1. Introduction
Estimating accurate dense depth maps is an essential task for unmanned vehicles [
1,
2]. Having access to the distance that separates them from objects of the environment is indeed a prerequisite for most obstacle avoidance and trajectory planning algorithms [
3,
4,
5]. To the best of our knowledge, the only reliable long-range distance sensors suitable for outdoors are heavy, bulky, power consuming, and expensive, which makes them unsuitable for use on vehicles such as drones where weight, size, and power availability are constrained. Therefore, these vehicles need to infer distances by other means. One way to achieve this is to replace the distance sensor with an algorithm that estimates depth from RGB pictures captured by an on-board-mounted camera, as done by Kim et al. [
4] for instance.
Small and lightweight unmanned ground or aerial vehicles are perfect devices to reach places otherwise barely accessible and, hence, are often used to venture off road in environments where direct cues about distance, such as object structures, are unknown. Natural landscapes are examples of such environments whose elements (vegetation, ground and relief) do not exhibit normalized structures or patterns. However, datasets suitable to study the task of depth estimation in environments with little structure—we call them “unstructured environments” in the following—were proposed only recently (see Fonder and Van Droogenbroeck [
6], Wang et al. [
7]). As a result, existing methods for outdoor depth estimation [
8,
9,
10,
11,
12] are benchmarked against older datasets that only target autonomous driving applications in urban environments.
These methods are all trained to directly infer depth or its inverse, known as disparity. As the motion of a car on a road is strongly constrained and urban areas contain many objects with a specific structure (cars, roads, signs, buildings, etc), the autonomous driving datasets mainly feature constrained trajectories and environments. Since the structure and semantics of elements in a scene likely provide direct cues about depth, it is uncertain if existing methods perform well in environments where such cues are not available. Furthermore, learning to directly infer depth or disparity reduces the capability of networks to generalize in environments where the depth distribution differs from the one used for training.
In this paper, we address the challenging task of estimating depth in unstructured environments. To overcome the shortcomings of existing methods, we introduce a notion of visual parallax, the frame-to-frame displacement of a pixel in an image sequence. With our formulation, the visual parallax is decoupled from the depth distribution thanks to the camera motion. This allows us to build a deep neural network based on plane-sweeping cost volumes that performs well when inferring depth both in specific environments and in generalization.
As highlighted by Schröppel et al. [
13], building plane-sweeping cost volumes from depth or disparity intervals requires two arbitrary parameters that constraint the performance and the generalization properties of the underlying network. In this work, we overcome the need to determine arbitrary parameters by building plane-sweeping cost volumes from parallax intervals.
The related work and the precise formulation of the task we address in this paper are presented in
Section 2 and
Section 3, respectively. Then, in
Section 4, we describe our dedicated depth estimation method. In
Section 5, we detail our experimental setup which is aimed at evaluating methods on unstructured environments and in generalization. We also present our results and discuss our method in this section.
Section 6 concludes the paper.
Our main contributions can be summarized as follows:
We define a notion of visual parallax between two frames from a generic six-degree-of-freedom (6-DoF) camera motion, and present a way to build cost volumes with this parallax;
We present a novel lightweight multi-level architecture, called M4Depth, that is based on these cost volumes, designed to perform end-to-end depth estimation on video streams acquired in unstructured environments, and suitable for real-time applications;
It is shown that M4Depth, is state-of-the-art on the Mid-Air dataset [
6], that it has good performances on the KITTI dataset [
14], and that it outperforms existing methods in a generalization setup on the TartanAir dataset [
7].
2. Related Work
Related works are presented according to four different categories.
(1) Depth from a single image. Estimating depth from a single RGB image is an old and well-established principle. If the first methods were fully handcrafted [
15], the growth of machine learning and the development of CNNs has impacted on the field of depth estimation through the introduction of new methods such as Monodepth [
16], Monodepth2 [
17], or the method proposed by Poggi et al. [
18] that have led to massive improvements in the quality of the depth estimates. Methods based on vision transformer networks, such as DPT [
19] or AdaBins [
20], push the performance even further and are currently the state-of-the-art in the field.
