
Domain Adaptive Hand Pose Estimation Based on Self-Looping Adversarial Training Strategy
Abstract
:1. Introduction
- We designed a new unsupervised domain adaptive model for hand pose estimation, which designed self-looping adversarial training strategy to bridge the gap between synthetic and real-world images.
- A new self-looping adversarial training strategy was designed to learn domain-invariant features more efficiently, which can lead to more accurate pseudo labels generated by the teacher network.
- Achieving state-of-the-art performance on H3D and STB real-world datasets demonstrates that self-looping adversarial training strategies can effectively reduce domain differences.
2. Related Work
2.1. Hand Pose Estimation
2.2. Unsupervised Domain Adaptation
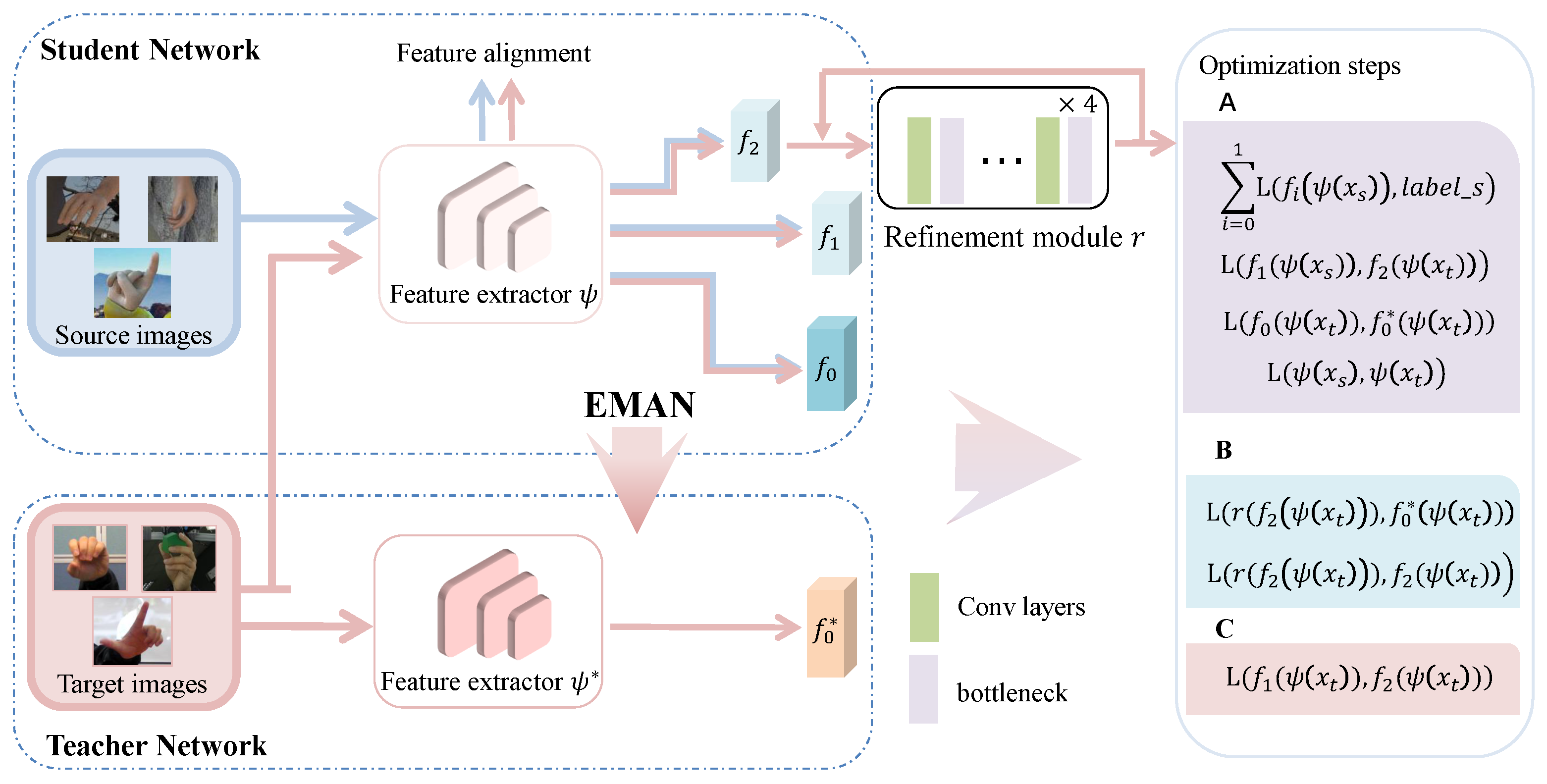
3. The Proposed Method
3.1. Multi-Branch Domain Adaptation Module
3.2. Self-Looping Adversarial Training
3.3. Training Process
4. Experiments
4.1. Datasets and Metrics
4.2. Implementation Details
4.3. Main Results
4.4. Ablation Study
5. Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Tao, D. Empowering Things with Intelligence: A Survey of the Progress, Challenges, and Opportunities in Artificial Intelligence of Things. IEEE Internet Things J. 2020, 8, 7789–7817. [Google Scholar] [CrossRef]
- Yang, J.; Yuan, J.; Li, Y. Parsing 3D motion trajectory for gesture recognition. J. Vis. Commun. Image Represent. 2016, 38, 627–640. [Google Scholar] [CrossRef]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3D hand shape and pose estimation from a single RGB image. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhu, C.; Yang, J.; Shao, Z.; Liu, C. Vision based hand gesture recognition using 3D shape context. IEEE/CAA J. Autom. Sin. 2021, 8, 1600–1613. [Google Scholar] [CrossRef]
- Baek, S.; Kim, K.I.; Kim, T.K. Weakly-supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses Interacting Objects. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yang, J.; Zhu, C.; Yuan, J. Real time hand gesture recognition via finger-emphasized multi-scale description. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME’17), Hong Kong, China, 10–14 July 2017; pp. 631–636. [Google Scholar]
- Pan, T.; Wang, Z.; Fan, Y. Optimized convolutional pose machine for 2D hand pose estimation. J. Vis. Commun. Image Represent. 2022, 83, 103461. [Google Scholar] [CrossRef]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Zhang, J.; Chen, Z.; Tao, D. Towards High Performance Human Keypoint Detection. Int. J. Comput. Vis. (IJCV) 2021, 129, 2639–2662. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, Q.; Zhang, J.; Tao, D. ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]
- Vishwakarma, D. A Two-fold Transformation Model for Human Action Recognition using Decisive Pose. Cogn. Syst. Res. 2019, 61, 1–13. [Google Scholar] [CrossRef]
- Lu, D.; Yong, W.; Robert, L.; Dan, H.; Shan, F. A CNN model for real time hand pose estimation. J. Vis. Commun. Image Represent. 2021, 79, 103200. [Google Scholar]
