
Research on Satellite Network Traffic Prediction Based on Improved GRU Neural Network

Abstract
:1. Introduction
- (1)
- In this paper, the correlation characteristics of satellite network traffic are fully considered, and the nonlinear time dynamic correlation is obtained by using a gating unit to avoid gradient disappearance or gradient explosion during training.
- (2)
- In the coding and decoding stages of the GRU network, an attention mechanism is introduced, and multiple intermediate vectors are added to uniformly process the time series and input information of the intermediate vectors at the current movement.
- (3)
- Particle swarm optimization algorithm is used to adjust the hyperparameters of the neural network.
2. Literature Review
3. Definition and Model of the Satellite Traffic Forecast Problem
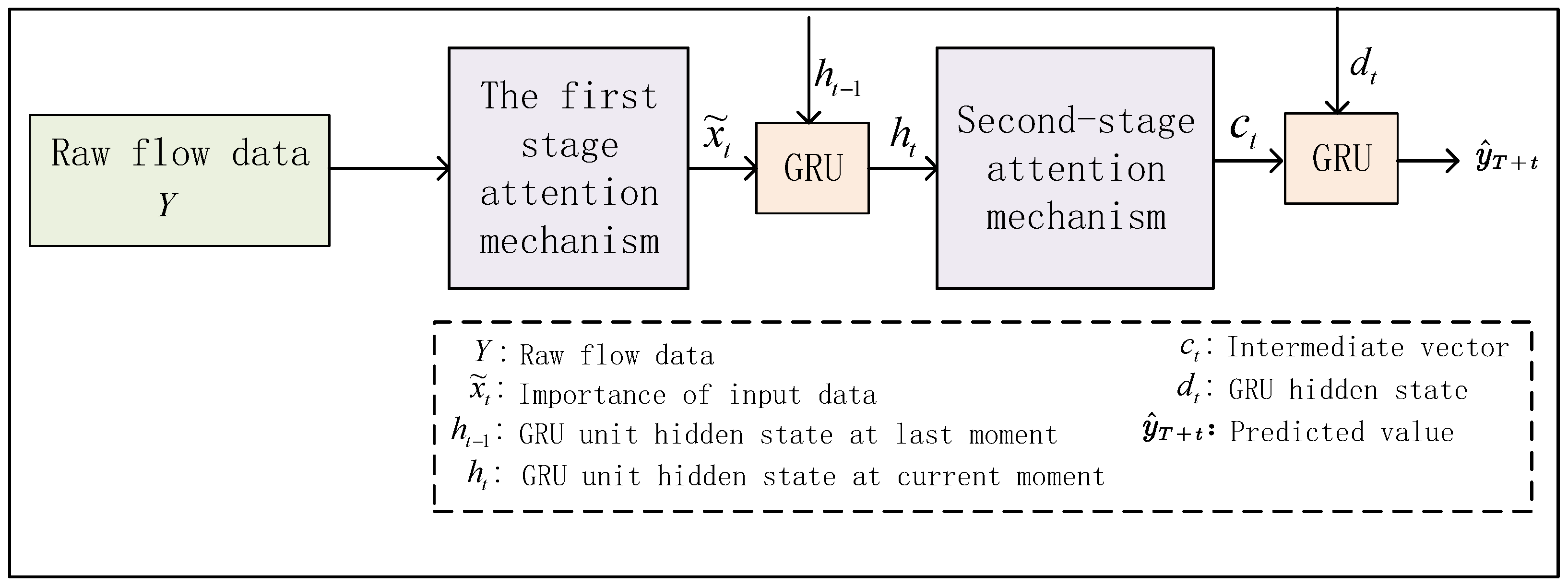
4. Traffic Prediction Method of the AT-GRU Satellite Network
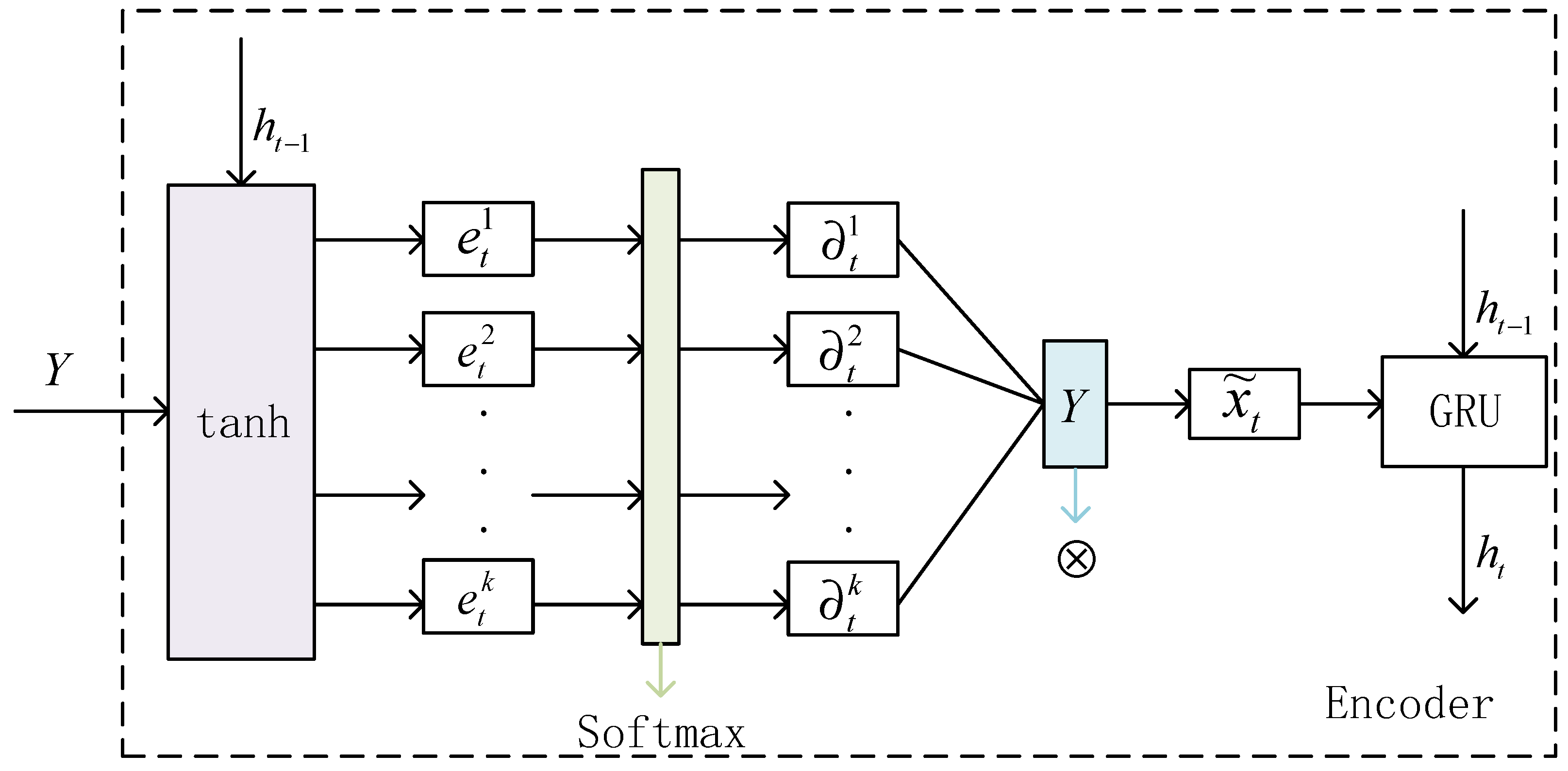
4.1. Design of Coding Unit Based on Attention Mechanism
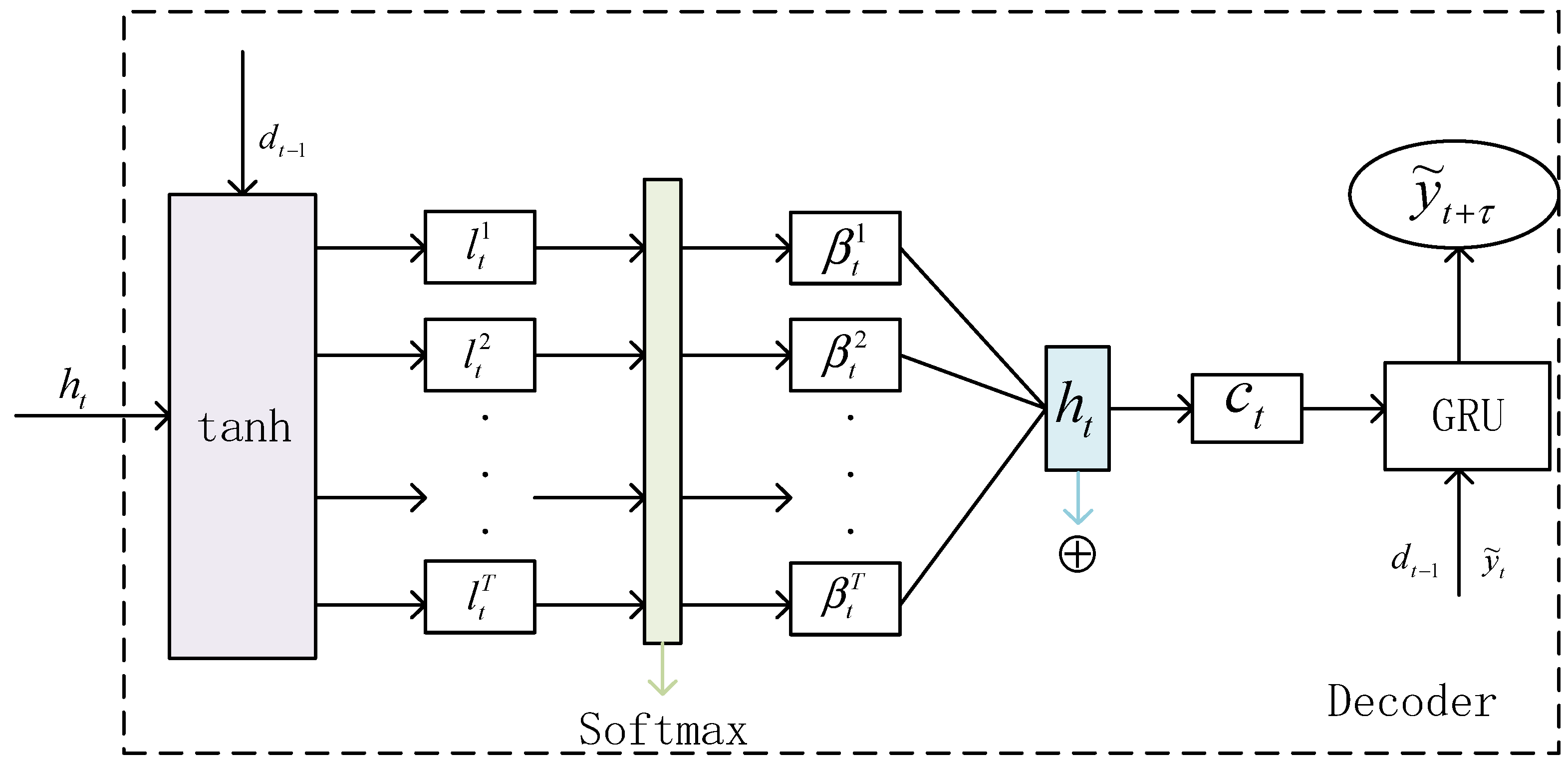
4.2. Design of Decoding Unit Based on Attention Mechanism
4.3. PSO Algorithm for GRU Hyperparameter Selection Problem
| Algorithms 1: Optimization algorithm of model hyperparameters based on PSO |
