3.1. Microbiological Results
The microbial counts from the Irish and Scottish seaweed cultivated in different harvest years and stored at different temperature conditions are presented in
Table 2 and
Table 3, respectively. As can be observed, the products presented a high variability in terms of microbial quality since the initial microbial load was significantly differentiated among the three harvest years in seaweeds of both origins. Apart from the different environmental conditions during the three years (different harvest period—late June in 2019, early June in 2020 and March in 2021), post-harvest procedures and treatments may have also contributed to these differences for both sites. Previous studies have also reported a high variability in the initial microbial populations of several seaweed species [
27,
28,
29].
The storage temperature seems to play an extremely significant role in microbial growth and, subsequently, in the rate of products’ degradation, as was expected. This is evident in the products harvested in 2020, stored at four different isothermal conditions at 0, 5, 10 and 15 °C. For the products of both harvesting sites, microbial growth was remarkably delayed at low temperatures storage, whilst in seaweed from SAMS, the microbial population of samples stored at 0 °C were below 4.0 log CFU/g even after 10 days of storage. Sánchez-García et al. [
30] reported high initial microbial cell counts reaching 8.5 × 10
7 microbial cells mL
−1. Throughout the storage period, this number increased significantly, being more pronounced in the samples stored at 15 °C compared to those stored at 4 °C.
The handling of seaweed immediately after harvest is of critical importance for the microbiological quality of fresh seaweed; it is important to keep the initial microbial load as low as possible in order to extend the products’ shelf life.
As far as microorganisms’ behavior is concerned, another point worth noting is the remarkable increase in the microbial population even within 24 h. By the time point microbial counts reached the level of 5.0–6.0 log CFU/g, a rapid increase in microbial load was observed, ranging from 2.0 to 4.0 log CFU/g in almost all of the tested products (in terms of origin, harvest year and temperature), rendering the products inappropriate for consumption. A summary of the microbiological load of MI and SAMS samples for all cases and storage conditions are presented in
Table 2 and
Table 3, respectively.
Considering all the above-mentioned, the determination of the shelf life should be prioritized in such products, taking into account factors such as species, environmental conditions and storage temperature.
