
A Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios

Abstract
:1. Introduction
- (1)
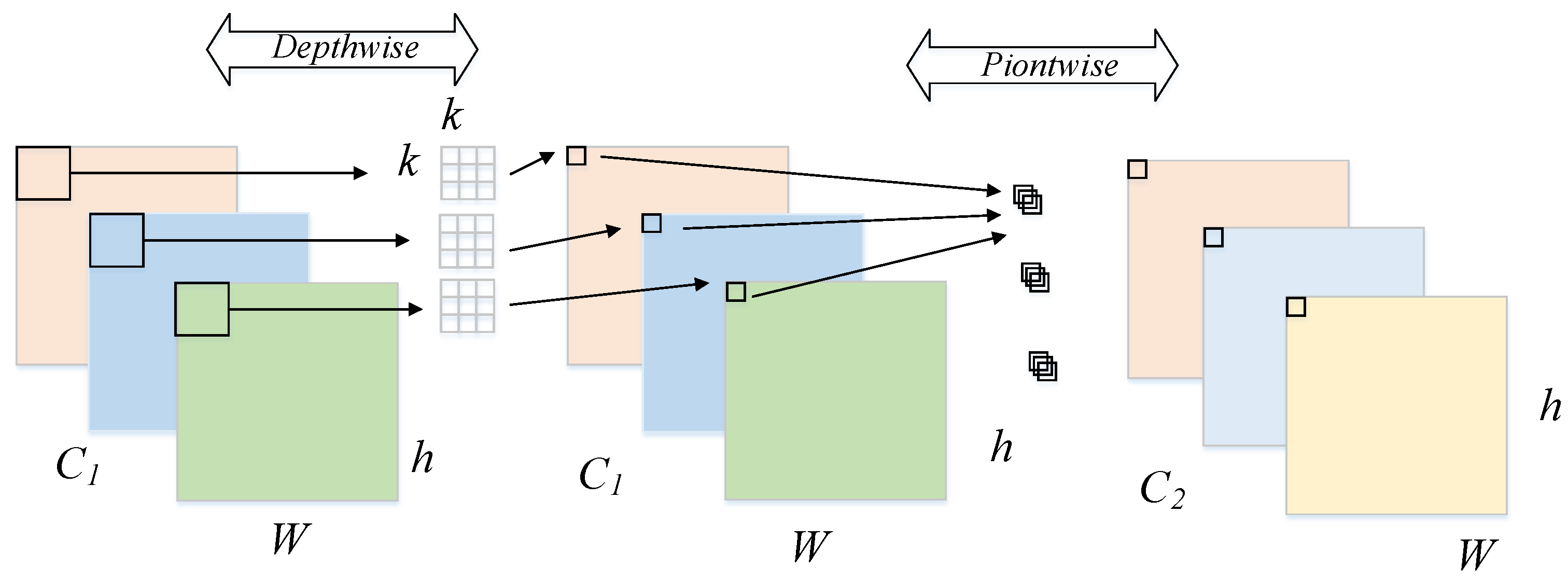
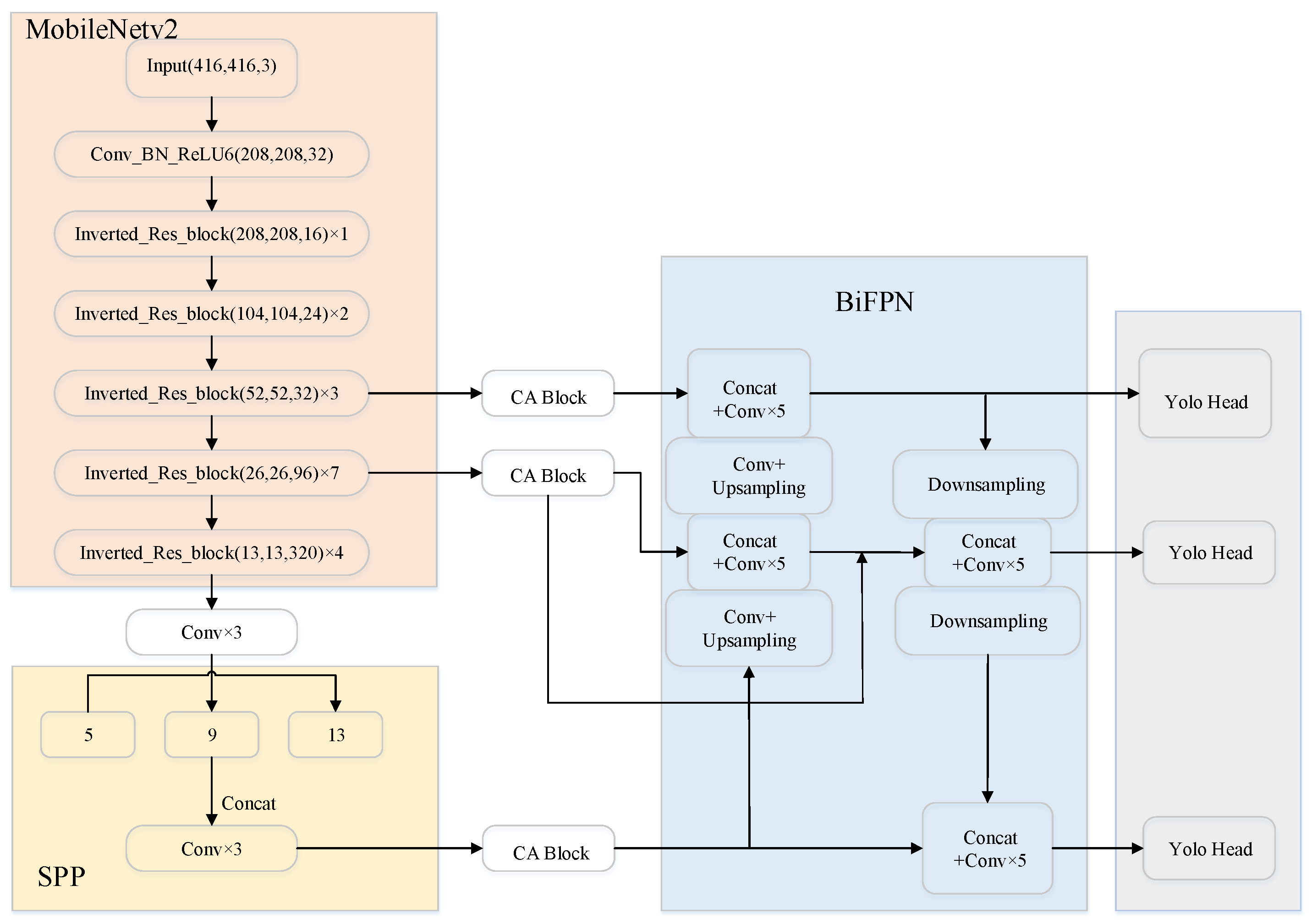
- To simplify the backbone network and improve the speed of vehicle–pedestrian detection obviously, the original backbone network