| Input: Initialize parameters such as population size and iteration times; Outputs: Optimal hyperparameters of neural network; 1. Procedure PSO; 2. 3. for each particle i do 4. Initialize the velocity vi and position of particle i 5. Evaluate particle i and set 6. end for 7. ; 8. While not stopping do 9. for to do 10. Update the velocity and position of the particle i; 11. Evaluate particle ; 12. if then 13. 14. end if 15. if then 16. 17. end if 18. end for 19. end while 20. Print 21. end procedure |
4.4. Loss Function
5. Results Simulation and Analysis
5.1. Description of the Data Set
5.2. Experimental Environment
5.3. Evaluation Index and Parameter Setting of Simulation
5.3.1. Evaluating Indicator
5.3.2. Results and Analysis of Optimal Parameter Combination of Model
- (1)
- Learning rate: A large choice for learning rate will lead to the lowest loss, while a small choice will lead to the local optimum of the result. Therefore, an appropriate learning rate is crucial. As shown in Figure 7, with the iterative evolution of the PSO optimization algorithm, the learning rate stabilized at 0.073 in the 12th iteration of the optimization algorithm. Therefore, the learning rate selected by the model was 0.073.
- (2)
- Several neurons: The number of neurons will affect the learning ability and network complexity of the model. Too many nodes will prolong the network training time, while too few nodes will lead to poor network performance. As shown in the Figure 8, after the ninth iteration of the optimization algorithm, the number of neurons was stable at 35.
- (3)
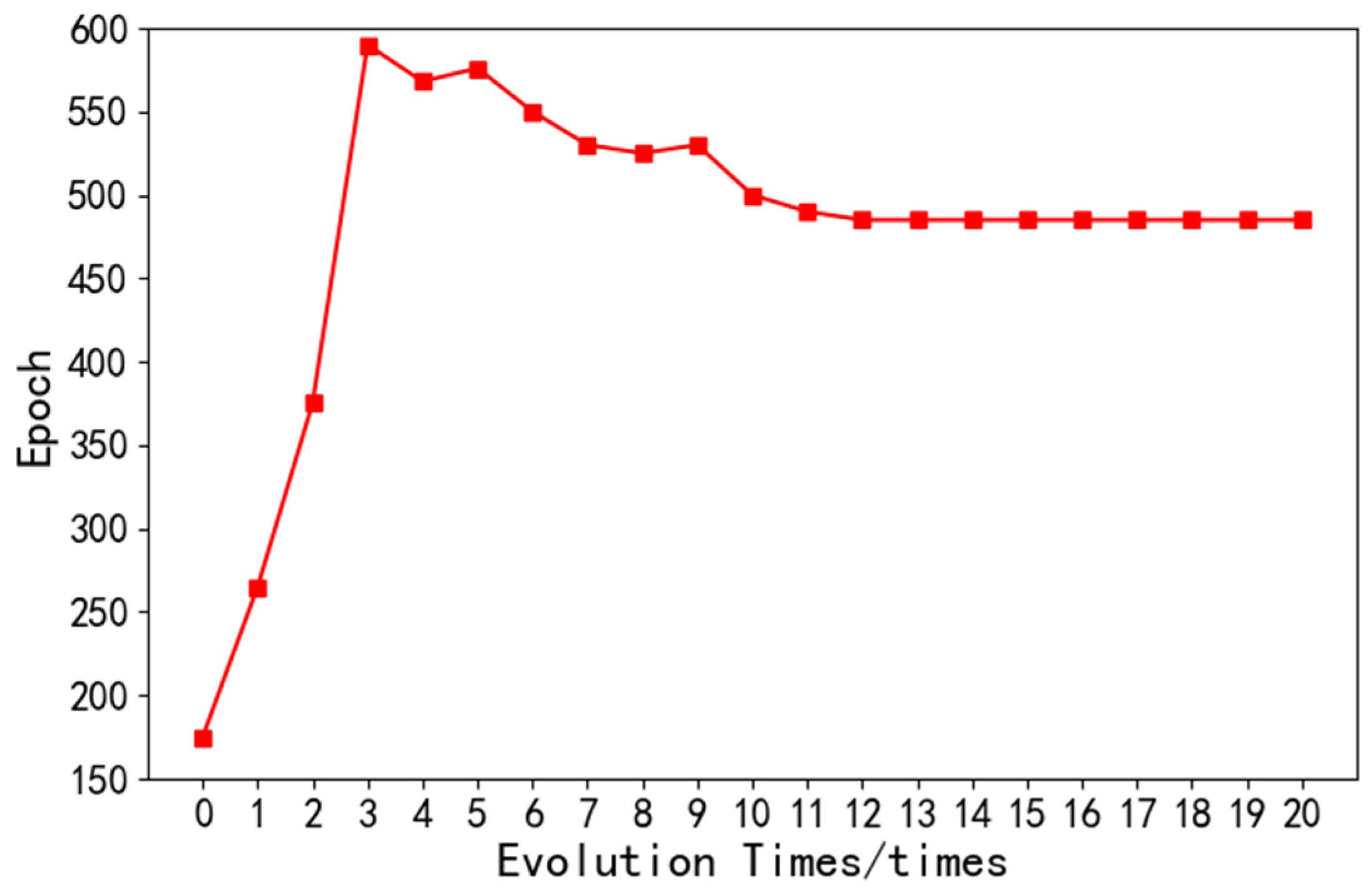
