
A Social Distance Estimation and Crowd Monitoring System for Surveillance Cameras

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Person Detection and Localization
2.2. Anomaly Recognition
2.3. Crowd Monitoring
3. Methodology
- Read a frame from the surveillance camera. This component can be adjusted to skip/drop frames in case of using high-resolution and/or high-frame-rate cameras.
- Detect human subjects in the input frame and compute their position. The position of each detected subject is estimated as a single point.
- Discard any localized positions outside a selected region of interest (ROI). The ROI is defined by the user beforehand and typically encloses the ground plane.
- Transform the localized positions from the image–pixel coordinates to the real-world coordinates. This provides a top-view depiction of the subject’s position.
- Smooth the noisy top-view positions and compensate for missing data due to occlusion with tracking.
- Estimate the inter-personal distances among the detected subjects and the occupancy/crowd density maps.
- Recognize social distance violations and identify congested or overcrowded regions in the scene.
- Integrate the smoothed/tracked positions, estimated parameters, and detected anomalies with the video frame.
- View the integrated video frame and generate a dynamic top-view map for the scene. This component allows adjusting the type and amount of appended information.
- High accuracy and reliability in terms of robustness to noise and missing data.
- Light weight for implementation and deployment.
- Modularity to facilitate maintenance, upgrades, decentralization, and to avoid resource allocation bottlenecks.
- Privacy-preserving by not carrying nor processing person-specific features.
- Robustness against different vertical pose states and actions, e.g., standing, sitting, bowing, bending, walking, and cycling.
3.1. Person Detection and Localization
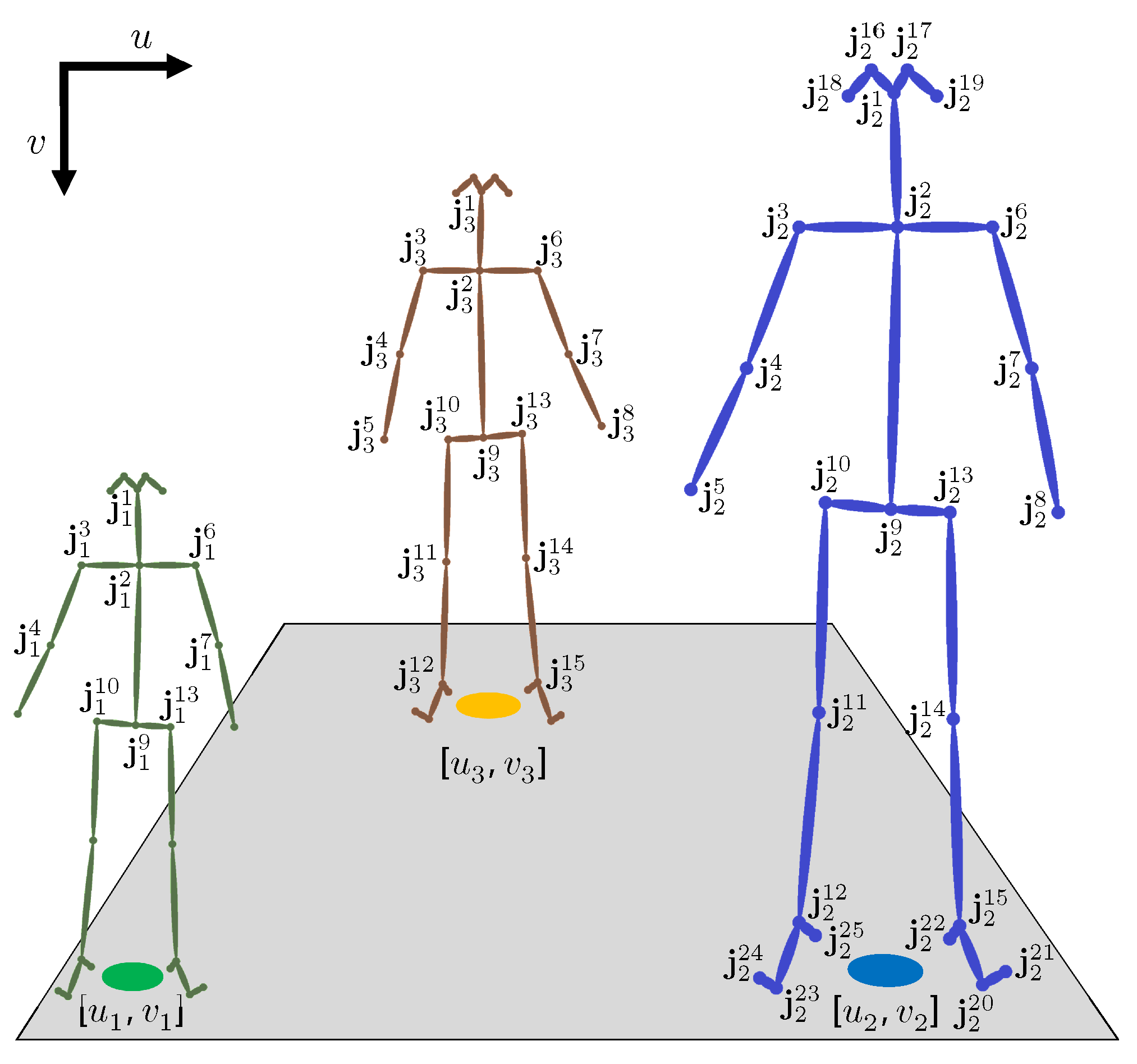
3.1.1. Detection
3.1.2. Localization
| Algorithm 1 The proposed localization strategy. | |
Input: and where . Output: and . Initialization: Left/right foot horizontal coordinates / and the feet vertical coordinate . ,,,,,,, | |
| |
| ▹ Both feet joints are available |
| ▹ Left foot and right knee joints are available |
| ▹ Left knee and right foot joints are available |
| ▹ Both knees’ joints are available |
| ▹ Right hip and left knee joints are available |
| ▹ Right knee and left hip joints are available |
| ▹ Hip’s joints are available |
| ▹ Torso’s joints are available |
| ▹ Consider any available feet joints |
| |
| |
| |
| ▹ Consider any available feet joints |
| ▹ Torso’s joints are available |
| |
| |
- (): subject is not detected.
