1. Introduction
The Internet of Things (IoT) is the major source of many upcoming applications related to intelligent transportation, health care, and smart grids [
1,
2,
3,
4]. IoT relies on many new technologies such as 6G communications, fog computing, and data analytics to provide ubiquitous connectivity, fast computing services, and intelligent application-related decision-making [
5,
6,
7,
8].
Fog computing holds key importance in future IoT applications as it helps with the fast computing of different application tasks. Fog computing offers many benefits compared to traditional cloud computing [
9,
10,
11]. Due to being closer to the edge and distributed in nature, fog nodes provide quicker and more reliable computation of tasks. However, efficient task offloading from IoT nodes to fog nodes is a major challenge that needs to be addressed.
Partial Offloading to Multiple Helper (POMH) is a task offloading technique that offers parallel computation of tasks and improves task latency. The tasks are divided into sub-tasks and passed to different fog nodes in parallel so that the overall computation time is reduced [
12]. The focus of this paper is to utilize graph matching theory to address the resource allocation challenges in POMH. The matching theory has the advantage of allocating resources in a stable manner while considering the preferences of agents [
13]. However, POMH is complex and involves decisions that require coordination among multiple stakeholders, such as task splitting and task offloading.
In POMH, the resource allocation problem is exacerbated because the sub-tasks of a task are processed at different computing devices, each of which takes a different amount of time to complete. The sub-task that takes the longest to complete determines the task completion time [
14]. For efficient utilization of assigned computation resources, all sub-tasks of a task must be completed at the same time. To do this, the size of sub-tasks needs to be adjusted proportionately to the computation resources allocated to that task.
This indicates that when we use the matching theory for resource allocation in POMH, the size of sub-tasks will vary with every allocation and cancellation of the potential match. This change in sub-task size changes the time and energy estimates for that task, generating variations in preference order of the tasks for the helping devices. In matching theory, this is an example of externalities, where players of one or both sets have dynamic preference profiles, and the decision of one player influences the decision of all other players [
15].
Solving the externalities problem in matching theory to make stable matching decisions is a difficult proposition that has long been a research focus, with few solutions proposed. Externalities problems are cyclic in nature and difficult to contain [
16]. Jinpeng Ma (JM) [
17] proposed that if we first find stable matching assignments while ignoring the externalities problem and then update the matched pairs to solve blocking pairs that arise due to changes in player preference profiles, the externalities problem can be solved in polynomial time with a convergence probability of one. In this paper, we used the JM concept to solve the externalities problem in POMH task offloading using the many-to-one matching technique. We use the Deferred Acceptance Algorithm (DAA) [
18] to obtain initial stable matching assignments while ignoring the externalities problem. This stable matching assignment is then updated to solve the externalities problem using the novel Stable Matching Update Algorithm (SMUA). The main contributions of this paper can be summarized as:
- 1.
To make the best use of the limited computation resources available on helper devices, we use POMH and formulate the resource allocation problem as a many-to-one matching problem. A task is divided into multiple sub-tasks that are processed concurrently at the task-originating device and multiple helper devices to reduce task completion time.
- 2.
To solve the externalities problem and produce stable matching assignments for POMH task offloading, we develop a novel many-to-one Stable Matching Update Algorithm (SMUA) based on the JM algorithm [
17]. To the best of our knowledge, this is the first work that addresses the externalities problem in matching theory for resource allocation in POMH.
The remainder of the paper is as follows. In
Section 2, we discuss related work on POMH and the externalities problem in matching theory. We provide a system model and formulate the problem in
Section 3. In
Section 4, we propose a solution based on the matching technique. We compare the performance of our proposed technique in
Section 5, and we conclude in
Section 6.
2. Related Work
In this section, we discuss a literature review of fog computing to understand and summarize work done by researchers in areas of (a) partial offloading of a task to a single helper device, (b) partial offloading of a task to multiple helper devices, and (c) the externalities problem of matching theory and how scholars have recommended solving this problem. Previous work on partial task offloading in fog computing and contributions of this paper are summarized in
Table 1.
2.1. Partial Offloading to Single Helper
Studies on task offloading with a single helper have focused on both binary and non-binary decision-making. In binary decision-making, the entire task is either offloaded to another device or retained for local computation, whereas in non-binary decision-making, i.e., partial offloading, only a piece of the task is offloaded and the rest is computed locally. In [
19], the authors implement partial offloading of the work, in which the IoT device computes the local component, and the offloaded component is performed in a virtual machine established within a mobile edge computing server. The authors of [
20] employ horizontal offloading to benefit from the free computation resources of neighboring fog nodes. The task is divided into two sub-tasks, where one sub-task is locally computed and the other is computed at the helper fog node.
2.2. Partial Offloading to Multiple Helpers
Assume that a task can be divided into multiple independent sub-tasks, some of which are processed locally, and the remaining are offloaded to multiple fog nodes for parallel processing; then, the task execution latency will be reduced by many times. Take the case of face detection as an example, where an image can be partitioned into multiple subsets, and through parallel execution of these subsets with multiple devices, the speed of the detection procedure can be enhanced multiple times. The authors of [
21] consider partial offloading in a meshed edge network using a heuristic technique based on graph theory. Tasks are partitioned based on projected delay in task queues and wait time in channel access. Work in [
22] employs POMH to relieve workload from the Data Center (DC) in a busy road situation with slow-moving cars. Using the Lagrange method, the DC discovers free computation resources in all cars within its coverage zone and offloads proportionally sized task to them while taking their distance into account.
The author of [
10] consider Vehicle-to-Vehicle (V2V) communication, in which a vehicle does parallel offloading of the task to other cars in its immediate vicinity. The work uses Markov Decision Process (MDP) to choose the cars and determine the size of the offloaded task for each vehicle. The research in [
23] considers a 5G scenario in which a mobile device is served by a macro base station under a small base station. The task is parallel processed at the macro base station and a small base station. The size of sub-tasks is determined, considering task queue length at the base station and communication link quality of the mobile device, using Deep Reinforcement Learning (DRL) with MDP. The work in [
24] used an iterative heuristic algorithm to make the offloading decision and to divide every task into three sub-tasks to be processed locally, at the edge server, and in the cloud server, respectively.