- Epoch: Epoch means training the network model once with all the data in the training set. Through the continuous iteration of the neural network, the loss value can be minimized. As shown in the Figure 9, after the 11th iteration of the optimization algorithm, the number of iterations of the network model finally stabilized at 500.
5.4. Comparison and Analysis of Simulation Results of Different Algorithms
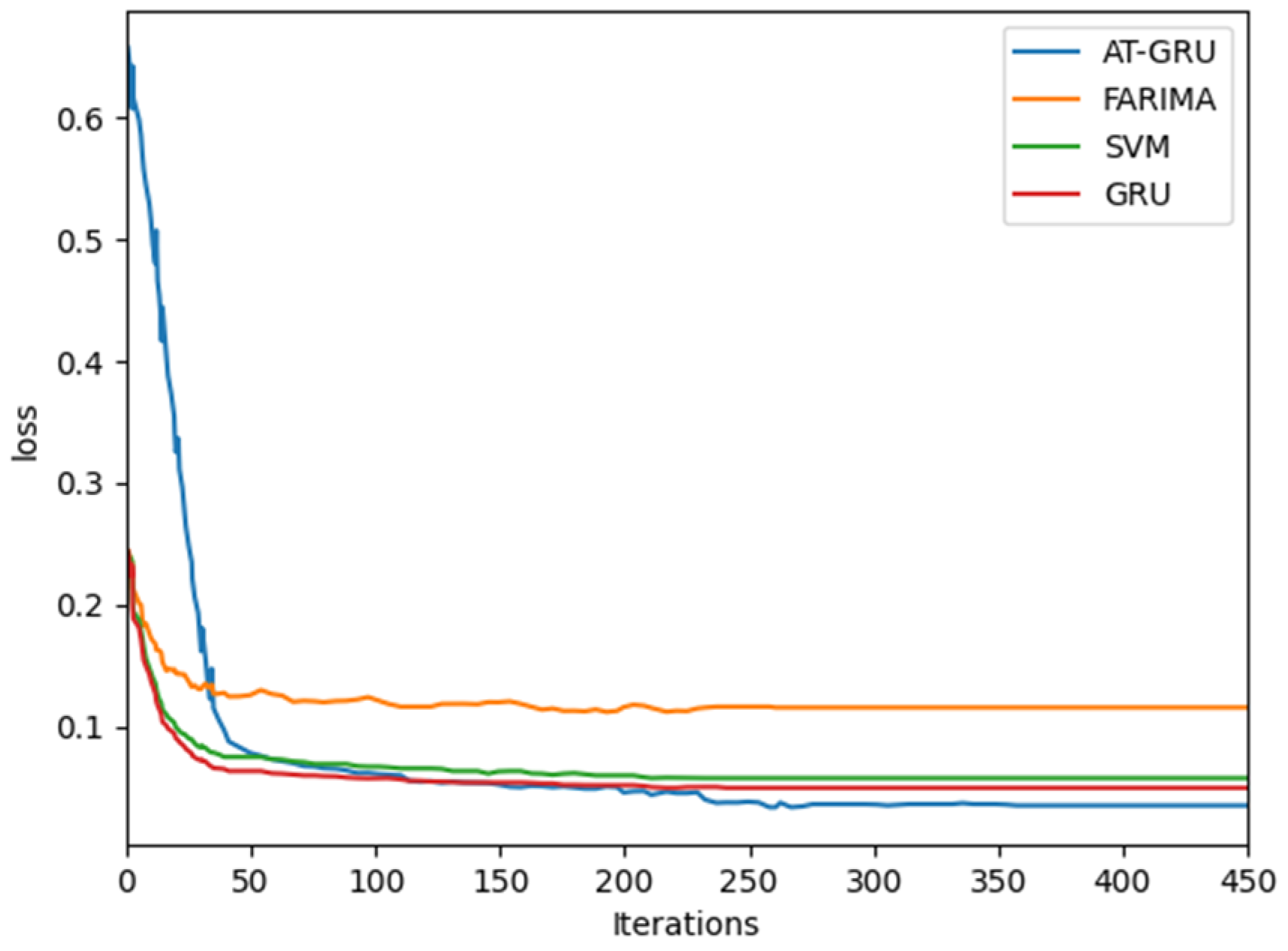
5.5. Convergence Analysis
5.6. Model Complexity Analysis
6. Summary and Prospect
6.1. Critical Analysis and Discussion
6.2. Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, J.; An, Y.; Wang, B.; Fang, W. ERSVC: An Efficient Routing Scheme for Satellite Constellation Adapting Vector Composition. Procedia Comput. Sci. 2012, 10, 984–991. [Google Scholar] [CrossRef] [Green Version]
- Lixiang, L. Analysis of the architecture and protocol of the integrated information network between heaven and earth. J. Chongqing Univ. Posts Telecommun. Nat. Sci. 2018, 30, 9–21. [Google Scholar]
- Zhu, Y.; Sheng, M.; Li, J.; Liu, R.; Wang, Y.; Chi, K. Traffic Modeling and Performance Analysis for Remote Sensing Satellite Networks. In Proceedings of the GLOBECOM 2018—2018 IEEE Global Communications Conference, Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar]
- Dong, Y.; Wang, L. TPDR: Traffic prediction based dynamic routing for LEO&GEO satellite networks. In Proceedings of the International Conference on Electronics Information & Emergency Communication, Beijing, China, 14–16 May 2015; pp. 104–107. [Google Scholar]