- (): subject is detected but () is not available, regardless of the reason.
- (): subject is detected and () is directly estimated from the feet joints.
- (): subject is detected and () is predicted using other joints.
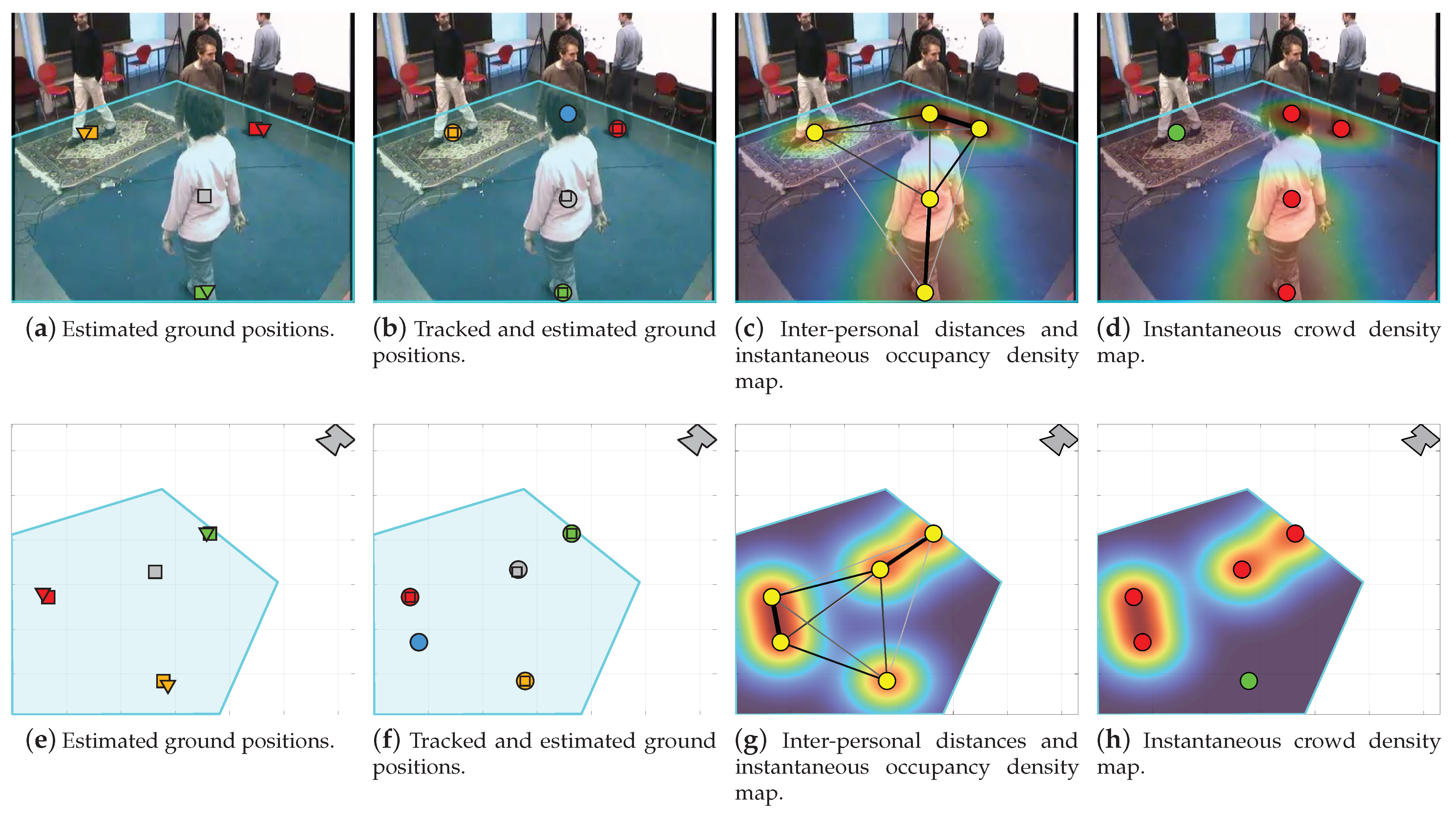
3.2. Top-View Transformation
3.3. Smoothing and Tracking
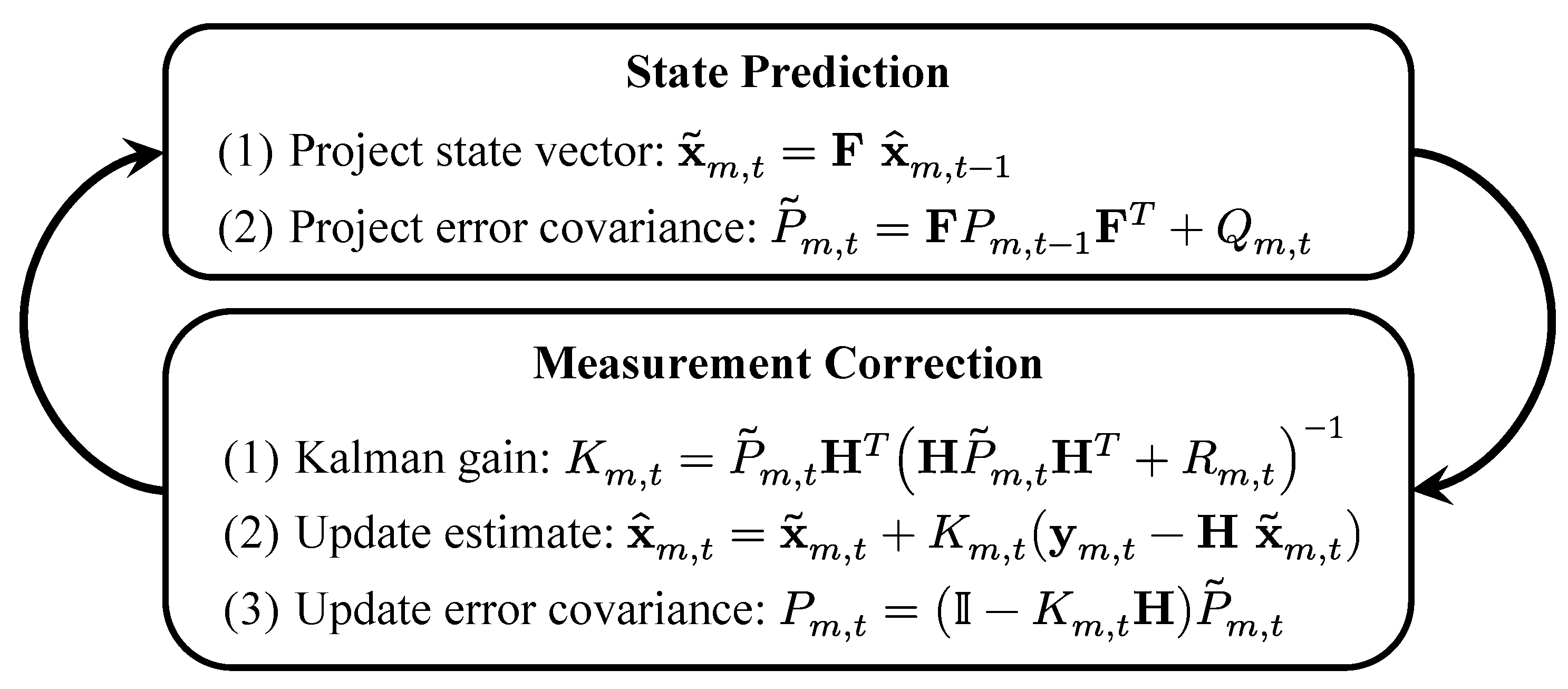
3.3.1. State and Measurement Models
3.3.2. The Linear Kalman Filter
3.3.3. Global Nearest Neighbor Tracking
- Initiation: create new tentative tracks for unassigned detections; .
- Promotion: confirm a tentative track if its likelihood of being true is greater than .
- Demotion: demote a confirmed track to tentative if the subject leaves the ROI.
- Deletion: delete a confirmed track if its maximum likelihood decreases by .
3.4. Parameter Estimation
3.4.1. Inter-Personal Distance
3.4.2. Occupancy and Crowd Density Maps
3.5. Anomaly Recognition
3.6. Performance Evaluation
4. Results and Discussions
4.1. Dataset
4.2. Preprocessing and Settings
4.3. System Integration
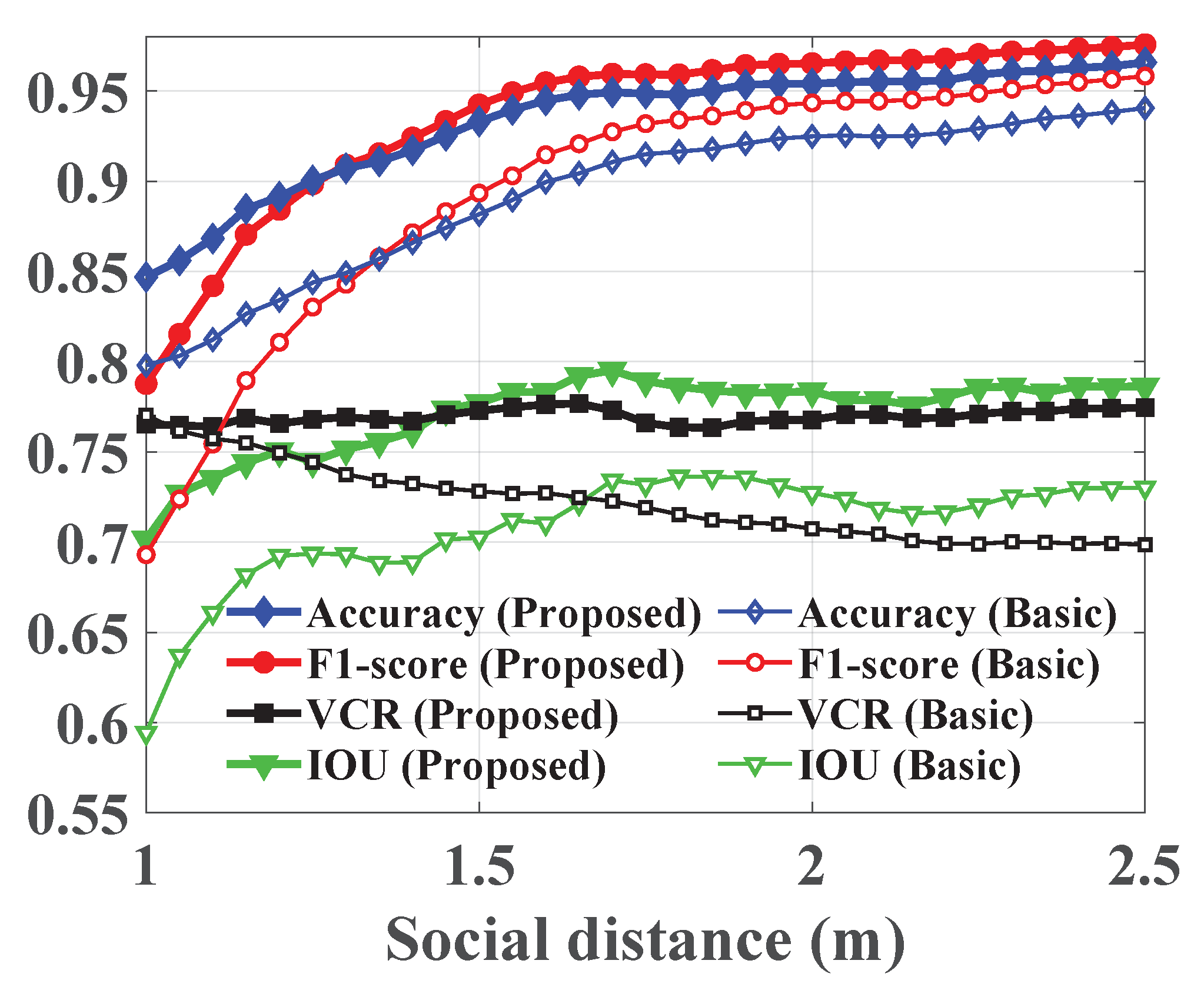
4.4. Evaluations and Results
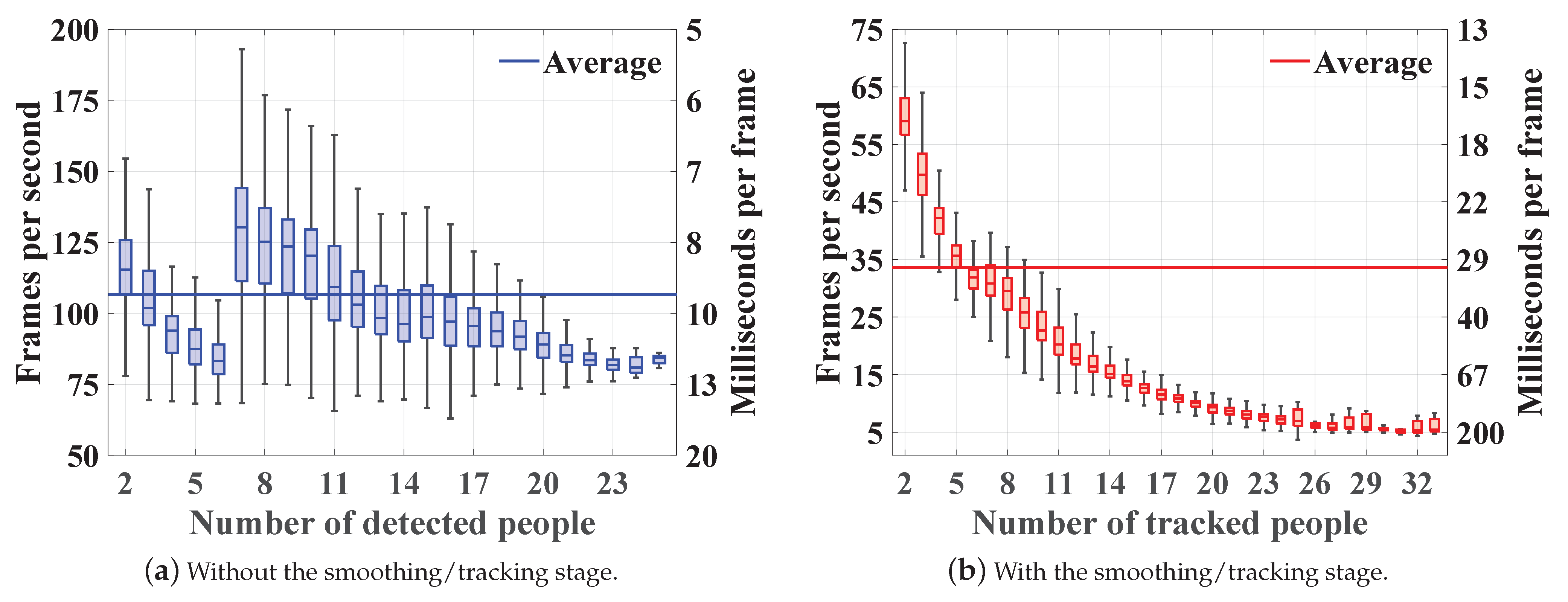
4.5. Computational Complexity Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fauci, A.S.; Lane, H.C.; Redfield, R.R. COVID-19—Navigating the Uncharted. N. Engl. J. Med. 2020, 382, 1268–1269. [Google Scholar] [CrossRef]
- Hoeben, E.M.; Bernasco, W.; Suonperä Liebst, L.; van Baak, C.; Rosenkrantz Lindegaard, M. Social distancing compliance: A video observational analysis. PLoS ONE 2021, 16, e0248221. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G.; Guizani, N. Explainable AI and Mass Surveillance System-Based Healthcare Framework to Combat COVID-I9 Like Pandemics. IEEE Netw. 2020, 34, 126–132. [Google Scholar] [CrossRef]
- Cristani, M.; Bue, A.D.; Murino, V.; Setti, F.; Vinciarelli, A. The Visual Social Distancing Problem. IEEE Access 2020, 8, 126876–126886. [Google Scholar] [CrossRef]
- Sugianto, N.; Tjondronegoro, D.; Stockdale, R.; Yuwono, E.I. Privacy-preserving AI-enabled video surveillance for social distancing: Responsible design and deployment for public spaces. Inf. Technol. People 2021. [Google Scholar] [CrossRef]
- Zuo, F.; Gao, J.; Kurkcu, A.; Yang, H.; Ozbay, K.; Ma, Q. Reference-free video-to-real distance approximation-based urban social distancing analytics amid COVID-19 pandemic. J. Transp. Health 2021, 21, 101032. [Google Scholar] [CrossRef]
