4.1.1. Data Description
The dataset was collected from the DDS designed by Spectra Quest, as shown in
Figure 3. This drivetrain consists of a two-stage planetary gearbox, two-stage parallel shaft gearbox with rolling bearings, bearing loader, and programmable magnetic brake.
Based on this drivetrain, we constructed four bearing health conditions by replacing the rolling bearings in the gearbox to simulate the industrial transmission system, as shown in
Figure 4, including health (normal), inner race damage (inner), ball damage (ball), and outer race damage (outer). We applied a torsional load by controlling the 3HP variable frequency AC drive, and the experiments were carried out under 0, 4, 6, and 8 V.
The vibration data were acquired by using SQI608A11-3F unidirectional acceleration sensors which were mounted on both ends of the fixed shaft of the gearbox through bolt connection under different working conditions and at a sampling frequency of 20 kHz. The samples drawn from four different working conditions are: A, B, C, and D, as listed in
Table 1. There were four categories under each domain, and each category had 410,624 data points. We applied a sliding window with a length of 2048 and
overlapping for the pre-processing, and 400 samples were assigned in each category.
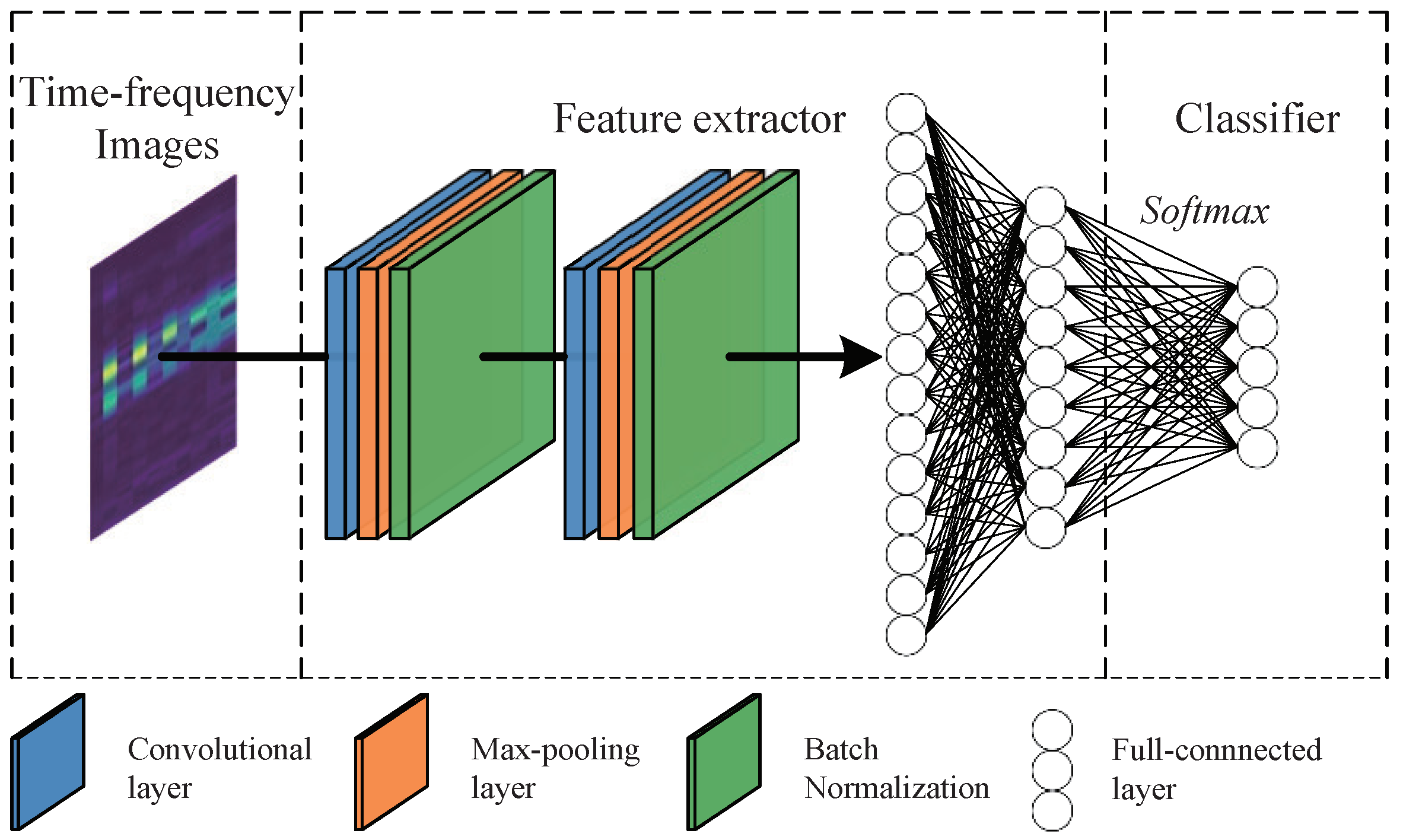
As one of the frequently used time–frequency analysis techniques, short-time Fourier transform (STFT) was applied to all the samples to obtain the corresponding time-varying frequency spectrum information. The Hamming window was used as the window function, the length of the window function was pre-set to 120, and the window overlap was . After converting the time-domain raw vibration signals into time–frequency images by STFT, we acquired images with a size of 64 × 64 × 3, which were input into the feature extractor to train the model.
