1. Introduction
Deep learning (DL), or deep structured learning (DSL), is part of machine learning (ML), which is based on artificial neural networks (ANN). There are three different types of learning that can be used: supervised, semi-supervised, and unsupervised [
1,
2,
3]. Moreover, for each of the named types, a novel research field consists of their hardware acceleration [
4,
5,
6]. This means that there is a need for improved and efficient machine learning systems.
The architecture of DL, which has been applied to different fields such as computer vision, drug design, image processing, board game programs, medical image processing, driver identification, etc., such as deep neural networks (DNN), deep reinforcement learning (DRL), convolutional neural networks (CNN), etc. [
7,
8,
9,
10,
11,
12].
With the ongoing development of deep learning, computer vision has made significant progress and is now applicable to online situations. One of the current subtasks of computer vision is object recognition. It is widely used in intelligent transportation applications such as motorized and non-motorized vehicle detection, pedestrian detection, and self-driving cars. This study, which focuses on traffic sign recognition, is critical for creating highly accurate maps for driverless automobiles. Traffic signs are widely scattered in real traffic situations, and weather conditions, such as fog, rain, and snow, can also affect recognition accuracy. In this case, it is undoubtedly fatal for drivers and pedestrians. Therefore, it is especially important to enhance traffic sign detection performance in a variety of complicated situations [
13].
Researchers’ contributions to convolutional neural networks have helped computer vision advance quickly in recent years. Prior to CIFAR [
9], only small, low-resolution datasets could be used to train neural networks for classification tasks. Then, Alex et al. [
9] presented AlexNet to accomplish the classification task in sizable datasets such as ImageNet [
14]. AlexNet consists of convolutional and fully connected layers. Following that, scientists suggested networks with more layers, such as VGG [
15], which somewhat increased the accuracy of networks. At a certain depth, the gradient will, however, diminish or disappear. In order to ensure that deeper network layers can obtain no fewer features than shallower network layers, He et al. [
16] proposed ResNet, which uses cross-layer connections to fuse the input with the output of the residual blocks. This effectively prevents the phenomenon of insignificance or even the disappearance of deeper features. By modifying the depth, width, and input image resolution of the network model, the majority of the earlier networks enhance network performance. In order to combine the three factors, Tan et al. [
17] introduced EfficientNet, which first constructed an ideal benchmark and then modified the benchmark network based on various scaling factors.
In deep learning, a CNN (or ConvNet) is one of the ANNs, most commonly applied to analyzing visual imagery [
18]. It is a regularization of multilayer perceptrons. It usually means fully connected networks. It means that the neurons in one layer are fully connected to all the neurons in the next layer.
In CNNs, to make complex patterns, they make simpler patterns by assembling them, so in terms of connectivity and complexity, CNNs are on the lower extreme. Another important advantage in comparison with other image processing algorithms is preprocessing. This means that the filters learn to optimize through automated learning. This independence from prior knowledge and human intervention in feature extraction is a major advantage.
A very good example of DL is driver identification. Simply, according to claims, the Intelligent Transportation System (ITS) will transform travel by enhancing people’s safety, security, and comfort. Although some vehicles are automated, there are still serious security concerns that need careful investigation and cutting-edge solutions. The attacker can steal the vehicle thanks to ITS’s security flaws. Therefore, in order to create a safe and secure system and safeguard the vehicles from theft, the identification of drivers is necessary. A driver can be recognized in two ways: (1) by face recognition of the driver, and (2) based on driving behavior. Face recognition involves processing 2-D images for images and learning the features, both of which need a lot of processing power.
Traffic sign recognition has two varying approaches that have been utilized by researchers in recent years. One-stage networks, such as R-FCN [
19], Faster R-CNN [
20], Mask R-CNN [
21], etc., and two-stage networks, such as YOLO [
22] and SSD [
23], improve the speed and accuracy of detection and classification. Both strategies have pros and cons and can be used differently. One-stage detectors, such as YOLO, are great for identifying small objects, but they struggle with large numbers of classes or classes that are identical to one another. When the traffic sign is too far away, blurry, or partially covered by other objects, the accuracy of the two-stage detectors drops dramatically [
24,
25,
26].
2. Structure of Different CNN Models
The most important models of CNNs are ResNet, XRexNet, DenseNet, VGG, SqueezeNet, and AlexNet. ResNets are one of the powerful systems for deep learning that were presented by Kaiming He et al. [
16]. He has achieved the training system with good performance. As a result, ResNet became one of the most widely used systems for computer vision tasks. The important idea of ResNet is to introduce residual blocks that include an “identity shortcut connection” that skips one or more layers, as shown in
Figure 1.
This residual block changes the goal of the stacked layers from fitting the ideal weights and biases H(x) to fitting the output of the ResBlock, H(x) = F(x) + x [
17].
