
Instance-Level Contrastive Learning for Weakly Supervised Object Detection

Abstract
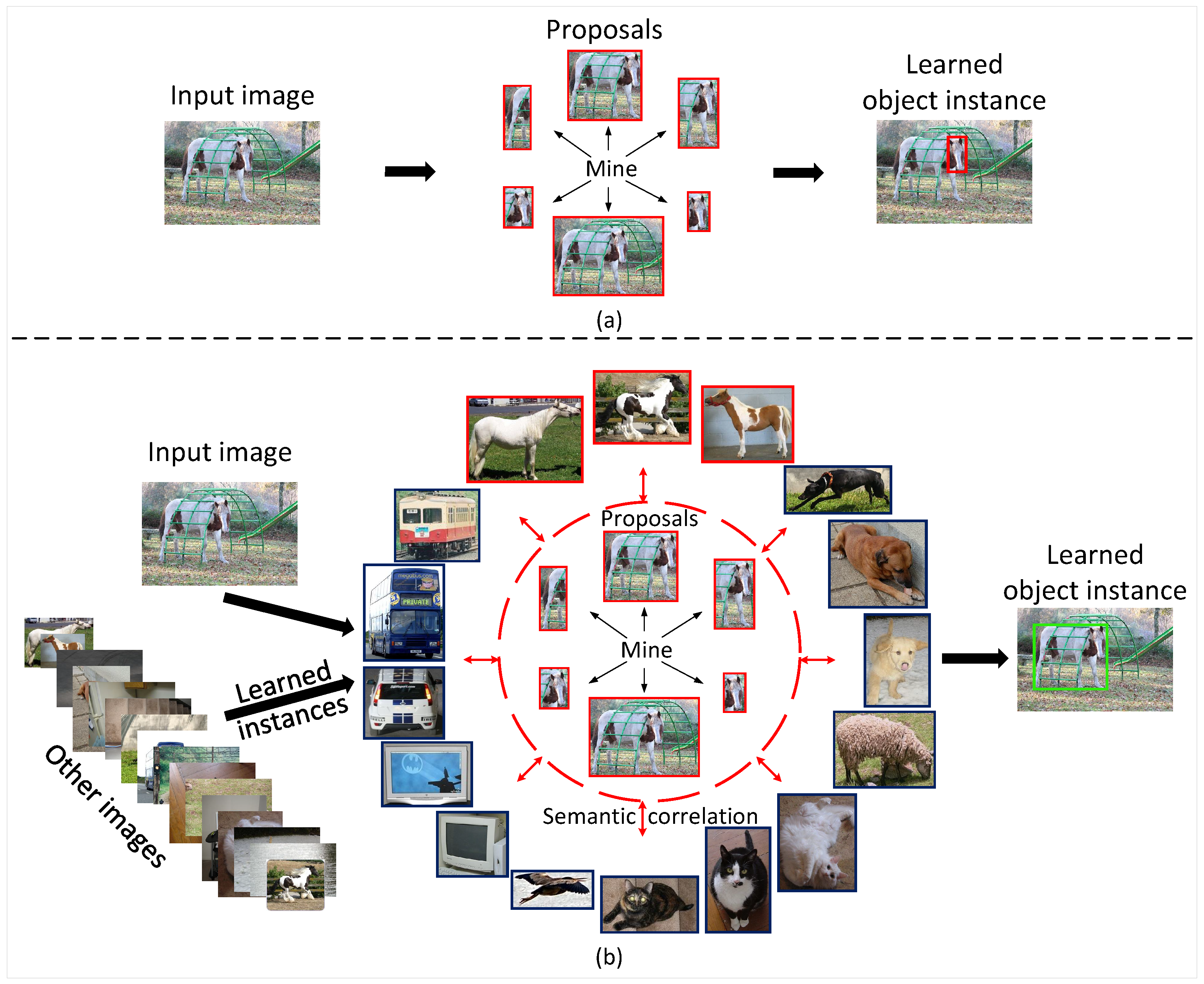
:1. Introduction
- We propose an instance-level contrastive learning (ICL) framework to guide the weakly supervised detector to learn instance representations. To the best of our knowledge, we are the first to explore contrastive learning in weakly supervised object detection.
- We propose an instance-diverse memory update (IMU) algorithm to store reliable instance representations into a memory bank, where multiple representation vectors are used in each class to maintain the diversity of instance representations.
- With the help of memory, we further propose a memory-aware instance mining (MIM) algorithm to efficiently mine object instances by combining proposal confidence and instance similarity.
- With the help of memory, we also propose a memory-aware proposal sampling (MPS) algorithm to alleviate the imbalance between positive and negative samples by finding more positive proposals and removing some unreliable negative proposals.