Taking all the aforementioned into account, the high diversity of the samples analyzed with microbiological and sensor technologies, as showcased earlier, should be underlined. Therefore, in summary, the samples used for the analysis originated from two different aquaculture sites (Ireland and Scotland), were harvested in two (in SAMS case) and three (in MI case) different years and were of different microbial quality (during data acquisition) due to storage under different temperature conditions. This high variability can definitely add value to the performed analysis since realistic conditions were simulated; on the other hand, this makes the prediction of microbial populations a hard task, garnering support for the use of generalized and robust prediction models.
3.2. FT-IR Results
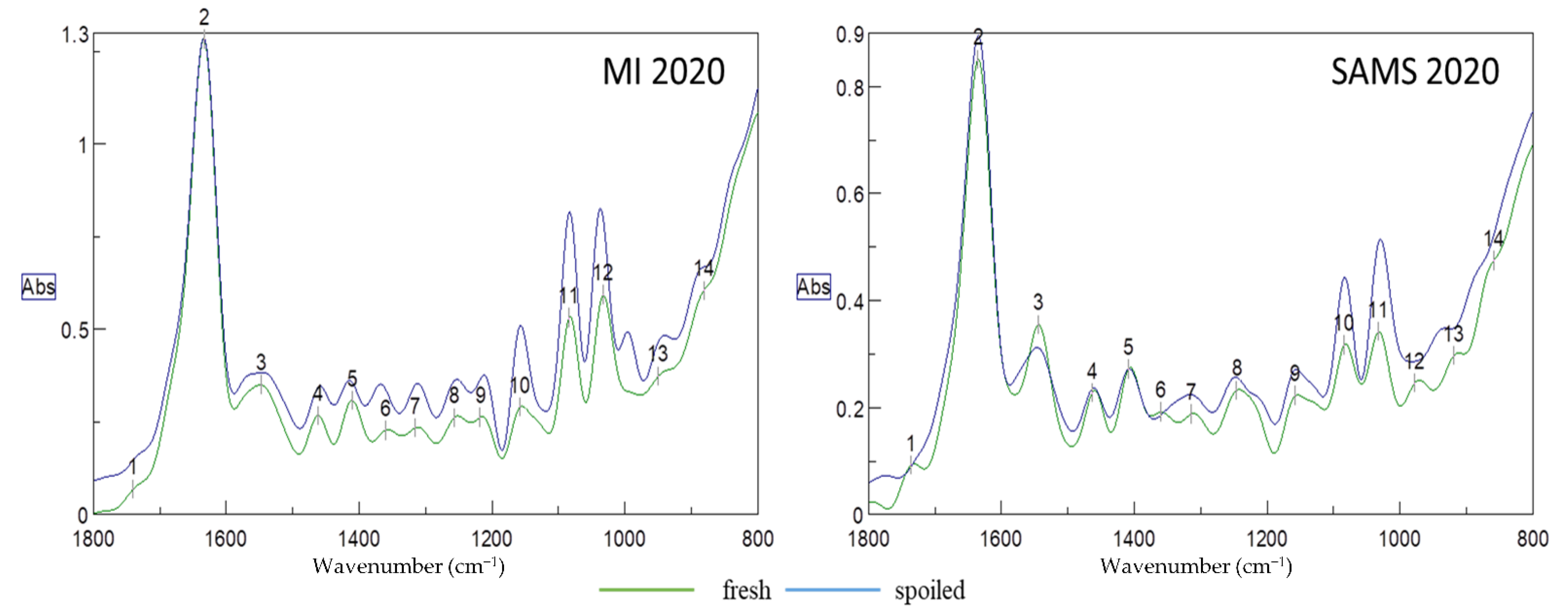
Typical deconvoluted FT-IR spectra of fresh and spoiled samples from both aquaculture sites (MI and SAMS) harvested in 2020 are presented in
Figure 1. Deconvolution is a function that analyzes bands that may contain overlapping curves and distinguishes the peak position for each band. The region of the spectrum in the range of 1800 to 800 cm
−1, can provide important information about changes occurring in specific functional groups, which are related to certain chemical groups (esters, aldehydes, alcohols, etc.) and molecules (proteins, lipids, carbohydrates). All of these groups, which are substantial components of the seaweed matrix, are subjected to changes after harvest and throughout storage which may affect the quality of the product (showing the degradation). Peak (1) at 1745 cm
−1 (
Figure 1) is related to the stretching C=O bonds of the esters of lipids and fatty acids, while the large broad peak at 1637 cm
−1 is relevant to the water content (O-H stretching). It should be noted that peaks related to chlorophyl content (1660, 1653, 1638 cm
−1) [
31] are overlapping with this large water peak, making it impossible to take them into consideration for further analysis. Peak (3) at 1548 cm
−1 is related to amide II and can be used for protein quantification. Each of the three wavenumbers, 1043 (12, MI), 1074 (11, MI), (10, SAMS) or 1156 cm
−1 (10, MI), (9, SAMS) can be used for the quantification of carbohydrates [
32]. Carbohydrates belonging to the polysaccharides group is partially of great importance in seaweed since there are certain functional compounds in this group such as alginates (1030, 1080 cm
−1) and fucoidan, a sulphate polysaccharide frequently found in brown seaweed like
A. esculenta. Bands around 1220 cm
−1 (9-MI), (8-SAMS) are assigned to the presence of sulphate ester groups (S=O, which is a characteristic component in fucoidan and other sulphated polysaccharides. Additionally, peaks at 1415–1380 cm