The CNNs begin with an input, which is followed by four different stages, and each stage has similar patterns.
With increasing the size of the ResNet, the accuracy of the prediction and also the time of the training will increase. The architecture of a ResNet50 is shown in
Figure 2.
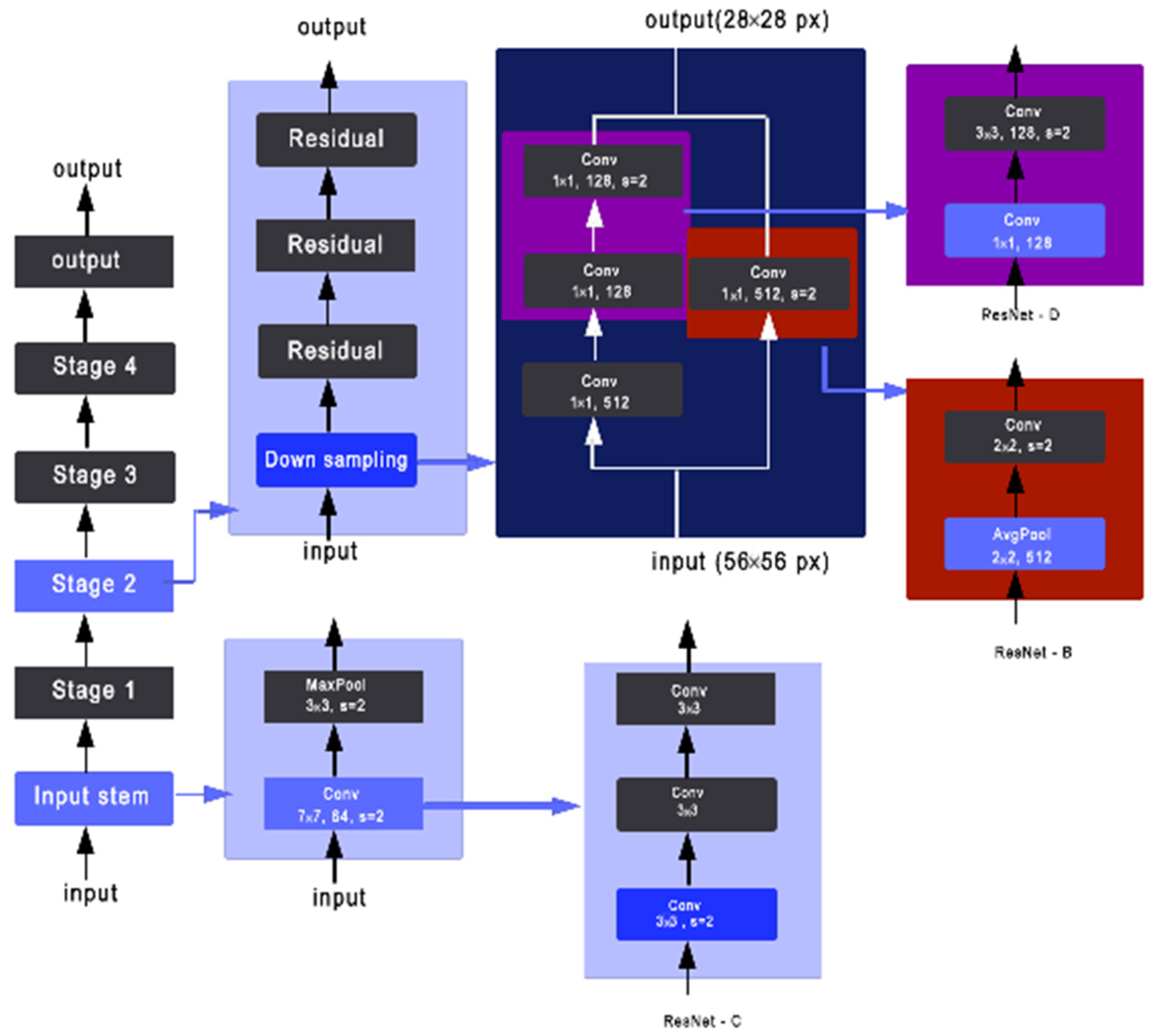
Tong He [
27] introduced XResNet with three different methods to improve the three separate convolutional steps that are presented in the ResNet structure. As shown in
Figure 3 and
Figure 4, ResNet-B moves the stride (2,2) to the second convolution and keeps a stride of 1 for the first layer [
27]. ResNet-C removes the 7 × 7 convolution and replaces it with three consecutive 3 × 3 convolutions. Finally, ResNet-D replaces the 1 × 1 convolution of stride (2,2) with a (2,2) average pooling layer of stride (2,2) followed by a 1 × 1 convolution layer [
28].
