

Lightweight Depth Completion Network with Local Similarity-Preserving Knowledge Distillation
 , , , , and
, , , , and
Abstract
:1. Introduction
2. Method
2.1. Problem Formulation
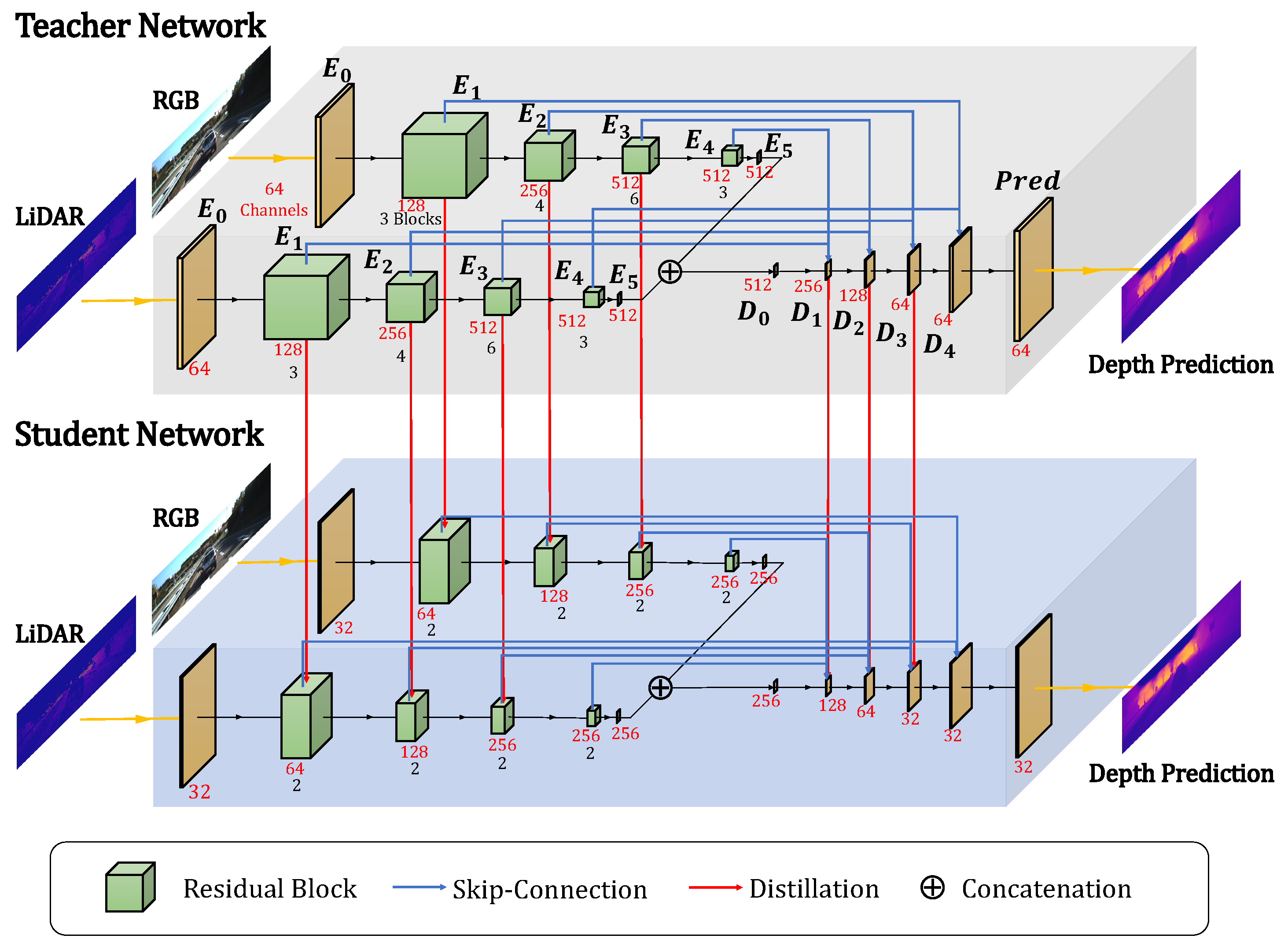
2.2. Network Architecture
2.3. Local Similarity-Preserving Knowledge Distillation
2.4. Training Lightweight Depth Completion Network
3. Experiments
3.1. Implementation Details
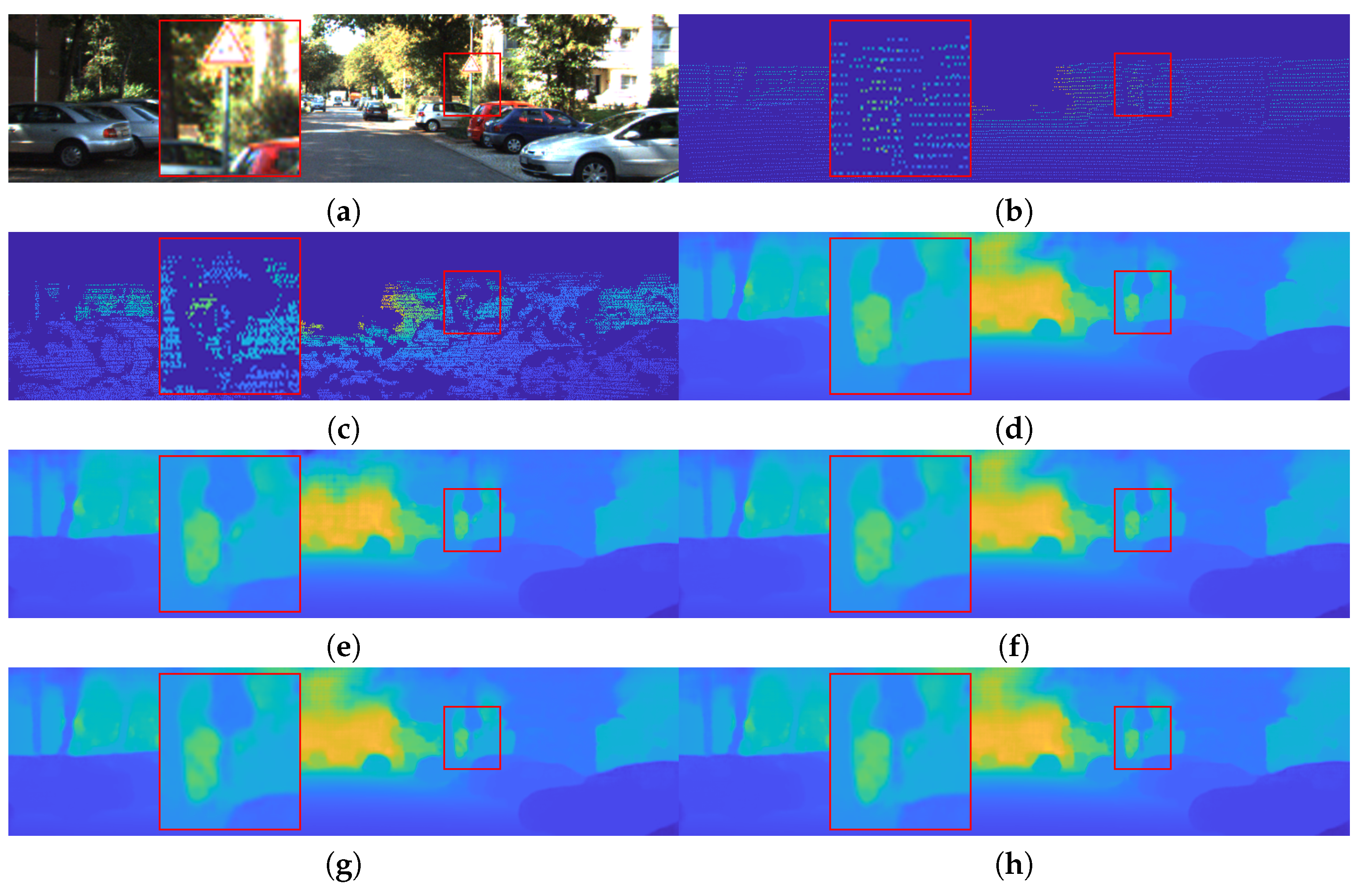
3.2. KITTI Depth Completion
3.3. NYU Depth V2
3.4. Ablation Studies
3.4.1. Layer Selection for Distillation
3.4.2. Sparsity of Supervision
3.4.3. Comparison to Global Similarity-Preserving KD
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ettinger, S.; Cheng, S.; Caine, B.; Liu, C.; Zhao, H.; Pradhan, S.; Chai, Y.; Sapp, B.; Qi, C.R.; Zhou, Y.; et al. Large Scale Interactive Motion Forecasting for Autonomous Driving: The Waymo Open Motion Dataset. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9710–9719. [Google Scholar]
- Wilson, B.; Qi, W.; Agarwal, T.; Lambert, J.; Singh, J.; Khandelwal, S.; Pan, B.; Kumar, R.; Hartnett, A.; Pontes, J.K.; et al. Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), Virtual Event, 6–14 December 2021; Available online: https://nips.cc/Conferences/2021 (accessed on 28 September 2022).
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Fong, W.K.; Mohan, R.; Hurtado, J.V.; Zhou, L.; Caesar, H.; Beijbom, O.; Valada, A. Panoptic nuscenes: A large-scale benchmark for lidar panoptic segmentation and tracking. IEEE Robot. Autom. Lett. 2022, 7, 3795–3802. [Google Scholar] [CrossRef]
- Malawade, A.V.; Mortlock, T.; Al Faruque, M.A. HydraFusion: Context-Aware Selective Sensor Fusion for Robust and Efficient Autonomous Vehicle Perception. In Proceedings of the 2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS), Milano, Italy, 4–6 May 2022; pp. 68–79. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-Ensembling Single-Stage Object Detector from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-Level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13039–13048. [Google Scholar]