- Antonucci, A.; Magnago, V.; Palopoli, L.; Fontanelli, D. Performance Assessment of a People Tracker for Social Robots. In Proceedings of the 2019 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Auckland, New Zealand, 20–23 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Gupta, K.; Gupta, K.; Gupta, K. A Survey on Human Activity Recognition and Classification. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020. [Google Scholar] [CrossRef]
- Golda, T.; Kalb, T.; Schumann, A.; Beyerer, J. Human Pose Estimation for Real-World Crowded Scenarios. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, China, 18–21 September 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. CrowdPose: Efficient Crowded Scenes Pose Estimation and a New Benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar] [CrossRef] [Green Version]
- Pi, Y.; Nath, N.D.; Sampathkumar, S.; Behzadan, A.H. Deep Learning for Visual Analytics of the Spread of COVID-19 Infection in Crowded Urban Environments. Nat. Hazards Rev. 2021, 22, 1–14. [Google Scholar] [CrossRef]
- Rezaei, M.; Azarmi, M. DeepSOCIAL: Social Distancing Monitoring and Infection Risk Assessment in COVID-19 Pandemic. Appl. Sci. 2020, 10, 7514. [Google Scholar] [CrossRef]
- Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Monitoring COVID-19 social distancing with person detection and tracking via fine-tuned YOLO v3 and Deepsort techniques. arXiv 2020, arXiv:2005.01385. [Google Scholar]
- Yang, D.; Yurtsever, E.; Renganathan, V.; Redmill, K.A.; Özgüner, Ü. A Vision-Based Social Distancing and Critical Density Detection System for COVID-19. Sensors 2021, 21, 4608. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Rodrigues, J.; Jeon, G.; Din, S. A deep learning-based social distance monitoring framework for COVID-19. Sustain. Cities Soc. 2021, 65, 102571. [Google Scholar] [CrossRef]
- Srinivasan, S.; Rujula Singh, R.; Biradar, R.R.; Revathi, S.A. COVID-19 Monitoring System using Social Distancing and Face Mask Detection on Surveillance video datasets. In Proceedings of the 2021 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 5–7 March 2021; pp. 449–455. [Google Scholar] [CrossRef]
- Magoo, R.; Singh, H.; Jindal, N.; Hooda, N.; Rana, P.S. Deep learning-based bird eye view social distancing monitoring using surveillance video for curbing the COVID-19 spread. Neural Comput. Appl. 2021, 33, 15807–15814. [Google Scholar] [CrossRef]
- Saponara, S.; Elhanashi, A.; Gagliardi, A. Implementing a real-time, AI-based, people detection and social distancing measuring system for COVID-19. J. Real-Time Image Process. 2021, 18, 1937–1947. [Google Scholar] [CrossRef]