The designer presented a dense convolutional network (DenseNet), an architecture that distills the complexity of other CNN learners into a simple connectivity pattern, so that with this system, the maximum information will flow between layers in the network and all layers will be directly connected with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes them on to all subsequent layers.
Figure 5 shows this layout schematically. In contrast to ResNets, we never combine features through summation before they are passed into a layer; instead, we combine features by concatenating them. Hence, the layer has inputs consisting of the feature maps of all the preceding convolutional blocks. Its own feature maps are passed on to all subsequent layers. This introduces connections in an L-layer network instead of just an L-layer network, as in traditional architectures. Because of its dense connectivity pattern, we refer to our approach as “Dense Convolutional Network” (DenseNet) [
28].
The AlexNet has eight layers with learnable parameters. The model consists of five layers with a combination of max pooling followed by three fully connected layers, and they use Relu activation in each of these layers except the output layer [
9].
Ref. [
9] found out that using the relu as an activation function accelerated the speed of the training process by almost six times. They also used the dropout layers to prevent their model from overfitting. Furthermore, the model is trained on the ImageNet dataset. The ImageNet dataset has almost 14 million images across a thousand classes.
The SqueezeNet [
29] is a smaller CNN architecture that uses fewer parameters while maintaining competitive accuracy. Several strategies are employed on the CNN basis to design the SqueezeNet: (1) replace 3 × 3 filters with 1 × 1 filters, (2) decrease the number of input channels to 3 × 3 filters, and (3) downsample late in the network so that the convolution layers have large activation maps. The SqueezeNet is comprised mainly of Fire modules that are squeeze convolution layers with only 1 × 1 filters. These layers are then fed into an expand layer, which has a mix of 1 × 1 and 3 × 3 convolution filters, as shown in
Figure 6.
VGG16 is a convolution neural network (CNN) architecture that was used to win the ILSVR (ImageNet) competition in 2014. It is regarded as one of the best vision model architectures available to date. Its structure is shown in
Figure 7. The most unique thing about VGG16 is that instead of having a large number of hyper-parameters, they focused on having convolution layers of a 3 × 3 filter with a stride 1 and always used the same padding and maxpool layer of a 2 × 2 filter with a stride 2. It follows this arrangement of convolution and max pool layers consistently throughout the whole architecture. In the end, it has two FC (fully connected layers), followed by a softmax for output. The 16 in VGG16 refers to it 16 layers that have weights. This network is pretty large, and it has about 138 million (approximately) parameters [
29].
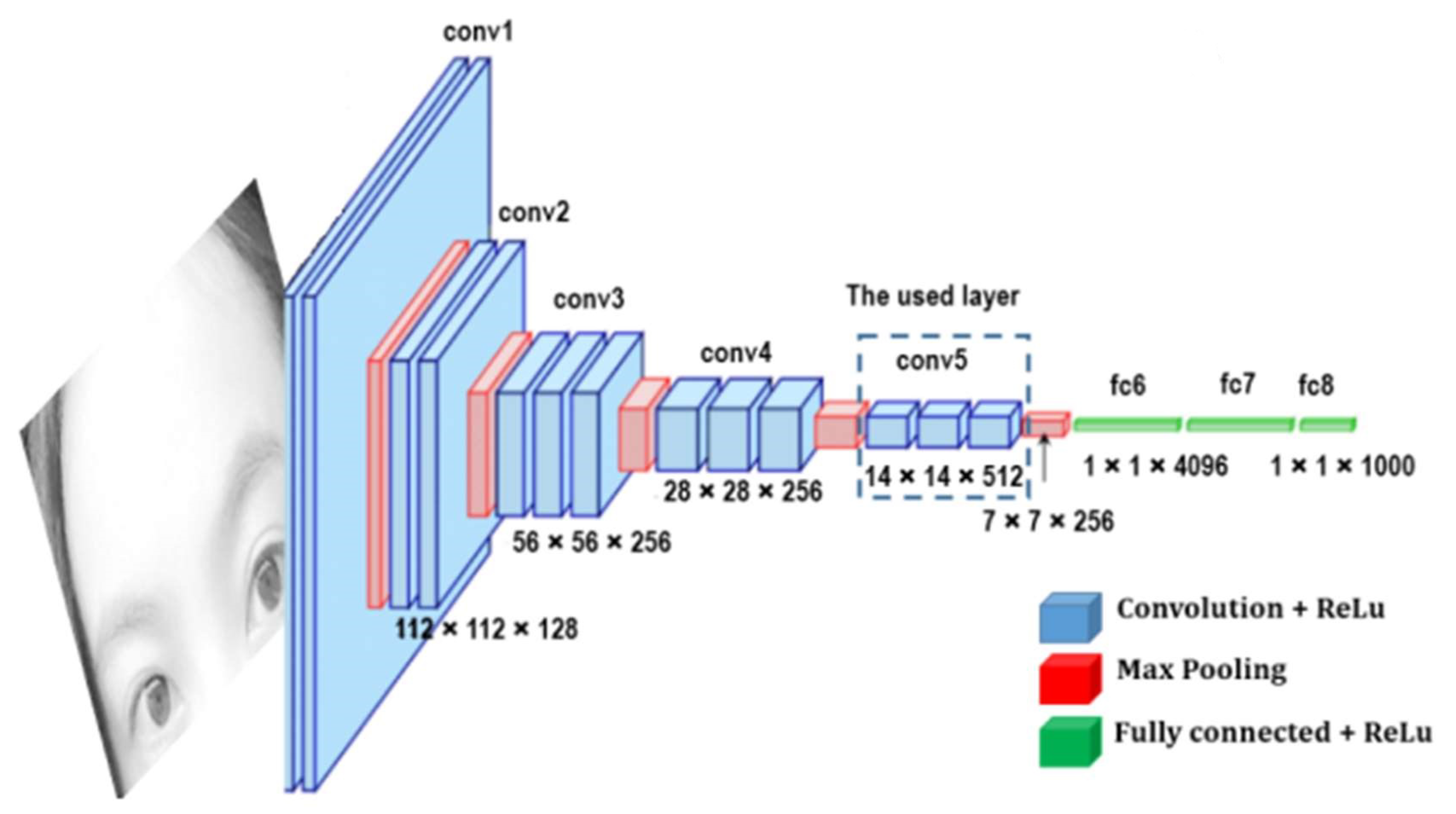
The architecture of the FCN-VGG19, shown in
Figure 8, is adapted from [