2. Related Work
2.1. Weakly Supervised Object Detection
2.2. Contrastive Learning
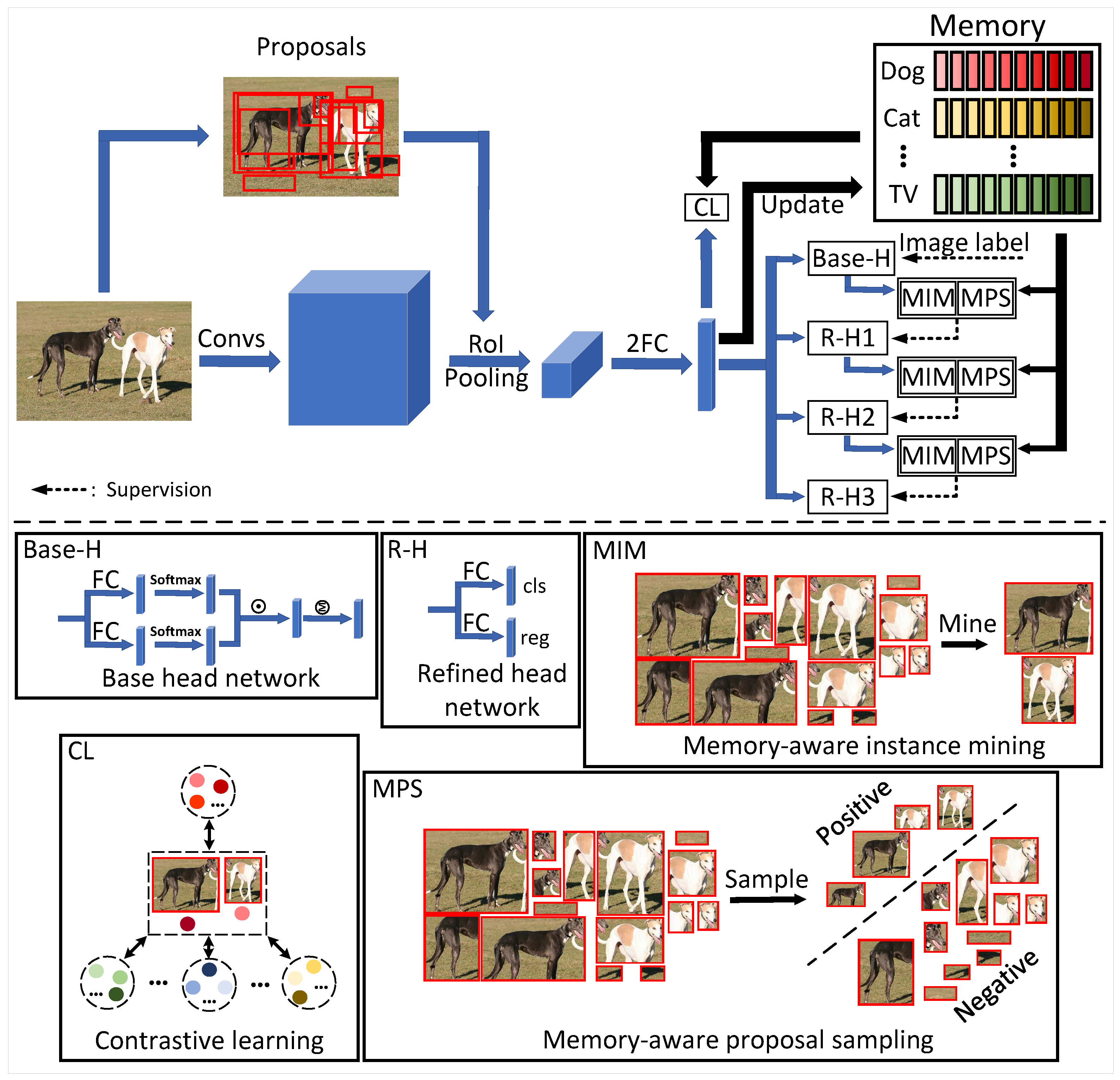
3. Method
3.1. Instance-Level Contrastive Learning
| Algorithm 1 Instance representation mining algorithm. |
| Input: The pre-generated proposals R, the pre-defined score threshold , the image label Y, the memory bank M, the outputs of instance refined heads and the proposal feature vectors . (I) average proposal scores (II) average coordinate offsets (III) obtain transformed proposals P by adding t to R (IV) instance representations and the corresponding confidences For to If or (1) (2) (3) (4) (5) (6) (7) , Output: , . |
3.2. Instance-Diverse Memory Updating Algorithm
| Algorithm 2 Instance-diverse memory updating algorithm. |
| Input: The pre-generated proposals R, the pre-defined score threshold , the image label Y, the memory bank M, the outputs of instance refined heads and the proposal feature vectors . (I) obtain reliable instance representations using Algorithm 1 For each representation in (a) compute the similarity between and with in Equation (6) (b) choose the most similarity feature from in Equation (7) (c) update in Equation (8) Output: Updated memory M. |
3.3. Memory-Aware Instance Mining Algorithm
| Algorithm 3 Memory-aware instance mining algorithm. |
| Input: The pre-generated proposals R, the pre-defined score threshold , the image label Y, the memory bank M, the outputs of instance refined head and the proposal feature vectors . (I) obtain transformed proposals by adding to R (II) calculate the memory-based confidence by Equation (10) (III) compute the combination confidence with Equation (11) For to C If (1) (2) (3) (4) (5) Output: , . |
3.4. Memory-Aware Proposal Sampling Algorithm
| Algorithm 4 Memory-aware proposal sampling algorithm. |
