
Comparing Handcrafted Features and Deep Neural Representations for Domain Generalization in Human Activity Recognition
 , ,
, ,  , , , and
, , , and 
Abstract
:1. Introduction
- A comparison between different data similarity measures and their relationship to generalization performance.
- A validation of the hypothesis that models based on HC features can be more robust than deep learning models for several HAR tasks in OOD settings.
- An empirical demonstration that a hybrid approach between HC features and deep representations can bridge the gap in OOD performance.
2. Related Work
3. Methodology
3.1. Datasets
3.2. Handcrafted Features
3.3. Deep Learning
3.4. Evaluation
| Algorithm 1 The algorithm procedure to compute the similarity between the two dataset T and V, using the Degree of Correspondence (DC). |
| procedure DC(: datasets, d: distance, ∂ distance metrics) For each , find , nearest neighbor of v in T Compute using a permutation procedure return DC end procedure |
4. Experiments and Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Supplementary Experiments





References
- Sousa Lima, W.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human activity recognition using inertial sensors in a smartphone: An overview. Sensors 2019, 19, 3213. [Google Scholar] [CrossRef] [PubMed]
- Ariza-Colpas, P.P.; Vicario, E.; Oviedo-Carrascal, A.I.; Butt Aziz, S.; Piñeres-Melo, M.A.; Quintero-Linero, A.; Patara, F. Human Activity Recognition Data Analysis: History, Evolutions, and New Trends. Sensors 2022, 22, 3401. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, N.; Ghazilla, R.A.R.; Khairi, N.M.; Kasi, V. Reviews on various inertial measurement unit (IMU) sensor applications. Int. J. Signal Process. Syst. 2013, 1, 256–262. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Köping, L.; Grzegorzek, M. Comparison of feature learning methods for human activity recognition using wearable sensors. Sensors 2018, 18, 679. [Google Scholar] [CrossRef] [PubMed]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2021, 426, 26–34. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, V.W.; Chen, Y.; Huang, M. Deep transfer learning for cross-domain activity recognition. In Proceedings of the 3rd International Conference on Crowd Science and Engineering, Singapore, 28–31 July 2018; pp. 1–8. [Google Scholar]
- Hoelzemann, A.; Van Laerhoven, K. Digging deeper: Towards a better understanding of transfer learning for human activity recognition. In Proceedings of the 2020 International Symposium on Wearable Computers, Virtual, 12–16 September 2020; pp. 50–54. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Nafea, O.; Abdul, W.; Muhammad, G.; Alsulaiman, M. Sensor-based human activity recognition with spatio-temporal deep learning. Sensors 2021, 21, 2141. [Google Scholar] [CrossRef]
- Sagawa, S.; Raghunathan, A.; Koh, P.W.; Liang, P. An investigation of why overparameterization exacerbates spurious correlations. In Proceedings of the 37th International Conference on Machine Learning, Virtual Conference, 13–18 July 2020; pp. 8346–8356. [Google Scholar]