29], which learns to combine high-level information with fine-level information using skips from the third and fourth pooling layers. The hidden layers are equipped with rectified linear units (ReLUs), and the number of channels for the convolutional layers increases with the depth of the network. During training, the input image is a fixed size of 224 × 224 pixels, while the receptive fields for all filters are 3 × 3 pixels throughout the whole network. This configuration allows the FCN (fully convolutional networks) to learn approximately 140 million parameters. Prediction is performed using upsampling layers with four channels for all classes [ncl] in the reference data. Upsampling layers are fused with 1 × 1 convolutions of the third and fourth pooling layers with the same channel dimension [x,y,ncl]. The final upsampling layer predicts fine details using fused information from the last convolutional layer, with the third and fourth pooling layers being upsampled at stride 8.
Table 1 shows a summary of the described CNN learning methods.
The last parameter that should be considered in the learning models is time complexity. The quantity of fundamental operations, such as multiplications and summations, that an algorithm performs determines its time complexity. Typically, the time complexity is stated as a function of the size n of the input. The size of the input, or n, which indicates how many items are taken into account for the input, must first be known in order to determine the time complexity. How many operations are made in relation to the amount of the input is the second parameter that affects time complexity (number of epochs). so the linear time complexity is O(2 × n) = O(n).
The following table compares the structure and different working conditions of each of the learning systems considered in this study.
3. Dataset
Traffic signs seen from a vehicle present themselves in various conditions that make it difficult to recognize them, such as different distances (low image resolution), lighting, vandalism, or even some obstacles, such as leaves on trees, which can compromise visibility. With this in mind, it is necessary to use a database with multiple images that can cover these different conditions during training [
31].
The database used is called “The German Traffic Sign Recognition Benchmark”, or GTSRB, and was used for neural network competitions in 2011. It has 43 different classes of signs found in Germany and about 50,000 images in total. Due to its large number of images, it is possible to achieve very good results, but it also has some defects that will be discussed later [
32].
The images for the model were loaded and prepared with fastai tools so that each class was divided between images and a label, which, in this case, is the name of the folder where the images of each class are located. Folders have been renamed from the original basis so that the results can be presented more clearly. In addition, the images were randomly divided into training images and validation images at a ratio of 4 training images to each validation image, resulting in approximately 40 thousand for training and 10 thousand for validation, and, finally, resized for training [
31].
4. Models and Methods
The recognition model was trained several times by different types of CNN-learners, observing the accuracy at the end of the training, the amount of processing used, and the time to perform the training. Some examples of the employed dataset are shown in
Figure 9. The learner models used in this article and whose results will be reviewed and compared, are ResNet 18, 34, and 50; DenseNet 121, 169, and 201; Vgg 16_bn and Vgg19_bn; SqueezeNet1_0 and SqueezeNet1_1; and AlexNet and XresNet50.