| Input: The pre-generated proposals R, the image label Y, the memory bank M, the mined object instance and the proposal feature vectors . (I) positive samples , negative samples (II) calculate (III) separate R into two parts and using Equation (12). (IV) (V) extract feature representations from For to C If (1) calculate the similarity between and (2) select the most similar proposal from by Equation (13) (3) , , (VI) (VII) sort from from high to low (VIII) obtain by removing the last low-similarity proposals from Output: , . |
3.5. Test
4. Experiments
4.1. Datasets and Evaluation Measures
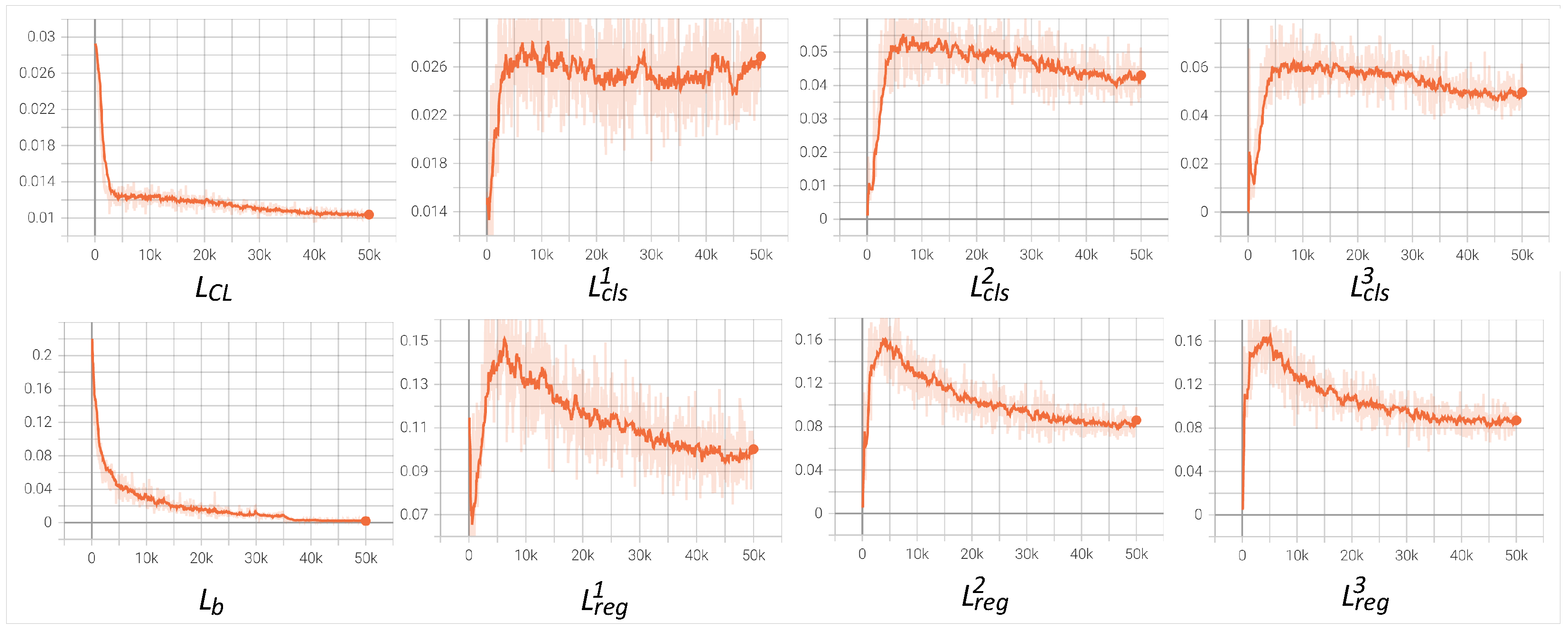
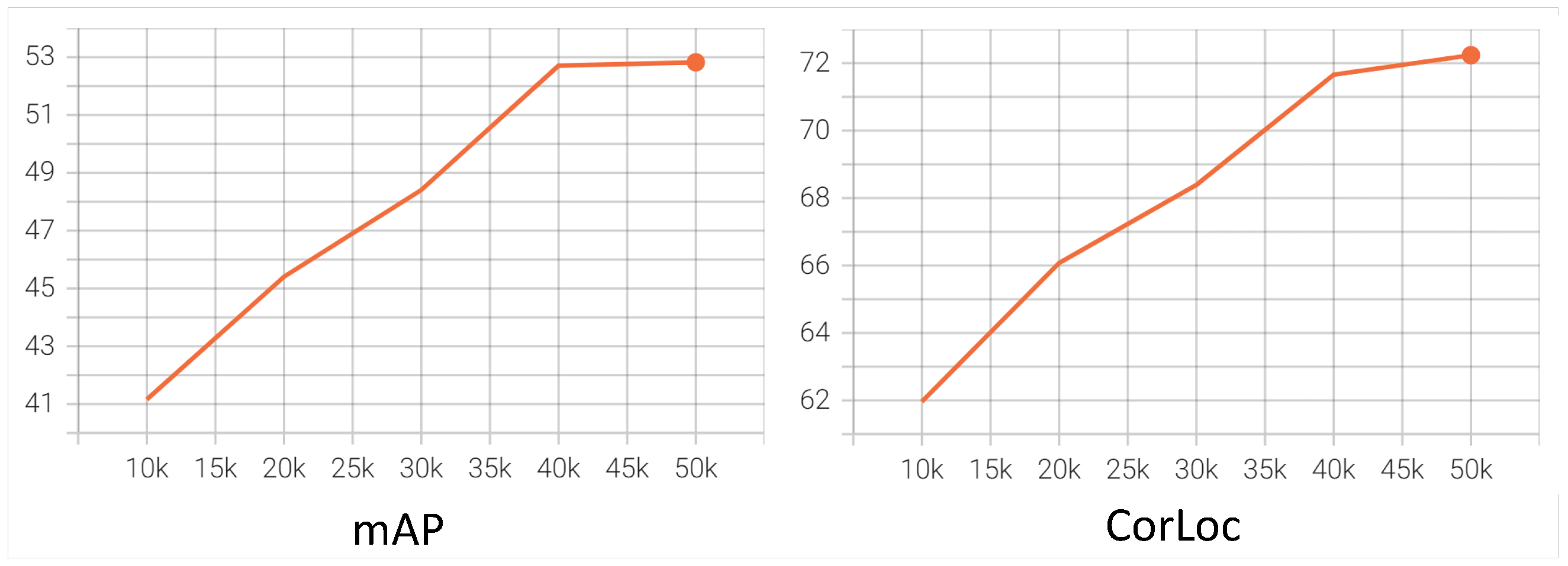
4.2. Experimental Details
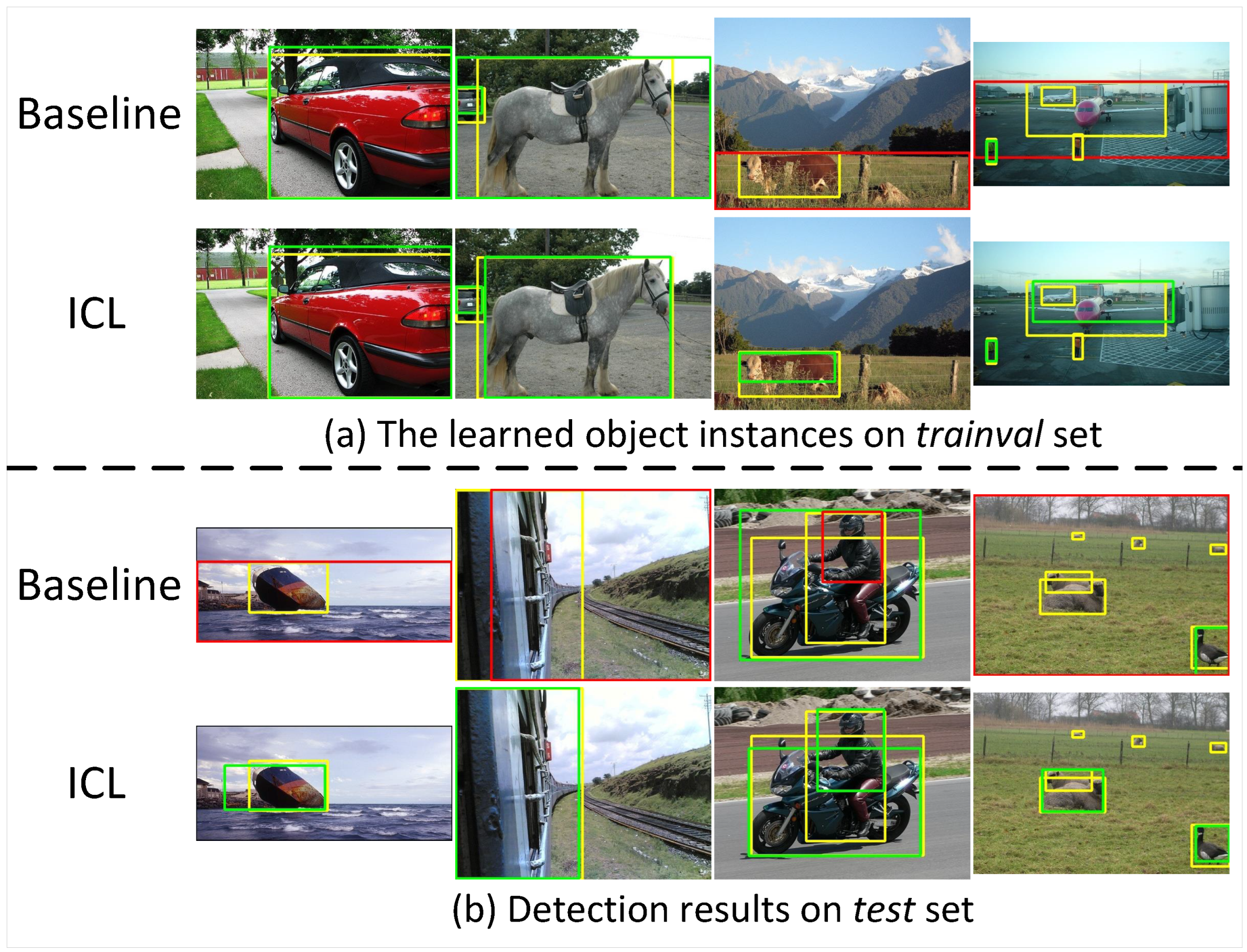
4.3. Comparison with Other Methods
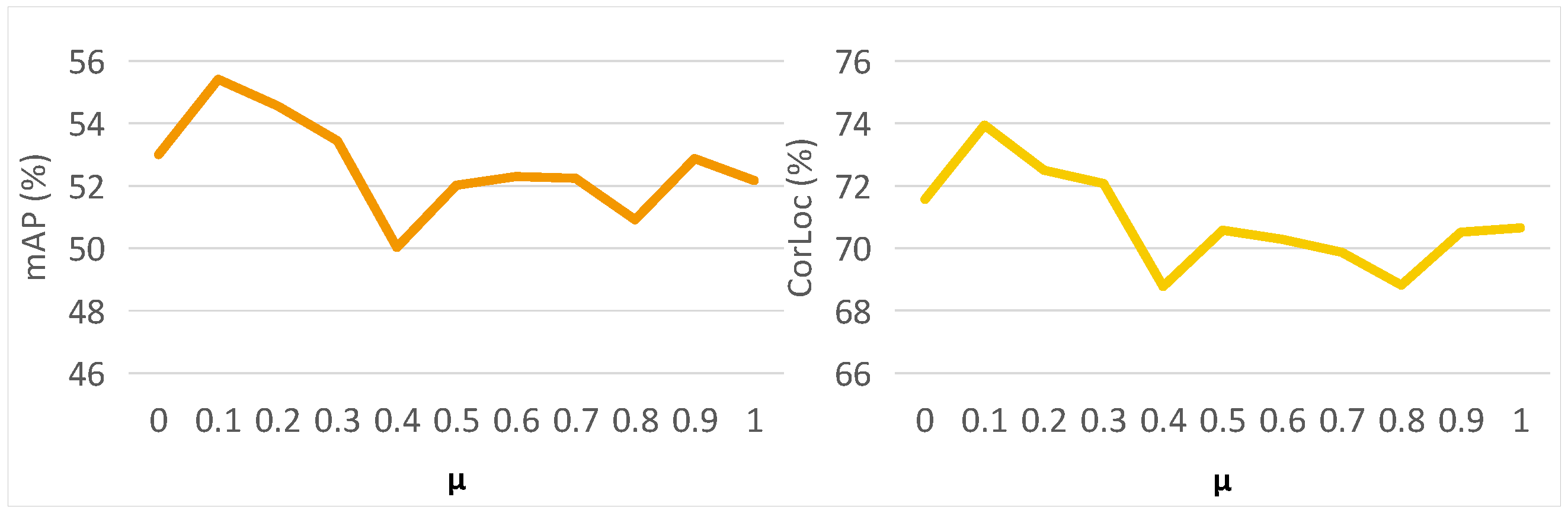
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Spain, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 9627–9636. [Google Scholar]
- Qiu, H.; Li, H.; Wu, Q.; Shi, H. Offset bin classification network for accurate object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 13188–13197. [Google Scholar]
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A lightweight real-time object detection method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lian, J.; Yin, Y.; Li, L.; Wang, Z.; Zhou, Y. Small object detection in traffic scenes based on attention feature fusion. Sensors 2021, 21, 3031. [Google Scholar] [CrossRef]
- Xiang, Y.; Zhao, B.; Zhao, K.; Wu, L.; Wang, X. Improved Dual Attention for Anchor-Free Object Detection. Sensors 2022, 22, 4971. [Google Scholar] [CrossRef]
- Kantorov, V.; Oquab, M.; Cho, M.; Laptev, I. Contextlocnet: Context-aware deep network models for weakly supervised localization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 350–365. [Google Scholar]
- Tang, P.; Wang, X.; Bai, X.; Liu, W. Multiple instance detection network with online instance classifier refinement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2843–2851. [Google Scholar]