- Ma, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4796–4803. [Google Scholar]
- Cheng, X.; Wang, P.; Yang, R. Depth estimation via affinity learned with convolutional spatial propagation network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 103–119. [Google Scholar]
- Park, J.; Joo, K.; Hu, Z.; Liu, C.K.; Kweon, I.S. Non-Local Spatial Propagation Network for Depth Completion. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Tao, Z.; Shuguo, P.; Hui, Z.; Yingchun, S. Dilated U-block for lightweight indoor depth completion with sobel edge. IEEE Signal Process. Lett. 2021, 28, 1615–1619. [Google Scholar] [CrossRef]
- Zhao, T.; Pan, S.; Gao, W.; Sheng, C.; Sun, Y.; Wei, J. Attention Unet++ for lightweight depth estimation from sparse depth samples and a single RGB image. Vis. Comput. 2022, 38, 1619–1630. [Google Scholar] [CrossRef]
- Xu, X.; Zou, Q.; Lin, X.; Huang, Y.; Tian, Y. Integral knowledge distillation for multi-person pose estimation. IEEE Signal Process. Lett. 2020, 27, 436–440. [Google Scholar] [CrossRef]
- Liu, T.; Zhao, R.; Xiao, J.; Lam, K.M. Progressive Motion Representation Distillation With Two-Branch Networks for Egocentric Activity Recognition. IEEE Signal Process. Lett. 2020, 27, 1320–1324. [Google Scholar] [CrossRef]
- Yoon, D.; Park, J.; Cho, D. Lightweight deep cnn for natural image matting via similarity-preserving knowledge distillation. IEEE Signal Process. Lett. 2020, 27, 2139–2143. [Google Scholar] [CrossRef]
- Yang, C.; Zhou, H.; An, Z.; Jiang, X.; Xu, Y.; Zhang, Q. Cross-image relational knowledge distillation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 12319–12328. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1365–1374. [Google Scholar]