Recent surveys [
9,
10,
11,
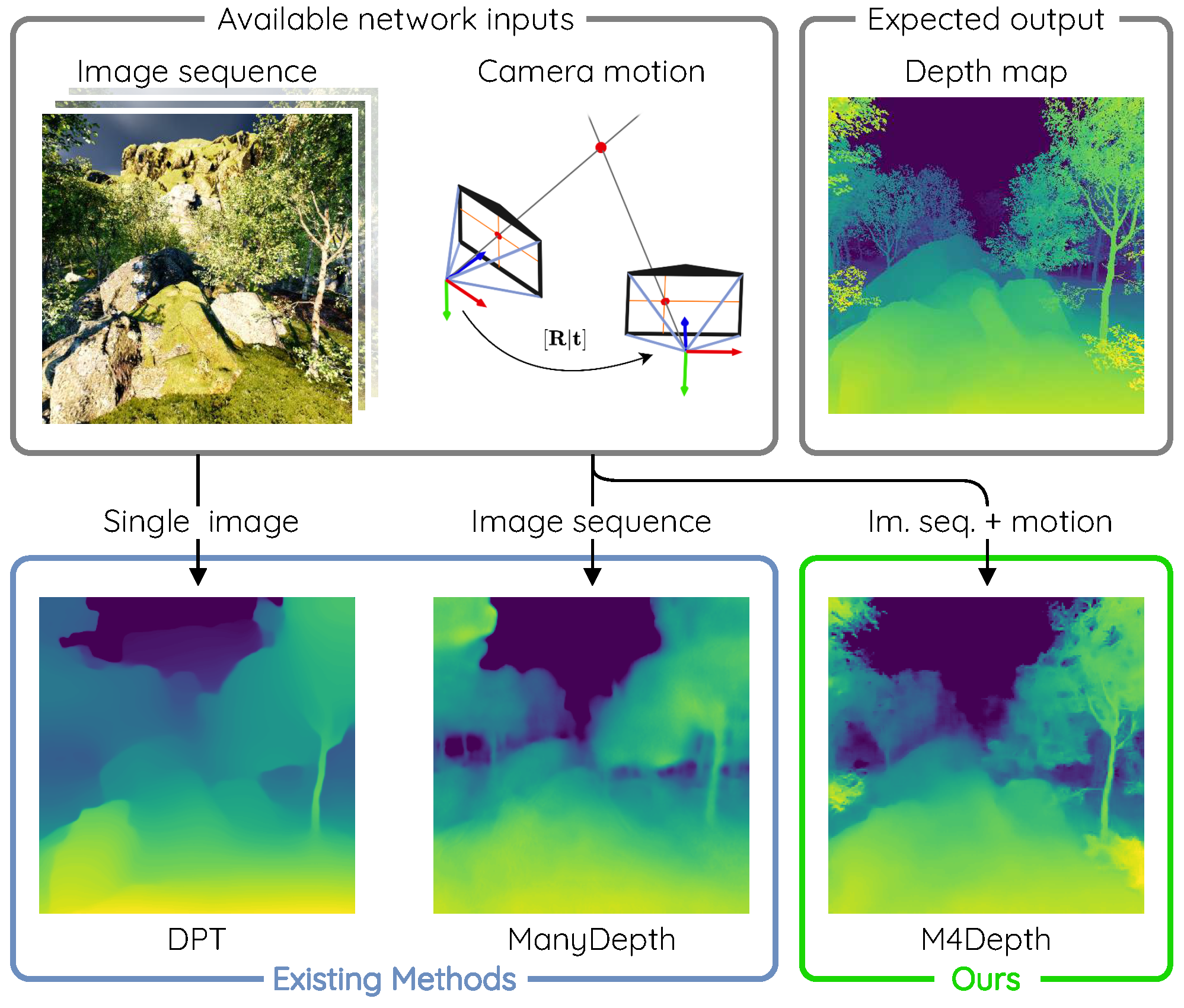
12] present summarized descriptions and comparisons of single image depth estimation methods. The main observation made in these surveys is that estimating depth from a single image remains difficult, especially for autonomous vehicle applications. Since the problem is ill-posed, networks have to heavily rely on priors to compute a suitable proposal. Such dependency on priors leads to a lack of robustness and generalization. Therefore, methods of this family need to be fine-tuned for every new scenario or environment encountered in order to produce good estimates. Despite their massive parameter count, transformers are no exception to these observations, as illustrated in
Figure 1.
(2) Depth from an image sequence. Methods exist that include recurrence in networks to make use of temporal information for improving estimates [
23,
24,
25,
26,
27]. They are mainly adaptations of existing architectures through the addition or modification of specific layers. As such, these methods do not make direct use of motion-induced constraints.
In their method named ManyDepth, Watson et al. [
22] avoided this issue by relying, among other things, on a model for motion and a cost volume built with the plane-sweeping method [
28,
29]. Xing et al. [
30] avoided the need for explicit motion modeling by using the planar parallax geometry [
31,
32]. The latest method however consists in a complex pipeline that explicitly relies on structure in the environment, which makes it unusable for our problem.
By design, methods independent of the camera motion are unable to estimate the proper scale for depth without relying on any prior knowledge about the structure of the scene. In addition, the scale estimated for the outputs is likely to drift over the sequence because there is no way to validate the proper scale at any time. This is problematic for autonomous vehicles moving in unstructured environments.
(3) Use of motion information. When motion is used by depth estimation methods, it is mostly exploited to build a loss function for self-supervised training [
17,
24,
25,
33,
34]. In these cases, motion and depth are learnt by two independent networks in an unsupervised fashion and depth is still estimated without any clue about motion. As the core of these depth estimation networks does not change compared to methods simply working on sequences, their estimations suffer from the same issues as the ones produced by methods that do not use motion.
