
Memory Visualization-Based Malware Detection Technique


Abstract
:1. Introduction
1.1. Background
1.2. Problem Statement
1.3. Objectives and Contribution
- We examine various image noises, including Gaussian, Salt Pepper, Poisson, and Speckle, and apply various filtering techniques to minimize the distortion in these images.
- We present a technique using discrete wavelet transform to compress the malware images to reduce the irrelevant and redundant data in the images, without compromising important information.
- We present various machine learning classifiers and experiments with their appropriate hyperparameters to tune them to obtain a significant result.
1.4. Paper Structure
2. Related Work
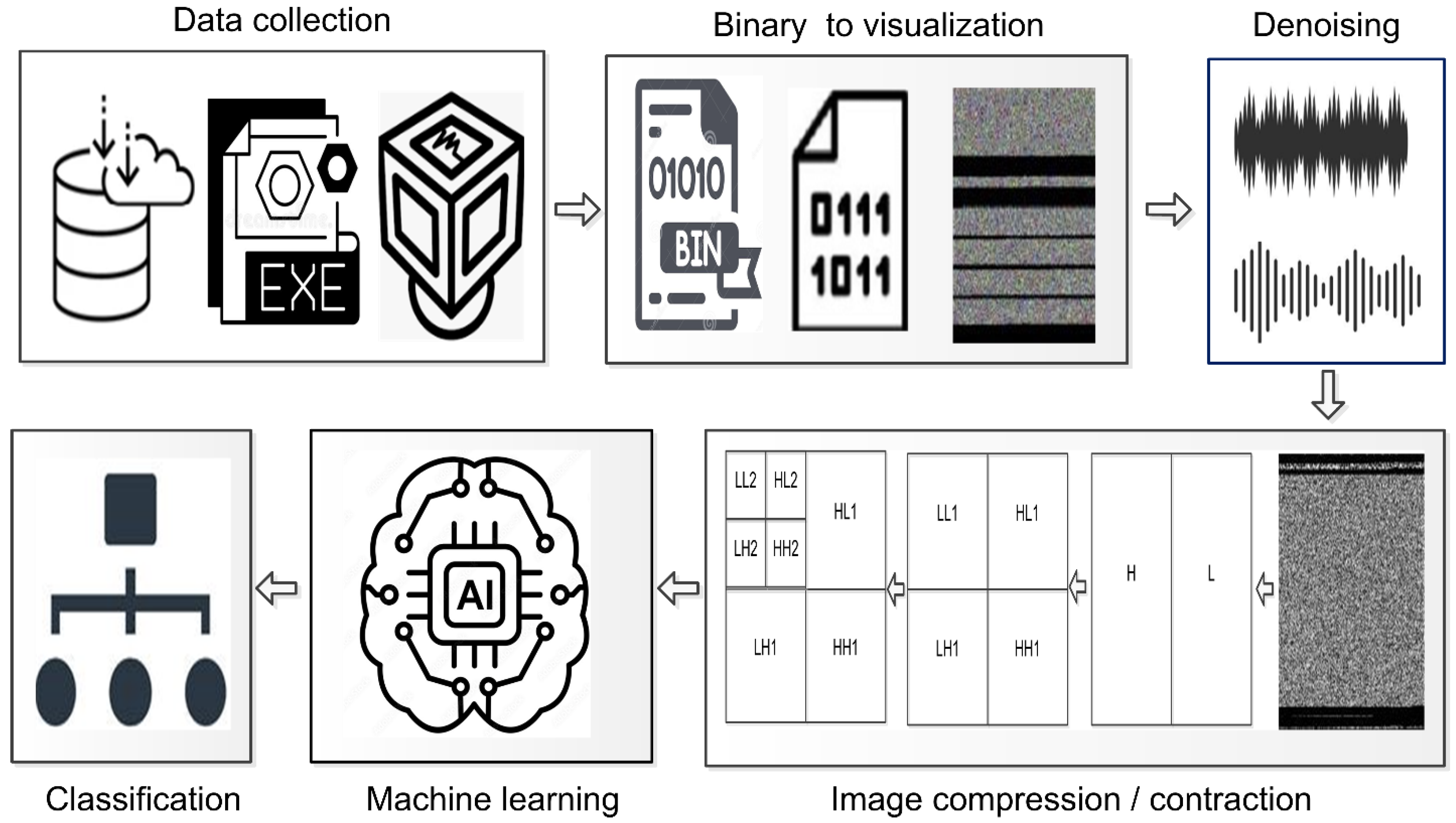
3. Methodology
3.1. Data Collection
- Adware
- Worm
- Trojan
- Virus
3.2. Binary to Visualization

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | File Range | Dimensions |
|---|---|---|
| 1 | File_size < 10,240 | 32 |
| 2 | 10,240 <= File_size <= 10,240 * 3 | 64 |
| 3 | 10,240 * 3 <= File_size <= 10,240 * 6 | 128 |
| 4 | 10,240 * 6 <= File_size <= 10,240 * 10 | 256 |
| 5 | 10,240 * 10 <= File_size <= 10,240 * 20 | 384 |
| 6 | 10,240 * 20 <= File_size <= 10,240 * 50 | 512 |
| 7 | 10,240 * 50 <= File_size <= 10,240 * 100 | 786 |
| 8 | Else | 1024 |
| Algorithm 1: Transformation algorithm for dumping (binary) files to RGB images | |
| Input: A path to a dataset of memory dump files | |
| Output: Transformation of RGB images with various dimensionality | |
| Start Set B a list of memory dump files Set width None Set height None Set data an empty list [ ] For i in length(B) where i integer numbers range from 0 to n. If file_size of B[i] < 10,240 width = 32 If 10,240 <= file_size of B[i] <= 10,240 * 3 width = 64 If 10,240 * 3 <= file_size of B[i] <= 10,240 * 6 width = 128 If 10,240 * 6 <= file_size of B[i] <= 10,240 * 10 width = 256 If 10,240 * 10 <= file_size of B[i] <= 10,240 * 20 width = 384 If 10,240 * 20 <= file_size of B[i] <= 10,240 * 50 width = 512 If 10,240 * 50 <= file_size of B[i] <= 10,240 * 100 width = 786 Else width = 1024 End If height = (file_size/width)/+1 image = Width × height image.save[‘PNG’] data.append[image] End For End | |
3.3. Denoising
- Gaussian Noise
- Salt-and-Pepper Noise
- Speckle Noise
- Poisson Noise
- Contrast Limited Adaptive Histogram Equalization (CLAHE)
- Bilateral Filter
- Wiener Filter
- Gaussian Filter
- Total variation
- Non-Local Means Denoising
| Algorithm 2: Transformation algorithm for the grayscale image to remove noise | |
| Input: A path to a dataset image | |
| Output: A set of denoised images | |
| Start Set data an empty list [ ] For I in image data where i integer numbers range from 0 to n. For each pixel of a single image Calculate Normalization function (11) Evaluate weighted function Equation (12) Calculate non-local means Equation (10) data.append[denoised image] End For End For End | |
3.4. Image Compression/Contraction
3.5. Machine Learning
3.6. Evaluation Metrics
- Peak Signal-to-Noise Ratio (PSNR)
- Universal Image Quality Index (UQI)
- Accuracy
- Precision
- Recall
- F1-score
- Computational cost
- Memory Utilization
4. Experiment, Result, and Findings


5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shafique, A.; Mehmood, A.; Alawida, M.; Khan, A.N.; Khan, A.U.R. A Novel Machine Learning Technique for Selecting Suitable Image Encryption Algorithms for IoT Applications. Wirel. Commun. Mob. Comput. 2022, 2022, 5108331. [Google Scholar] [CrossRef]
- Aslan, Ö.A.; Samet, R. A comprehensive review on malware detection approaches. IEEE Access 2020, 8, 6249–6271. [Google Scholar] [CrossRef]
- Harter, G.T.; Rowe, N.C. Testing Detection of K-Ary Code Obfuscated by Metamorphic and Polymorphic Techniques. In National Cyber Summit; Springer: Cham, Switzerland, 2021; pp. 110–123. [Google Scholar]
- Indusface. New Malware Report. Available online: https://www.indusface.com/blog/15-malware-statistics-to-take-seriously-in-2022/#_ednref1 (accessed on 10 June 2022).
- AV-TEST. Malware Development. Available online: https://www.av-test.org/en/statistics/malware/ (accessed on 12 June 2022).
- Abbas, S.; Faisal, M.; Rahman, H.U.; Khan, M.Z.; Merabti, M.J.I.A. Masquerading attacks detection in mobile ad hoc networks. IEEE Access 2018, 6, 55013–55025. [Google Scholar] [CrossRef]
- SecureList. Mobile Malware Report. Available online: https://securelist.com/it-threat-evolution-in-q1-2022-mobile-statistics/106589/ (accessed on 10 June 2022).