- Shen, Y.; Ji, R.; Wang, Y.; Wu, Y.; Cao, L. Cyclic guidance for weakly supervised joint detection and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 697–707. [Google Scholar]
- Yang, K.; Zhang, P.; Qiao, P.; Wang, Z.; Dai, H.; Shen, T.; Dou, Y. Rethinking segmentation guidance for weakly supervised object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 946–947. [Google Scholar]
- Wei, Y.; Shen, Z.; Cheng, B.; Shi, H.; Xiong, J.; Feng, J.; Huang, T. Ts2c: Tight box mining with surrounding segmentation context for weakly supervised object detection. In Proceedings of the European Conference on ComputerbVision, Salt Lake City, UT, USA, 18–23 June 2018; pp. 434–450. [Google Scholar]
- Li, X.; Kan, M.; Shan, S.; Chen, X. Weakly supervised object detection with segmentation collaboration. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 9735–9744. [Google Scholar]
- Bilen, H.; Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854. [Google Scholar]
- Wan, F.; Liu, C.; Ke, W.; Ji, X.; Jiao, J.; Ye, Q. C-mil: Continuation multiple instance learning for weakly supervised object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2199–2208. [Google Scholar]
- Lin, C.; Wang, S.; Xu, D.; Lu, Y.; Zhang, W. Object instance mining for weakly supervised object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11482–11489. [Google Scholar]
- Xu, Y.; Zhou, C.; Yu, X.; Xiao, B.; Yang, Y. Pyramidal multiple instance detection network with mask guided self-correction for weakly supervised object detection. IEEE Trans. Image Process. 2021, 30, 3029–3040. [Google Scholar] [CrossRef]
- Wu, Z.; Wen, J.; Xu, Y.; Yang, J.; Li, X.; Zhang, D. Enhanced Spatial Feature Learning for Weakly Supervised Object Detection. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Wan, F.; Yue, J.; Xu, S.; Ye, Q. Discrepant multiple instance learning for weakly supervised object detection. Pattern Recognit. 2022, 122, 108233. [Google Scholar] [CrossRef]