- Chen, Q.; Zhang, Y.; Guo, J.; Yang, L.; Fan, C.; Zhao, Y.; Chen, X. Traffic Prediction Based on Surrogate Model in Satellite Constellation Networks. In Proceedings of the 2019 12th IFIP Wireless and Mobile Networking Conference (WMNC), Paris, France, 11–13 September 2019; pp. 126–130. [Google Scholar]
- Christian, G.A.; Wijaya, I.P.; Sari, R.F. Network Traffic Prediction Of Mobile Backhaul Capacity Using Time Series Forecasting. In Proceedings of the 2021 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 21–22 July 2021; pp. 58–62. [Google Scholar] [CrossRef]
- Li, J.; Dong, C.B. Research on network security situation Prediction oriented adaptive learning neuron. In Proceedings of the 2nd International Conference on Networks Security. Wireless Communication and Trusted Computing, Wuhan, China, 24–25 April 2010; pp. 483–485. [Google Scholar]
- Zhou, W.; Wang, W.; Zhao, D. Passenger flow forecasting in metro transfer station based on the combination of singular spectrum analysis and AdaBoost-weighted extreme learning machine. Sensors 2020, 20, 3555. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Mu, D.; Liu, Y. Research on network traffic prediction model based on neural network. In Proceedings of the 2019 2nd International Conference on Information Systems and Computer Aided Education (ICISCAE), Wuhan, China, 24–25 April 2019; pp. 554–557. [Google Scholar]