- Kaspersky. Malware Attack on PC. Available online: https://securelist.com/it-threat-evolution-in-q1-2022-non-mobile-statistics/106531/ (accessed on 15 June 2022).
- Or-Meir, O.; Nissim, N.; Elovici, Y.; Rokach, L. Dynamic malware analysis in the modern era—A state of the art survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–48. [Google Scholar] [CrossRef] [Green Version]
- Sihwail, R.; Omar, K.; Ariffin, K.Z. A survey on malware analysis techniques: Static, dynamic, hybrid and memory analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1662–1671. [Google Scholar] [CrossRef] [Green Version]
- Damodaran, A.; Troia, F.D.; Visaggio, C.A.; Austin, T.H.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2015, 13, 1–12. [Google Scholar] [CrossRef]
- Nataraj, L.; Karthikeyan, S.; Jacob, G.; Manjunath, B.S. Malware images: Visualization and automatic classification. In Proceedings of the 8th International Symposium on Visualization for Cyber Security, Pittsburgh, PA, USA, 28 October 2020; pp. 1–7. [Google Scholar]
- Bozkir, A.S.; Tahillioglu, E.; Aydos, M.; Kara, I. Catch them alive: A malware detection approach through memory forensics, manifold learning and computer vision. Comput. Secur. 2021, 103, 102166. [Google Scholar] [CrossRef]
- Willems, C.; Holz, T.; Freiling, F. Toward automated dynamic malware analysis using cwsandbox. Secur. Priv. 2007, 5, 32–39. [Google Scholar] [CrossRef]
- Shijo, P.; Salim, A.J.P.C.S. Integrated static and dynamic analysis for malware detection. Procedia Comput. Sci. 2015, 46, 804–811. [Google Scholar] [CrossRef] [Green Version]
- Sihwail, R.; Omar, K.; Zainol Ariffin, K.A.; Al Afghani, S. Malware detection approach based on artifacts in memory image and dynamic analysis. Appl. Sci. 2019, 9, 3680. [Google Scholar] [CrossRef]
- Russo, F. A method for estimation and filtering of Gaussian noise in images. IEEE Trans. Instrum. Meas. 2003, 52, 1148–1154. [Google Scholar] [CrossRef]
- Pimpalkhute, V.A.; Page, R.; Kothari, A.; Bhurchandi, K.M.; Kamble, V.M. Digital image noise estimation using DWT coefficients. IEEE Trans. Image Process. 2021, 30, 1962–1972. [Google Scholar] [CrossRef] [PubMed]
- Kollem, S.; Reddy, K.R.L.; Rao, D.S. A review of image denoising and segmentation methods based on medical images. Int. J. Mach. Learn. Comput. 2019, 9, 288–295. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, K.; Khan, J.; Iqbal, M.S.U.D. A comparative study of different denoising techniques in digital image processing. In Proceedings of the 2019 8th International Conference on Modeling Simulation and Applied Optimization (ICMSAO), Manama, Bahrain, 15–17 April 2019; pp. 1–6. [Google Scholar]
- Hashemi, H.; Hamzeh, A. Visual malware detection using local malicious pattern. J. Comput. Virol. Hacking Tech. 2019, 15, 1–14. [Google Scholar] [CrossRef]
- Kolosnjaji, B.; Demontis, A.; Biggio, B.; Maiorca, D.; Giacinto, G.; Eckert, C.; Roli, F. Adversarial malware binaries: Evading deep learning for malware detection in executables. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 533–537. [Google Scholar]
- Salehi, Z.; Sami, A.; Ghiasi, M. Using feature generation from API calls for malware detection. Comput. Fraud Secur. 2014, 2014, 9–18. [Google Scholar]
- Veeramani, R.; Rai, N. Windows api based malware detection and framework analysis. In Proceedings of the International Conference on Networks and Cyber Security, Alexandria, VA, USA, 14–16 December 2012. [Google Scholar]
- Christodorescu, M.; Jha, S.; Kinder, J.; Katzenbeisser, S.; Veith, H. Software transformations to improve malware detection. J. Comput. Virol. 2007, 3, 253–265. [Google Scholar]
- Oyama, Y. Trends of anti-analysis operations of malwares observed in API call logs. J. Comput. Virol. Hacking Tech. 2018, 14, 69–85. [Google Scholar] [CrossRef] [Green Version]
- Mehmood, A.; Khan, A.N.; Elhadef, M. HeuCrip: A malware detection approach for internet of battlefield things. Clust. Comput. 2022, 1–16. [Google Scholar]
- Cheng, Y.; Fan, W.; Huang, W.; An, J. A shellcode detection method based on full native api sequence and support vector machine. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Birmingham, UK, 13–15 October 2017; IOP Publishing: Bristol, UK; p. 012124. [Google Scholar]
- Bayer, U.; Kirda, E.; Kruegel, C. Improving the efficiency of dynamic malware analysis. In Proceedings of the 2010 ACM Symposium on Applied Computing, Sierre, Switzerland, 22–26 March 2010; pp. 1871–1878. [Google Scholar]
- Udayakumar, N.; Anandaselvi, S.; Subbulakshmi, T. Dynamic malware analysis using machine learning algorithm. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 795–800. [Google Scholar]
