

ThelR547v1—An Asymmetric Dilated Convolutional Neural Network for Real-time Semantic Segmentation of Horticultural Crops
 ,
,
Abstract
:1. Introduction
2. Related Works
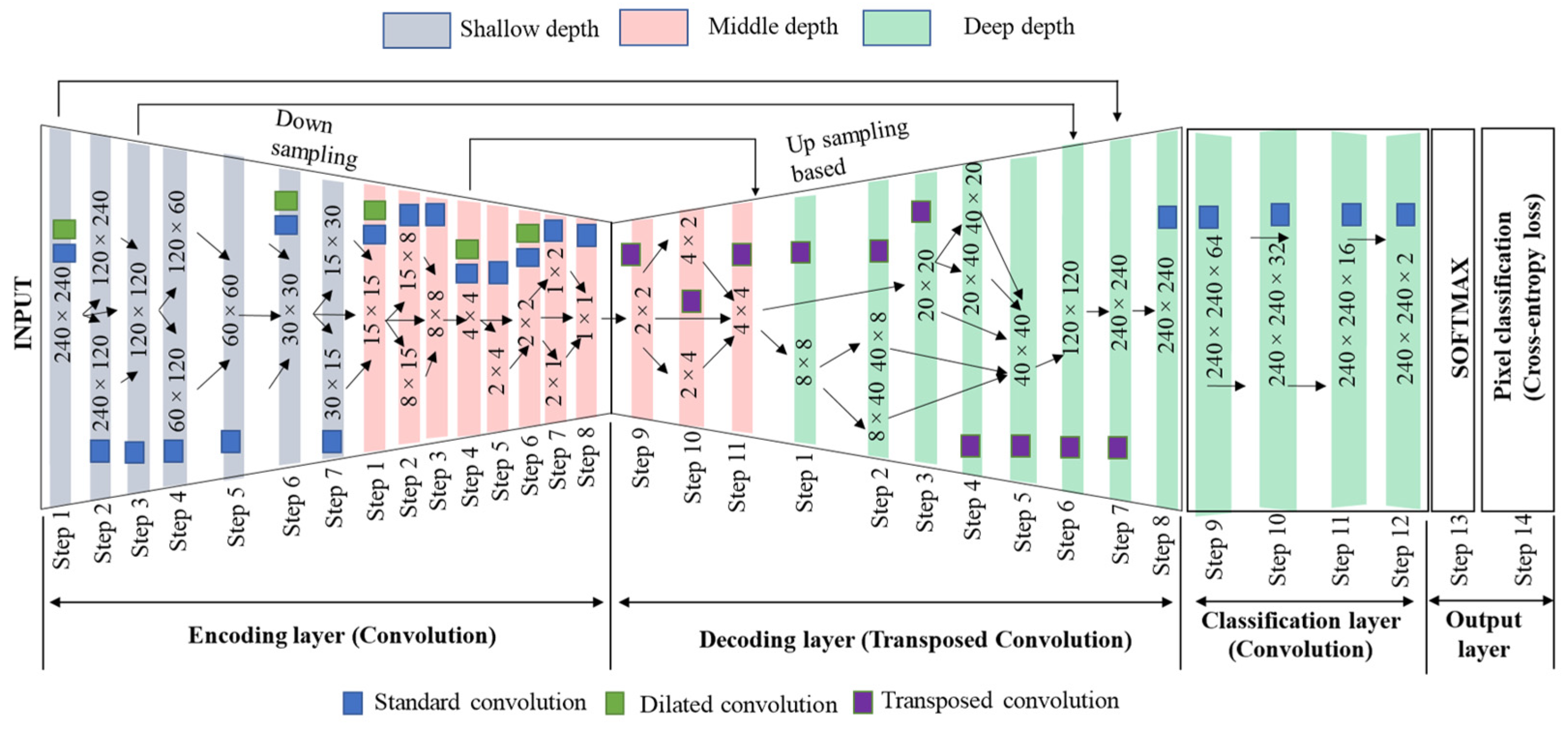
3. Materials and Methods