One notable exception is the idea proposed by Luo et al. [
35]. Their method uses a self-supervised loss based on motion estimation to fine-tune the network at test time. It achieves outstanding performance, but at the cost of a large computational burden. Furthermore, this method cannot estimate depth before the whole image sequence is available, meaning that it only operates in an offline mode and makes it inappropriate for autonomous vehicle applications.
(4) 3-D reconstruction. Structure from motion (SfM) and multi-view stereo (MVS) are two research fields that have developed in parallel with depth estimation. The idea is to reconstruct 3-D shapes from a set of RGB images that capture the scene from different points of view under specific hypothesis (MVS requires known camera poses, SfM does not). Reconstruction is achieved by explicitly expressing the relative camera position between the images of the set. Approaches for performing this task are varied [
36,
37] and are, by their nature, often unsuitable for real-time depth estimation. However, some are adaptable for depth estimation on sequences [
38,
39,
40], while others are specifically designed to work on image sequences in real time [
41,
42].
The approach proposed by Düzçeker et al. [
41] and the method called DeepV2D by Teed and Deng [
42] are similar. They both propose a three-stage network. Their stages are an image-encoding network followed by the computation of a cost volume that is finally processed by a depth estimation network. The purpose of the cost volume consists of providing the costs for matching a point in an image with a series of candidates in another image. The cost volume of both methods is built by a plane-sweeping method [
28,
29].
As highlighted by Schröppel et al. [
13], the multi-frame methods that rely on plane-sweeping cost volumes share a common shortcoming. They build their cost volumes from depth or disparity intervals, which requires two arbitrary parameters: (1) the maximum range, and (2) the quantization step along this range. The maximum range has to be known at the time of training or fine-tuning, which prevents dynamic adaptations to new depth distributions. The quantization step, that is the range divided by the number of samples along the range, is an important parameter for determining the performance of the network. A large quantization step degrades the depth resolution, hence the performance of a network, while taking a smaller quantization step will increase the inference time without any guarantee of improving the final result.
3. Problem Statement
We now present the technicalities of the problem we want to solve. We consider a camera rigidly attached to a vehicle moving within an unknown static environment. The intrinsic parameters of the camera are supposed to be known and constant. We introduce the following components and notations:
is an RGB image of size recorded by the camera at time step t. Images have the following properties: (1) motion blur and rolling shutter artifacts are negligible; (2) the camera focal length f is known and constant during a flight; (3) the camera shutter speed and gain are unknown, and can change over time;
is the transformation matrix encoding the motion of the optical center of the camera from time step to t. As this matrix is computed for monitoring the state of the vehicle, we assume that it is available for our method as well.
is the z coordinate (in meters) of the point recorded by the pixel at coordinates of the frame with respect to the camera coordinate system.
Using these notations, a depth map is an array of values with .
We denote by the complete series of image frames and camera motions up to time step t. We define a set of functions D that are able to estimate a depth map from , that is , such that . Our objective is to a find function D in this set that best estimates .
Since collision avoidance is essential for autonomous vehicle applications, errors in the estimate of distance for closer objects should have a higher impact than errors occurring for objects in the background of the scene. This is taken care of by constructing a dedicated loss function for training and by minimizing the error relative to the distance of the object. During testing, we will use the set of performance metrics defined by Eigen et al. [
43] to better grasp the behavior of our method.
Our baseline. Based on the related work, we have selected a representative set of existing methods for which the training code is available, as given in
Table 1; they constitute the baseline for our performance tests. In this table, we indicate for each method, respectively, the nature of its supervision mode, if it is based on a single or multiple frames, if it is recurrent, how it deals with the camera pose, and if weights for the KITTI are provided by the authors.
4. Description of a New Method for Depth Estimation
Like other previous works, our method, named Motion for Depth (aka M4Depth), is based on a multi-level architecture that relies on cost volumes and that is trainable in an end-to-end fashion. The key novelty is that the network is designed to infer a parallax map, which is converted into a depth map by using motion information. The parallax map has several interesting properties that should make M4Depth more robust in generalization. This is described in the next section.
4.1. Deriving the Bijective Relation between Depth and Visual Parallax
The apparent displacement of static objects between images captured with a moving camera is the parallax effect. Parallax is defined for a generic frame-to-frame transformation, and degenerates into standard stereo disparity when the frame-to-frame transformation amounts to a translation along the camera x or y axis. Like disparity, parallax conveys information about the distance of objects from the camera, but for an unconstrained camera baseline.
Previous works using parallax geometry [
30,
31,
32] assume that frame-to-frame point correspondence, hence parallax, is known to derive 3-D rigidity constraint between pairs of points for recovering the 3-D scene structure without using the camera motion. Our method does the opposite; it uses the constraints imposed by motion, whose parameters are provided by the on-board inertial measurement unit, and geometry to guide the inference of parallax along the epipolar lines. In the following, we establish that depth is a linear function of the inverse of the parallax when the latter is defined in a specific way.
