
Thermal Infrared Tracking Method Based on Efficient Global Information Perception


Abstract
:1. Introduction
- To the best of our knowledge, we are the first to use the Transformer structure in the TIR target tracking method. In the feature extraction process, in order to balance the contradiction between global perception ability and computational complexity, the A Simple and Strong Baseline for Transformer Tracking structure is utilized for feature extraction. The feature fusion process supplements the relative position encoding to the standard Transformer structure, which allows the model to continuously consider the influence of positional relationships during the learning process, and can generalize to capture the different positional information for different input sequences, so that the Transformer structure can more efficiently model the semantic information contained in images.
- The target prediction process creatively utilizes the heterogeneous bi-prediction heads. The fully connected sub-network is responsible for the classification prediction of the foreground or background, and the convolutional sub-network is responsible for the regression prediction of the target bounding box. The experiments show that the heterogeneous prediction heads can further improve the performance of the tracker.
- In order to alleviate the contradiction between the vast demand for training data of the Transformer model and the insufficient scale of the TIR target tracking dataset, the LaSOT-TIR dataset is generated based on the visible light target tracking dataset LaSOT with a generative adversarial network. After using the LaSOT-TIR dataset, the performance of the tracker on the long-term tracking task of the TIR modal targets improves significantly, and we also improve the generalization ability.
2. Related Work
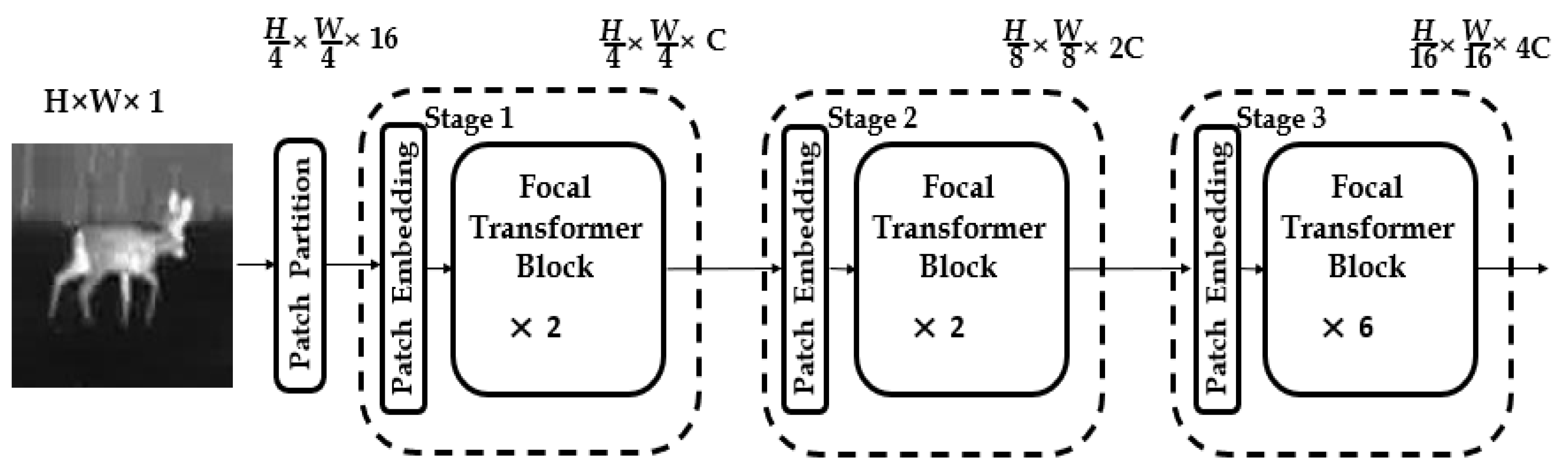
3. Methods
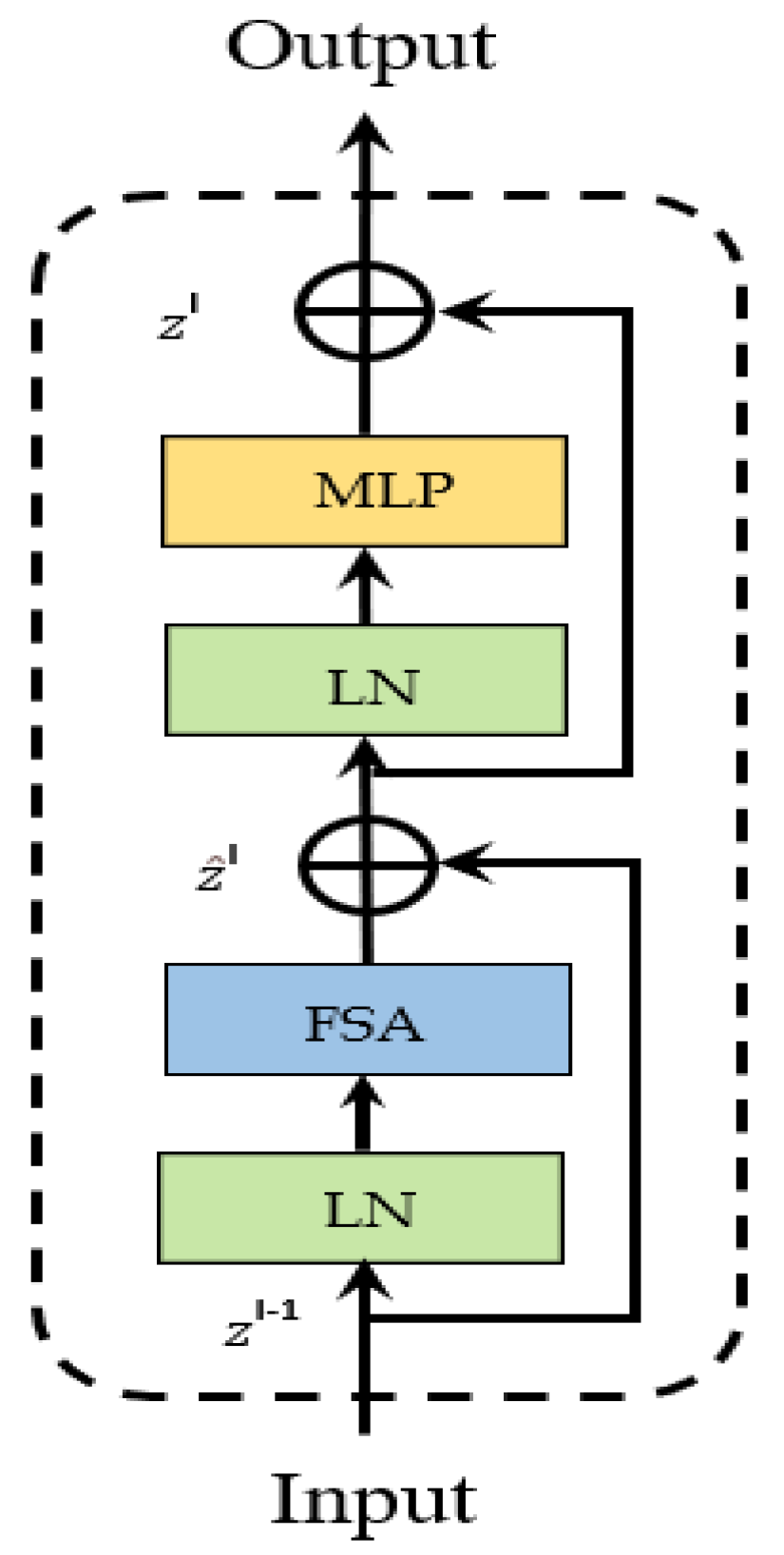
3.1. Feature Extraction Backbone Network
3.2. Feature Fusion Network
3.3. Prediction Head
4. Experiments
4.1. Network Structure
4.2. Positional Encoding
4.3. Network Training
4.3.1. LaSOT-TIR Dataset Generation
4.3.2. Offline Training
4.3.3. Online Reasoning