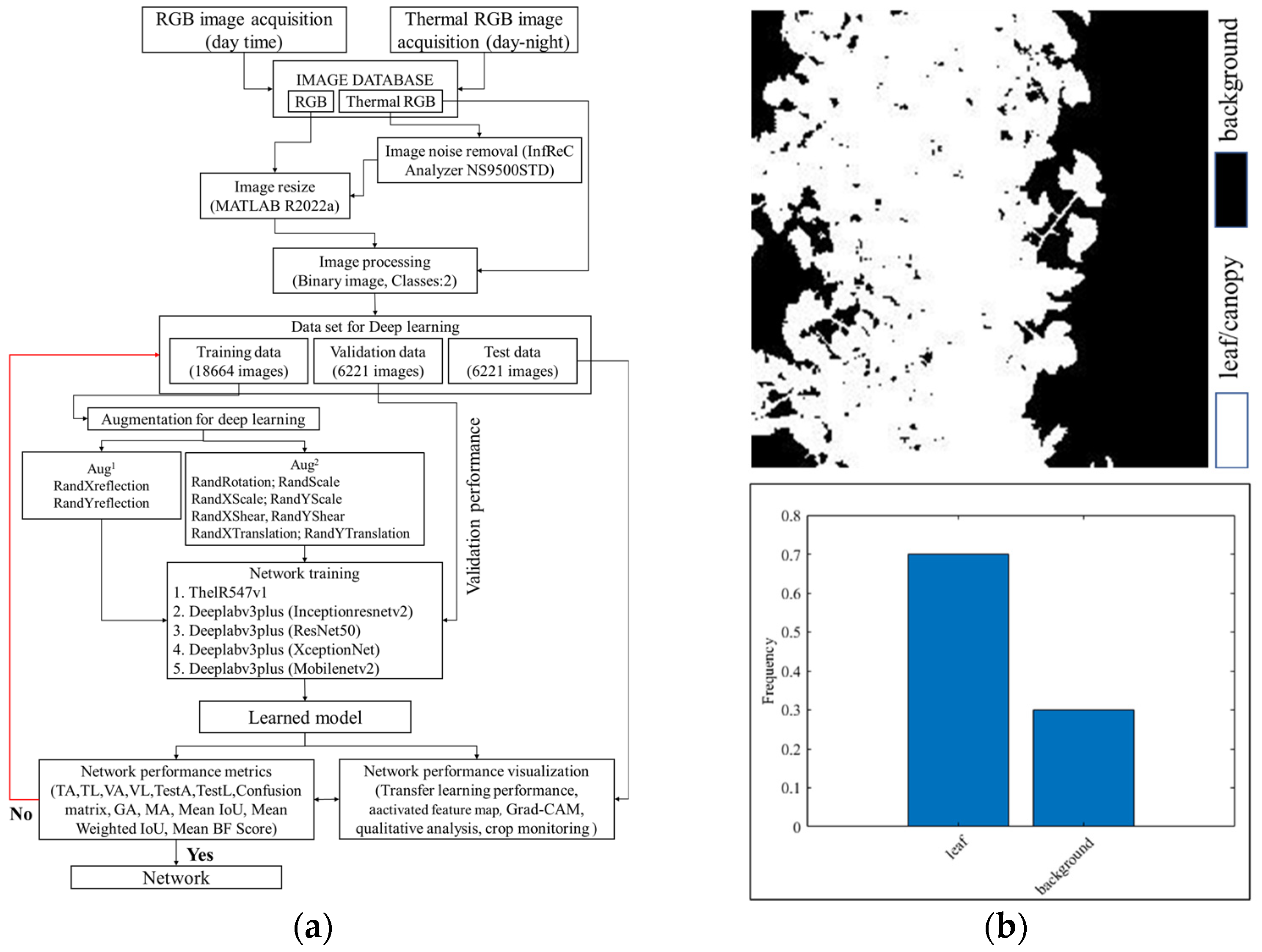
3.1. Image Acquisition and Dataset Preparation
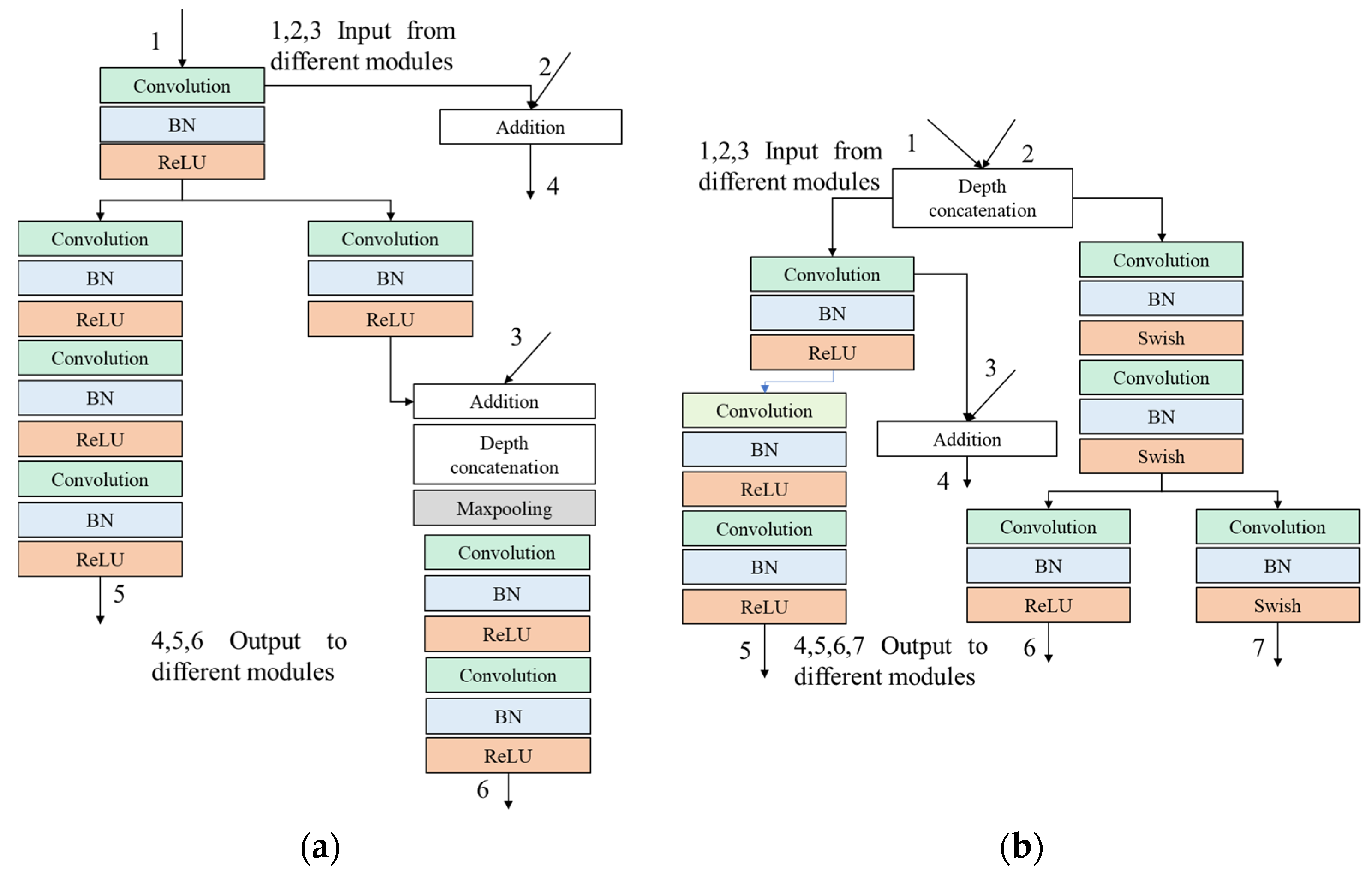
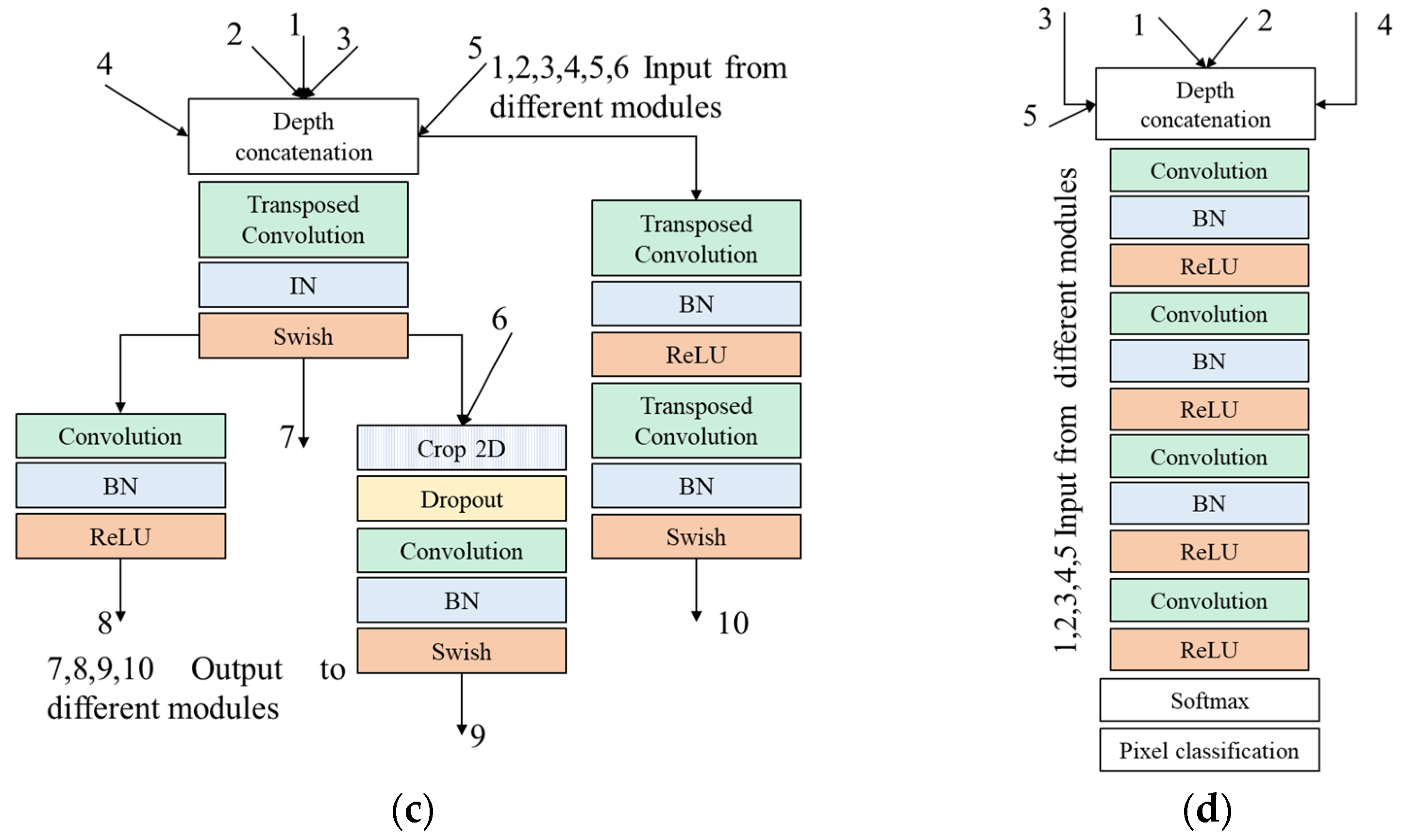
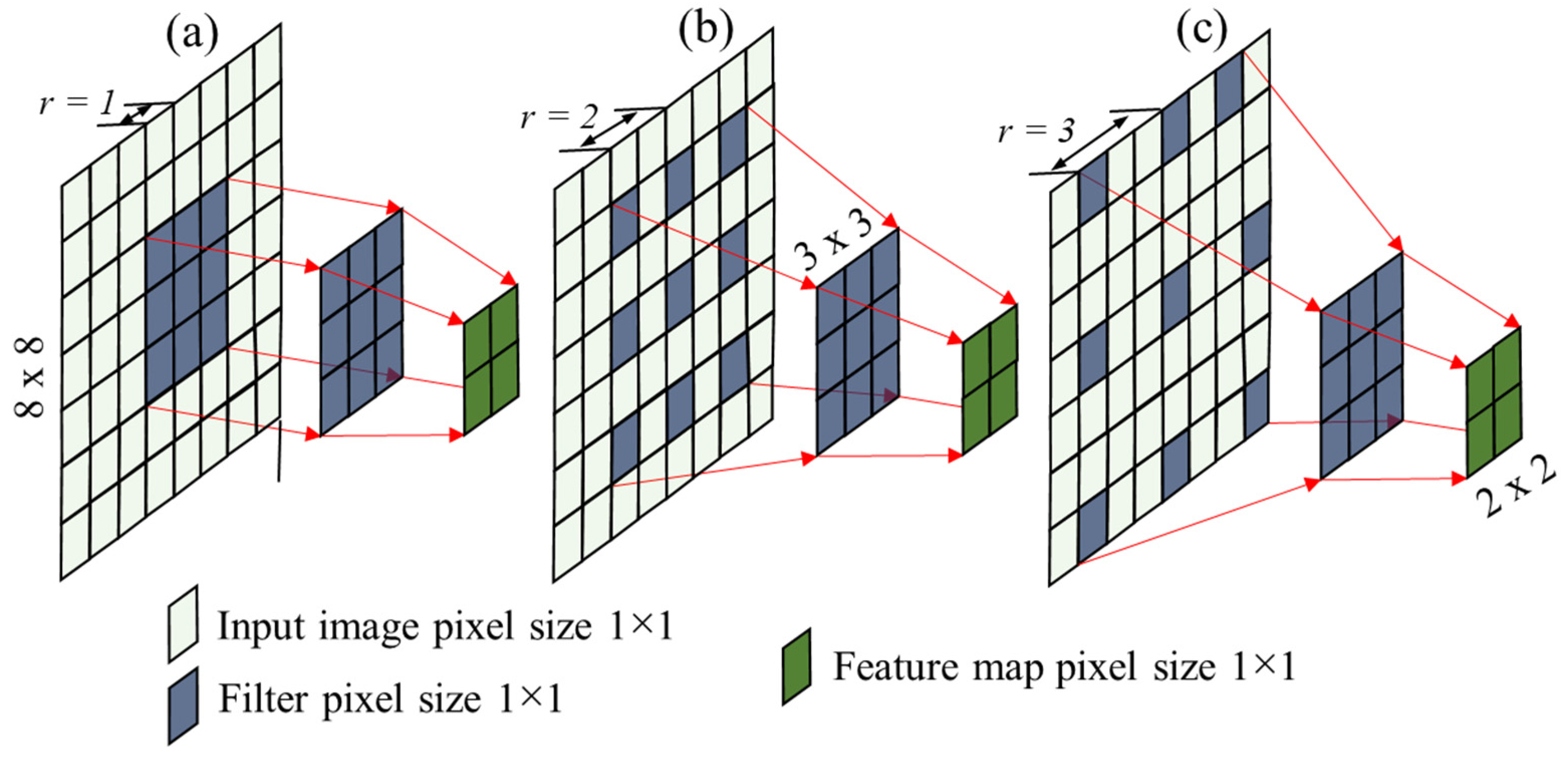
3.2. Asymmetric Multi-Branch Module