4.1.3. Parameters of the Proposed Method
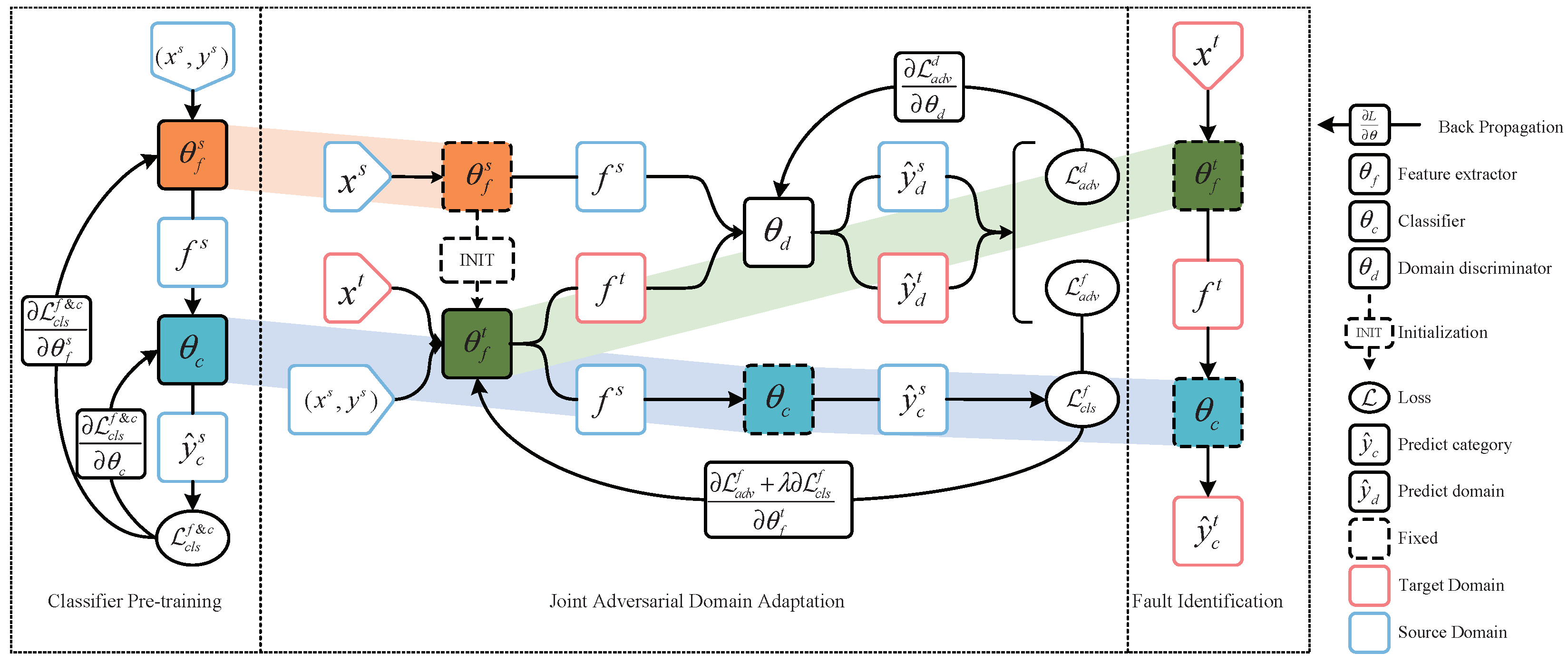
To achieve the best possible result, the parameters and implementation details of the JADA method are mainly determined based on the experiment results and relevant literature. The network is built according to the JADA fault diagnosis model structure described in
Section 3, and the detailed architecture of JADA is listed in
Table 3, which divides the model into four modules according to the functions of each part of the model, i.e., the source feature extractor, target feature extractor, classifier, and discriminator. The source and target feature extractors share the same architecture, which consists of two convolutional layers, two max-pooling layers and two fully connected layers. The input of the feature extractor is time–frequency images as mentioned before, and the output is a feature vector with a size 1 × 128. In addition, both the classifier and discriminator are composed of fully connected layers, and both take the feature vector, output by the feature extractor, as the input.
