

Deep-E Enhanced Photoacoustic Tomography Using Three-Dimensional Reconstruction for High-Quality Vascular Imaging
 , and
, and 
Abstract
:1. Introduction
2. Methods
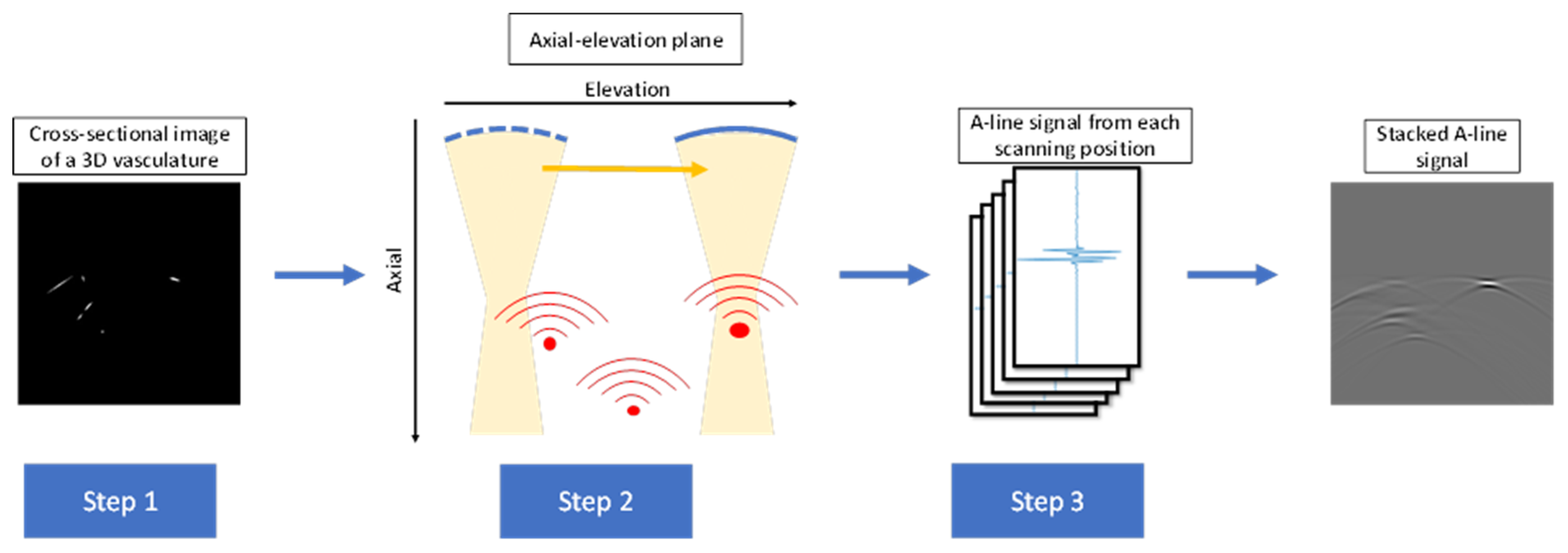
2.1. System Setup
2.2. Simulation of PA Signal
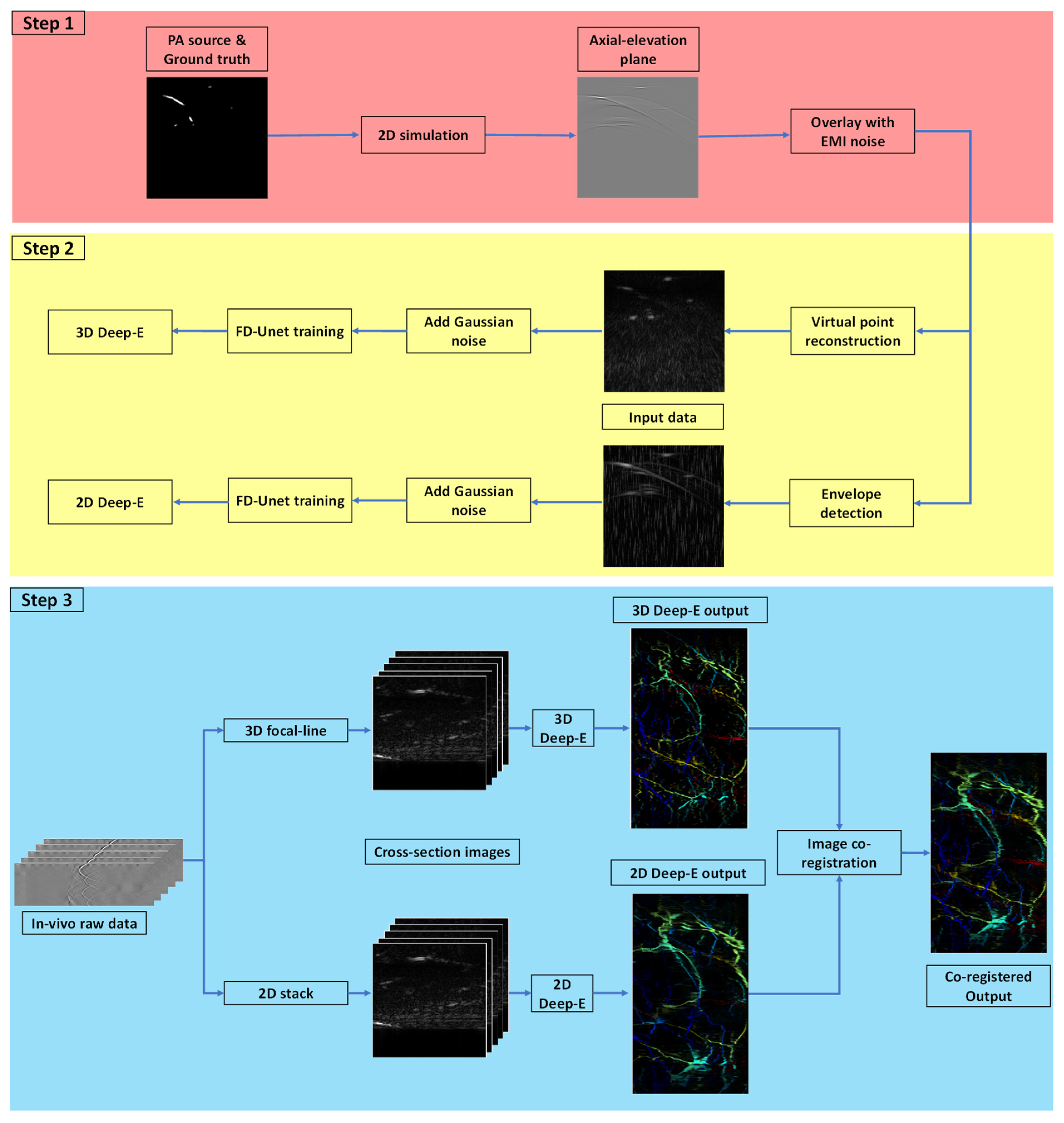
2.3. Image Reconstruction Algorithms
2.4. Input Dataset and Neural Network Parameters
- Dense block: It consists of a sequence of a 1 × 1 and 3 × 3 convolution with batch normalization and ReLU activation function. The outputs from earlier convolutional layers are concatenated together as the input to the subsequent layer.
- Down block: It is a learned downsampling operation that consists of a 1 × 1 convolution block with a stride of 1, and a 3 × 3 convolution block with a stride of 2. It gradually reduces the feature map size and increases the channel number. In the last layer of the downsampling path, we can obtain 512 feature maps with the size of 8 × 8.
- Up block: It consists of a 3 × 3 transposed convolution block with a stride of 2 followed by ReLU activation function and batch normalization to expand the feature map size.