Our notion of parallax, new to the best of our knowledge, denoted by
, is established as follows. The transformation matrix
formalizing the known physical camera motion with 6 DoF between consecutive frames of the video stream can be broken down into a rotation matrix
and a 3-D translation vector
. Using the classical pinhole camera model, a point
P in space seen by the camera at two different time instants
t and
, and projected at coordinates
in the current frame
t is linked to its previous coordinates
in frame at time
by the motion
as follows:
where
is the depth of the point
P at time
t, and
is a camera calibration matrix, which is identical at times
t and
. It is possible to simplify the expression of the
matrix to:
with
and
being the focal lengths along the
x and
y axes respectively. This assumes that the coordinates
are expressed directly with respect to the principal point of the sensor
and that the skew parameter is negligible.
Before defining our visual parallax, we rewrite Equation (
1) as
with
From this equation, we can see that are the coordinates of the point P in the plane of a virtual camera V whose origin is the same as the camera at time t but with the orientation of the camera at time .
We now introduce the parallax map
, where the pixelwise parallax
is defined as the Euclidean norm,
where
With this definition, the parallax is only a function of perceived pixel motion. It is therefore invariant to the particular combination of depth and camera motion.
After reorganization, using Equation (
3) and simplification, we get:
By taking into account the physics of a scene and the camera motion of an autonomous vehicle, it can be shown that
should rarely be negative. As a result, the parallax
can be computed as follows:
This bijective expression links the parallax for a pixel to the depth of the corresponding point in space. Since parallax can be estimated from the RGB content of two consecutive images, we have a means to estimate the depth by inverting the equation, yielding:
As expected, this expression becomes identical to the definition of the standard stereo disparity when the camera only moves along the x or y axis.
In practice, there are different ways to estimate
, and in our method, we build various proposals for
and let the network use them to compute the best estimate. Note that, once a parallax map
has been estimated, the
coordinates are given by a function
, parametrized as follows
These coordinates are defined on a continuous space instead of a discrete grid.
4.2. Definition of the Network
Our primary motivation for inferring parallax rather than depth directly is driven by the need to produce a method that is robust, even in unseen environments. Training a network to infer depths drawn from a given data distribution will tie it to this distribution. Our formulation for the parallax consists of decoupling the value to infer from depth thanks to motion, and allows one to map many depth values to a same parallax value. As a result, a single learnt parallax distribution can represent many depth distributions, which is a desirable ability for robustness and generalization.
As for optical flow, estimating the parallax can be performed iteratively. Instead of simply iterating on a full network as proposed in [
39], we approach the iterative process as a multi-scale pyramidal network, as PWC-Net [
44]. By doing so, we embed the iterative process in the architecture itself. This architecture is an adaptation of the U-Net encoder-decoder with skip connections [
45], where each level
l of the decoder has to produce an estimate for the desired output, which in our case is a parallax map. In the decoder, the estimate produced at one level is forwarded to feed the next level to be refined. The levels of this type of architecture are generic and can be stacked at will to obtain the desired network depth.
Our architecture, illustrated in
Figure 2, uses the same standard encoder network as PWC-Net [
44] with the only exception that we add a Domain-Invariant Normalization layer (DINL) [