- Hou, Y.C.; Baharuddin, M.Z.; Yussof, S.; Dzulkifly, S. Social Distancing Detection with Deep Learning Model. In Proceedings of the 2020 8th International Conference on Information Technology and Multimedia (ICIMU), Selangor, Malaysia, 24–25 August 2020; pp. 334–338. [Google Scholar] [CrossRef]
- Gupta, S.; Kapil, R.; Kanahasabai, G.; Joshi, S.S.; Joshi, A.S. SD-Measure: A Social Distancing Detector. In Proceedings of the 2020 12th International Conference on Computational Intelligence and Communication Networks (CICN), Bhimtal, India, 25–26 September 2020; pp. 306–311. [Google Scholar] [CrossRef]
- Qin, J.; Xu, N. Reaserch and implementation of social distancing monitoring technology based on SSD. Procedia Comput. Sci. 2021, 183, 768–775. [Google Scholar] [CrossRef]
- Shao, Z.; Cheng, G.; Ma, J.; Wang, Z.; Wang, J.; Li, D. Real-time and Accurate UAV Pedestrian Detection for Social Distancing Monitoring in COVID-19 Pandemic. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Shorfuzzaman, M.; Hossain, M.S.; Alhamid, M.F. Towards the sustainable development of smart cities through mass video surveillance: A response to the COVID-19 pandemic. Sustain. Cities Soc. 2021, 64, 102582. [Google Scholar] [CrossRef] [PubMed]
- Ahamad, A.H.; Zaini, N.; Latip, M.F.A. Person Detection for Social Distancing and Safety Violation Alert based on Segmented ROI. In Proceedings of the 2020 10th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 21–22 August 2020; pp. 113–118. [Google Scholar] [CrossRef]
- Aghaei, M.; Bustreo, M.; Wang, Y.; Bailo, G.; Morerio, P.; Del Bue, A. Single Image Human Proxemics Estimation for Visual Social Distancing. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2784–2794. [Google Scholar] [CrossRef]
- Seker, M.; Mannisto, A.; Iosifidis, A.; Raitoharju, J. Automatic Social Distance Estimation From Images: Performance Evaluation, Test Benchmark, and Algorithm. arXiv 2021, arXiv:2103.06759. [Google Scholar]
- Khandelwal, P.; Khandelwal, A.; Agarwal, S.; Thomas, D.; Xavier, N.; Raghuraman, A. Using Computer Vision to enhance Safety of Workforce in Manufacturing in a Post COVID World. arXiv 2020, arXiv:2005.05287. [Google Scholar]
- Nascimento, J.C.; Abrantes, A.J.; Marques, J.S. An algorithm for centroid-based tracking of moving objects. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing Proceedings, Phoenix, AZ, USA, 15–19 March 1999; Volume 6, pp. 3305–3308. [Google Scholar] [CrossRef]
