

Compact Image-Style Transfer: Channel Pruning on the Single Training of a Network

Abstract
:1. Introduction
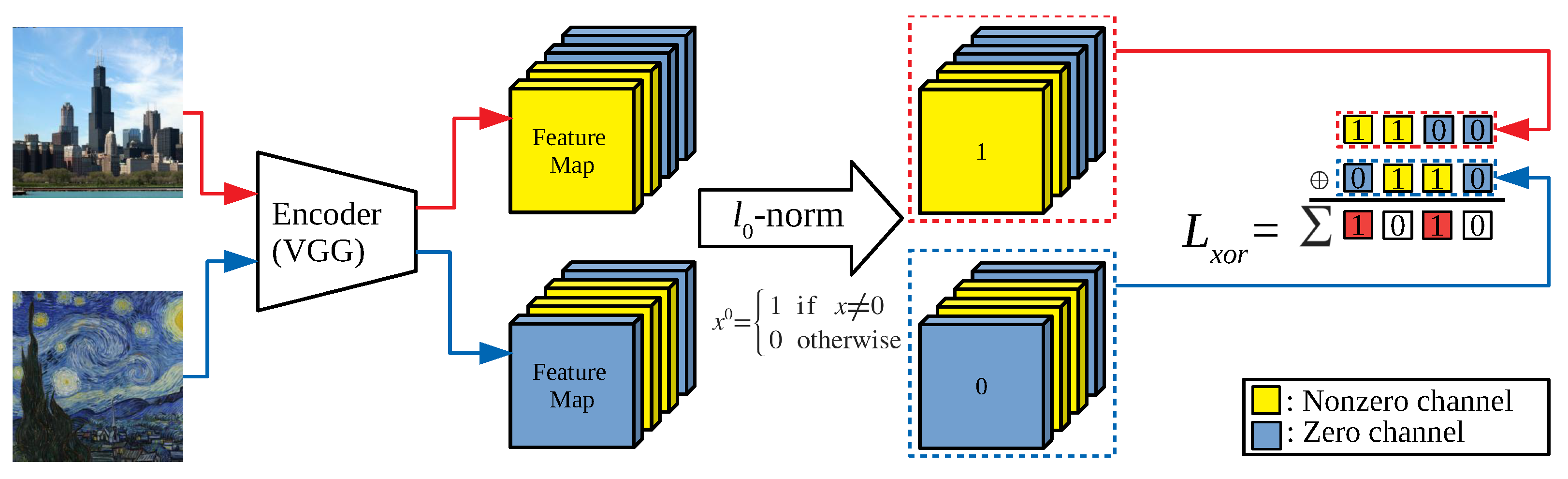
- Our channel loss increases the number of inactive channels, i.e., zero-response channels, of the feature map which increases the compactness of a network.
- Our xor loss forces a consistent position of zero-response channels regardless of the input image, which makes it possible to eliminate the corresponding filter parameters without losing the performance of the network.
- Our method achieved a compact network of 20% fewer parameters and 49% faster image-generating speed than the existing image-style transfer methods without performance degradation.
- Our method also achieved 26% fewer parameters and a top-1 accuracy improvement by 0.16% in the image classification task.