- Arjovsky, M.; Bottou, L.; Gulrajani, I.; Lopez-Paz, D. Invariant risk minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- Barandas, M.; Folgado, D.; Fernandes, L.; Santos, S.; Abreu, M.; Bota, P.; Liu, H.; Schultz, T.; Gamboa, H. TSFEL: Time series feature extraction library. SoftwareX 2020, 11, 100456. [Google Scholar] [CrossRef]
- Chen, Y.; Xue, Y. A deep learning approach to human activity recognition based on single accelerometer. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 1488–1492. [Google Scholar]
- Zebin, T.; Scully, P.J.; Ozanyan, K.B. Human activity recognition with inertial sensors using a deep learning approach. In Proceedings of the 2016 IEEE Sensors, Orlando, FL, USA, 30 October 2016–3 November 2016; pp. 1–3. [Google Scholar]
- Geirhos, R.; Jacobsen, J.H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Shortcut learning in deep neural networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Gagnon-Audet, J.C.; Ahuja, K.; Darvishi-Bayazi, M.J.; Dumas, G.; Rish, I. WOODS: Benchmarks for Out-of-Distribution Generalization in Time Series Tasks. arXiv 2022, arXiv:2203.09978. [Google Scholar]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (Bigcomp), Jeju, Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. Hand-crafted features vs residual networks for human activities recognition using accelerometer. In Proceedings of the 2019 IEEE 23rd International Symposium on Consumer Technologies (ISCT), Ancona, Italy, 19–21 June 2019; pp. 153–156. [Google Scholar]
- Balcan, M.F.; Blum, A.; Srebro, N. A theory of learning with similarity functions. Mach. Learn. 2008, 72, 89–112. [Google Scholar] [CrossRef]
- Bousquet, N. Diagnostics of prior-data agreement in applied Bayesian analysis. J. Appl. Stat. 2008, 35, 1011–1029. [Google Scholar] [CrossRef]
- Kouw, W.M.; Loog, M.; Bartels, L.W.; Mendrik, A.M. Learning an MR acquisition-invariant representation using Siamese neural networks. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 364–367. [Google Scholar]
- Redko, I.; Morvant, E.; Habrard, A.; Sebban, M.; Bennani, Y. Advances in Domain Adaptation Theory; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Veen, D.; Stoel, D.; Schalken, N.; Mulder, K.; Van de Schoot, R. Using the data agreement criterion to rank experts’ beliefs. Entropy 2018, 20, 592. [Google Scholar] [CrossRef] [PubMed]
- Schat, E.; van de Schoot, R.; Kouw, W.M.; Veen, D.; Mendrik, A.M. The data representativeness criterion: Predicting the performance of supervised classification based on data set similarity. PLoS ONE 2020, 15, e0237009. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Soares, F.; de Guadiana-Romualdo, L.G.; Challa, F.; Sulejmani, A.; Seghezzi, M.; Carobene, A. The importance of being external. methodological insights for the external validation of machine learning models in medicine. Comput. Methods Programs Biomed. 2021, 208, 106288. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Zhou, F.; Jiang, Z.; Shui, C.; Wang, B.; Chaib-draa, B. Domain generalization with optimal transport and metric learning. arXiv 2020, arXiv:2007.10573. [Google Scholar]
