

Attention-Based Scene Text Detection on Dual Feature Fusion
Abstract
:1. Introduction
- (1)
- We propose an attention-based bi-directional feature fusion pyramid model. This is a more efficient approach than previous methods to make up for the shortcomings of lightweight networks ResNet-18 in feature extraction and reduce missed and false detections caused by large differences in text scale, which trades a small increase in computation for better accuracy based on a lightweight and efficient backbone network.
- (2)
- Position-sensitive spatial attention is introduced, focusing on the intermediate features of two-stage feature fusion. Unlike previous methods of attention weighting on multi-scale feature maps, our proposed method focuses on the one feature map with the highest resolution and strongest semantic features in the FPN, which results in better spatial attention weighting and can accommodate both strong and weak responses of texts at different scales.
- (3)
- Experiments on the multi-directional English text dataset ICDAR2015 [4], Chinese dataset CTW1500 [5] and long text dataset MSRA-TD500 [6] demonstrate the effectiveness of the proposed model. The model not only ensures the quality of feature extraction but also achieves a good balance between speed and accuracy due to the lightweight network.
2. Related Work
2.1. Scene Text Detection
2.2. Multi-Scale Feature Fusion
2.3. Attention Mechanism
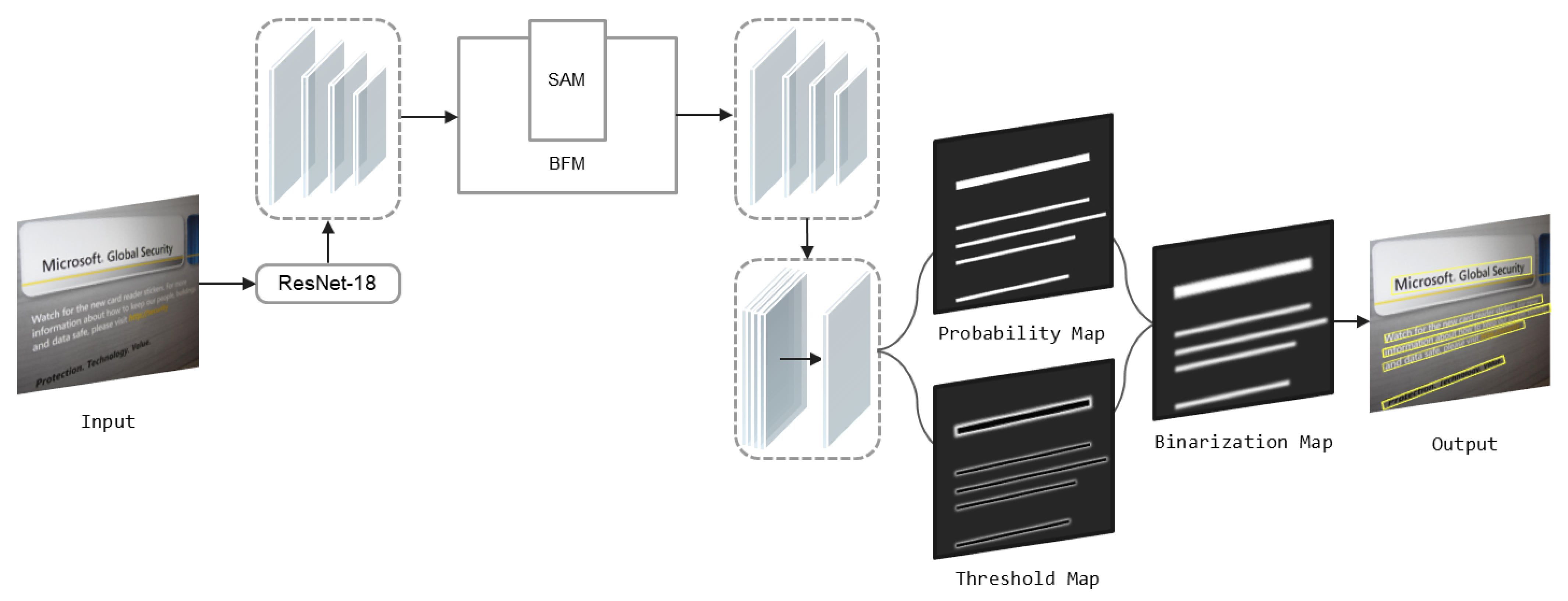
3. Methodology
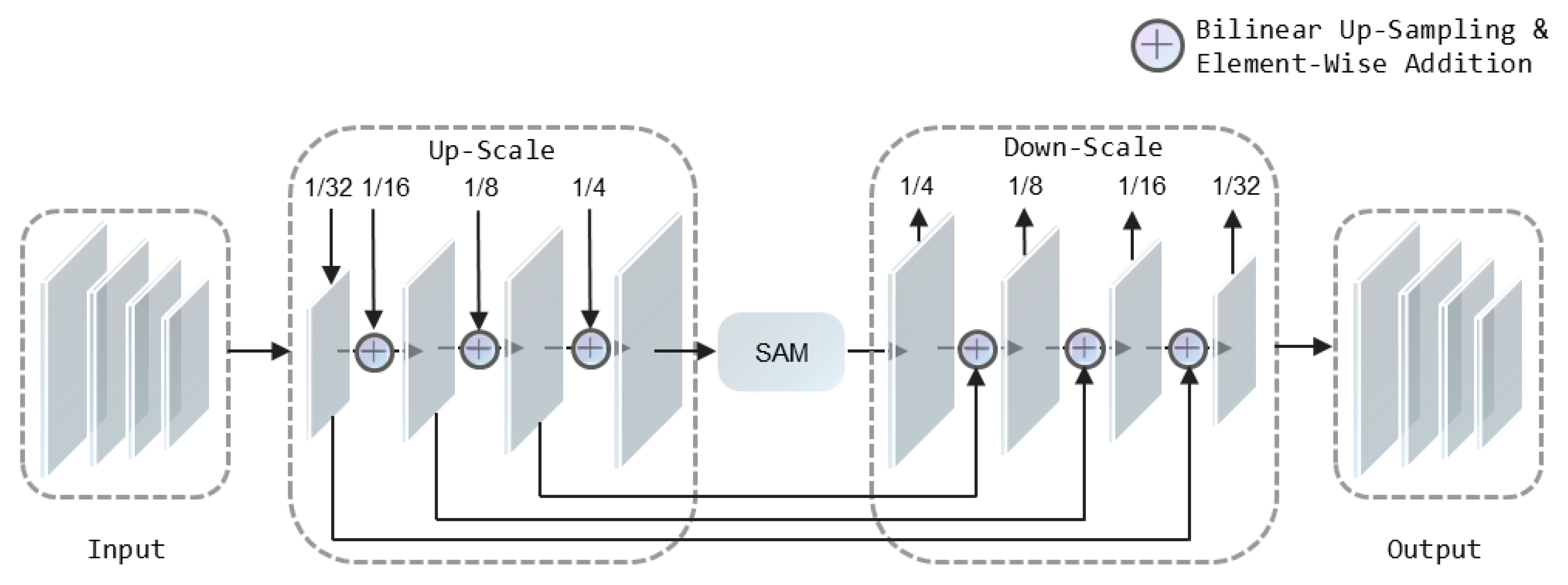
3.1. Bi-Directional Feature Fusion Pyramid Module (BFM)
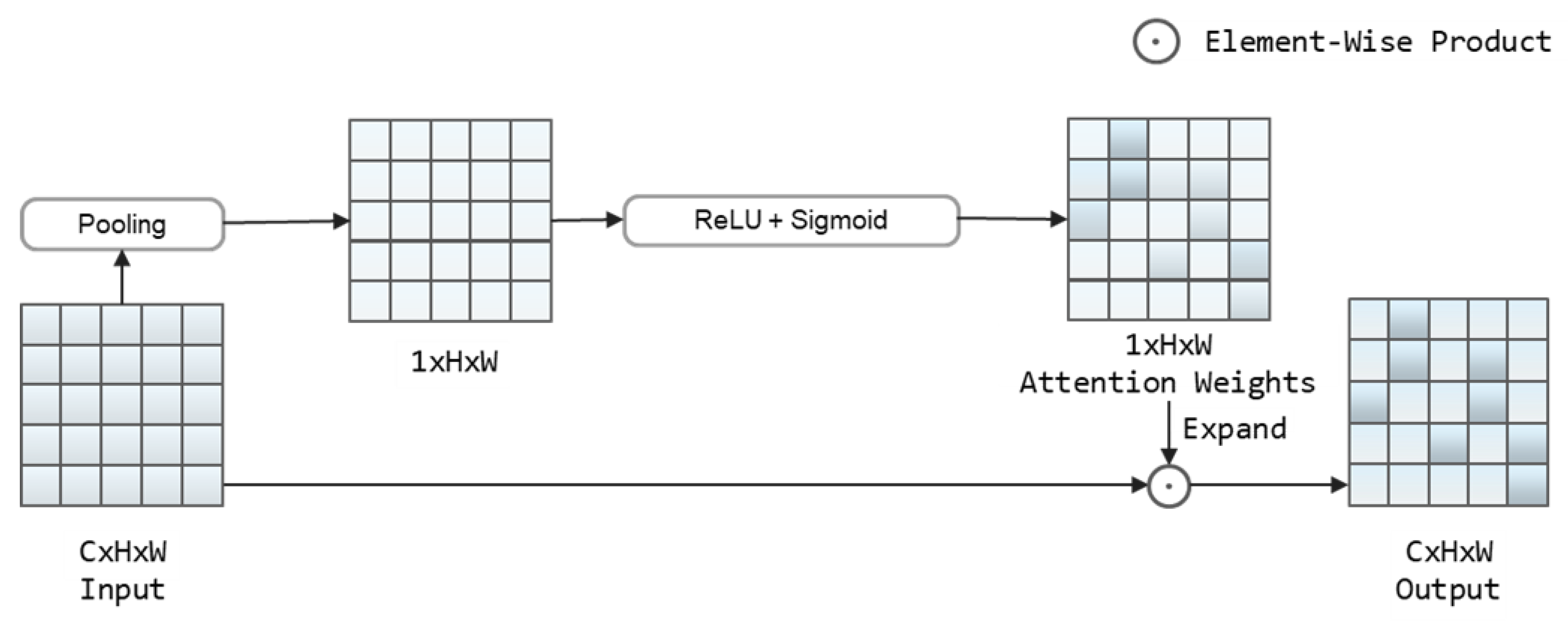
3.2. Spatial Attention Module (SAM)
3.3. Differentiable Binarization (DB)
3.3.1. Binarization
3.3.2. Label Generation
3.3.3. Loss Function
4. Experiments
4.1. Datasets and Experimental Environment
4.2. Ablation Experiments
4.3. Comparison Experiments

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | P (%) | R (%) | F (%) |
|---|---|---|---|
| CTPN [37] | 74.2 | 51.6 | 60.9 |
