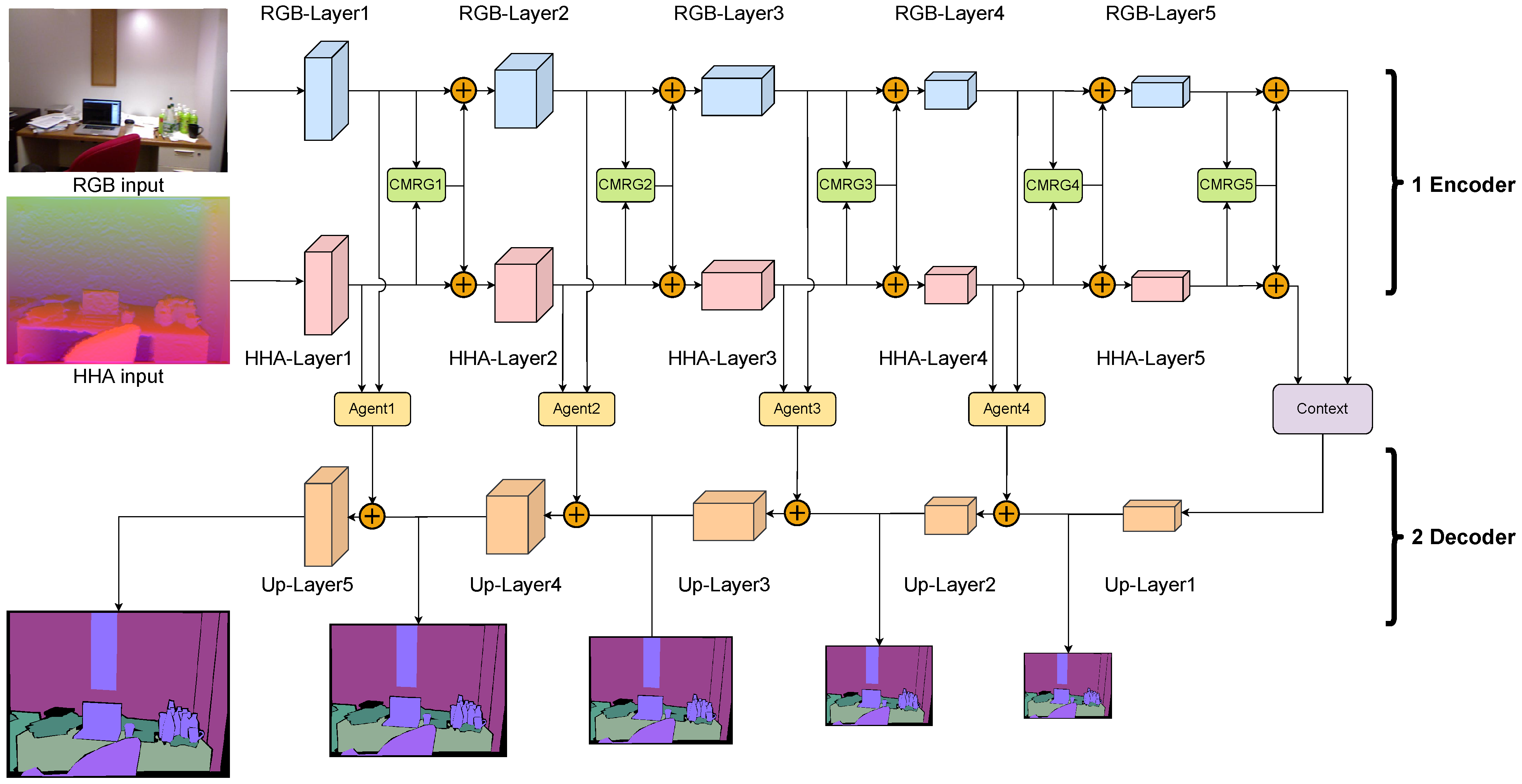
For RGB and HHA data, the former mainly record appearance information (e.g., color, texture) that can emphasize the visual boundary, whereas the latter primarily capture shape information (e.g., structure, spatial) that can highlight the geometric boundary. Thus, it is challenging to fully utilize RGB and HHA images via fusion and enhancement of cross-modality features. We propose the Cross-Modality Refine Gate (CMRG) based on the attention mechanism to aggregate features from multiple modalities.