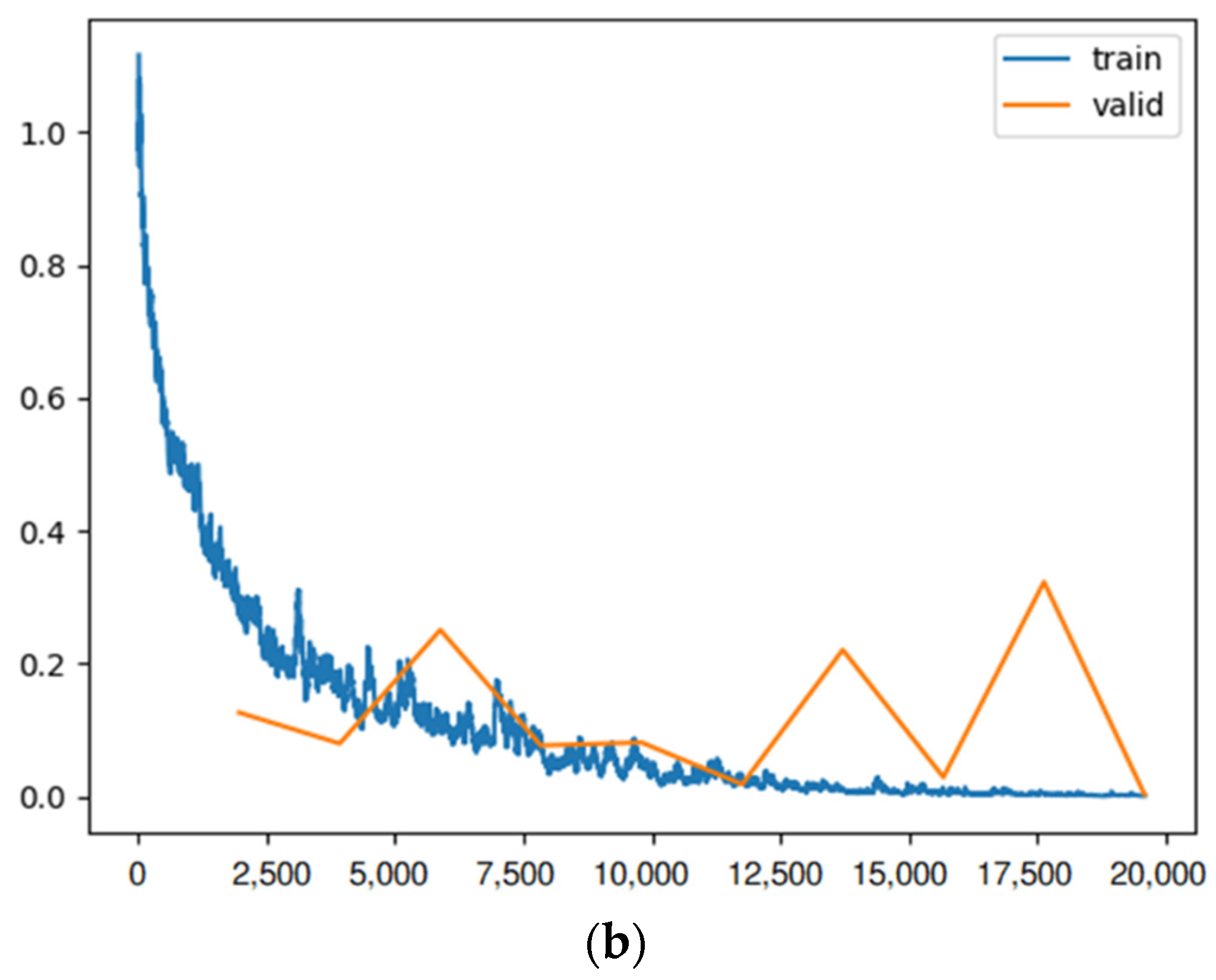
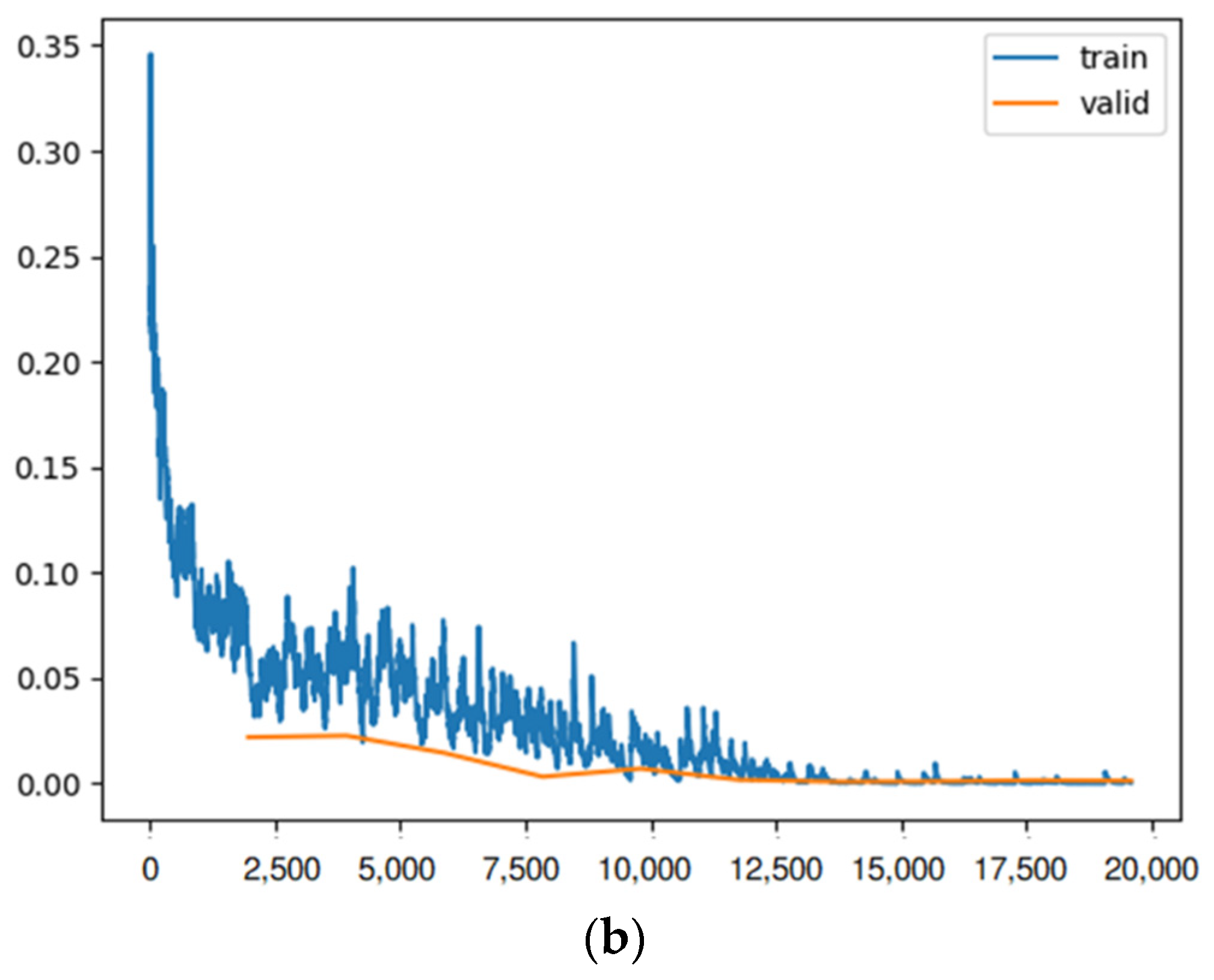
To find the most efficient way to train the model, some elements were changed: the size of each training batch, the number of training iterations (fine tuning), and the number of layers (for example, for the ResNet model), so that the loss rate (similar to
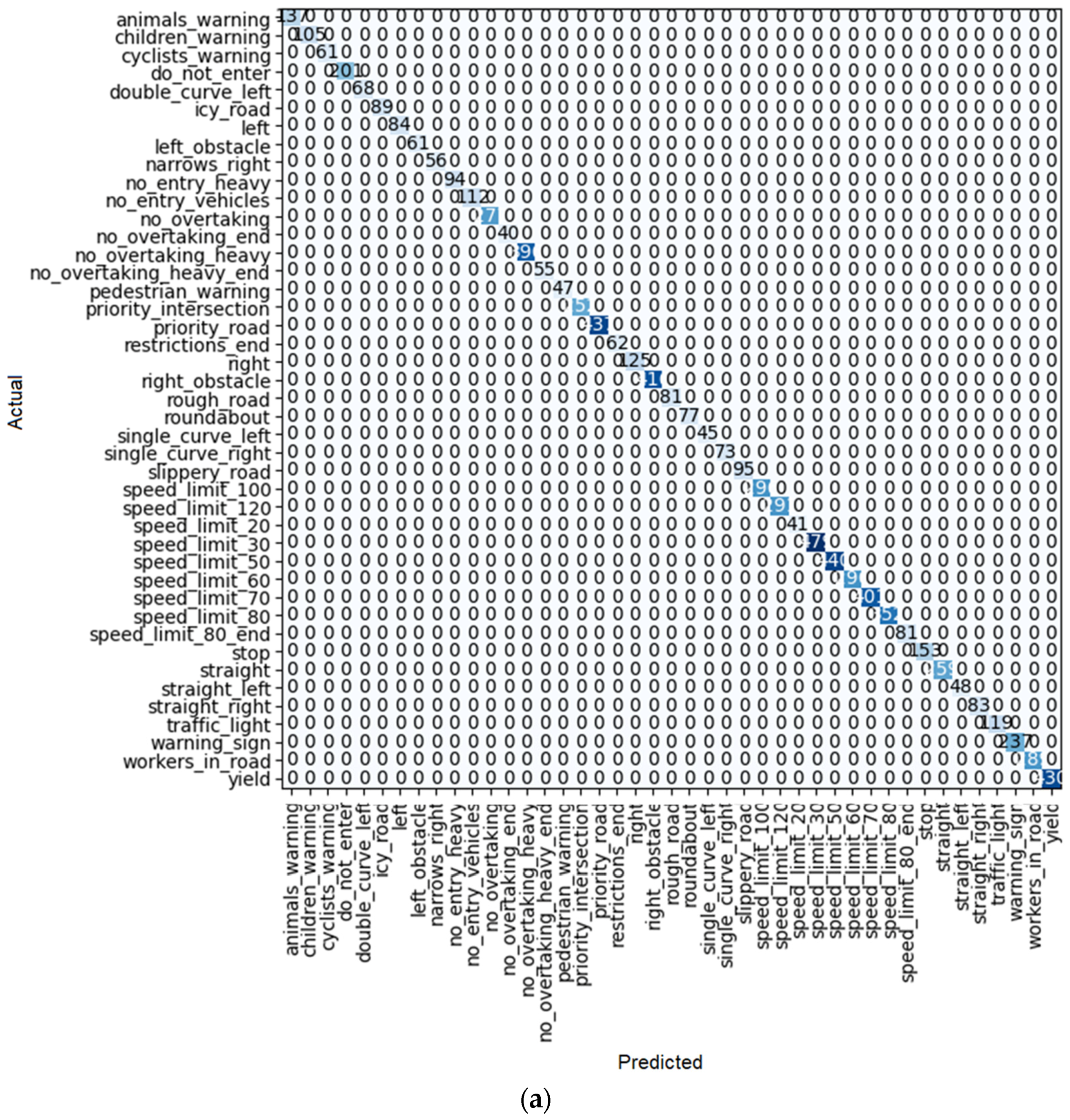
Figure 10b) for training and validation at the end of training is as close as possible, indicating training with little overfitting or underfitting. In addition, the outcome of each learner system is displayed in a confusion matrix similar to
Figure 10a. For each method of learning, there is a table that shows the result of train loss, valid loss, accuracy, error rate, and the desired time of training for each epoch.
The results can vary due to some other factors, the main ones being the random initialization of the values and the scrambling of the training data implemented by the fastai algorithm. However, it was possible to notice some patterns in the different trainings performed, where changing values considerably improved the result to the point of stagnation.
5. Result