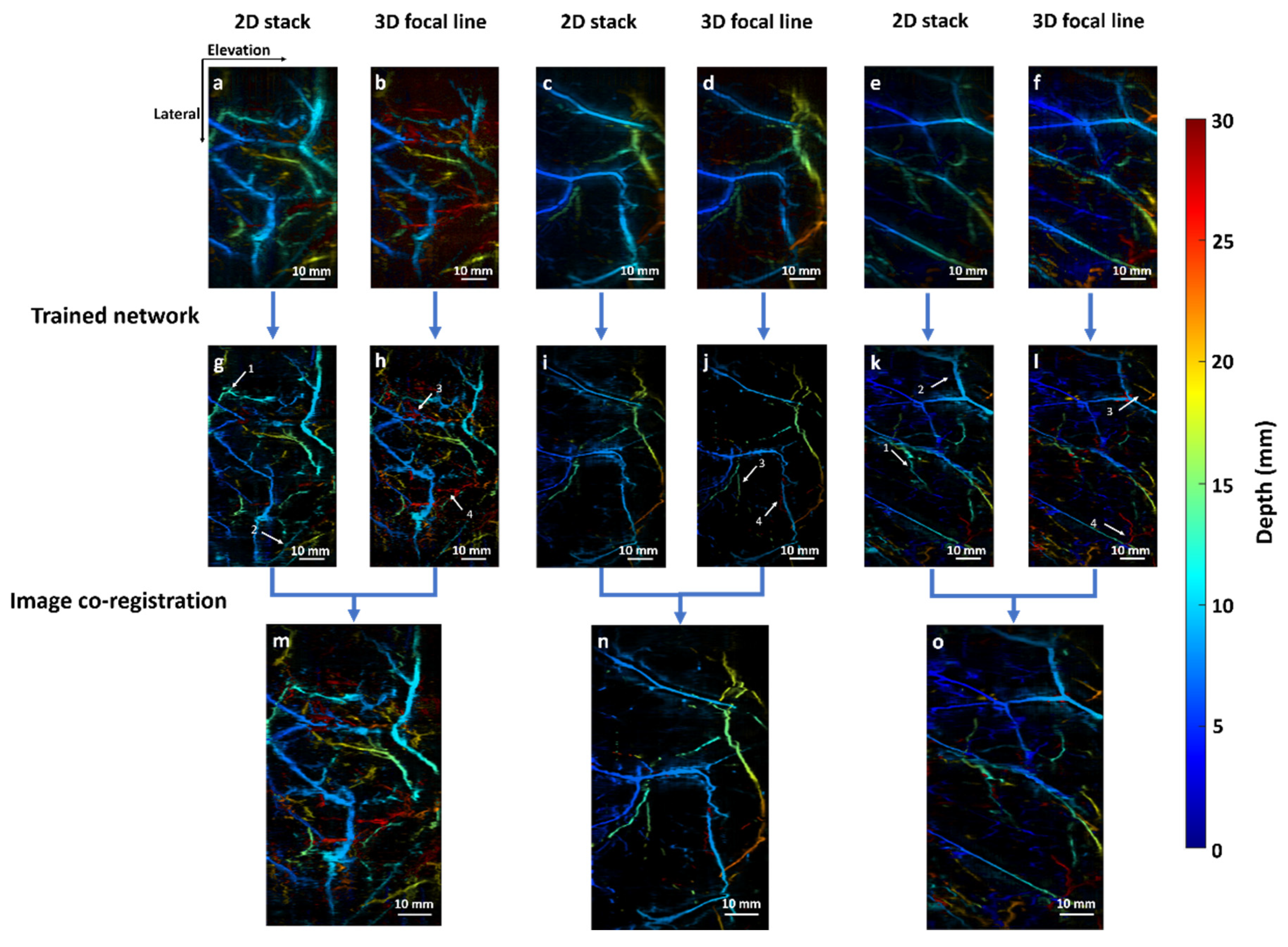
2.5. Image Co-Registration
2.6. Summary
3. Results
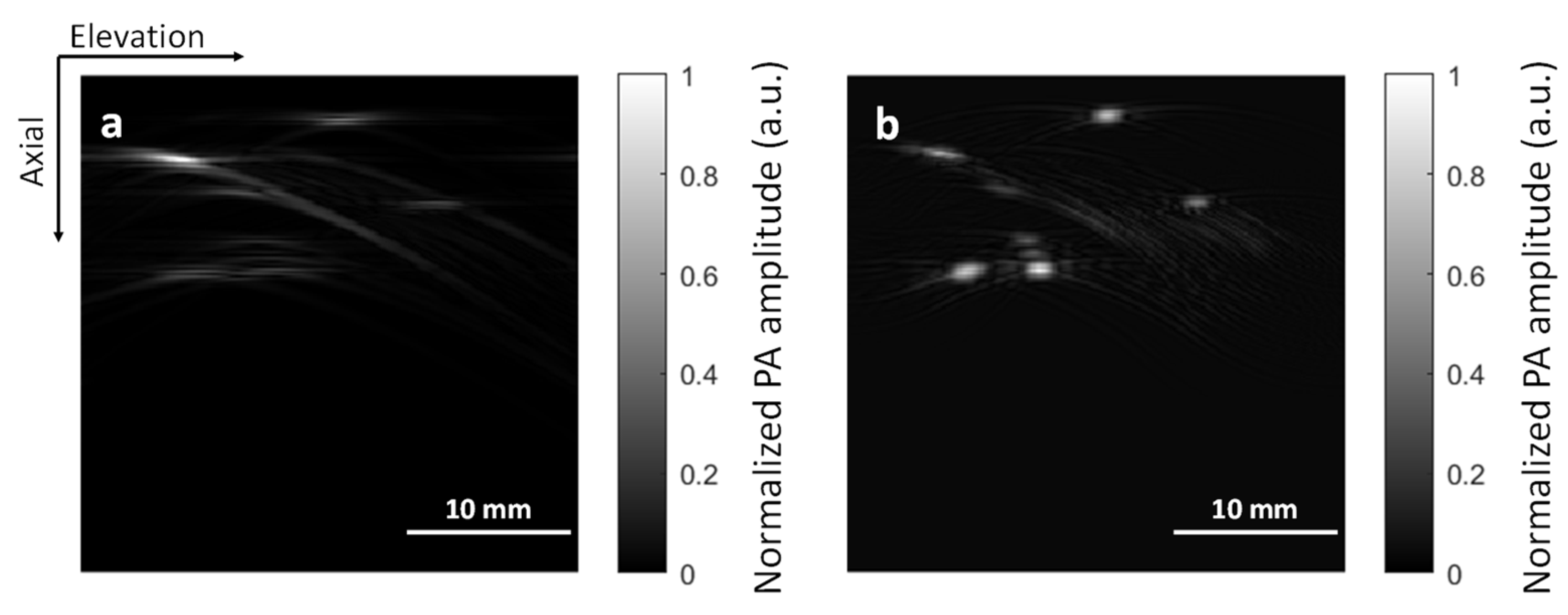
3.1. Validation with Simulated Vasculature
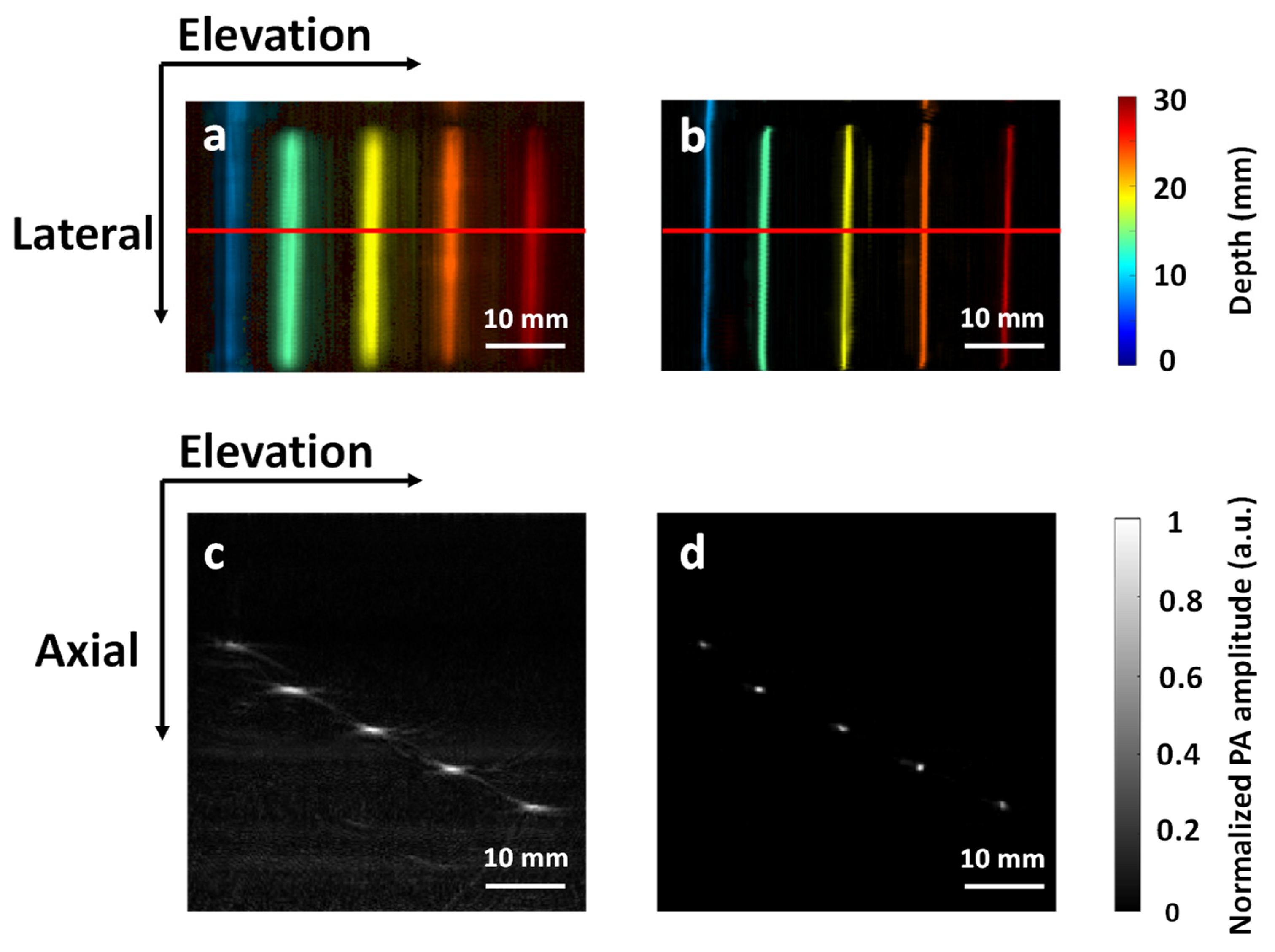
3.2. Validation with Phantom Data
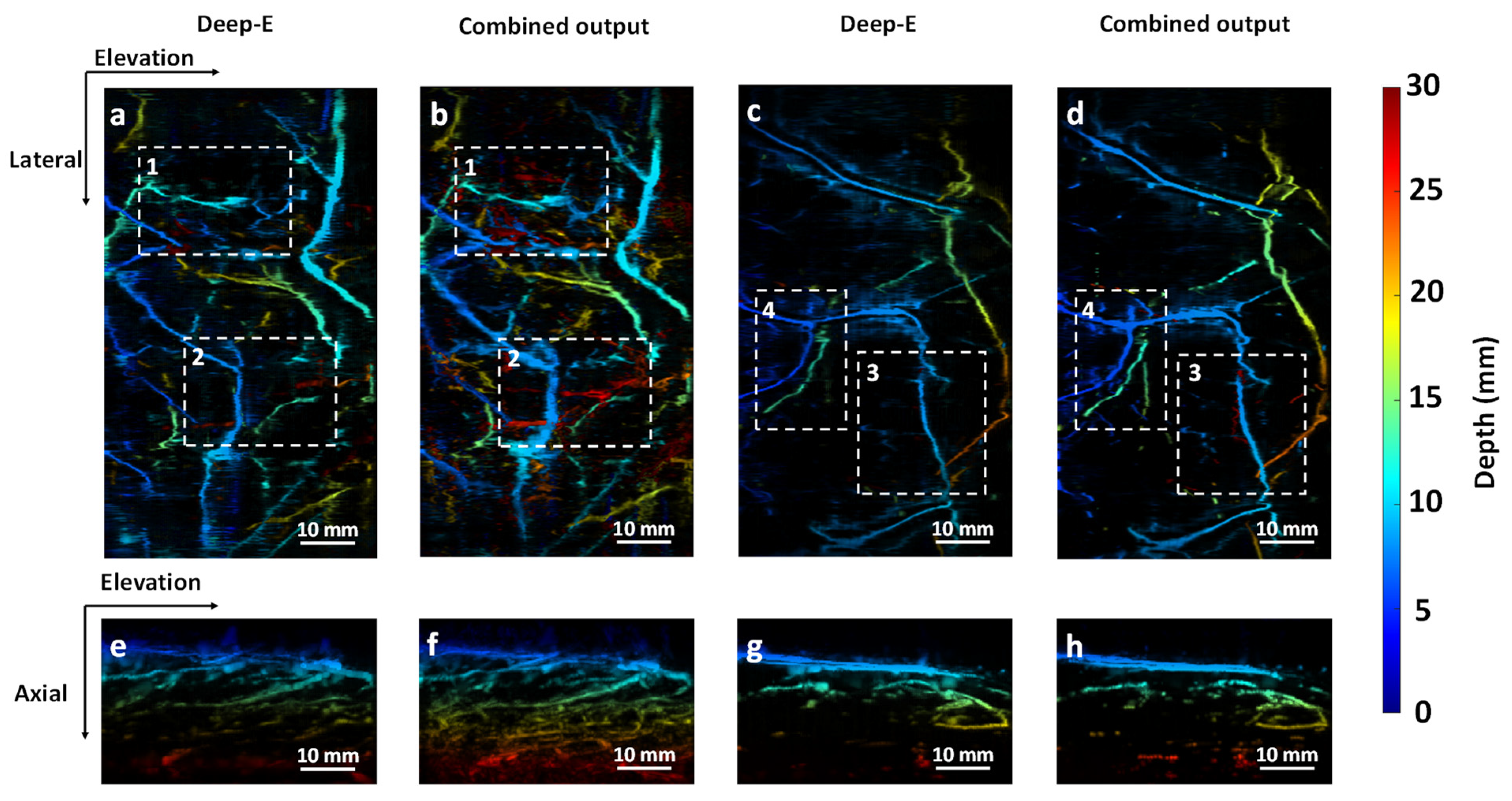
3.3. Validation with In Vivo Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, L.V. Prospects of photoacoustic tomography. Med. Phys. 2008, 35, 5758–5767. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Yao, J.; Wang, L.V. Photoacoustic tomography: Principles and advances. Electromagn. Waves Camb. 2014, 147, 1–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.V.; Hu, S. Photoacoustic tomography: In vivo imaging from organelles to organs. Science 2012, 335, 1458–1462. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, H.; Duan, T.; Lan, H.; Zhou, M.; Gao, F. Review of Low-Cost Photoacoustic Sensing and Imaging Based on Laser Diode and Light-Emitting Diode. Sensors 2018, 18, 2264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nyayapathi, N.; Lim, R.; Zhang, H.; Zheng, W.; Wang, Y.; Tiao, M.; Oh, K.W.; Fan, X.C.; Bonaccio, E.; Takabe, K. Dual scan mammoscope (DSM)—A new portable photoacoustic breast imaging system with scanning in craniocaudal plane. IEEE Trans. Biomed. Eng. 2019, 67, 1321–1327. [Google Scholar] [CrossRef]