CSPDarknet53 is replaced with MobileNetv2 embedded with Depthwise Separable Convolution [10].
- (2)
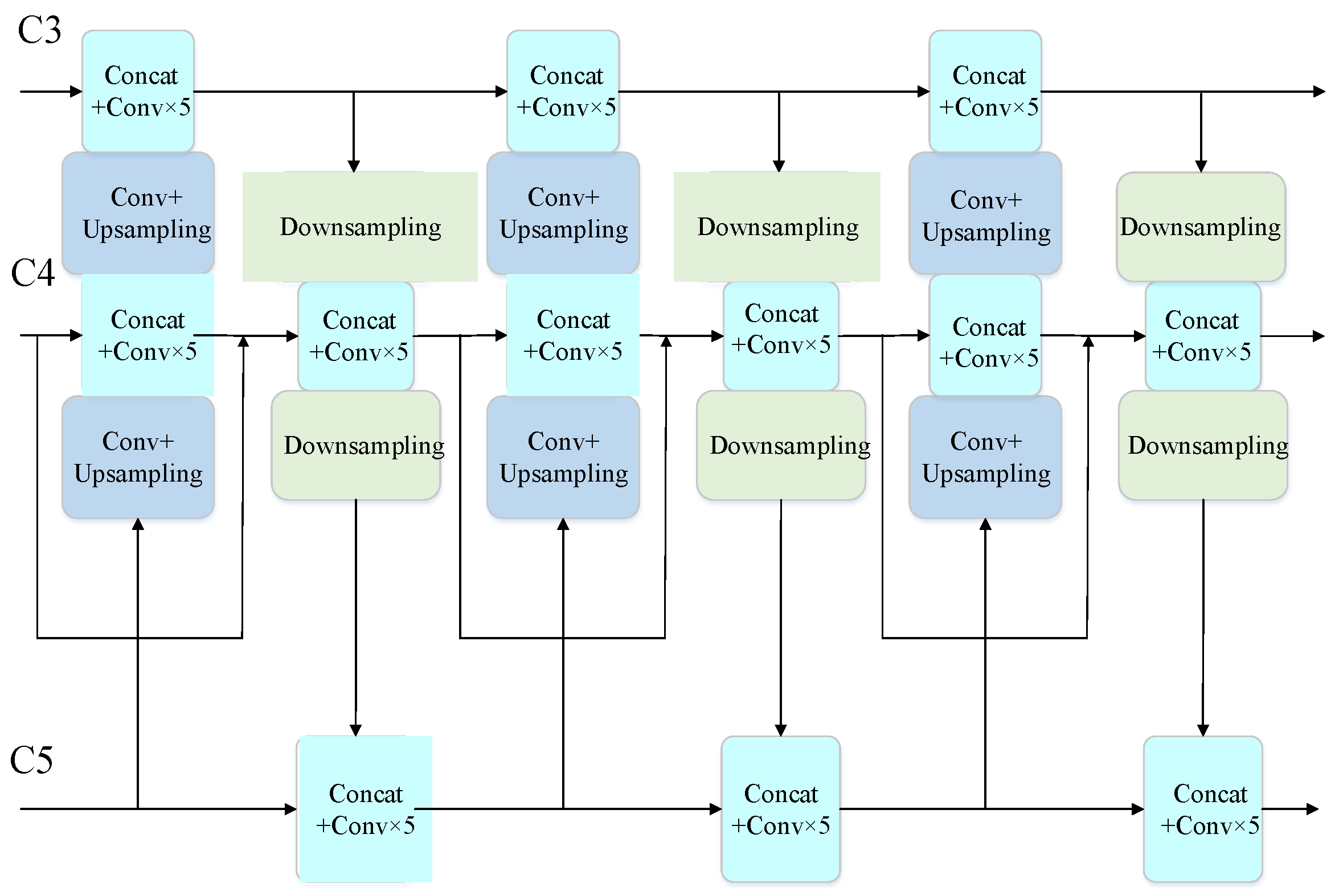
- The feature pyramid structure is optimized by means of multi-scale feature fusion to realize the interaction of feature information among different feature layers.