The batch size, number of iterations, training model, and number of layers were changed while training the recognition model multiple times. Accuracy was measured at the end of each training cycle, along with the processing power and training time required. Large batches were shown to take less time, use more computer memory, but lose a significant amount of accuracy after training.
The best outcome was 16, whereas the largest batch value tested was 128, where lower values did not indicate greater accuracy, and longer training sessions did not result in any appreciable gains.
5.1. ResNet
5.1.1. ResNet 18
The first note that should be considered is that in the number of iterations, up to four iterations, the training loss rate decreases considerably; from 4 to 5, it presents a considerable increase, but again after iteration 5, it decreases again.
As shown in
Figure 10a, after 10 iterations, only one of the ResNet 18 predictions had an error, and it was the single-curve-left sign predicted as the children’s warning sign. For the others, all the predictions were correct.
5.1.2. ResNet 34
The number of iterations in ResNet 34 is similar to ResNet 18, which has 10 iterations. Used in fine tuning, it was observed that up to 3 iterations the training loss rate decreased considerably; from 3 to 4, it presented an increase, but again after iteration 4, it totally decreased again. So as a very simple result, it can be concluded that, in this case compared with ResNet 18, the error tends to zero faster than in the other case. The results are shown in
Table 3 and
Figure 11.
5.1.3. ResNet 50
Among the ResNet learning models, ResNet 50 has the best performance because its train loss trend is completely downward. The results are shown in
Table 4. The only place where there is some improvement in this process is in the last iteration, which has increased somewhat. Moreover, as shown in
Figure 12a, only one error occurred in the detection of traffic signs.
5.2. Squeezenet
About the train loss of both SqueezeNet 1_0 and SqueezeNet 1_1, both of them have a downward trend, just as the accuracy has an upward trend. However, the problem starts when we examine the valid loss and error rate. As shown in
Table 5 and
Table 6, as well as
Figure 13b and
Figure 14b, a lot of fluctuation can be seen in these two parameters. As a result, these two cases are not suitable for this purpose because they had weak validation results. The proof of this claim can be seen in
Figure 13a and
Figure 14b. This is because the system errors in detecting traffic signs are very high.
