1. Introduction
Deep learning has enabled artificial intelligence (AI) to quickly progress in recent years. The convergence of AI and the internet of things (IoT) is redefining the way industries, businesses, and technologies function. IoT can be used in various applications of automation with less or no human intervention. AI makes it possible for machines to learn from experience, adjust to new inputs, and perform human-like tasks. One of the primary objectives of AI is pattern classification and recognition. One of the ways that pattern recognition is carried out is through using rectangular windows followed by a classification process [
1,
2]. Numerous machine learning algorithms have been developed that play a vital role in pattern recognition. There are numerous algorithms, such as support vector machines (SVM), stochastic gradient descent (SGD), etc., for feature extraction. However, a typical convolutional neural network (CNN) has the ability to learn, adapt, and extract features automatically from existing databases [
3,
4]. In short, CNNs are the the popular method for any pattern classification or object detection algorithm [
5,
6]. However, they are computationally intensive and are difficult to deploy in any mobile interface device. To develop the performance of feature representation, the design induces more complexity, and their deployment on mobile platforms can be challenging. So, the need for a lightweight network configuration, without decreasing the accuracy of the system, remains [
7].
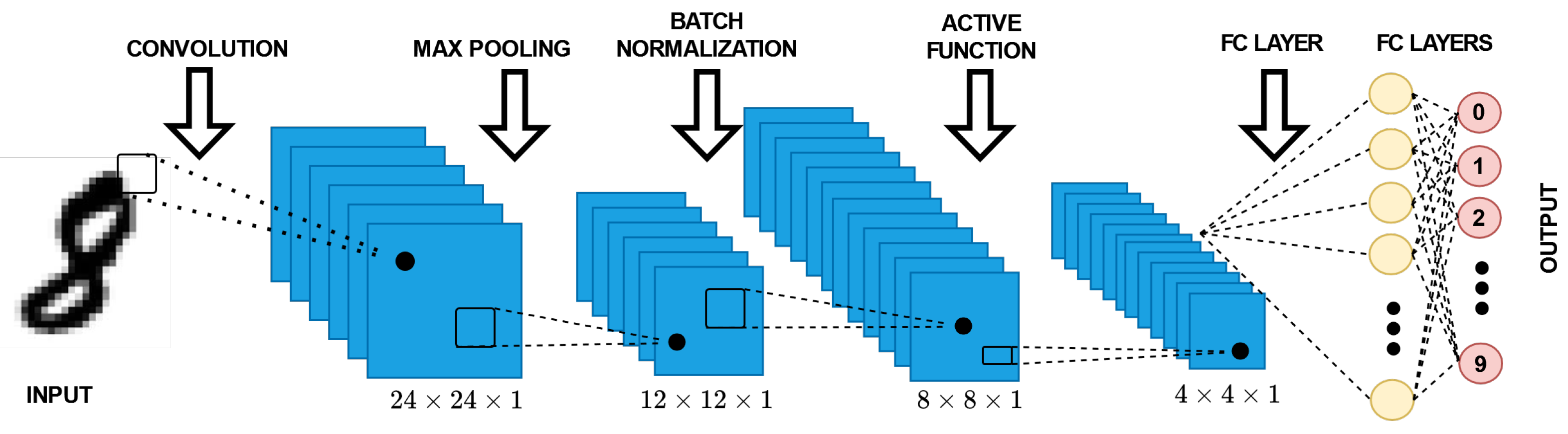
A typical architecture of a CNN can be seen in
Figure 1. In general, a CNN contains three basic layers. The first layer is the convolutional layer [
8], the second is the pooling layer followed by the batch normalization layer, and the third is an output later, which is a fully connected layer. At each layer, the features are classified, and subsequently the information is passed on to the next layer. The binary neural network (BNN) approach is similar to CNN but provides better storage and memory capacity.
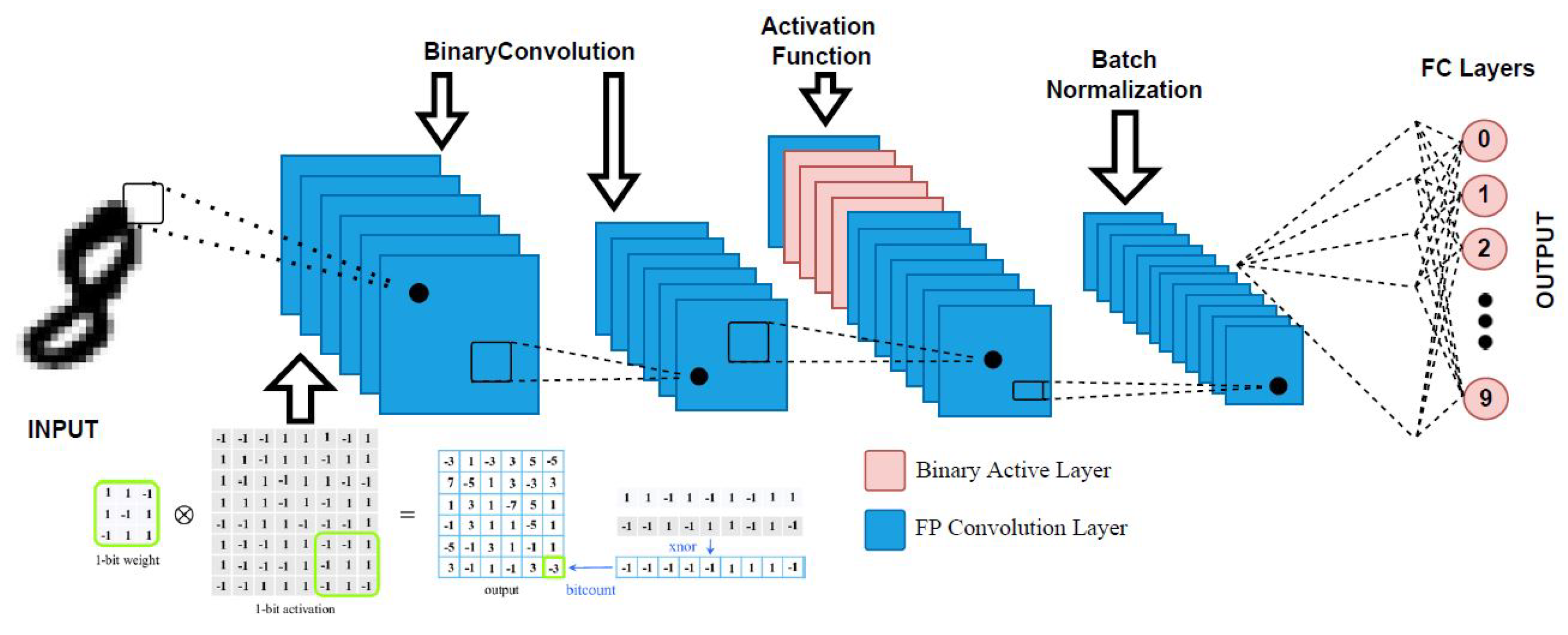
Another approach is the BNN. This approach is a type of DNN processor that provides better storage space in terms of computing and memory usage while having a marginal tradeoff with accuracy. For a detailed performance comparison, some works have analyzed the BNN approach using the processor model of an infrared spectrum (IR) human-based image recognition application. In one work, algorithm analysis was performed for a 32-bit DNN using various model parameters, such as the kernel number and synaptic connection [
9]. In this, the system structure was applicable for a BNN, such as an application-specific integrated circuit or a field programmable gate array (FPGA). The local storage was leveraged; that is, the full storage in the weights of BNN was used to speed up the process. Recently, object detection was performed using a hybrid convolutional recurrent network [
1]. This work used the BNN to compare its performance against a GPU. A BNN’s architecture can be seen in
Figure 2. Here, the input image is passed to the binary convolution layer. The features are scaled down before being passed to the next activation function for the classification of the pattern in another format, followed by the batch normalization layer. The output is a discovered pattern or object.