- Tang, P.; Wang, X.; Bai, S.; Shen, W.; Bai, X.; Liu, W.; Yuille, A. Pcl: Proposal cluster learning for weakly supervised object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 176–191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Fu, Z.; Jiang, R.; Chen, Y.; Hua, X.S. Slv: Spatial likelihood voting for weakly supervised object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 12995–13004. [Google Scholar]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef] [Green Version]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1735–1742. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9729–9738. [Google Scholar]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 7352–7362. [Google Scholar]
- Yan, C.; Chang, X.; Luo, M.; Liu, H.; Zhang, X.; Zheng, Q. Semantics-guided contrastive network for zero-shot object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Chang, H.; Zheng, Y.; Li, Z.; Chen, Z.; Zhang, Z. Contrastive Learning-Based Robust Object Detection Under Smoky Conditions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LO, USA, 21–24 June 2022; pp. 4295–4302. [Google Scholar]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and local contrastive self-supervised learning for semantic segmentation of HR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5618014. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Arbeláez, P.; Pont-Tuset, J.; Barron, J.T.; Marques, F.; Malik, J. Multiscale combinatorial grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 328–335. [Google Scholar]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Deselaers, T.; Alexe, B.; Ferrari, V. Weakly supervised localization and learning with generic knowledge. Int. J. Comput. Vis. 2012, 100, 275–293. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]








{kind=link}
{kind=link}