- Vinchoff, C.; Chung, N.; Gordon, T.; Lyford, L.; Aibin, M. Traffic prediction in optical networks using graph convolutional generative adversarial networks. In Proceedings of the 2020 22nd International Conference on Transparent Optical Networks (ICTON), Bari, Italy, 19–23 July 2020; pp. 1–4. [Google Scholar]
- Li, M.; Wang, Y.; Wang, Z.; Zheng, H. A deep learning method based on an attention mechanism for wireless network traffic prediction. Ad Hoc Netw. 2020, 107, 102258. [Google Scholar] [CrossRef]
- Wang, S.; Zhuo, Q.; Yan, H. A network traffic prediction method based on LSTM. ZTE Commun. 2019, 17, 19–25. [Google Scholar]
- Nikravesh, A.Y.; Ajila, S.A.; Lung, C.H.; Ding, W. Mobile Network Traffic Prediction Using MLP, MLPWD, and SVM. In Proceedings of the IEEE International Congress on Big Data, San Francisco, CA, USA, 27 June–2 July 2016; pp. 402–409. [Google Scholar]
- Liu, D.; Xu, X.; Xu, W.; Zhu, B. Graph convolutional network: Traffic speed prediction fused with traffic flow data. Sensors 2021, 21, 6402. [Google Scholar] [CrossRef] [PubMed]
- Sudhakaran, S.; Venkatagiri, A.; Taukari, P.A.; Jeganathan, A.; Muthuchidambaranathan, P. Metropolitan cellular traffic prediction using deep learning techniques. In Proceedings of the 2020 IEEE International Conference on Communication, Networks and Satellite (Comnetsat), Batam, Indonesia, 17–18 December 2020; pp. 6–11. [Google Scholar]