- Qu, C.; Nguyen, T.; Taylor, C. Depth Completion via Deep Basis Fitting. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–7 October 2020. [Google Scholar]
- Hu, J.; Bao, C.; Ozay, M.; Fan, C.; Gao, Q.; Liu, H.; Lam, T.L. Deep Depth Completion from Extremely Sparse Data: A Survey. arXiv 2022, arXiv:2205.05335. [Google Scholar] [CrossRef]
- Chen, L.; Li, Q. An Adaptive Fusion Algorithm for Depth Completion. Sensors 2022, 22, 4603. [Google Scholar] [CrossRef] [PubMed]
- Lee, B.U.; Jeon, H.G.; Im, S.; Kweon, I.S. Depth completion with deep geometry and context guidance. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3281–3287. [Google Scholar]
- Lee, B.U.; Lee, K.; Kweon, I.S. Depth Completion using Plane-Residual Representation. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13916–13925. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. In Proceedings of the Neural Information Processing Systems Workshops (NeurIPSW), Montreal, QC, Canada, 11–12 December 2015. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Levin, A.; Lischinski, D.; Weiss, Y. A closed-form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 228–242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; De Mello, S.; Gu, J.; Zhong, G.; Yang, M.H.; Kautz, J. Learning affinity via spatial propagation networks. Proc. Adv. Neural Inf. Process. Syst. 2017, 2017, 1521–1531. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Proc. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Passalis, N.; Tefas, A. Learning deep representations with probabilistic knowledge transfer. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 268–284. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Uhrig, J.; Schneider, N.; Schneider, L.; Franke, U.; Brox, T.; Geiger, A. Sparsity invariant cnns. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October; IEEE: Piscataway, NJ, USA, 2017; pp. 11–20. [Google Scholar]