3.3. Image Acquisition and Dataset Preparation
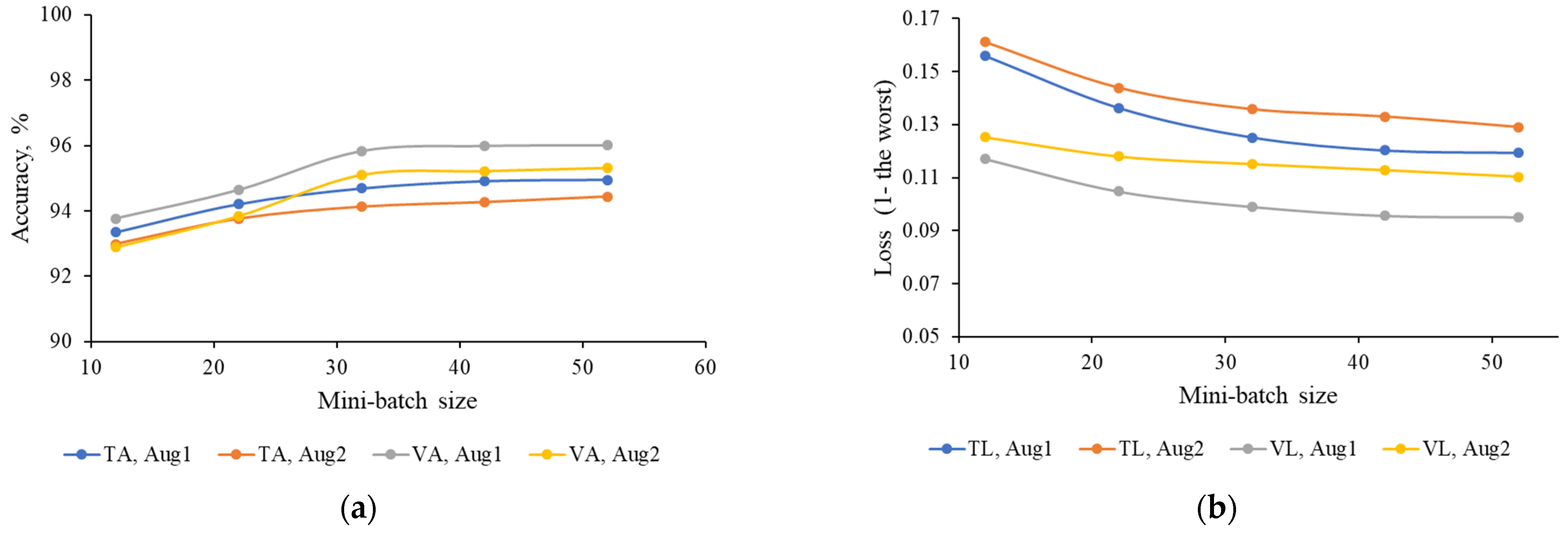
3.4. Network Training Parameters
3.5. Evaluation Metrics for Comparative Analysis
4. Results
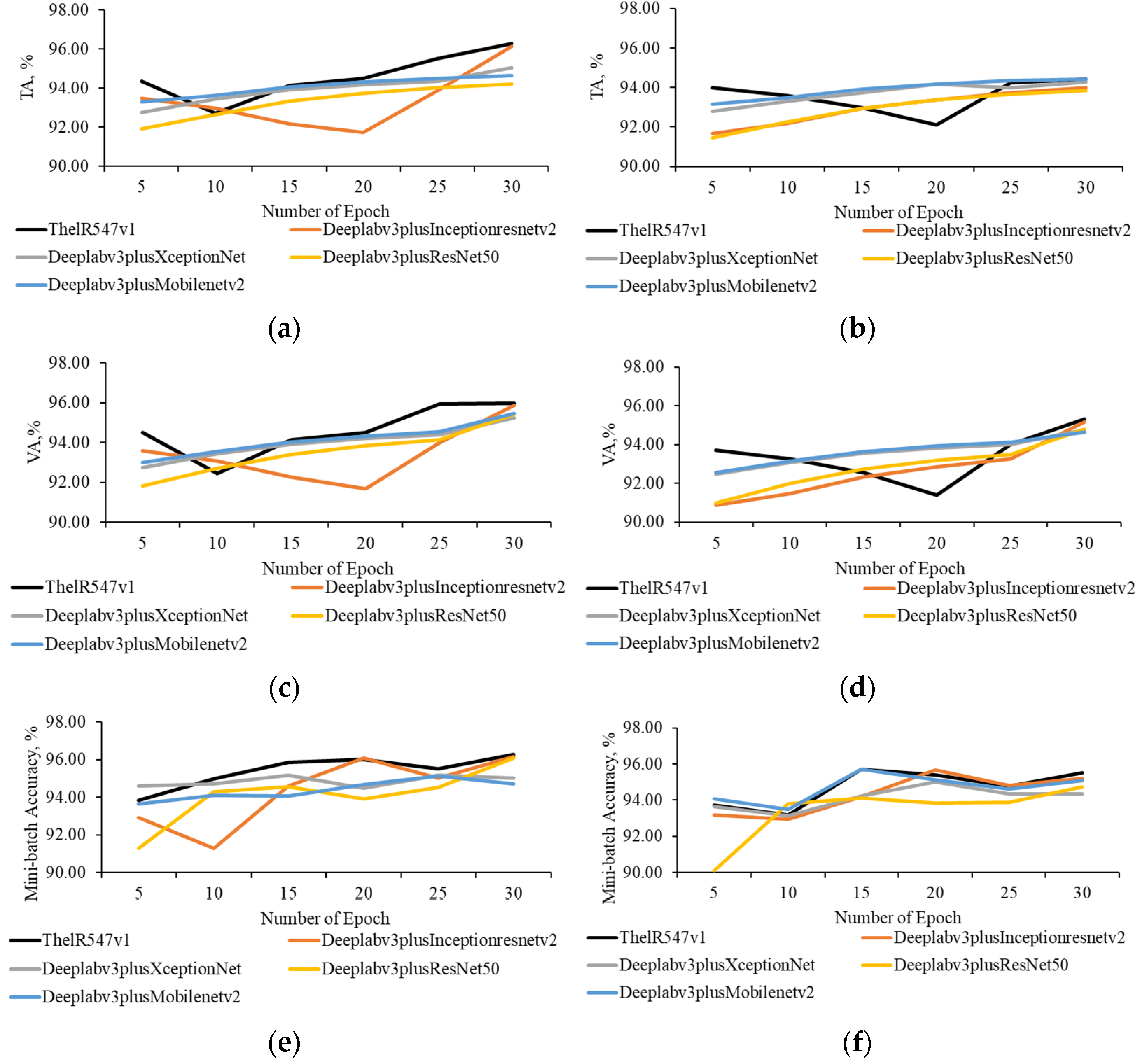
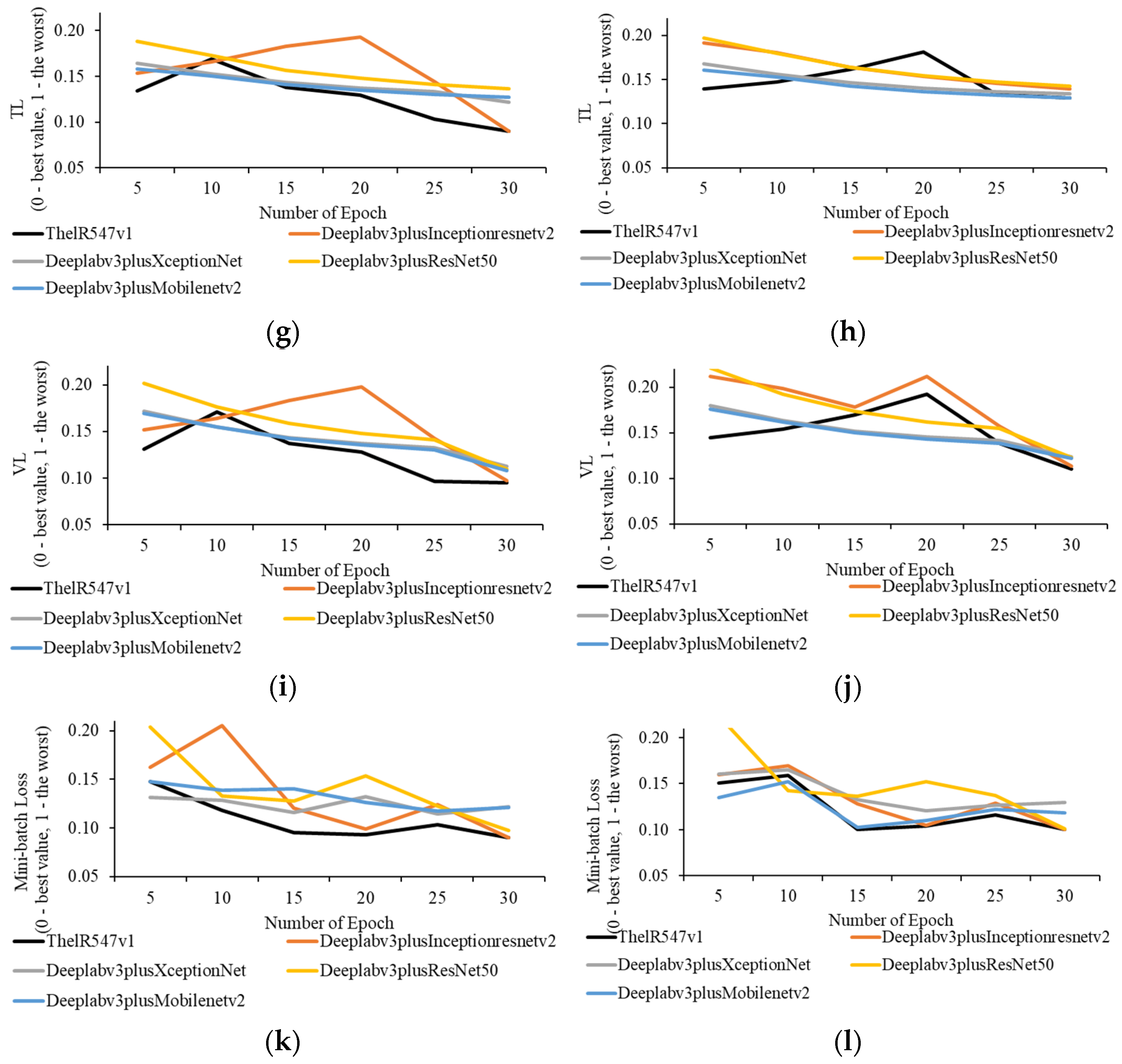