- Li, N.; Hu, L.; Deng, Z.L.; Su, T.; Liu, J.W. Research on GRU neural network Satellite traffic prediction based on transfer learning. Wirel. Pers. Commun. 2021, 118, 815–827. [Google Scholar] [CrossRef]
- Liu, R.; Sheng, M.; Lui, K.S.; Wang, X.; Zhou, D.; Wang, Y. Capacity of two-layered satellite networks. Wirel. Netw. 2017, 23, 2651–2669. [Google Scholar] [CrossRef]
- Zhao, R.; Wang, D.; Yan, R.; Mao, K.; Shen, F.; Wang, J. Machine health monitoring using local feature-based gated recurrent unit networks. IEEE Trans. Ind. Electron. 2017, 65, 1539–1548. [Google Scholar] [CrossRef]
- Wang, B.; Kong, W.; Guan, H.; Xiong, N.N. Air quality forecasting based on gated recurrent long short term memory model in Internet of Things. IEEE Access 2019, 7, 69524–69534. [Google Scholar] [CrossRef]
- Li, Z.; Yuan, R.; Yuan, W.; Jiangnan, Q.; Zhang, Y. Research progress in attention mechanism in deep learning. J. Chin. Inf. Process. 2019, 33, 1–11. [Google Scholar]
- Wang, Q.; Yuan, C.; Wang, J.; Zeng, W. Learning attentional recurrent neural network for visual tracking. IEEE Trans. Multimed. 2018, 21, 930–942. [Google Scholar] [CrossRef]
- Verma, P. Attention is All You Need? Good Embeddings with Statistics are enough: Audio Understanding WITHOUT Convolutions/Transformers/BERTs/Mixers/Attention/RNNs or…. arXiv 2021, arXiv:2110.03183. [Google Scholar]
- Lecun, Y.; Bottou, L.; Orr, G.B. Neural Networks: Tricks of the Trade. Can. J. Anaesth. 2012, 41, 658. [Google Scholar]