- (3)
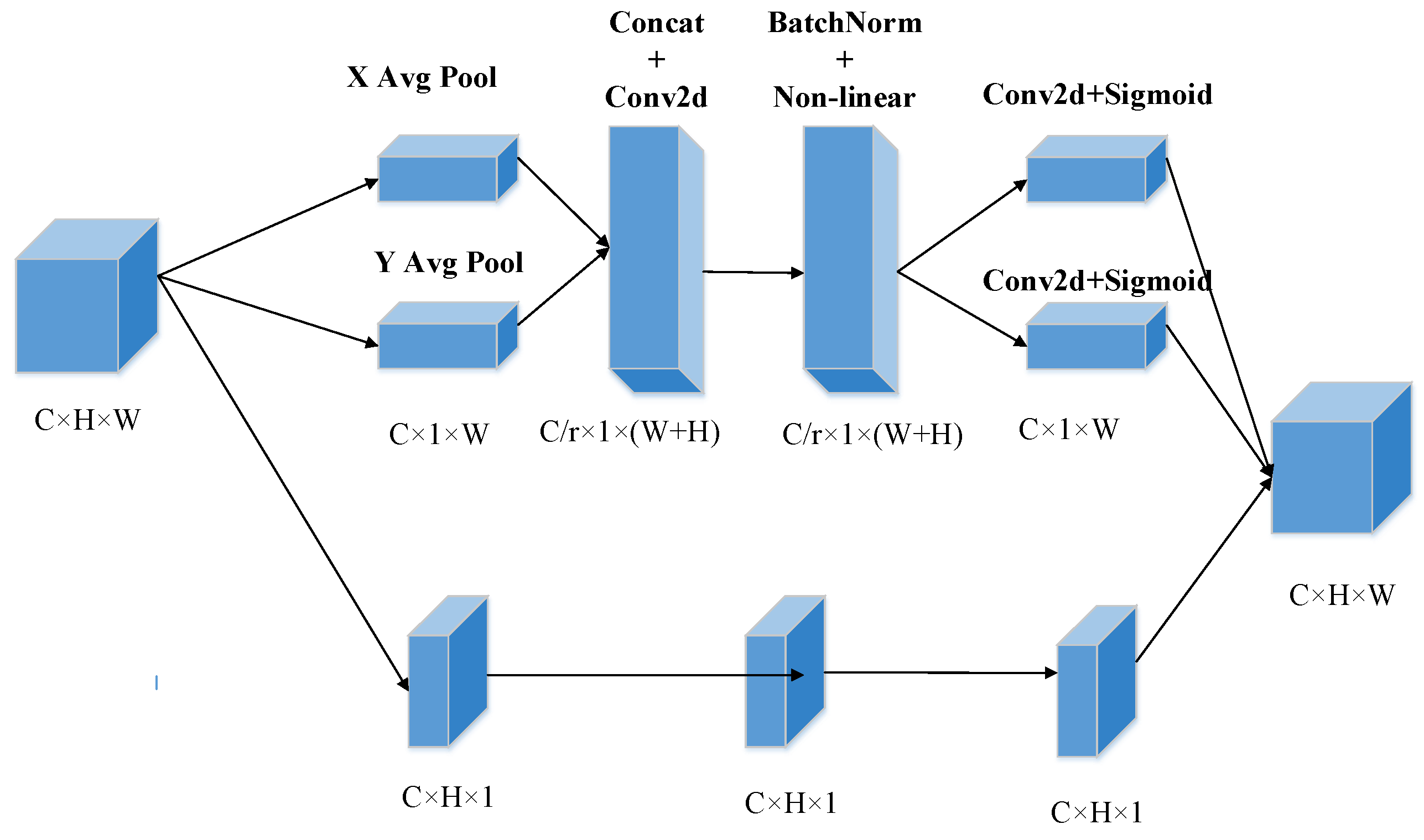
- The coordinate attention mechanism is applied to focus on the region of interest in the image by adjusting the weights so as to enhance the feature extraction capability of the model.