−1 (peak 5) are due to S=O stretching vibrations in sulphate. Brown seaweed is also known for its high content of phenolic compounds, which can be found near 1260 cm
−1. Samples from both sites exhibited a peak at 1080 cm
−1 (11-MI, 10-SAMS), which arises from C-O stretching of primary and secondary alcohols, while a similar peak at 1020 cm
−1 (12-MI, 11-SAMS) is due to C-O stretching of primary alcohols [
33]. Finally, peaks of weak bands in the range of 800 to 920 cm
−1 (13, 14) can be assigned to C-H bending vibrations which can be found in monosaccharides, such as glucose and galactose [
34].
The aforementioned functional groups, apart from being very important for the characterization of seaweed quality in general, are also of critical importance for estimating the microbiological quality as many of these compounds are expected to change during the spoilage phenomenon evolution. Certain molecules, such as sugars and proteins, are consumed by microorganisms and as microbes grow, several metabolites (alcohols, esters, aldehydes, sulphur compounds, etc.) are produced at the same time that can be imprinted on an IR spectrum.
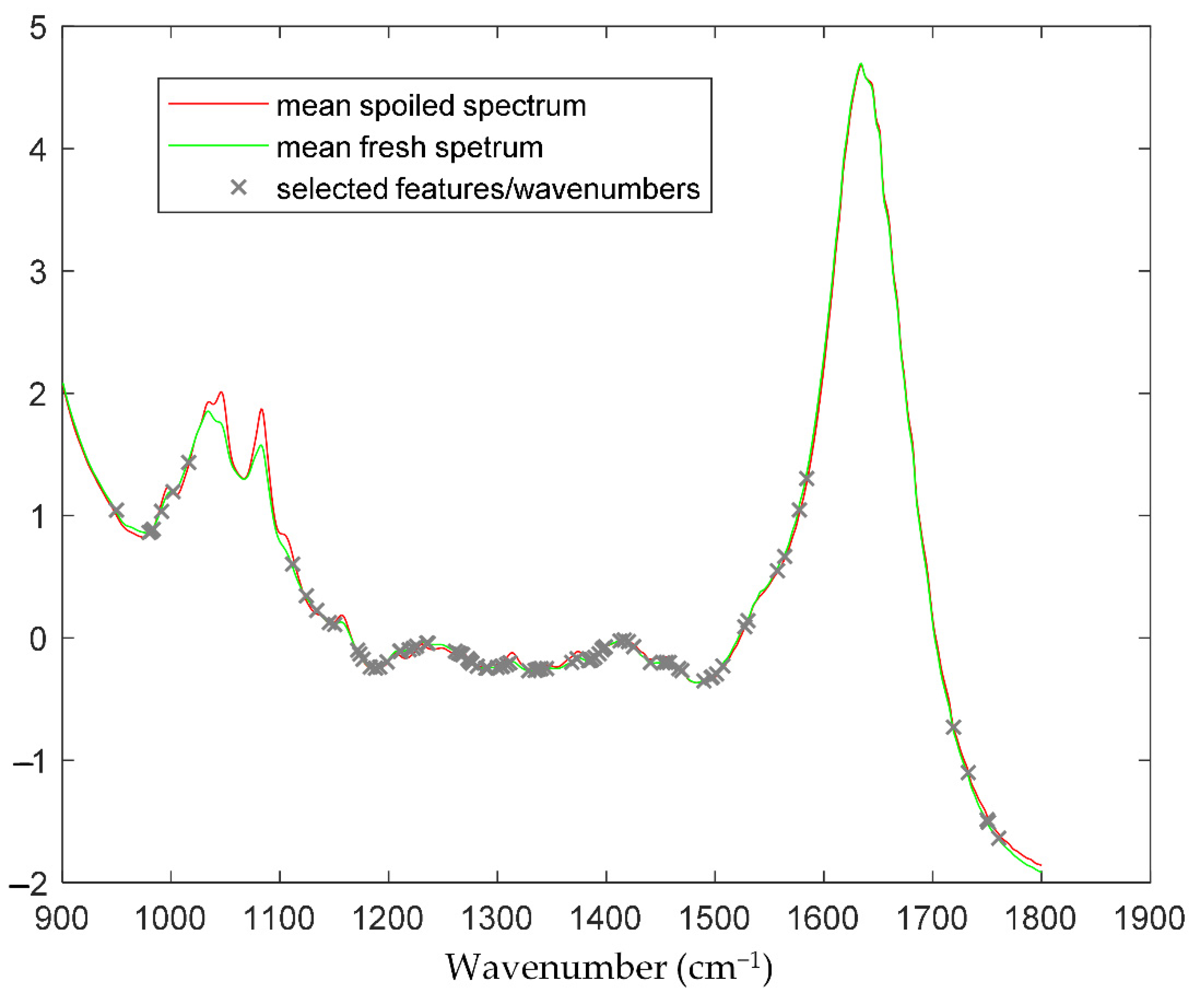
The prediction results in terms of microbial abundance (i.e., TVC values) for the data acquired with FT-IR spectroscopy are presented below. The selected features/wavenumbers are presented in
Figure 2, where it can be noticed that the critical information in terms of TVC estimation is not only located at wavenumbers where a “difference” is apparent between spoiled and fresh samples (e.g., area in [1000, 1100 cm
−1]), since this area and the corresponding features are correlated not to the TVC values but to other sources of variation, e.g., origin, harvest time or other sources. The workflow followed in order to train and evaluate/validate the efficiency and performance of the prediction model has been described in the
Section 2 (Methods Section). In order to obtain a strict efficiency evaluation, we moved as follows in terms of data separation into training and test datasets. The data for
A. esculenta MI spanned over three years of collection, i.e., 2019, 2020 and 2021. For the first two years (2019 and 2020), the sample size was 107, from which ~25% of them, specifically 28 samples, were used as an external validation dataset and the rest, i.e., 79 samples, were used as a training set. The splitting was performed using a random generator to permit a fully randomized selection of the samples. Then, all data from the 2021 harvest was kept out of the training phase and along with the 28 test samples, forming a large test/validation set of 92 data samples.