3.2.1. Convolutional Block Attention Module
As discussed in
Section 2, the attention mechanism has been extensively used in the CV field for determining where the focus should be placed and for deciding what is valuable. In particular, the Convolutional Block Attention Module (CBAM) combines channel and spatial-attention mechanisms during propagation, an achieves outstanding performance in feature extraction [
40]. For further modification of the CBAM, we discuss its overall structure and sub-modules details first.
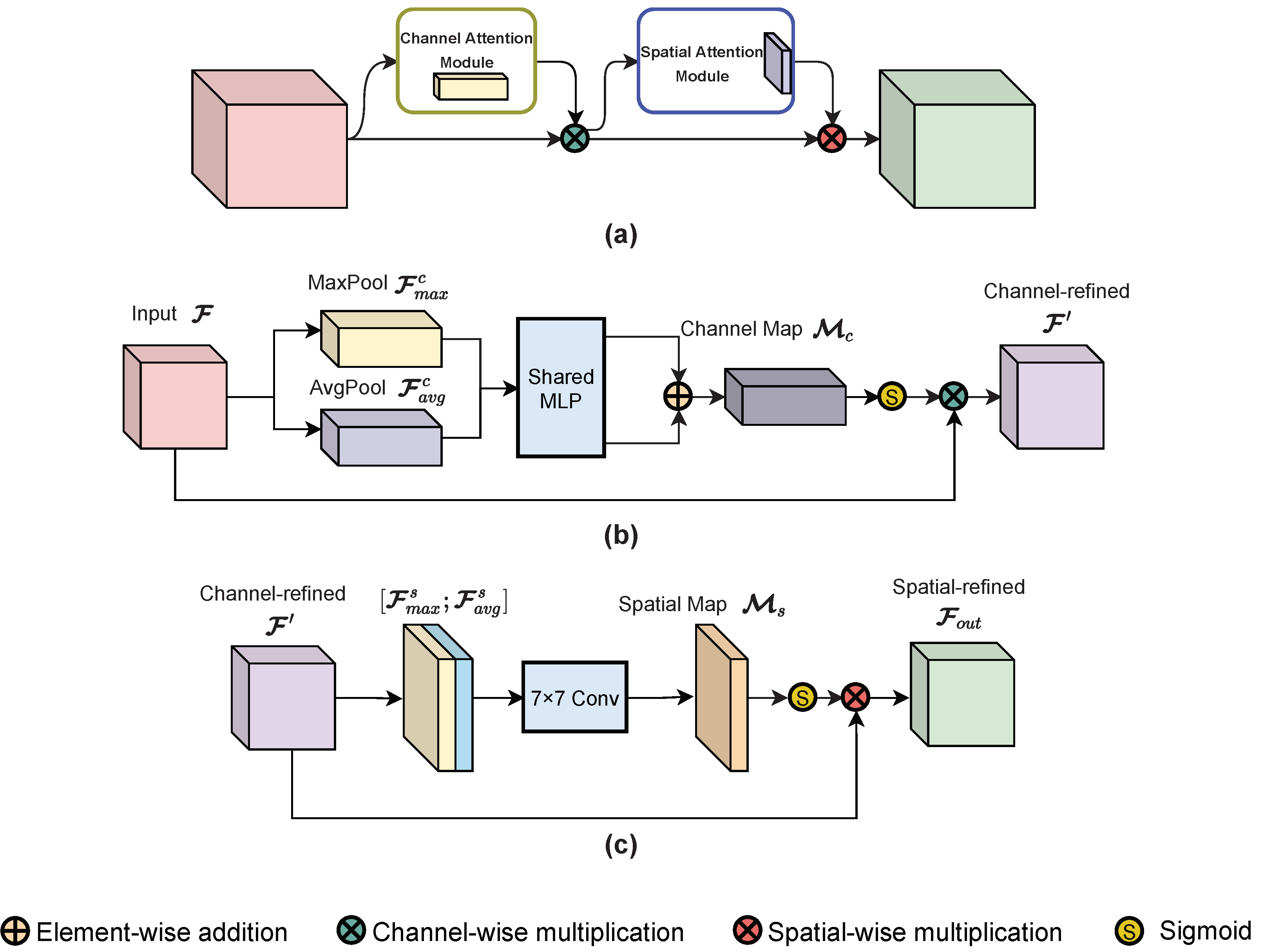
The structures of the CBAM and its sub-modules are shown in
Figure 6. The CBAM refines the input feature maps by sequentially applying one channel-attention module and one spatial-attention module, as illustrated in
Figure 6a. Given input feature maps
, the CBAM first infers a 1D channel-attention map
using the channel-attention module and refines the feature maps via channel-wise multiplication; then, it infers a 2D spatial-attention map
using the spatial-attention module and performs spatial-wise multiplication on the channel-refined feature maps to yield the output. The CBAM process can be formulated as follows:
where
represents the input feature maps,
represents the channel-refined feature maps,
represents the final output, and ⊗ denotes element-wise multiplication. In the multiplication procedure, the attention values are broadcast as follows. Channel-attention values are broadcast along the spatial dimension (channel-wise multiplication), while spatial-attention values are broadcast along the channel dimension (spatial-wise multiplication).