- SONG, M.; Mo, L.; Zhou, K. Influence of inertia weight and learning factor on the performance of standard pso algorithm. J. Jishou Univ. (Nat. Sci. Ed.) 2019, 40, 24. [Google Scholar]
- Chang, Z.; Zhang, Y.; Chen, W. Effective Adam-Optimized LSTM Neural Network for Electricity Price Forecasting. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018; pp. 245–248. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Yuan, Y.; Zeng, N.; Hone, K.; Liu, X. A novel sigmoid-function-based adaptive weighted particle swarm optimizer. IEEE Trans. Cybern. 2019, 51, 1085–1093. [Google Scholar] [CrossRef]
- Guan, N.; Shan, L.; Yang, C.; Xu, W.; Zhang, M. Delay Compensated Asynchronous Adam Algorithm for Deep Neural Networks. In Proceedings of the 2017 IEEE International Symposium on Parallel and Distributed Processing with Applications and 2017 IEEE International Conference on Ubiquitous Computing and Communications (ISPA/IUCC), Guangzhou, China, 12–15 December 2017; pp. 852–859. [Google Scholar] [CrossRef]
- Yang, J.; Sheng, H.; Wan, H.; Yu, F. FARIMA Model Based on Particle Swarm-genetic Hybrid Algorithm Optimization and Application. In Proceedings of the 2021 3rd International Academic Exchange Conference on Science and Technology Innovation (IAECST), Guangzhou, China, 10–12 December 2021; pp. 188–192. [Google Scholar]