- Zhang, Z.; Qi, P.; Wang, W. Dynamic malware analysis with feature engineering and feature learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1210–1217. [Google Scholar]
- Jindal, C.; Salls, C.; Aghakhani, H.; Long, K.; Kruegel, C.; Vigna, G. Neurlux: Dynamic malware analysis without feature engineering. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 444–455. [Google Scholar]
- Ijaz, M.; Durad, M.H.; Ismail, M. Static and dynamic malware analysis using machine learning. In Proceedings of the 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 8–12 January 2019; pp. 687–691. [Google Scholar]
- Raghuraman, C.; Suresh, S.; Shivshankar, S.; Chapaneri, R. Static and dynamic malware analysis using machine learning. In Proceedings of the First International Conference on Sustainable Technologies for Computational Intelligence, Islamabad, Pakistan, 8–12 January 2019; Springer: Cham, Switzerland; pp. 793–806. [Google Scholar]
- Zhang, S.; Zhao, C.; Huang, B. Simultaneous static and dynamic analysis for fine-scale identification of process operation statuses. IEEE Trans. Ind. Inform. 2019, 15, 5320–5329. [Google Scholar]
- Shah, S.S.H.; Ahmad, A.R.; Jamil, N.; Khan, A.U.R. Memory Forensics-Based Malware Detection Using Computer Vision and Machine Learning. Electronics 2022, 11, 2579. [Google Scholar]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z. An effective memory analysis for malware detection and classification. Comput. Mater. Contin. 2021, 67, 2301–2320. [Google Scholar] [CrossRef]
- Dai, Y.; Li, H.; Qian, Y.; Lu, X. A malware classification method based on memory dump grayscale image. Digit. Investig. 2018, 27, 30–37. [Google Scholar] [CrossRef]
- Mosli, R.; Li, R.; Yuan, B.; Pan, Y. Automated malware detection using artifacts in forensic memory images. In Proceedings of the 2016 IEEE Symposium on Technologies for Homeland Security (HST), Waltham, MA, USA, 10–12 May 2016; pp. 1–6. [Google Scholar]
- Rathnayaka, C.; Jamdagni, A. An efficient approach for advanced malware analysis using memory forensic technique. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, Australia, 1–4 August 2017; pp. 1145–1150. [Google Scholar]
- Teller, T.; Hayon, A. Enhancing Automated Malware Analysis Machines with Memory Analysis; Black Hat: Las Vegas, NV, USA, 2014. [Google Scholar]
- Nissim, N.; Lahav, O.; Cohen, A.; Elovici, Y.; Rokach, L. Volatile memory analysis using the MinHash method for efficient and secured detection of malware in private cloud. Comput. Secur. 2019, 87, 101590. [Google Scholar] [CrossRef]
- Tien, C.-W.; Liao, J.-W.; Chang, S.-C.; Kuo, S.-Y. Memory forensics using virtual machine introspection for Malware analysis. In Proceedings of the 2017 IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7–10 August 2017; pp. 518–519. [Google Scholar]
- Choi, S.; Jang, S.; Kim, Y.; Kim, J. Malware detection using malware image and deep learning. In Proceedings of the 2017 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 18–20 October 2017; pp. 1193–1195. [Google Scholar]
- Davies, S.R.; Macfarlane, R.; Buchanan, W.J. Evaluation of live forensic techniques in ransomware attack mitigation. Forensic Sci. Int. Digit. Investig. 2020, 33, 300979. [Google Scholar] [CrossRef]
- Kumara, M.A.; Jaidhar, C.D. Leveraging virtual machine introspection with memory forensics to detect and characterize unknown malware using machine learning techniques at hypervisor. Digit. Investig. 2017, 23, 99–123. [Google Scholar] [CrossRef]
- Sali, V.R.; Khanuja, H. Ram forensics: The analysis and extraction of malicious processes from memory image using gui based memory forensic toolkit. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Tekerek, A.; Yapici, M.M. A novel malware classification and augmentation model based on convolutional neural network. Comput. Secur. 2022, 112, 102515. [Google Scholar] [CrossRef]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.; Wang, Y.; Iqbal, F. Malware classification with deep convolutional neural networks. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- Hemalatha, J.; Roseline, S.A.; Geetha, S.; Kadry, S.; Damaševičius, R. An efficient densenet-based deep learning model for malware detection. Entropy 2021, 23, 344. [Google Scholar] [CrossRef]
- Aslan, Ö.; Yilmaz, A.A. A new malware classification framework based on deep learning algorithms. IEEE Access 2021, 9, 87936–87951. [Google Scholar] [CrossRef]
- Dumpware10. Memory Based Malware Dataset. Available online: https://web.cs.hacettepe.edu.tr/~selman/dumpware10/ (accessed on 20 March 2022).