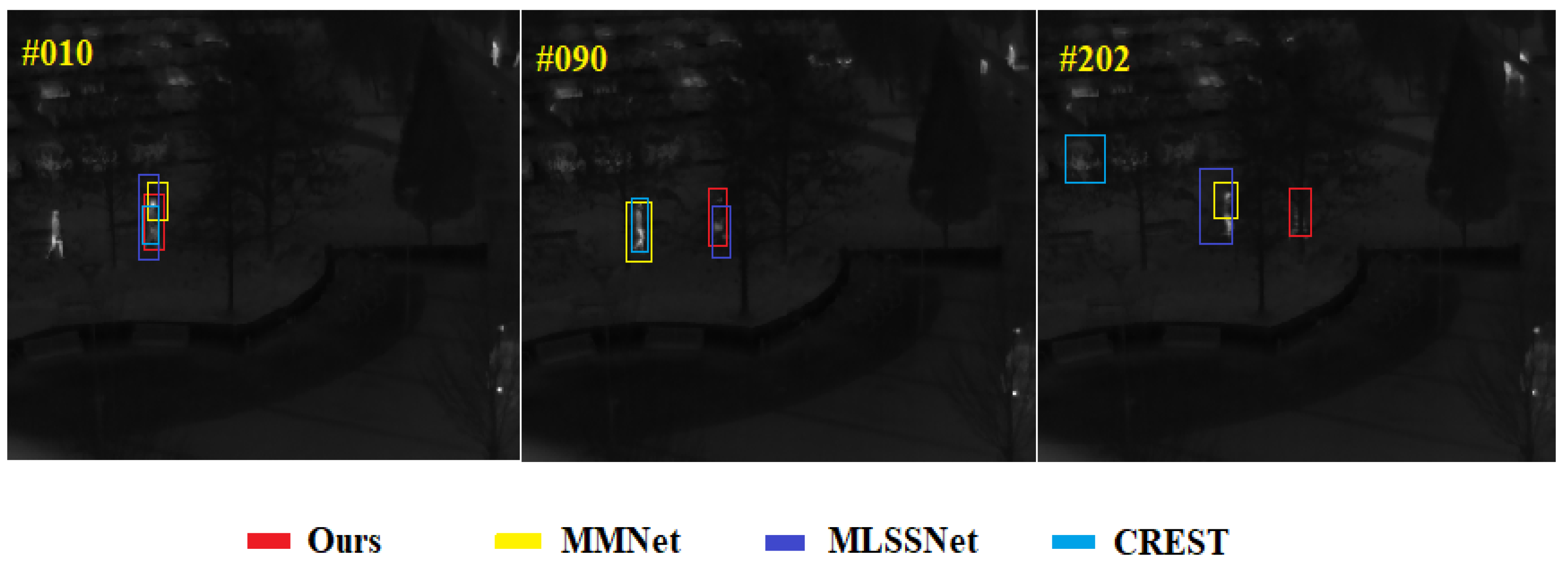
4.4. Performance Evaluation
4.4.1. VOT2015-TIR and VOT2017-TIR Dataset
4.4.2. PTB-TIR Dataset
4.4.3. LSOTB-TIR Dataset
4.4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Li, C.; Liang, X.; Lu, Y. RGB-T Object Tracking: Benchmark and Baseline. J. Pattern Recognit. 2019, 96, 106–117. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; He, Z.; Li, C.; Zheng, F. LSOTB-TIR:A Large-Scale High-Diversity Thermal Infrared Object Tracking Benchmark. In Proceedings of the ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Felsberg, M.; Kristan, M. The Thermal Infrared Visual Object Tracking VOT 2016 Challenge Results. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 824–849. [Google Scholar]
- Song, Y.; Chao, M.; Gong, L.; Zhang, J.; Yang, M.H. CREST: Convolutional Residual Learning for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2574–2583. [Google Scholar]
- Li, X.; Ma, C.; Wu, B. Target-Aware Deep Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1369–1378. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the International Conference on Neural Information Processing Systems, Long Beach, LA, USA, 4–9 December 2017; pp. 109–125. [Google Scholar]
- Yang, J.; Li, C.; Zhang, P. Focal Self-attention for Local-Global Interactions in Vision Transformers. In Proceedings of the International Conference on Neural Information Processing Systems, Online, 6–14 December 2021; pp. 309–324. [Google Scholar]
- Ye, Y.; Liu, S.; Sun, Q.; Liu, H.J.; Liu, B.; Yang, H.; Wu, Y.F. Application of Improved Particle Filter Algorithm in Deep Space Infrared Small Target Tracking. J. Acta Electron. Sin. 2015, 43, 1503–1512. [Google Scholar]
- Zhang, Y.; Tian, Y.; Yang, F.; Huang, B. Tracking of Infrared Small-Target Based on Improved Mean-Shift Algoeirhm. J. Infrared Laser Eng. 2014, 43, 2164–2169. [Google Scholar]
- Comaniciu, D.; Ramesh, V.; Meer, P. Real-time tracking of non-rigid objects using mean shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 15 June 2000; pp. 142–149. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar]
