
Transformer-Based Maneuvering Target Tracking


Abstract
:1. Introduction
2. Problem Formulation
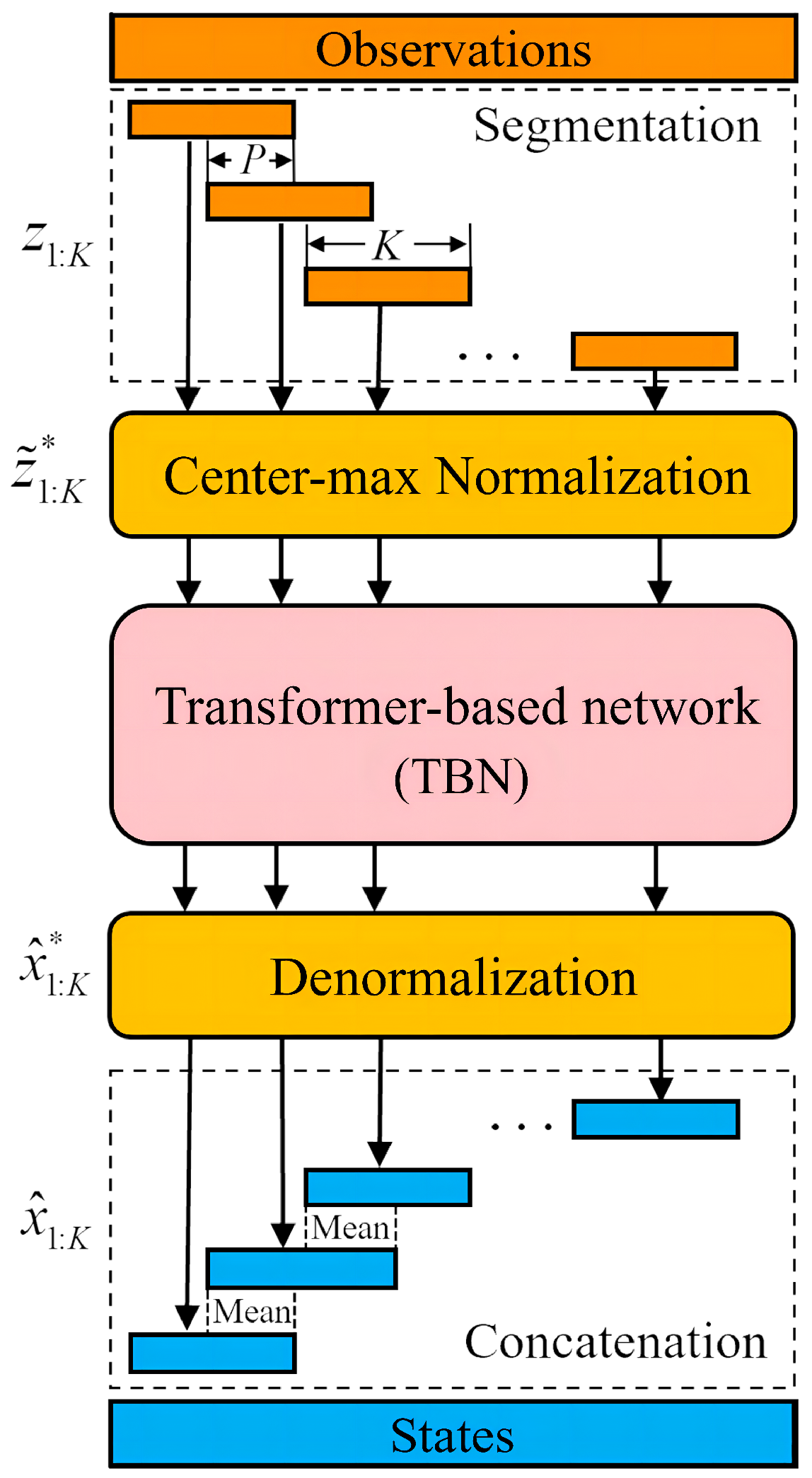
3. Proposed Model
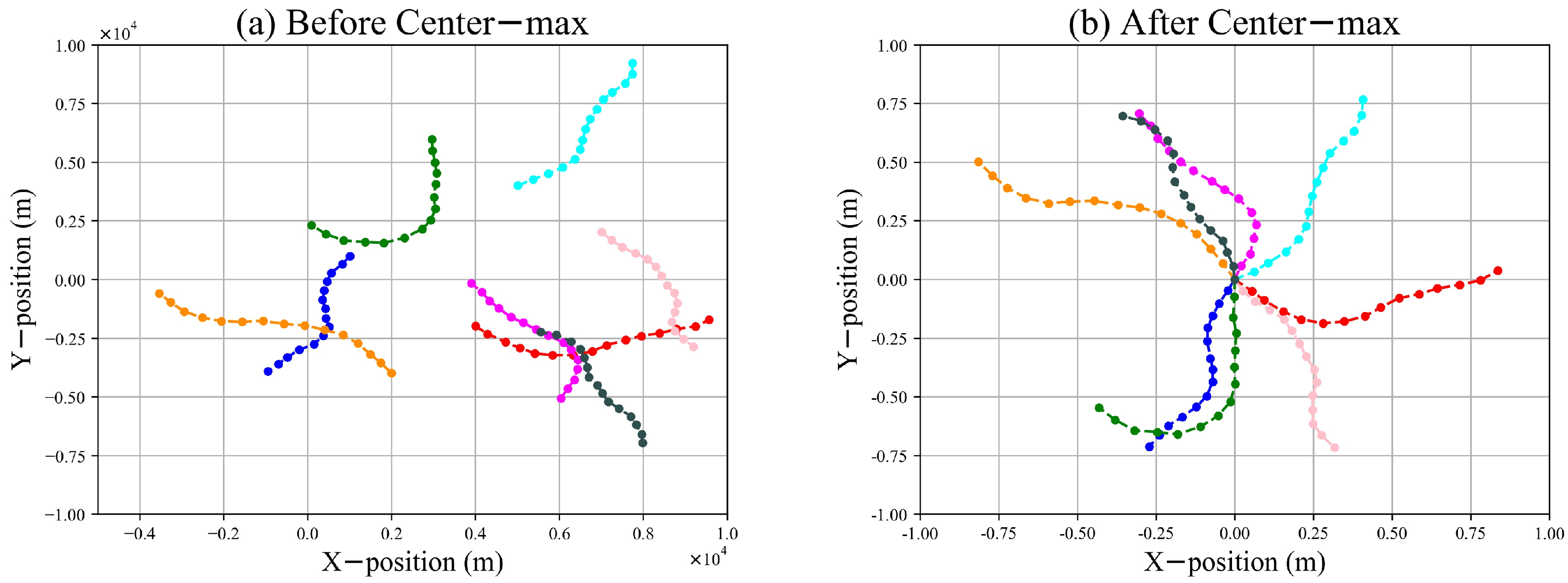
3.1. Center–Max Normalization
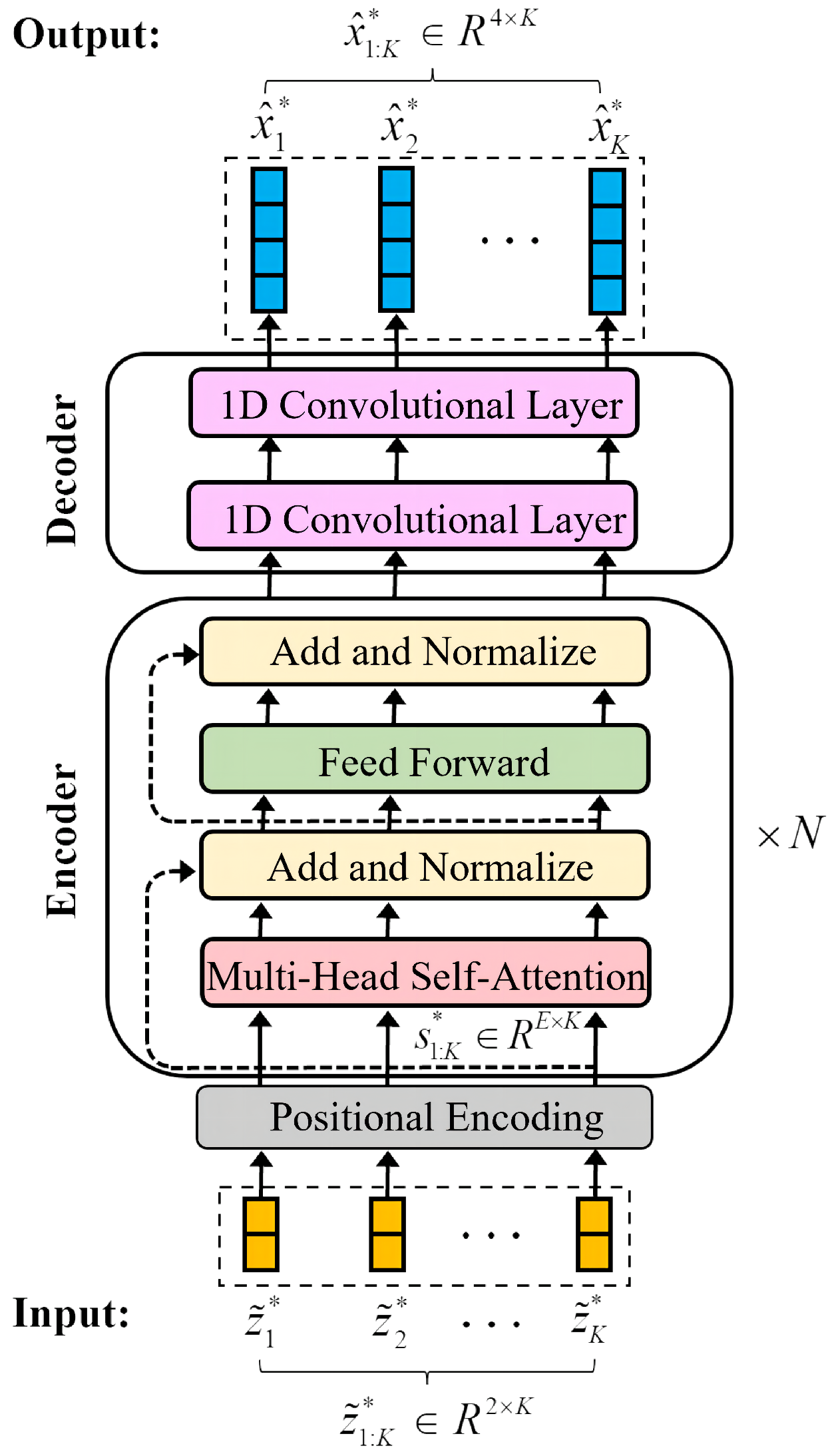
3.2. Proposed Network
3.2.1. Positional Encoding
3.2.2. Multi-Head Self-Attention
3.2.3. Feedforward Layer
3.3. Maneuvering Target Tracking Based on the TBN
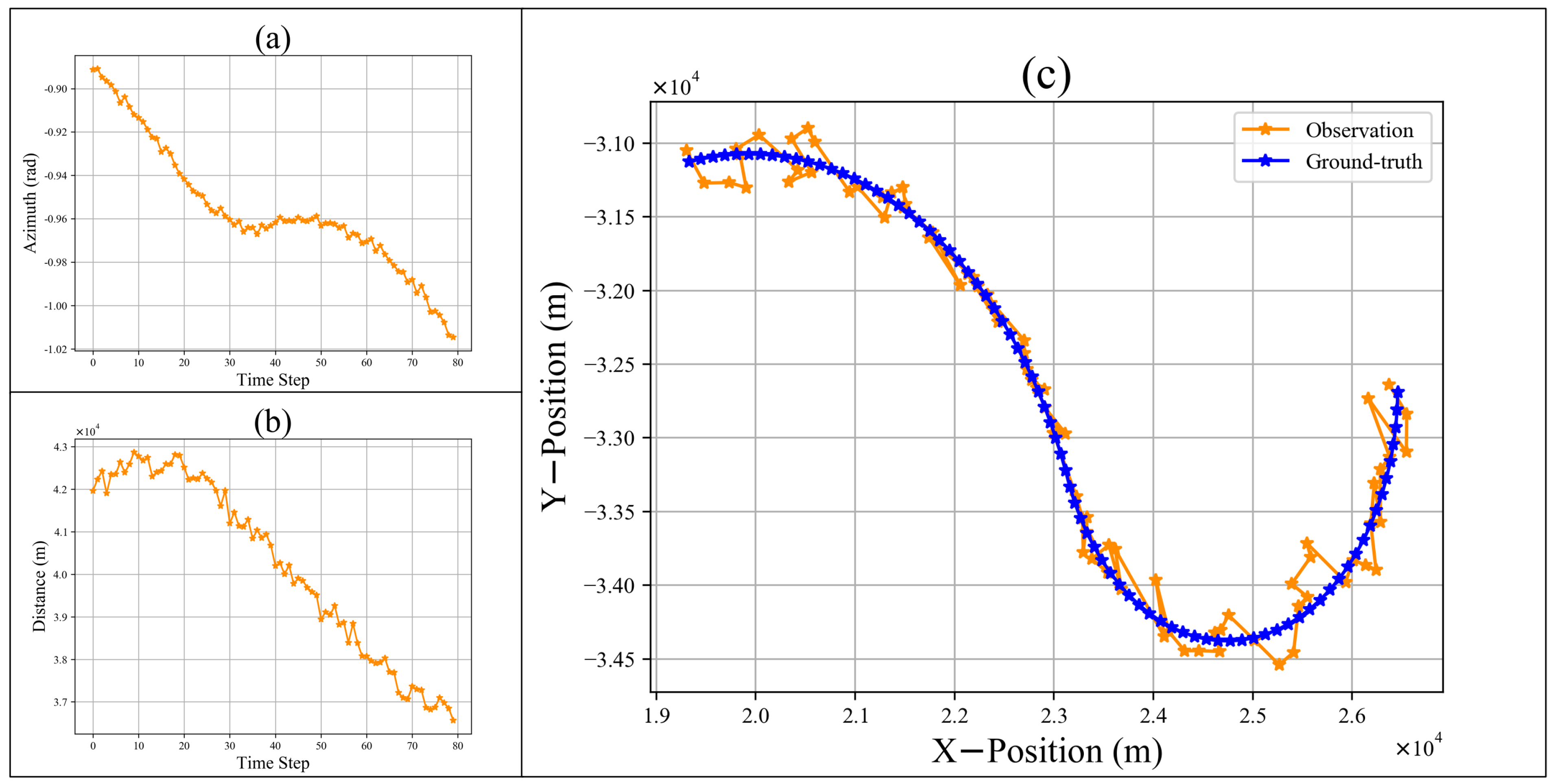
4. Experiments and Results
4.1. Implementation Details
4.2. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Blom, H.A.; Bar-Shalom, Y. The interacting multiple model algorithm for systems with Markovian switching coefficients. IEEE Trans. Autom. Control. 1988, 33, 780–783. [Google Scholar] [CrossRef]
- Pulford, G.W.; La Scala, B.F. MAP estimation of target manoeuvre sequence with the expectation-maximization algorithm. IEEE Trans. Aerosp. Electron. Syst. 2002, 38, 367–377. [Google Scholar] [CrossRef]
- Chen, H.; Chang, K. Novel nonlinear filtering & prediction method for maneuvering target tracking. IEEE Trans. Aerosp. Electron. Syst. 2009, 45, 237–249. [Google Scholar]