| EAST | 83.6 | 73.5 | 78.2 |
| PAN | 84 | 81.9 | 82.9 |
| PSENet | 86.9 | 84.5 | 85.7 |
| SPCNet | 88.7 | 85.8 | 87.2 |
| CRAFT [38] | 89.8 | 84.3 | 86.9 |
| ContourNet [39] | 86.1 | 87.6 | 86.9 |
| DBNet (ResNet-18) | 86.8 | 78.4 | 82.3 |
| DBNet++(ResNet-18) | 90.1 | 77.2 | 83.1 |
| Base (ResNet-18) | 88.8 | 72.3 | 79.7 |
| Ours (ResNet-18) | 90.2 | 78.7 | 84.1 |
| PMTD [40] | 91.3 | 87.4 | 89.3 |
| Method | P (%) | R (%) | F (%) |
|---|---|---|---|
| SegLink [41] | 86 | 70 | 77 |
| EAST | 87.3 | 67.4 | 76.1 |
| PAN | 84.4 | 83.8 | 84.1 |
| RRPN | 82 | 68 | 74 |
| CRAFT | 88.2 | 78.2 | 82.9 |
| TextSnake | 83.2 | 73.9 | 78.3 |
| PixelLink | 83 | 73.2 | 77.8 |
| Base (ResNet-18) | 86.3 | 77.4 | 81.6 |
| Ours (ResNet-18) | 87.9 | 78.1 | 82.7 |
| DBNet++(ResNet-18) | 87.9 | 82.5 | 85.1 |
| Method | P (%) | R (%) | F (%) |
|---|---|---|---|
| EAST | 78.7 | 49.1 | 60.4 |
| PAN | 86.4 | 81.2 | 83.7 |
| PSENet | 84.8 | 79.7 | 82.2 |
| CRAFT | 86 | 81.1 | 83.5 |
| TextSnake | 85.3 | 67.9 | 75.6 |
| DBNet (ResNet-18) | 84.8 | 77.5 | 81.0 |
| ContourNet | 84.1 | 83.7 | 83.9 |
| Base (ResNet-18) | 85.8 | 77.2 | 81.3 |
| Ours (ResNet-18) | 87.7 | 78.3 | 82.8 |
| DBNet++(ResNet-18) | 86.7 | 81.3 | 83.9 |
4.4. Visualization Results
5. Conclusions
- (1)
- A location-sensitive spatial attention mechanism, SAM, is proposed, focusing on the intermediate features of the two-stage feature fusion, assigning corresponding location weights to them and highlighting the pixels that contain more significant text features.
- (2)
- BFM is used instead of FPN, and SAM is introduced to the intermediate features of the two-stage feature fusion network of BFM, which reduces the interference of its confounding effect on the strong semantic features at the higher levels in the process of enhancing the weak semantic features at the lower levels. Both of these modules effectively improve the precision of text detection. Even with a lightweight backbone network ResNet-18, our approach can balance detection quality and speed, achieving good coordination between accuracy and efficiency measures.