- Rezaee, K.; Rezakhani, S.M.; Khosravi, M.R.; Moghimi, M.K. A survey on deep learning-based real-time crowd anomaly detection for secure distributed video surveillance. Pers. Ubiquitous Comput. 2021. [Google Scholar] [CrossRef]
- Bouhlel, F.; Mliki, H.; Hammami, M. Crowd Behavior Analysis based on Convolutional Neural Network: Social Distancing Control COVID-19. In Proceedings of the International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Online, 8–10 February 2021; Volume 5, pp. 273–280. [Google Scholar] [CrossRef]
- Kizrak, M.A.; Bolat, B. Crowd Density Estimation by Using Attention Based Capsule Network and Multi-Column CNN. IEEE Access 2021, 9, 75435–75445. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Ahmad, A.; Jeon, G. IoT-based crowd monitoring system: Using SSD with transfer learning. Comput. Electr. Eng. 2021, 93, 107226. [Google Scholar] [CrossRef]
- Elbishlawi, S.; Abdelpakey, M.H.; Eltantawy, A.; Shehata, M.S.; Mohamed, M.M. Deep Learning-Based Crowd Scene Analysis Survey. J. Imaging 2020, 6, 95. [Google Scholar] [CrossRef]
- Ozcan, A.H.; Unsalan, C.; Reinartz, P. Sparse people group and crowd detection using spatial point statistics in airborne images. In Proceedings of the 2015 7th International Conference on Recent Advances in Space Technologies (RAST), Istanbul, Turkey, 16–19 June 2015; pp. 307–310. [Google Scholar] [CrossRef] [Green Version]
- Gloudemans, D.; Gloudemans, N.; Abkowitz, M.; Barbour, W.; Work, D.B. Quantifying Social Distancing Compliance and the Effects of Behavioral Interventions Using Computer Vision. In Proceedings of the Workshop on Data-Driven and Intelligent Cyber-Physical Systems, Nashville, TN, USA, 18 May 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Kholopov, I.S. Bird’s Eye View Transformation Technique in Photogrammetric Problem of Object Size Measuring at Low-altitude Photography. In Proceedings of the International Conference “Actual Issues of Mechanical Engineering” 2017 (AIME 2017), Tomsk, Russia, 27–29 July 2017; Atlantis Press: Tomsk, Russia, 2017; pp. 318–324. [Google Scholar] [CrossRef] [Green Version]
- Toriya, H.; Kitahara, I.; Ohta, Y. Mobile Camera Localization Using Aerial-view Images. Inf. Media Technol. 2014, 9, 896–904. [Google Scholar] [CrossRef] [Green Version]
- Calore, E.; Pedersini, F.; Frosio, I. Accelerometer based horizon and keystone perspective correction. In Proceedings of the 2012 IEEE International Instrumentation and Measurement Technology Conference Proceedings, Graz, Austria, 13–16 May 2012; pp. 205–209. [Google Scholar] [CrossRef]