- Zheng, W.; Lee, D.; Xia, J. Photoacoustic tomography of fingerprint and underlying vasculature for improved biometric identification. Sci. Rep. 2021, 11, 17536. [Google Scholar] [CrossRef]
- Chang, K.-W.; Zhu, Y.; Hudson, H.M.; Barbay, S.; Guggenmos, D.J.; Nudo, R.J.; Yang, X.; Wang, X. Photoacoustic imaging of squirrel monkey cortical and subcortical brain regions during peripheral electrical stimulation. Photoacoustics 2022, 25, 100326. [Google Scholar] [CrossRef] [PubMed]
- Xavierselvan, M.; Singh, M.K.A.; Mallidi, S. In vivo tumor vascular imaging with light emitting diode-based photoacoustic imaging system. Sensors 2020, 20, 4503. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhan, Y.; Tiao, M.; Xia, J. Review of methods to improve the performance of linear array-based photoacoustic tomography. J. Innov. Opt. Health Sci. 2019, 13, 2030003. [Google Scholar] [CrossRef] [Green Version]
- Gateau, J.; Gesnik, M.; Chassot, J.-M.; Bossy, E. Single-side access, isotropic resolution, and multispectral three-dimensional photoacoustic imaging with rotate-translate scanning of ultrasonic detector array. J. Biomed. Opt. 2015, 20, 056004. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, D.; Zhang, Y.; Geng, J.; Lovell, J.F.; Xia, J. Slit-enabled linear-array photoacoustic tomography with near isotropic spatial resolution in three dimensions. Opt. Lett. 2016, 41, 127–130. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Huang, C.; Zhang, H.; Xia, J. Slit-based photoacoustic tomography with co-planar light illumination and acoustic detection for high-resolution vascular imaging in human using a linear transducer array. Biomed. Eng. Lett. 2022, 12, 125–133. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Y.; Zhou, Y.; Lovell, J.F.; Xia, J. Coherent-weighted three-dimensional image reconstruction in linear-array-based photoacoustic tomography. Biomed. Opt. Express 2016, 7, 1957–1965. [Google Scholar] [CrossRef] [Green Version]
- Gröhl, J.; Schellenberg, M.; Dreher, K.; Maier-Hein, L. Deep learning for biomedical photoacoustic imaging: A review. Photoacoustics 2021, 22, 100241. [Google Scholar] [CrossRef]
- Yang, C.; Lan, H.; Gao, F.; Gao, F. Review of deep learning for photoacoustic imaging. Photoacoustics 2021, 21, 100215. [Google Scholar] [CrossRef]
- Dehner, C.; Olefir, I.; Chowdhury, K.B.; Jüstel, D.; Ntziachristos, V. Deep learning based electrical noise removal enables high spectral optoacoustic contrast in deep tissue. arXiv 2021, arXiv:2102.12960. [Google Scholar] [CrossRef]
- Zhang, H.; Bo, W.; Wang, D.; Di Spirito, A.; Huang, C.; Nyayapathi, N.; Zheng, E.; Vu, T.; Gong, Y.; Yao, J. Deep-E: A Fully-Dense Neural Network for Improving the Elevation Resolution in Linear-array-based Photoacoustic Tomography. IEEE Trans. Med. Imaging 2021, 41, 1279–1288. [Google Scholar] [CrossRef] [PubMed]
