

Transformer Based Binocular Disparity Prediction with Occlusion Predict and Novel Full Connection Layers
 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
2.1. Stereo Matching
2.2. End-to-End Methods for Stereo Matching
2.3. Supervised and Self-Supervised Method
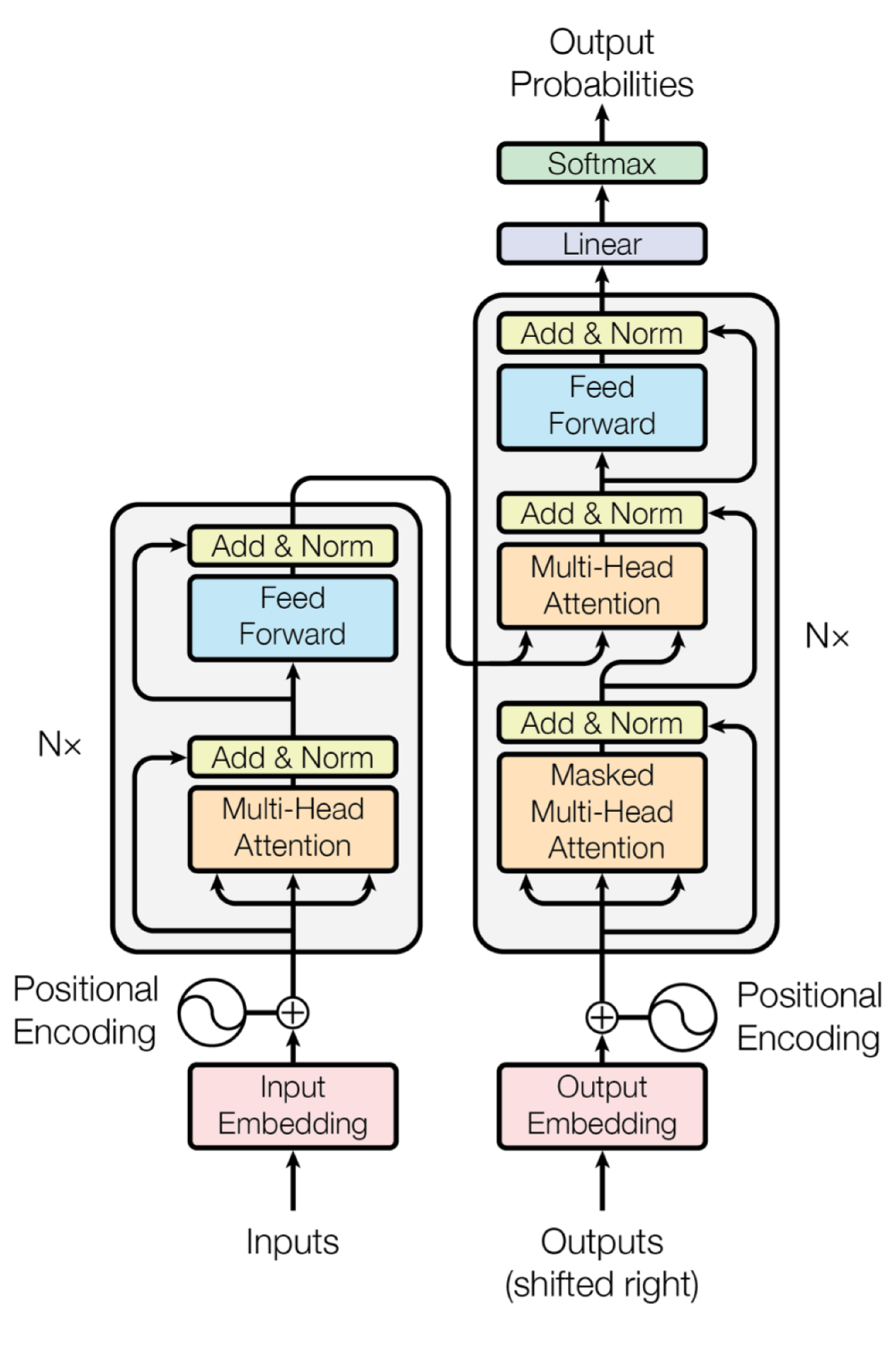
2.4. Transformer-Based Structure
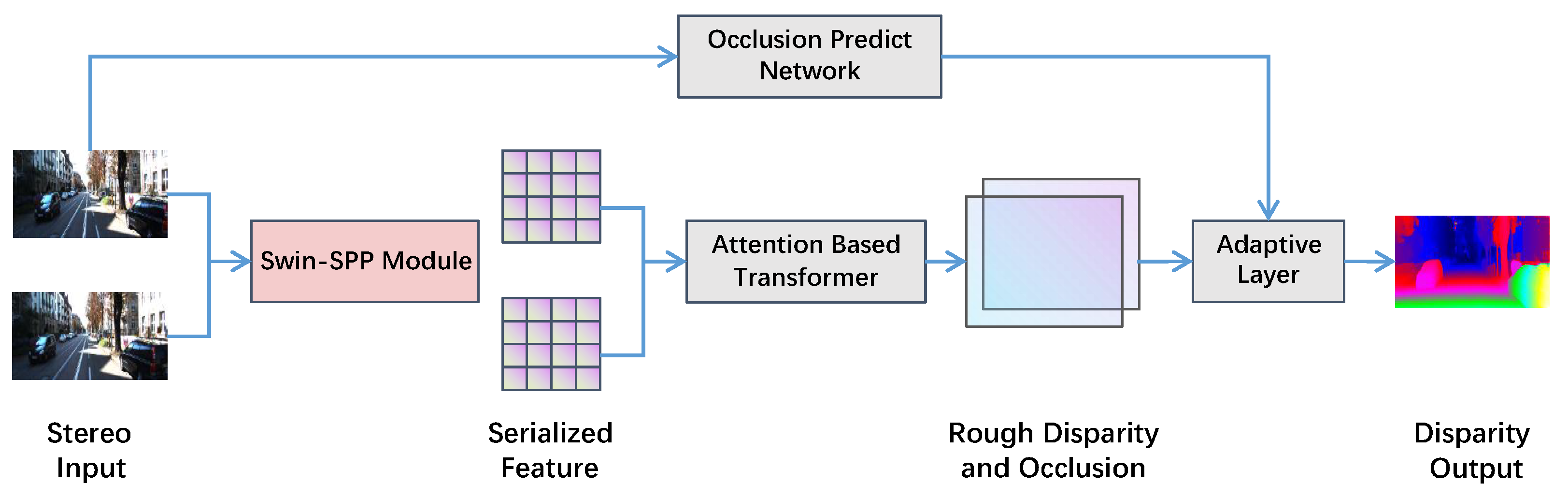
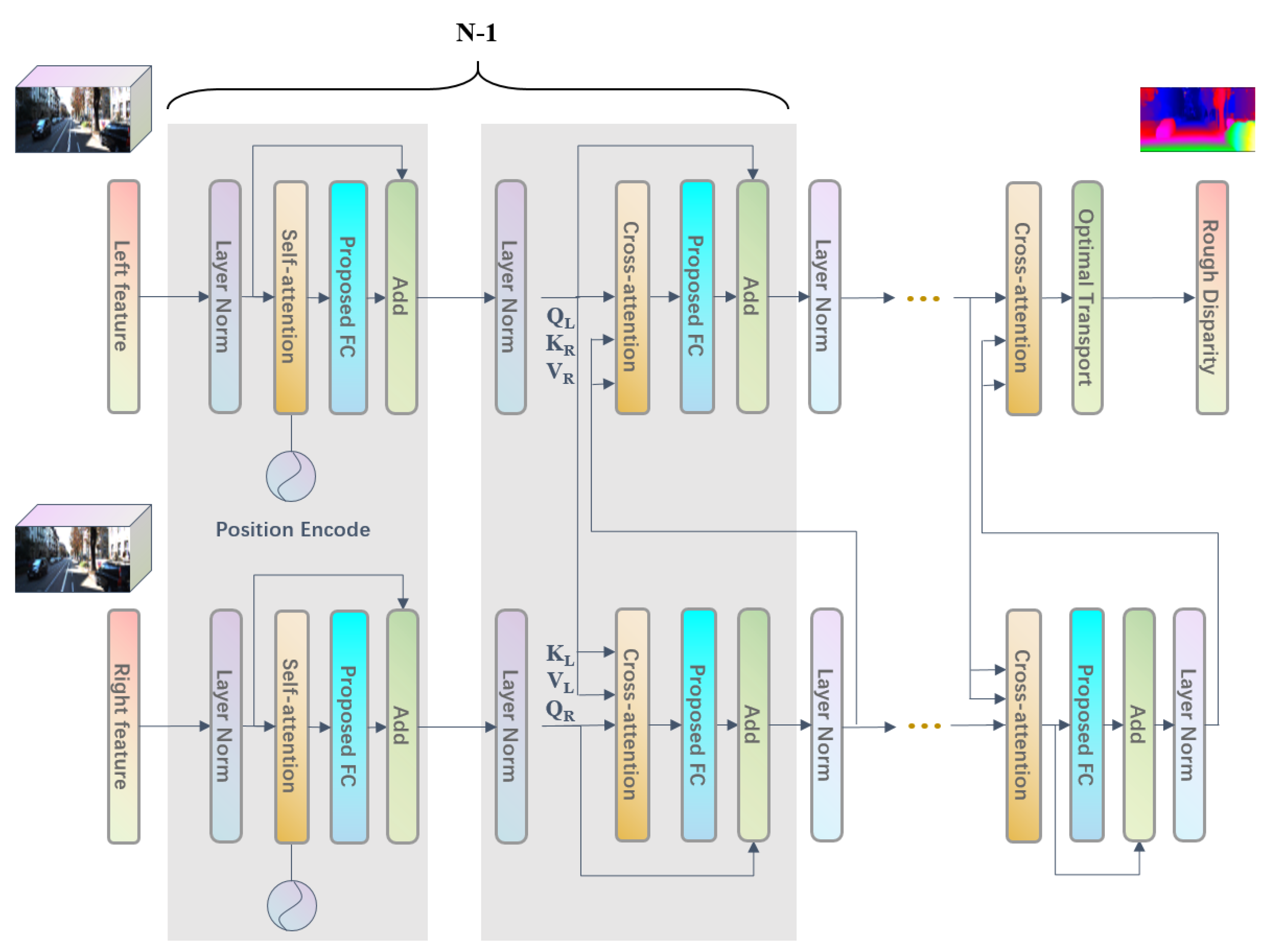
3. Architecture
4. Stereo Matching Backbone Network Based on Self-Attention and Cross-Attention
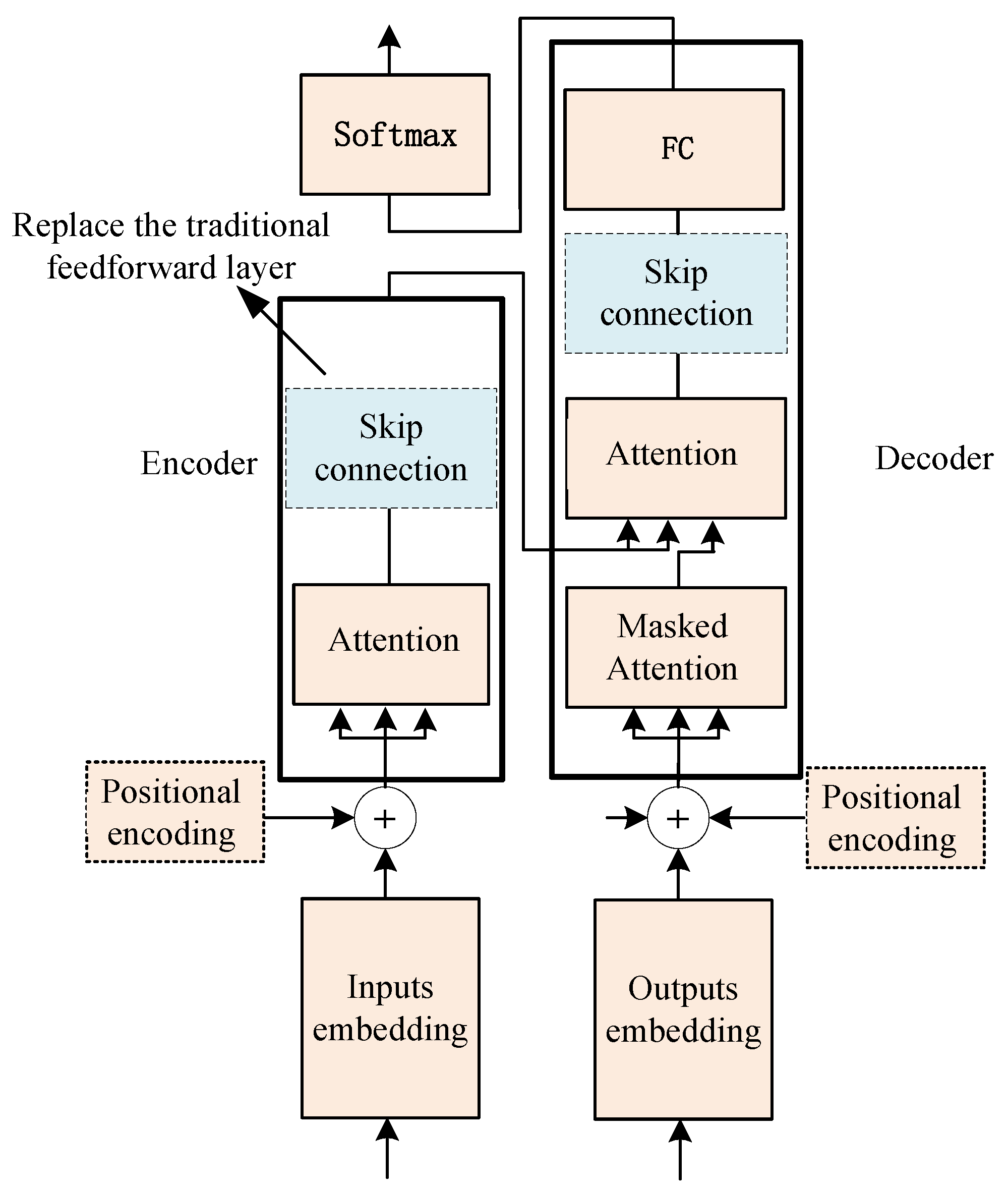
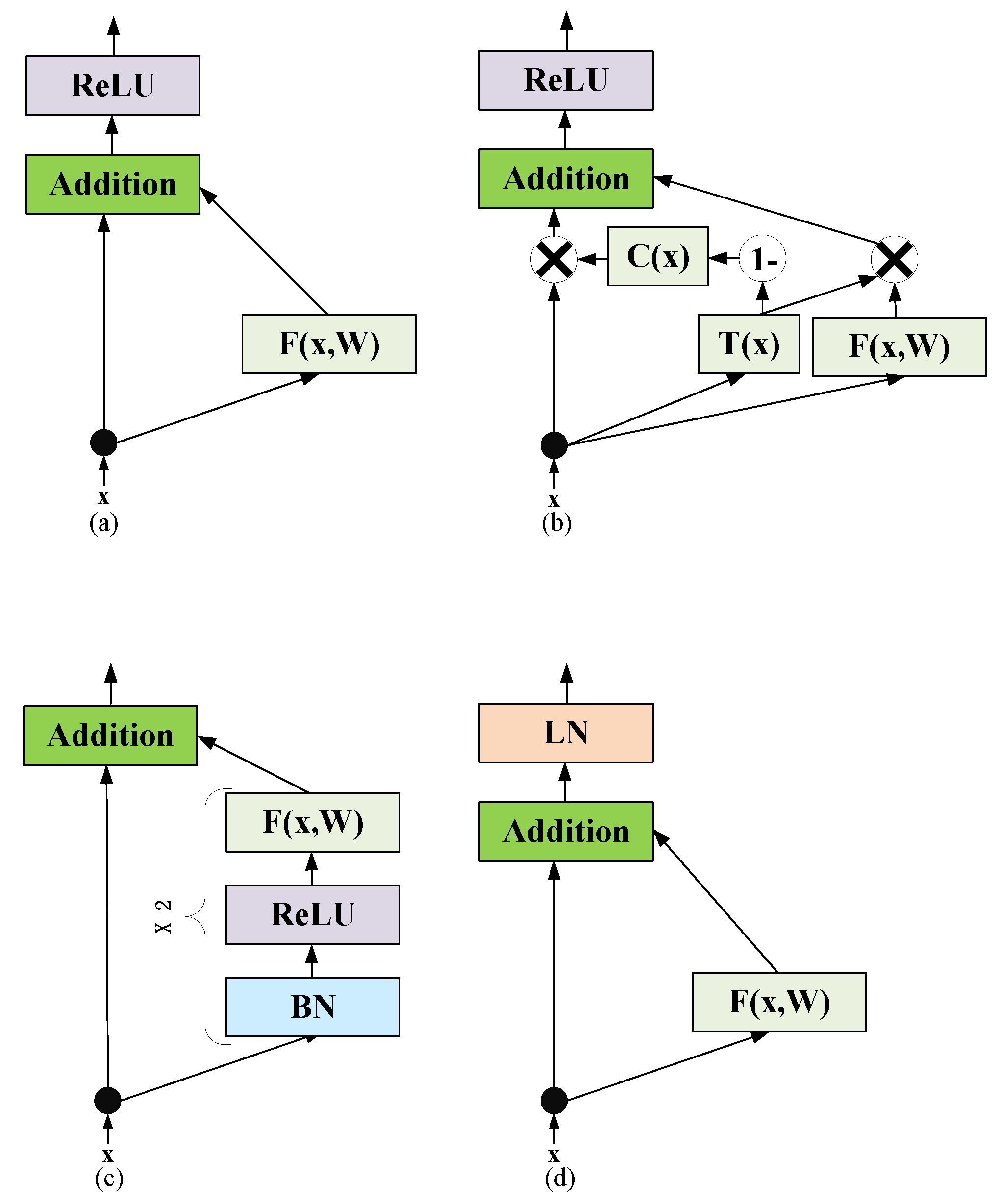
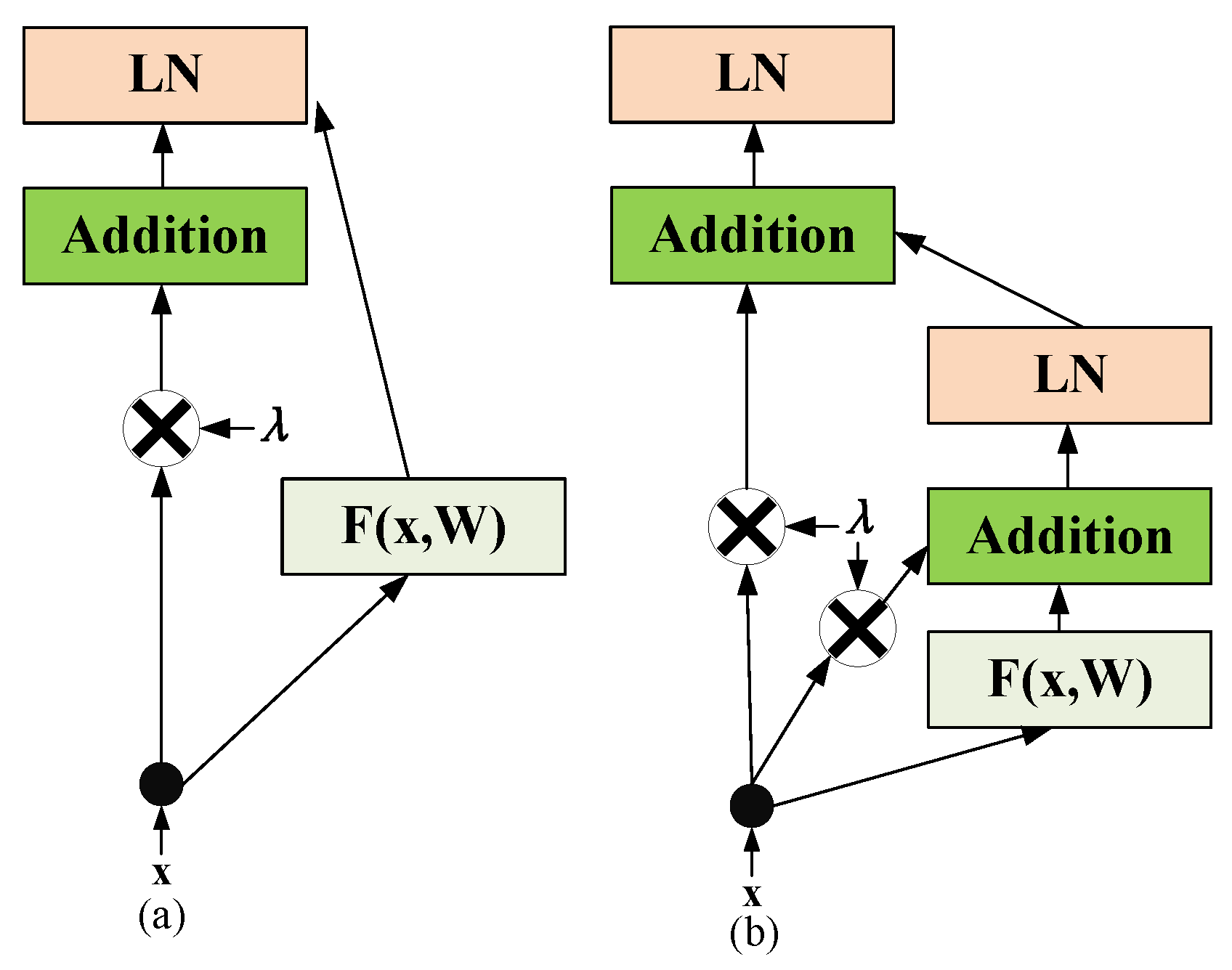
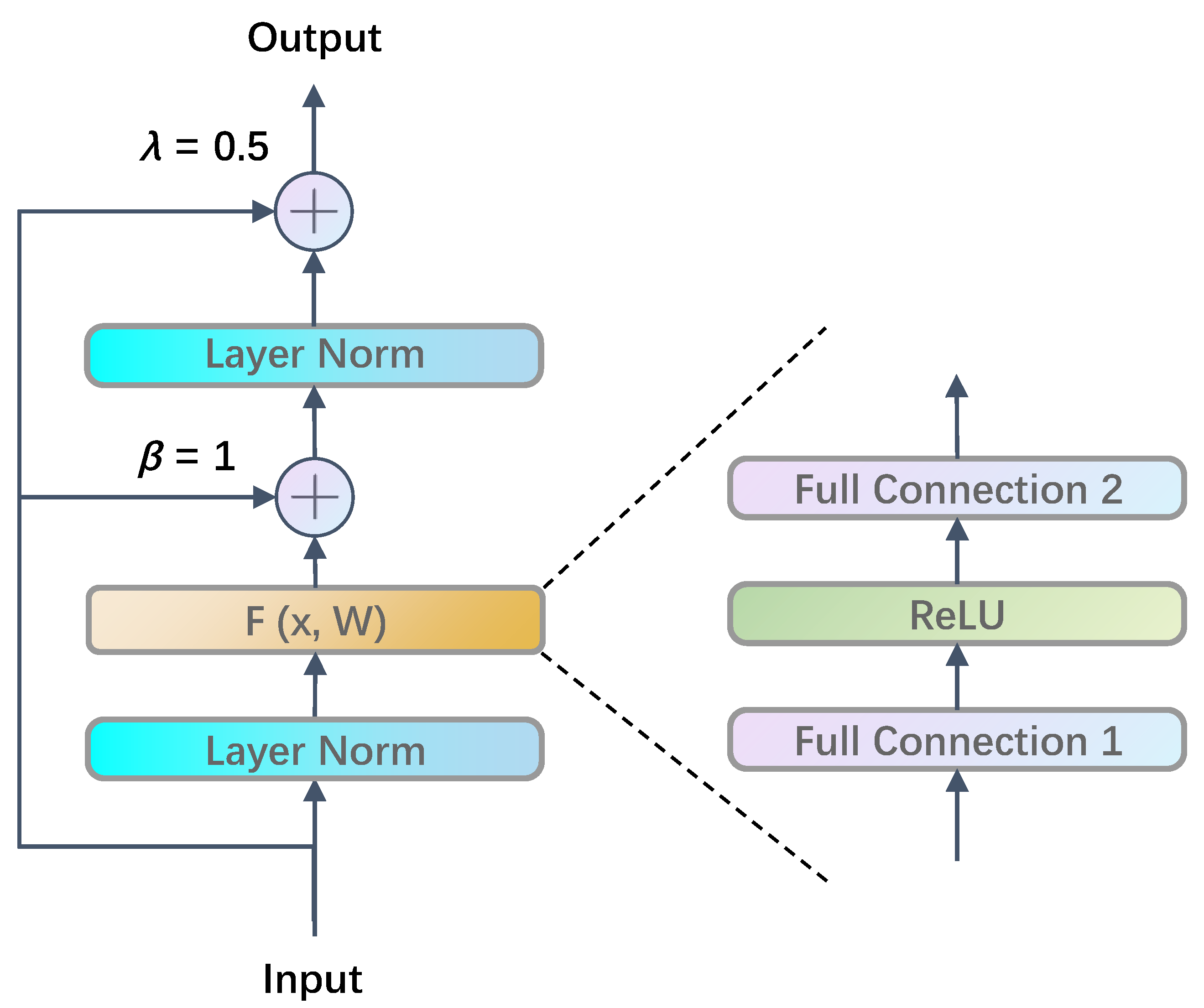
4.1. Skip Connection Structure in Transformer Feedforward Layer
4.2. Disparity Map Generation Based on Transformer
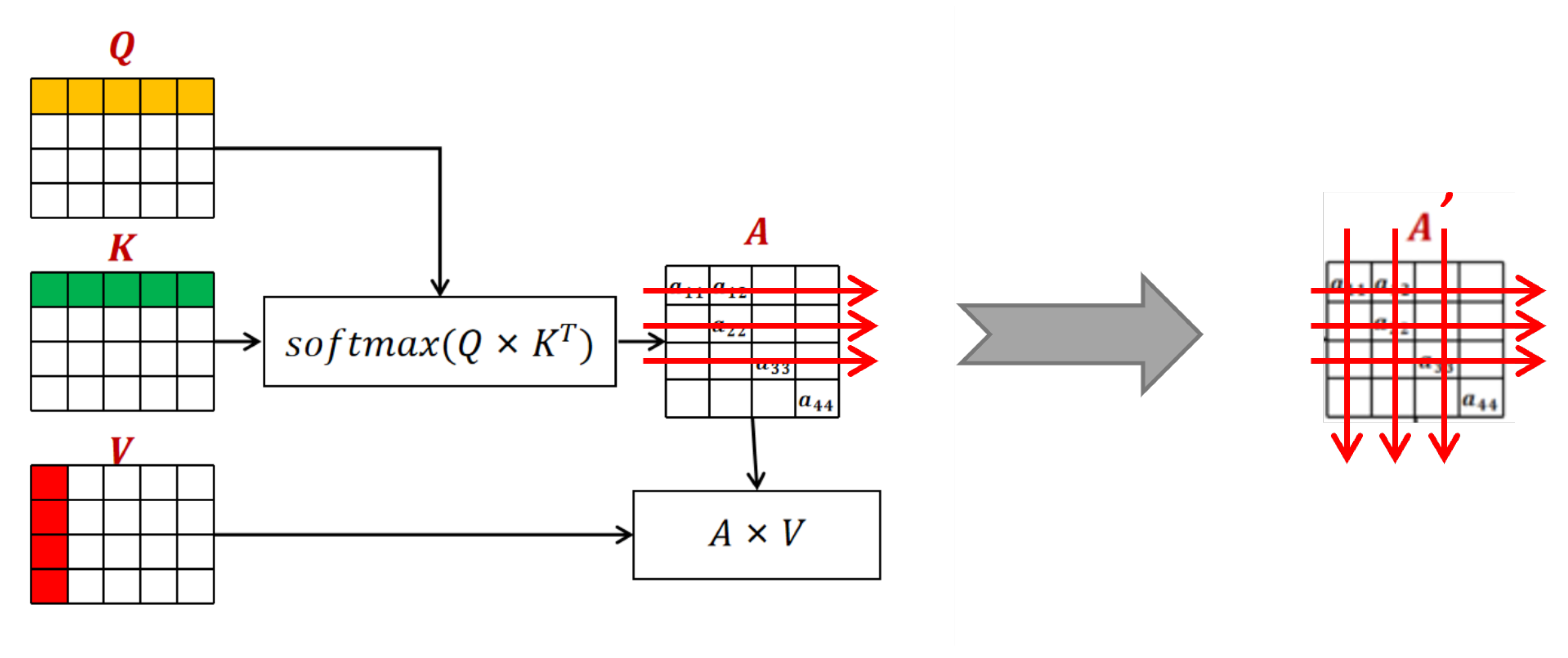
4.2.1. Attention Mask
4.2.2. Explicit Uniqueness Constraints
4.2.3. Preliminary Disparity Map Generation
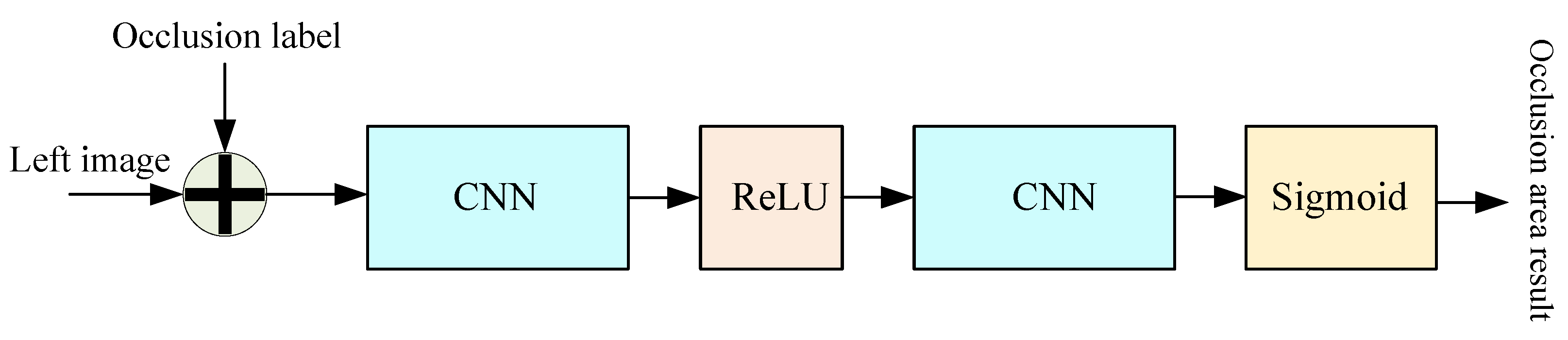
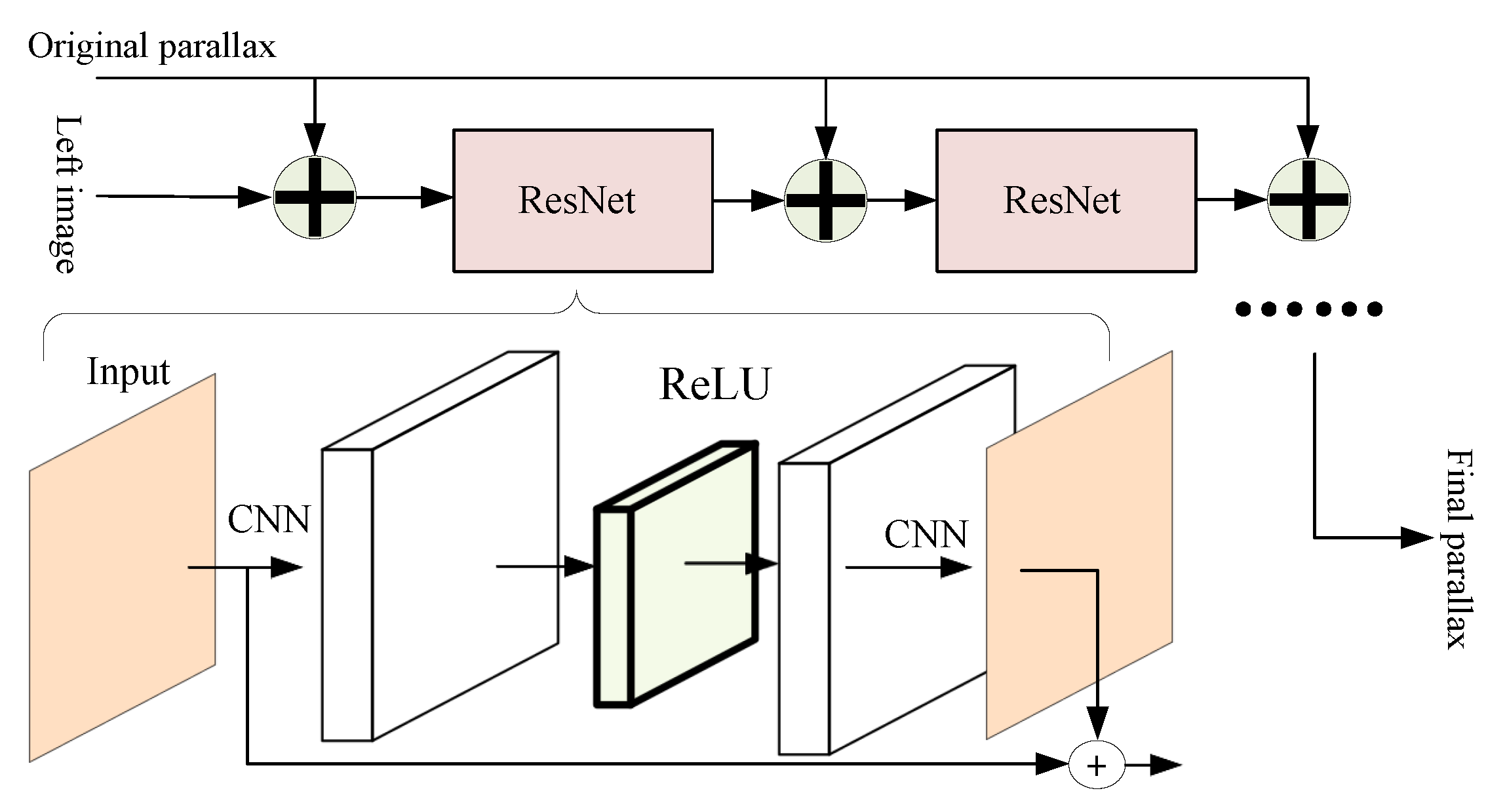
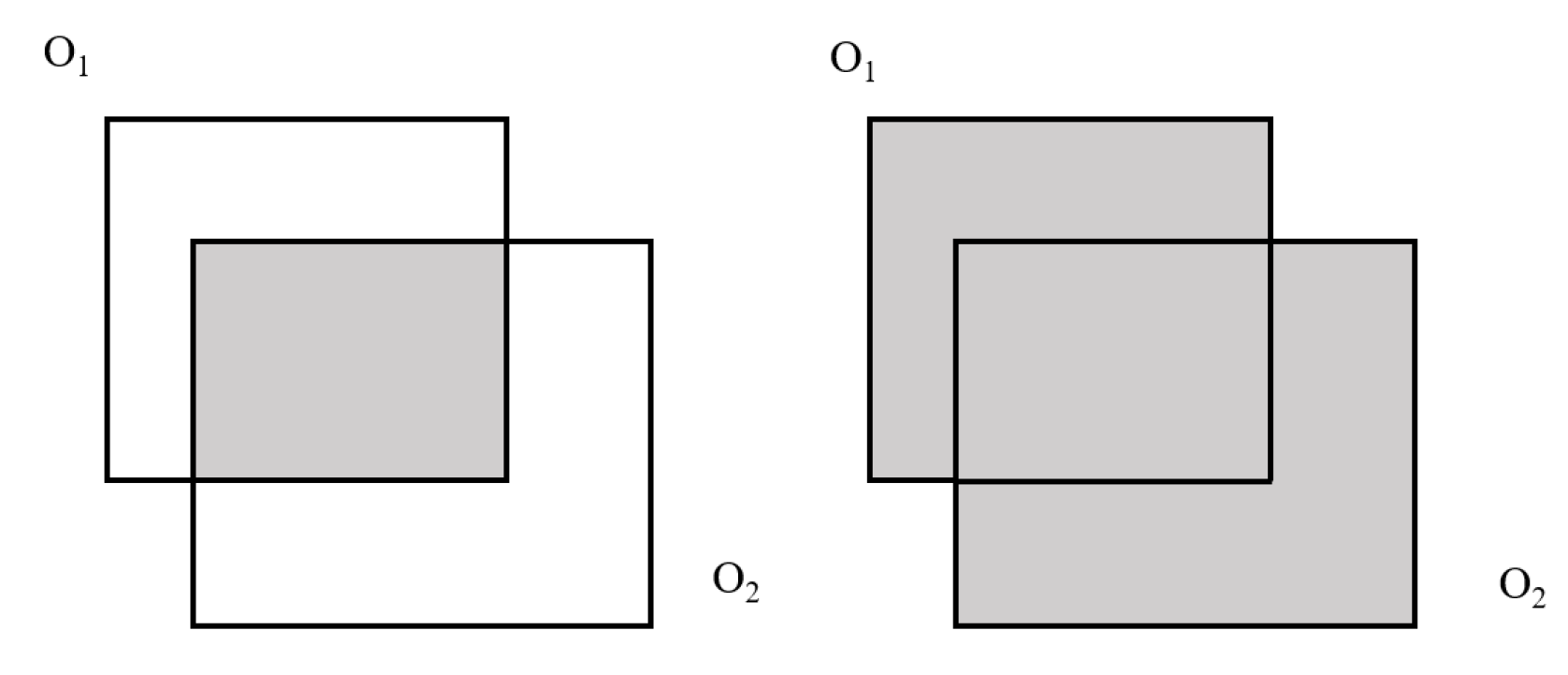
5. Occlusion Prediction and Adaptive Sub-Networks
6. Experiments
6.1. Evaluation Methord
6.2. DispNet/FlowNet2.0 Dataset
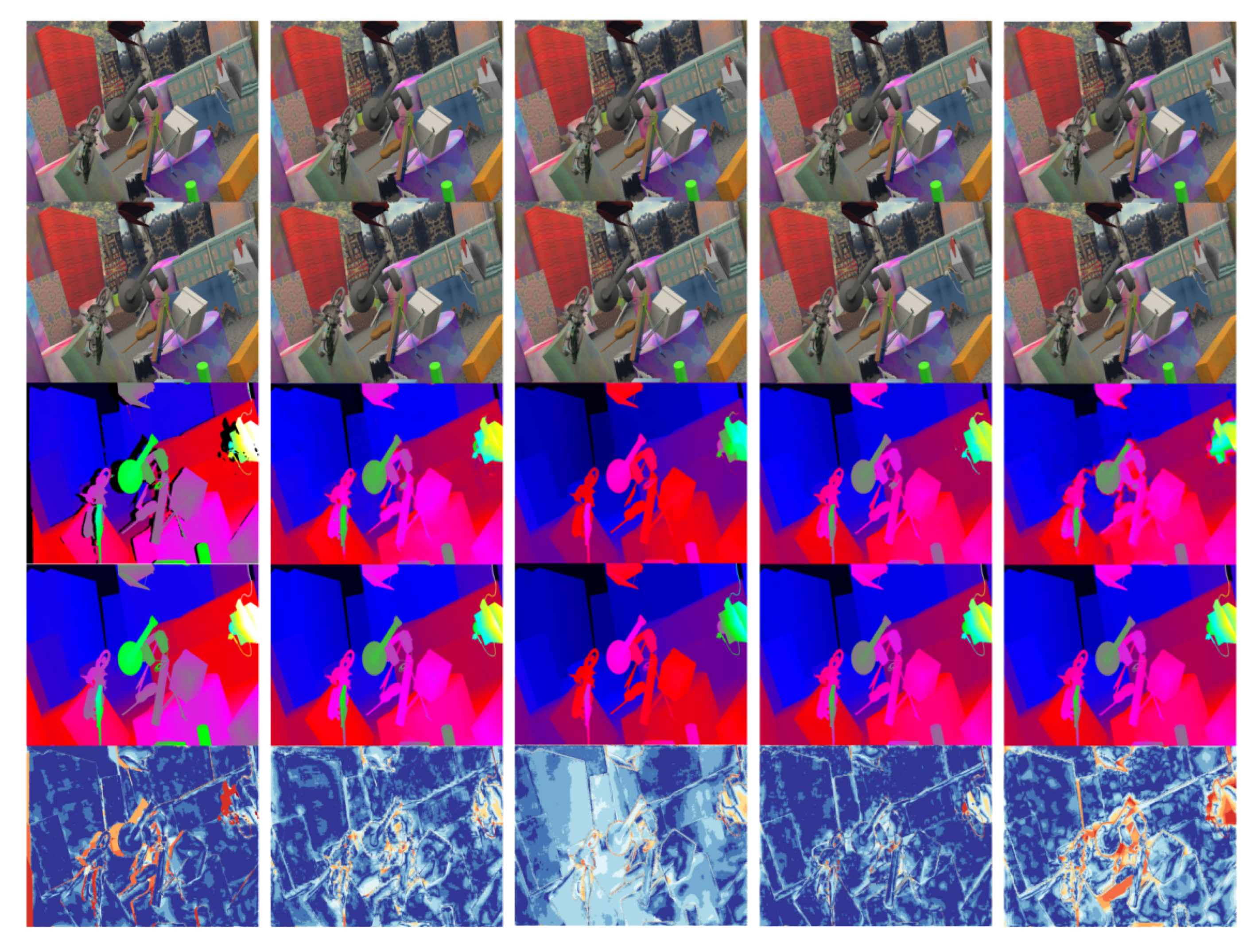
- Except for the occlusion area, the algorithm in this chapter has a cooler overall tone, indicating a higher accuracy.
- Our algorithm has a sharper and clearer boundary in the edge area.