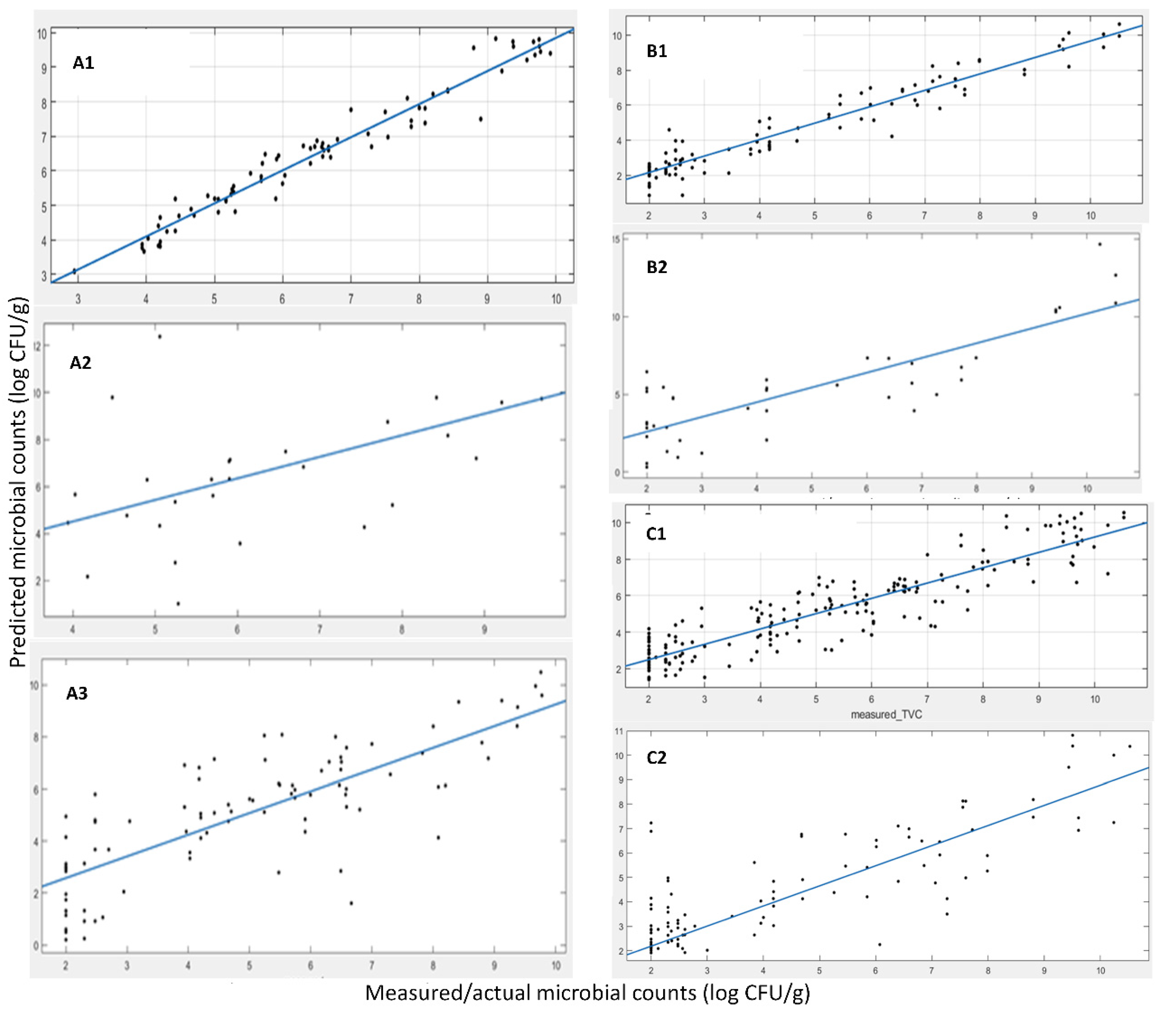
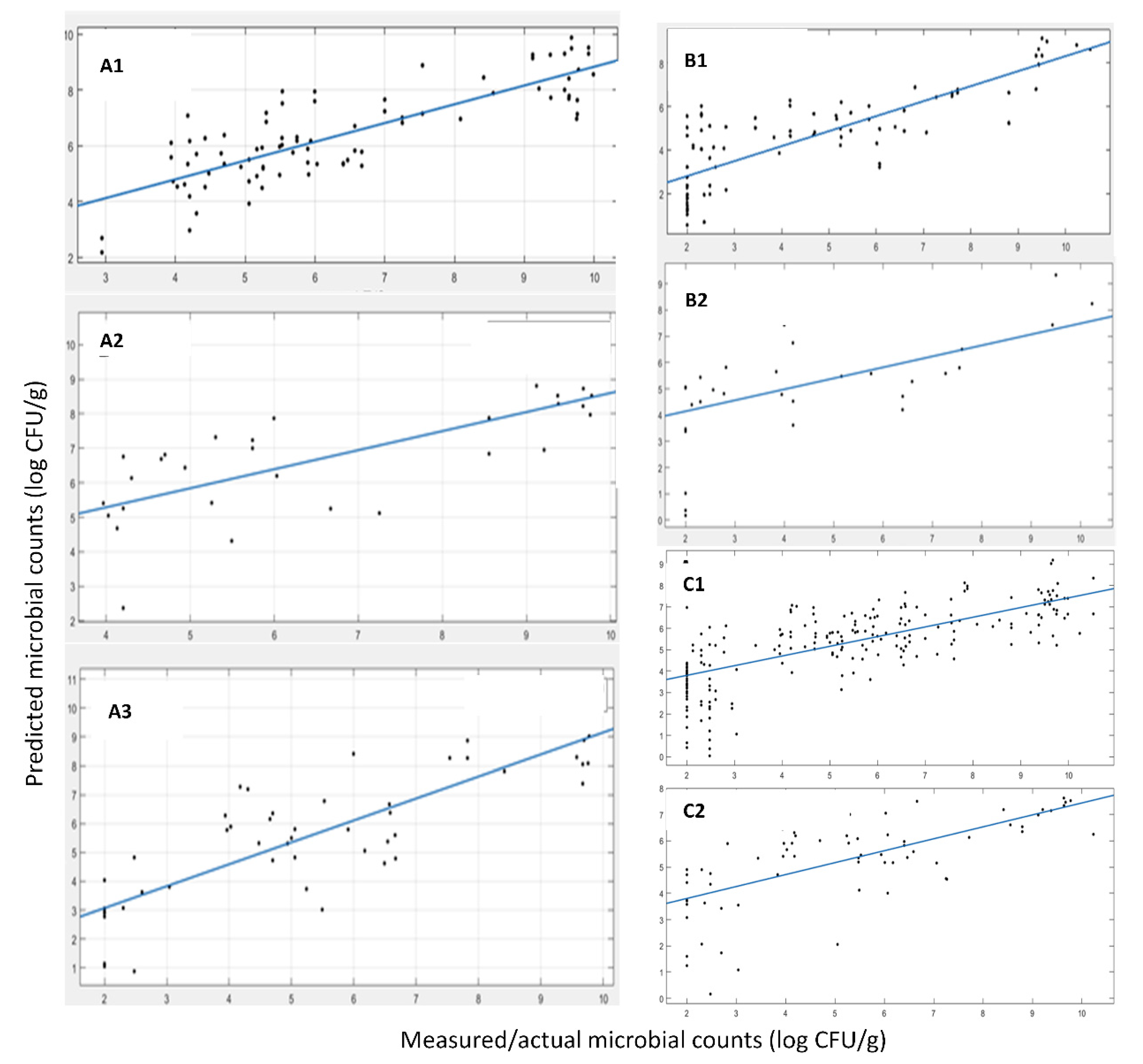
Table 4 (MI) and
Figure 3 (A-MI, B-MI, C-MI) present the results of the linear regression between the actual, measured by microbiology techniques, and the predicted TVC values.
The developed model for the FT-IR sensor with MI origin samples exhibited good performance in terms of fitting results via the linear regression (i.e., y = αx + β) with slopes of 0.96, 0.92 and 0.83 for the cross-validation phase, test phase with the 28 samples from harvests 2019 and 2020 (A) and harvests 2019, 2020 and 2021 (B), correspondingly. The R-squared values (showing the goodness of fit) were 0.96, 0.90 and 0.63, while the RMSE values were 0.38, 0.86 and 1.50, respectively. All of the above indicate a good prediction performance of the model on the external test data sets and the “worsening” of the corresponding indicators is something that is expected due to the addition of a large data set consisting of a new batch of samples (from a different year). This dataset has not been “seen” by the model during the training phase, i.e., harvest samples from 2021. The observed decrease in performance was expected due to the additional variability of samples from a completely different harvest year and also the time period of harvesting within the year. Apart from the slight performance decrement, the model and, thus, the adopted methodology, is able to identify the features, the specific wavelengths of the spectrum that are the most information-rich and relevant to the phenomenon under investigation and the TVC values, i.e., microbiological spoilage of the corresponding product. Magwaza et al. [
35] investigated the ability of PLS models using data from individual orchards and data combining orchards from two different harvesting seasons to predict physicochemical attributes of mandarin fruit. Fruits from different harvest seasons (2011 and 2012) were used to demonstrate the effect of seasonal variability on Please ensure your meaning is retained model prediction performance. The 2012 harvest season fruits were used in training models, while those from the 2011 harvest season were used in the testing procedure. The low prediction accuracy indicated that the seasonal variation significantly affected calibration models across seasons. In order to minimize the effect caused by seasonal and origin diversity, robust models combining two harvest seasons and four different orchards were developed. The robust model including more orchards and harvest seasons showed improved prediction accuracy compared to specific models developed based on a single orchard or single harvest season.