To improve the efficiency of model optimization, the hyperparameters are set as elaborated below based on the results of multiple experiments.
(1) Classifier pre-training stage: The Adam algorithm is selected as the optimizer, which dynamically adjusts the learning rate via first-order and second-order moment estimations. The initial learning rate is 0.0001, whereas the exponential decay rates of the first-order and second-order moment estimations are 0.9 and 0.999, respectively. Scalar is selected by searching and fixed as .
(2) Joint adversarial adaptation stage: The Adam algorithm is selected to optimize the parameters of the target feature extractor and domain discriminator, where the initial learning rates of the target feature extractor and domain discriminator are 0.0001 and 0.0005, respectively. The exponential decay rates of the first-order and second-order moment estimations are set to 0.9 and 0.999, respectively.
In addition, the batch size is set as 64 for both the above-mentioned stages, whereas the classifier pre-training stage and joint adversarial adaptation stage trained 200 and 1000 iterations, respectively.
The hyperparameter
in Equation (
3) dominates the intra-class variations, and
in Equation (
8) is a trade-off parameter to balance the discrepancy between the marginal distribution and conditional distribution across the domains. Because both of them seriously affect the transfer performance of the JADA, we conducted two experiments to investigate their sensitivities.
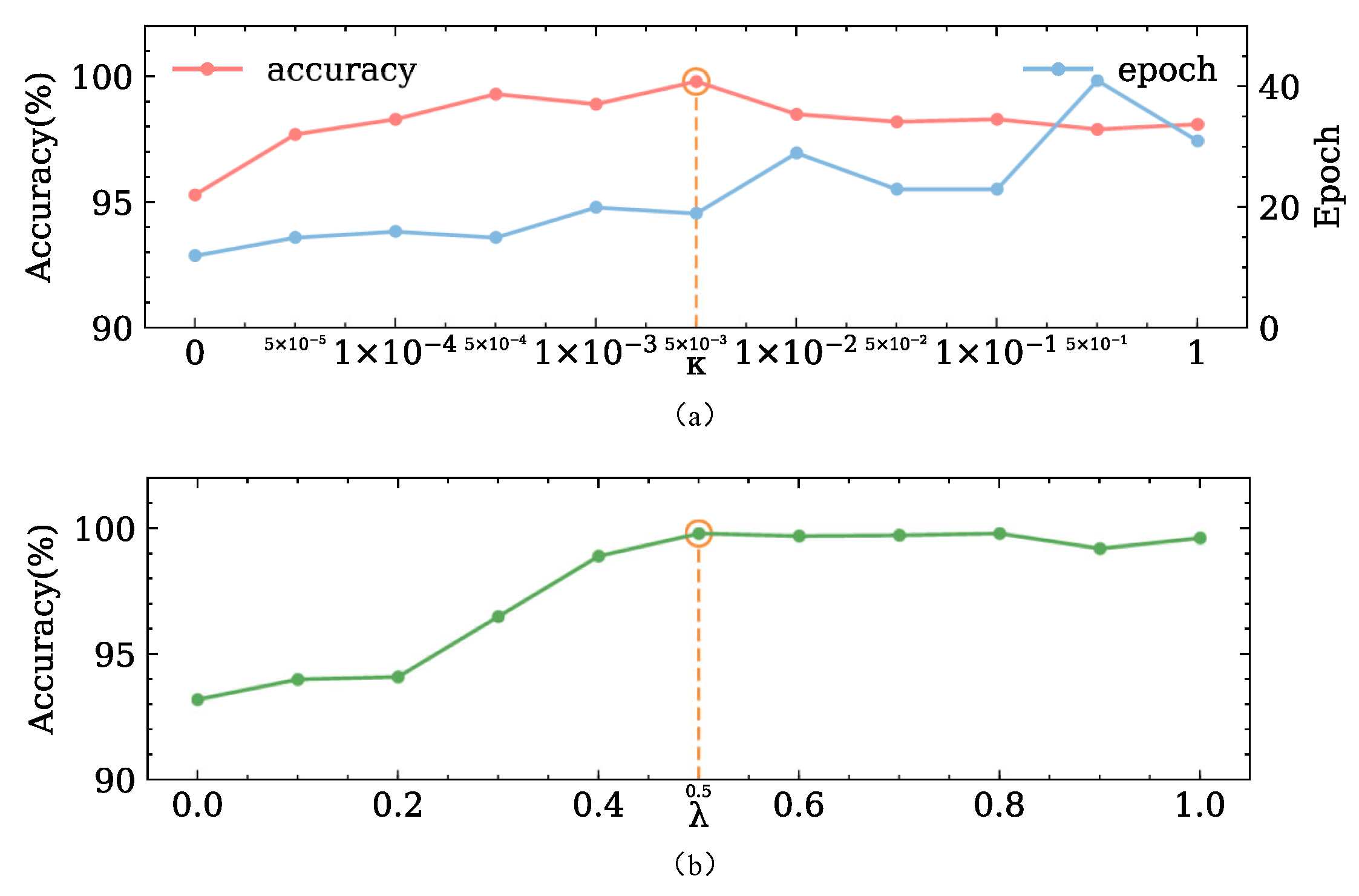
In the first experiment, we fixed
and varied
to evaluate the performance of the learned models. The average classification accuracies of these models on twelve transfer diagnosis tasks are shown in
Figure 5. It is obvious that simply using the cross-entropy loss (in this case,
) results in a poor transfer performance. Properly choosing the value of
can improve the classification accuracies of the JADA. We can observe that the model reaches its peak accuracy when
is set to
.
In the second experiment, we fixed and varied from 0 to 1 to evaluate the performance of the learned models. It is obvious that only adapting the marginal distribution (in this case, ) results in poor classification accuracy, which indicates that the class-wise distribution of the learned features is under-adapted. On the contrary, the model reaches its peak accuracy when is set to 0.5. Moreover, the transfer performance of JADA remains largely stable across a wide range of , which indicates that can balance the contributions of the marginal distribution and conditional distribution adaptations in the loss function.