- Vazquez, D.; Lopez, A.M.; Marin, J.; Ponsa, D.; Geronimo, D. Virtual and real world adaptation for pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2014, 36, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-supervised 3d hand pose estimation from monocular rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 666–682. [Google Scholar]
- Zimmermann, C.; Brox, T. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, C.; Lee, G.H. From Synthetic to Real: Unsupervised Domain Adaptation for Animal Pose Estimation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Jiang, J.; Ji, Y.; Ximei Wang, Y.L.; Wang, J.; Long, M. Regressive Domain Adaptation for Unsupervised Keypoint Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Mueller, F.; Bernard, F.; Sotnychenko, O.; Mehta1, D. GANerated Hands for Real-Time 3D Hand Tracking from Monocular RGB. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Y.; Chen, L.; Liu, Y.; Yong, J.; Zheng, W. Adaptive Wasserstein Hourglass for Weakly Supervised Hand Pose Estimation from Monocular RGB. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2076–2084. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Conference and Workshop on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Jin, R.; Zhang, J.; Yang, J.; Tao, D. Multi-Branch Adversarial Regression for Domain Adaptative Hand Pose Estimation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6125–6136. [Google Scholar] [CrossRef]
- Zhao, Z.; Wang, T.; Xia, S.; Wang, Y. Hand-3d-studio: A new multi-view system for 3d hand reconstruction. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2478–2482. [Google Scholar]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. A hand pose tracking benchmark from stereo matching. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Vishwakarma, D.; Maheshwari, R.; Kapoor, R. An Efficient Approach for the Recognition of Hand Gestures from Very Low Resolution Images. In Proceedings of the 2015 Fifth International Conference on Communication Systems and Network Technologies, Gwalior, India, 4–6 April 2015; pp. 467–471. [Google Scholar] [CrossRef]
- Huang, Y.; Yang, J. A multi-scale descriptor for real time RGB-D hand gesture recognition. Pattern Recognit. Lett. 2021, 144, 97–104. [Google Scholar] [CrossRef]
- Vishwakarma, D.; Kapoor, R. An Efficient Interpretation of Hand Gestures to Control Smart Interactive Television. Int. J. Comput. Vis. Robot. 2017, 7, 454–471. [Google Scholar] [CrossRef]
- He, Y.; Yang, J.; Shao, Z.; Li, Y. Salient feature point selection for real time RGB-D hand gesture recognition. In Proceedings of the 2017 IEEE International Conference on Real-time Computing and Robotics (RCAR), Okinawa, Japan, 14–18 July 2017; pp. 103–108. [Google Scholar]
- Vishwakarma, D.K. Hand gesture recognition using shape and texture evidences in complex background. In Proceedings of the 2017 International Conference on Inventive Computing and Informatics (ICICI), Coimbatore, India, 23–24 November 2017; pp. 278–283. [Google Scholar] [CrossRef]