- Liu, Q.; Lu, X.; He, Z.; Zhang, C.; Chen, W. Deep Convolutional Neural Networks for Thermal Infrared Object Tracking. J. Knowl.-Based Syst. 2017, 134, 189–198. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; He, Z.; Fan, N.; Liang, Y. Multi-Task Driven Feature Models for Thermal Infrared Tracking. In Proceedings of the Thirty-Third AAAI Conference on Artifificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Shi, J.; Chen, R.; Wang, H. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 177–190. [Google Scholar]
- Liu, S.; Zhang, R.; Zhao, S. Infrared Pedestrian Target Tracking Method Based on Video Prediction. J. Harbin Inst. Technol. 2020, 52, 192–200. [Google Scholar]
- Li, M.; Peng, L.; Chen, Y.; Huang, S.; Qin, F.; Peng, Z. Mask Sparse Representation Based on Semantic Features for Thermal Infrared Target Tracking. J. Remote Sens. 2019, 11, 1967. [Google Scholar] [CrossRef]
- Wu, H.; Li, W.; Li, W.; Liu, G. A Real Time Robust Approach for Tracking UAVs in Infrared Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 4448–4455. [Google Scholar]
- Zulkifley, M.A. Two streams multiple-model object tracker for thermal infrared video. J. IEEE Access 2019, 7, 32383–32392. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (Virtual), Online, 3–7 May 2021; pp. 105–120. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8122–8131. [Google Scholar]
- Yan, B.; Peng, H.; Fu, J. Learning Spatio-Temporal Transformer for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10428–10437. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L. Rethinking Classification and Localization for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10183–10192. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. arXiv 2018, arXiv:1803.0215. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M. Generative Adversarial Nets. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, US, USA, 6–9 May 2019; pp. 321–334. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the European Conference on Computer Vision Workshops, Amsterdam, The Netherlands, 3–8 November 2016; pp. 850–865. [Google Scholar]
- Felsberg, M.; Berg, A.; Hager, G. The Thermal Infrared Visual Object Tracking VOT-TIR2015 Challenge Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Santiago, Chile, 7–13 December 2015; pp. 639–651. [Google Scholar]