- Ning, X.H.; Hui, X. Algorithm of maneuvering target tracking for video based on UKF and IMM. In Proceedings of the IEEE Conference Anthology, China, 1–8 January 2013; pp. 1–4. [Google Scholar]
- Li, B.; Pang, F.; Liang, C.; Chen, X.; Liu, Y. Improved interactive multiple model filter for maneuvering target tracking. In Proceedings of the Proceedings of the 33rd IEEE Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 7312–7316. [Google Scholar]
- Gao, C.; Yan, J.; Zhou, S.; Varshney, P.K.; Liu, H. Long short-term memory-based deep recurrent neural networks for target tracking. Inf. Sci. 2019, 502, 279–296. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Z.; Xu, M. DeepMTT: A deep learning maneuvering target-tracking algorithm based on bidirectional LSTM network. Inf. Fusion 2020, 53, 289–304. [Google Scholar] [CrossRef]
- Yu, W.; Yu, H.; Du, J.; Zhang, M.; Liu, J. DeepGTT: A general trajectory tracking deep learning algorithm based on dynamic law learning. IET Radar Sonar Navig. 2021, 15, 1125–1150. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Zimmermann, H.G.; Grothmann, R.; Schafer, A.M.; Tietz, C. Dynamical consistent recurrent neural networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 3, pp. 1537–1541. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gao, C.; Liu, H.; Zhou, S.; Su, H.; Chen, B.; Yan, J.; Yin, K. Maneuvering target tracking with recurrent neural networks for radar application. In Proceedings of the 2018 IEEE International Conference on Radar (RADAR), Oklahoma City, OK, USA, 23–27 April 2018; pp. 1–5. [Google Scholar]
- Ma, L.; Tian, S. A hybrid CNN-LSTM model for aircraft 4D trajectory prediction. IEEE Access 2020, 8, 134668–134680. [Google Scholar] [CrossRef]
- Zhang, Z.; Ni, G.; Xu, Y. Ship trajectory prediction based on LSTM neural network. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1356–1364. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Kim, Y.; Denton, C.; Hoang, L.; Rush, A.M. Structured attention networks. arXiv 2017, arXiv:1702.00887. [Google Scholar]