A similar approach for data splitting Into training and the test set was employed for
A. esculenta samples from SAMS. In this case, the samples were not from a different harvest year so as to be used as the test set (like the 2021 harvest in
A. esculenta from MI) due to the limitations of the scope for efficient training sample sizes. Samples from the two harvest years (2019 and 2020), accounting for 124 samples, were adequate for the model development. Using the same methodology as before, we trained a prediction model using 84 samples, while the rest of the 40 samples were used as the external validation data set. In
Figure 3 (A-SAMS, B-SAMS) and
Table 4 (SAMS), we summarize the results of the 1-1 fit of the predicted vs. the actual TVC values via a linear regression (i.e., y = αx + β), as shown previously. The results also indicated a good prediction performance of the model on the external test data set (data not used in training), although this resulted in a rather high RMSE. RMSEs up to 1.0 log CFU/g, although seemingly high for prediction bounds, are common in food microbiology even for state-of-the-art laboratory analysis, and thus, they are acceptable. It is well acknowledged that it is usually a deviation of the TVC value for the exact same sample when it is analyzed in parallel by two different persons.
Furthermore, for the above analysis and prediction model building, we moved forward towards building a model which would be independent of the seaweed origin and only look at the microbiological population estimation/prediction. To this end, a superset of data was created, consisting of both
A. esculenta MI and SAMS. In this case, the data were split with a random generator following the “rule” of 75% (252 samples in total) as training and 25% (64 test data samples randomly selected) as test sets. This model, during the feature selection phase, is expected to disregard any features/wavenumbers closely related to the origin and their specific distinct way of spoilage due to the origin, leading to a model that would be origin agnostic with regard to seaweed spoilage estimation. The results for this approach with the superset of MI and SAMS
A. esculenta data are shown in
Table 4 (MI+SAMS) and
Figure 3 (A-MI+SAMS, B-MI+SAMS). These results indicate a good prediction performance of the model in parallel with enhanced robustness for the two origins of seaweeds considered herein from the external test data set selected. It is apparent that the combination of samples from both aquaculture sites benefits the model development and its performance, making it origin-free for microbiological population prediction.
It is worth noticing that this work was conducted with samples stored at different temperature conditions. Apart from the differences originating from the metabolic products, different storage temperature can change the cellular structure of seaweed tissue and also affect absorptions in certain bands [
36,
37]. In general, spectra are sensitive to fluctuations in temperature conditions. It has been recorded that the weather conditions can change the sample temperature and subsequently change the spectra and affect the prediction accuracy [