Figure 6b,c describe the detailed structure of the channel-attention module and the spatial-attention module.
As shown in
Figure 6b, the channel-attention module first aggregates the spatial information of input feature
into two descriptors, average-pooled features
and max-pooled features
, via average-pooling and max-pooling operations, respectively. Then, both descriptors are supplied to a shared network containing one hidden layer of multi-layer perception (MLP). A reduction ratio is set to the shared MLP in order to decrease parameter overhead. After propagation in the shared MLP, the descriptors are fused by element-wise summation and modified by a sigmoid function to produce the channel-attention map
. At last, the channel-refined features
can be generated by multiplying the attention map and input features. The channel-attention map is computed as follows:
where
denotes the sigmoid function,
and
represent the MLP weights, and
r is the reduction ratio. As specified, the MLP weights are shared with both inputs.
represents the channel-attention map,
represents the average-pooled features, and
represents the max-pooled features.
The spatial-attention module is presented in
Figure 6c. Similar to the aforementioned channel-attention module, the spatial-attention module aggregates channel information of the refined features to maps
and
first via average-pooling and max-pooling along the channel axis. The two maps are then merged by concatenation. After that, the concatenated features are convolved by a standard convolution layer to generate the spatial-attention map
. The final refined features are also produced by multiplication. The spatial-attention map is computed as follows:
where
denotes the sigmoid function,
represents the
convolutional layer, and
refers to the concatenation.
represents the spatial-attention map,
, and
represent the pooled maps.
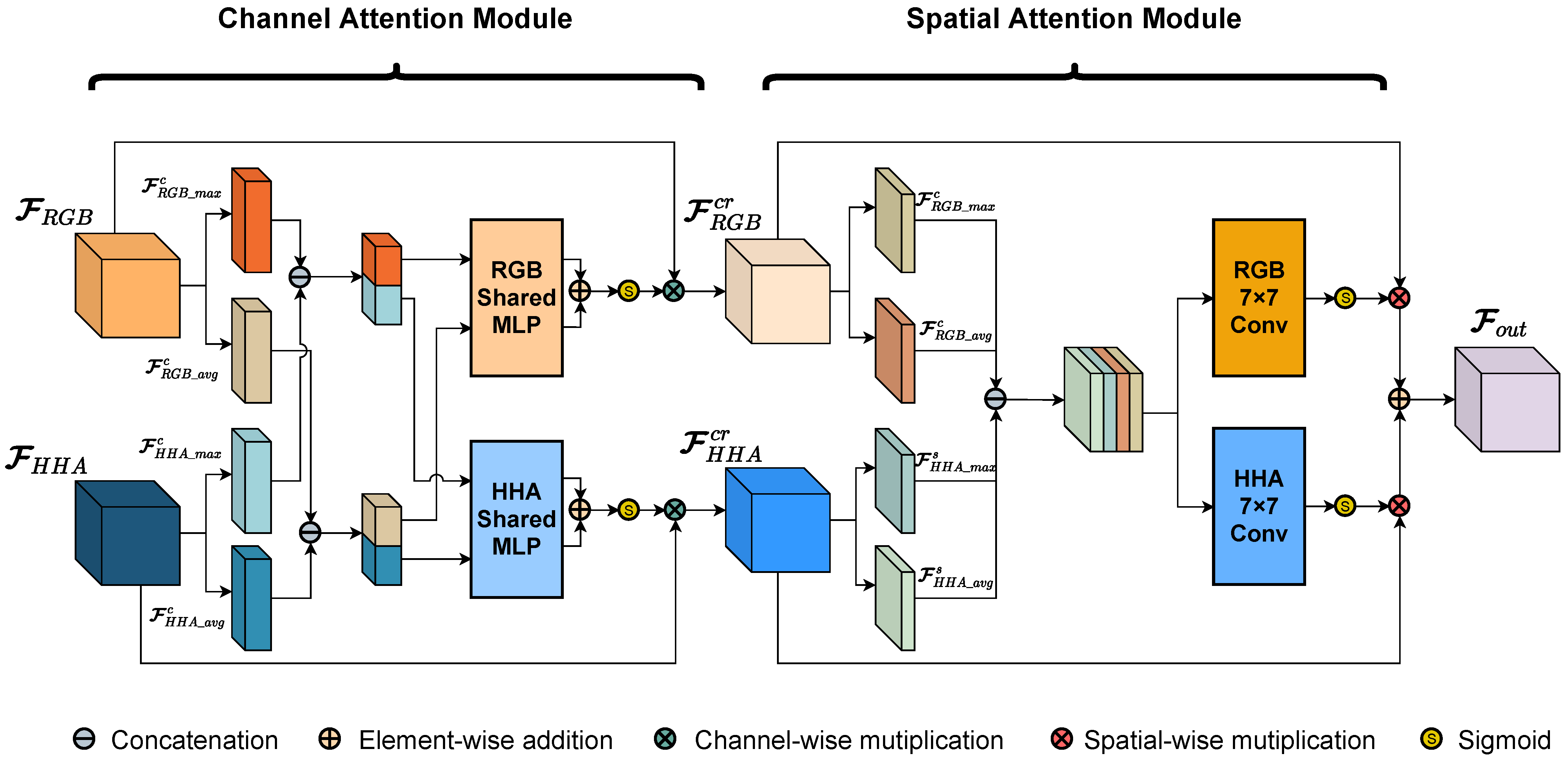
3.2.2. Structure of Cross-Modality Refine Gate
Although CBAM exhibits good performance w.r.t. the extraction and representation of features through the channel- and spatial-attention mechanisms, it is inadequate for the cross-modality features. Inspired by CBAM, where the channel- and spatial-attention modules are sequentially employed (and the attention mechanisms are applied with each modality separately), here, we design a unique attention module, the Cross-Modality Refine Gate (CMRG), which is designed to deal with cross-modality features. The structure of the CMRG is illustrated in
Figure 7. Differing from the CBAM, the CMRG takes the multi-modality features as the input, instead of receiving only one feature maps. The self-attention mechanism in the CMRG utilizes the cross-modality information to produce the attention maps, which only rely on one modality in CBAM.