- Shen, Z.; Liu, J.; He, Y.; Zhang, X.; Xu, R.; Yu, H.; Cui, P. Towards out-of-distribution generalization: A survey. arXiv 2021, arXiv:2108.13624. [Google Scholar]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Logacjov, A.; Bach, K.; Kongsvold, A.; Bårdstu, H.B.; Mork, P.J. HARTH: A Human Activity Recognition Dataset for Machine Learning. Sensors 2021, 21, 7853. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Chai, D.; He, J.; Zhang, X.; Duan, S. InnoHAR: A deep neural network for complex human activity recognition. IEEE Access 2019, 7, 9893–9902. [Google Scholar] [CrossRef]
- Moreira, D.; Barandas, M.; Rocha, T.; Alves, P.; Santos, R.; Leonardo, R.; Vieira, P.; Gamboa, H. Human Activity Recognition for Indoor Localization Using Smartphone Inertial Sensors. Sensors 2021, 21, 6316. [Google Scholar] [CrossRef] [PubMed]
- Gholamiangonabadi, D.; Kiselov, N.; Grolinger, K. Deep neural networks for human activity recognition with wearable sensors: Leave-one-subject-out cross-validation for model selection. IEEE Access 2020, 8, 133982–133994. [Google Scholar] [CrossRef]
- Bragança, H.; Colonna, J.G.; Oliveira, H.A.B.F.; Souto, E. How Validation Methodology Influences Human Activity Recognition Mobile Systems. Sensors 2022, 22, 2360. [Google Scholar] [CrossRef]
- Ding, R.; Li, X.; Nie, L.; Li, J.; Si, X.; Chu, D.; Liu, G.; Zhan, D. Empirical study and improvement on deep transfer learning for human activity recognition. Sensors 2018, 19, 57. [Google Scholar] [CrossRef] [PubMed]
- Ahuja, K.; Caballero, E.; Zhang, D.; Gagnon-Audet, J.C.; Bengio, Y.; Mitliagkas, I.; Rish, I. Invariance principle meets information bottleneck for out-of-distribution generalization. Adv. Neural Inf. Process. Syst. 2021, 34, 3438–3450. [Google Scholar]
- Rosenfeld, E.; Ravikumar, P.; Risteski, A. The risks of invariant risk minimization. arXiv 2020, arXiv:2010.05761. [Google Scholar]
- Boyer, P.; Burns, D.; Whyne, C. Out-of-distribution detection of human activity recognition with smartwatch inertial sensors. Sensors 2021, 21, 1669. [Google Scholar] [CrossRef]
- Trabelsi, I.; Françoise, J.; Bellik, Y. Sensor-based Activity Recognition using Deep Learning: A Comparative Study. In Proceedings of the 8th International Conference on Movement and Computing, Chicago, IL, USA, 22–24 June 2022; pp. 1–8. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a New Benchmarked Dataset for Activity Monitoring. In Proceedings of the 2012 16th Annual International Symposium on Wearable Computers (ISWC), Newcastle, UK, 18–22 June 2012; IEEE Computer Society: Washington, DC, USA, 2012; pp. 108–109. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Creating and Benchmarking a New Dataset for Physical Activity Monitoring. In Proceedings of the 5th International Conference on PErvasive Technologies Related to Assistive Environments, Heraklion, Greece, 6–8 July 2012; Association for Computing Machinery: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Fusion of smartphone motion sensors for physical activity recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef]
- Leutheuser, H.; Schuldhaus, D.; Eskofier, B.M. Hierarchical, Multi-Sensor Based Classification of Daily Life Activities: Comparison with State-of-the-Art Algorithms Using a Benchmark Dataset. PLoS ONE 2013, 8. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Garcia, R.; Holgado-Terriza, J.A.; Damas, M.; Pomares, H.; Rojas, I.; Saez, A.; Villalonga, C. mHealthDroid: A Novel Framework for Agile Development of Mobile Health Applications. In Ambient Assisted Living and Daily Activities; Pecchia, L., Chen, L.L., Nugent, C., Bravo, J., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 91–98. [Google Scholar] [CrossRef]