46] after the first convolutional layer. We use it to increase the robustness of the network to varied colors, contrasts and luminosity conditions without increasing the number of convolutional filters.
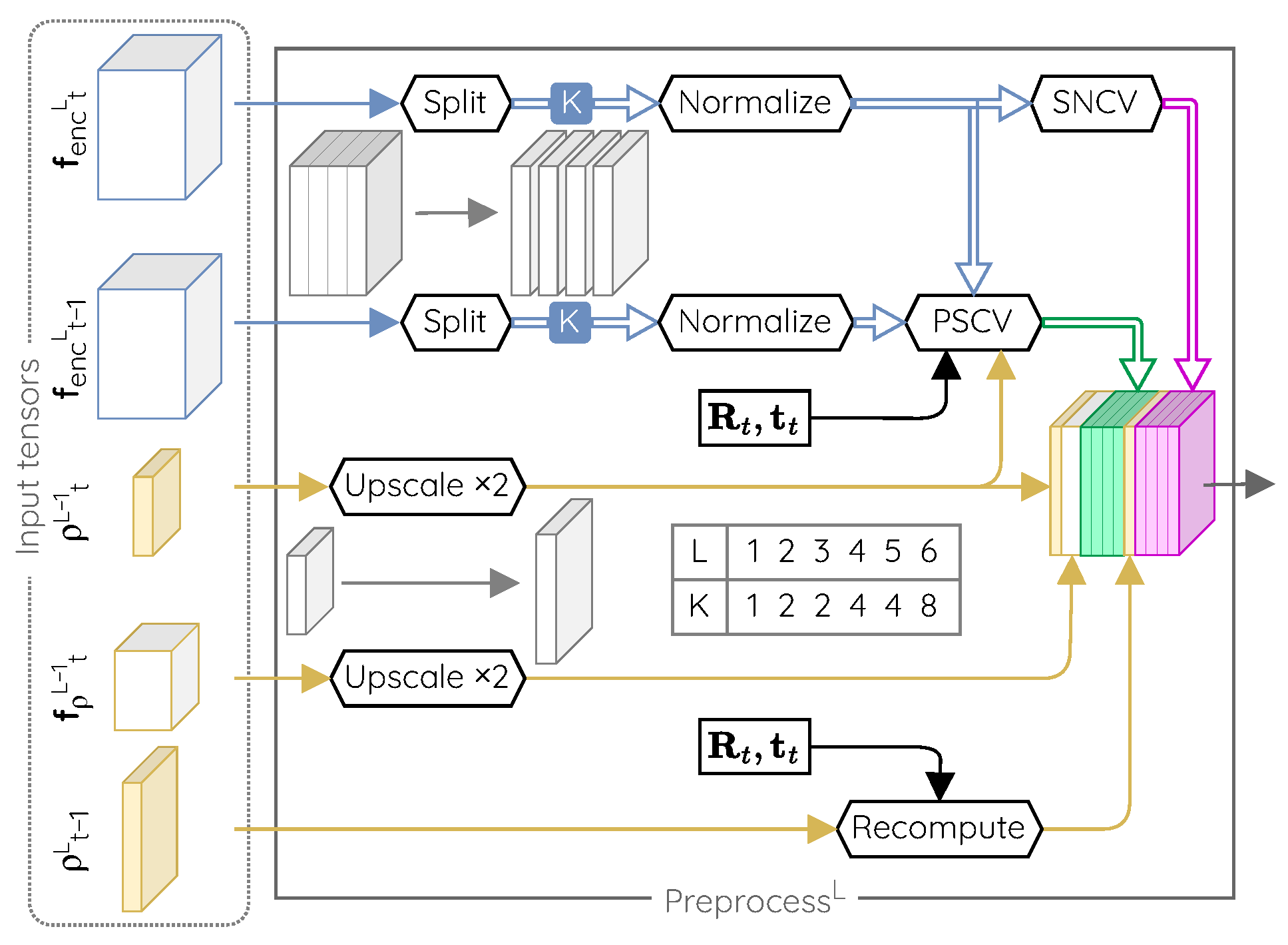
At each level L of the decoder, a small convolutional subnetwork is in charge of refining the parallax map. We named it the parallax refiner. Its inputs are the upscaled parallax estimate made by the previous decoder level in the architecture and a series of preprocessed data generated by a preprocessing unit.
The preprocessing unit is illustrated in
Figure 3. It is made of fixed operations and has no learnable parameters. Its purpose is to prepare the input for the next parallax refiner.
In short, the preprocessor has two main purposes. First, it adapts the vectors of the feature maps produced by the encoders to make the network robust to unknown visual inputs. For that, it uses these data alongside camera motion to build two distinct cost volumes, the Parallax Sweeping Cost Volume (PSCV) and the Spatial Neighborhood Cost Volume (SNCV). Second, it recomputes the parallax estimate obtained for the previous time by adjusting it to the camera motion. These data are then concatenated and forwarded to the parallax refiner.
Description of the Building Blocks of the Preprocessing Unit
In the following, we describe the components of the preprocessing unit and motivate their use.
Split and normalize layers. The use of leaky ReLU activation units in the encoder can lead to feature maps containing plenty of small values. While classification or segmentation networks rely on the raw value of each entry in a feature vector, our network relies on the relative differences between neighboring feature vectors through the use of cost volumes. To achieve good generalization properties, this relative difference should remain significant in all situations. The split and normalize layers ensure that this is the case.
The split layer subdivides feature vectors in K sub-vectors to be processed in parallel in subsequent layers. It provides the network with the ability to decouple the relative importance of specific features within a same vector by assigning them to different sub-vectors.
The normalize layer normalizes the features of a same sub-vector and therefore levels the difference in magnitude of different sub-vectors. This is beneficial for the parallax refiner layers as this normalization leads the outputs of the cost volumes to span to a known pre-defined range. It also allows a full use of the information embedded in sub-vectors whose magnitude is very small because of the leaky ReLU activation units.
Recompute layer. The parallax values estimated by the network are specific to the motion occurring between two given frames. By using the set of equations developed in
Section 4.1 and if the camera motion is known, it is possible to compute the parallax values that should be observed at a given time step from a previous parallax estimate. The purpose of the recompute layer is to update the parallax values estimated for the previous frame to provide a hint in the form of a first estimate of the parallax values for the current frame.
Spatial Neighborhood Cost Volume (SNCV). This cost volume is computed from a single feature map
and is a form of spatial autocorrelation. Each pixel of the cost volume is assigned the costs of matching the feature vector located at the same location in the feature map with the neighboring feature vectors located within a given range
r of the considered location,
where the cost of matching two vectors
and
of dimension
N is defined as their correlation [
48,
49].
The SNCV gives an indication about the two-dimensional spatial structure of the scene captured by the features of the encoder. By design, it is impossible to recover the feature vectors that led to a given cost value. Network parameters trained with this cost metric will therefore be invariant to changes in the input feature vectors if they lead to the same cost value. This can help us to obtain a robust and generalizable depth estimation network, which was not achievable by forwarding the feature map directly.