As shown in
Figure 7, the CMRG consists of two parts: the channel-attention module, and the spatial-attention module. The input of the CMRG is a pair of feature maps
and
, which are derived from the RGB and HHA branches, respectively. Firstly, the CMRG utilizes the channel-attention module to infer two 1D channel-attention maps—
and
—to refine
and
via channel-wise multiplication. By the sharing of descriptors from each modality and the inference of exclusive attention maps for each modality, the cross-modality channel-attention operation primarily filters out noisy and chaotic information and improves the effective characteristics of the original feature maps from the channel aspect. Then, the CMRG infers two 2D spatial-attention maps—
and
—to enhance the channel-refined feature maps
and
via spatial-wise multiplication. The cross-modality spatial attention primarily strengthens the association among pixels in the feature maps in order to put more attention on the areas with similar characteristics, even though some of them are far from each other. Finally, the output
is generated by adding the spatial-refined feature maps together. This process can be formulated as follows:
where
and
represent the input feature maps,
and
represent the channel-attention maps,
and
represent the spatial-attention maps,
and
represent the channel-refined feature maps,
and
represent the spatial-refined feature maps, and ⊗ denotes element-wise multiplication. In the multiplication procedure, the attention values are broadcast the same as in the implementation in CBAM.
As shown in
Figure 7, the channel-attention module first aggregates each feature maps into two 1D descriptors, totaling four via average-pooling and max-pooling, among which
and
are generated from RGB feature maps, whereas
and
are generated from HHA feature maps. Then, the descriptors from various modalities are concatenated to produce two cross-modality channel descriptors:
and
. Both cross-modality descriptors are fed into two independent MLPs with one hidden layer:
and
. After the shared network is applied to each descriptor, element-wise summations are utilized to generate modality-specific channel-attention maps
and
. The channel-refined procedure in CMRM can be formulated as follows:
where
denotes the sigmoid function and
denotes the concatenation. It is worth mentioning that, different from the CBAM, both MLP have weights of
and
;
r is the reduction ratio. Furthermore,
and
represent the RGB descriptors,
and
represent the HHA descriptors, and
and
represent the cross-modality descriptors.