- Wu, M.Y.; Ting, P.W.; Tang, Y.H.; Chou, E.T.; Fu, L.C. Hand pose estimation in object-interaction based on deep learning for virtual reality applications. J. Vis. Commun. Image Represent. 2022, 70, 102802. [Google Scholar] [CrossRef]
- Li, M.; Wang, J.; Sang, N. Latent Distribution-based 3D Hand Pose Estimation from Monocular RGB Images. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4883–4894. [Google Scholar] [CrossRef]
- Guo, S.; Rigall, E.; Qi, L.; Dong, X.; Li, H.; Dong, J. Graph-Based CNNs With Self-Supervised Module for 3D Hand Pose Estimation From Monocular RGB. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1514–1525. [Google Scholar] [CrossRef]
- Vishwakarma, D.; Grover, V. Hand gesture recognition in low-intensity environment using depth images. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 429–433. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, C.; Liu, Y. Mask-Pose Cascaded CNN for 2D Hand Pose Estimation From Single Color Image. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3258–3268. [Google Scholar] [CrossRef]
- Spurr, A.; Song, J.; Park, S.; Hilliges, O. Cross-Modal Deep Variational Hand Pose Estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 89–98. [Google Scholar] [CrossRef] [Green Version]
- Wan, C.; Probst, T.; Van Gool, L.; Yao, A. Crossing Nets: Combining GANs and VAEs with a Shared Latent Space for Hand Pose Estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1196–1205. [Google Scholar] [CrossRef] [Green Version]
- Dibra, E.; Wolf, T.; Oztireli, C.; Gross, M. How to Refine 3D Hand Pose Estimation from Unlabelled Depth Data? In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 135–144. [Google Scholar] [CrossRef]
- Yang, L.; Yao, A. Disentangling Latent Hands for Image Synthesis and Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9869–9878. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Lu, S.; Guan, D.; Zhang, X. Contextual-Relation Consistent Domain Adaptation for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 705–722. [Google Scholar]
- Gong, R.; Chen, Y.; Paudel, D.P.; Li, Y.; Chhatkuli, A.; Li, W.; Dai, D.; Gool, L.V. Cluster, Split, Fuse, and Update: Meta-Learning for Open Compound Domain Adaptive Semantic Segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Kim, Y.; Hong, S. Adaptive Graph Adversarial Networks for Partial Domain Adaptation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 172–182. [Google Scholar] [CrossRef]
- Liu, G.; Wu, J. Unsupervised person re-identification by Intra–Inter Camera Affinity Domain Adaptation. J. Vis. Commun. Image Represent. 2021, 80, 103310. [Google Scholar] [CrossRef]
- Li, H.; Pan, S.J.; Wang, S.; Kot, A.C. Domain Generalization with Adversarial Feature Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5400–5409. [Google Scholar] [CrossRef]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3752–3761. [Google Scholar] [CrossRef]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096-2030. [Google Scholar]
