
Night Vision Anti-Halation Method Based on Infrared and Visible Video Fusion


Abstract
:1. Introduction
2. Principle and Method
3. Fusion Strategy of Frame Selection Based on Inter-Frame Difference
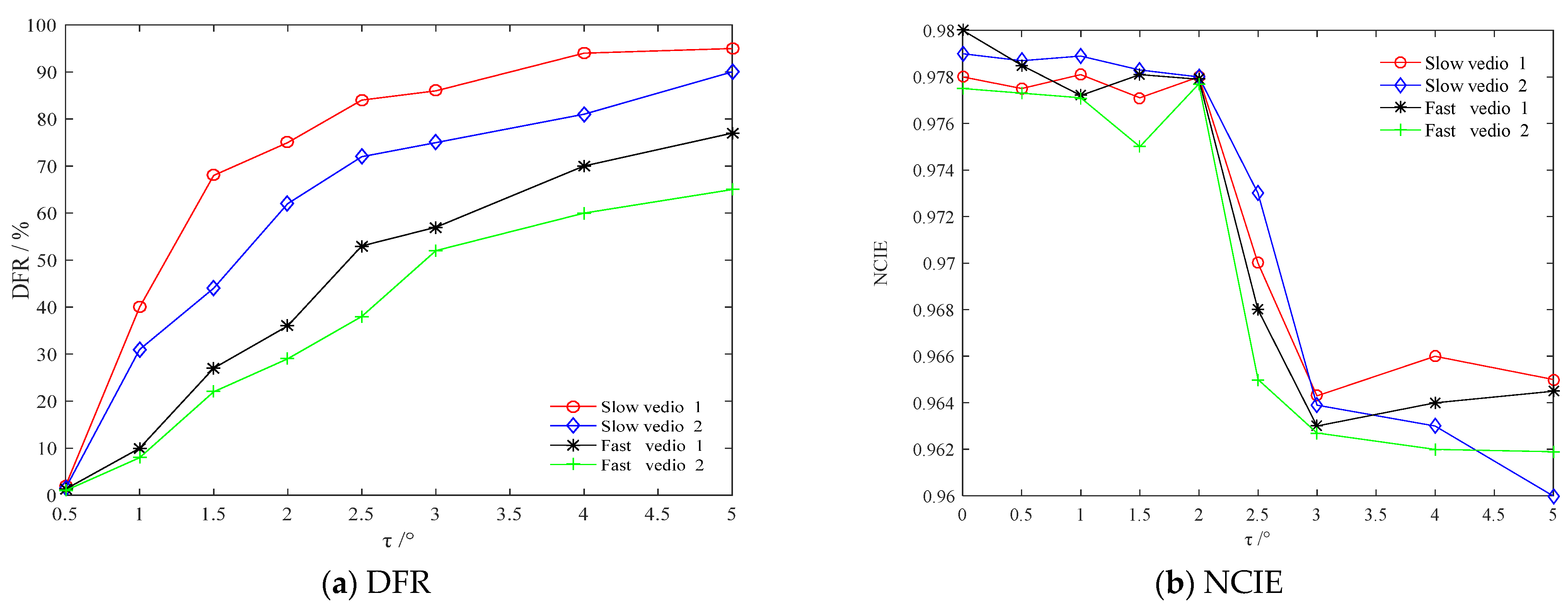
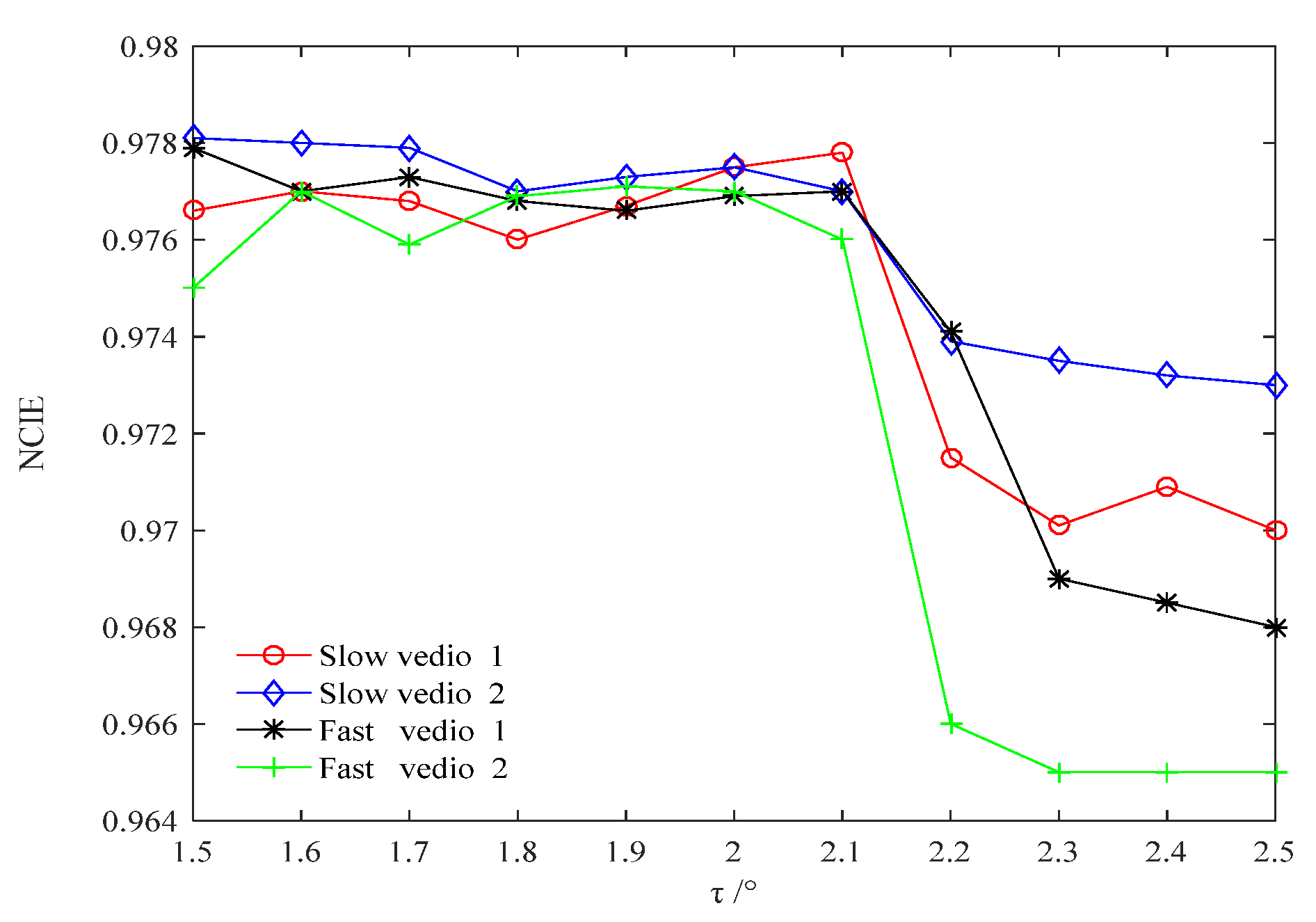
3.1. Quantization of Inter-Frame Difference
3.2. Setting of Cosine Angle Threshold
3.3. Implementation of Frame Selection Fusion
- (1)
- Initialization:
- S[0]←ZR←1;
- ZC←2;
- ZF←3;
- count←1;
- (2)
- Iteratively select retained frames:
- while ZC < K
- {
- if (θRC < τop)
- {
- if (θRF > τop)
- {
- ZR←ZC;
- S[count]←ZC;
- count←count + 1;
- }
- else
- {
- ZC←ZC + 1;
- ZF←ZF + 1;
- }
- }
- }
- (3)
- Keep the last frame and end the frame selection.
- S[count + 1]←K.