- Norton. Adware. Available online: https://us.norton.com/internetsecurity-emerging-threats-what-is-grayware-adware-and-madware.html (accessed on 15 June 2022).
- Github. bin2png Version. Available online: https://github.com/ESultanik/bin2png (accessed on 10 November 2021).
- Garnett, R.; Huegerich, T.; Chui, C.; He, W. A universal noise removal algorithm with an impulse detector. IEEE Trans. Image Process. 2005, 14, 1747–1754. [Google Scholar] [CrossRef] [Green Version]
- Kumain, S.C.; Singh, M.; Singh, N.; Kumar, K. An efficient Gaussian noise reduction technique for noisy images using optimized filter approach. In Proceedings of the 2018 First International Conference on Secure Cyber Computing and Communication (ICSCCC), Jalandhar, India, 15–17 December 2018; pp. 243–248. [Google Scholar]
- Azzeh, J.; Zahran, B.; Alqadi, Z. Salt and pepper noise: Effects and removal. JOIV Int. J. Inform. Vis. 2018, 2, 252–256. [Google Scholar] [CrossRef] [Green Version]
- Duarte-Salazar, C.A.; Castro-Ospina, A.E.; Becerra, M.A.; Delgado-Trejos, E. Speckle noise reduction in ultrasound images for improving the metrological evaluation of biomedical applications: An overview. IEEE Access 2020, 8, 15983–15999. [Google Scholar] [CrossRef]
- Rezende, E.; Ruppert, G.; Carvalho, T.; Theophilo, A.; Ramos, F.; Geus, P.D. Malicious software classification using VGG16 deep neural network’s bottleneck features. In Information Technology-New Generations; Springer: Cham, Switzerland, 2018; pp. 51–59. [Google Scholar]













| Category | Classes | Quantity |
|---|---|---|
| Adware | Adposhel | 457 |
| Worm | Allaple.A | 437 |
| Adware | Amonetize | 436 |
| Worm | AutoRun-PU | 196 |
| Adware | BrowseFox | 190 |
| Trojan | Dinwod!rfn | 127 |
| Adware | InstallCore.C | 467 |
| Adware | MultiPlug | 488 |
| Trojan | Vilsel | 389 |
| Virus | VBA | 499 |
| Benign | -- | 608 |
| Parameters | Values |
|---|---|
| Operating System | Windows 7 Professional—64 bit |
| RAM | 32 |
| Processor | 2.40 GHz |
| Hard Drive | 512 SSD |
| Noise Type | CLAHE Parameters | Evaluation Metrics | ||||
|---|---|---|---|---|---|---|
| tileGridSize | clipLimit | MSE | PSNR | SSIM | UQI | |
| Gaussian | (1,1) | 0.001 | 0.7203 | 49.55 | 0.9996, 0.9999 | 0.9994 |
| 0.01 | 0.7203 | 49.55 | 0.9996, 0.9999 | 0.9994 | ||
| 0.05 | 0.7251 | 49.52 | 0.9996, 0.9996 | 0.9994 | ||
| 0.1 | 0.9854 | 48.19 | 0.9996, 0.9996 | 0.9993 | ||
| 0.2 | 3.4 | 42.8 | 0.9994, 0.9999 | 0.9991 | ||
| 0.5 | 59.93 | 30.35 | 0.9994, 0.9981 | 0.9937 | ||
| (2,2) | 0.001 | 0.732 | 49.48 | 0.9996, 0.9996 | 0.9993 | |
| 0.01 | 0.732 | 49.48 | 0.9996, 0.9999 | 0.9993 | ||
| 0.05 | 0.7673 | 49.28 | 0.9996, 0.9999 | 0.9993 | ||
| 0.1 | 0.9815 | 48.21 | 0.9996, 0.9999 | 0.9993 | ||
| 0.2 | 3.9 | 42.21 | 0.9992, 0.9999 | 0.9989 | ||
| 0.5 | 56.26 | 30.62 | 0.9946, 0.9981 | 0.9935 | ||
| Salt-and-Pepper | (1,1) | 0.001 | 0.7063 | 49.64 | 0.99924, 0.9999 | 0.9924 |
| 0.01 | 0.7063 | 49.64 | 0.99924, 0.9999 | 0.9924 | ||
| 0.05 | 0.8246 | 48.96 | 0.9992, 0.9999 | 0.9923 | ||
| 0.1 | 0.973 | 48.24 | 0.9992, 0.9999 | 0.9923 | ||
| 0.2 | 5.08 | 41.07 | 0.9998, 0.9999 | 0.9919 | ||
| 0.5 | 48.52 | 31.27 | 0.9995, 0.9984 | 0.9886 | ||
| (2,2) | 0.001 | 0.8209 | 48.98 | 0.9992, 0.9999 | 0.9923 | |
| 0.01 | 0.8209 | 48.98 | 0.9992, 0.9999 | 0.9923 | ||
| 0.05 | 0.9708 | 48.25 | 0.9992, 0.9999 | 0.9923 | ||
| 0.1 | 2.6 | 43.96 | 0.9991, 0.9999 | 0.9922 | ||
| 0.2 | 5.95 | 40.38 | 0.9988, 0.9998 | 0.9918 | ||