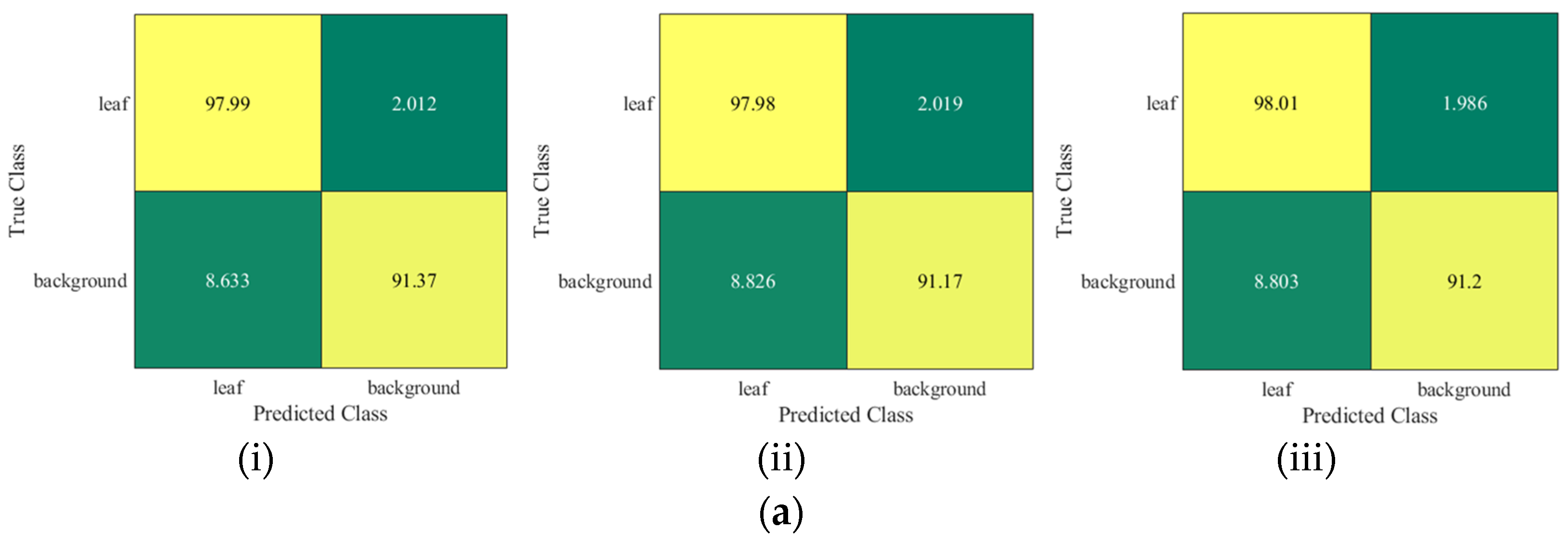
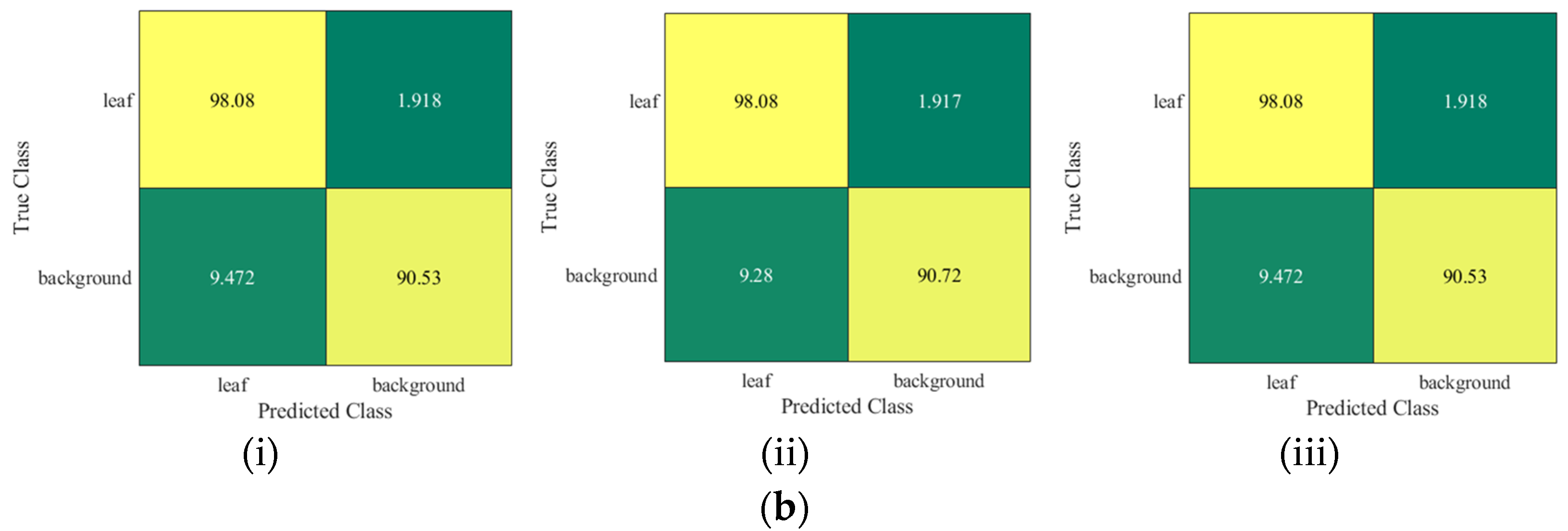
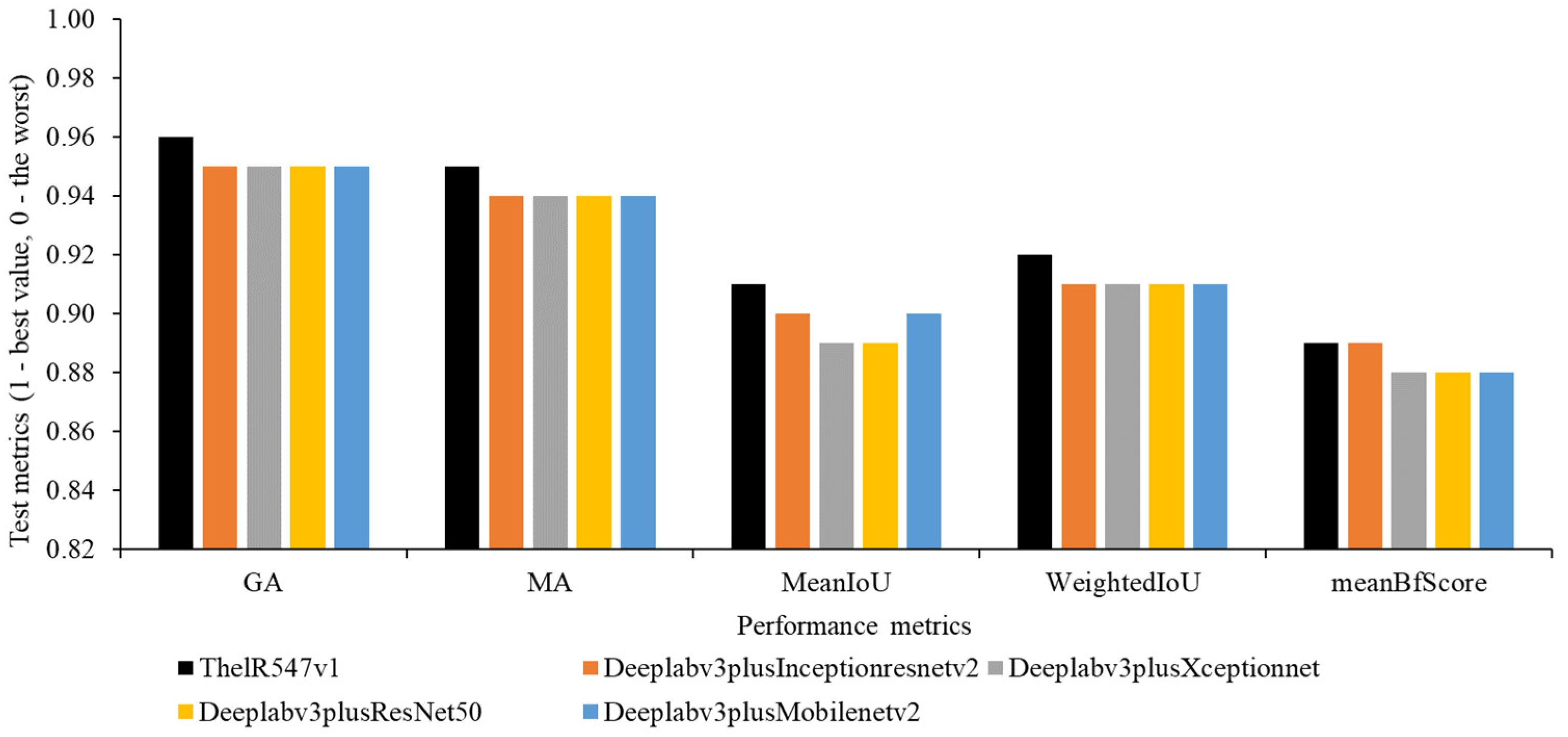
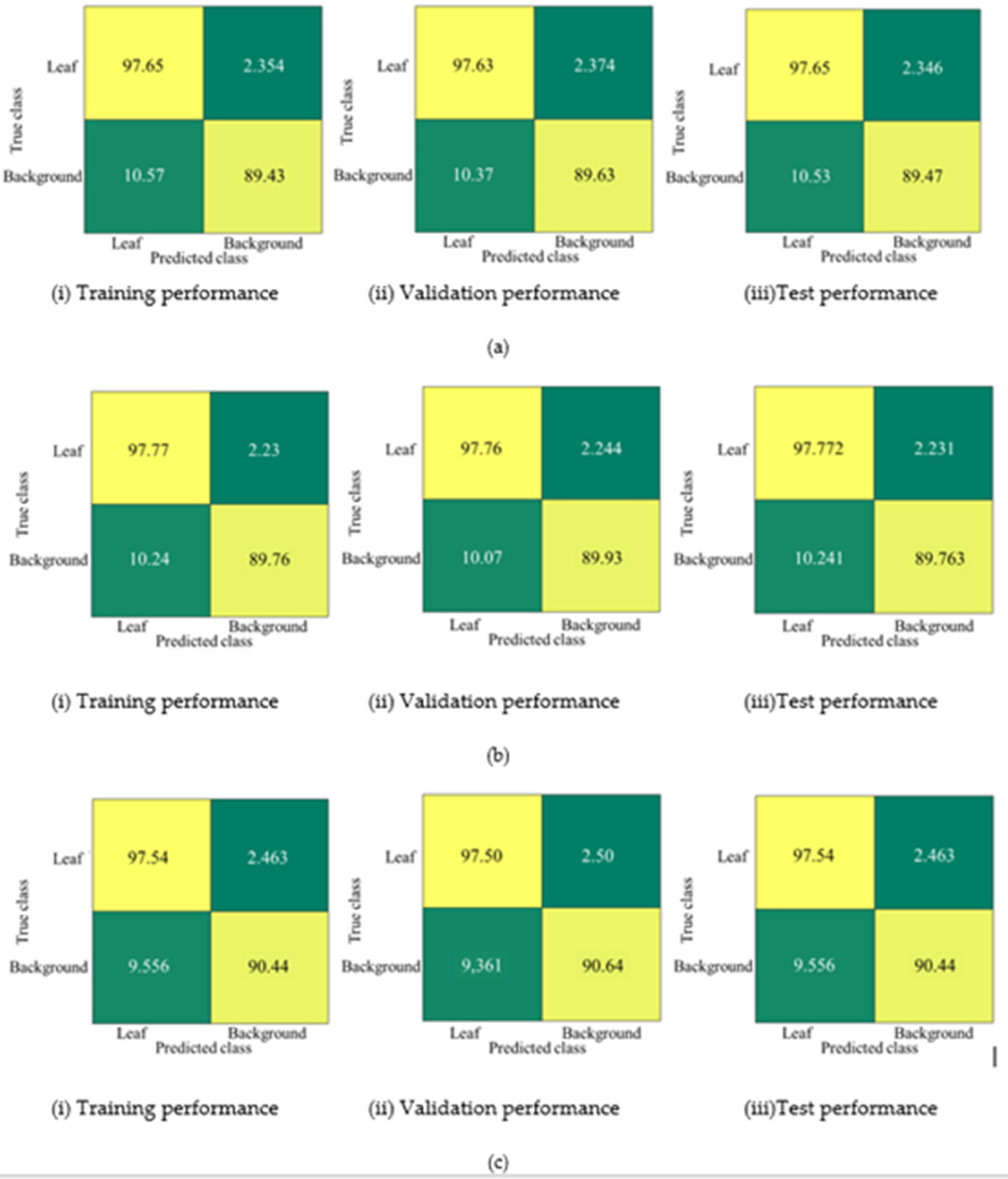
4.1. Quantitative Evaluation
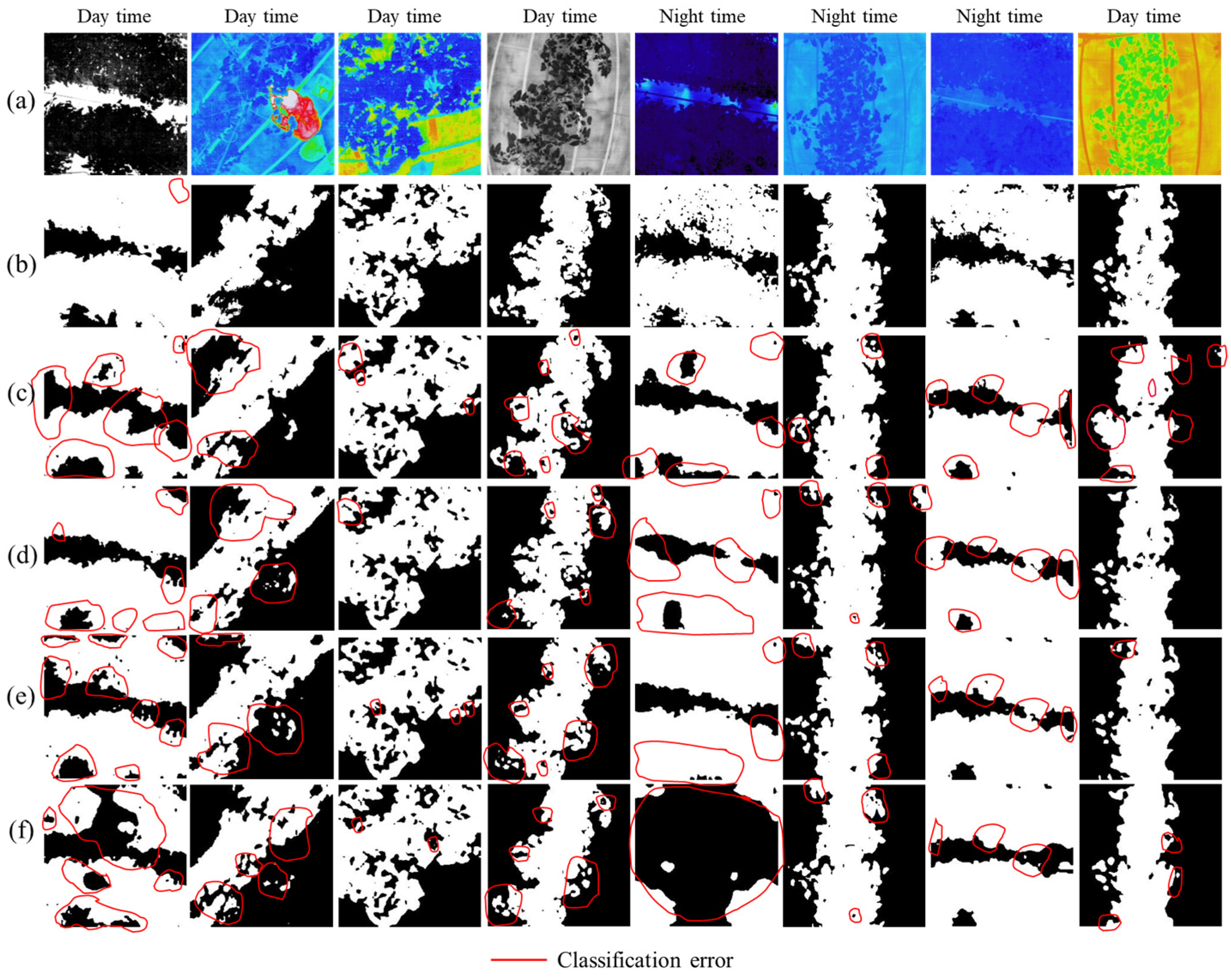