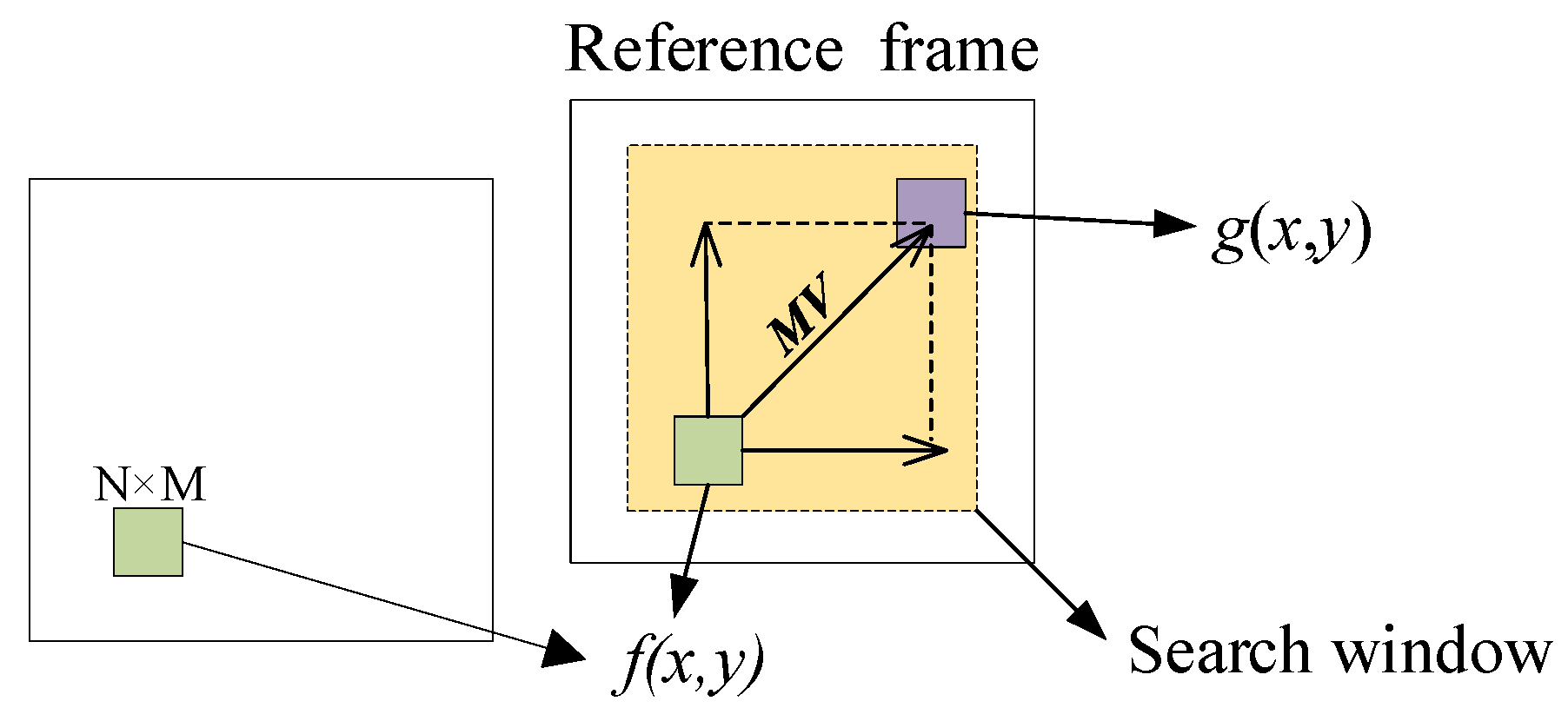
4. Time-Mark-Based Adaptive Motion Compensation Algorithm
5. Results and Discussion
5.1. Evaluation of Frame Selection
5.2. Evaluation of Frame Fusion
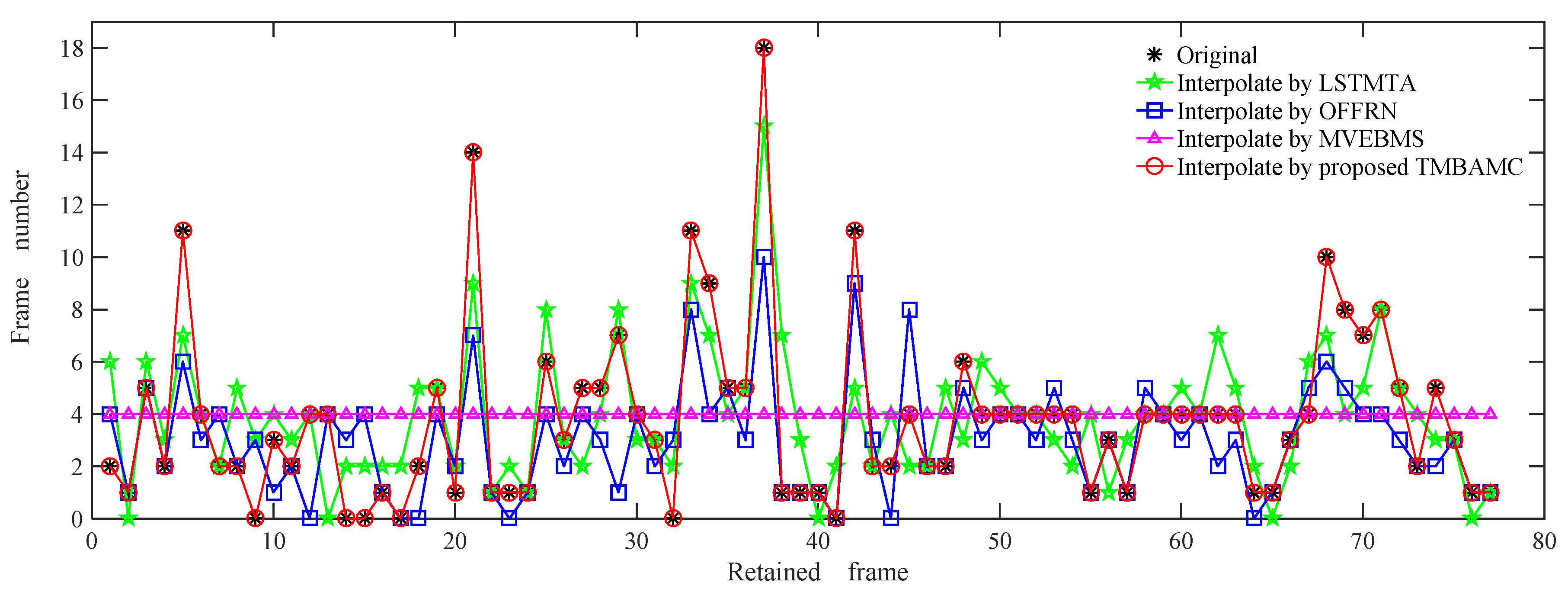
5.3. Evaluation of Frame Interpolation
5.3.1. Accuracy of Number of Frame Interpolation
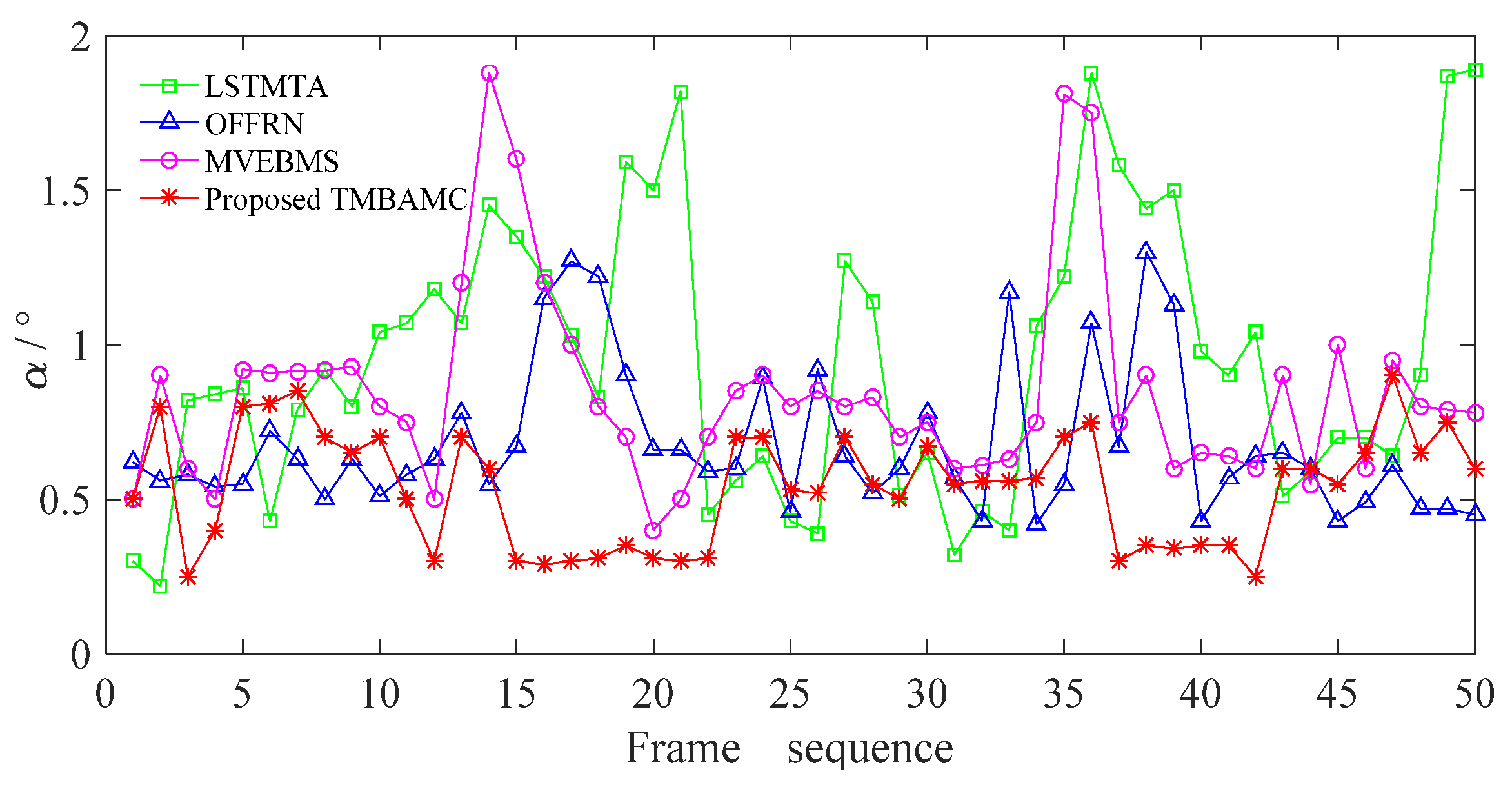
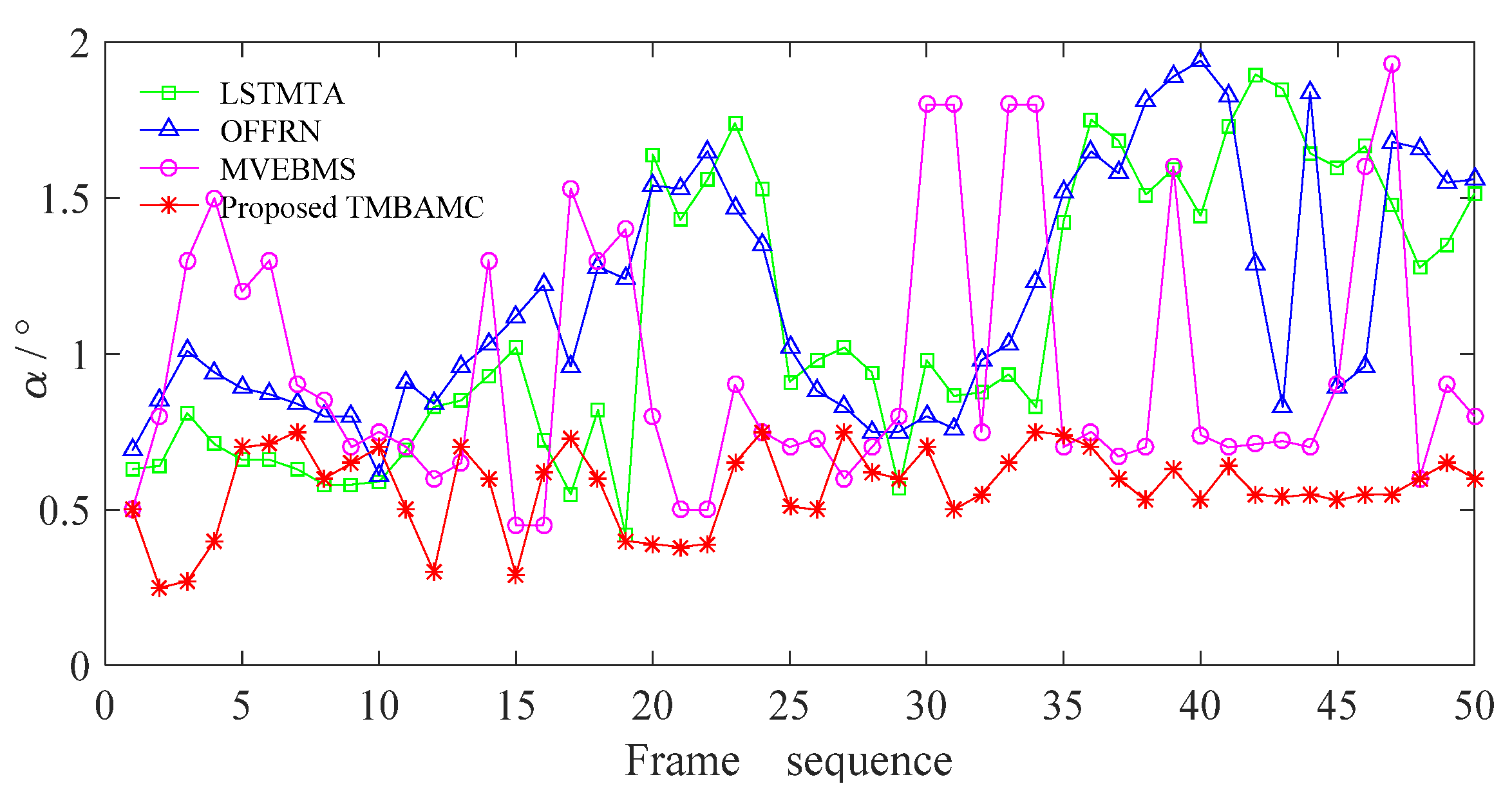
5.3.2. Synchronization of Frame Interpolation Content
5.3.3. Evaluation of Anti-Halation Performance of Video Fusion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wood-Joanne, M. Nighttime driving: Visual, lighting and visibility challenges. Ophthalmic. Physiol. Opt. 2020, 40, 187–201. [Google Scholar] [CrossRef] [Green Version]
- Patricia, A.G.; César, B.; Maria, C. Driver glare exposure with different vehicle frontlighting systems. J. Saf. Res. 2021, 76, 228–237. [Google Scholar] [CrossRef]
- Mårsell, E.; Boström, E.; Harth, A.; Losquin, A.; Guo, C.; Cheng, Y.C.; Mikkelsen, A. Spatial control of multiphoton electron excitations in InAs nanowires by varying crystal phase and light polarization. Nano Lett. 2018, 18, 907–915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nowosielski, A.; Małecki, K.; Forczmański, P.; Smoliński, A.; Krzywicki, K. Embedded night-vision system for pedestrian detection. IEEE Sens. J. 2020, 20, 9293–9304. [Google Scholar] [CrossRef]