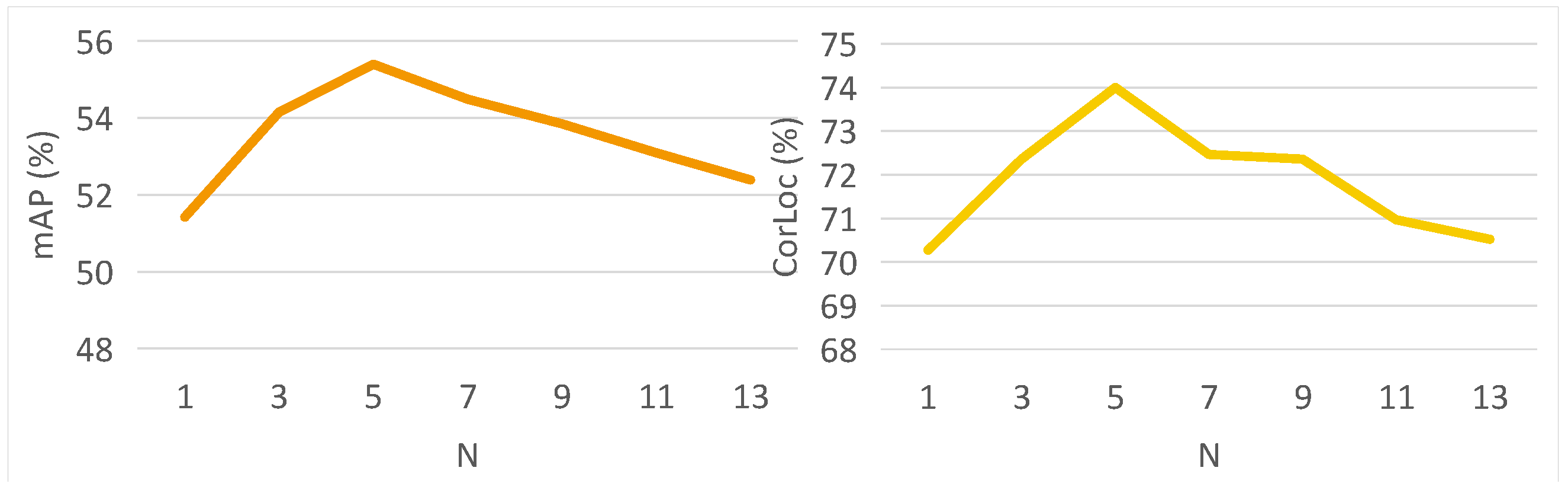{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | aer | bik | bir | boa | bot | bus | car | cat | cha | cow | tab | dog | hor | mot | per | pla | she | sof | tra | tv | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN [20] | 39.4 | 50.1 | 31.5 | 16.3 | 12.6 | 64.5 | 42.8 | 42.6 | 10.1 | 35.7 | 24.9 | 38.2 | 34.4 | 55.6 | 9.4 | 14.7 | 30.2 | 40.7 | 54.7 | 46.9 | 34.8 |
| Kantorov et al. [14] | 57.1 | 52.0 | 31.5 | 7.6 | 11.5 | 55.0 | 53.1 | 34.1 | 1.7 | 33.1 | 49.2 | 42.0 | 47.3 | 56.6 | 15.3 | 12.8 | 24.8 | 48.9 | 44.4 | 47.8 | 36.3 |
| OICR [15] | 58.0 | 62.4 | 31.1 | 19.4 | 13.0 | 65.1 | 62.2 | 28.4 | 24.8 | 44.7 | 30.6 | 25.3 | 37.8 | 65.5 | 15.7 | 24.1 | 41.7 | 46.9 | 64.3 | 62.6 | 41.2 |
| PCL [26] | 54.4 | 69.0 | 39.3 | 19.2 | 15.7 | 62.9 | 64.4 | 30.0 | 25.1 | 52.5 | 44.4 | 19.6 | 39.3 | 67.7 | 17.8 | 22.9 | 46.6 | 57.5 | 58.6 | 63.0 | 43.5 |
| C-MIL [21] | 62.5 | 58.4 | 49.5 | 32.1 | 19.8 | 70.5 | 66.1 | 63.4 | 20.0 | 60.5 | 52.9 | 53.5 | 57.4 | 68.9 | 8.4 | 24.6 | 51.8 | 58.7 | 66.7 | 63.5 | 50.5 |
| Lin et al. [22] | 55.6 | 67.0 | 45.8 | 27.9 | 21.1 | 69.0 | 68.3 | 70.5 | 21.3 | 60.2 | 40.3 | 54.5 | 56.5 | 70.1 | 12.5 | 25.0 | 52.9 | 55.2 | 65.0 | 63.7 | 50.1 |
| TSC [18] | 59.3 | 57.5 | 43.7 | 27.3 | 13.5 | 63.9 | 61.7 | 59.9 | 24.1 | 46.9 | 36.7 | 45.6 | 39.9 | 62.6 | 10.3 | 23.6 | 41.7 | 52.4 | 58.7 | 56.6 | 44.3 |
| WS-JDS [16] | 52.0 | 64.5 | 45.5 | 26.7 | 27.9 | 60.5 | 47.8 | 59.7 | 13.0 | 50.4 | 46.4 | 56.3 | 49.6 | 60.7 | 25.4 | 28.2 | 50.0 | 51.4 | 66.5 | 29.7 | 45.6 |
| SDCN [19] | 59.8 | 67.1 | 32.0 | 34.7 | 22.8 | 67.1 | 63.8 | 67.9 | 22.5 | 48.9 | 47.8 | 60.5 | 51.7 | 65.2 | 11.8 | 20.6 | 42.1 | 54.7 | 60.8 | 64.3 | 48.3 |
| Yang et al. [17] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 50.6 |
| SLV [27] | 65.6 | 71.4 | 49.0 | 37.1 | 24.6 | 69.6 | 70.3 | 70.6 | 30.8 | 63.1 | 36.0 | 61.4 | 65.3 | 68.4 | 12.4 | 29.9 | 52.4 | 60.0 | 67.6 | 64.5 | 53.5 |