- Our algorithm has a strong representation ability at microscopic structures, which is not exhibited in other methods.
- Our algorithm presents uniform changes in non-textured areas with disparity gradient (such as tilted surfaces) and has less false matching.
6.3. KITTI Benchmark
- Our algorithm integrates the occlusion processing module, so the parts with higher thermal error values are less in the challenging area, indicating higher overall accuracy.
- Compared with other algorithms, our algorithm has a sharper and clearer boundary for the regular region with a small area and obvious boundary (triangle and circular signs in the Figure) while to a prominent extent maintaining the shape characteristics of the regular region with a small area.
- The algorithm in this chapter has better disparity fitting in the remote area. There is no obvious prediction error for scenes like the sky, and it has less mismatching than other algorithms.
6.4. Generalization Ability
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ohta, Y.; Kanade, T. Stereo by intra-and inter-scanline search using dynamic programming. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 139–154. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Laga, H.; Jospin, L.V.; Boussaid, F.; Bennamoun, M. A survey on deep learning techniques for stereo-based depth estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Shaked, A.; Wolf, L. Improved stereo matching with constant highway networks and reflective confidence learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4641–4650. [Google Scholar]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Park, H.; Lee, K.M. Look wider to match image patches with convolutional neural networks. IEEE Signal Process. Lett. 2016, 24, 1788–1792. [Google Scholar] [CrossRef] [Green Version]
- Ye, X.; Li, J.; Wang, H.; Huang, H.; Zhang, X. Efficient stereo matching leveraging deep local and context information. IEEE Access 2017, 5, 18745–18755. [Google Scholar] [CrossRef]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Chen, Z.; Sun, X.; Wang, L.; Yu, Y.; Huang, C. A deep visual correspondence embedding model for stereo matching costs. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 972–980. [Google Scholar]
- Seki, A.; Pollefeys, M. Sgm-nets: Semi-global matching with neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 231–240. [Google Scholar]
- Schonberger, J.L.; Sinha, S.N.; Pollefeys, M. Learning to fuse proposals from multiple scanline optimizations in semi-global matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 739–755. [Google Scholar]
- Zhang, Q.; Lin, C.; Li, F. Application of binocular disparity and receptive field dynamics: A biologically-inspired model for contour detection. Pattern Recognit. 2021, 110, 107657. [Google Scholar] [CrossRef]