4.2. Qualitative Evaluation
4.2.1. Transfer Learning Performance Evaluation
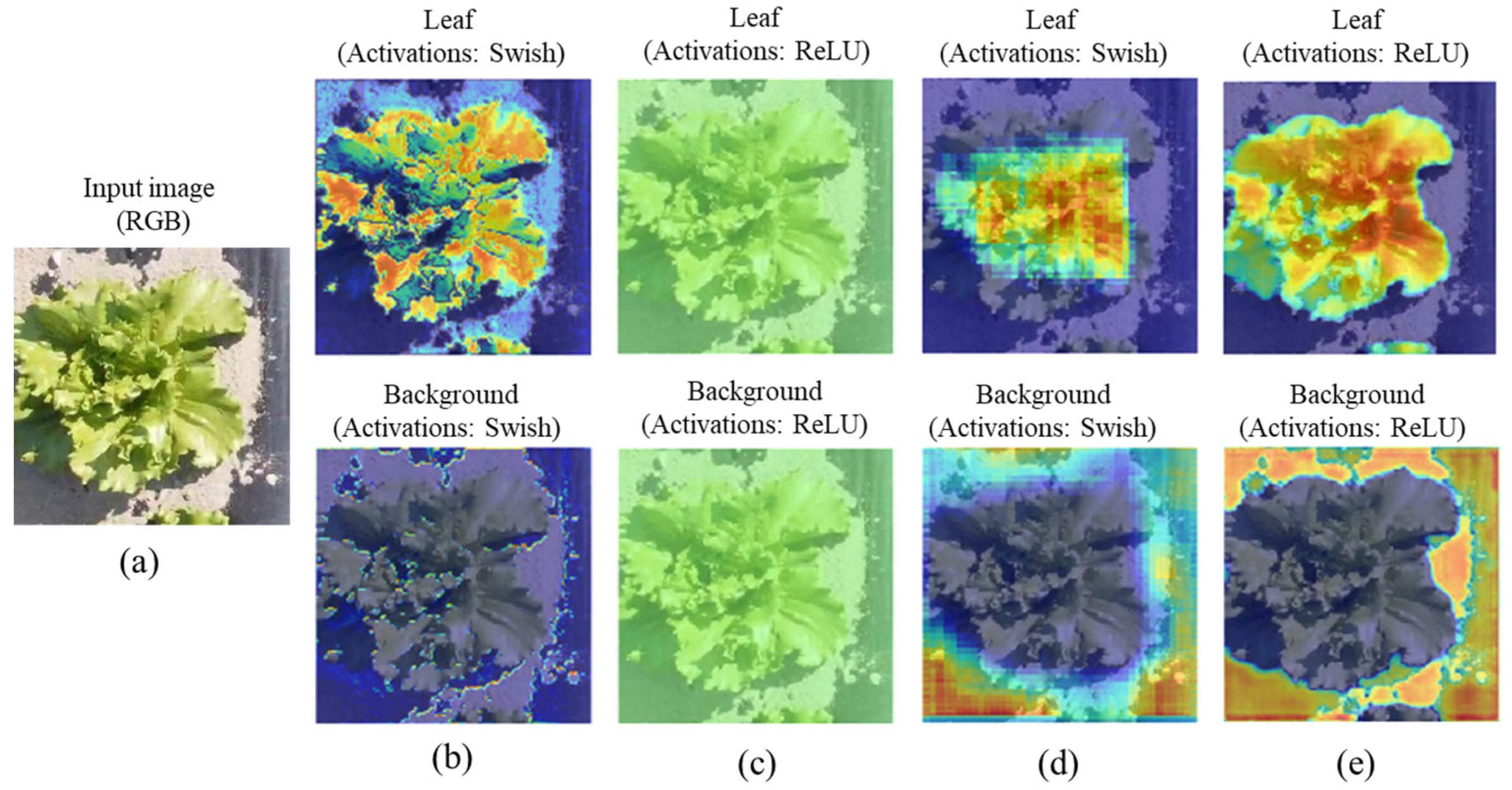
4.2.2. Activated Feature Map Visualization
4.2.3. Gradient-Based Class Activation Heatmap (Grad-CAM) Visualization in the Different Layers