To achieve the best transfer performance of the JADA, we set and to and 0.5, respectively, based on the aforementioned analysis.
4.1.4. Comparison Methods
To verify the effectiveness of the proposed method, we compared the classification accuracy and transfer performance of the proposed method with those of the other methods, including CNN, Transfer Component Analysis (TCA) [
26], Joint Distribution Adaptation (JDA) [
27], Domain Adversarial Neural Network (DANN) [
28], and Adversarial Discriminative Domain Adaptation (ADDA) [
29]:
(1) CNN: As a benchmark for evaluating the domain-invariant feature learning capabilities of the DA methods, CNN is trained on only the source samples, and then, the trained model is directly applied to the target data. The architecture of the CNN is the same as the backbone of JADA.
(2) TCA: TCA maps the source and target samples into reproducing a kernel Hilbert space using the kernel function to minimize the difference in marginal distribution between the source and target domains while retaining their internal attributes. The optimal subspace dimension is set by searching 4, 8, 16, 32, 64, 128, and the trade-off parameter is searched from 0.01, 0.1, 1, 10, 100, while using the linear kernel [
30].
(3) JDA: JDA can adapt the marginal distribution and conditional distribution between the source and target domains simultaneously, and its hyperparameters are consistent with those of the TCA.
(4) DANN: DANN first leverages the adversarial learning between the domain discriminator and feature extractor to achieve domain-invariant representations, while the gradient reversal layer is introduced to automatically reverse the gradient direction of the domain classification loss during the back propagation process. The backbone architecture of the DANN is the same as that of the proposed method.
(5) ADDA: Tzeng et al. [
28] summarized a general adversarial adaptation (GAN) framework, then proposed ADDA with a GAN-based loss, which learns the feature extractor through adversarial training and realizes the classification of the target samples by sharing the classifier.
For a fair comparison, the hyperparameters of all the aforementioned methods are determined based on experiments and reported literature to obtain the best classification accuracy for each transfer diagnosis task. Every experiment is repeated ten times to report the results for reducing the randomness and singularity. In addition, the network optimization part of the above-mentioned methods uses the Adam algorithm as the optimizer with a set learning rate of 0.0001.