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Naiemi, F.; Ghods, V.; Khalesi, H. Scene text detection and recognition: A survey. Multimed. Tools Appl. 2022, 81, 1–36. [Google Scholar] [CrossRef]
- Ibrayim, M.; Li, Y.; Hamdulla, A. Scene Text Detection Based on Two-Branch Feature Extraction. Sensors 2022, 22, 6262. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 2117–2125. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Valveny, E. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Yuliang, L.; Lianwen, J.; Shuaitao, Z.; Sheng, Z. Detecting curve text in the wild: New dataset and new solution. arXiv 2017, arXiv:1712.02170. [Google Scholar]
- Yao, C.; Bai, X.; Liu, W.; Ma, Y.; Tu, Z. Detecting texts of arbitrary orientations in natural images. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 26 July 2012. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE international Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Nabati, R.; Qi, H. Rrpn: Radar region proposal network for object detection in autonomous vehicles. In Proceedings of the 2019 IEEE International Conference on Image Processing, ICIP, IEEE, Taipei, Taiwan, 26 August 2019; pp. 3093–3097. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes++: A single-shot oriented scene text detector. IEEE Trans. Image Processing 2018, 27, 3676–3690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, M.; Zhu, Z.; Shi, B.; Xia, G.S.; Bai, X. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar]
- He, P.; Huang, W.; He, T.; Zhu, Q.; Qiao, Y.; Li, X. Single shot text detector with regional attention. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3047–3055. [Google Scholar]
- Lyu, P.; Liao, M.; Yao, C.; Wu, W.; Bai, X. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proceedings of the European Conference on Computer Vision, ECCV, Munich, Germany, 8–14 September 2018; pp. 67–83. [Google Scholar]