- Yegorov, A.D.; Yegorov, V.A.; Yegorov, S.A. Dynamic range of CCD photosensors for atomic-emission analyzers. J. Appl. Spectrosc. 2019, 86, 443–448. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, Y.; Li, H. Anti-halation method of visible and infrared image fusion based on improved IHS-Curvelet transform. Infrared Laser Eng. 2018, 47, 440–448. [Google Scholar] [CrossRef]
- Ma, M.; Mei, S.; Wan, S.; Wang, Z.; Feng, D.D.; Bennamoun, M. Similarity based block sparse subset selection for video summarization. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3967–3980. [Google Scholar] [CrossRef]
- Wang, J.; Zeng, C.; Wang, Z.; Jiang, K. An improved smart key frame extraction algorithm for vehicle target recognition. Comput. Electr. Eng. 2022, 97, 107540. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, Y. Video key frame monitoring algorithm and virtual reality display based on motion vector. IEEE Access 2020, 8, 159027–159038. [Google Scholar] [CrossRef]
- Shishido, H.; Harazaki, A.; Kameda, Y.; Kitahara, I. Smooth switching method for asynchronous multiple viewpoint videos using frame interpolation. J. Vis. Commun. Image Represent. 2019, 62, 68–76. [Google Scholar] [CrossRef]
- Fang, N.; Zhan, Z. High-resolution optical flow and frame-recurrent network for video super-resolution and deblurring. Neurocomputing 2022, 489, 128–138. [Google Scholar] [CrossRef]