- Shi, H.; Gao, S.; Tian, Y.; Chen, X.; Zhao, J. Learning Bounded Context-Free-Grammar via LSTM and the Transformer: Difference and Explanations. Proc. Aaai Conf. Artif. Intell. 2022, 36, 8267–8276. [Google Scholar] [CrossRef]
- Magill, D. Optimal adaptive estimation of sampled stochastic processes. IEEE Trans. Autom. Control. 1965, 10, 434–439. [Google Scholar] [CrossRef]
- Li, X.R.; Bar-Shalom, Y. Design of an interacting multiple model algorithm for air traffic control tracking. IEEE Trans. Control. Syst. Technol. 1993, 1, 186–194. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Z.; Xu, M. A Kalman estimation based rao-blackwellized particle filtering for radar tracking. IEEE Access 2017, 5, 8162–8174. [Google Scholar] [CrossRef]
- Kazemi, S.M.; Goel, R.; Eghbali, S.; Ramanan, J.; Sahota, J.; Thakur, S.; Wu, S.; Smyth, C.; Poupart, P.; Brubaker, M. Time2vec: Learning a vector representation of time. arXiv 2019, arXiv:1907.05321. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Distance range | ∼ |
| Angle range | ∼ |
| Velocity range | ∼ |
| Turn rate | ∼ |
| The standard deviation of acceleration noise | ∼ |
| The standard deviation of azimuth noise | ∼ |