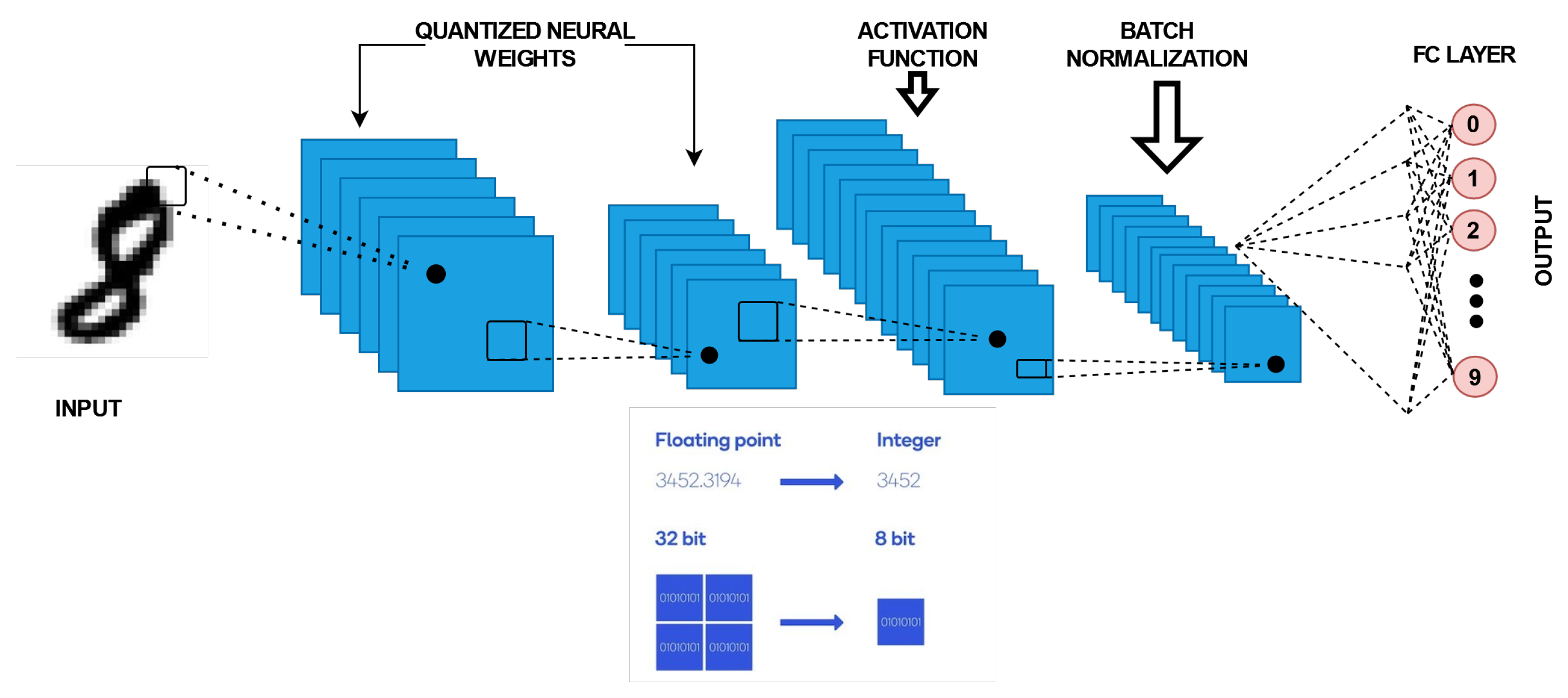
Another form of NN is the quantized neural network (QNN). QNNs are low-precision neural networks and have similar performance to a CNN while safeguarding the network structure. A BNN is also a form of amQNN. QNN consists of a quantization layer, multiply accumulation (MAC) layer, and a batch normalization layer. Although the storage and computation costs are greatly reduced, there is data loss due to quantization errors, which occurs under tradeoff conditions. A suitable quantization architecture should be able to store useful information in continuous variables and is critical to network performance.
Figure 3 shows a QNN architecture. The network layer contributes differently to the overall performance, each with different sensitivities to size. As the network propagates forward, the variability of the hierarchical functions subsequently rises. In the shallow layer, the internal features are dispersed over multiple complexes. To obtain the functions as in [
10,
11], we need to have accurate neurons. At deeper layers, the coarse convolution filter can distinguish the previous local features [
12]. Thus, parameter accuracy can be flexibly designed using network configuration and hierarchical feature distribution [
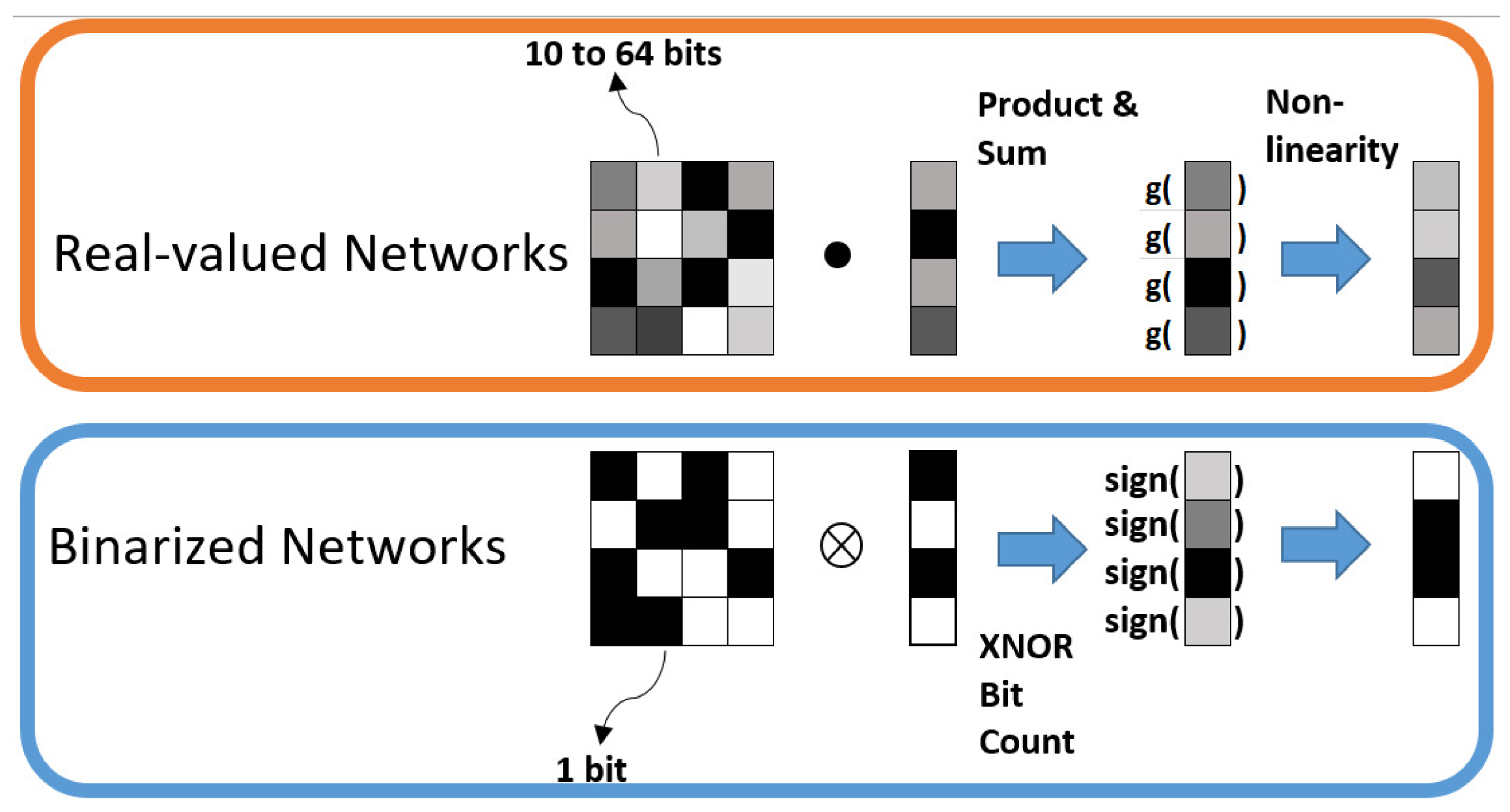
13]. The difference in weight implementation and distribution between a full precision neural network and a BNN [
14] is shown in
Figure 4. While the full precision values can vary from 10 to 64 bits or even more, the BNN has a 1 bit memory stack.