- Ma, F.; Cavalheiro, G.V.; Karaman, S. Self-supervised sparse-to-dense: Self-supervised depth completion from lidar and monocular camera. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May; IEEE: Piscataway, NJ, USA, 2019; pp. 3288–3295. [Google Scholar]
- Qiu, J.; Cui, Z.; Zhang, Y.; Zhang, X.; Liu, S.; Zeng, B.; Pollefeys, M. Deeplidar: Deep surface normal guided depth prediction for outdoor scene from sparse lidar data and single color image. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3313–3322. [Google Scholar]



{kind=link}
{kind=link}
| Network | # Params (M)/GFLOPs (912 × 220) | Distillation | Metrics | |||
|---|---|---|---|---|---|---|
| RMSE | MAE | iRMSE | iMAE | |||
| Self S2D [33] | 26.11/637.89 | - | 878.6 | 260.9 | 3.3 | 1.3 |
| ResNet34 (T) | 51.77/349.36 | - | 865.2 | 222.1 | 2.4 | 1.0 |
| ResNet18 (S) | 8.56/59.22 | - | 921.5 | 233.3 | 2.7 | 1.0 |
| ResNet18 (D) | 8.56/59.22 | PROB [30] | 902.6 | 243.3 | 8.5 | 1.1 |
| ATT [31] | 907.6 | 245.0 | 2.7 | 1.1 | ||
| Ours | 893.0 | 234.9 | 2.8 | 1.0 | ||
| Ours + PROB | 893.7 | 238.6 | 2.6 | 1.0 | ||
| Ours + ATT | 893.3 | 243.5 | 2.6 | 1.0 | ||
| Ours + PROB + ATT | 891.8 | 238.6 | 2.7 | 1.0 | ||
| Network | # Params (M)/GFLOPs (304 × 228) | Distillation | Metrics | ||||
|---|---|---|---|---|---|---|---|
| RMSE | REL | ||||||
| S2D + SPN [8,27] | 31.88/24.53 | - | 172.0 | 0.0310 | 0.9710 | 0.9940 | 0.9980 |
| DeepLiDAR [34] | 143.98/502.12 | - | 115.0 | 0.0220 | 0.9930 | 0.9990 | 1.0000 |
| ResNet34 (T) | 51.77/112.32 | - | 114.4 | 0.0184 | 0.9932 | 0.9989 | 0.9998 |
| ResNet18 (S) | 0.66/1.46 | - | 152.1 | 0.0282 | 0.9875 | 0.9978 | 0.9995 |
| ResNet18 (D) | 0.66/1.46 | PROB [30] | 154.8 | 0.0328 | 0.9891 | 0.9982 | 0.9996 |
| ATT [31] | 149.9 | 0.0302 | 0.9891 | 0.9982 | 0.9996 | ||
| Ours | 138.8 | 0.0248 | 0.9899 | 0.9984 | 0.9997 | ||
| Ours + PROB | 138.9 | 0.0249 | 0.9900 | 0.9984 | 0.9997 | ||