38]. The effect of temperature on IR spectra is related to the behavior of the hydrogen-bonded OH groups of water, which causes a broad absorption band around 1649 nm [
39]. This broad band can be comprised of five component spectra of five different hydrogen bonds. The cluster size of hydrogen bonds decreases as the temperature increases and this can affect the relative absorbance value of the clusters with no hydrogen-bonded OH groups. Consequently, the hydroxyl band of water shifts to the lower wavelengths and becomes sharper as the temperature increases [
40]. It is also indicated that this problem would arise in any other products containing a high water level (>80%), including seaweed. Therefore, the temperature fluctuations can affect both the spectral data acquisition and prediction models in real-world applications.
3.3. E-Nose Results
In e-nose instruments, electrochemical sensor arrays and proper identification equipment are employed. This differs from GC, GC-MS and other analytical methods in that it obtains not the qualitative and quantitative results of the individual components of the samples, but rather the overall information of the volatile components in the samples, that is, the fingerprint data [
41].
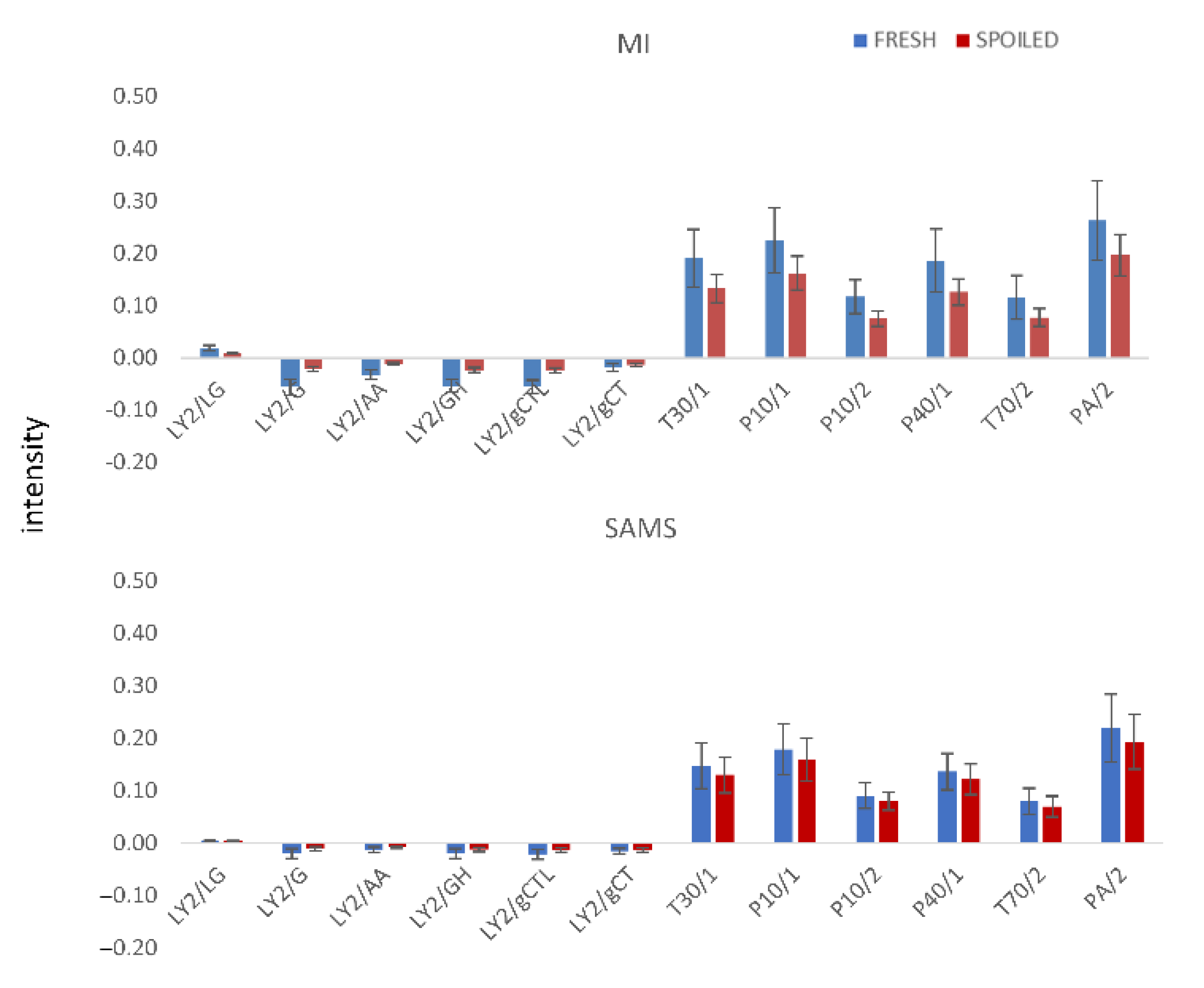
Representative responses/signals of the e-nose sensors (highest intensity within the 120 secs of analysis) of fresh and spoiled samples of different origin stored at different temperatures are presented in
Figure 4. “Fresh” samples are the average of 30 different samples with a population lower than 4.0 log CFU/g, while the ‘’spoiled’’ ones are the average of 30 different samples with a population higher than 8.0 log CFU/g.
In general, signals from fresh samples were stronger than those from spoiled ones for most of the tested cases. Additionally, samples from MI presented higher values compared to SAMS samples for the same microbial counts. Based on
Table 1 and the applications of each sensor, the response of most of them was expected to change during storage. Additionally, it should be also noted that sensors with low intensities (LY sensors) may significantly contribute to the estimation of microbial populations as their signal seems to change from fresh to spoiled samples.
The prediction model development and validation of the e-nose sensor for the samples originating from MI and SAMS and harvesting during years 2019, 2020 and 2021 (MI only) is presented below. A dataset of 83 samples was used for the model development, while 30 samples (not used in model training) were randomly selected to form and serve as an external test data set.
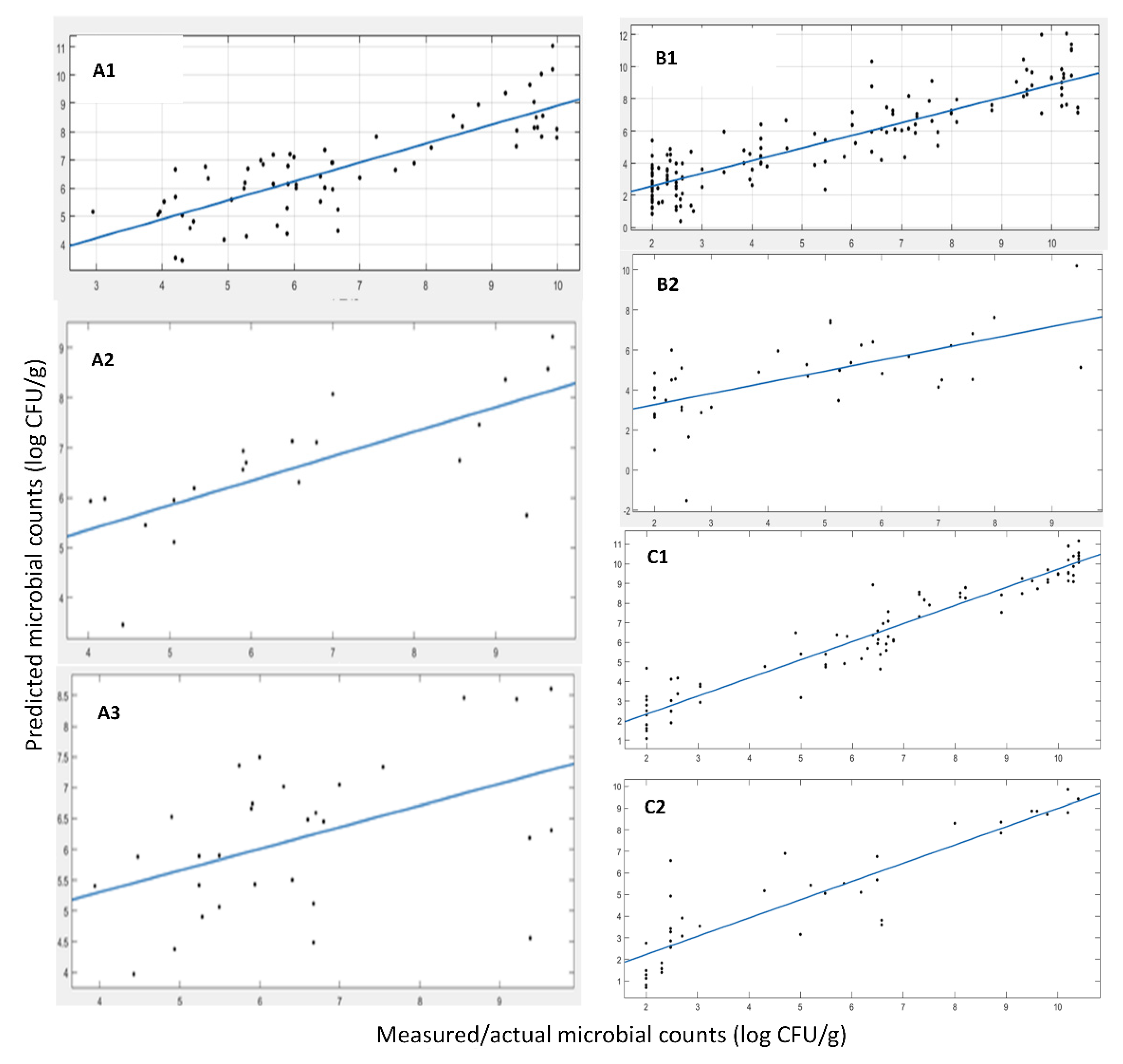
Figure 5 and
Table 5 present the results of the linear regression (i.e., y = αx + β) between the actual and predicted by the developed prediction model values of TVC. These results did not indicate a very good prediction performance, at least not as good as in the case of FT-IR, as presented previously. A reason for this performance shortage could be that the variables/features measured do not provide a strong correlation to the phenomenon under study, i.e., microbiological spoilage. Furthermore, some additional data were accumulated, representing the 2021 harvest of