- Huang, W.; Li, Y.; Hu, F. Real-Time 6-DOF Monocular Visual SLAM based on ORB-SLAM2. In Proceedings of the 2019 Chinese Control Furthermore, Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 2929–2932. [Google Scholar] [CrossRef]
- Zhang, L.; Li, Y.; Zhao, Y.; Sun, Q.; Zhao, Y. High Precision Monocular Plane Measurement for Large Field of View. In Proceedings of the 2018 IEEE 8th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Tianjin, China, 19–23 July 2018; pp. 1388–1392. [Google Scholar] [CrossRef]
- Kiran, A.G.; Murali, S. Automatic rectification of perspective distortion from a single image using plane homography. Int. J. Comput. Sci. Appl. 2013, 3, 47–58. [Google Scholar] [CrossRef] [Green Version]
- Bishop, G.; Welch, G. An introduction to the Kalman filter. SIGGRAPH Course 2001, 41, 27599-23175. [Google Scholar]
- Almagbile, A.; Wang, J.; Ding, W. Evaluating the Performances of Adaptive Kalman Filter Methods in GPS/INS Integration. J. Glob. Position. Syst. 2010, 9, 33–40. [Google Scholar] [CrossRef] [Green Version]
- Sinha, A.; Ding, Z.; Kirubarajan, T.; Farooq, M. Track Quality Based Multitarget Tracking Approach for Global Nearest-Neighbor Association. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 1179–1191. [Google Scholar] [CrossRef]
- Dezert, J.; Benameur, K. On the Quality of Optimal Assignment for Data Association. In Belief Functions: Theory and Applications; Cuzzolin, F., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 374–382. [Google Scholar] [CrossRef] [Green Version]
- Al-Shakarji, N.M.; Bunyak, F.; Seetharaman, G.; Palaniappan, K. Multi-object Tracking Cascade with Multi-Step Data Association and Occlusion Handling. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Fleuret, F.; Berclaz, J.; Lengagne, R.; Fua, P. Multicamera People Tracking with a Probabilistic Occupancy Map. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 267–282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chavdarova, T.; Baqué, P.; Bouquet, S.; Maksai, A.; Jose, C.; Bagautdinov, T.; Lettry, L.; Fua, P.; Van Gool, L.; Fleuret, F. WILDTRACK: A Multi-camera HD Dataset for Dense Unscripted Pedestrian Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5030–5039. [Google Scholar] [CrossRef]
- Benfold, B.; Reid, I. Stable multi-target tracking in real-time surveillance video. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3457–3464. [Google Scholar] [CrossRef]