- Zheng, E.; Zhang, H.; Goswami, S.; Kabir, I.E.; Doyley, M.M.; Xia, J. Second-Generation Dual Scan Mammoscope With Photoacoustic, Ultrasound, and Elastographic Imaging Capabilities. Front. Oncol. 2021, 11, 779071. [Google Scholar] [CrossRef] [PubMed]
- Treeby, B.E.; Cox, B.T. k-Wave: MATLAB toolbox for the simulation and reconstruction of photoacoustic wave fields. J. Biomed. Opt. 2010, 15, 021314. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martinez-Perez, M.E.; Hughes, A.D.; Thom, S.A.; Parker, K.H. Improvement of a Retinal Blood Vessel Segmentation Method Using the Insight Segmentation and Registration Toolkit (ITK). In Proceedings of 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 22–26 August 2007; pp. 892–895. [Google Scholar]
- Xia, J.; Guo, Z.; Maslov, K.; Aguirre, A.; Zhu, Q.; Percival, C.; Wang, L.V. Three-dimensional photoacoustic tomography based on the focal-line concept. J. Biomed. Opt. 2011, 16, 090505. [Google Scholar] [CrossRef]
- Li, M.-L.; Zhang, H.F.; Maslov, K.; Stoica, G.; Wang, L.V. Improved in vivo photoacoustic microscopy based on a virtual-detector concept. Opt. Lett. 2006, 31, 474–476. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guan, S.; Khan, A.A.; Sikdar, S.; Chitnis, P.V. Fully dense UNet for 2-D sparse photoacoustic tomography artifact removal. IEEE J. Biomed. Health Inform. 