A. esculenta MI. Since the model developed previously did not perform very well, we chose to rebuild the model using all harvests’ data samples and split them into training and test data sets from scratch, as described earlier. Thus, in total we accounted for 176 samples (years 2019, 2020 and 2021) where the external validation (test set) was set to 50 samples. In
Figure 5 and
Table 5, the linear regression results are shown (i.e., y = αx + β), showcasing a slope of ~0.76, an R-squared value of the fit of ~0.71 and an RMSE of the predictions of ~1.28. These numbers indicate a good prediction performance of the model on the external test data set. It is apparent that the data enrichment approach, with the additional data from harvest 2021, merited the model development. Thus, a robust model that is capable of predicting the microbiological population was able to be developed. In the case of
A. esculenta from SAMS, since no data from the 2021 harvest year were available, 30 test samples were randomly separated from the pool of 113 total samples. Using this split of data, we trained and validated the prediction model and the results are presented in
Figure 5 and
Table 5, showing the results of the linear regression (i.e., y = αx + β) between the actual and predicted by the developed prediction model TVC values. These numbers did not indicate a very good prediction performance of the model, at least not as good as in the case of FT-IR or even the results from the e-nose sensors in the case of
A. esculenta MI, as presented earlier. Further, as shown previously, the most probable issue may be the size of the data and their inherent variability. To support this claim, the augmented dataset with the 2021 harvest shown earlier yields a model that outperformed the model using just the data from the 2019 and 2020 harvest. Finally, using data from both MI and SAMS, a very poor prediction performance of the model was recorded, based on the performance indices.
Many metal oxide-type sensors provide a primary response to certain chemical species along with a large number of secondary (weak) responses that overlap among various sensor types. These overlaps are probably differentiated among samples, increasing complexity, which might be confusing for the model training. However, a statistical learning method can be employed to teach the sensors to acquire the characteristics of each sample under investigation [
42].
3.4. MSI Results
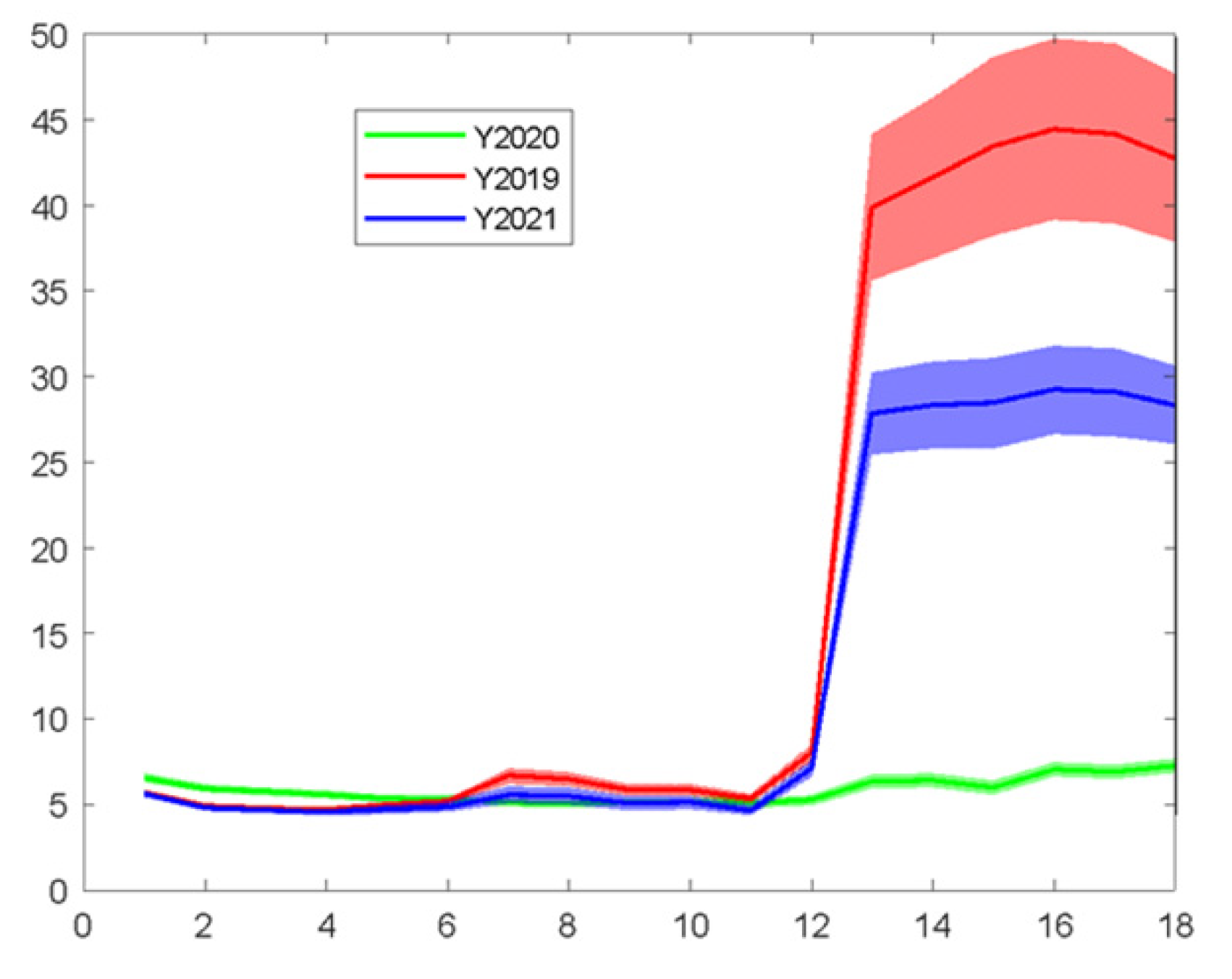
The profile of spectra acquired through MSI analysis and the differences among different years in the spectral profile of the samples are presented in
Figure 6. The data—mainly bands in the visible spectrum—exhibited large variations among the three harvesting years, probably due to the period of harvesting or other specific conditions (environmental conditions or practices during and after the harvest) affecting the end-product, mainly at the visual range, i.e., the color of the samples, which is commonly independent of the microbiological load.