There were various methods of training and quantization described in [
15,
16]. In most methods, the major challenges were the following: (a). In [
15], the authors used the Pascal VOC database, with 2000 iterations for training purpose. This consumed a lot of storage space and I/O resources. (b). Extracting each range’s suggested feature individually wasted a lot of resources because the DNN function’s sharing feature was not used.
The major contributions of this paper are as follows:
The paper analyzes the effect of pattern classification on various DNN classifiers on a IoT based hardware platform, including CNN, QNN, and BNN, and their implementation on an FPGA based IoT platform.
The hardware used in the work is low power, compatible with Python, and mobile, which can also connect to the cloud, making it more compatible with IoT devices.
Using the architecture of a BNN, we can reduce the computing time without much variation in the accuracy.
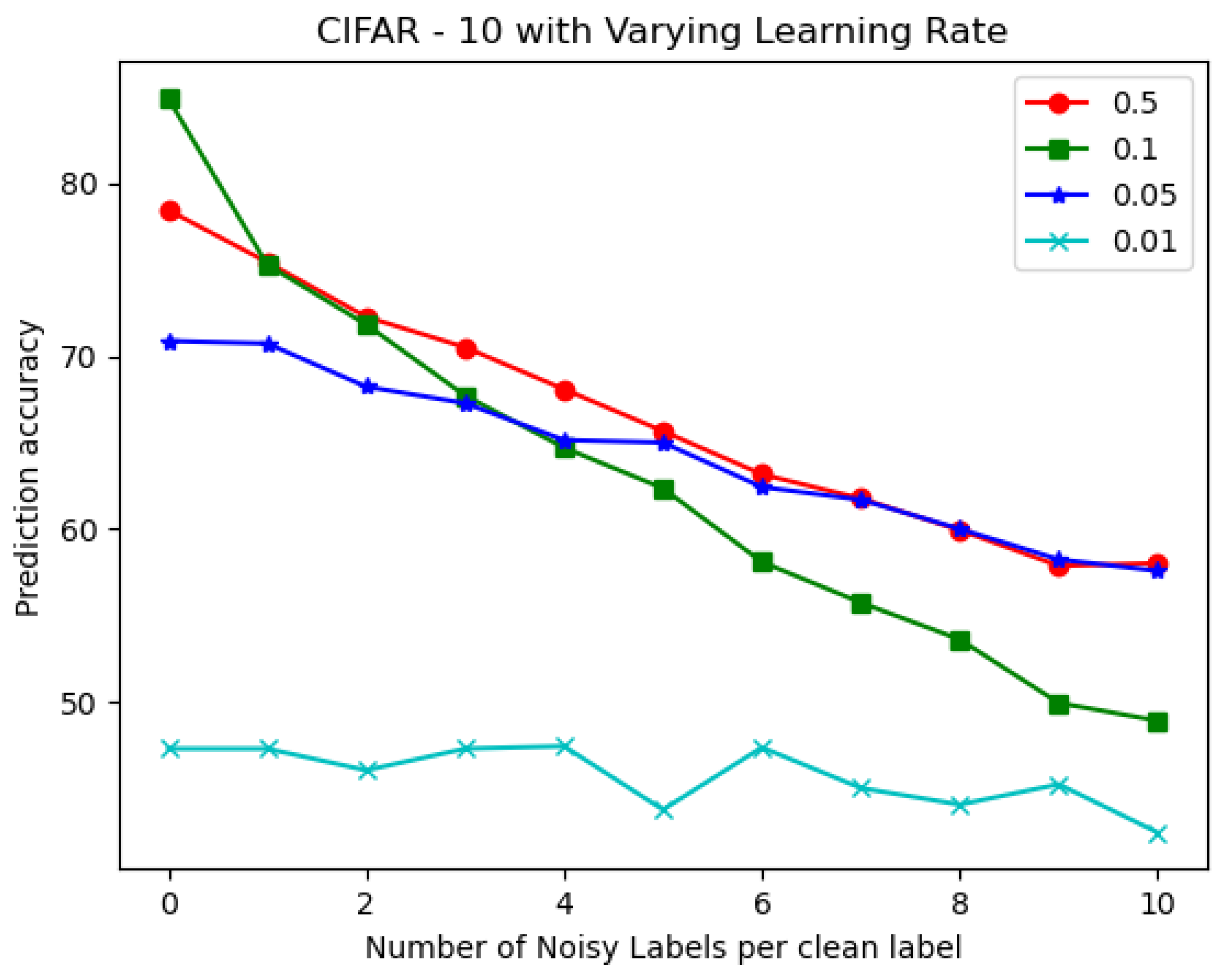
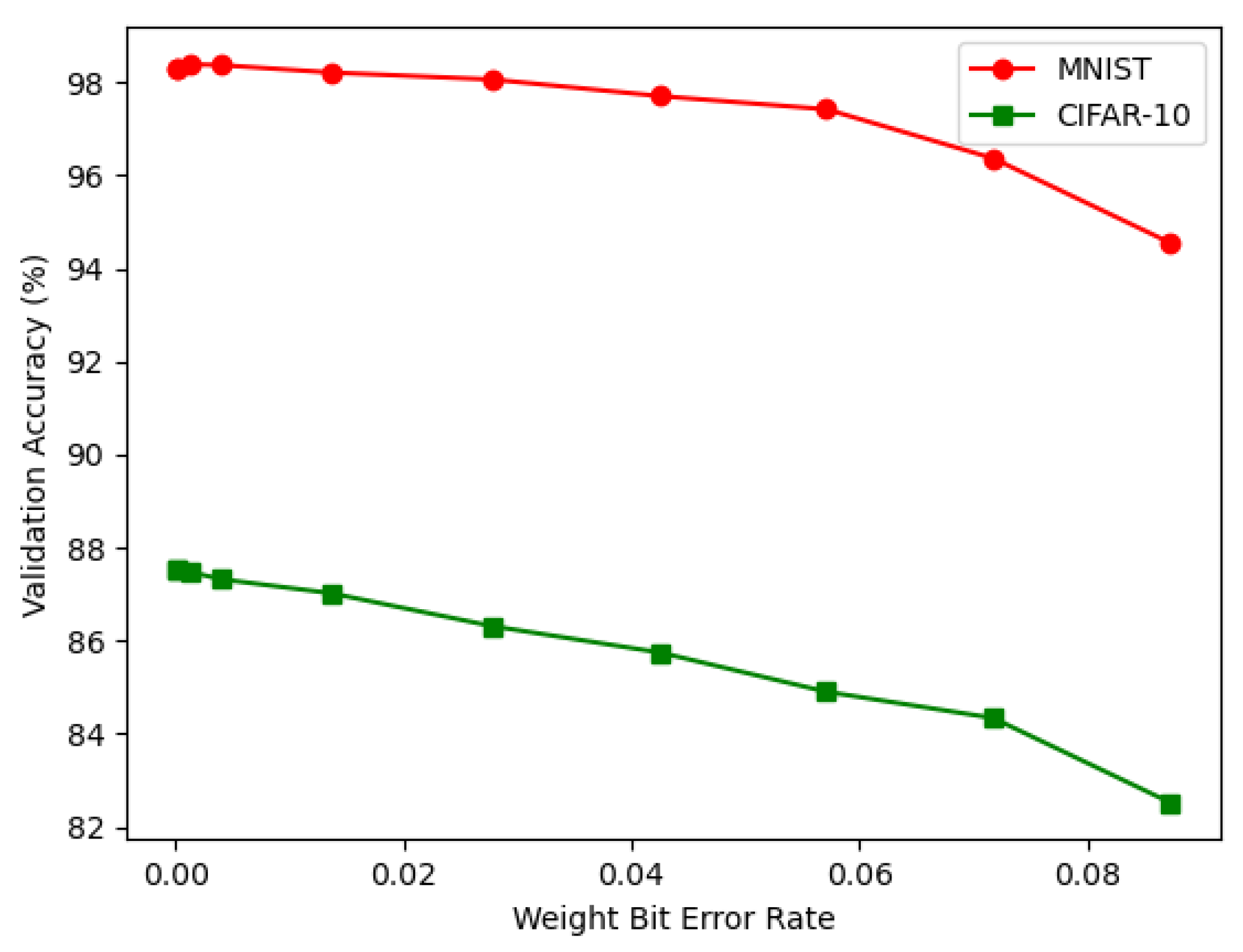
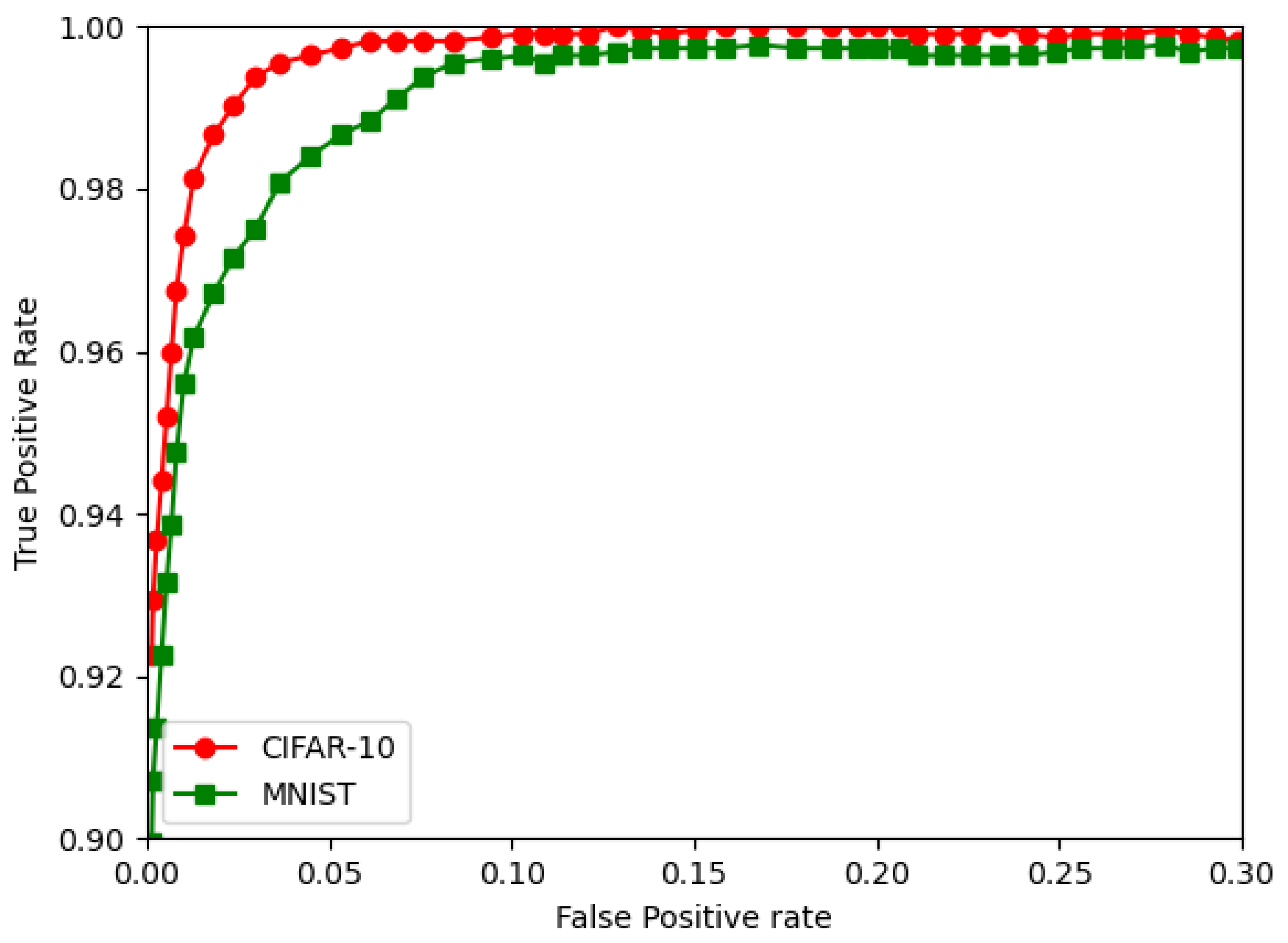
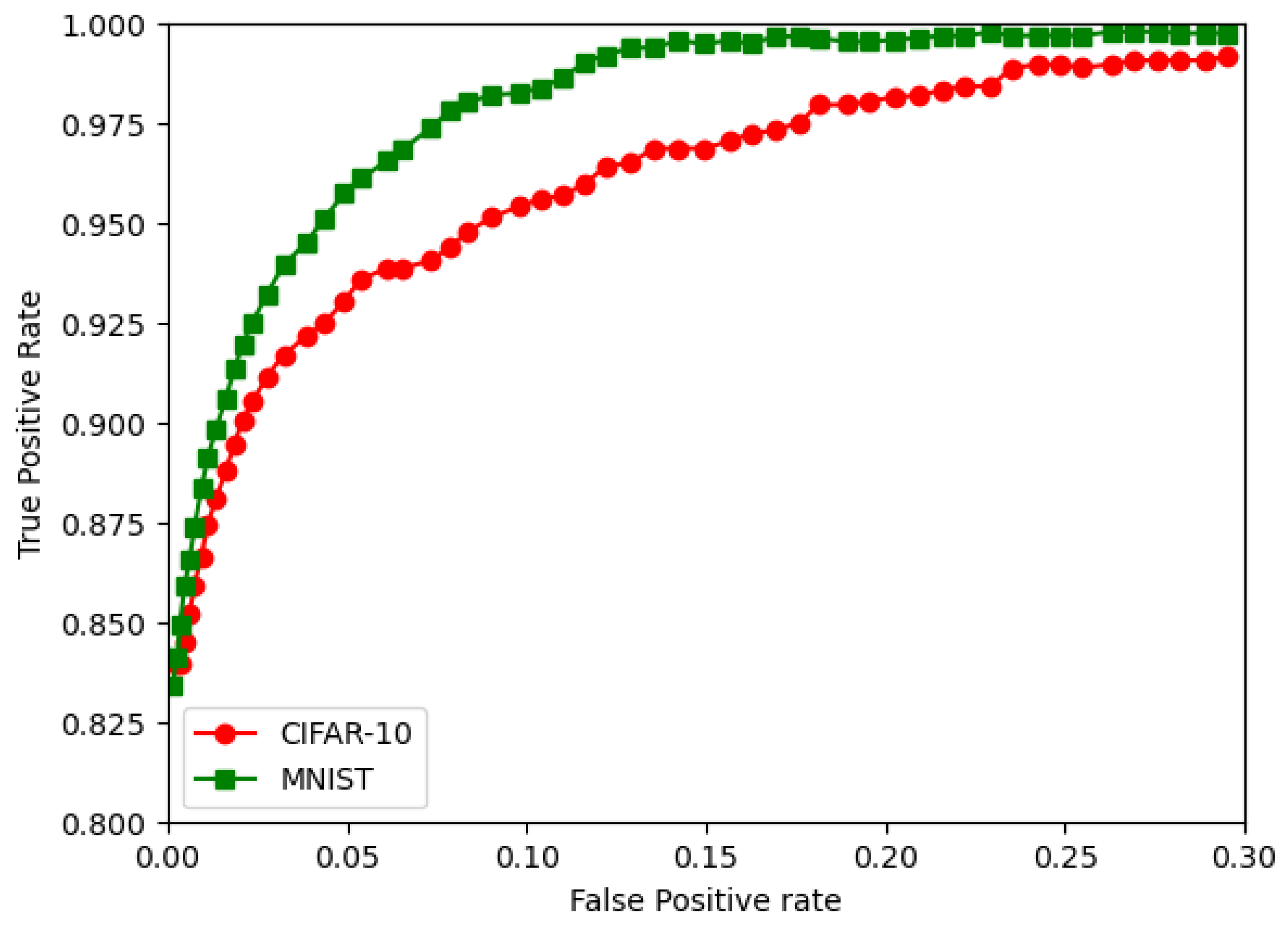
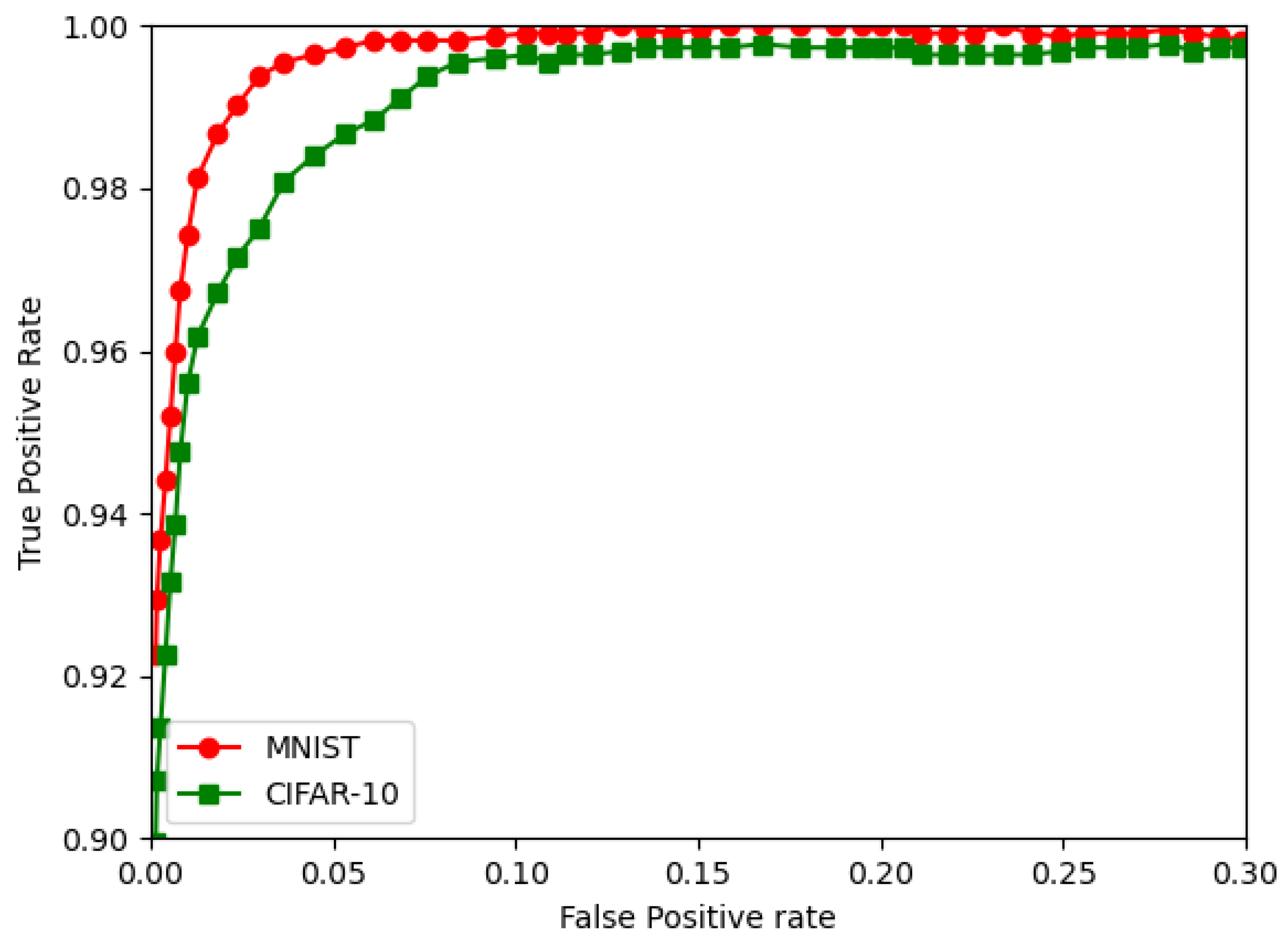
We use the MNIST and CIFAR-10 databases for our analysis in terms of the prediction accuracy, weight bit error rate, RoC curve, and execution time on the PYNQ Z2 FPGA board.