Work in [
25] considered both horizontal and vertical offloading of the task in all layers except the cloud server. Task distribution is considered as a tree with branches to regulate the direction of the flow of tasks. For each node in the tree, the branch and bound algorithm are used to convert MINLP into NLP sub-problems. Each sub-problem is iteratively selected and solved using a depth-first search strategy. The work in [
26] used directed acyclic task graphs to perform horizontal offloading of workloads among fog nodes. For each fog node, a clout value is calculated based on the fog node reliability (i.e., experience, residual power, computation capability, storage capacity, wait time, and distance). The task is offloaded to the fog node with the highest clout value. The authors of [
27] subdivided tasks into multiple sub-tasks and formulated a Generalized Nesh Equilibrium Problem (GNEP) to solve the optimization problem. In this work, fog nodes advertise their tasks, for which helping fog nodes offer their resources. Based on offered resources, the advertising fog node calculates optimal solutions and does parallel offloading of the task.
The author of [
28] discussed vertical task offloading to a cloud server as well as horizontal task offloading from task fog nodes to helper fog nodes. Task fog nodes advertise their tasks, which helps fog nodes offer their resources while considering channel rate. The authors used a many-to-one matching technique to match task node tasks with helper fog nodes. The task fog node sets offloading ratios for local task computing, cloud computation, and helper fog node computation. The authors of [
12] performed POMH task offloading by leveraging both horizontal task offloading to neighboring fog nodes and vertical offloading to the cloud. They suggested a broad framework to minimize delay in service provisioning through an adaptive task offloading mechanism.
The authors of [
29] discussed the impact of the number of task splits on time efficiency in POMH. The authors of [
30] developed offloading policies based on residual energy with the fog nodes to optimize time or energy by offloading tasks to high-residual-power fog nodes and fog access points using POMH.
2.3. Externalities Problem
Solving the externalities problem in matching algorithms has been a significant research area for a long time, and scholars have contributed useful work in this area. In matching theory, the externalities problem describes a scenario in which one or both player sets have dynamic preference profiles that regularly change during the matching process. The matching decision of one player affects the preference order of every other player in the network. Stability in matching assignments is a prerequisite for using matching theory to solve resource allocation problems. Stability in matching assignment implies that the predetermined objective functions have been achieved, and matched partners are satisfied with their current partner and would not choose to switch partners. With externalities problems, it gets challenging to achieve stability in matching decisions.
Researchers working to solve the externalities problem propose that it is not essential that small changes in the preference profile of a player affect the stability of all matched pairs. This means that it is highly probable that only a few matching decisions result in players opting to change their partners. Based on this, researchers provide different ways for updating matches to satisfy all blocking pairs and maintaining stability to address the externalities problem. While updating matches by satisfying blocking pairs, the most difficult challenge is to control the domino effect. This reflects a situation in which satisfying one blocking pair may spawn more blocking pairs, changing this process into a cyclic process in which pairs begin to replicate themselves.
Knuth [
16] believes that updating a stable matching using the Gale–Shapley algorithm is impossible due to the cyclic nature of the externalities problem. In contrast, Roth and Vande [
31] established in their work that stable matching is always attainable when tackling externalities problems, even if we start from an arbitrary value. In contrast to the Gale–Shapley algorithm, which consistently provides the same stable matching outcomes, the Roth and Vande method offers a diversity of stable matching in each iteration, i.e., every time they give a different stable matching result. Jinpeng Ma [
17] further deliberated the work of Roth and Vande and developed a stable matching update mechanism for the Gale–Shapely algorithm. The JM algorithm evaluates each stable match in turn and resolves its blocking pairs under the externalities problem. He demonstrated that the JM algorithm can always find stable matching with a probability of one. The work in [