| 0.5 | 47.87 | 31.32 | 0.99954, 0.9983 | 0.9884 | ||
| Poisson | (1,1) | 0.001 | 0.7347 | 49.46 | 0.9951, 0.9999 | 0.9559 |
| 0.01 | 0.7347 | 49.46 | 0.9951, 0.9999 | 0.9559 | ||
| 0.05 | 0.7873 | 49.16 | 0.9951, 0.9999 | 0.9559 | ||
| 0.1 | 0.9971 | 48.14 | 0.9951, 0.9999 | 0.9559 | ||
| 0.2 | 5.44 | 40.77 | 0.9947, 0.9998 | 0.9554 | ||
| 0.5 | 70.63 | 29.64 | 0.9893, 0.9977 | 0.9495 | ||
| (2,2) | 0.001 | 0.7755 | 49.23 | 0.9951, 0.9999 | 0.9559 | |
| 0.01 | 0.7755 | 49.23 | 0.9951, 0.9999 | 0.9559 | ||
| 0.05 | 0.8904 | 48.63 | 0.9951, 0.9999 | 0.9559 | ||
| 0.1 | 0.9954 | 48.15 | 0.9951, 0.9999 | 0.9559 | ||
| 0.2 | 6.63 | 39.91 | 0.9946, 0.998 | 0.9552 | ||
| 0.5 | 65.25 | 29.98 | 0.9893, 0.9976 | 0.9497 | ||
| Speckle | (1,1) | 0.001 | 0.737 | 49.45 | 0.9951, 0.9999 | 0.956 |
| 0.01 | 0.737 | 49.45 | 0.9951, 0.9999 | 0.956 | ||
| 0.05 | 0.7849 | 49.18 | 0.9951, 0.9999 | 0.956 | ||
| 0.1 | 0.9956 | 48.14 | 0.9951, 0.9999 | 0.9559 | ||
| 0.2 | 4.64 | 41.46 | 0.9948, 0.9999 | 0.9555 | ||
| 0.5 | 69.83 | 29.68 | 0.9894, 0.9977 | 0.9497 | ||
| (2,2) | 0.001 | 0.7608 | 49.31 | 0.9951, 0.9999 | 0.956 | |
| 0.01 | 0.7608 | 49.31 | 0.9951, 0.9999 | 0.956 | ||
| 0.05 | 0.84 | 48.88 | 0.9951, 0.9999 | 0.956 | ||
| 0.1 | 0.9947 | 48.15 | 0.9951, 0.9999 | 0.9559 | ||
| 0.2 | 6.58 | 39.94 | 0.9946, 0.9998 | 0.9553 | ||
| 0.5 | 66.35 | 29.91 | 0.9892, 0.9975 | 0.9496 | ||
| Noise Type | Bilateral Filter Parameters | Evaluation Metrics | ||||
|---|---|---|---|---|---|---|
| Dimension | SigmaColor | SigmaSpace | MSE | PSNR | UQI | |
| Gaussian | 5 | 35 | 10 | 167.54 | 25.88 | 0.9674 |
| 50 | 168.02 | 25.87 | 0.9676 | |||
| 150 | 169.54 | 25.83 | 0.9686 | |||
| 50 | 10 | 370.48 | 22.42 | 0.9489 | ||
| 50 | 372.8 | 22.41 | 0.9492 | |||
| 150 | 373.33 | 22.4 | 0.9489 | |||
| 25 | 35 | 10 | 199.57 | 25.12 | 0.9603 | |
| 50 | 202.14 | 25.07 | 0.9595 | |||
| 150 | 203.41 | 25.04 | 0.9597 | |||
| 50 | 10 | 480.9 | 21.31 | 0.9331 | ||
| 50 | 484.81 | 21.27 | 0.9316 | |||
| 150 | 487.43 | 21.25 | 0.9313 | |||
| 55 | 5 | 10 | 0.7149 | 49.58 | 0.9996 | |
| 15 | 0.9597 | 49.93 | 0.9997 | |||
| 150 | 0.6559 | 49.96 | 0.9997 | |||
| 15 | 10 | 15.19 | 36.31 | 0.9942 | ||
| 50 | 15.35 | 36.26 | 0.9942 | |||
| 150 | 15.28 | 36.28 | 0.9942 | |||
| 65 | 5 | 10 | 0.7075 | 49.63 | 0.9996 | |
| 50 | 0.62 | 50.2 | 0.9997 | |||
| 150 | 0.6314 | 50.09 | 0.9996 | |||
| 15 | 10 | 15.31 | 36.28 | 0.9938 | ||
| 50 | 14.96 | 36.38 | 0.9944 | |||
| 150 | 15.05 | 36.35 | 0.9943 | |||
| Salt-and-Pepper | 5 | 35 | 10 | 141.64 | 26.61 | 0.9872 |
| 50 | 142.28 | 26.59 | 0.9884 | |||
| 150 | 142.19 | 26.6 | 0.9867 | |||
| 50 | 10 | 324.8 | 23.01 | 0.979 | ||
| 50 | 325.15 | 23 | 0.9785 | |||
| 150 | 326.47 | 22.99 | 0.9784 | |||
| 25 | 35 | 10 | 186.26 | 25.42 | 0.9747 | |
| 50 | 187.44 | 25.4 | 0.974 | |||
| 150 | 189.34 | 25.35 | 0.9683 | |||
| 50 | 10 | 475.98 | 21.35 | 0.9543 | ||
| 50 | 482.74 | 21.29 | 0.9501 | |||
| 150 | 481.88 | 21.3 | 0.9526 | |||
| 55 | 5 | 10 | 0.8669 | 48.75 | 0.9997 | |
| 15 | 0.8613 | 48.77 | 0.9996 | |||
| 150 | 0.8903 | 48.63 | 0.9995 | |||
| 15 | 10 | 13.91 | 36.69 | 0.9907 | ||
| 50 | 13.86 | 36.71 | 0.9919 | |||
| 150 | 13.92 | 36.69 | 0.9874 | |||
| 65 | 5 | 10 | 0.8757 | 48.7 | 0.9996 | |
| 50 | 0.8722 | 48.72 | 0.9997 | |||
| 150 | 0.8817 | 48.67 | 0.9997 | |||
| 15 | 10 | 13.65 | 36.77 | 0.991 | ||
| 50 | 13.56 | 36.8 | 0.9901 | |||
| 150 | 13.51 | 36.82 | 0.9888 | |||