| Ours + ATT | 138.7 | 0.0248 | 0.9899 | 0.9984 | 0.9997 | ||
| Ours + PROB + ATT | 143.6 | 0.0268 | 0.9899 | 0.9984 | 0.9997 | ||
| Encoder | Decoder | Metrics | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E0 | E1 | E2 | E3 | E4 | D0 | D1 | D2 | D3 | D4 | RMSE | MAE | iRMSE | iMAE |
| - | - | ✓ | ✓ | ✓ | - | - | - | - | - | 899.3 | 241.8 | 2.7 | 1.1 |
| - | - | - | - | - | ✓ | ✓ | ✓ | - | - | 897.1 | 239.9 | 2.9 | 1.0 |
| - | ✓ | ✓ | ✓ | - | - | - | - | - | - | 894.4 | 235.5 | 2.5 | 1.0 |
| - | - | - | - | - | - | ✓ | ✓ | ✓ | - | 896.4 | 237.9 | 2.6 | 1.0 |
| ✓ | ✓ | ✓ | - | - | - | - | - | - | - | 901.7 | 239.4 | 2.8 | 1.1 |
| - | - | - | - | - | - | - | ✓ | ✓ | ✓ | 899.8 | 242.0 | 2.6 | 1.0 |
| ✓ | ✓ | ✓ | ✓ | - | - | - | - | - | - | 898.1 | 237.2 | 2.6 | 1.0 |
| - | - | - | - | - | - | ✓ | ✓ | ✓ | ✓ | 894.1 | 238.3 | 2.6 | 1.0 |
| - | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | 902.8 | 236.7 | 2.7 | 1.0 |
| - | ✓ | ✓ | ✓ | - | - | ✓ | ✓ | ✓ | - | 893.0 | 234.9 | 2.8 | 1.0 |
| ✓ | ✓ | ✓ | - | - | - | - | ✓ | ✓ | ✓ | 898.7 | 236.8 | 2.6 | 1.0 |
| ✓ | ✓ | ✓ | ✓ | - | - | ✓ | ✓ | ✓ | ✓ | 894.9 | 235.7 | 2.6 | 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, Y.; Park, J.; Cho, D.; Hwang, Y.; Choi, S.B.; Kweon, I.S. Lightweight Depth Completion Network with Local Similarity-Preserving Knowledge Distillation. Sensors 2022, 22, 7388. https://doi.org/10.3390/s22197388
Jeong Y, Park J, Cho D, Hwang Y, Choi SB, Kweon IS. Lightweight Depth Completion Network with Local Similarity-Preserving Knowledge Distillation. Sensors. 2022; 22(19):7388. https://doi.org/10.3390/s22197388
Chicago/Turabian StyleJeong, Yongseop, Jinsun Park, Donghyeon Cho, Yoonjin Hwang, Seibum B. Choi, and In So Kweon. 2022. "Lightweight Depth Completion Network with Local Similarity-Preserving Knowledge Distillation" Sensors 22, no. 19: 7388. https://doi.org/10.3390/s22197388