science and Information Technologies (CSIT), Lviv, Ukraine, 5–8 September 2017; pp. 162–167. [Google Scholar] [CrossRef]
- Handa, A.; Newcombe, R.A.; Angeli, A.; Davison, A.J. Real-Time Camera Tracking: When is High Frame-Rate Best? In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 222–235. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Zainuddin, N.; Mustafah, Y.; Shawgi, Y.; Rashid, N. Autonomous Navigation of Mobile Robot Using Kinect Sensor. In Proceedings of the 2014 International Conference on Computer and Communication Engineering, Kuala Lumpur, Malaysia, 23–25 September 2014; pp. 28–31. [Google Scholar] [CrossRef]
- Bowman, D.A.; Kruijff, E.; LaViola, J.J.; Poupyrev, I. 3D User Interfaces: Theory and Practice; Addison Wesley Longman Publishing Co., Inc.: Redwood City, CA, USA, 2004. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Average Color | Dominate Color | |||
|---|---|---|---|---|
| Mean | STD | Mean | STD | |
| Known environment | 110.9818, 110.6834,125.3244 | 11.1791,11.2014, 6.3755 | 114.2768, 171.9477, 170.8425 | 18.5680, 12.0359, 8.7037 |
| Transfer features | 84.0189, 84.2476, 83.5052 | 5.0146, 5.4588, 5.5117 | 11.9112, 12.0532, 11.9745 | 3.3174, 3.4040, 3.5008 |
| 119.9242, 125.1150, 123.8134 | 12.2781, 6.5528, 7.4241 | 179.4007, 214.4179, 193.91524 | 8.8878, 7.6791, 13.3808 | |
| 128.9802, 143.6930, 140.1511 | 13.6080, 10.2819, 9.3439 | 174.8663, 208.5393, 175.3898 | 14.4137, 9.6241, 11.1316 | |
| Normal features | 120.8573, 120.9270, 120.8453 | 12.9963, 12.9853, 12.9868 | 83.6730, 83.6655, 83.6190 | 16.7216, 16.6732, 16.5330 |
| 110.5359, 97.0221, 112.8038 | 24.3627, 28.4992, 6.5405 | 109.7473, 97.8742, 196.9221 | 27.4893, 28.5040, 14.3613 | |
| 163.2307, 149.6583, 184.5755 | 4.9271, 6.2114, 2.9584 | 231.9854, 207.9542, 217.7950 | 4.0251, 4.4566, 6.5562 | |
| Domain | Transfer Features | Normal Features | ||
|---|---|---|---|---|
| Centroid | Distance | Centroid | Distance | |
| Known | 0.1565, 0.3084, −0.6504 | - | 0.1565, 0.3084, −0.6504 | - |
| Unknown A | 0.1741, 0.3108, −0.5918 | 0.0612 | 0.1934, 0.3004, −0.3697 | 0.2832 |
| Unknown B | 0.1549, 0.3215, −0.6529 | 0.0134 | 0.1553, 0.3260, −0.5249 | 0.1267 |
| Unknown C | 0.1365, 0.3254, −0.6811 | 0.0403 | 0.1410, 0.3047, −0.5773 | 0.0748 |
| Environment | Model | Accuracy Euclidean Distance (Mean-Sdt) (↓) | Accuracy Manhattan Distance (Mean-Sdt) (↓) | Accuracy Cosine Similarity (Mean-Sdt) (↑) | Free Collision Coefficient (↑) |
|---|---|---|---|---|---|