Parallax Sweeping Cost Volume (PSCV). This cost volume is computed from two consecutive feature maps
and
, and a parallax map estimate
(see left of
Figure 3). For each pixel, the cost volume assigns the cost of matching the feature vector located at the same place in
with the corresponding reprojected feature vectors from
according to:
In that expression, the feature map
is reprojected for a range
of parallax values equally distributed around a given estimate, that is
where
is given by Equation (
10), and
. In this expression,
is interpolated from
since
returns real coordinates, and
ensures the positiveness of the parallax used for computing the reprojection. Each vector element of the cost volume corresponds to one given parallax correction with respect to the provided estimate. Browsing through a range of parallax values for each pixel creates a series of candidates for the corresponding reprojected point. By searching for the reprojected candidate that is the most similar to the visual information observed at time step
t, it is possible to assess which parallax is the most likely to be associated to each pixel.
Building the cost volumes from parallax intervals eliminates the contextual and arbitrary choices required otherwise (i.e., the range and the quantization step). As the parallax is defined within the image space, it is indeed bound to the image resolution. A good step size is therefore always 1 (pixel) and the maximum parallax value that can be encountered is equal to the diagonal of the image (in pixels). Since we are using a pyramidal architecture, a range at the L-th level is equivalent to a range in the original image. By stacking N levels, our architecture can theoretically cover a range of pixels while needing a total of only samples to obtain a pixelwise resolution.
4.3. Loss Function Definition
Since the levels of our architecture are stackable at will, the architecture can have any depth. We now detail our loss function for a network that is made of M levels.
As in previous works [
50,
51,
52], we use a multi-scale loss function. For each frame and each level, we compute the
distance on the logarithm of the depths resulting from the conversion of parallax estimates using Equation (
9). The logarithm leads to a scale invariant loss function [
43] and the use of an
distance is motivated by its good convergence properties [
53]. Since intermediate depth maps have a lower resolution, ground truths are resized by bilinear interpolation to match the dimensions of the estimates. The resulting terms are aggregated through a weighted sum, yielding
The total loss for the sequence is defined as the average of the loss computed for each of its time steps.
5. Experiments
In this section, we present three experiments to analyze the performance of our method. For each of them, we detail the chosen dataset, the training (if appropriate), and discuss the results. Our first and second series of experiments aim to assess the performance in unstructured environments, as driven by our problem statement, and on a standard benchmark, respectively. The experiments present comparisons with baseline methods that might significantly differ, in terms of training procedure, number of parameters, etc. In order to disentangle the intrinsics of the training phase, we have devoted our third series of experiments to generalization tests.
We use the metrics from Eigen et al. [
43] for depth maps capped at 80 m to compare the performance of each method. Additionally, we replicate the experiments performed on M4Depth with PWC-Net [
44] to evaluate the benefits of our proposal over its parent. As PWC-Net is an optical flow network, we use Equation (
1) to obtain the frame-to-frame optical flow from depth and motion for training the network. During testing, we compute depth by assuming that the length of the optical flow vectors corresponds to the visual parallax.
5.1. Unstructured Environments
For our first experiment, we compare the performance of our method with those of the state-of-the-art on a dataset featuring unstructured environments.
Mid-Air dataset. For this experiment, we used Mid-Air [
6]. This synthetic dataset consists of a set of drone trajectories recorded in large, unstructured, and static environments under varied weather and lighting conditions. All trajectories were recorded in different places of the environments, which means that there was little overlap between the visual content of two individual trajectories. This allows one to build a test set whose content is not present in the training set while belonging to the same data distribution. In addition, Mid-Air meets all the assumptions of our problem statement (see
Section 3), which makes it a perfect choice.
The first performance reported on Mid-Air for depth estimation was provided recently by Miclea and Nedevschi [
54]. The authors of this paper do not, however, provide the details required to reproduce their train and test splits and their results. As a result, we have to define our own splits.
The dataset features 192 trajectories. We selected one in three to create our test set, which was more varied than the small test set suggested in the original paper [
6]. The frame rate was subsampled by a factor of four (from 25 to
fps) to increase the apparent motion between two frames. For all our experiments, images and depth maps were resized to a size of
pixels. We used bilinear interpolation to resize color images and the nearest-neighbor method for depth maps.
Training. We used the He initialization [
55] for our variables and the Adam optimizer [
56] for the training itself. We used the default moment parameters for the latter (
,
). The learning rate was set to
. We trained our network with six levels. All our trainings were performed on sequences of four time steps and with a batch size of three sequences. The network was trained on a GPU with
of VRAM for
iterations. After each epoch, we computed the performance of the network on the validation set of the KITTI dataset to avoid any overfitting, and keep a copy of the best set of weights to be used for the tests after the training.