- Bull, A.D. Convergence Rates of Efficient Global Optimization Algorithms. J. Mach. Learn. Res. 2011, 12, 2879–2904. [Google Scholar]
- Osokin, D. Real-time 2D Multi-Person Pose Estimation on CPU: Lightweight OpenPose. arXiv 2018, arXiv:1811.12004. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Parameters | |||||
|---|---|---|---|---|---|---|
| 6p-c0 | 6 | 0.204 | 2.01 | 398 | 76 | −186 |
| 6p-c1 | 8.21 | 0.329 | 8.78 | 399 | 64 | −71 |
| 6p-c2 | 0.216 | 0.278 | 0.271 | 52 | 52 | −84 |
| 6p-c3 | 7 | 0.015 | 1.76 | 104 | 86 | −106 |
| OxTown | 2 | 0.873 | 0.142 | 23 | 11 | −26 |
| C1 | 7 | 6 | 2 | 11 | 1 | −92 |
| C2 | 0.002 | 1.46 | 12 | 8 | −181 | |
| C3 | 0.02 | 0.0078 | 6 | 139 | 2 | −5 |
| C4 | 429 | 0.022 | 0.062 | 81 | 3 | −2 |
| C5 | 2.05 | 3.79 | 15 | 3 | −41 | |
| C6 | 9 | 4 | 15 | 9 | −106 | |
| C7 | 5 | 0.0006 | 4 | 395 | 1 | −2 |
| Measure | Approach | S/T | EPFL-MPV | OxTown | EPFL-Wildtrack | Overall | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6p-c0 | 6p-c1 | 6p-c2 | 6p-c3 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | |||||
| PDR | Basic [26] | - | 90.9 | 90.7 | 87.5 | 87.3 | 85.7 | 59.2 | 56.6 | 74.2 | 87.3 | 78.2 | (39.9) | 91.3 | 85.4 |
| Proposed | ✕ | 93.8 | 94.0 | 89.1 | 88.1 | 88.4 | 64.7 | 62.6 | 79.1 | 88.5 | 80.8 | 43.5 | 92.5 | 87.9 | |
| ✓ | 95.6 | 96.5 | 91.9 | 90.8 | 89.8 | 84.4 | 83.4 | 79.2 | 88.5 | 83.9 | (82.9) | 92.6 | 91.5 | ||
| Error | Basic [26] | - | 17.0 | 17.2 | 23.0 | 21.9 | 24.0 | 51.3 | 52.8 | 49.0 | 41.3 | 33.8 | (80.4) | 15.4 | 24.7 |
| Proposed | ✕ | 12.6 | 13.2 | 20.7 | 20.6 | 20.8 | 47.0 | 47.1 | 49.8 | 39.8 | 30.9 | 76.1 | 14.3 | 21.7 | |
| ✓ | 10.7 | 10.7 | 16.6 | 17.8 | 19.1 | 31.9 | 36.7 | 48.3 | 36.3 | 27.0 | (42.0) | 14.0 | 18.0 | ||
| Accuracy | Basic [26] | - | 91.0 | 89.2 | 83.3 | 85.6 | 92.8 | 95.5 | 97.7 | 92.5 | 88.0 | 92.3 | (82.7) | 97.0 | 89.3 |
| Proposed | ✕ | 94.1 | 92.7 | 86.5 | 88.2 | 94.5 | 96.5 | 98.6 | 93.5 | 88.5 | 93.0 | 87.0 | 96.9 | 91.8 | |
| ✓ | 94.9 | 94.6 | 88.2 | 89.8 | 95.6 | 99.4 | 99.7 | 93.5 | 88.1 | 92.7 | (99.7) | 96.9 | 93.3 | ||
| F1-score | Basic [26] | - | 90.7 | 89.1 | 80.7 | 83.8 | 95.9 | 97.7 | 98.8 | 95.9 | 79.2 | 95.7 | (90.2) | 98.1 | 89.5 |
| Proposed | ✕ | 94.4 | 92.9 | 85.0 | 87.5 | 96.9 | 98.2 | 99.3 | 96.5 | 81.2 | 96.0 | 92.9 | 98.1 | 92.3 | |
| ✓ | 95.2 | 94.9 | 87.0 | 89.5 | 97.5 | 99.7 | 99.8 | 96.5 | 80.0 | 95.9 | (99.8) | 98.1 | 93.6 | ||
| Precision | Basic [26] | - | 98.2 | 98.1 | 98.4 | 95.6 | 97.4 | 100 | 100 | 98.7 | 88.8 | 100 | 100 | 99.0 | 97.6 |