2019, 24, 568–576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thirion, J.-P. Image matching as a diffusion process: An analogy with Maxwell’s demons. Med. Image Anal. 1998, 2, 243–260. [Google Scholar] [CrossRef] [Green Version]
- Vercauteren, T.; Pennec, X.; Perchant, A.; Ayache, N. Diffeomorphic Demons: Efficient Non-parametric Image Registration. NeuroImage 2009, 45 (Suppl. 1), 61–72. [Google Scholar] [CrossRef] [Green Version]
- Hoffman, D.P.; Slavitt, I.; Fitzpatrick, C.A. The promise and peril of deep learning in microscopy. Nat. Methods 2021, 18, 131–132. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gaussian Noise Level | Input PSNR (dB) | Output PSNR (dB) | Input Cross-Section PSNR (dB) | Output Cross-Section PSNR (dB) | Input SSIM | Output SSIM | Input Cross-Section SSIM | Output Cross-Section SSIM |
|---|---|---|---|---|---|---|---|---|
| 9 dB | 5.54 | 17.61 | 10.78 | 29.93 | 0.014 | 0.756 | 0.001 | 0.994 |
| 12 dB | 6.74 | 17.96 | 12.16 | 29.31 | 0.023 | 0.814 | 0.001 | 0.994 |
| EMI only | 11.85 | 20.13 | 19.49 | 38.78 | 0.051 | 0.859 | 0.009 | 0.995 |
| Object 1 Diameter (mm) | Object 2 Diameter (mm) | |||||
|---|---|---|---|---|---|---|
| Axial | Elevation | Average | Axial | Elevation | Average | |
| Input | 0.63 | 0.98 | 0.81 | 0.76 | 1.53 | 1.15 |
| Output | 0.26 | 0.27 | 0.27 | 0.32 | 0.43 | 0.38 |