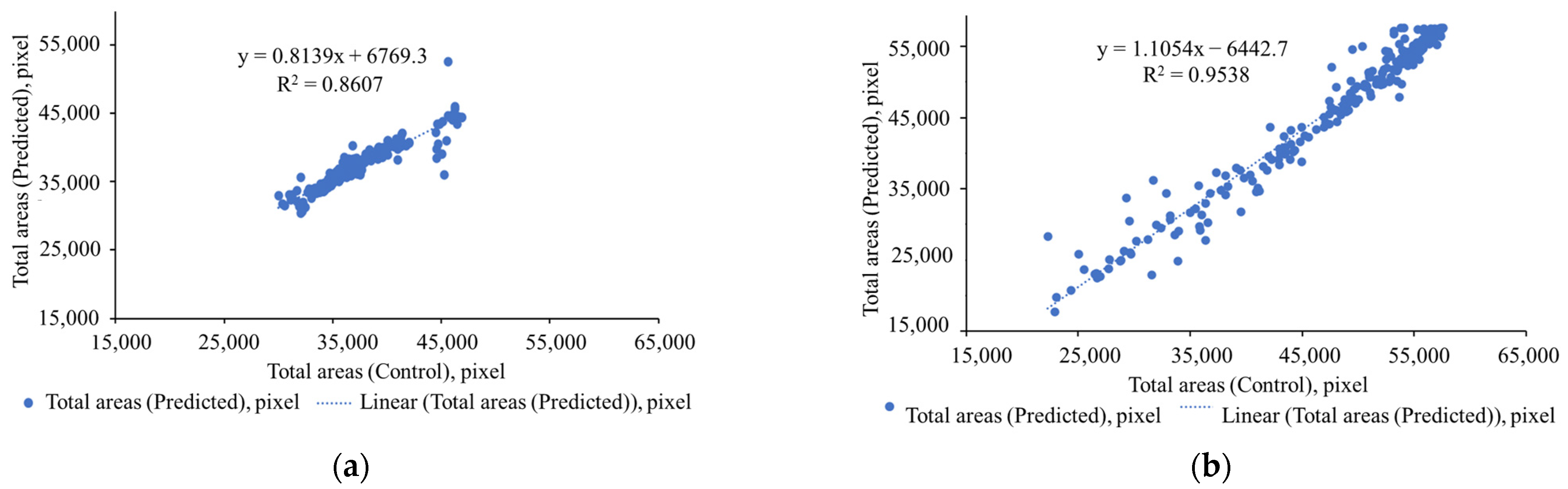
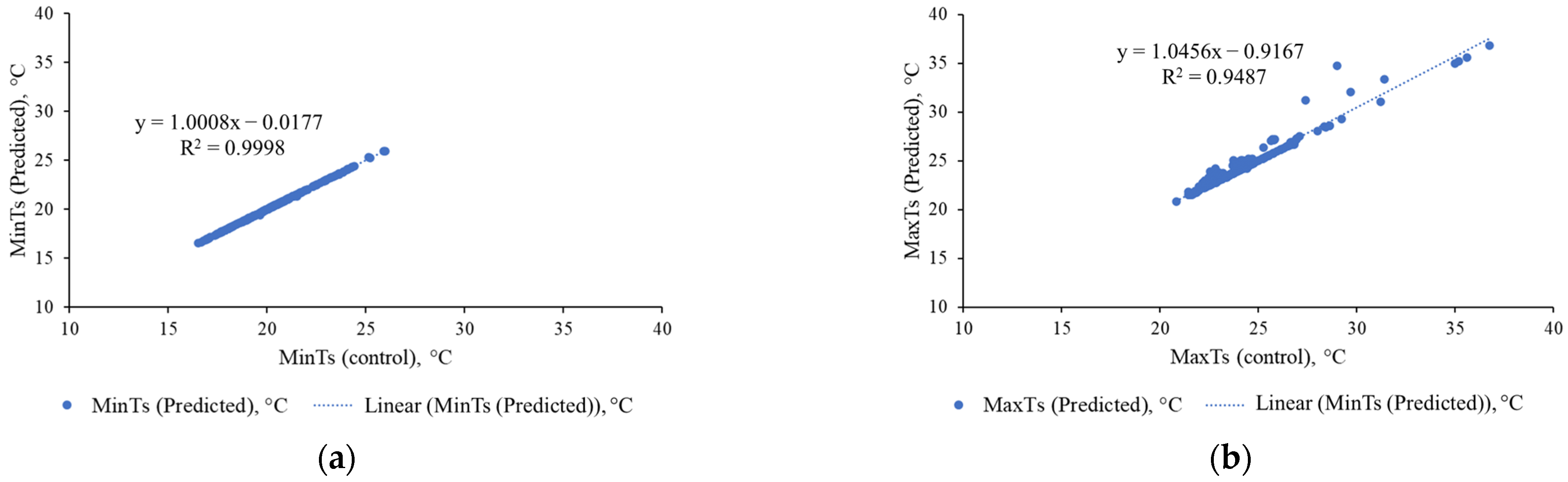
4.3. Crop Monitoring Performance
5. Discussion
- The training time of ThelR547v1 is 4 times that of Deeplabv3plusInceptionResNetv2, 9.5 times that of Deeplabv3plusXceptionNet, 9.2 times that of Deeplabv3plusResNet50, and 12.2 times that of Deeplabv3plusMobilenetv2. In our future work, we plan to optimize the number of dilations rate of the of the dilated convolution layer and optimize the network hyperparameters.