- Li, B.; Han, J.; Xu, Y.; Rose, K. Optical Flow Based Co-located Reference Frame for Video Compression. IEEE Trans. Image Process. 2020, 29, 8303–8315. [Google Scholar] [CrossRef] [PubMed]
- Zhan, Z.; Yang, X.; Li, Y.; Pang, C. Video deblurring via motion compensation and adaptive information fusion. Neurocomputing 2019, 341, 88–98. [Google Scholar] [CrossRef]
- Rao, K.S.; Paramkusam, A.V.; Darimireddy, N.K.; Chehri, A. Block Matching Algorithms for the Estimation of Motion in Image Sequences: Analysis. Procedia Comput. Sci. 2021, 192, 2980–2989. [Google Scholar] [CrossRef]
- Kerfa, D.; Saidane, A. An efficient algorithm for fast block matching motion estimation using an adaptive threshold scheme. Multimed. Tools Appl. 2020, 79, 1–12. [Google Scholar] [CrossRef]
- Tran, Q.N.; Yang, S. Video frame interpolation via down–up scale generative adversarial networks. Comput. Vis. Image Underst. 2022, 220, 103434. [Google Scholar] [CrossRef]
- Ye, H.; Zhang, L.; Zhang, D. Non-imaging target recognition algorithm based on projection matrix and image Euclidean distance by computational ghost imaging. Opt. Laser Technol. 2021, 137, 106779. [Google Scholar] [CrossRef]
- Liu, P.; Zeeshan, A.; Tahir, M. Some cosine similarity measures and distance measures between complex q-rung orthopair fuzzy sets and their applications. Int. J. Comput. Intell. Syst. 2021, 14, 1653. [Google Scholar] [CrossRef]
- Xia, H.; Liu, Z. Target classification of SAR images using nonlinear correlation information entropy. J. Appl. Remote Sens. 2020, 14, 036520. [Google Scholar] [CrossRef]