| D-MIL [25] | 60.4 | 71.3 | 51.1 | 25.4 | 23.8 | 70.4 | 70.3 | 71.9 | 25.2 | 63.4 | 42.6 | 67.1 | 57.7 | 70.1 | 15.5 | 26.6 | 58.7 | 63.3 | 66.9 | 67.6 | 53.5 |
| ICL | 61.9 | 73.0 | 44.0 | 33.3 | 32.9 | 75.3 | 74.7 | 73.8 | 2.6 | 70.6 | 62.0 | 60.8 | 72.2 | 71.3 | 26.0 | 25.4 | 57.3 | 57.7 | 72.7 | 60.9 | 55.4 |
| Method | aer | bik | bir | boa | bot | bus | car | cat | cha | cow | tab | dog | hor | mot | per | pla | she | sof | tra | tv | mean |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WSDDN [20] | 65.1 | 58.8 | 58.5 | 33.1 | 39.8 | 68.3 | 60.2 | 59.6 | 34.8 | 64.5 | 30.5 | 43.0 | 56.8 | 82.4 | 25.5 | 41.6 | 61.5 | 55.9 | 65.9 | 63.7 | 53.5 |
| Kantorov et al. [14] | 83.3 | 68.6 | 54.7 | 23.4 | 18.3 | 73.6 | 74.1 | 54.1 | 8.6 | 65.1 | 47.1 | 59.5 | 67.0 | 83.5 | 35.3 | 39.9 | 67.0 | 49.7 | 63.5 | 65.2 | 55.1 |
| OICR [15] | 81.7 | 80.4 | 48.7 | 49.5 | 32.8 | 81.7 | 85.4 | 40.1 | 40.6 | 79.5 | 35.7 | 33.7 | 60.5 | 88.8 | 21.8 | 57.9 | 76.3 | 59.9 | 75.3 | 81.4 | 60.6 |
| PCL [26] | 79.6 | 85.5 | 62.2 | 47.9 | 37.0 | 83.8 | 83.4 | 43.0 | 38.3 | 80.1 | 50.6 | 30.9 | 57.8 | 90.8 | 27.0 | 58.2 | 75.3 | 68.5 | 75.7 | 78.9 | 62.7 |
| C-MIL [21] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 65.0 |
| Lin et al. [22] | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | 67.2 |
| TSC [18] | 84.2 | 74.1 | 61.3 | 52.1 | 32.1 | 76.7 | 82.9 | 66.6 | 42.3 | 70.6 | 39.5 | 57.0 | 61.2 | 88.4 | 9.3 | 54.6 | 72.2 | 60.0 | 65.0 | 70.3 | 61.0 |
| WS-JDS [16] | 82.9 | 74.0 | 73.4 | 47.1 | 60.9 | 80.4 | 77.5 | 78.8 | 18.6 | 70.0 | 56.7 | 67.0 | 64.5 | 84.0 | 47.0 | 50.1 | 71.9 | 57.6 | 83.3 | 43.5 | 64.5 |
| SDCN [19] | 85.8 | 83.1 | 56.2 | 58.5 | 44.7 | 80.2 | 85.0 | 77.9 | 29.6 | 78.8 | 53.6 | 74.2 | 73.1 | 88.4 | 18.2 | 57.5 | 74.2 | 60.8 | 76.1 | 79.2 | 66.8 |
| SLV [27] | 84.6 | 84.3 | 73.3 | 58.5 | 49.2 | 80.2 | 87.0 | 79.4 | 46.8 | 83.6 | 41.8 | 79.3 | 88.8 | 90.4 | 19.5 | 59.7 | 79.4 | 67.7 | 82.9 | 83.2 | 71.0 |