| Poisson | 5 | 35 | 10 | 147.79 | 26.43 | 0.967 |
| 50 | 148.47 | 26.41 | 0.967 | |||
| 150 | 148.5 | 26.41 | 0.967 | |||
| 50 | 10 | 325.2 | 23 | 0.9511 | ||
| 50 | 326.27 | 22.99 | 0.951 | |||
| 150 | 326.32 | 22.99 | 0.951 | |||
| 25 | 35 | 10 | 193.73 | 26.25 | 0.9224 | |
| 50 | 167.22 | 25.18 | 0.9209 | |||
| 150 | 197.36 | 25.17 | 0.9203 | |||
| 50 | 10 | 464.03 | 21.46 | 0.8926 | ||
| 50 | 471.63 | 21.39 | 0.8907 | |||
| 150 | 471.92 | 21.39 | 0.8906 | |||
| 55 | 5 | 10 | 0.7635 | 49.3 | 0.999 | |
| 15 | 0.755 | 49.35 | 0.999 | |||
| 150 | 0.7562 | 49.34 | 0.999 | |||
| 15 | 10 | 14.82 | 36.42 | 0.9522 | ||
| 50 | 15.21 | 36.3 | 0.9519 | |||
| 150 | 15.23 | 36.3 | 0.9519 | |||
| 65 | 5 | 10 | 0.7771 | 49.22 | 0.9988 | |
| 50 | 0.742 | 49.42 | 0.9988 | |||
| 150 | 0.7439 | 49.41 | 0.9988 | |||
| 15 | 10 | 14.87 | 36.4 | 0.9523 | ||
| 50 | 14.96 | 36.37 | 0.952 | |||
| 150 | 14.98 | 36.37 | 0.952 | |||
| Speckle | 5 | 35 | 10 | 147.73 | 26.43 | 0.9667 |
| 50 | 148.39 | 26.41 | 0.9667 | |||
| 150 | 148.41 | 26.41 | 0.9667 | |||
| 50 | 10 | 325.33 | 23 | 0.9512 | ||
| 50 | 326.48 | 22.99 | 0.9511 | |||
| 150 | 326.53 | 22.99 | 0.9511 | |||
| 25 | 35 | 10 | 196.71 | 25.19 | 0.9226 | |
| 50 | 200.32 | 25.11 | 0.9213 | |||
| 150 | 200.42 | 25.11 | 0.9212 | |||
| 50 | 10 | 471.37 | 21.39 | 0.8928 | ||
| 50 | 479.16 | 21.32 | 0.8909 | |||
| 150 | 479.43 | 21.32 | 0.8909 | |||
| 55 | 5 | 10 | 0.7767 | 49.22 | 0.9987 | |
| 15 | 0.7722 | 49.25 | 0.9987 | |||
| 150 | 0.7756 | 49.23 | 0.9987 | |||
| 15 | 10 | 15.05 | 36.35 | 0.9522 | ||
| 50 | 15.38 | 36.25 | 0.9519 | |||
| 150 | 15.4 | 36.25 | 0.9519 | |||
| 65 | 5 | 10 | 0.7925 | 49.14 | 0.9989 | |
| 50 | 0.7527 | 49.36 | 0.9989 | |||
| 150 | 0.7523 | 49.36 | 0.9989 | |||
| 15 | 10 | 14.9 | 36.39 | 0.9522 | ||
| 50 | 14.95 | 36.38 | 0.9519 | |||
| 150 | 14.19 | 36.37 | 0.9519 | |||
| Noise Type | TV Chambolle Parameters | Evaluation Metrics | |||
|---|---|---|---|---|---|
| Weight | eps | MSE | PSNR | UQI | |
| Gaussian | 0.1 | 0.0002 | 0.0174 | 65.7 | 0.8986 |
| 0.2 | 0.0002 | 0.0299 | 63.37 | 0.8409 | |
| 0.3 | 0.0002 | 0.03 | 63.35 | 0.84 | |
| 0.4 | 0.0002 | 0.034 | 62.8 | 0.8193 | |
| 0.5 | 0.0002 | 0.0358 | 62.8 | 0.8105 | |
| 0.6 | 0.0002 | 0.37 | 62.44 | 0.805 | |
| 0.7 | 0.0002 | 0.0377 | 62.35 | 0.0801 | |
| 0.8 | 0.0002 | 0.0382 | 62.3 | 0.7989 | |
| 0.9 | 0.0002 | 0.0385 | 62.27 | 0.7971 | |
| Salt-and-Pepper | 0.1 | 0.0002 | 0.017 | 65.82 | 0.9282 |
| 0.2 | 0.0002 | 0.0337 | 62.84 | 0.833 | |
| 0.3 | 0.0002 | 0.038 | 62.33 | 0.7879 | |
| 0.4 | 0.0002 | 0.0406 | 62.04 | 0.7692 | |
| 0.5 | 0.0002 | 0.0429 | 61.79 | 0.756 | |
| 0.6 | 0.0002 | 0.0443 | 61.66 | 0.7488 | |
| 0.7 | 0.0002 | 0.0452 | 61.57 | 0.7441 | |
| 0.8 | 0.0002 | 0.0457 | 61.52 | 0.7415 | |
| 0.9 | 0.0002 | 0.0461 | 61.48 | 0.7395 | |
| Speckle | 0.1 | 0.0002 | 0.0149 | 66.37 | 0.8784 |
| 0.2 | 0.0002 | 0.0254 | 64.07 | 0.8132 | |
| 0.3 | 0.0002 | 0.0256 | 64.04 | 0.814 | |
| 0.4 | 0.0002 | 0.0294 | 63.44 | 0.787 | |
| 0.5 | 0.0002 | 0.0312 | 63.18 | 0.7751 | |
| 0.6 | 0.0002 | 0.0326 | 62.99 | 0.766 | |
| 0.7 | 0.0002 | 0.0333 | 62.89 | 0.7609 | |
| 0.8 | 0.0002 | 0.0338 | 62.84 | 0.7579 | |
| 0.9 | 0.0002 | 0.034 | 62.8 | 0.7562 | |
| Poisson | 0.1 | 0.0002 | 0.0149 | 66.39 | 8777 |
| 0.2 | 0.0002 | 0.0217 | 64.75 | 0.8394 | |
| 0.3 | 0.0002 | 0.0252 | 64.1 | 0.815 | |
| 0.4 | 0.0002 | 0.029 | 63.49 | 0.7888 | |
| 0.5 | 0.0002 | 0.0308 | 63.23 | 0.7761 | |