| Ground truth | 0.27 | 0.29 | 0.28 | 0.32 | 0.51 | 0.41 |
| Averaged Pencil Lead Diameter (mm) | Contrast-to-Noise Ratio | ||
|---|---|---|---|
| Axial | Elevation | ||
| Input | 0.85 ± 0.08 | 1.82 ± 0.13 | 7.32 |
| Output | 0.56 ± 0.07 | 0.54 ± 0.04 | 12.53 |
| Ground truth | 0.50 | 0.50 | |
| Pencil Lead Diameter along the Trasnducer’s Elevation Direction (mm) | |||
|---|---|---|---|
| Input | 0.91 ± 0.09 | 1.92 ± 0.19 | 2.81 ± 0.42 |
| Output | 0.71 ± 0.07 | 0.93 ± 0.16 | 1.55 ± 0.11 |
| Ground truth | 0.50 | 0.90 | 2.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Zhang, H.; Huang, C.; McQuillan, K.; Li, H.; Xu, W.; Xia, J. Deep-E Enhanced Photoacoustic Tomography Using Three-Dimensional Reconstruction for High-Quality Vascular Imaging. Sensors 2022, 22, 7725. https://doi.org/10.3390/s22207725
Zheng W, Zhang H, Huang C, McQuillan K, Li H, Xu W, Xia J. Deep-E Enhanced Photoacoustic Tomography Using Three-Dimensional Reconstruction for High-Quality Vascular Imaging. Sensors. 2022; 22(20):7725. https://doi.org/10.3390/s22207725
Chicago/Turabian StyleZheng, Wenhan, Huijuan Zhang, Chuqin Huang, Kaylin McQuillan, Huining Li, Wenyao Xu, and Jun Xia. 2022. "Deep-E Enhanced Photoacoustic Tomography Using Three-Dimensional Reconstruction for High-Quality Vascular Imaging" Sensors 22, no. 20: 7725. https://doi.org/10.3390/s22207725