- Xie, Q.; Hu, X.; Ren, L.; Qi, L.; Sun, Z. A Binocular Vision Application in IoT: Realtime Trustworthy Road Condition Detection System in Passable Area. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Zhang, C.; Tian, K.; Fan, B.; Meng, G.; Zhang, Z.; Pan, C. Continual Stereo Matching of Continuous Driving Scenes With Growing Architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–24 June 2022; pp. 18901–18910. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 4040–4048. [Google Scholar]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5410–5418. [Google Scholar]
- Pang, J.; Sun, W.; Ren, J.S.; Yang, C.; Yan, Q. Cascade residual learning: A two-stage convolutional neural network for stereo matching. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 887–895. [Google Scholar]
- Liang, Z.; Feng, Y.; Guo, Y.; Liu, H.; Chen, W.; Qiao, L.; Zhou, L.; Zhang, J. Learning for disparity estimation through feature constancy. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2811–2820. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-end learning of geometry and context for deep stereo regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Nie, G.Y.; Cheng, M.M.; Liu, Y.; Liang, Z.; Fan, D.P.; Liu, Y.; Wang, Y. Multi-level context ultra-aggregation for stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3283–3291. [Google Scholar]
- Knobelreiter, P.; Reinbacher, C.; Shekhovtsov, A.; Pock, T. End-to-end training of hybrid CNN-CRF models for stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2339–2348. [Google Scholar]