15] further deliberated the JM algorithm to reduce the stable match update time.
3. System Model
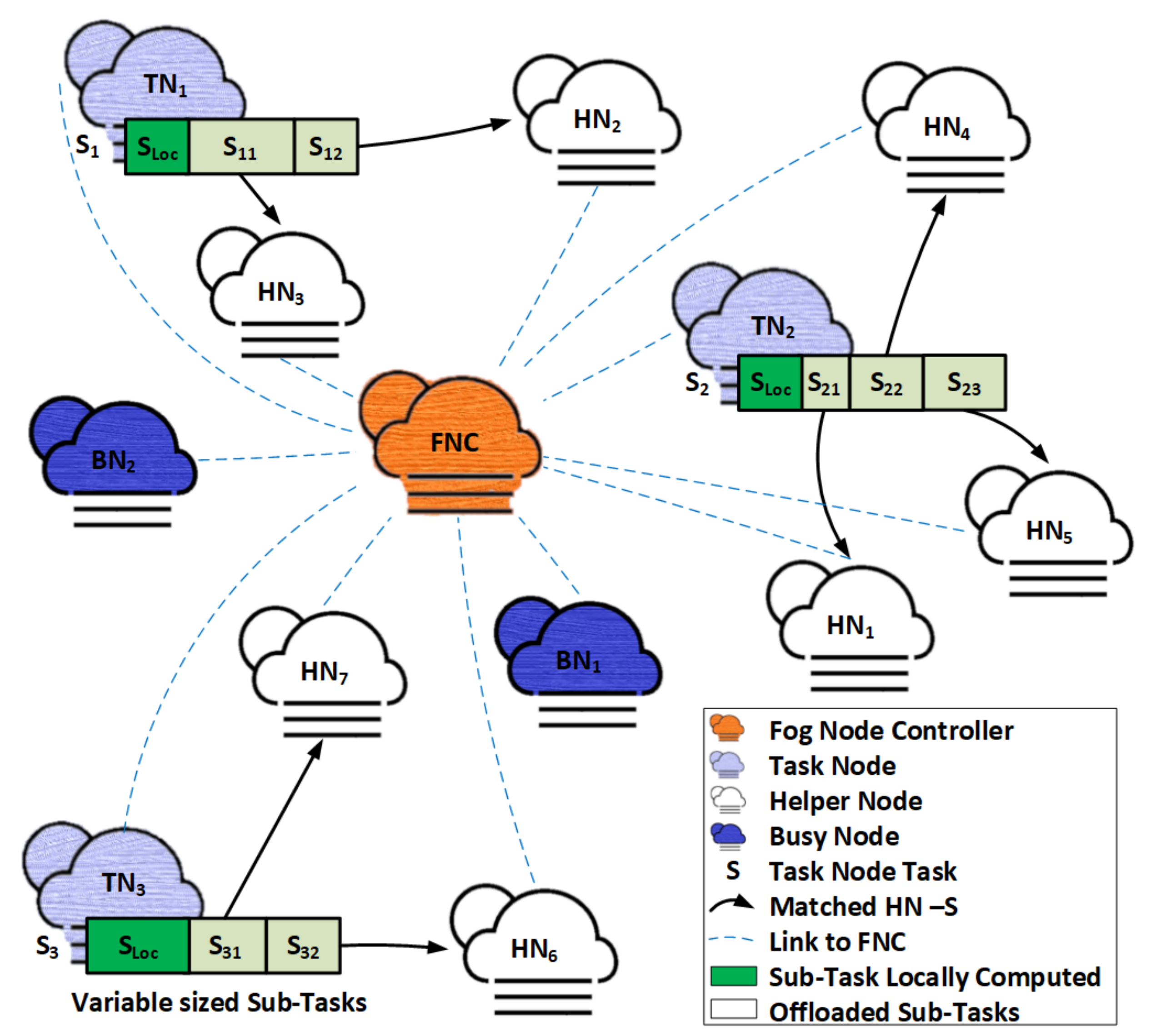
Consider a cooperative and self-sufficient fog-computing network in which fog nodes assist each other in accomplishing computing tasks. We assume that all fog nodes in this network have comparable computational capacity but differ in workload. Because of the difference in workload, the role of fog nodes can be altered from (1) Task Nodes (TNs) when they have a large task to compute, to (2) Helper Nodes (HNs) when they have some spare computation resources to compute tasks for others, and to (3) Busy Nodes (BNs) when they are busy computing previous tasks. The fog network in
Figure 1 has three TN tasks, seven HNs, and two BNs.
Let there be
k number of HNs and
m number of TNs, denoted as
and
, respectively. Let
be the task size generated by TN, which we assume to be generically split-able, e.g., tasks such as face identification and image processing that may be divided into any number and size of sub-tasks [
27]. Let
represent the sub-tasks of
. For POMH task execution,
is broken into
sub-tasks. One sub-task is locally processed at the TN, represented by task percentage
, whereas the remaining
r sub-tasks, represented by task percentages
, are offloaded to
r number of HNs for parallel computation of the task. For task percentages, the following condition must be met:
In this study, we contemplate a centralized mechanism for task and resource allocation, for which a fog node is designated as the Fog Node Controller (FNC). TN, on generation of task , sends an offloading request to FNC in the form of a tuple , where (in bits) represents input task size, (cycles) is the number of Central Processor Unit (CPU) cycles required to complete the task and, (seconds) is the time required by TN to locally compute the entire task . We assume that TN has sufficient resources to complete the task within task deadline and is employing POMH to improve task completion time, i.e., TN wants to improve of task .
We assume that FNC has Channel State Information (CSI) and resource information of all fog nodes in the network. FNC uses a many-to-one matching technique for resource allocation and task distribution in the network. TN tasks are split into multiple sub-tasks, whereas available free computation resources of an HN are considered as a single unit and allocated in full. When doing POMH, we need to ensure that all sub-tasks of task finish at the same time. For this, we need to size the sub-tasks such that TN and all HNs computing these sub-tasks complete them simultaneously.
3.1. Latency Model
In POMH, a task is simultaneously processed at TN and multiple HNs. As a result, the task completion time of is determined by several interconnected parameters and can be generally defined as local computation time and offload computation time. Following are the sequential steps involved in this process:
3.1.1. Local Computation Time
Local computation time refers to the amount of time spent by TN in computing the local component of task
. In this paper, we assume that a TN can compute the local component of the task while offloading other sub-tasks to respective HNs. If
is the Central Processor Unit (CPU) speed of TN
, and
is the task percentage of task
locally processed, then the latency incurred in computing the local component of the task can be calculated as:
3.1.2. Offload Computation Time
Steps involved in computing sub-tasks of task at multiple HNs are explained below:
- 1.
Sub-task transmission time
This refers to the amount of time spent in transmitting sub-tasks of task
from TN to HNs. Each sub-task will experience a different transmission time, dictated by the transmission rate
between TN
and HN
. Sub-task transmission time and transmission rate can be calculated as:
where
is the transmit power of TN
,
is the white-noise power, and
is the channel gain, which is inversely proportional to the distance between TN
and HN
[
32].
- 2.
Sequence time
In this paper, we assume that each fog node has a single antenna that can only transmit to one other fog node at a time. Therefore, in POMH, TN must send
r distinct transmissions in
r directions to offload
r number of sub-tasks. This means that all sub-tasks will be communicated serially, and each sub-task will have to wait in TN for its turn to be offloaded, which we refer to as sequence time. The sequence time of a sub-task is defined as the sum of the transmission time of all sub-tasks offloaded before it. The sequence time for the first sub-task to be transmitted is zero, and the sequence time for subsequent sub-tasks can be calculated as follows:
In this paper, we assume that HNs can start processing the sub-task from the moment they receive the sub-task. If
k is the last sub-task of task
, then total transmission time of all sub-tasks of
as calculated from Equations (
3) and (
5) is:
- 3.