A series of data augmentation steps were performed on each sequence during the training to boost the robustness of our trained network to visual novelties. More precisely, we applied the same random brightness, contrast, hue, and saturation change to all the RGB images of a sequence and the colors of a sequence were inverted with a probability. Finally, we randomly rotated the data of the sequence by a multiple of 90 degrees around the z-axis of the camera when training on Mid-Air. With these settings, a training takes approximately 30 h.
Because of the lack of reproducible performances reported on Mid-Air, we had to train a selection of state-of-the-art methods drawn in
Table 1 to build a baseline. The training details for the chosen methods are given in the
Appendix A. We could not guarantee obtaining the best performance out of DeepV2D [
42] because of the importance of its hyper-parameters and the excessive duration of its training time. We, therefore, decided to discard it for this experiment.
Results. The results are reported in
Table 2. In this table and following tables, the best score for a metric is highlighted in bold and the second best is underlined.
Globally, it appears that M4Depth outperforms the baseline methods. However, it slightly underperforms on the relative performance metrics when compared to PWC-Net. This observation, compared with the excellent performances on other metrics, indicates that our network tends to overestimate depth more often than other methods. A qualitative comparison of the outputs of the different methods is shown in
Figure 4. From this figure, we observe that although M4Depth lacks details in areas with sharp depth transitions, it recovers depth details more accurately than baseline methods, even for challenging scene elements such as forests or unstructured terrain.
5.2. Standard Depth Estimation Benchmark
The purpose of the second experiment was to assess the performance on a standard depth estimation benchmark.
KITTI dataset [14]. Most real datasets that provide RGB+D and motion data focus on cars driving in partially dynamic urban environments [
14,
57,
58]. In this field, KITTI is the reference benchmark dataset when evaluating the performance of a depth estimation method. KITTI is not fully compliant with our problem statement: it has incomplete depth maps, there are some moving objects, and the camera has only three degrees of freedom, etc. Despite that, it is a good practical choice for performing tests on real data.
We used the dataset split proposed by Eigen et al. [
43]. The camera pose was estimated by a combined GPS-inertial unit and was therefore subject to measurement imperfections. Since a few samples were recorded in urban canyons where poor GPS reception induced erratic pose estimates, and as our method requires reliable pose estimates, we discarded these problematic samples from the splits. Additionally, we also subsampled the frame rate by a factor of two (from 10 to 5 fps) to roughly match the one of our Mid-Air sets. Finally, images were resized to
pixels.
Training. For tests on KITTI, we reused the weights of the network with six levels trained on Mid-Air and fine-tuned them for additional iterations on a 50–50% mix of KITTI and Mid-Air samples. The fine-tuning was required to train our network to deal with large areas with poor textures and frame-to-frame illumination changes as these characteristics are not present in Mid-Air. As the ground-truth depth maps for KITTI were generated from Lidar measurements, they were sparse and fine details were missing in the ground truths. Shortcomings created by these imperfections can be mitigated by fine-tuning on both datasets. During the fine-tuning, we also performed random color augmentation on the sequences. With these settings, the fine-tuning takes three hours.
Results. The performance of M4Depth with six levels on the KITTI dataset is reported in
Table 3.
We observe that M4Depth has similar performances to current state-of-the-art methods. As expected, instances with dynamic elements or poor GPS localization lead to degraded performances. These results, however, prove that M4Depth also works with real data despite their imperfections.
An overview of the outputs of our method on KITTI is shown in
Figure 5. M4Depth appears to preserve fine details, and to reliably estimate depth even in areas with less texture or for shiny objects such as cars.
5.3. Generalization
In this last experiment, we wanted to evaluate the generalization capabilities of all the methods. For this, we wanted to use static scenes that were semantically close to either the Mid-Air dataset (natural unstructured environments) or the KITTI dataset (urban environments), and test the performance of the method trained on Mid-Air (respectively KITTI) on the selected unstructured (respectively urban) scenes without any fine-tuning.
As we wanted to focus only on the generalization performance for depth estimation, we bypassed the pose estimation network for ManyDepth and DeepV2D, and used the ground-truth motion to generate the depth maps with these methods. Additionally, the depth maps produced by baseline methods were not guaranteed to be at the correct scale. To alleviate this issue in performance tests, we applied a median scaling to the depth maps of baseline methods.
TartanAir dataset [7]. For this experiment, we used TartanAir. It is a synthetic dataset consisting of trajectories recorded by a free-flying camera in a series of different environment scenes. With each scene being relatively small in size, there is a lot of overlap in the visual content recorded for different trajectories within a same scene. As such, assembling clearly separated train and test sets drawn from the same data distribution is not possible. Despite this drawback, the diversity of the scenes makes TartanAir an interesting choice for testing the generalization capabilities of methods.
For the generalization test from the Mid-Air dataset, we selected the “Gascola” and “season forest winter” scenes of TartanAir and used the weights trained for the baseline. For the one from the KITTI dataset, we selected the “Neighborhood” and “Old Town” scenes and used the pre-trained weights released by the authors of the methods.