5.3. VGG
One of the best methods studied so far is VGG. This issue can be seen further.
5.3.1. VGG16_bn
In the case of the VGG16_bn method, as shown in
Table 7 and
Figure 15, the train loss trend is completely downward, and the accuracy of the system reaches 100% in the last epoch. On the other hand, valid loss reached a very low number of 0.000127, and the error rate completely reached zero. As a result, this is one of the methods that has the ability to be introduced as the best method at the end.
5.3.2. VGG19_bn
Another method from the VGG group that was investigated is VGG19_bn. As shown in
Table 8, the train loss in this method was 0.00004 in the last epoch, its accuracy reached 100 percent in the eighth epoch, and the error rate reached 0 in this epoch. The only negative point about this method compared to the previous one is that the time required for each epoch is a bit longer. Other data is shown in
Figure 16.
5.4. XresNet 50
Another method that has been investigated is XresNet 50. This method is one of the most widely used for image classification. As shown in
Table 9, in this method, the valid loss has reached 0.000869 in the last epoch. Moreover, by considering
Figure 17a, a large error can be seen in the detection of traffic signs. Another important parameter, which is very important, is the accuracy, which reached 99.8852% in this method. As a result, if we compare with the previous methods, we realize that this model cannot be among the candidates for the best investigated methods.
5.5. Densenet
By looking at the results of the DenseNet group, it can be seen that this group is also one of the best for detecting traffic signs. As seen in
Table 10,
Table 11 and
Table 12, train loss experiences a downward trend with low volatility in these models. Moreover, the error rate in DenseNet 121, 169, and 201 reaches 0.000128, 0.000255, and 0.000510, respectively. However, in the case of DenseNet 121, there is no error in detection. For example, one of these errors is shown in
Figure 18. As shown in this figure, there is a traffic sign with a speed limit of 80 km/h, which is correctly recognized by model DenseNet 121, but by models DenseNet 169 and DenseNet 201, it is wrongly recognized as a speed limit of 60 km/h. The superiority of DenseNet 121 over DenseNet 169 and 201 is clearly evident in the parameters of the table. In DenseNet 169 and 201, an error in detecting traffic signs is also observed, as shown in
Figure 19a,
Figure 20a, and
Figure 21a.
5.6. AlexNet
The last method that is examined in this article is AlexNet. A very positive point that can be seen in
Table 13 of this method is the time required for each epoch. This time is only 12 min on average. On the other hand, if we have a tradeoff between the time required for each epoch, train loss, and accuracy, we realize that this system can be introduced as one of the best methods. The results are shown in
Figure 22.
On the other hand, all the parameters of this system follow a completely uniform trend without fluctuations during different epochs, which is another reason for the goodness of this method.
6. Comparison
As shown in the above figures and tables, models SqueezeNet1_0 and SqueezeNet1_1 could not be used for this project because they did not learn correctly, and therefore they are not used in comparison. For the other methods, we use the last epoch of each learning model to compare them with each other.
As shown in the above table, and by considering that each iteration is equivalent to 1960 batches for training and 491 for validation, if maximum accuracy and minimum system error are important, the best results can be VGG16_bn and VGG19_bn. However, for these two models, the time required is the longest compared to other systems. But if less training time is desired with acceptable accuracy and error, AlexNet is the best option. As shown in
Table 14, after ten epochs, the accuracy of the system is 0.998725 and the error rate is just 0.001275, very close to zero. Moreover, with these parameters, the time needed for the training for the last epoch is just about 13 min.
7. Conclusions
As a result, this article demonstrates that in the same situation, with the same data set structure and processor (Intel(R) Core(TM) i5-4300M CPU @ 2.60 GHz, 2.59 GHz), we can compare the mentioned models and find the best training model for a traffic sign detection system.
So, as shown in
Table 14, the best system with acceptable error and accuracy and the shortest time required for training is the VGG19_bn model.
Two very important limitations that can be seen in the results are: (1) the speed of CNN learning systems and (2) the problem of classification with different positions. As for the second problem, when there is some tilt or rotation in the images, CNNs usually have trouble classifying them.
After further study and after finding the best method, in future studies this method can be examined online and on video in real time, exactly what is needed in driverless cars.
Each classifier relies on its own properties, which are determined by the specific classifier. The optimal parameter values depend on the scenario in which the classifier is to be applied. This study showed that it is not always possible to set the parameters accurately when applying classifiers to different data sets. If we study the future, firstly, we will work with different learning models similar XceptionV2, MobileNetV2, also we will likely do network searches to find different parameter values and then choose a parameter that is the best match. This maximizes accuracy because it is not guaranteed to find the absolute optimal value for a given classifier in a given data set, but it constitutes a good approximation.



 ,
, 




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}