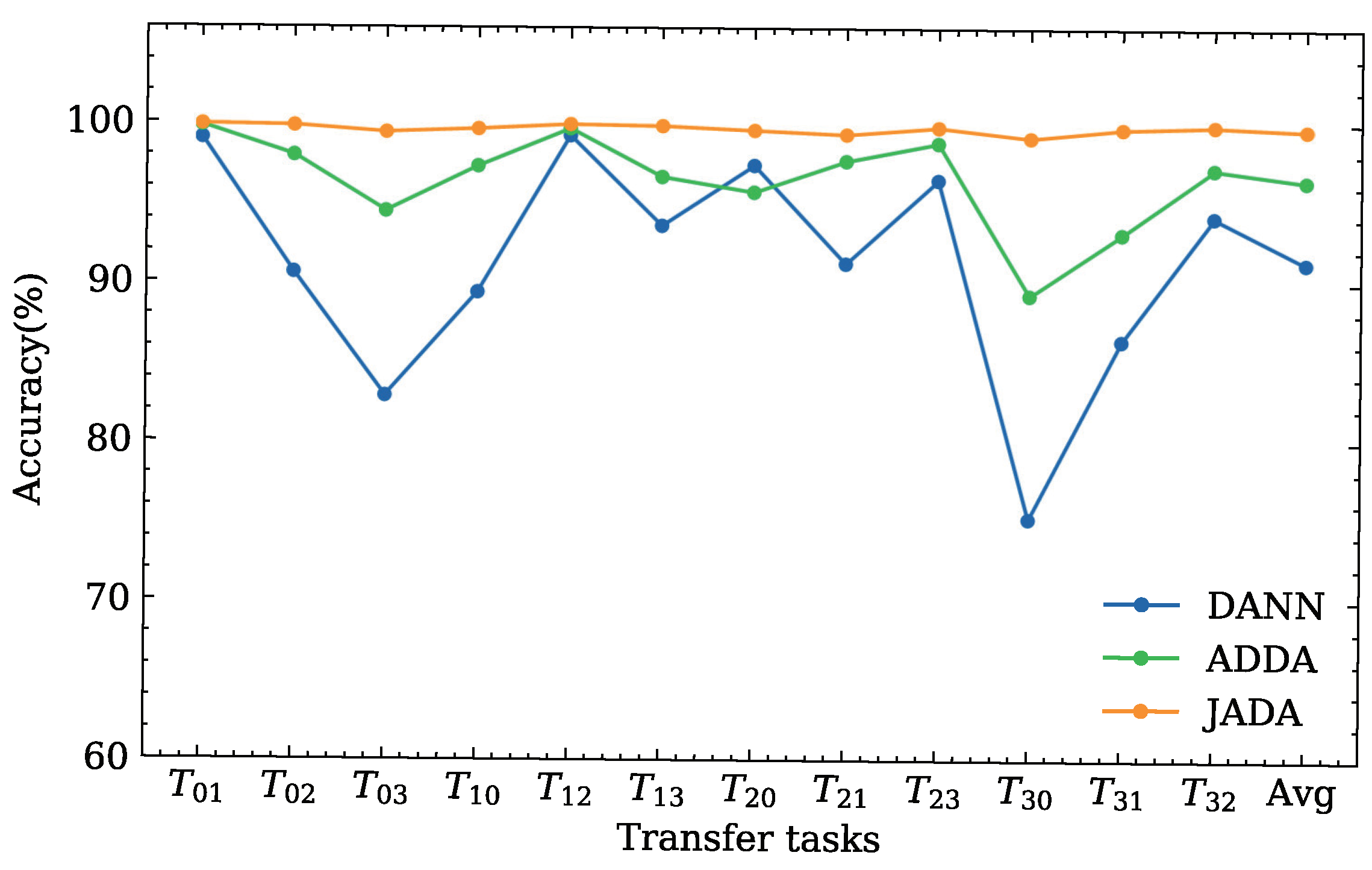
4.1.5. Result Analysis
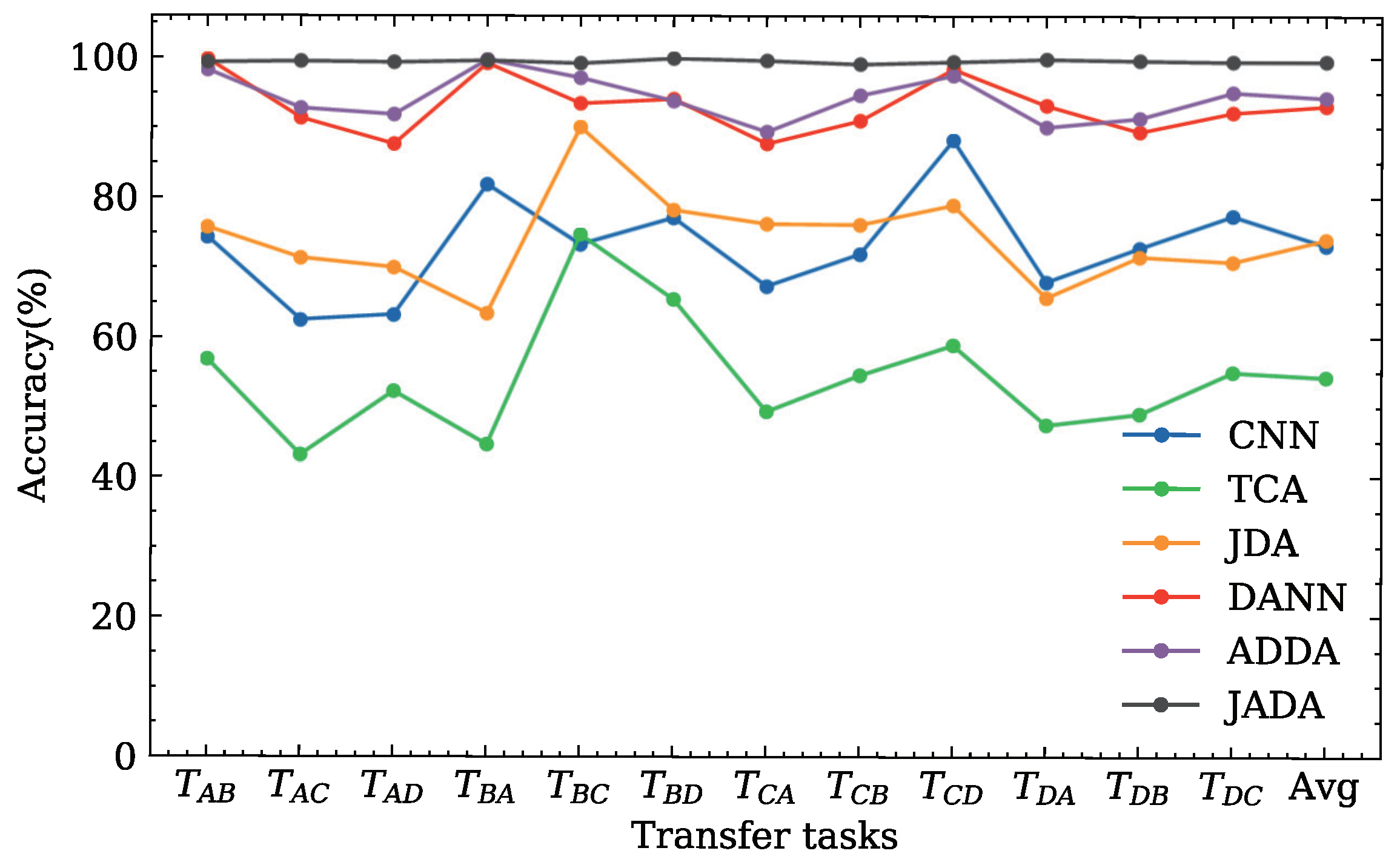
The classification accuracies for twelve transfer diagnosis tasks derived the DDS dataset are illustrated in
Figure 6 and
Table 4.
As evident from the result of the experiment shown in
Figure 6 and
Table 4, the performance of the CNN is poor in every transfer diagnosis task. This indicates that changing the working loads produces a certain effect on the data distribution between the source and target domains.
The traditional transfer learning methods, i.e., TCA and JDA, have poor performance in each transfer diagnosis task with average accuracies of approximately and , respectively. This indicates that the traditional transfer learning methods may be unable to extract the high-level features from the samples and may be unsuitable for dealing with complex transfer diagnosis tasks owing to the lack of a corresponding domain adaptation layer and only considering the probability distribution between the source and target domains.
The adversarial domain adaptation-based methods are superior to the CNN, TCA, and JDA, indicating that the adversarial domain adaptation is significant for practical diagnostic requirements. Among the three adversarial domain adaptation methods, i.e., DANN, ADDA, and JADA, it can be seen that the proposed method achieves the best classification performance according to the average classification accuracy. Although the other comparison methods obtain a higher accuracy compared to the proposed method in several tasks, e.g., ADDA achieves in the transfer diagnosis task , there are large differences in different tasks for these methods. In contrast, JADA can obtain robust results in various transfer diagnosis tasks.
In summary, the proposed method can effectively deal with the transfer diagnosis tasks under varying working conditions.