The prediction model development and validation for the MSI of A. esculenta from MI and SAMS samples, from the harvest years of 2019, 2020 and 2021 (MI) and the harvest years of 2019, 2020 (SAMS) are presented below.
The developed model for the MSI sensor was applied to the 20 test samples of
A. esculenta MI (out of an 84 total sample size). In
Figure 7 and
Table 6, the results for the linear regression (i.e., y = αx + β) are shown. A slope of ~0.49, an R-squared value of the fit of ~0.51 and an RMSE of the predictions of ~0.95 were estimated. Those numbers indicate a relatively good prediction performance of the model on the external test data set. In addition, model evaluation was also performed using some additional samples from the harvest of 2021. Thus, there were, in total, 167 samples (years 2019, 2020 and 2021), while the external validation (test set) consisted of 30 samples. The results are shown in
Figure 6, where a slope of ~0.35, an R-squared value of the fit of ~0.22 and the RMSE of the predictions of ~1.01 were calculated. Again, the prediction performance of the model on the external test data set was not satisfactory. It has been found that the samples from different harvest years exhibit a large variation in their MSI spectra (please refer to
Figure 6), suggesting that maybe the MSI is not suitable for efficient microbial population estimation, unlike the FT-IR sensor and, to some extent, the e-nose sensor, as shown previously, mainly due to their independence from the “color” of the samples that misleads the prediction model.
In
Figure 7 and
Table 6, the results of the linear regression (i.e., y = αx + β) are presented, between the actual and predicted by the developed prediction model, for the TVC values of
A. esculenta SAMS. As shown in
Figure 7 the results of the linear regression (i.e., y = αx + β) with a slope of ~0.56, an R-squared value of the fit of ~0.40 and the RMSE of the predictions of ~1.93 do not indicate a fair prediction performance (unlike during the training with cross validation), which can be justified by keeping in mind
Figure 6 and the corresponding issue of the spectral differences among the years of harvesting.
In the case that data from SAMS and MI were combined, performance statistics values were slightly better than those models developed for each origin in separate (R-squared, 0.8; RMSE, 1.14). Probably by enlarging the size of data, the model was trained/learned better (good performance statistics in cross validation) and the differences in products among the differences in years were more successfully incorporated into the model, while the significance of the visual features (colour related) was degraded.
Another explanation for the low performance of the prediction models in the MSI sensor case, is the known issue of non-uniform distribution of light on the fruit and vegetable surface existing in almost all the imaging systems. Part of tissue with low intensity, especially the region near to the border, might even be wrongly considered as defective. Particularly for hyperspectral imaging, the bright spots in the central position caused by overexposing and progressive darkness at the edges enhance this phenomenon. This issue also results in a high spectral variability, which subsequently increases the complexity of the calibration model and decreases at the same time the universality, practicability and accuracy of the models.
The content of chlorophylls, anthocyanins and carotenoids and their proportion determine seaweed appearance and color and serve as attributes of quality since their content changes during ripening, maturation and storage. In addition, seaweed’s surface presents differentiations and pigments distributed non-uniformly on it. This results in variations of color and, consequently, in spectral reflectance and absorbance ability. Thus, for example, spectra originating from green color seaweed areas demonstrate the highest reflectance value due to their strong reflecting ability, while darker, brownish areas’ spectra hold a relative lower reflectance value [
37,
43]. It is apparent then that it is really difficult to distinguish samples with quality “defects” from samples with discoloring (no quality downgrade is apparent), thus influencing the defect recognition and segmentation [
39], limiting in this way the performance and the ability of a model based on optical information to perform adequately.
Although this study attempted—to a large extent—to increase the variability of the dataset—taking into consideration that in order to increase the robustness of calibration models, it is necessary to have sufficient variability in the calibration set—poor model performances were still observed in some cases, where solid justification has been provided. Inserting additional stochasticity and variability into the calibration models improves their generalization and, consequently, their prediction efficiency and robustness concerning the application to new samples and in real-life applications. Usually, but not exclusively, it also led to an increase in the models’ complexity, which is one of the main reasons contributing to overfitting. Thus, others should be extra careful during model calibration so as to lower the problem dimensionality (feature selection) in such a way that features are not directly correlated with the problem at hand (herein known as the spoilage estimation), which would be eliminated as new samples are added. This way, previously “significant” features that were more correlated to other aspects (e.g., origin or harvest year) than the one under investigation (TVC herein), are excluded during the recalibration of the model. Therefore, as stated in Zhang et al. [
44], viewed in terms of game theory, the balance between the specificity and universality of models should be paid more attention.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}