Queuing delay at HNs
This refers to the amount of time a sub-task must wait at HN while HN is busy computing other tasks. In this paper, only free computation resources of an HN are made available to compute for a single TN only. As a result, there will be no queue time in HN, and the sub-task will be computed as soon as HN receives it.
- 4.
HN computation latency
This refers to the amount of time spent computing the sub-task at the fog node. If
is the CPU cycles made available by HN
for
sub-task, then:
- 5.
Result download latency
This refers to the time spent transmitting the processed output from the HN to the relevant TN. In this paper, we assume that the output is very small compared to the input; therefore, download latency is neglected [
33].
- 6.
Total offload computation delay
The total time spent computing a sub-task at HN is the sum of the times mentioned above and can be given as:
3.1.3. Total Task Latency
Because each sub-task of task
has a different size, communicates over a variety of communication channels, and is processed at various fog nodes with diverse computational capabilities, each sub-task will have a variable latency. From these variable finish times, the sub-task taking the longest time to complete will define the latency of task
as:
For successful completion of task
:
3.2. Same Finish Time for All Sub-Tasks
Typically, fog networks have limited computation resources, so it is critical to make optimal use of this valuable resource. From Equation (
9), we know that task
completion time is decided by the sub-task that takes the longest time to complete. Therefore, if all sub-tasks of
do not complete at the same time, the valuable computation resources of HNs that complete their share of
earlier would be squandered. Therefore, for effective utilization of HN resources, all sub-tasks of
must finish at the same time, i.e.,
Except for the sub-task sizes, all criteria determining sub-task completion time are fixed. Therefore, we must regulate the sub-task sizes to ensure that all sub-tasks of
are complete at the same time. This means that in POMH, all
’s of task
are interdependent, and their relative sizes must be adjusted taking into account channel conditions and computation capabilities of devices on which they will be computed to ensure simultaneous completion of all sub-tasks. For a single task split, the values of
and
for same completion time are determined by equating Equations (
1), (
2) and (
8):
3.3. Problem Formulation
The objective of this paper is to make the best use of HNs’ available free computation resources to reduce TN task completion time and hence improve user experience. For this, we want to formulate a task-splitting and resource-allocation strategy based on a matching technique that efficiently matches sub-tasks of task to HNs, hence minimizing task computational latency. The optimization problem can be stated as follows:
Constraint (
14) ensures that task
is completed before its task deadline
, whereas constraint (
15) ensures that overall task completion time is less than the time required to fully compute the task at TN. Constraint (
16) ensures that all sub-tasks are complete at the same time. Constraint (
17) ensures that whole task
is converted into sub-tasks, i.e., no part of
is left unattended. Constraint (
18) ensures that no additional sub-tasks are created. The number of sub-tasks is equal to the number of HNs that will compute task
with the TN, plus one that will be computed locally by the TN. If no HN commits to computing
with TN, the task will be computed entirely by TN.
Constraint (
19) ensures that only one sub-task of TN
is offloaded to HN
.
The formulated problem represents a combinatorial optimization problem, which is NP-hard to solve [
34]. It is nearly impossible to achieve an optimal solution in polynomial time for an increasing number of TNs and HNs. Moreover, each device aims to maximize its benefit, which may lead to an unstable outcome.
4. Proposed Solution
In this section, we explain the proposed technique to solve the problem formulated in
Section 3.3. Due to the interdependence of multiple parameters, the formulated problem is NP-hard, and it is difficult to find its solution in polynomial time. Using traditional optimization-based techniques to solve such a problem is likely to result in extensive computation delays and may not work efficiently with a large number of devices. Matching theory, on the other hand, is scalable, computationally inexpensive, and simple to implement, and it has gained momentum in a variety of resource allocation problems [
13]. It is an important mathematical tool for dynamically modeling and solving task offloading problems. It considers resource-demanding and resource-allocating devices to be members of two independent sets and builds beneficial associations between them while considering individual preference ranking over the players of the opposite set. As a result, each agent is satisfied and has no incentive to change its assigned allocation.
From Equation (
11), we know that for efficient utilization of assigned HN computation resources, all sub-tasks of task
must complete at the same time. To do this, the size of sub-tasks needs to be adjusted proportionately to the computation resources allocated to
. This indicates that when we use the matching theory for resource allocation in POMH, the size of sub-tasks will vary with every allocation and cancellation of a potential match. This change in sub-task size changes the HNs’ time and energy estimates for TN tasks, generating variations in HN preference order. In matching theory, this is an example of externalities, in which HNs have dynamic preference profiles, and the decision of one HN influences the decision of all HNs.
The externalities problem in matching theory necessitates special attention and the use of specialized algorithms to minimize the effects of constantly varying preference ordering of players. In this research, we employ the Deferred Acceptance Algorithm (DAA) to obtain initial stable matching assignments while ignoring the externalities problem. This stable matching assignment is then updated to solve the externalities problem using the proposed SMUA, which uses the stable-matching-update technique of the JM algorithm. The JM algorithm is designed to solve the externalities problem for Gale Shapley, a one-to-one matching technique that produces stable matching assignments in polynomial time with an algorithm convergence probability of one. We used the same technique to solve the many-to-one externalities problem for resource allocation in POMH. The proposed SMUA is a many-to-one resource allocation technique for POMH that always gives stable matching assignments.
4.1. Matching Game
In general, a matching game is a two-sided assignment problem between two disjointed sets of players, with each player having a defined preference order against players from the opposite set. The preference order specifies the extent to which a player’s objective functions are met by players from the opposing set. In our case, we have two sets of HNs and TN tasks represented by and , respectively, and we want to match TN tasks to available free computation resources of HNs so that the objective functions of both HNs and TN tasks are met. Before explicitly explaining the proposed solution, we explain the matching concepts in light of the formulated problem:
4.1.1. Matching Assignment
A many-to-one matching assignment between
and
is based on a mapping function
such that:
Condition (
20) and (
21) show that a task can have a maximum of
matches with
number of HNs, while a task cannot have more than one match with a single HN. Condition (
22) shows that an HN can only have one match, whereas, condition (
23) implies that a task is matched to an HN if and only if that HN is matched to that task and vice versa.