- Banos, O.; Villalonga, C.; Garcia, R.; Saez, A.; Damas, M.; Holgado-Terriza, J.A.; Lee, S.; Pomares, H.; Rojas, I. Design, implementation and validation of a novel open framework for agile development of mobile health applications. BioMed. Eng. Online 2015, 14. [Google Scholar] [CrossRef] [PubMed]
- Sztyler, T.; Stuckenschmidt, H. On-body Localization of Wearable Devices: An Investigation of Position-Aware Activity Recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Ferrari, A.; Mobilio, M.; Micucci, D.; Napoletano, P. On the homogenization of heterogeneous inertial-based databases for human activity recognition. In Proceedings of the 2019 IEEE World Congress on Services (SERVICES), Milan, Italy, 8–13 July 2019; Volume 2642, pp. 295–300. [Google Scholar]
- Figueira, C.; Matias, R.; Gamboa, H. Body Location Independent Activity Monitoring. In Proceedings of the 9th International Conference on Bio-inspired Systems and Signal Processing, Rome, Italy, 21–23 February 2016. [Google Scholar]
- Shakya, S.R.; Zhang, C.; Zhou, Z. Comparative study of machine learning and deep learning architecture for human activity recognition using accelerometer data. Int. J. Mach. Learn. Comput. 2018, 8, 577–582. [Google Scholar]
- Shiranthika, C.; Premakumara, N.; Chiu, H.L.; Samani, H.; Shyalika, C.; Yang, C.Y. Human Activity Recognition Using CNN & LSTM. In Proceedings of the 2020 5th International Conference on Information Technology Research (ICITR), Online, 2–4 December 2020; pp. 1–6. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Cabitza, F.; Campagner, A.; Sconfienza, L.M. As if sand were stone. New concepts and metrics to probe the ground on which to build trustable AI. BMC Med. Inform. Decis. Mak. 2020, 20, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Heckel, R.; Yilmaz, F.F. Early stopping in deep networks: Double descent and how to eliminate it. arXiv 2020, arXiv:2007.10099. [Google Scholar]
- Nakkiran, P.; Kaplun, G.; Bansal, Y.; Yang, T.; Barak, B.; Sutskever, I. Deep double descent: Where bigger models and more data hurt. J. Stat. Mech. Theory Exp. 2021, 2021, 124003. [Google Scholar] [CrossRef]
- Bai, J.; Lu, F.; Zhang, K. ONNX: Open Neural Network Exchange. Available online: https://github.com/onnx/onnx (accessed on 26 September 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
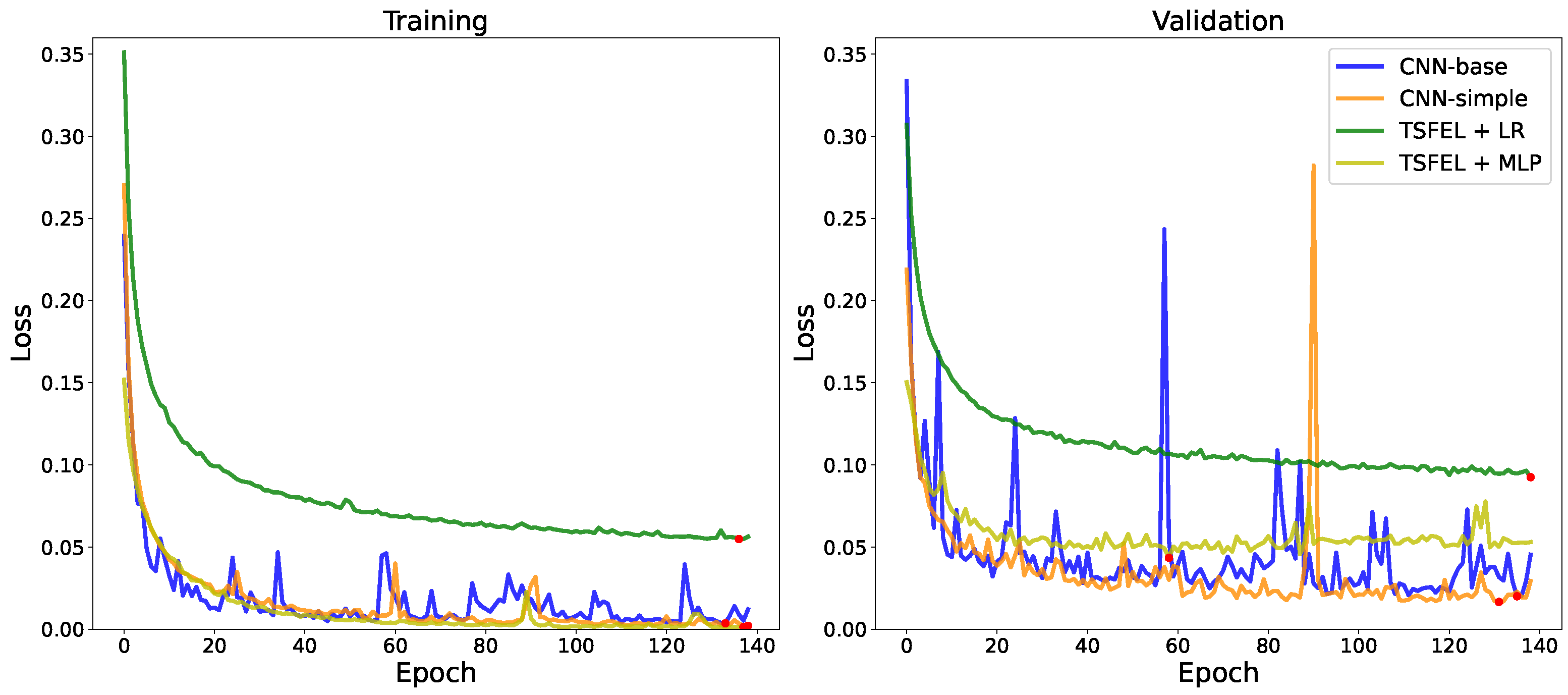{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Devices | Source |
|---|---|---|---|
| PAMAP2—Physical Activity Monitoring | 9 subjects; 18 physical activities including sitting, lying, standing, walking, ascending stairs, descending stairs and running. | Heart rate monitor (≈9 Hz); 3 inertial measurement units each containing a triaxial accelerometer, a gyroscope and a magnetometer (100 Hz); Positions: wrist, chest and ankle. | [40,41] |
| Sensors Activity Dataset (SAD) | 10 subjects; 7 physical activities: sitting, standing, walking, ascending stairs, descending stairs, running and biking. | 5 smartphones containing an accelerometer, a gyroscope and a magnetometer (50 Hz); Positions: jeans pocket, arm, wrist and belt. | [42] |