| D-MIL [25] | 81.3 | 82.0 | 72.7 | 48.9 | 42.0 | 80.2 | 86.1 | 78.5 | 43.9 | 80.2 | 42.2 | 76.5 | 68.7 | 91.2 | 32.7 | 56.0 | 81.4 | 69.6 | 78.7 | 79.9 | 68.7 |
| ICL | 85.3 | 88.9 | 65.5 | 57.5 | 57.4 | 86.0 | 90.7 | 85.8 | 15.1 | 88.7 | 78.0 | 74.4 | 89.2 | 93.5 | 39.2 | 57.6 | 88.5 | 71.6 | 86.2 | 80.1 | 74.0 |
| Method | mAP | CorLoc |
|---|---|---|
| Kantorov et al. [14] | 35.3 | 54.8 |
| OICR [15] | 37.9 | 62.1 |
| PCL [26] | 40.6 | 63.2 |
| C-MIL [21] | 46.7 | 67.4 |
| Lin et al. [22] | 45.3 | 67.1 |
| TSC [18] | 40.0 | 64.4 |
| WS-JDS [16] | 39.1 | 63.5 |
| SDCN [19] | 43.5 | 67.9 |
| SLV [27] | 49.2 | 69.2 |
| D-MIL [25] | 49.6 | 70.1 |
| ICL | 50.1 | 70.4 |
| Method | PASCAL Metrics | COCO Metrics | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | CorLoc | AP | AP | AP | AP | AP | AP | |
| Baseline | 41.2 | 60.6 | 14.9 | 37.0 | 10.7 | 1.8 | 8.6 | 19.4 |
| ICL | 55.4 | 74.0 | 20.8 | 48.8 | 14.4 | 2.3 | 10.3 | 27.1 |
| ICL w/o IMU | 53.6 | 72.9 | 19.8 | 46.8 | 14.2 | 2.8 | 10.1 | 25.9 |
| ICL w/o MIM | 49.7 | 69.6 | 18.0 | 43.1 | 12.5 | 2.1 | 8.9 | 23.8 |
| ICL w/o MPS | 52.9 | 71.4 | 19.5 | 46.7 | 13.5 | 3.3 | 10.5 | 25.0 |
| mAP | CorLoc | |
|---|---|---|
| 1/10 | 52.7 | 70.8 |
| 1/8 | 52.0 | 70.1 |
| 1/6 | 53.6 | 72.6 |
| 1/4 | 55.4 | 74.0 |
| 1/2 | 52.4 | 70.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Zeng, B. Instance-Level Contrastive Learning for Weakly Supervised Object Detection. Sensors 2022, 22, 7525. https://doi.org/10.3390/s22197525
Zhang M, Zeng B. Instance-Level Contrastive Learning for Weakly Supervised Object Detection. Sensors. 2022; 22(19):7525. https://doi.org/10.3390/s22197525
Chicago/Turabian StyleZhang, Ming, and Bing Zeng. 2022. "Instance-Level Contrastive Learning for Weakly Supervised Object Detection" Sensors 22, no. 19: 7525. https://doi.org/10.3390/s22197525