| A | Autoencoder | 2.4481 ± 0.7458 | 4.9868 ± 1.6354 | 0.7896 ± 0.0896 | 0.78 |
| HC | 1.3789 ± 0.3489 | 3.4579 ± 0.8978 | 0.8928 ± 0.0480 | 0.88 | |
| TL-Autoencoder | 7.7589 ± 1.7895 | 11.4587 ± 2.4756 | 0.5478 ± 0.0789 | 0.52 | |
| TL-HC | 2.1458 ± 0.7458 | 3.2458 ± 0.8756 | 0.8878 ± 0.0478 | 0.86 | |
| ARcore | 0.8253 | 1.3268 | 0.8647 | 0.92 | |
| Kinect | 0.5146 | 0.9984 | 0.8964 | 0.96 | |
| B | Autoencoder | 3.4656 ± 1.4183 | 5.0145 ± 0.9315 | 0.7265 ± 0.1018 | 0.79 |
| HC | 1.8425 ± 0.5792 | 2.9854 ± 0.7419 | 0.8472 ± 0.0478 | 0.86 | |
| TL-Autoencoder | 5.2947 ± 1.2415 | 9.6542 ± 1.7892 | 0.6217 ± 0.1479 | 0.59 | |
| TL-HC | 1.9475 ± 0.4531 | 4.0154 ± 0.6548 | 0.8934 ± 0.1256 | 0.89 | |
| ARcore | 0.9205 | 2.0268 | 0.7908 | 0.88 | |
| Kinect | 0.7251 | 1.1356 | 0.8955 | 0.94 | |
| C | Autoencoder | 2.1946 ± 0.6026 | 3.7146 ± 0.7987 | 0.8476 ± 0.1796 | 0.82 |
| HC | 0.9987 ± 1.0147 | 2.5892 ± 0.9735 | 0.8956 ± 0.0145 | 0.90 | |
| TL-Autoencoder | 5.8624 ± 1.9752 | 10.2305 ± 1.0174 | 0.6204 ± 0.0497 | 0.59 | |
| TL-HC | 2.2580 ± 0.0325 | 4.0563 ± 0.6520 | 0.8942 ± 0.0041 | 0.88 | |
| ARcore | 0.9527 | 1.159 | 0.8872 | 0.96 | |
| Kinect | 0.8745 | 1.3746 | 0.9004 | 0.96 | |
| D | Autoencoder | 1.9524 ± 0.8456 | 3.2168 ± 0.5428 | 0.8128 ± 0.1558 | 0.84 |
| HC | 2.0415 ± 0.5478 | 4.0127 ± 0.7812 | 0.8872 ± 0.0147 | 0.92 | |
| TL-Autoencoder | 4.4527 ± 1.2305 | 9.4762 ± 1.9856 | 0.5856 ± 0.0586 | 0.62 | |
| TL-HC | 2.7586 ± 0.2569 | 5.9682 ± 0.4368 | 0.9028 ± 0.1868 | 0.88 | |
| ARcore | 0.8898 | 1.5743 | 0.9246 | 0.98 | |
| Kinect | 0.9975 | 1.7104 | 0.9165 | 0.96 |
| Experiment | User 1 | User 2 | User 3 | User 4 | User 5 | User 6 | User 7 | User 8 |
|---|---|---|---|---|---|---|---|---|
| 1 | 4 | 6 | 5 | 4 | 4 | 3 | 7 | 5 |
| 2 | 4 | 3 | 4 | 4 | 3 | 1 | 4 | 3 |
| 3 | 2 | 1 | 2 | 1 | 1 | 0 | 2 | 1 |
| 4 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maldonado-Romo, J.; Maldonado-Romo, A.; Aldape-Pérez, M. Path Generator with Unpaired Samples Employing Generative Adversarial Networks. Sensors 2022, 22, 9411. https://doi.org/10.3390/s22239411
Maldonado-Romo J, Maldonado-Romo A, Aldape-Pérez M. Path Generator with Unpaired Samples Employing Generative Adversarial Networks. Sensors. 2022; 22(23):9411. https://doi.org/10.3390/s22239411
Chicago/Turabian StyleMaldonado-Romo, Javier, Alberto Maldonado-Romo, and Mario Aldape-Pérez. 2022. "Path Generator with Unpaired Samples Employing Generative Adversarial Networks" Sensors 22, no. 23: 9411. https://doi.org/10.3390/s22239411