2. Related Work
2.1. Object Detection
2.2. Object Detection Based on Attention Mechanism
3. Methodology
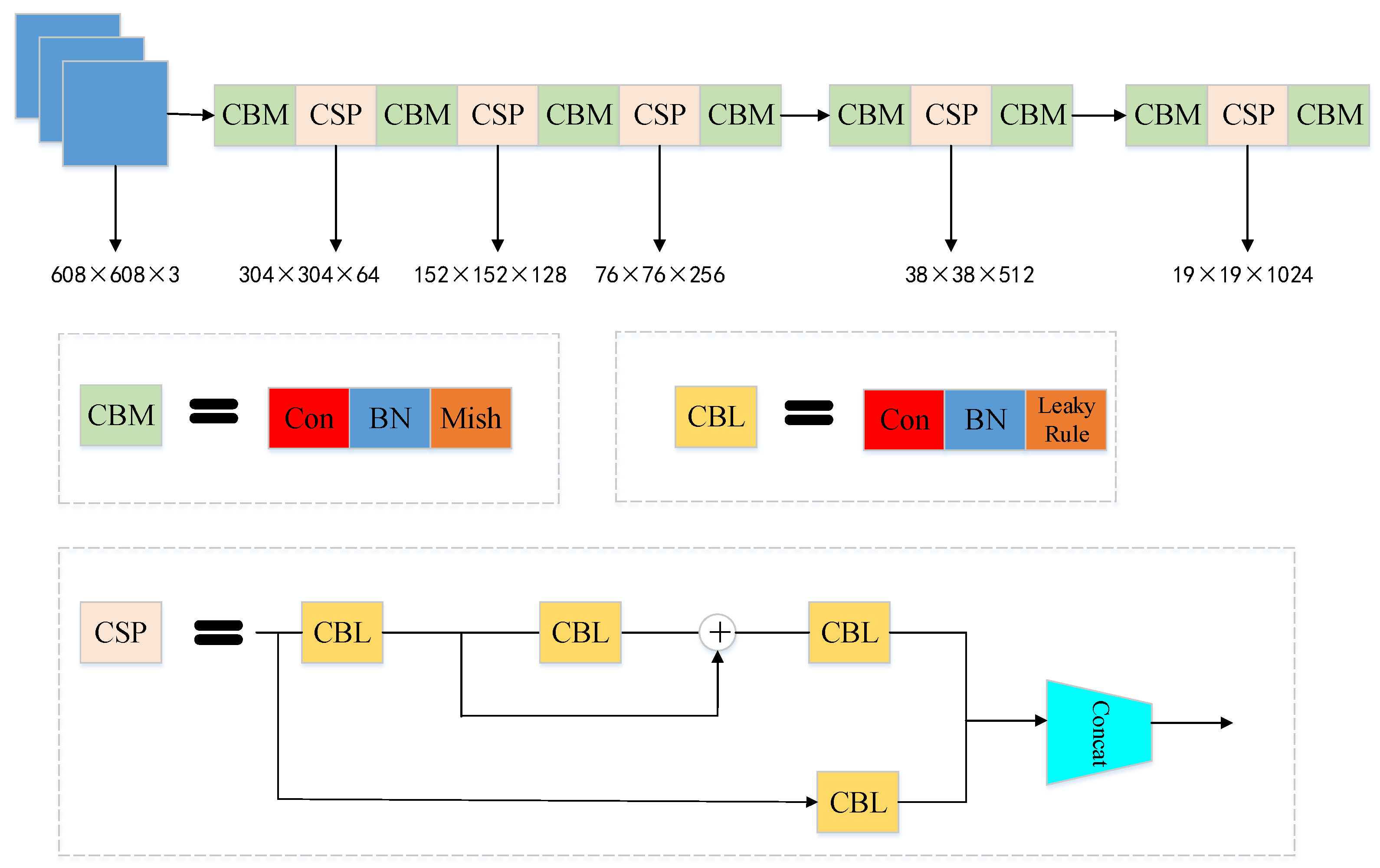
3.1. YOLOv4 Object Detection Model
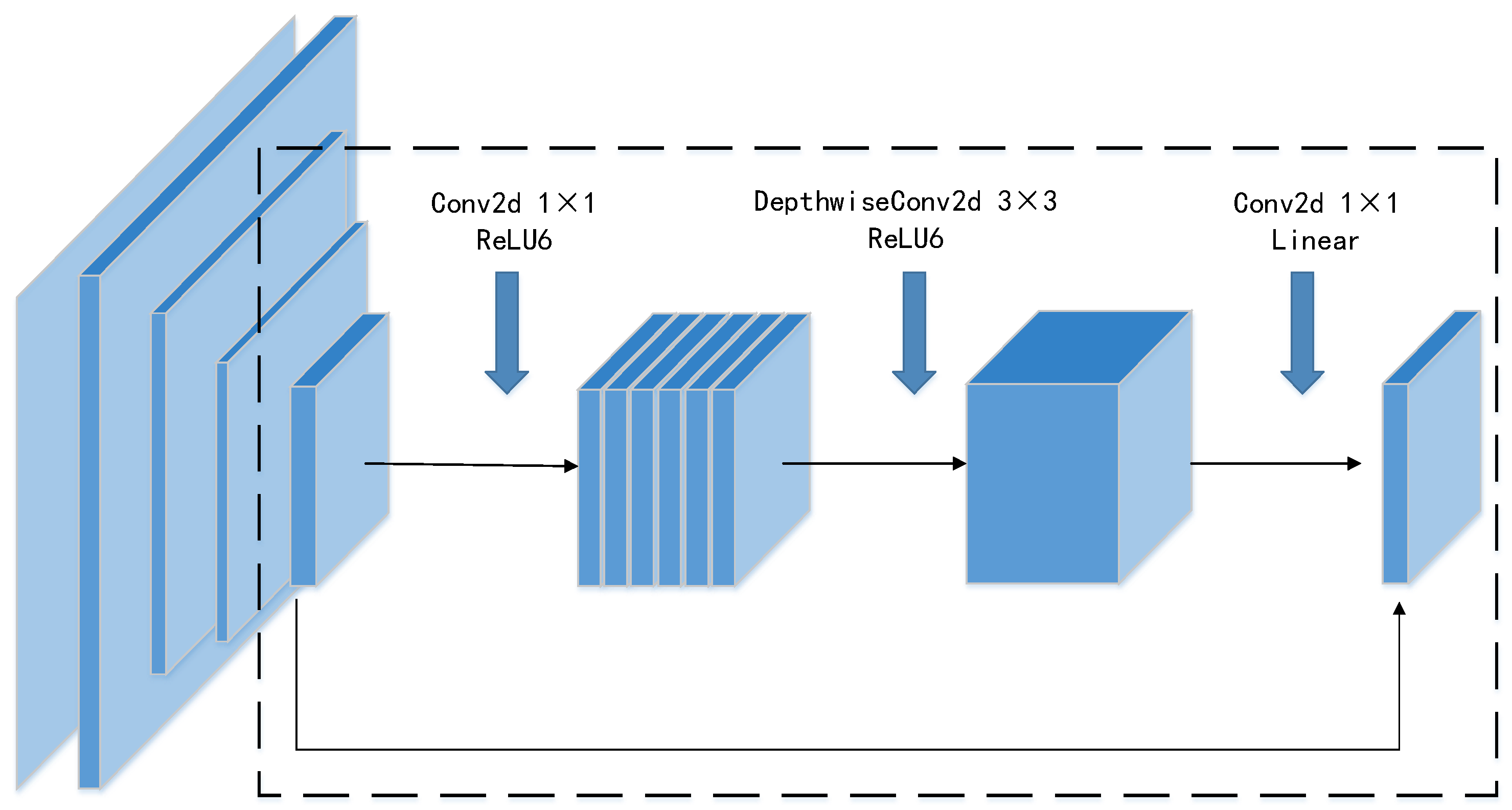
3.2. MobielNetv2-YOLOv4
3.3. Improved Enhanced Feature Extraction Network
3.4. CA-MobileNetv2-YOLOv4
4. Experimental Results and Analysis
4.1. Experimental Environment and Parameter Description
4.2. Datasets
4.3. Evaluation Metrics
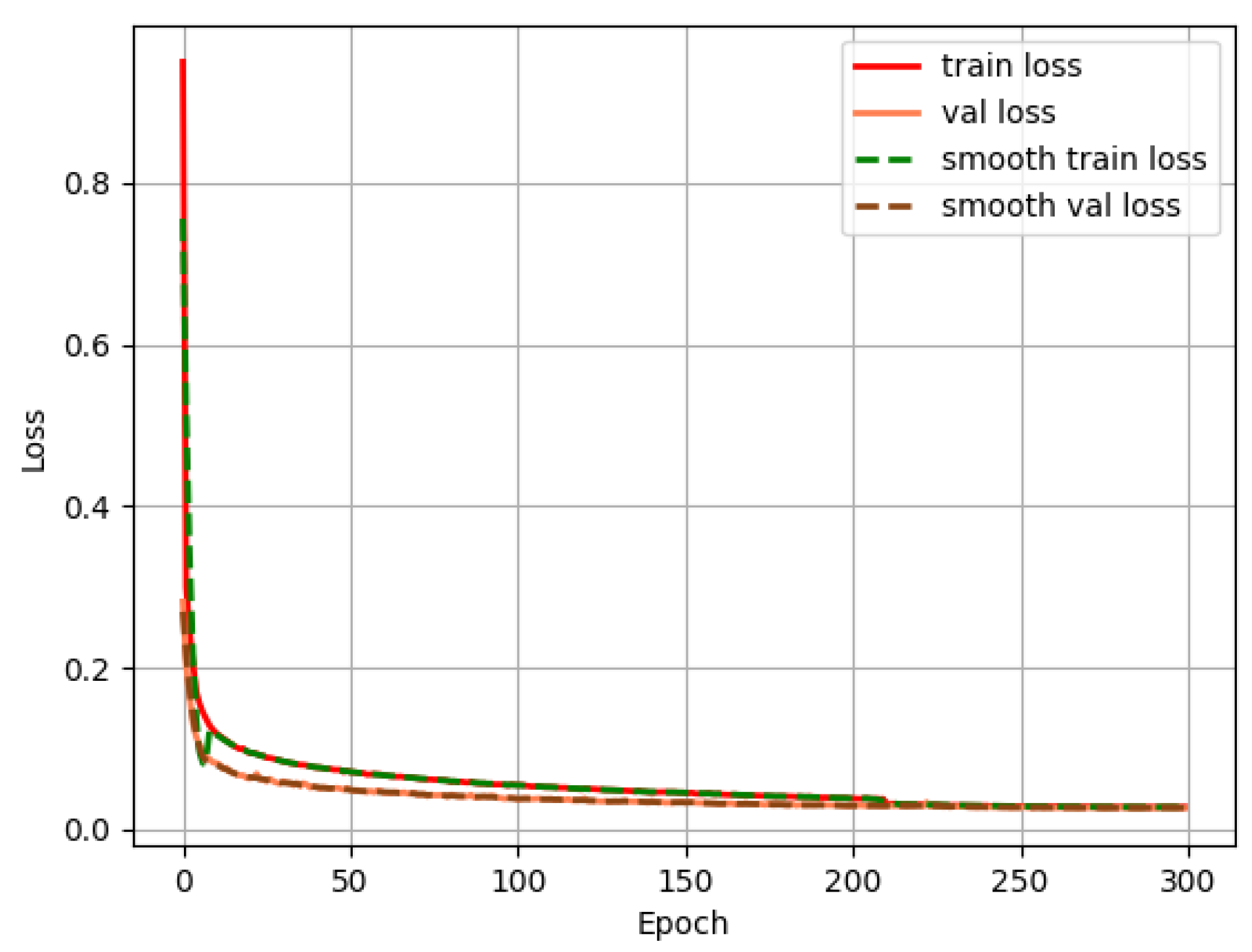
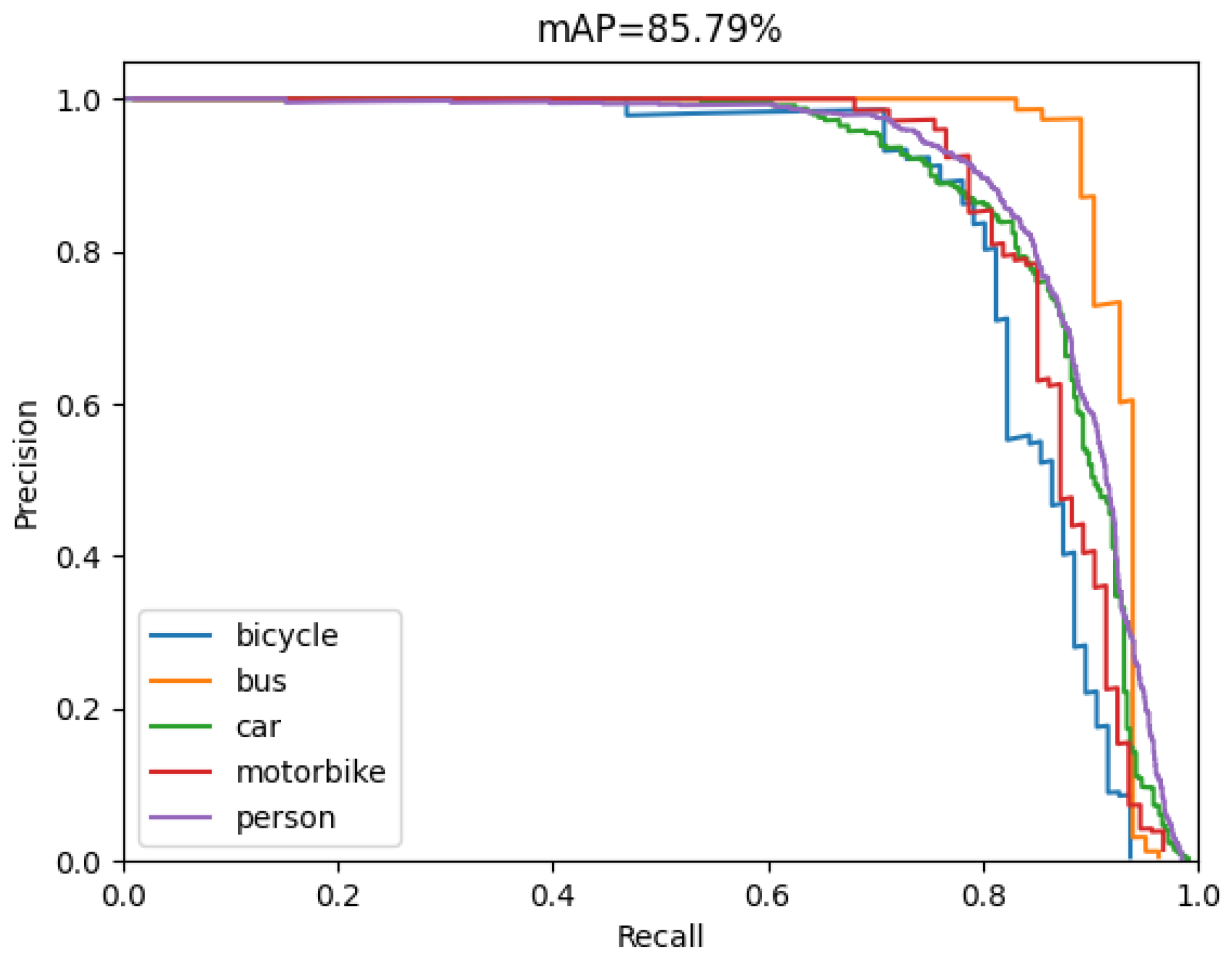
4.4. Experimental Results
4.5. Comparison Detection Performacne on Differernt Datasets
4.6. Comparison of Detection Performance with Other Algorithm
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Meng, C.C.; Bao, H.; Ma, Y. Vehicle Detection: A Review. In Proceedings of the 3rd International Conference on Computer Information Science and Application Technology (CISAT), Electr Network, Dali, China, 17 July 2020. [Google Scholar]
- Al-qaness, M.A.A.; Abbasi, A.A.; Fan, H.; Ibrahim, R.A.; Alsamhi, S.H.; Hawbani, A. An improved YOLO-based road traffic monitoring system. Computing 2021, 103, 211–230. [Google Scholar] [CrossRef]
- Du, L.Y.; Chen, X.J.; Pei, Z.H.; Zhang, D.H.; Liu, B.; Chen, W. Improved Real-Time Traffic Obstacle Detection and Classification Method Applied in Intelligent and Connected Vehicles in Mixed Traffic Environment. J. Adv. Transp. 2022, 2022, 2259113. [Google Scholar] [CrossRef]