4.1.2. Association between HN and TN Tasks
“In matching theory, an association set is defined for each player and is populated by those players from the opposite set with whom it may make an acceptable match, i.e., the pair meets defined objectives under specified constraints [35]."
In our paper, if a pair of TN task and HN can jointly improve task completion time
to make it lower than local computation time
, then the pair can be associated. The association set is used to narrow the search space for matches, where a match for every player is searched from its association set only. Let
and
be association sets defined for HNs and TN tasks respectively. Then, HN can be defined in the association set of a TN task if and only if that TN task is also defined in the association set of that HN, i.e.,
4.1.3. Player Preference Profile
“A matching game has two sets of preference relations and that allows each player ( to indicate preference over all players ( in the opposite set and vice versa [36].”
The objective of this paper is to minimize task computation time
. Therefore, a TN task will prefer an HN with which it can jointly obtain the smallest task computation time
, i.e.,
The objective of HNs is to minimize
. In this paper, we also want to maximize the number of TN tasks leveraging HN computation resources. Therefore, rather than using the traditional profiling technique in which HNs aim to reduce their task computation time only, we use the metric of the percentage improvement in task completion time to define the HN preference profile. This technique calculates task completion time for two scenarios: (1) when the TN task is not served by HN and (2) when the TN task is served by HN. The difference in time is converted to a percentage improvement in task completion time. The TN task with the greatest percentage improvement in task completion time is preferred over the others.
The time calculations and corresponding preference order of TN tasks for HN change with each matching decision. These variations arise because the size of
of task
changes with each addition and deletion of a match to finish all sub-tasks of
at the same time, according to constraints (
16) and (
17) of the formulated problem. This introduces the externalities problem into the matching process, which will be discussed later in this section. TN tasks, on other hand, have a fixed preference profile.
4.1.4. Quota/Capacity of Players
A player’s quota represents the number of matches that can be made with players of the opposite set. In this article, all free computation resources of an HN are allotted to a single TN task; hence, the HN quota is one. A TN task, on the other hand, is divided into sub-tasks and has a quota of r matches with HNs.
4.1.5. Blocking Pair
“A matching function λ is said to be blocked by a pair of agents iff , , but , and similarly , , i.e., A pair blocks assignment λ when they are not matched with each under current λ but they prefer to be matched with each other [37].”
In other words, a player with a higher preference cannot be skipped to match with a player with a lower preference.
4.1.6. Stable Matching Assignment
The stability of assignment
implies that if
then atleast one of the two players
and
is better off in
: either
is matched with a player of
that
prefers to
or
is matched with a player of
that
prefers to
[
37].
Stability in matching assignments implies that all players are happy with their existing partners and would not want to change partners under the current circumstances. Stability can be achieved only when there is no blocking pair to the matched pairs.
4.2. Solving Externalities Problem for Resource Allocation in POMH Scenario
We use two algorithms to solve POMH-based resource assignment problems. The first algorithm finds stable matching assignments without addressing the externalities problem, while the second algorithm updates the first algorithm’s matching assignments to solve the externalities problem and obtain stable matching assignments.
4.2.1. Stable Matching Assignments without Addressing the Externalities Problem
In our work, all algorithms are executed in FNC, and FNC makes resource allocation and task-split decisions based on the results of these algorithms. On generation of task , TN sends an offloading request to FNC. FNC first establishes associations between HNs and TNs based on the transmission rate and the availability of adequate free computation resources with HN that can reduce computation time over its local computation time . FNC uses Channel State Information (CSI) periodically sent to it by all fog nodes to determine distances and transmission rates between the TN and HNs.
FNC then calculates preference profile
for all TN tasks. FNC also calculates the initial preference order of TN tasks for HNs
without taking the externalities problem into account. Based on this information, FNC uses DAA to match a single TN task to many HNs using the many-to-one matching technique. DAA generates stable matching assignments without addressing the externalities problem. The steps involved are shown in Algorithm 1 The externalities problem is then solved using the JM algorithm [
17] to generate stable matching assignments in polynomial time with an algorithm convergence probability of one, as discussed below.
| Algorithm 1 Stable matching assignments without addressing the externalities problem |
![Sensors 22 06906 i001]() |
4.2.2. Stable Matching Update Algorithm (SMUA) to Solve Externalities Problem
In this paper, the size of task
sub-tasks changes with the allocation of HN resources. This is done to ensure that all sub-tasks of
finish at the same time, which is essential for efficient utilization of assigned HN resources. HN preference order for TN tasks changes as sub-task sizes changes, resulting in a dynamic preference profile. This poses an externalities problem while making resource allocation decisions in POMH. If we try to solve the externalities problem during the matching process, the preference order of all HNs may begin to fluctuate, and we may never be able to find the stable solution as anticipated by Knuth [
16].