- Li, C.; Qi, H. Selection of multi-view SAR images via nonlinear correlation information entropy with application to target classification. Remote Sens. Lett. 2020, 11, 1100–1109. [Google Scholar] [CrossRef]
- Krishnammal, P.M.; Raja, S.S. Medical image segmentation using fast discrete curvelet transform and classification methods for MRI brain images. Multimed. Tools Appl. 2019, 79, 1–24. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, X.; Tian, Y. An image fusion method based on curvelet transform and guided filter enhancement. Math. Probl. Eng. 2020, 4, 9821715. [Google Scholar] [CrossRef]
- Su, J.K.; Mersereau, R.M. Motion estimation methods for overlapped block motion compensation. IEEE Trans. Image Process. 2000, 9, 1509–1521. [Google Scholar] [CrossRef] [PubMed]
- Bao, W.; Lai, W.S.; Zhang, X.; Gao, Z.; Yang, M.H. MEMC-Net: Motion estimation and motion compensation driven neural network for video interpolation and enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 933–948. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Video | Original Sequence | Retained Sequence by FSIFD | Retained Sequence by RFEC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| NCIE | Frames | Duration | NCIE | Frames | Duration | NCIE | Frames | Duration | |
| Fast video1 | 0.978 | 371 | 14.84 s | 0.976 | 78 | 3.12 s | 0.975 | 64 | 2.56 s |