We resized the images of this dataset to pixels and subsampled the frame rate by a factor of two. Additionally, some scenes appeared to have large, underexposed areas where there was no color information in the RGB frames. Having large pitch-black areas in an RGB image is unrealistic in practice as cameras dynamically adapt their shutter speed depending on the exposure of the scene. To prevent the errors made by depth estimation methods in these areas from dominating the performance analysis, we discarded all the pixels for which the color in the RGB image had a value equal to zero.
Results. The results of our experiments are reported in
Table 4 and
Table 5. Overall M4Depth outperforms the other methods with a significant margin both for structured and unstructured environments. As on Mid-Air, PWC-Net slightly outperforms M4Depth on some relative metrics, but not for both sequences. It is worth noting that the hierarchy of the performances has completely changed between the test on KITTI and the one in generalization as our method outperforms DeepV2D [
42] on the latter. These results therefore show the better generalization capability of M4Depth when compared to state-of-the-art methods.
The images obtained in generalization on TartanAir are shown in
Figure 6 and
Figure 7. It can be seen that the visual quality of the outputs in generalization is similar to that of the outputs produced on the dataset used for training. This confirms the strong performance of M4Depth in generalization as established with metrics.
Some general observations on the weaknesses of M4Depth can also be made from these outputs. First, the network cannot resolve all the details when the scene is too cluttered. This is especially visible in forest environments where tree branches overlap. Second, sometimes there are issues with sky recognition. This, however, is to be expected as our network mostly relies on perceived frame-to-frame pixel displacement to produce estimates. Finally, small and isolated structures such as cables are not always detected (see the outputs on urban scenes).
5.4. Discussion on the Architecture
Ablation study. We report the average performance over four trainings for ablated versions of our architecture in
Table 6. The results show that the SNCV is the block that leads to the best performance boost. This highlights the benefits of giving some spatial information to the parallax refiners. The other blocks contribute to improve either test or generalization performances, but not both at the same time. As expected, the main contributors to generalization performances are the DINL and the normalization layer.
Increasing the number of levels in the architecture improves the performances. It should be noted, however, that the network tends to overfit the training dataset, therefore leading to worse generalization performance if the network gets too deep.
Overall, this ablation study shows that a compromise between performance on the training dataset and performance in generalization has to be made.
Limitations. With our approach, large areas with no repetitive textures are prone to poor depth estimates. The feature matching performed by our cost volumes matching can indeed become unstable if large areas share exactly the same features. This can therefore lead to bad depth estimates.
We mitigated this issue by using a multi-scale network and by including an SNCV at each of its levels, but these solutions do not make our network totally immune to this issue.
Inference speed. Our network has
million parameters and requires up to 500 MB of GPU memory to run with six levels. At inference time on Mid-Air, an NVidia Tesla V100 GPU needs 17 ms to process a single frame for a raw TensorFlow implementation. This corresponds to 59 frames per second which is roughly twenty-times faster than DeepV2D, the best-performing method on KITTI. According to NVidia’s technical overview [
59], this should translate to 5 fps, at least, on their Jetson TX2 embedded GPU. Such inference speed is compatible with the real-time constraints required for robotic applications and can even be improved with inference optimizers such as TensorRT.
Interpretation of the results. As opposed to other methods, our network is designed to exclusively use the relative difference between feature vectors rather than relying on the raw semantic cues, i.e., the raw value of the feature vectors, to estimate depth. All reference methods, even the ones based on cost volumes, forward the feature maps generated by their encoder directly to their depth estimation subnetwork. Doing so gives networks the ability to use semantic cues directly to estimate depth. This ability is only valuable for instances where the set of features possibly encountered can be encoded by the network and associated to a specific depth.
Our experiments show that reference methods perform well—better than M4Depth for some—on KITTI, the dataset with constrained and structured scenes. However, they fall behind in unstructured environments when the link between semantic cues and depth is weak, and in generalization when semantic cues are different from the reference. This tends to imply that baseline networks rely on the raw feature values to derive depth.
All these observations lead us to believe that severing the direct link between the encoder and the decoder of the architecture while proposing relevant substitute data through the preprocessing unit is the key factor that allows M4Depth to perform so well overall in our experiments.
6. Conclusions
In this paper, we address the challenging task of estimating depth from RGB image sequences acquired in unknown environments by a camera moving with six degrees of freedom. For this, we first define a notion of visual parallax for generic camera motion, which is central for our M4Depth method, and we then show how it can be used to estimate depth. Then, we present new cost volumes designed to boost the performance of the underlying deep neural network of our method.
Three series of experiments were performed on synthetic datasets as well as on the KITTI dataset that features real data. They show that M4Depth is superior to the baseline both in unstructured environments and in generalization while also performing well on the standard KITTI benchmark, which shows its superiority for autonomous vehicles that would need to venture off road. In addition to being motion- and feature-invariant, our method is lightweight and fast enough to be considered for real-time applications.
Our further works on M4Depth will, among others, focus on the determination of its own uncertainty on depth estimates at inference time. Such an addition would provide a great advantage over other methods that do not offer this capability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