Therefore, we used the JM algorithm [
17] to solve the externalities problem in this paper. The JM algorithm is a matching update process that is based on the concept that minor changes in a player’s preference profile may not affect the stability of all matched pairs. The JM algorithm starts with an arbitrary stable matching assignment produced by any matching technique and solves the externalities problem by resolving blocking pairs that may arise while the HN preference order changes. The JM algorithm always converges and finds stable matching with a probability of one. The JM method was designed to resolve externalities in one-to-one matching assignments; we modified the same approach to address externalities in many-to-one matching assignments. We attempt to update a stable matching by isolating the pairs responsible for its instability. This reduces the number of possible new blocking pairs as well as the size of the stable matching to update. The steps involved are shown in Algorithm 2 and, the working principle used in our proposed SMUA is given in
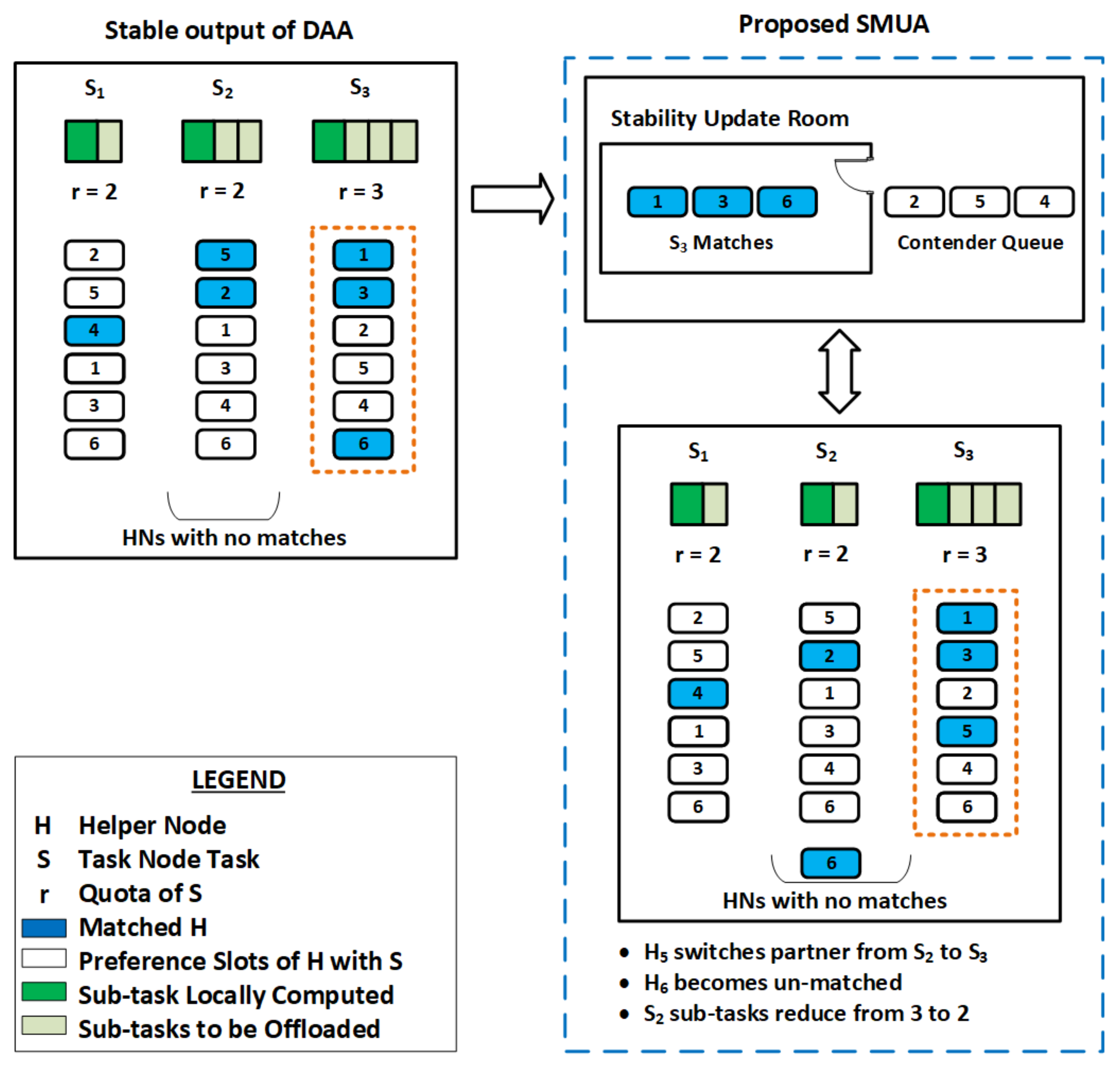
Figure 2, and an explanation of the different steps involved is given below:
Consider the three tasks
, and
, each with a quota
r of two, two, and three, respectively, as illustrated in
Figure 2. The total allowable quota for TNs is seven, and there are six HNs to assist them. The left side of
Figure 2 shows a stable match output of the DAA algorithm without addressing the externalities problem, with three tasks securing one, two, and three matches, respectively.
SMUA solves the externalities problem by updating this non-externalities-based stable matching assignment with the JM technique. Matches to tasks are iteratively updated to account for new blocking pairs that may emerge as a result of the new HN preference profile until all externalities problems are solved and pairs become stable.
Allow TN matches to enter a single-entry stability update room at random. In
Figure 2, the matches of
, i.e.,
, and
, enter the stability update room.
All HNs that can potentially form blocking pairs to matches of the selected TN task queue outside the stability update room in the sequence of . For , HNs and queue outside the stability update room.
HN in front of the queue, i.e., , enters the room and finds its preference number among the matches in . stays in the room for further calculations if its preference number is within quota r of . Since is third in the preference order, matches against the quota of three; therefore, stays in the room.
calculates the percentage time improvement if it serves , and compares it to the percentage time improvement of its current match, i.e., . If its current match has a high percentage time improvement, it continues with and exits the stability update room.
enters the stability update room and finds that matching with provides a high percentage improvement in time over its current match , so switches its match to . The number of matches is decreased from two to one, and the number of sub-tasks is reduced from three to two.
With the addition of the match, the total number of matches held with exceeds the permitted quota range of three. As a result, the match with the lowest preference in is released, i.e., exits the stability update room. If a chance presents itself, will match another TN task.
When enters the stability update room, it has a preference number of four amongst the held matches in . Since its sequence number is more than the quota, it quits the room.
Iteratively, the process continues until the externalities problem is addressed and all blocking pairs are satisfied. When the matching assignment at the start of the iteration is the same as the matching assignment at the end of the loop, the finish condition is identified.
| Algorithm 2 Proposed SMUA to solve externalities problem |
![Sensors 22 06906 i002]() |
Since the proposed SMUA updates an existing stable matching assignment to solve the externalities problem by resolving new blocking pairs, it always produces stable matching assignments.