- Zhang, Y.; Liu, T.; Long, M.; Jordan, M. Bridging theory and algorithm for domain adaptation. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 7404–7413. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle Consistent Adversarial Domain Adaptation. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. (JMLR) 2008, 9, 2579–2605. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MCP | PIP | DIP | Fingertip | Avg |
|---|---|---|---|---|---|
| Res101 [8] | 67.4 | 64.2 | 63.3 | 54.8 | 61.8 |
| MCD [46] | 59.1 | 56.1 | 54.7 | 46.9 | 54.6 |
| DD [48] | 72.7 | 69.6 | 66.2 | 54.4 | 65.2 |
| DANN [47] | 67.3 | 62.6 | 60.9 | 51.2 | 60.6 |
| Cyclegan [49] | 63.8 | 63.6 | 61.3 | 53.5 | 60.1 |
| Mean-teacher [22] | 72.6 | 71.2 | 67.1 | 59.4 | 66.8 |
| RegDA [19] | 79.6 | 54.4 | 71.2 | 62.9 | 72.5 |
| MarsDA [23] | 87.7 | 85.8 | 80.7 | 70.1 | 80.6 |
| Our | 87.2 | 86.2 | 80.8 | 72.5 | 81.3 |
| Oracle | 97.7 | 97.2 | 95.7 | 92.5 | 95.8 |
| Method | MCP | PIP | DIP | Fingertip | Avg |
|---|---|---|---|---|---|
| Res101 [8] | 67.6 | 65.4 | 65.9 | 59.9 | 63.1 |
| MCD [46] | 58.1 | 56.3 | 55.4 | 46.7 | 54.9 |
| DD [48] | 62.5 | 70.1 | 68.5 | 71.9 | 68.4 |
| DANN [47] | 68.1 | 64.1 | 65.1 | 59.2 | 63.1 |
| Cyclegan [49] | 58.2 | 58.5 | 57.9 | 58.9 | 58.1 |
| Mean-teacher [22] | 68.9 | 71.2 | 69.7 | 67.2 | 68.9 |
| RegDA [19] | 67.4 | 79.6 | 75.4 | 73.8 | 73.6 |
| MarsDA [23] | 75.7 | 84.7 | 81.2 | 83.5 | 80.2 |
| Our | 79.8 | 89.1 | 84.9 | 76.8 | 82.4 |
| Oracle | 93.9 | 93.0 | 93.8 | 94.4 | 93.4 |
| Method | MCP | PIP | DIP | Fingertip | Avg |
|---|---|---|---|---|---|
| Source only | 67.4 | 64.2 | 63.3 | 54.8 | 61.8 |
| +RD | 79.6 | 74.4 | 71.2 | 62.9 | 72.5 |
| +SAT | 82.5 | 77.2 | 73.5 | 63.4 | 74.7 |
| +RD+MT | 82.6 | 82.2 | 79.1 | 67.4 | 76.3 |
| +RD+MT+FA | 85.4 | 84.6 | 79.9 | 67.6 | 78.9 |
| +SAT+MT+FA | 87.2 | 86.2 | 80.8 | 72.5 | 81.3 |
| Method | 0–10 | 10–20 | 20–30 | 30–40 | 40–50 | 50–60 | 60–70 | 70–80 | 80–90 | 90–100 |
|---|---|---|---|---|---|---|---|---|---|---|
| RegDA | 1.471 | 0.367 | 0.247 | 0.405 | 0.376 | 0.196 | 0.726 | 1.087 | 1.432 | 0.450 |
| MarsDA | 1.578 | 0.378 | 0.216 | 0.196 | 0.659 | 0.714 | 0.565 | 0.848 | 1.188 | 0.594 |
| Our | 1.308 | 0.251 | 0.194 | 0.346 | 0.162 | 0.064 | 0.084 | 0.089 | 0.065 | 0.070 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, R.; Yang, J. Domain Adaptive Hand Pose Estimation Based on Self-Looping Adversarial Training Strategy. Sensors 2022, 22, 8843. https://doi.org/10.3390/s22228843
Jin R, Yang J. Domain Adaptive Hand Pose Estimation Based on Self-Looping Adversarial Training Strategy. Sensors. 2022; 22(22):8843. https://doi.org/10.3390/s22228843
Chicago/Turabian StyleJin, Rui, and Jianyu Yang. 2022. "Domain Adaptive Hand Pose Estimation Based on Self-Looping Adversarial Training Strategy" Sensors 22, no. 22: 8843. https://doi.org/10.3390/s22228843