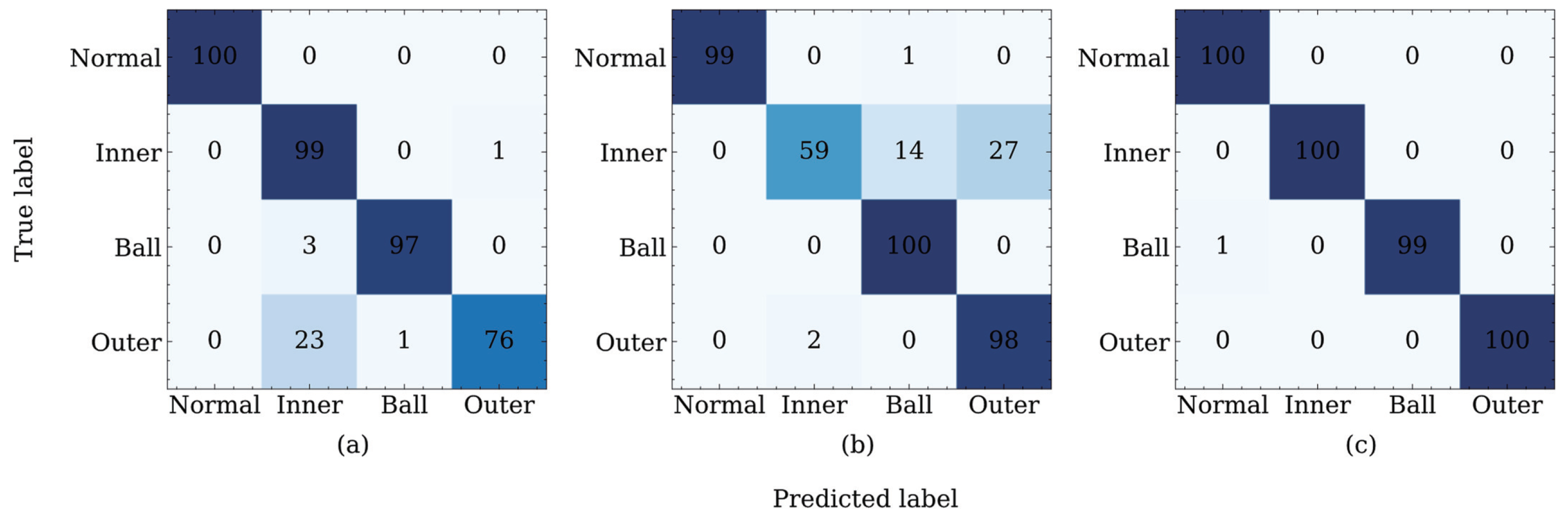
For a detailed analysis of the classification accuracy of each category, we take the transfer diagnosis task
as an example and calculate the confusion matrix corresponding to adversarial domain adaptation methods with a higher average classification accuracy, as shown in
Figure 7.
Figure 7a shows that in addition to the normal category, DANN exhibits different degrees of misclassifications for the other three categories. Among them, the error classification of the outer race damage is the most serious. Twenty-three samples are misclassified as inner race damages and one sample is misclassified as ball damages. The classification accuracy of the ADDA for the outer race damage is higher than that of the DANN, as shown in
Figure 7b. The ADDA method incorrectly categorizes the two samples as inner race damages. However, the ADDA method exhibits a large error when classifying the inner race damages, as shown in
Figure 7b. Only fifty-nine samples are correctly classified, among the total one hundred samples. Consequently, according to the confusion matrix shown in
Figure 7c, the proposed JADA method can correctly classify the categories of normal, inner, and outer. Furthermore, there is only one misclassification in the sample, whose category is ball. In general, the classification accuracy of the JADA method in each category is close to or reaches
, and the number of misclassification samples is far lower than those in the DANN and ADDA methods; this result verifies the superiority of the JADA over these other methods.