4.3. Complexity Analysis
The overall time complexity of our proposed SMUA depends on the following actions: (1) FNC works out the transmission rate between HNs and TNs, consuming a maximum of time; (2) FNC works out association sets and a preference profile of HNs and TN tasks for which it again requires time; (3) stable matching assignment without solving the externalities problem can be obtained in time; and (3) proposed SMUA will consume a maximum of time to update the matches to solve the externalities problem. Therefore the overall time complexity of the proposed SMUA can be expressed as , which is polynomial.
5. Performance Evaluation
In this section, we evaluate the performance of the proposed SMUA by comparing our simulation results against other algorithms in the literature.
5.1. Simulation Setup
To demonstrate the efficacy of the proposed SMUA, we developed a MATLAB simulation of a cooperative fog network, and the values of significant parameters used in simulations are summarized in
Table 2. The fog nodes are uniformly distributed over an area of 60 m × 60 m.
The role of fog nodes in our fog network alternates between HNs, TNs, and BNs. However, for simulation purposes, we consider 30 HNs and 5 to 15 TNs, with each simulation varying by 1 TN. Fog node computation resources (cycles/s) are considered to be heterogeneous and are uniformly selected from the range of 0.8–1.2 GHz (Here we are modeling smartphones with ARM Cortex-A8 processors as fog nodes. These smartphones have a 1 GHz clock speed [
27]). TNs are configured to use all of their computation resources to compute their tasks, whereas HNs are configured to make only
of their computation resources available to compute TN tasks, with the remainder being allocated for internal processes. TNs generate tasks with uniform distribution in the range of 4000–5000 KB. Each bit requires 2500–3000 CPU cycles (cycles/s) to compute. (The data size and computational demand of face recognition applications are about 5000 KB and 3000 cycle/bit, respectively [
27]).
We are employing a many-to-one matching technique to allocate HN resources to TN tasks. Therefore, in this paper, a TN task can be divided into 1–6 sub-tasks based on the number of matches obtained by a TN task. The free computation resources of an HN are treated as a single entity and allocated to a single TN task. After completion of the matching process, the size of sub-tasks is adjusted to ensure that all sub-tasks are complete at the same time. The effective communication range of HNs to compute TN tasks is set as 30 m. Each TN has an active up-link with dedicated bandwidth of 5 MB with each HN, ensuring no wait time to access the channel. The TN transmission power is set as 100 mW. Considering the PCS-1900 GSM band, the free space path loss in