- Zhou, Y.; Wen, S.; Wang, D.; Meng, J.; Mu, J.; Irampaye, R. MobileYOLO: Real-Time Object Detection Algorithm in Autonomous Driving Scenarios. Sensors 2022, 22, 3349. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]
- Zhu, D.; Xu, G.; Zhou, J.; Di, E.; Li, M. Object Detection in Complex Road Scenarios: Improved YOLOv4-Tiny Algorithm. In Proceedings of the 2021 2nd Information Communication Technologies Conference (ICTC), Nanjing, China, 7–9 May 2021. [Google Scholar]
- Wang, R.; Wang, Z.; Xu, Z.; Wang, C.; Li, Q.; Zhang, Y.; Li, H. A Real-Time Object Detector for Autonomous Vehicles Based on YOLOv4. Comput. Intell. Neurosci. 2021, 2021, 9218137. [Google Scholar] [CrossRef] [PubMed]
- Jamiya, S.S.; Rani, P.E. LittleYOLO-SPP: A delicate real-time vehicle detection algorithm. Optik 2021, 225, 165818. [Google Scholar] [CrossRef]
- Choi, J.; Chun, D.; Kim, H.; Lee, H.J. Gaussian YOLOv3: An Accurate and Fast Object Detector Using Localization Uncertainty for Autonomous Driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 502–511. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Chen, Q.; Wang, Y.M.; Yang, T.; Zhang, X.Y.; Cheng, J.; Sun, J.; Ieee Comp, S.O.C. You Only Look One-level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), virtual, 19–25 June 2021; pp. 13034–13043. [Google Scholar]