| Proposed | ✕ | 96.0 | 97.4 | 96.8 | 93.4 | 97.2 | 100 | 100 | 97.4 | 85.0 | 99.8 | 100 | 98.6 | 96.4 | |
| ✓ | 95.7 | 97.0 | 96.4 | 91.7 | 97.0 | 100 | 100 | 97.4 | 86.4 | 98.2 | 100 | 98.6 | 95.9 | ||
| Recall | Basic [26] | - | 84.8 | 82.6 | 69.5 | 75.4 | 94.4 | 95.5 | 97.7 | 93.5 | 71.6 | 91.7 | (82.7) | 97.3 | 83.7 |
| Proposed | ✕ | 92.8 | 89.3 | 76.5 | 82.6 | 96.6 | 96.5 | 98.6 | 95.8 | 77.9 | 92.6 | 86.9 | 97.6 | 89.0 | |
| ✓ | 94.6 | 93.0 | 79.8 | 87.5 | 98.1 | 99.4 | 99.7 | 95.7 | 74.7 | 93.7 | (99.7) | 97.6 | 91.8 | ||
| VCR | Basic [26] | - | 81.3 | 78.5 | 78.1 | 78.7 | 64.8 | 33.5 | 36.5 | 46.1 | 86.7 | 72.6 | (20.9) | 86.8 | 72.2 |
| Proposed | ✕ | 84.3 | 83.7 | 80.1 | 80.1 | 67.6 | 38.4 | 43.1 | 48.3 | 85.9 | 75.9 | 26.0 | 89.7 | 75.1 | |
| ✓ | 86.0 | 86.6 | 81.4 | 79.6 | 65.1 | 62.5 | 63.2 | 47.5 | 86.5 | 73.3 | (59.8) | 89.7 | 77.0 | ||
| CORR | Basic [26] | - | 98.3 | 99.1 | 98.9 | 98.9 | (85.3) | 89.1 | 73.4 | 85.8 | 96.4 | 88.2 | 72.3 | 98.8 | 93.8 |
| Proposed | ✕ | 99.2 | 99.4 | 99.2 | 99.3 | 89.4 | 90.0 | 72.5 | 86.0 | 96.8 | 90.7 | 72.3 | 98.6 | 95.1 | |
| ✓ | 99.4 | 99.2 | 99.2 | 99.2 | (89.9) | 89.3 | 77.3 | 86.3 | 97.1 | 91.1 | 72.8 | 98.6 | 95.3 | ||
| IOU | Basic [26] | - | (74.7) | 86.2 | 84.1 | 84.0 | 52.2 | 51.8 | 47.1 | 63.8 | 61.9 | 44.7 | 13.9 | 83.8 | 70.8 |
| Proposed | ✕ | 83.4 | 89.6 | 85.3 | 86.1 | 61.0 | 55.7 | 51.3 | 61.5 | 66.9 | 47.3 | 14.4 | 83.4 | 75.6 | |
| ✓ | (87.1) | 89.2 | 86.3 | 85.7 | 63.8 | 55.3 | 55.2 | 61.6 | 68.2 | 50.7 | 22.3 | 83.4 | 77.1 | ||
| Method | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| Yang et al. [15] | (92.8) | (95.6) | 95.4 | 95.9 |
| Basic [26] | 96.0 | 97.9 | 98.9 | 96.8 |
| Proposed, S/T: ✕ | (97.4) | (98.6) | 98.8 | 98.4 |
| Proposed, S/T: ✓ | (98.3) | (99.1) | 98.7 | 99.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Sa’d, M.; Kiranyaz, S.; Ahmad, I.; Sundell, C.; Vakkuri, M.; Gabbouj, M. A Social Distance Estimation and Crowd Monitoring System for Surveillance Cameras. Sensors 2022, 22, 418. https://doi.org/10.3390/s22020418
Al-Sa’d M, Kiranyaz S, Ahmad I, Sundell C, Vakkuri M, Gabbouj M. A Social Distance Estimation and Crowd Monitoring System for Surveillance Cameras. Sensors. 2022; 22(2):418. https://doi.org/10.3390/s22020418
Chicago/Turabian StyleAl-Sa’d, Mohammad, Serkan Kiranyaz, Iftikhar Ahmad, Christian Sundell, Matti Vakkuri, and Moncef Gabbouj. 2022. "A Social Distance Estimation and Crowd Monitoring System for Surveillance Cameras" Sensors 22, no. 2: 418. https://doi.org/10.3390/s22020418