- Xue, Y.; Chen, J.; Wan, W.; Huang, Y.; Yu, C.; Li, T.; Bao, J. Mvscrf: Learning multi-view stereo with conditional random fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 4312–4321. [Google Scholar]
- Paschalidou, D.; Ulusoy, O.; Schmitt, C.; Van Gool, L.; Geiger, A. Raynet: Learning volumetric 3d reconstruction with ray potentials. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3897–3906. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5525–5534. [Google Scholar]
- Yang, G.; Zhao, H.; Shi, J.; Deng, Z.; Jia, J. Segstereo: Exploiting semantic information for disparity estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 636–651. [Google Scholar]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-wise correlation stereo network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3273–3282. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Lanchantin, J.; Wang, T.; Ordonez, V.; Qi, Y. General multi-label image classification with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 16478–16488. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Tran, A.; Mathews, A.; Xie, L. Transform and tell: Entity-aware news image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020; pp. 13035–13045. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding. arXiv 2021, arXiv:2102.05095. [Google Scholar]
- Chen, X.; Wu, Y.; Wang, Z.; Liu, S.; Li, J. Developing real-time streaming transformer transducer for speech recognition on large-scale dataset. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, USA, 6–11 June 2021; pp. 5904–5908. [Google Scholar]
- Liu, X.; Zheng, Y.; Killeen, B.; Ishii, M.; Hager, G.D.; Taylor, R.H.; Unberath, M. Extremely dense point correspondences using a learned feature descriptor. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Toronto, ON, USA, 14–19 June 2020; pp. 4847–4856. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Poole, B.; Lahiri, S.; Raghu, M.; Sohl-Dickstein, J.; Ganguli, S. Exponential expressivity in deep neural networks through transient chaos. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Schoenholz, S.S.; Gilmer, J.; Ganguli, S.; Sohl-Dickstein, J. Deep information propagation. arXiv 2017, arXiv:1611.01232. [Google Scholar]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T. On layer normalization in the transformer architecture. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 10524–10533. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Liu, F.; Ren, X.; Zhang, Z.; Sun, X.; Zou, Y. Rethinking Skip Connection with Layer Normalization in Transformers and ResNets. arXiv 2021, arXiv:2105.07205. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Liu, Y.; Zhu, L.; Yamada, M.; Yang, Y. Semantic correspondence as an optimal transport problem. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020; pp. 4463–4472. [Google Scholar]