- Peng, H.L.; Guo, S.; Zuo, X.Y.; Assoc Comp, M. A Vehicle Detection Method Based on YOLOV4 Model. In Proceedings of the 2nd International Conference on Artificial Intelligence and Information Systems (ICAIIS), Chongqing, China, 28–30 May 2021. [Google Scholar]
- Ma, L.; Chen, Y.; Zhang, J. Vehicle and Pedestrian Detection Based on Improved YOLOv4-tiny Model. J. Phys. Conf. Ser. 2021, 1920, 012034. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.Y.; Lin, M.X.; Sun, R. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.L.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhao, T.T.; Yi, X.L.; Zeng, Z.Y.; Feng, T. MobileNet-Yolo based wildlife detection model: A case study in Yunnan Tongbiguan Nature Reserve, China. J. Intell. Fuzzy Syst. 2021, 41, 2171–2181. [Google Scholar] [CrossRef]
- Li, X.L.; Qin, Y.; Wang, F.J.; Guo, F.; Yeow, J.T.W. Pitaya detection in orchards using the MobileNet-YOLO model. In Proceedings of the 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 6274–6278. [Google Scholar]
- Li, J.P.; Zhu, K.Y.; Wang, F.; Jiang, F.J. Deep neural network-based real time fish detection method in the scene of marine fishing supervision. J. Intell. Fuzzy Syst. 2021, 41, 4527–4532. [Google Scholar] [CrossRef]
- Gao, C.; Cai, Q.; Ming, S.F. YOLOv4 Object Detection Algorithm with Efficient Channel Attention Mechanism. In Proceedings of the 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; pp. 1764–1770. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.P.; Zhang, Z.Y.; Wang, X.G.; Tyagi, A.; Agrawal, A. Context Encoding for Semantic Segmentation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Woo, S.H.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QU, Canada, 11–17 October 2021. [Google Scholar]