| The standard deviation of distance noise | ∼ |
| RMSE of Position (m) | RMSE of Velocity (m/s) | |
|---|---|---|
| LSTM+MM | 16.27 | 6.75 |
| LSTM+CM | 14.43 | 5.14 |
| TBN+CM | 13.50 | 3.64 |
| RMSE of Position (m) | RMSE of Velocity (m/s) | |
|---|---|---|
| IMM | 14.54 | 6.35 |
| LSTM+MM | 11.82 | 4.64 |
| LSTM+CM | 10.30 | 3.47 |
| TBN+CM | 9.33 | 2.04 |
| RMSE of Position (m) | RMSE of Velocity (m/s) | |||
|---|---|---|---|---|
| TBN+CM | LSTM+MM | TBN+CM | LSTM+MM | |
| A2 | 9.94 | 146.14 | 2.08 | 56.19 |
| A3 | 9.15 | 295.71 | 2.03 | 78.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, G.; Wang, Z.; Huang, Y.; Zhang, H.; Ma, X. Transformer-Based Maneuvering Target Tracking. Sensors 2022, 22, 8482. https://doi.org/10.3390/s22218482
Zhao G, Wang Z, Huang Y, Zhang H, Ma X. Transformer-Based Maneuvering Target Tracking. Sensors. 2022; 22(21):8482. https://doi.org/10.3390/s22218482
Chicago/Turabian StyleZhao, Guanghui, Zelin Wang, Yixiong Huang, Huirong Zhang, and Xiaojing Ma. 2022. "Transformer-Based Maneuvering Target Tracking" Sensors 22, no. 21: 8482. https://doi.org/10.3390/s22218482