| 0.6 | 0.0002 | 0.0322 | 63.04 | 0.767 | |
| 0.7 | 0.0002 | 0.0329 | 62.94 | 0.7619 | |
| 0.8 | 0.0002 | 0.0334 | 62.88 | 0.7589 | |
| 0.9 | 0.0002 | 0.0336 | 62.85 | 0.7572 | |
| Noise Type | Wiener Filter Parameters | Evaluation Metrics | ||
|---|---|---|---|---|
| Mysize | MSE | PSNR | UQI | |
| Gaussian | (5,5) | 0.0224 | 64.54 | 0.8669 |
| (7,7) | 0..0260 | 63.96 | 0.8411 | |
| (9,9) | 0.0278 | 63.68 | 0.8316 | |
| (11,11) | 0.0291 | 63.48 | 0.8248 | |
| (3,3) | 0.0171 | 65.78 | 0.902 | |
| (13,13) | 0.0301 | 63.34 | 0.8192 | |
| Salt-and-Pepper | (5,5) | 0.0279 | 63.66 | 0.841 |
| (7,7) | 0.0323 | 63.02 | 0.8026 | |
| (9,9) | 0.0348 | 62.7 | 0.7835 | |
| (11,11) | 0.0364 | 62.51 | 0.7735 | |
| (3,3) | 0.0187 | 65.4 | 0.9147 | |
| (13,13) | 0.0376 | 62.37 | 0.765 | |
| Speckle | (5,5) | 0.0187 | 65.39 | 0.8532 |
| (7,7) | 0.022 | 64.69 | 0.8107 | |
| (9,9) | 0.0237 | 64.38 | 0.7943 | |
| (11,11) | 0.025 | 64.15 | 0.7879 | |
| (3,3) | 0.0136 | 66.79 | 0.8879 | |
| (13,13) | 0.0259 | 63.98 | 0.7804 | |
| Poisson | (5,5) | 0.0186 | 65.42 | 8513 |
| (7,7) | 0.0218 | 64.72 | 0.8118 | |
| (9,9) | 0.0234 | 64.42 | 0.7984 | |
| (11,11) | 0.0247 | 64.19 | 0.7884 | |
| (3,3) | 0.0135 | 66.81 | 0.8872 | |
| (13,13) | 0.0256 | 64.03 | 0.7811 | |
| Noise Type | Non Local Means Parameters | Evaluation Matrices | ||||
|---|---|---|---|---|---|---|
| Patch Size | h Values | Patch Distance | MSE | PSNR | UQI | |
| Gaussian | 11 | 3 | 3 | 0.0351 | 62.67 | 0.8127 |
| 5 | 0.0384 | 62.28 | 0.7957 | |||
| 7 | 0.0394 | 62.17 | 0.789 | |||
| 2 | 3 | 0.0322 | 63.04 | 0.8245 | ||
| 5 | 0.0358 | 62.58 | 0.8045 | |||
| 7 | 0.0373 | 62.4 | 0.7967 | |||
| 9 | 3 | 3 | 0.0351 | 62.67 | 0.8123 | |
| 5 | 0.038 | 62.32 | 0.7957 | |||
| 7 | 0.0388 | 62.23 | 0.7919 | |||
| 2 | 3 | 0.0317 | 63.11 | 0.8253 | ||
| 5 | 0.0353 | 62.64 | 0.8069 | |||
| 7 | 0.0369 | 62.45 | 0.7965 | |||
| 5 | 2 | 3 | 0.0302 | 63.31 | 0.8318 | |
| 5 | 0.0335 | 62.87 | 0.8121 | |||
| 7 | 0.0344 | 62.76 | 0.8058 | |||
| 1 | 3 | 0.0132 | 66.89 | 0.8989 | ||
| 5 | 0.0189 | 65.35 | 0.8663 | |||
| 7 | 0.0209 | 64.92 | 0.8555 | |||
| Salt-and-Pepper | 11 | 3 | 3 | 0.0351 | 62.67 | 0.8135 |
| 5 | 0.0382 | 62.3 | 0.7957 | |||
| 7 | 0.0391 | 62.19 | 0.7892 | |||
| 2 | 3 | 0.0319 | 63.08 | 0.8251 | ||
| 5 | 0.0357 | 62.59 | 0.8051 | |||
| 7 | 0.0371 | 62.42 | 0.7969 | |||
| 9 | 3 | 3 | 0.0425 | 61.84 | 0.7592 | |
| 5 | 0.0457 | 61.52 | 0.7402 | |||
| 7 | 0.0466 | 61.44 | 0.7335 | |||
| 2 | 3 | 0.0391 | 62.19 | 0.7734 | ||
| 5 | 0.0432 | 61.77 | 0.7502 | |||
| 7 | 0.0445 | 61.63 | 0.7416 | |||
| 5 | 2 | 3 | 0.037 | 62.44 | 0.7813 | |
| 5 | 0.0405 | 62.04 | 0.759 | |||
| 7 | 0.0417 | 61.92 | 0.7515 | |||
| 1 | 3 | 0.0181 | 65.53 | 0.8836 | ||
| 5 | 0.0235 | 64.4 | 0.8443 | |||
| 7 | 0.026 | 63.97 | 0.8295 | |||
| Poisson | 11 | 3 | 3 | 0.0294 | 63.43 | 0.7862 |
| 5 | 0.0327 | 62.97 | 0.76 | |||
| 7 | 0.0339 | 62.82 | 0.7489 | |||
| 2 | 3 | 0.0255 | 64.05 | 0.8022 | ||
| 5 | 0.0294 | 63.44 | 0.7743 | |||
| 7 | 0.031 | 63.21 | 0.7609 | |||
| 9 | 3 | 3 | 0.0293 | 63.46 | 0.7872 | |
| 5 | 0.0326 | 62.99 | 0.7606 | |||
| 7 | 0.0337 | 62.85 | 0.7498 | |||
| 2 | 3 | 0.0253 | 64.08 | 0.8034 | ||
| 5 | 0.0292 | 63.47 | 0.7744 | |||
| 7 | 0.0307 | 63.25 | 0.7615 | |||
| 5 | 2 | 3 | 0.0241 | 64.3 | 0.808 | |
| 5 | 0.0272 | 63.77 | 0.7814 | |||
| 7 | 0.0283 | 63.6 | 0.7703 | |||
| 1 | 3 | 0.0101 | 68.08 | 0.8811 | ||
| 5 | 0.0135 | 66.82 | 0.8428 | |||
| 7 | 0.015 | 66.36 | 0.8317 | |||