- Rios, A.C.; dos Reis, D.H.; da Silva, R.M.; Cuadros, M.; Gamarra, D.F.T. Comparison of the YOLOv3 and SSD MobileNet v2 Algorithms for Identifying Objects in Images from an Indoor Robotics Dataset. In Proceedings of the 14th IEEE International Conference on Industry Applications (INDUSCON), Univ Sao Paulo, Escola Politecnica, Virtual, 15–18 August 2021; pp. 96–101. [Google Scholar]
- Ning, W.B.; Mu, X.C.; Zhang, C.; Dai, T.T.; Qian, S.; Sun, X.T. Object Detection and Danger Warning of Transmission Channel Based on Improved YOLO Network. In Proceedings of the 4th IEEE Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Virtual, 12–14 June 2020; pp. 1089–1093. [Google Scholar]
- Zhang, M.H.; Xu, S.B.; Song, W.; He, Q.; Wei, Q.M. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Li, J.X.; Pan, Z.F.; Liu, Q.S.; Cui, Y.; Sun, Y.B. Complementarity-Aware Attention Network for Salient Object Detection. IEEE Trans. Cybern. 2022, 52, 873–886. [Google Scholar] [CrossRef] [PubMed]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13708–13717. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MobileNetv2 | BiFPN | Coordinate Attention | Parameters (M) | mAP (%) | FPS (Hz) | |
|---|---|---|---|---|---|---|
| Model 1 | 64.62 | 81.08 | 30 | |||