- Cuturi, M. Lightspeed computation of optimal transportation distances. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Peyré, G.; Cuturi, M. Computational optimal transport: With applications to data science. Found. Trends Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Tulyakov, S.; Ivanov, A.; Fleuret, F. Practical deep stereo (pds): Toward applications-friendly deep stereo matching. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | Parameters |
|---|---|
| CPU | Intel Core i7-10700 @2.9 GHz |
| GPU | NVIDIA GTX 2080Ti |
| Memory | DDR4 3200 Hz 16 G |
| Operating System | Ubuntu 18.04 LTS |
| Deep Learning Framework | PyTorch 1.7.1 |
| EPE | 3PE% | Occulution IOU% | Parameters | Runtime | |
|---|---|---|---|---|---|
| PSMNet | 1.25 | 3.31 | — | 5.2 M | 0.59 s |
| AnyNet | 3.19 | — | — | 40,000 | 97.3 ms |
| DeepPruner | 0.86 | 2.13 | — | N/A | 182 ms |
| AANet | 0.87 | — | — | N/A | 62 ms |
| GC-Net | 2.51 | 9.34 | — | 3.5 M | 0.95 s |
| Ours | 0.47 | 1.41 | 98.04 | 2.6 M | 0.46 s |
| EPE | 3PE/% | Occlusion IOU/% | Parameters | Runtime | |
|---|---|---|---|---|---|
| PSMNet | 0.6 | 1.89 | — | 5.2 M | 0.50 s |
| AnyNet | — | 6.10 | — | 40,000 | 97.3 ms |
| DeepPruner | — | 2.03 | — | N/A | 180 ms |
| AcfNet | 0.58 | 1.78 | — | 5.6 M | 0.48 s |
| GC-Net | 0.70 | 2.30 | — | 3.5 M | 0.9 s |
| Ours | 0.57 | 1.74 | 98.80 | 2.6 M | 0.46s |
| EPE | 3PE/% | Occlusion IOU/% | Parameters | Runtime | |