| Speckle | 11 | 3 | 3 | 0.0298 | 63.38 | 0.7435 |
| 5 | 0.0331 | 62.92 | 0.7594 | |||
| 7 | 0.0342 | 62.78 | 0.7483 | |||
| 2 | 3 | 0.0259 | 63.98 | 0.7989 | ||
| 5 | 0.0298 | 63.38 | 0.7733 | |||
| 7 | 0.0314 | 63.15 | 0.76 | |||
| 9 | 3 | 3 | 0.0297 | 63.4 | 0.7894 | |
| 5 | 0.033 | 62.94 | 0.7596 | |||
| 7 | 0.0341 | 62.8 | 0.7486 | |||
| 2 | 3 | 0.0258 | 64.01 | 0.7996 | ||
| 5 | 0.0296 | 63.4 | 0.773 | |||
| 7 | 0.0312 | 63.18 | 0.76 | |||
| 5 | 2 | 3 | 0.0245 | 64.22 | 0.8085 | |
| 5 | 0.0277 | 63.7 | 0.7801 | |||
| 7 | 0.0288 | 63.52 | 0.769 | |||
| 1 | 3 | 0.0104 | 67.95 | 0.878 | ||
| 5 | 0.0138 | 66.7 | 0.8404 | |||
| 7 | 0.0154 | 66.24 | 0.829 | |||
| Family | Discrete Wavelet Transform Parameters | Evaluation Metric |
|---|---|---|
| PSNR | ||
| Daubechies | db1 | 90.36 |
| db2 | 95.17 | |
| db3 | 49.55 | |
| db4 | 56.35 | |
| db5 | 54.1 | |
| db6 | 50.02 | |
| db7 | 49.45 | |
| db8 | 50.22 | |
| db9 | 50.83 | |
| db10 | 53.01 | |
| Symlets | sym2 | 51.14 |
| sym3 | 51.05 | |
| sym4 | 51.07 | |
| sym5 | 51.34 | |
| sym6 | 51.14 | |
| sym7 | 51.26 | |
| sym8 | 51.17 | |
| sym9 | 48.63 | |
| Biorthogonal | bior1.1 | 90.36 |
| bior1.3 | 75.79 | |
| bior1.5 | 70.15 | |
| bior2.2 | 56.7 | |
| bior2.4 | 68.45 | |
| bior2.6 | 64.17 | |
| bior2.8 | 66.44 | |
| bior3.1 | 48.13 | |
| bior3.3 | 54.63 | |
| bior3.5 | 54.01 | |
| bior3.7 | 53.72 | |
| bior3.9 | 53.7 | |
| bior4.4 | 51.17 | |
| bior5.5 | 5.09 | |
| bior6.8 | 51.14 | |
| Coiflets | coif1 | 57.7 |
| coif2 | 58.24 | |
| coif3 | 56.31 | |
| coif4 | 50.89 | |
| coif5 | 52.54 | |
| coif6 | 56.15 | |
| coif7 | 57.62 | |
| coif8 | 58.37 | |
| coif9 | 51.51 | |
| coif10 | 54.15 | |
| Reverse Biorthogonal | rbior1.1 | 90.36 |
| rbior1.3 | 71.75 | |
| rbior1.5 | 69.87 | |
| rbior2.2 | 52.85 | |
| rbior2.4 | 57.96 | |
| rbior2.6 | 57.23 | |
| rbior2.8 | 59.82 | |
| rbior3.1 | 49.38 | |
| rbior3.3 | 51.65 | |
| rbior3.5 | 51.96 | |
| rbior3.7 | 52.15 | |
| rbior3.9 | 52.37 | |
| rbior4.4 | 51.17 | |
| rbior5.5 | 51.09 | |
| rbior6.8 | 51.14 |
| Classifiers | Parameters Name | Parameters Values | Optimal Values |
|---|---|---|---|
| SVC | C | 1, 5, 10, 100, 1000 | 100 |
| gamma | 1, 0.1, 0.01, 0.001, 0.0001 | 0.01 | |
| kernel | ‘RBF’, ‘Linear’ | ‘RBF’ | |
| Extra Tree Classifier | n_estimators | 10, 50, 100, 200, 300 | 300 |
| criterion | ‘gini’, ‘entropy’, ‘log_loss’ | ‘Gini’ | |
| Histogram-based Gredient Boosting | learning_rate | 0.1, 0.01, 0.001, 0.0001 | 0.1 |
| loss | ‘log_loss’, ‘auto’,‘categorical_crossentropy’ | ‘categorical_crossentropy’ | |
| l2_regularization | 0, 1 | 0 | |
| K_Nearest Neighbor | n_neighbors | 1, 5, 10, 15, 20 | 1 |
| weights | ‘uniform’, ‘distance’ | ‘uniform’ | |
| algorith | ‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’ | ‘auto’ | |
| Random Forest | n_estimators | 10, 50, 100, 155, 200 | 50 |
| criterion | ‘gini’, ‘entropy’, ‘log_loss’ | ‘gini’ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, S.S.H.; Jamil, N.; Khan, A.u.R. Memory Visualization-Based Malware Detection Technique. Sensors 2022, 22, 7611. https://doi.org/10.3390/s22197611
Shah SSH, Jamil N, Khan AuR. Memory Visualization-Based Malware Detection Technique. Sensors. 2022; 22(19):7611. https://doi.org/10.3390/s22197611
Chicago/Turabian StyleShah, Syed Shakir Hameed, Norziana Jamil, and Atta ur Rehman Khan. 2022. "Memory Visualization-Based Malware Detection Technique" Sensors 22, no. 19: 7611. https://doi.org/10.3390/s22197611