| Slow video1 | 0.980 | 375 | 15.00 s | 0.977 | 231 | 9.24 s | 0.952 | 88 | 3.52 s |
| Algorithm | NIF * = NOF | NIF ≠ NOF | Total Frames | Duration | |||
|---|---|---|---|---|---|---|---|
| Groups | Frames | Groups (NIF > NOF) | Groups (NIF < NOF) | Frames | |||
| LSTMTA | 20 | 69 | 32 | 25 | 230 | 377 | 15.08 s |
| OFFRN | 31 | 67 | 12 | 34 | 166 | 311 | 12.44 s |
| MVEBMS | 18 | 72 | 38 | 21 | 236 | 386 | 15.44 s |
| TMBAMC | 77 | 293 | 0 | 0 | 0 | 371 | 14.84 s |
| Experiment | The Frame-By-Frame Fusion | The Proposed Method | ||||
|---|---|---|---|---|---|---|
| FPS | T(n) | S(n) | FPS | T(n) | S(n) | |
| slow video on suburban road | 1.20 | O(n3) | O(n) | 6.83 | O(n2) | O(n) |
| fast video on suburban road | 0.90 | 5.88 | ||||
| slow video on urban main road | 1.08 | 6.65 | ||||
| fast video on urban main road | 0.95 | 5.72 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Wang, H.; Yang, J. Night Vision Anti-Halation Method Based on Infrared and Visible Video Fusion. Sensors 2022, 22, 7494. https://doi.org/10.3390/s22197494
Guo Q, Wang H, Yang J. Night Vision Anti-Halation Method Based on Infrared and Visible Video Fusion. Sensors. 2022; 22(19):7494. https://doi.org/10.3390/s22197494
Chicago/Turabian StyleGuo, Quanmin, Hanlei Wang, and Jianhua Yang. 2022. "Night Vision Anti-Halation Method Based on Infrared and Visible Video Fusion" Sensors 22, no. 19: 7494. https://doi.org/10.3390/s22197494