| Model 2 | ✓ | 11.15 | 83.98 | 38 | ||
| Model 3 | ✓ | ✓ | 20.16 | 85.29 | 37 | |
| Model 4 | ✓ | ✓ | ✓ | 21.16 | 85.79 | 35 |
| KITTI | BDD100K | Ours | ||||
|---|---|---|---|---|---|---|
| mAP (%) | FPS (Hz) | mAP (%) | FPS (Hz) | mAP (%) | FPS (Hz) | |
| Model 1 | 67.9 | 29 | 73.8 | 30 | 70.1 | 30 |
| Model 2 | 69.3 | 37 | 75.1 | 40 | 72.0 | 39 |
| Model 3 | 70.1 | 36 | 76.0 | 38 | 72.7 | 37 |
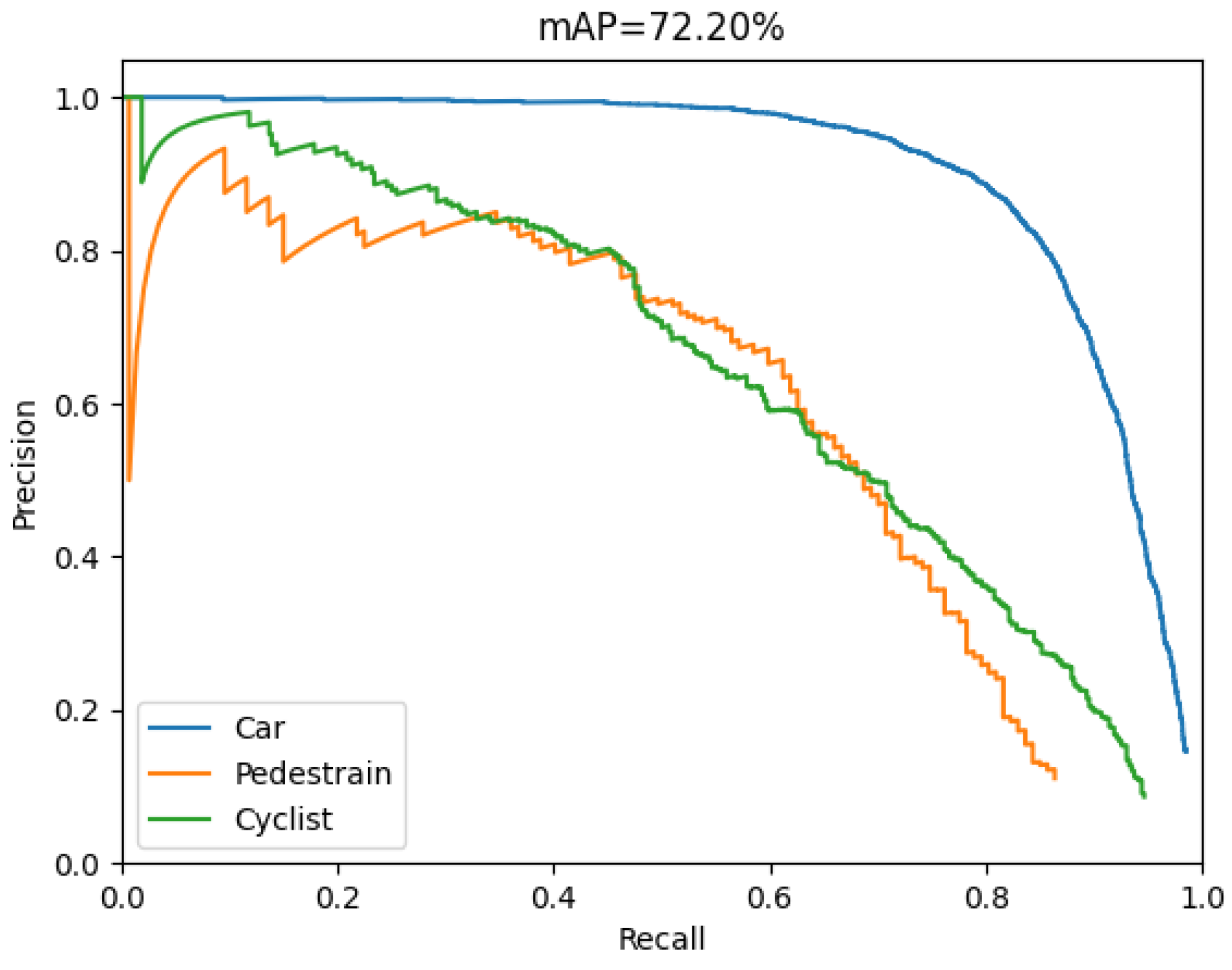
| Model 4 | 72.2 | 35 | 78.3 | 37 | 75.2 | 36 |
| Method | Backbone | Input Size | Parameters (M) | mAP (%) | FPS (Hz) |
|---|---|---|---|---|---|
| YOLOv3 | Darknet53 | 640 × 640 | 58.65 | 65.26 | 30 |
| YOLOv4 | CSPDarknet53 | 640 × 640 | 64.62 | 66.80 | 28 |
| YOLOv5 | CSPDarknet53 | 640 × 640 | 86.70 | 73.20 | 26 |
| CA-MobileNetv2-YOLOv4 (Ours) | MobileNetv2 | 640 × 640 | 21.16 | 72.20 | 35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Zhou, A.; Zhao, F.; Wu, H. A Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios. Sensors 2022, 22, 8480. https://doi.org/10.3390/s22218480
Zhang Y, Zhou A, Zhao F, Wu H. A Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios. Sensors. 2022; 22(21):8480. https://doi.org/10.3390/s22218480
Chicago/Turabian StyleZhang, Yong, Aibo Zhou, Fengkui Zhao, and Haixiao Wu. 2022. "A Lightweight Vehicle-Pedestrian Detection Algorithm Based on Attention Mechanism in Traffic Scenarios" Sensors 22, no. 21: 8480. https://doi.org/10.3390/s22218480