In the remainder of this paper, the related work and a literature survey are presented in
Section 2; the background and the system concept for an IoT-based pattern detection implemented in the PYNQ Z2 FPGA ZYNQ board are described in
Section 3, based on CNN, QNN, and BNN DNN;
Section 4 presents the results and discussion, and
Section 5 concludes this work.
2. Related Work
The recent works on pattern recognition are described as per the CNN, QNN, and BNN works in the FPGA- and IoT-based platforms.
One of the earlier works on BNN was proposed by Austin et al. [
17]. The author described the implementation of a binary neural network on a hardware platform. The research showed that training and implementation was 200 times faster than that of a current workstation. However, with the advent of modern computing platforms, numerous techniques have improved this over time.
A recent work by Li et al. [
9] proposed a fixed sign binary neural network for the IoT. They demonstrated that their FSB algorithm achieved almost full precision results using CIFAR-10 and an imageNet database. They showed that the resource constrained IoT platforms could use BNN along with their proposed algorithm for better accuracy and faster computation.
A VLSI-implemented BNN for an embedded vision-based IoT was proposed by Kumar et al. [
18]. They proposed binary weighted convolutional neural networks and realized them on an FPGA, which helped in the case of low energy resources.
An IoT application for remote sensing application was proposed by Reiter et al. [
19]. The main motive to develop the application was to reduce the bandwidth of expensive earth observation images during capture and transmission. The authors developed a BNN and QNN based real-time remotely sensed cloud detection using FPGA.
Another work on QNN was proposed by Chang et al [
20]. To counter the complex memory and computational complexity involved in full precision CNN, a new method called CLIP-Q was proposed. The authors developed a software and hardware codesigned platform and tested it on the CIFAR-10 and CIFAR-100 datasets. A similar kind of work was proposed by [
21] for quantizing the weights of pretrained neural networks, which was used for multilayer perceptron (MLP) and CNN. The authors used a method to quantize each neuron or hidden unit using a greedy path-following algorithm. They used the MNIST, CIFAR-10, and VGG16 datasets. The methods were more computationally efficient, and the quantization error also decayed with the width of the NN layer.
Due to the difficulty of training a mixed precision model and the vast space of all possible bit quantizations, finding an optimal mixed precision model that can preserve accuracy while satisfying specific constraints on the model size and computation is extremely difficult. For this, Yu et al. [
22] proposed a novel soft Barrier Penalty-based NAS (BP-NAS) for mixed precision quantization. This ensured that all the searched models were within the valid domain defined by the complexity constraint and thus could return an optimal model under the given constraint by conducting a single search.
Similarly, Chu et al. [
15] proposed a mixed-precision QNN with progressively decreasing bitwidth. For feature representation, a bitwidth assignment heuristic based on quantitative separability was provided. Several common CNNs, such as AlexNex, ResNet, and Faster R-CNN, were quantized using the proposed mixed-precision method. Bartan and Mert [
23] presented a convex optimization strategy for training quantized NNs with polynomial activations; hidden convexity in two-layer neural networks, semidefinite lifting, and Grothendieck’s identity were all used for their method.
For network compression, QNN can be an efficient approach that can be implemented on FPGAs. Chen et al. implemented n-bit QNNs [
24]. The authors’ work was able to show similar accuracy when they used Resnet, Densenet, and Alexnet. The experimental work was conducted on an Xilinx ZCU102 platform.
Due to significant losses from the XNOR operations due to binary mapping, Wang et al. [
25] proposed a channel-wise interaction-based binary convolutional neural network learning method (CI-BCNN) for efficient inference. The authors mined the channel-wise interactions by reinforcement learning. For this purpose, they used the CIFAR-10 and ImageNet datasets.
With all the scenarios for recently developed DNN classifiers, the challenge for a simple and readily available computer vision application platform for IoT application still remains. With the demand for low power and higher computing efficiency, the need to use an efficient algorithm for various IoT based applications is always a challenge.
3. Background and System Concept
Pattern classification and subsequent object recognition is the process of recognizing objects and classifying patterns in images. In the case of digital images and video, object recognition is a computing technology related to computer vision that includes image processing that handles the recognition of instances of specific semantic objects (people, buildings, cars, etc.).
Patterns or input images are recognized and categorized according to the CNN, QNN, and BNN methods. In
Figure 1, the input image is collected from the MNIST and CIFAR-10 datasets. The image is first reprocessed for noise removal, which also includes various undesirable regions of the target image. The features of the datasets are classified using the DNN techniques of CNN, BNN, and QNN. In the real-world scenario, the DNN classifier plays a vital role in computer vision, natural language processing, and speech recognition. However, one of the challenges is that DNNs consume large amounts of memory and perform at a high computational cost. This is a great disadvantage to any mobile and compact devices and can greatly impact the battery life.
3.1. Convolution Neural Network (CNN)
The CNN classifier for pattern classification can be described as shown in
Figure 5. The CNN classifier contains three major blocks: (a) a convolution layer, (b) a pooling layer, and (c) an activation layer.
The convolution layer is the main unit of any CNN process. This is the first layer, which takes the input. This layer extracts the feature from the input image. It has three main operations, standard convolution, extended convolution, and transpose convolution.
3.2. Binarized Neural Network (BNN)
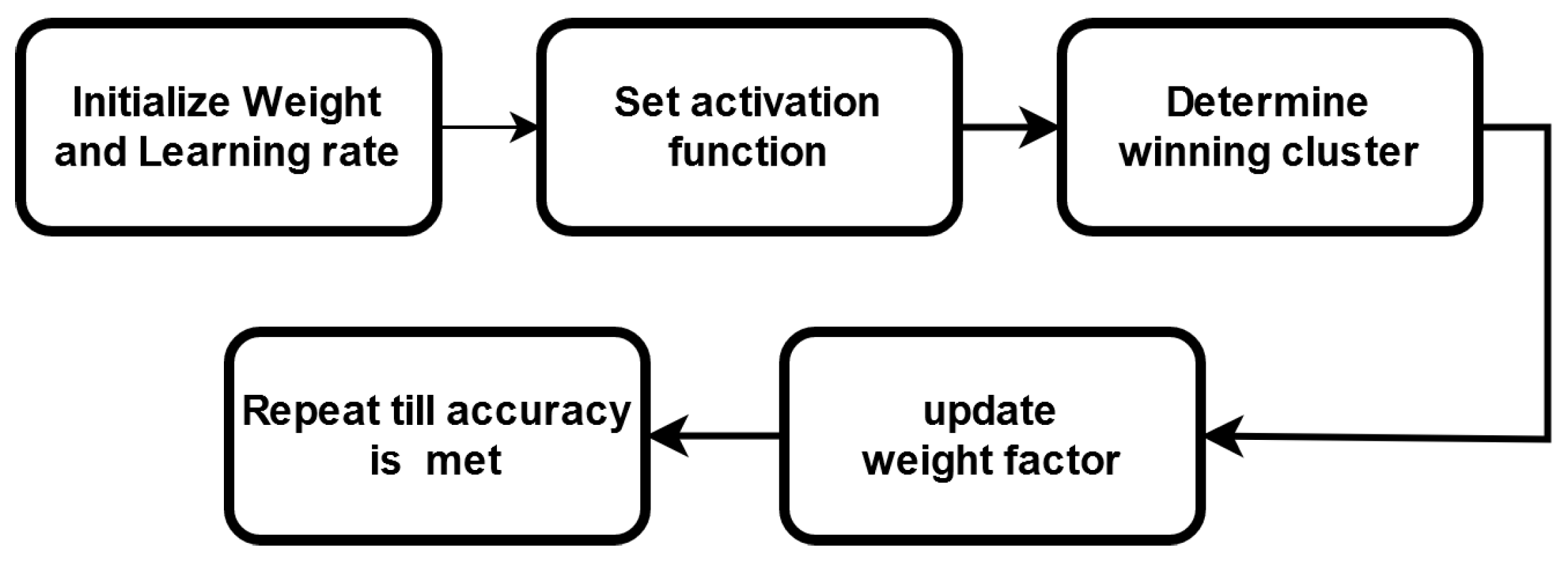
DNNs are computationally expensive and memory intensive for training and storing models. For miniature devices such as IoT devices, this poses a challenge. The binary neural network (BNN) is bounded by the set [+1, −1] [
26]. BNNs require much less memory, which is why they are preferred for low-power devices [
27]. A single-bit of binary data occupies only 1/32 times of the memory needed for a 32-bit display and has 32 times less memory access. A BNN’s architecture is almost identical to that of a CNN; the only difference is that all of its parameters are binarized to either +1 or −1. The −1 is encoded as 0, and +1 is encoded as 1. While using the CIFAR-10 dataset, the BNNs, constructed in the beginning, lost roughly 3% of their accuracy. Binary convolution is easy, as it is computed as 0, 1, and its hardware execution is as easy since it uses a simple XNOR function with a smaller portion. This leads to a lower hardware cost for binary arithmetic.