- Due to the lack of large datasets, the proposed network is sometimes unable to distinguish the boundaries between the leaves/canopy and background in some cases. To solve this, we plan to continue the collection of more challenging datasets (complex background, environmental noise, various stages of plant growth, cultivation media such as soil and hydroponic conditions such as greenhouses or open fields) and extensive development of manual ground truth (binary) data for training the network.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Confusion Matrix by Other Networks

References
- Yang, W.; Feng, H.; Zhang, X.; Zhang, J.; Doonan, J.H.; Batchelor, W.D.; Xiong, L.; Yan, J. Crop phenomics and high-throughput phenotyping: Past decades, current challenges, and future perspectives. Mol. Plant. 2020, 13, 187–214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minervini, M.; Scharr, H.; Tsaftaris, S.A. Image analysis: The new bottleneck in plant phenotyping (Applications Corner). IEEE Signal Process. Mag. 2015, 32, 126–131. [Google Scholar] [CrossRef] [Green Version]
- Ullah, H.S.; Asad, M.H.; Bais, A. End to end segmentation of canola field images using dilated U-Net. IEEE Access 2021, 9, 59741–59753. [Google Scholar] [CrossRef]
- Ko, T.; Lee, S. Novel method of semantic segmentation applicable to augmented reality. Sensors 2020, 20, 1737. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaur, R.; Hosseini, H.G.; Sinha, R.; Lindén, M. Automatic lesion segmentation using atrous convolutional deep neural networks in dermoscopic skin cancer images. BMC Med. Imaging 2022, 22, 103. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.P.; Nakano, Y.; Lee, U.; Tokuda, K.; Kochi, N. TheLNet270v1–A novel deep-network architecture for the automatic classification of thermal images for greenhouse plants. Front. Plant Sci. 2021, 12, 630425. [Google Scholar] [CrossRef]
- Ku, T.; Yang, Q.; Zhang, H. Multilevel feature fusion dilated convolutional network for semantic segmentation. Int. J. Adv. Robot. Syst. 2021, 18, 17298814211007665. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587v3. [Google Scholar]
- Lin, X.; Wa, S.; Zhang, Y.; Ma, Q. A dilated segmentation network with the morphological correction method in farming area image Series. Remote Sens. 2022, 14, 1771. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kallipolitis, A.; Revelos, K.; Maglogiannis, I. Ensembling EfficientNets for the classification and interpretation of histopathology images. Algorithms 2021, 14, 278. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. arXiv 2018, arXiv:1801.04381v4. [Google Scholar]
- Chen, L. Encoder-decoder with atrous separable convolution for semantic image segmentation. arXiv 2018, arXiv:1802.02611v3. [Google Scholar]
- Kuznichov, D.; Zvirin, A.; Honen, Y.; Kimmel, R. Data augmentation for leaf segmentation and counting tasks in rosette plants. arXiv 2019, arXiv:1903.08583v1. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the impact of residual connections on learning. arXiv 2017, arXiv:1602.07261v2. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. arXiv 2017, arXiv:1610.02357v3. [Google Scholar]
- López, A.; Molina-Aiz, F.D.; Valera, D.L.; Peña, A. Determining the emissivity of the leaves of nine horticultural crops by means of infrared thermography. Sci. Hortic. 2012, 137, 49–58. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Sermanet, P.; Kavukcuoglu, K.; Chintala, S.; LeCun, Y. Pedestrian detection with unsupervised multi-stage feature learning. arXiv 2013, arXiv:1212.0142v2. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285v2. [Google Scholar]
- He, J.; Wu, P.; Tong, Y.; Zhang, X.; Lei, M.; Gao, J. Bearing fault diagnosis via improved one-dimensional multi-scale dilated CNN. Sensors 2021, 21, 7319. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of deep learning for dense scenes analysis in agriculture: A review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramachandran, P.; Zoph, B.; Le, V.Q. Swish: A self-gated activation function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Nair, V.; Geoffrey, E.H. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Imaging Platform | Aspect Ratio | Pixel Resolution | Imaging Condition |
|---|---|---|---|
| RGB | 1:1, 16:9, 4:3 | 6000 × 4000, 4928 × 3264, 4288 × 2848, 4256 × 2832, 4032 × 1960, 3872 × 2592, 3648 × 3648, 3024 × 4032, 3024 × 3024, 2160 × 2160, 1960 × 4032, 720 × 720 | Heterogeneous illumination and background variation |
| Thermal RGB | 1:1 | 240 × 240, 480 × 360 |
| Augmentation Option | |
|---|---|
| Aug1 | Aug2 |
| RandXreflection: 1 | RandXreflection: 1 |
| RandYreflection: 1 | RandYreflection: 1 |
| RandRotation: [−10 10] | |
| RandScale: [1 1] | |
| RandXScale: [1 1.2] | |
| RandYScale: [1 1.2] | |
| RandXShare: [−2 2] | |
| RandYShare: [−2 2] | |
| RandXTranslation: [−3 3] | |
| RandYTranslation: [−3 3] | |
| Original Dataset | Image Dataset | Binary Dataset | Total Number of Images | Augmented Dataset | |
|---|---|---|---|---|---|
| Aug1 | Aug2 | ||||
| Training | 18,664 | 18,664 | 37,328 | 111,984 | 410,608 |
| validation | 6221 | 6221 | 12,442 | - | - |
| Test | 6221 | 6221 | 12,442 | - | - |
| Layers Name | Number of Layers | Layers Name | Number of Layers |
|---|---|---|---|
| Image input | 1 | ReLU | 143 |
| Convolution | 92 | Swish | 23 |
| Group convolution | 2 | Concatenation (depth) | 16 |
| Dilated convolution | 15 | Concatenation (addition) | 19 |
| Transposed convolution | 59 | Concatenation (multiplication) | 2 |
| Batch normalization | 157 | Dropout | 3 |
| Group normalization | 4 | Crop 2D | 1 |
| Instance normalization | 4 | Softmax | 1 |
| Max pooling | 4 | Binary-cross entropy | 1 |
| Network Depth | Network Layers | Filter Size | Dilate Rate | Stride Rate | Max Pooling Size |
|---|---|---|---|---|---|
| Shallow depth | Encoding | 3 × 3; 1 × 3; 3 × 1; 2 × 3 | 1,1; 2,2 | 1,1;1,2; 2,1; 2,2 | 3 × 3 |
| Middle depth | Decoding | 3 × 3; 1 × 3; 2 × 2; 3 × 2; 2 × 3 | 1,1; 2,2; 3,3 | 1,1; 2,1; 1,2; 2,2 | 5 × 5 |
| Deep depth | Decoding | 3 × 3; 2 × 2; 3 × 1; 2 × 3 | 1,1 | 1,1; 2,2; 5,5; 1,5; 5,1; 1,2; 2,1; 3,3 | - |
| Classification | 3 × 3 | 1,1 | 1,1 | - |
| Configuration Item | Parameter Value |
|---|---|
| CPU | Intel(R) CPU Core (TM) i9-10850K CPU @ 3.60 GHz (Cores 10) × 20 processors |
| GPU | NVIDIA GeForce RTX 3060 PCI-E with GDDR6 (1.78 GHz), 2 × 12 GB |
| Compute Unified Device Architecture (CUDA) | 3584 cores, 12.74 TFLOPS |
| Software acceleration | Nvidia CUDA 11.2 |
| Memory | 128 GB |
| Hard disk | Samsung SSD 970 EVO Plus (500 GB) |
| Operating system | Windows 10 pro (64-bit) |
| Network Name | Leaf | Background | ||||
|---|---|---|---|---|---|---|
| GA | IoU | Mean BfScore | GA | IoU | Mean BfScore | |
| ThelR547v1 | 0.98 | 0.94 | 0.93 | 0.91 | 0.87 | 0.86 |
| Deeplabv3plusInceptionresnetv2 | 0.98 | 0.94 | 0.93 | 0.90 | 0.86 | 0.85 |
| Deeplabv3plusXceptionNet | 0.97 | 0.93 | 0.92 | 0.89 | 0.84 | 0.83 |
| Deeplabv3plusResNet50 | 0.97 | 0.93 | 0.92 | 0.89 | 0.85 | 0.83 |
| Deeplabv3plusMobilenetv2 | 0.95 | 0.93 | 0.92 | 0.90 | 0.85 | 0.84 |
| Network Name | Network Size, Mb | Number of Layers | Number of Parameters, M | Total Number of Connections |
|---|---|---|---|---|
| ThelR547v1 | 15.5 | 547 | 5.4 | 1222 |
| Deeplabv3plusInceptionResNetv2 | 204 | 853 | 71.1 | 1912 |
| Deeplabv3plusXceptionNet | 60.2 | 205 | 27.6 | 444 |
| Deeplabv3plusResNet50 | 104 | 206 | 43.9 | 454 |
| Deeplabv3plusMobileNetv2 | 7.4 | 186 | 6.7 | 402 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, M.P.; Hatou, K.; Aihara, T.; Kawahara, M.; Okamoto, S.; Senoo, S.; Sumire, K. ThelR547v1—An Asymmetric Dilated Convolutional Neural Network for Real-time Semantic Segmentation of Horticultural Crops. Sensors 2022, 22, 8807. https://doi.org/10.3390/s22228807
Islam MP, Hatou K, Aihara T, Kawahara M, Okamoto S, Senoo S, Sumire K. ThelR547v1—An Asymmetric Dilated Convolutional Neural Network for Real-time Semantic Segmentation of Horticultural Crops. Sensors. 2022; 22(22):8807. https://doi.org/10.3390/s22228807
Chicago/Turabian StyleIslam, Md Parvez, Kenji Hatou, Takanori Aihara, Masaki Kawahara, Soki Okamoto, Shuhei Senoo, and Kirino Sumire. 2022. "ThelR547v1—An Asymmetric Dilated Convolutional Neural Network for Real-time Semantic Segmentation of Horticultural Crops" Sensors 22, no. 22: 8807. https://doi.org/10.3390/s22228807