- Xie, E.; Zang, Y.; Shao, S.; Yu, G.; Yao, C.; Li, G. Scene text detection with supervised pyramid context network. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; 33, pp. 9038–9045. [Google Scholar] [CrossRef] [Green Version]
- Deng, D.; Liu, H.; Li, X.; Cai, D. Pixellink: Detecting scene text via instance segmentation. In Proceedings of the The Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; 32, pp. 6773–6780. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 5551–5560. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W.; He, X.; Wu, W.; Yao, C. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision, ECCV, Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9336–9345. [Google Scholar]
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 February 2022; pp. 8440–8449. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time scene text detection with differentiable binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11474–11481. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, H.; Miao, F.; Chen, Y.; Xiong, Y.; Chen, T. A hyperspectral image classification method using multifeature vectors and optimized KELM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2781–2795. [Google Scholar] [CrossRef]
- Yu, Y.; Hao, Z.; Li, G.; Liu, Y.; Yang, R.; Liu, H. Optimal search mapping among sensors in heterogeneous smart homes. Math. Biosci. Eng. 2023, 2, 1960–1980. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, L.; Zhou, X.; Zhou, Y.; Sun, Y.; Zhu, W.; Zhao, H. Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 2022, 612, 576–593. [Google Scholar] [CrossRef]
- Huang, C.; Zhou, X.; Ran, X.; Liu, Y.; Deng, W.; Deng, W. Co-evolutionary competitive swarm optimizer with three-phase for large-scale complex optimization problem. Inf. Sci. 2022, 619, 2–28. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, ECCV, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 603–612. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27–28 October 2019; pp. 3146–3154. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Liao, M.; Zou, Z.; Wan, Z.; Yao, C.; Bai, X. Real-time scene text detection with differentiable binarization and adaptive scale fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Huang, W.; He, T.; He, P.; Qiao, Y. Detecting text in natural image with connectionist text proposal network. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 56–72. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character region awareness for text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9365–9374. [Google Scholar]
- Wang, Y.; Xie, H.; Zha, Z.J.; Xing, M.; Fu, Z.; Zhang, Y. Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11753–11762. [Google Scholar]
- Liu, J.; Liu, X.; Sheng, J.; Liang, D.; Li, X.; Liu, Q. Pyramid mask text detector. arXiv 2019, arXiv:1903.11800. [Google Scholar]
- Shi, B.; Bai, X.; Belongie, S. Detecting oriented text in natural images by linking segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 2550–2558. [Google Scholar]




| Backbone | BFM | SAM | DB | P (%) | R (%) | F (%) |
|---|---|---|---|---|---|---|
| ResNet-18 | 84.6 | 76.1 | 80.1 | |||
| ResNet-18 | √ | 85.3 | 76.3 | 80.6 | ||
| ResNet-18 | √ | 88.3 | 73.3 | 80.1 | ||
| ResNet-18 | √ | √ | 89.4 | 77.3 | 82.9 | |
| ResNet-18 | √ | √ | 89.2 | 78.3 | 83.4 | |
| ResNet-18 | √ | √ | √ | 89.8 | 78.2 | 83.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Silamu, W.; Wang, Z.; Xu, M. Attention-Based Scene Text Detection on Dual Feature Fusion. Sensors 2022, 22, 9072. https://doi.org/10.3390/s22239072
Li Y, Silamu W, Wang Z, Xu M. Attention-Based Scene Text Detection on Dual Feature Fusion. Sensors. 2022; 22(23):9072. https://doi.org/10.3390/s22239072
Chicago/Turabian StyleLi, Yuze, Wushour Silamu, Zhenchao Wang, and Miaomiao Xu. 2022. "Attention-Based Scene Text Detection on Dual Feature Fusion" Sensors 22, no. 23: 9072. https://doi.org/10.3390/s22239072