Figure 6a roughly describes the flowchart block of a BNN.
3.3. Quantized Neural Network (QNN)
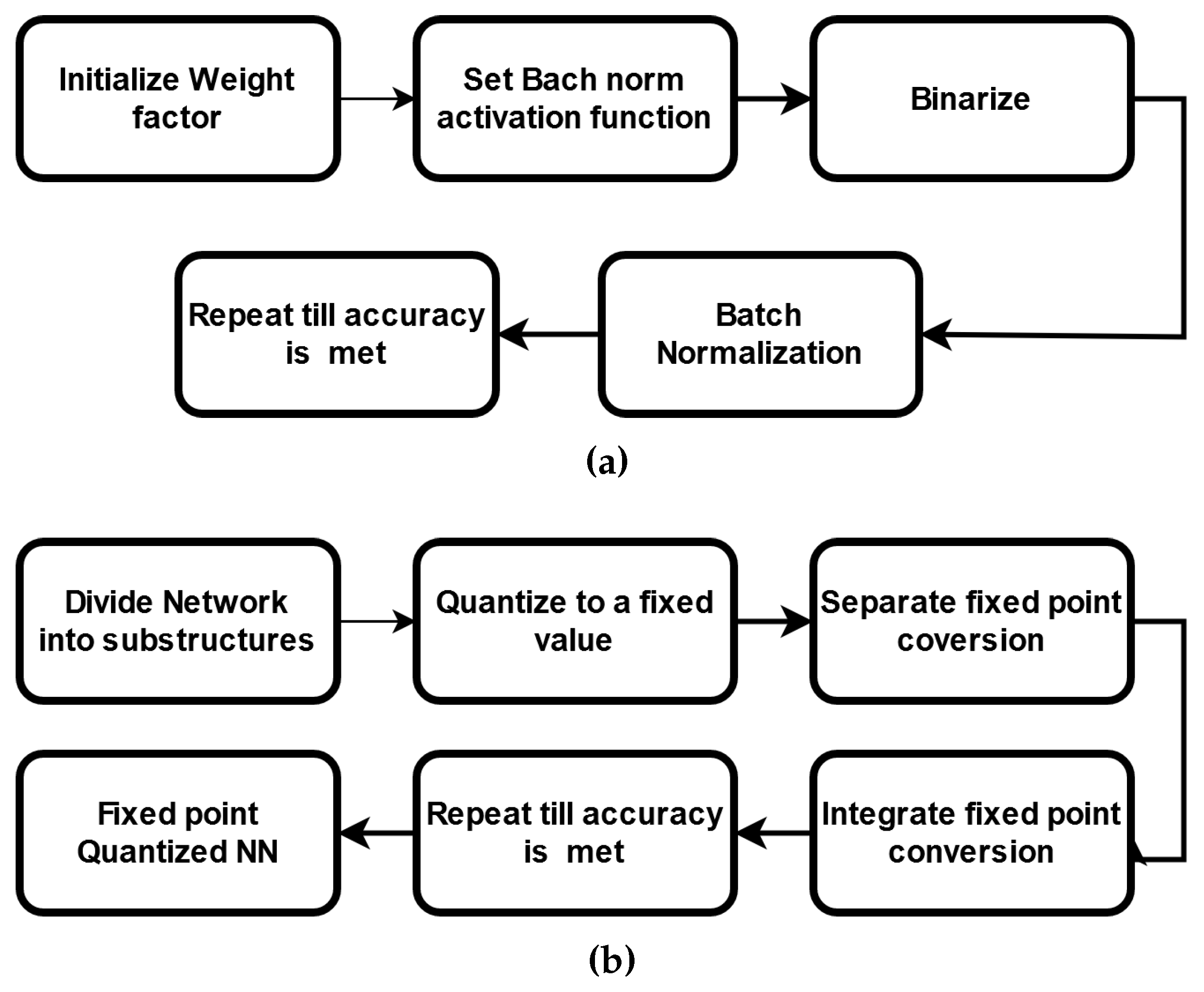
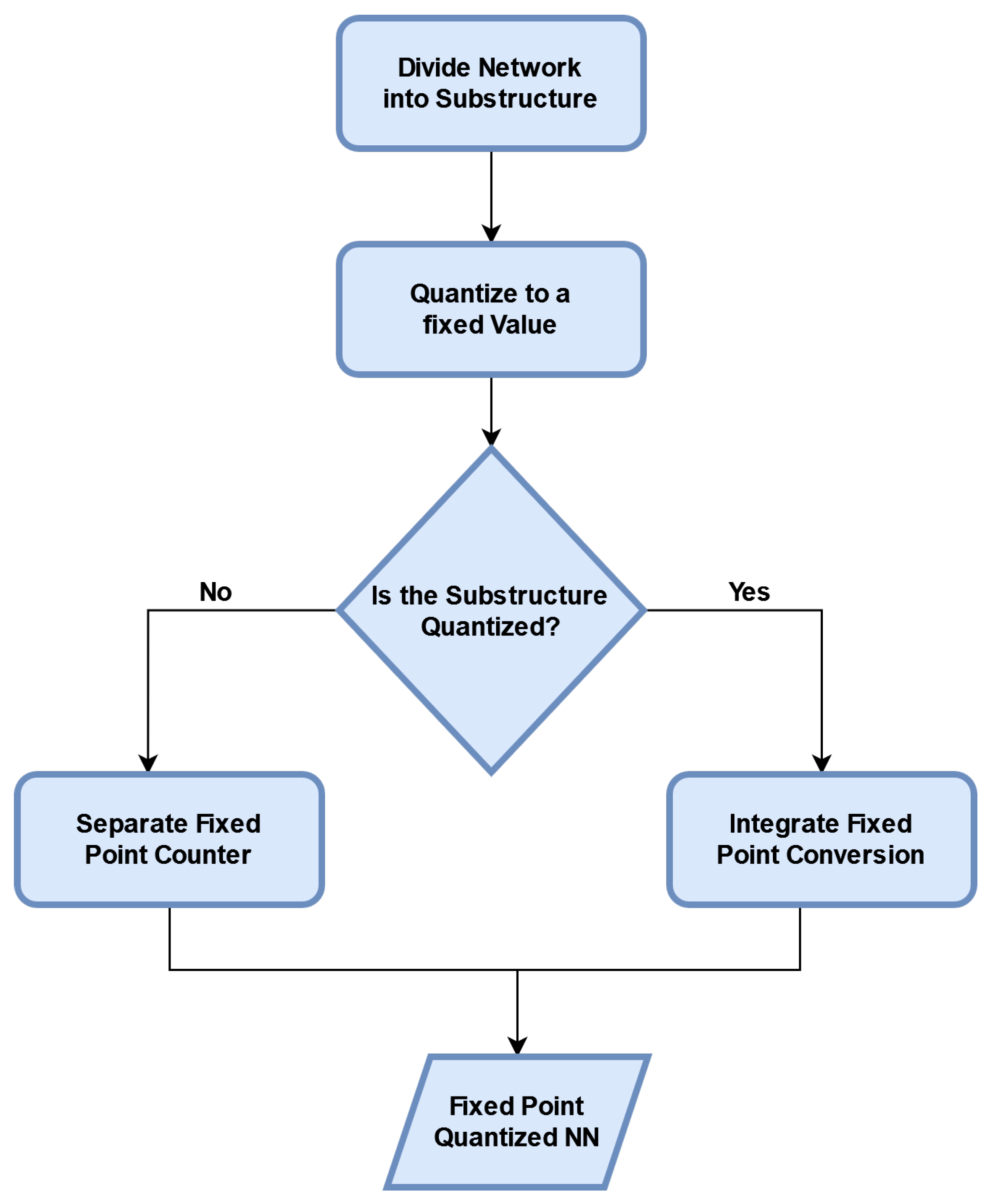
As mentioned, QNNs are low-precision neural networks and can perform similarly to CNN while safeguarding the network structure. A BNN is also a form of a QNN. It defines the model parameters that are conserved by using a smaller bit width; moreover, the model size is reduced several times. QNN consists of a quantization layer, a multiply accumulation (MAC) layer, and a batch normalization layer. Although the storage and computation costs are greatly reduced, data loss due to quantization errors occurs under tradeoff conditions. A suitable quantization architecture should be able to store useful information in continuous variables and is critical to network performances.
Figure 7 describes the typical blocks of a QNN flowchart.
For quantization, to convert from a floating point to fixed point, we need to find the required number of bits m to represent the unsigned integer part:
In the process of quantizing a network, the network can be deployed to the IoT device. Deployment includes:
Exporting DNN weights and encoding them in a suitable format for on-target inference.
Creating an inference program based on the DNN’s architecture.
Compiling the program.
Uploading a weighted inference program to the IoT platform.
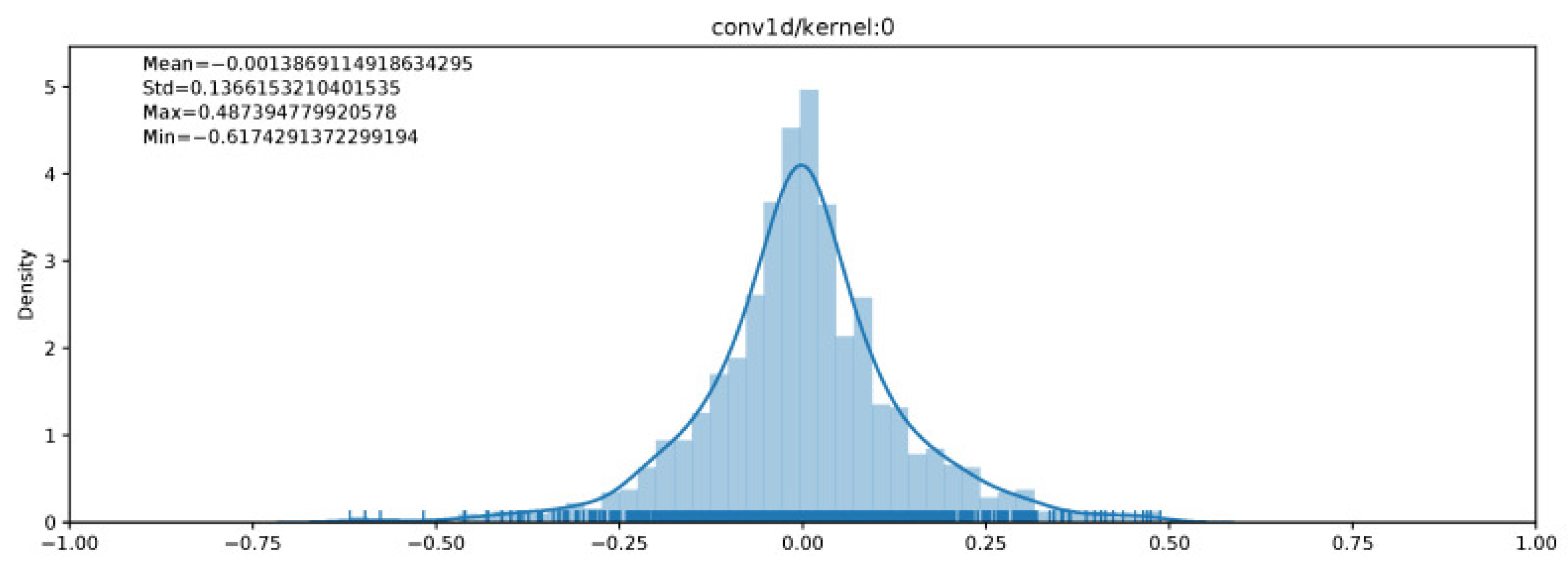
Figure 8 demonstrates the distribution for a convolutional kernel layer.
3.4. Overall Process for Deploying the Algorithms
Import the MNIST and CIFAR-10 database sets.
Set the parameters required for training.