Following the optimization of the features by the channel-attention module, the pair of feature maps—
and
—are fed into the spatial-attention module. Similar to the implementation of channel attention, the spatial-attention module initially aggregates cross-modality features via average-pooling and max-pooling along the channel axis, and infers four 2D maps, among which
and
are generated from refined RGB feature maps, while
and
are generated from refined HHA feature maps. Then, the concatenation is applied to combine all maps. The cross-modality map is then convolved by two independent standard convolution layers with kernel size of
to generate the modality-specific spatial-attention map
and
. The spatial-refined procedure in the CMRG can be formulated as follows:
where
denotes the sigmoid function,
represents the
convolutional layer, and
refers to the concatenation.
and
represent the RGB maps, and
and
represent the HHA maps.
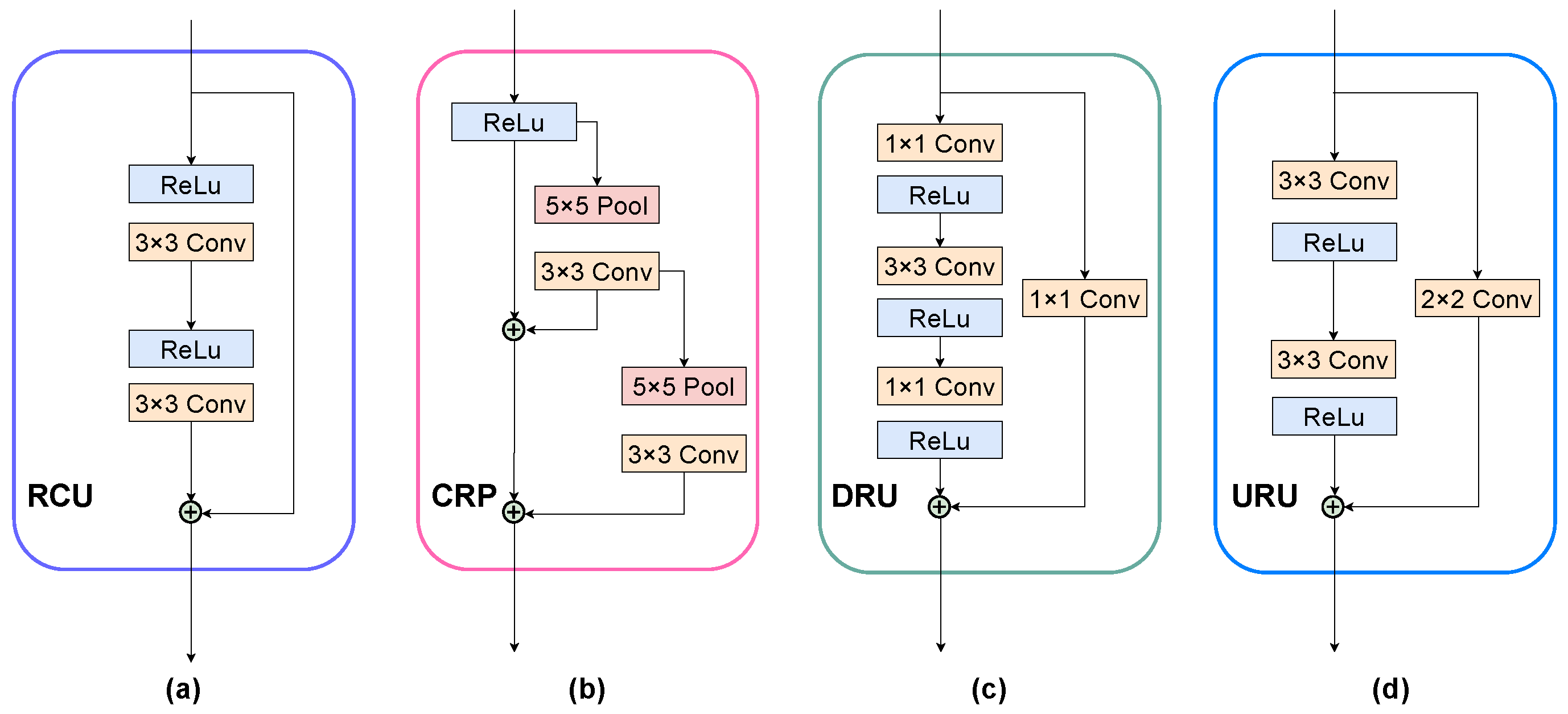
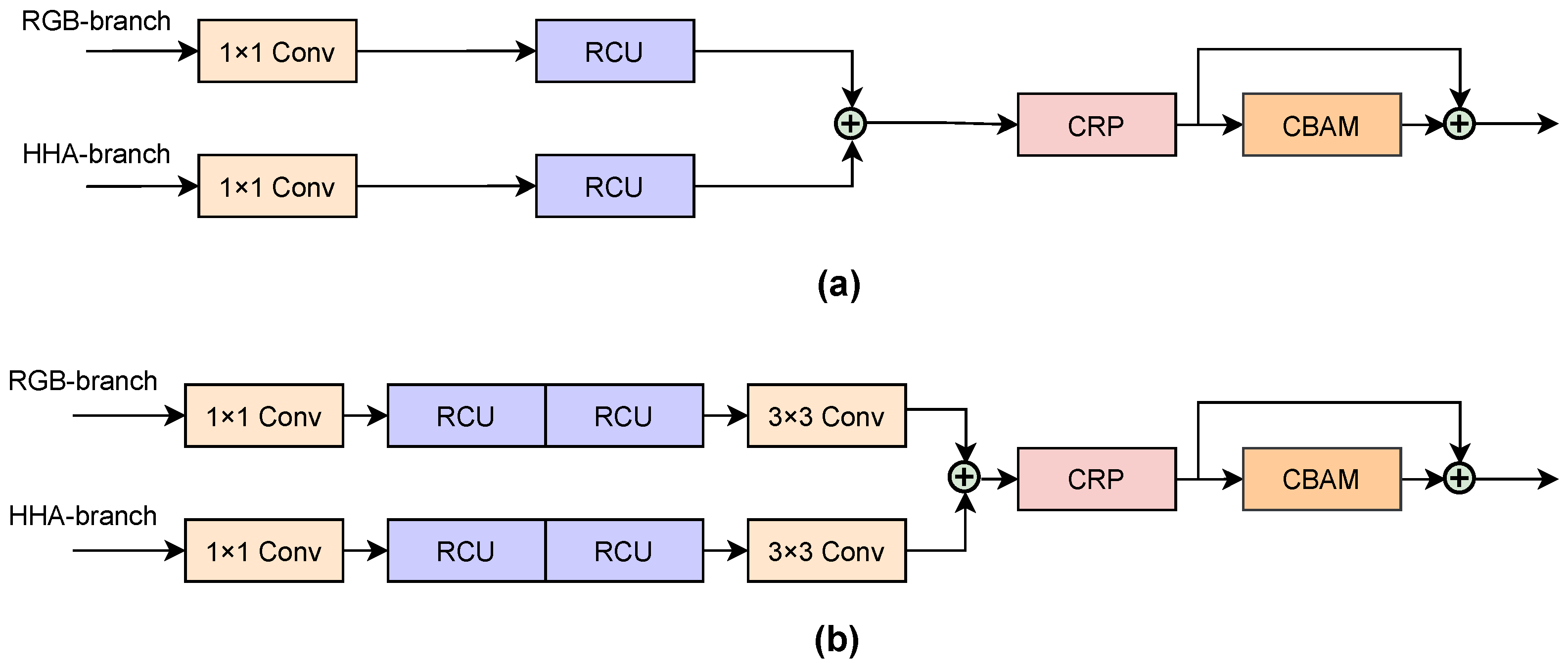
To refine the features by taking advantages of different physical significance, the CMRG utilizes combined information from RGB and HHA to generate attention maps instead of relying solely on a single modality. Due to the limited sensing capabilities of the depth camera, this strategy improves the sturdiness and effectiveness of the backbone, especially in the HHA branch. To be specific, for the purpose of generating fine attention maps, the descriptors (maps) are derived using both average-pooling and max-pooling, with average-pooling descriptors (maps) representing the global information and max-pooling descriptors (maps) representing prominent information, thereby improving the availability of the attention maps. In addition, the CMRG employs channel- and spatial-attention mechanisms to improve the representation and aggregation of cross-modality information. In this structure, the channel-attention module is primarily responsible for capturing ’what’ is important, whereas the spatial-attention module is primarily responsible for determining ’where’ should be prioritized.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}