|---|---|---|---|---|---|
| PSMNet | — | 2.33 | — | 5.2 M | 0.50 s |
| AnyNet | — | 6.20 | — | 40,000 | 97.3 ms |
| DeepPruner | — | 2.15 | — | N/A | 180 ms |
| AcfNet | — | 1.89 | — | 5.6 M | 0.48 s |
| GC-Net | — | 2.87 | — | 3.5 M | 0.9 s |
| Ours | 0.6869 | 2.04 | 99.86 | 2.6 M | 0.46 s |
| Ours* | 0.6098 | 1.56 | 99.87 | 2.6 M | 0.46 s |
| Middlebury | KITTI | |||||
|---|---|---|---|---|---|---|
| EPE | 3pix Error | Occlusion IOU | EPE | 3pix Error | Occlusion IOU | |
| PSMNet | 3.05 | 12.96 | — | 6.56 | 27.79 | — |
| GwcNet | 1.89 | 8.59 | — | 2.21 | 12.60 | — |
| AANet | 2.19 | 12.80 | — | 1.99 | 12.42 | — |
| Ours | 2.23 | 6.09 | 95.5% | 1.40 | 5.74 | 98.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Xu, X.; Xiang, B.; Chen, G.; Gong, G.; Lu, H. Transformer Based Binocular Disparity Prediction with Occlusion Predict and Novel Full Connection Layers. Sensors 2022, 22, 7577. https://doi.org/10.3390/s22197577
Liu Y, Xu X, Xiang B, Chen G, Gong G, Lu H. Transformer Based Binocular Disparity Prediction with Occlusion Predict and Novel Full Connection Layers. Sensors. 2022; 22(19):7577. https://doi.org/10.3390/s22197577
Chicago/Turabian StyleLiu, Yi, Xintao Xu, Bajian Xiang, Gang Chen, Guoliang Gong, and Huaxiang Lu. 2022. "Transformer Based Binocular Disparity Prediction with Occlusion Predict and Novel Full Connection Layers" Sensors 22, no. 19: 7577. https://doi.org/10.3390/s22197577