Load a DNN classifier, i.e., CNN, BNN, or QNN.
Perform DNN on the CPU and also on the FPGA-based IoT device.
Observe and analyze the parametric results.
5. Conclusions
A detailed analysis of two pattern classification classes was implemented on low power IoT-based FPGA hardware. The challenge with the DNN-based pattern classification method can be overcome by using a quantized neural network; furthermore, BNN can also be used. The work was performed on an XILINX Zynq 7020 series Pynq board, which served as the hardware platform. The MNIST and CIFAR-10 databases were considered for simulation and experimentation. In this work, the CNN, QNN, and BNN classification algorithm models for the MNIST and CIFAR-10 databases were successfully implemented on an IoT-based hardware platform. The DNN classifier model was implemented in Python and analyzed for various evaluation parameters. These included the prediction accuracy, weight bit error rate, ROC curve, and execution time. The results showed that the BNN and QNN could be efficiently implemented and operated on mobile hardware devices such as the one used in this work, i.e., the ZYNQ Z2 board, which is an FPGA-based device that can be used as an IoT device. The analysis from the experiments performed using the FPGA-based hardware showed that the QNN, including the BNN, for pattern recognition application for IoT applications can be used in IoT based applications including in real time. This can be used for the future scope of the work. Most importantly, the QNN replaced the conventional CNN, reducing the device’s memory usage and computational resources.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}