- Tang, Y.; Zhou, J. The performance of PSO-SVM in inflation forecasting. In Proceedings of the 2015 12th International Conference on Service Systems and Service Management (ICSSSM), Guangzhou, China, 22–24 June 2015; pp. 1–4. [Google Scholar]
- Yang, S.; Yu, X.; Zhou, Y. Lstm and gru neural network performance comparison study: Taking yelp review dataset as an example. In Proceedings of the 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 12–14 June 2020; pp. 98–101. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Value |
|---|---|
| CPU | Core i7-9700K |
| GPU | NVIDIA GeForce RTX 2080TI |
| Memory capacity | 11 G |
| RAM | 64 G |
| Disk capacity | 2 TB |
| Prediction Model | MAE | RMSE | R2 | FLOPS |
|---|---|---|---|---|
| GRU | 19.49 | 28.08 | 0.8499 | 28.61 G |
| SVM | 22.68 | 32.25 | 0.8459 | 28.06 G |
| FARIMA | 33.73 | 42.20 | 0.7142 | 55.62 G |
| AT-GRU | 14.24 | 20.37 | 0.9552 | 25.03 G |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Li, W.; Feng, J.; Zhang, J. Research on Satellite Network Traffic Prediction Based on Improved GRU Neural Network. Sensors 2022, 22, 8678. https://doi.org/10.3390/s22228678
Liu Z, Li W, Feng J, Zhang J. Research on Satellite Network Traffic Prediction Based on Improved GRU Neural Network. Sensors. 2022; 22(22):8678. https://doi.org/10.3390/s22228678
Chicago/Turabian StyleLiu, Zhiguo, Weijie Li, Jianxin Feng, and Jiaojiao Zhang. 2022. "Research on Satellite Network Traffic Prediction Based on Improved GRU Neural Network" Sensors 22, no. 22: 8678. https://doi.org/10.3390/s22228678