| DaLiAc—Daily Life Activities | 19 subjects; 13 physical activities including sitting, lying, standing, walking outside, ascending stairs, descending stairs and treadmill running. | 4 sensors, each with a triaxial accelerometer and gyroscope (200 Hz); Positions: hip, chest and ankles. | [43] |
| MHEALTH | 10 subjects; 12 physical activities including sitting, lying, standing, walking, climbing/descending stairs, jogging and running. | 3 wearable sensors containing an accelerometer, a gyroscope and a magnetometer. One of the sensors also provides 2-lead ECG measurements (50 Hz); Positions: chest, wrist and ankle. | [44,45] |
| RealWorld (HAR) | 15 subjects; 8 physical activities including sitting, lying, standing, walking, ascending stairs, descending stairs and running/jogging. | 6 wearable sensors containing accelerometers, gyroscopes and magnetometers (50 Hz). Also includes GPS, light and sound level sensors; Positions: chest, forearm, head, shin, thigh, upper arm, and waist. | [46] |
| Activity | Datasets (%) | Total | ||||||
|---|---|---|---|---|---|---|---|---|
| PAMAP2 | SAD | DaLiAc | MHEALTH | RealWorld | % | # | ||
| Run | 10.5 | 16.9 | 20.0 | 33.3 | 19.1 | 18.3 | 7975 | |
| Sit | 19.8 | 16.9 | 10.6 | 16.7 | 17.0 | 16.3 | 7102 | |
| Stairs | 23.6 | 32.2 | 12.3 | 16.7 | 30.0 | 26.3 | 11,460 | |
| Stand | 20.4 | 16.9 | 10.6 | 16.7 | 16.4 | 16.2 | 7047 | |
| Walk | 25.7 | 16.9 | 46.5 | 16.7 | 17.5 | 22.8 | 9927 | |
| Total | % | 12.7 | 24.4 | 15.3 | 4.96 | 42.6 | - | - |
| # | 5541 | 10,620 | 6644 | 2160 | 18,546 | - | 43,511 | |
| Metric | Setting | Avg. OOD | |||
|---|---|---|---|---|---|
| ID | OOD-U | OOD-MD | OOD-SD | ||
| Wasserstein | |||||
| MMD | |||||
| Euclidean | |||||
| DC Euclidean * | |||||
| Cosine | |||||
| DC Cosine * | |||||
| Metric | Setting | Avg. OOD | |||
|---|---|---|---|---|---|
| ID | OOD-U | OOD-MD | OOD-SD | ||
| Wasserstein | |||||
| MMD | |||||
| Euclidean | |||||
| DC Euclidean * | |||||
| Cosine | |||||
| DC Cosine * | |||||
| Model | Setting | Avg. OOD | |||
|---|---|---|---|---|---|
| ID | OOD-U | OOD-MD | OOD-SD | ||
| CNN-simple | |||||
| CNN-base | |||||
| ResNet | |||||
| CNN-simple hybrid | |||||
| CNN-base hybrid | |||||
| ResNet hybrid | |||||
| TSFEL + MLP | |||||
| TSFEL + LR | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bento, N.; Rebelo, J.; Barandas, M.; Carreiro, A.V.; Campagner, A.; Cabitza, F.; Gamboa, H. Comparing Handcrafted Features and Deep Neural Representations for Domain Generalization in Human Activity Recognition. Sensors 2022, 22, 7324. https://doi.org/10.3390/s22197324
Bento N, Rebelo J, Barandas M, Carreiro AV, Campagner A, Cabitza F, Gamboa H. Comparing Handcrafted Features and Deep Neural Representations for Domain Generalization in Human Activity Recognition. Sensors. 2022; 22(19):7324. https://doi.org/10.3390/s22197324
Chicago/Turabian StyleBento, Nuno, Joana Rebelo, Marília Barandas, André V. Carreiro, Andrea Campagner, Federico Cabitza, and Hugo Gamboa. 2022. "Comparing Handcrafted Features and Deep Neural Representations for Domain Generalization in Human Activity Recognition" Sensors 22, no. 19: 7324. https://doi.org/10.3390/s22197324