2. Related Works
2.1. Image-Style Transfer
2.2. Network Pruning
3. Method
3.1. Channel Loss
3.2. XOR Loss
3.3. Channel Pruning during Target Task Learning
4. Experiments
4.1. Experimental Setup
4.1.1. Setup for Image Style Transfer
4.1.2. Setup for Image Classification
4.2. Experimental Results of Pruning for Image-Style Transfer Task
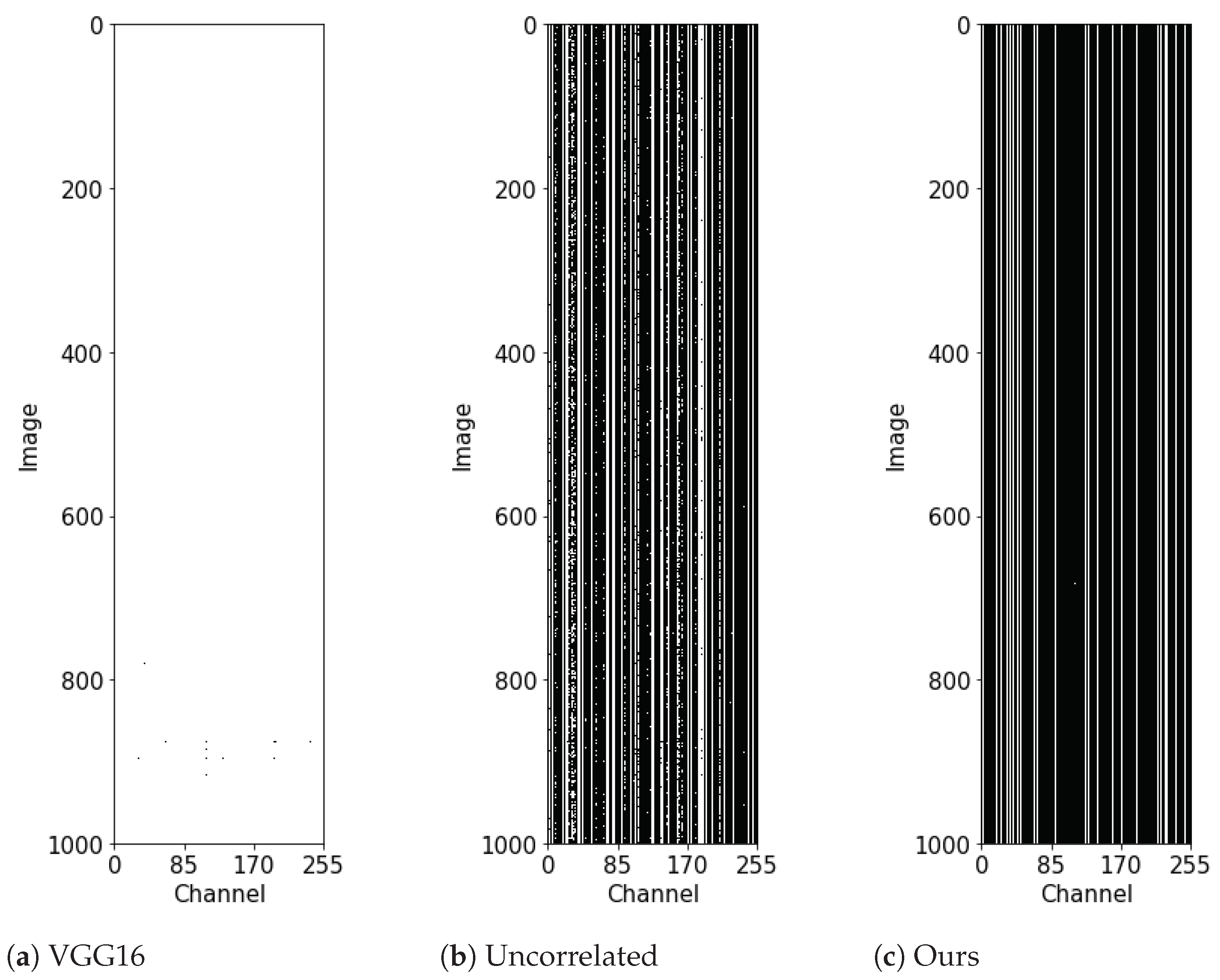
4.2.1. Analysis of Feature-Map Channel Response
4.2.2. Efficiency in Memory and Speed
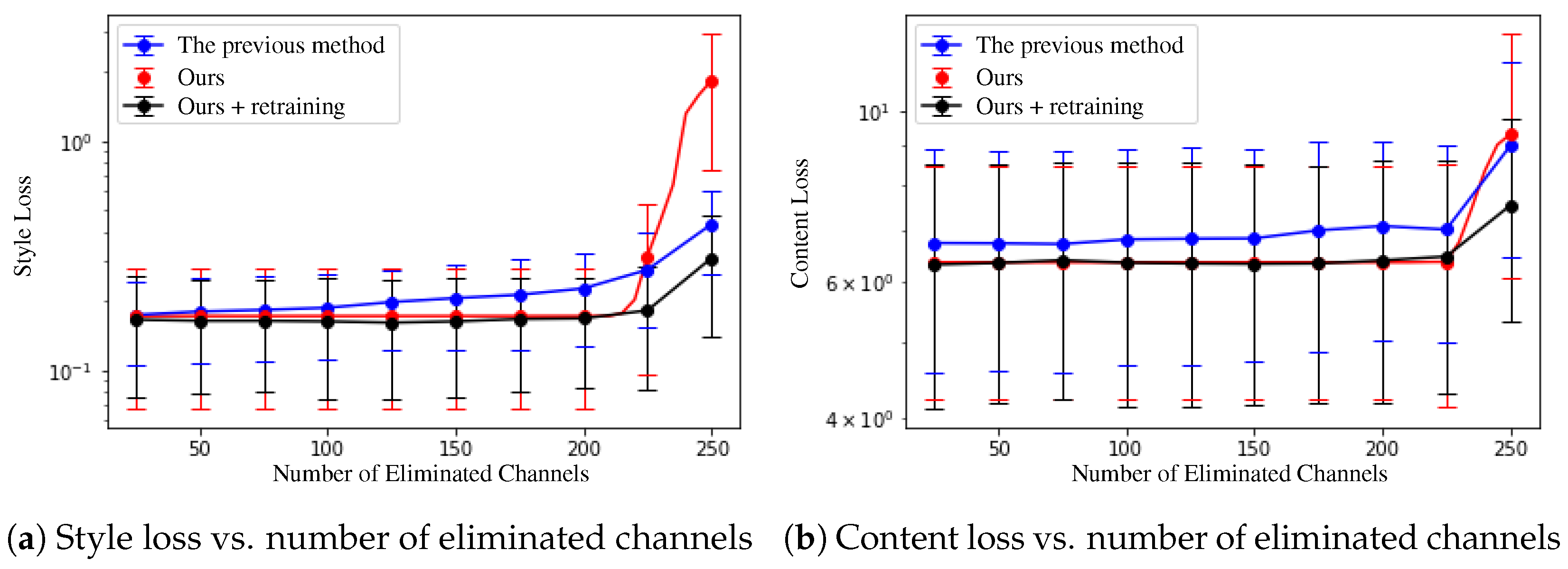
4.2.3. Quality of Stylized Image
4.2.4. Comparison with the Existing Pruning Method
4.3. Experimental Results of Pruning for Image Classification Task
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Universal style transfer via feature transforms. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 385–395. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-Net: Multi-scale Zero-shot Style Transfer by Feature Decoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8242–8250. [Google Scholar]
- Yao, Y.; Ren, J.; Xie, X.; Liu, W.; Liu, Y.J.; Wang, J. Attention-aware multi-stroke style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1467–1475. [Google Scholar]
- Wu, Z.; Song, C.; Zhou, Y.; Gong, M.; Huang, H. Efanet: Exchangeable feature alignment network for arbitrary style transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12305–12312. [Google Scholar]
- Lin, T.; Ma, Z.; Li, F.; He, D.; Li, X.; Ding, E.; Wang, N.; Li, J.; Gao, X. Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 5141–5150. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrary style transfer with style-attentional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5880–5888. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wang, Z.; Zhao, L.; Chen, H.; Qiu, L.; Mo, Q.; Lin, S.; Xing, W.; Lu, D. Diversified arbitrary style transfer via deep feature perturbation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 7–12 February 2020; pp. 7789–7798. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 2, pp. 1389–1397. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- Luo, J.H.; Zhang, H.; Zhou, H.Y.; Xie, C.W.; Wu, J.; Lin, W. Thinet: Pruning cnn filters for a thinner net. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2018, 41, 2525–2538. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.; Ji, R.; Wang, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 7–12 February 2020; pp. 1529–1538. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Luo, J.H.; Wu, J. Autopruner: An end-to-end trainable filter pruning method for efficient deep model inference. Pattern Recognit. 2020, 107, 107461. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V.S. Texture Networks: Feed-forward Synthesis of Textures and Stylized Images. In Proceedings of the 33rd International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1349–1357. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A Learned Representation For Artistic Style. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Improved Texture Networks: Maximizing Quality and Diversity in Feed-Forward Stylization and Texture Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6924–6932. [Google Scholar]
- Li, C.; Wand, M. Precomputed real-time texture synthesis with markovian generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 702–716. [Google Scholar]
- Gupta, A.; Johnson, J.; Alahi, A.; Fei-Fei, L. Characterizing and improving stability in neural style transfer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4067–4076. [Google Scholar]
- Chen, D.; Liao, J.; Yuan, L.; Yu, N.; Hua, G. Coherent Online Video Style Transfer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1105–1114. [Google Scholar]
- Jing, Y.; Liu, Y.; Yang, Y.; Feng, Z.; Yu, Y.; Tao, D.; Song, M. Stroke controllable fast style transfer with adaptive receptive fields. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 238–254. [Google Scholar]
- Wang, X.; Oxholm, G.; Zhang, D.; Wang, Y.F. Multimodal transfer: A hierarchical deep convolutional neural network for fast artistic style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2, pp. 5239–5247. [Google Scholar]
- Ghiasi, G.; Lee, H.; Kudlur, M.; Dumoulin, V.; Shlens, J. Exploring the structure of a real-time, arbitrary neural artistic stylization network. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017; pp. 114.1–114.12. [Google Scholar]