- Kristan, M.; Leonardis, A. The Visual Object Tracking vot2017 Challenge Results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 1949–1972. [Google Scholar]
- Qiao, L.; He, Z. PTB-TIR: A Thermal Infrared Pedestrian Tracking Benchmark. IEEE Trans. Multimed. 2020, 22, 666–675. [Google Scholar]
- Liu, Q.; Li, X.; He, Z. Learning Deep Multi-Level Similarity for Thermal Infrared Object Tracking. IEEE Trans. Multimed. 2020, 99, 2114–2126. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracking Method | VOT2015-TIR | VOT2017-TIR | Speed | ||||
|---|---|---|---|---|---|---|---|
| EAO↑ | Acc↑ | Rob↓ | EAO↑ | Acc↑ | Rob↓ | FPS | |
| Ours | 0.356 | 0.65 | 2.01 | 0.338 | 0.63 | 2.56 | 90.0 |
| MMNet | 0.344 | 0.61 | 2.09 | 0.320 | 0.58 | 2.91 | 18.9 |
| MLSSNet | 0.329 | 0.57 | 2.42 | 0.286 | 0.56 | 3.11 | 18.0 |
| CREST | 0.258 | 0.62 | 3.11 | 0.252 | 0.59 | 3.26 | 0.6 |
| TADT | 0.234 | 0.61 | 3.33 | 0.262 | 0.60 | 3.18 | 42.7 |
| SRDCF | 0.225 | 0.62 | 3.06 | 0.197 | 0.59 | 3.84 | 12.3 |
| Siamese-FC | 0.219 | 0.60 | 4.10 | 0.225 | 0.57 | 4.29 | 66.9 |
| Backbone Network | Prediction Head Network | VOT2017-TIR | ||
|---|---|---|---|---|
| EAO↑ | Acc↑ | Rob↓ | ||
| Focal Transformer | FC (cla.) + CNN (reg.) | 0.338 | 0.63 | 2.56 |
| Focal Transformer | FC (cla.) + FC (reg.) | 0.335 | 0.58 | 2.59 |
| Focal Transformer | CNN (cla.) + CNN (reg.) | 0.331 | 0.60 | 2.61 |
| ResNet-50 | FC (cla.) + CNN (reg.) | 0.325 | 0.55 | 2.76 |
| ResNet-50 | FC (cla.) + FC (reg.) | 0.323 | 0.51 | 2.79 |
| ResNet-50 | CNN (cla.) + CNN (reg.) | 0.319 | 0.53 | 2.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Liu, X.; Ren, H.; Xue, L. Thermal Infrared Tracking Method Based on Efficient Global Information Perception. Sensors 2022, 22, 7408. https://doi.org/10.3390/s22197408
Zhao L, Liu X, Ren H, Xue L. Thermal Infrared Tracking Method Based on Efficient Global Information Perception. Sensors. 2022; 22(19):7408. https://doi.org/10.3390/s22197408
Chicago/Turabian StyleZhao, Long, Xiaoye Liu, Honge Ren, and Lingjixuan Xue. 2022. "Thermal Infrared Tracking Method Based on Efficient Global Information Perception" Sensors 22, no. 19: 7408. https://doi.org/10.3390/s22197408