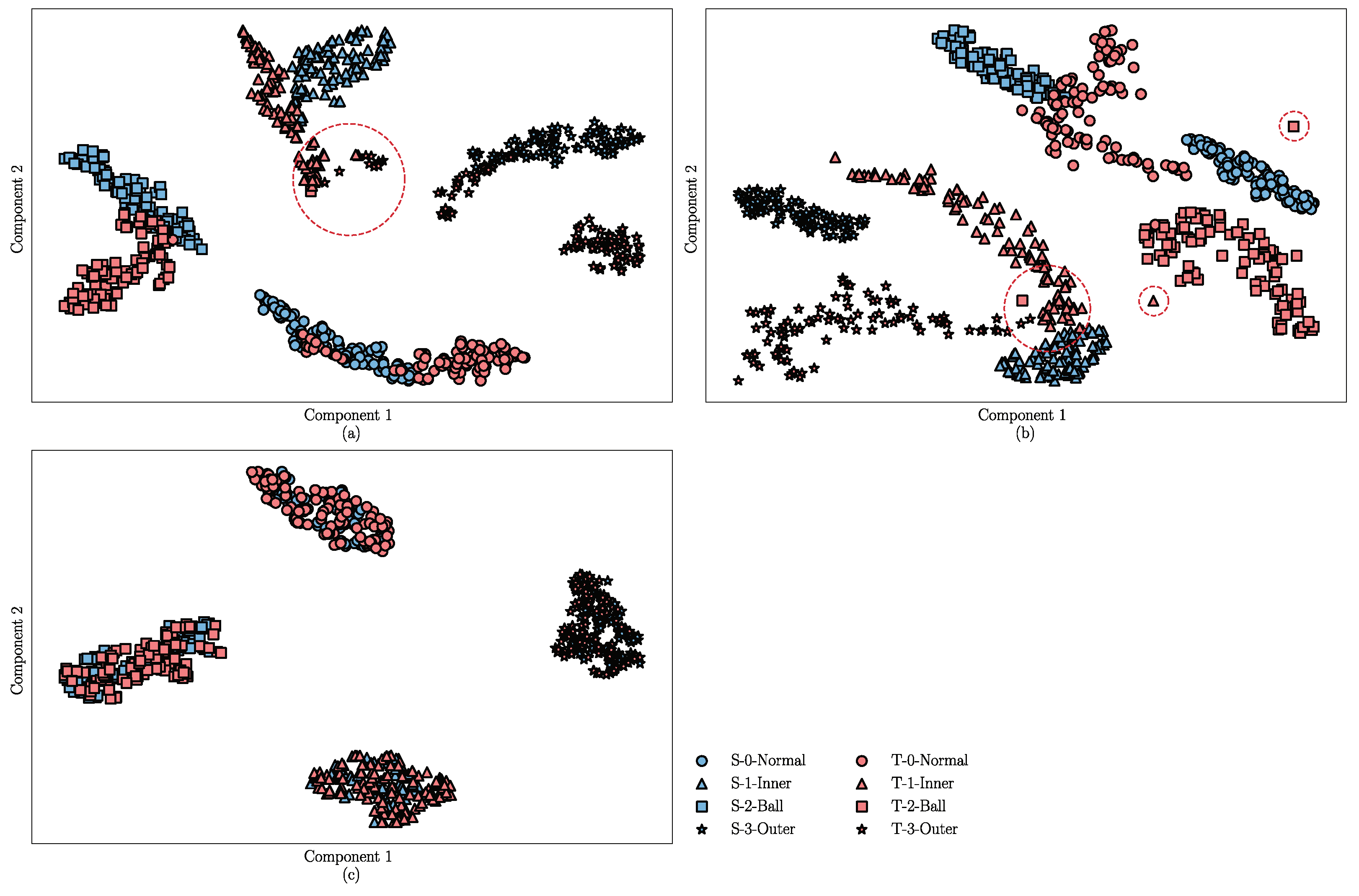
For a visual analysis of the DA and fault diagnosis performance of the DANN, ADDA, and the proposed method, the t-distributed stochastic neighbor embedding (t-SNE) algorithm [
31] is introduced to reduce the dimension of the learned features and plot their distribution into a two-dimensional space according to the similarity. In this part, the feature extractor of the trained DANN, ADDA, and JADA methods are fixed, and then the target samples are used as the inputs. The learned features are shown in
Figure 8a–c, where blue represents the source samples and red represents the target samples. Four different shapes are used to distinguish between the different categories of the samples.
The results shown in
Figure 8a indicate that the features learned by the DANN exhibit good distinguishability in the source samples, however, there is a certain difference in the distribution of the target and source domains. Moreover, the features in the target domain are not well separated, and there are a few misclassifications, as shown in the red dashed circle in
Figure 8a. The visualization results of the ADDA are shown in
Figure 8b, where the boundary between the source domain features is clear, but there are several confusion and misclassifications in the target domain, as shown in the red dashed circle in
Figure 8b. In addition, there is a huge discrepancy in the feature distribution between the source and target domains, possibly because the ADDA method ignores the discrepancy in the conditional distribution between the source and target samples.
Figure 8c indicates that the learned transferable features are subject to smaller distribution discrepancies compared to those shown in
Figure 8a,b, and the features of the source and target domains from the same category are densely clustered, which indicates that the proposed JADA can correct the distribution discrepancy between the features that are learned from the different domains. The result visually proves that the JADA method has a better transfer performance compared to the other methods.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}