- Jing, Y.; Liu, X.; Ding, Y.; Wang, X.; Ding, E.; Song, M.; Wen, S. Dynamic instance normalization for arbitrary style transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4369–4376. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Sun, Z.; Li, Q.; Ding, E. AdaAttN: Revisit Attention Mechanism in Arbitrary Neural Style Transfer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 6649–6658. [Google Scholar]
- Li, Y.; Adamczewski, K.; Li, W.; Gu, S.; Timofte, R.; Van Gool, L. Revisiting Random Channel Pruning for Neural Network Compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 191–201. [Google Scholar]
- Fu, C.Y. pytorch-vgg-cifar10. Available online: https://github.com/chengyangfu/pytorch-vgg-cifar10 (accessed on 20 December 2017).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Nichol, K. Kaggle Dataset: Painter by Numbers. Available online: https://www.kaggle.com/c/painter-by-numbers (accessed on 31 December 2016).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 400–407. [Google Scholar] [CrossRef]
- Yoon, Y.; Kim, M.; Choi, H. End-to-end learning for arbitrary image style transfer. Electron. Lett. 2018, 54, 1276–1278. [Google Scholar] [CrossRef]
- Kim, M.; Choi, H.C. Uncorrelated Feature Encoding for Faster Image Style Transfer. Neural Netw. 2021, 140, 148–157. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Speed (ms) | Memory | ||
|---|---|---|---|---|
| Encoder/Decoder | Transformer | Total | (# of Parameters) | |
| (a) Universal | 6.67 (0.05) | 377.80 (5.26) | 384.47 (5.29) | 34 M |
| (b) Universal + ours | 6.76 (0.07) | 190.20 (3.83) | 196.95 (3.93) | 27 M |
| (c) AvatarNet | 2.93 (0.07) | 325.53 (7.02) | 328.46 (7.05) | 7 M |
| (d) AvatarNet + ours | 2.84 (0.08) | 198.97 (12.43) | 201.80 (12.52) | 5 M |
| # of Parameters | Top-1 Error (%) | |
|---|---|---|
| (a) Base | 15 M | 7.74% |
| (b) Ours | 11 M | 7.58% |
| (c) Li et al. [12] | 11 M | 8.04% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M.; Choi, H.-C. Compact Image-Style Transfer: Channel Pruning on the Single Training of a Network. Sensors 2022, 22, 8427. https://doi.org/10.3390/s22218427
Kim M, Choi H-C. Compact Image-Style Transfer: Channel Pruning on the Single Training of a Network. Sensors. 2022; 22(21):8427. https://doi.org/10.3390/s22218427
Chicago/Turabian StyleKim, Minseong, and Hyun-Chul Choi. 2022. "Compact Image-Style Transfer: Channel Pruning on the Single Training of a Network" Sensors 22, no. 21: 8427. https://doi.org/10.3390/s22218427