between a TN and an HN is calculated as:
[
37]. The channel gain
is then calculated as:
. The communication channel is assumed to be noisy, with noise power
.
5.2. Baseline Algorithms
To gauge the performance of the proposed SMUA, we compare its results with the following baseline schemes:
- 1.
Liu et al. [
27] (referred to as POST);
- 2.
Zu et al. [
28] (referred to as SMETO);
- 3.
Zhang et al. [
20] (referred to as FEMTO);
- 4.
Local computing in which TNs process the task on a local device (referred to as Local).
The performance of the proposed SMUA against a non-externality-based matching solution will be discussed separately to gain insight into the factors influencing the performance of the proposed SMUA. Among the baseline schemes, SMETO models its resource allocation strategy as a matching game, whereas POST and FEMTO employ an optimization technique for resource allocation. POST, SMETO, and FEMTO all use the POMH technique to reduce task computation time. The primary objective of POST is task efficiency, whereas the primary objective of SMETO and FEMTO is energy efficiency. The DAA matching algorithm is used to make resource allocation decisions in POST and FEMTO.
5.3. Task Latency
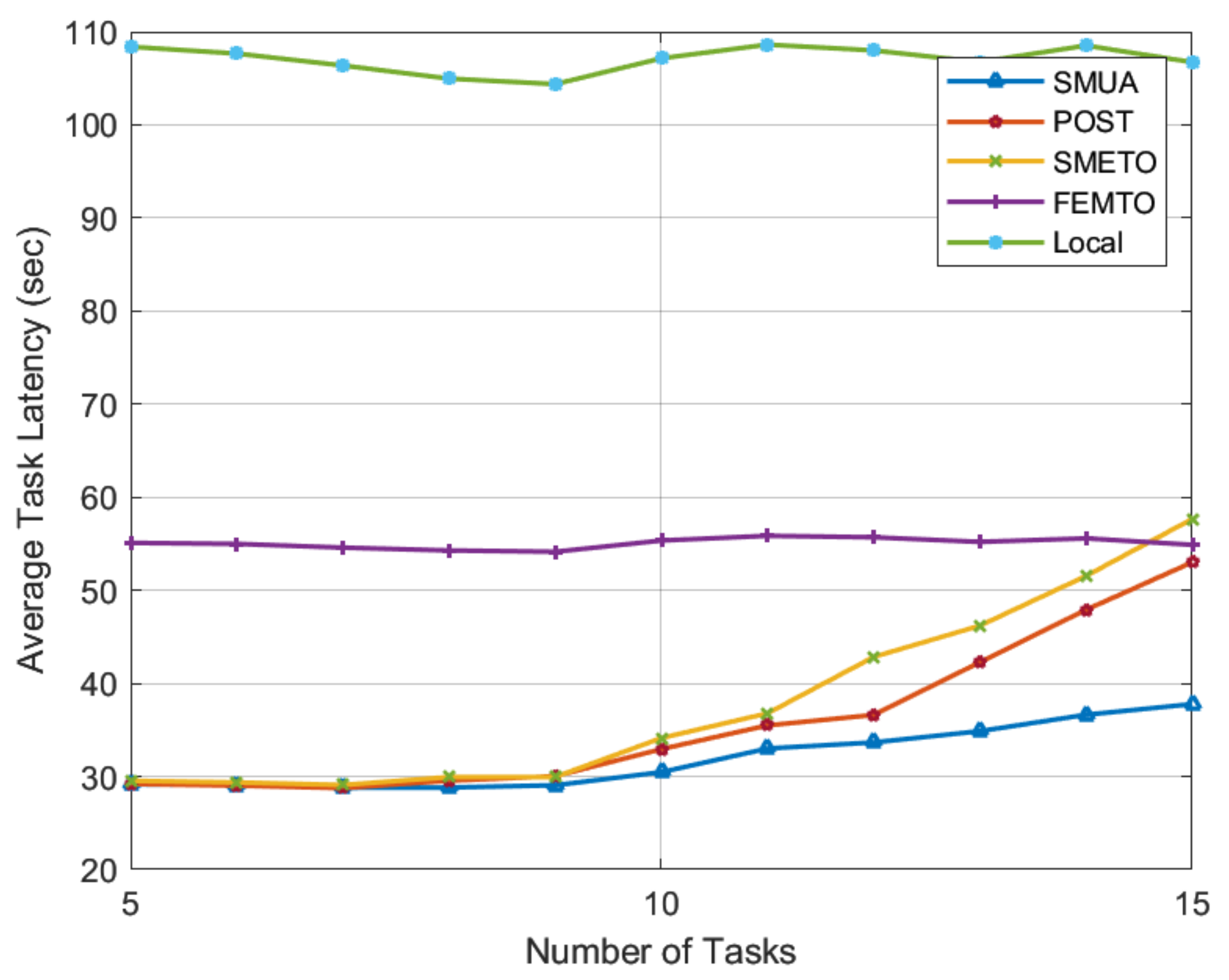
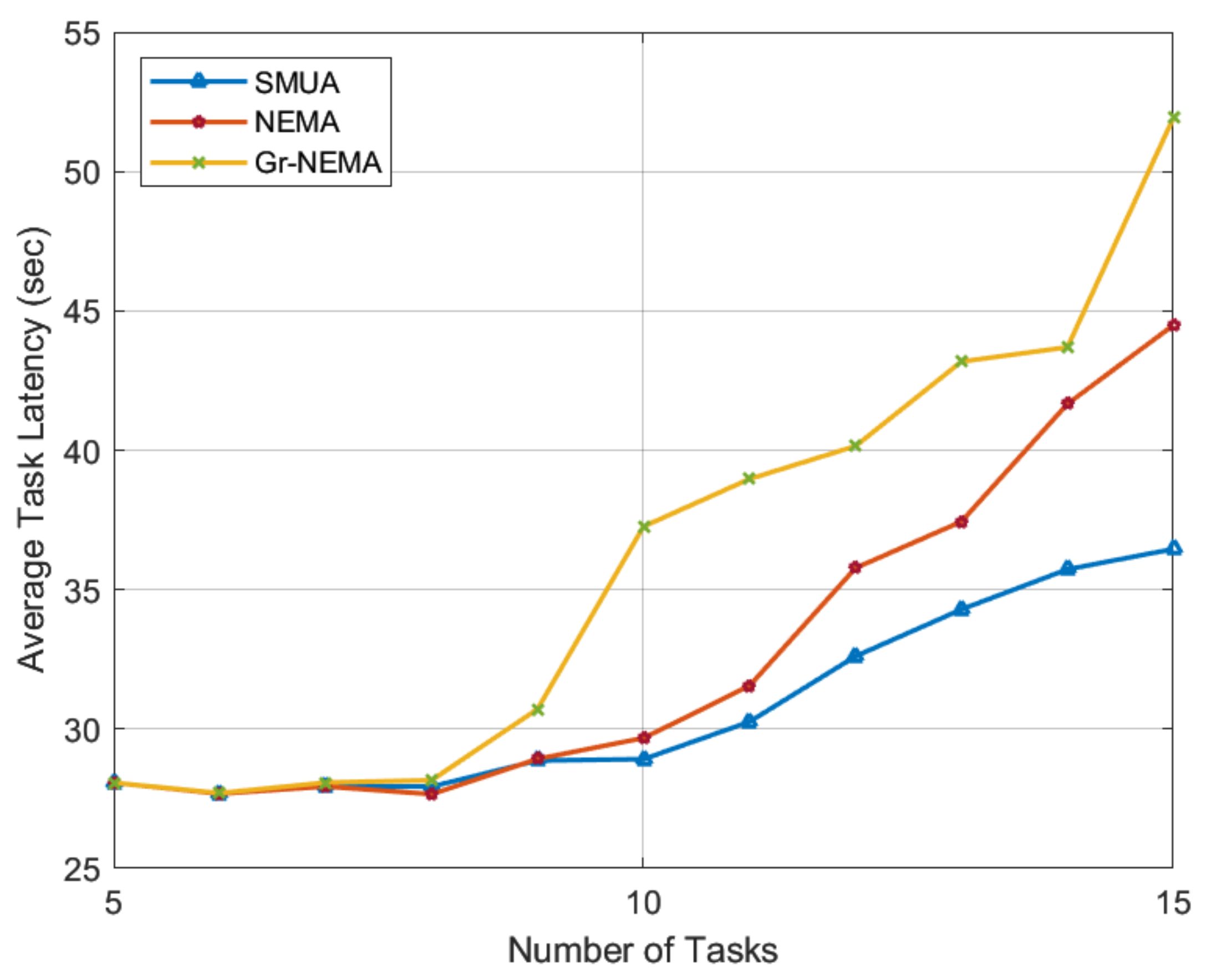
Figure 3 shows the average task latency experienced by the baseline schemes under consideration. In this simulation, we permitted a maximum of three matches for each TN task. The number of TN tasks ranged from 5 to 15, while the number of HNs was set to 30. These are intriguing numbers for evaluating the performance of matching algorithms because when we test for TNs 5 through 9, the number of HNs exceeds the TN matching capacity, leaving many HNs unmatched. Every baseline algorithm performs optimally, selecting the best HNs to achieve their objectives. When there are 10 TNs, the number of HNs equals the TN task-matching capacity, and from TN 11 through 15, the number of HNs is fewer than the number that could serve the maximum capacity of the TN tasks. In such a case, baseline schemes become resource-constrained and exhibit their true performance in a heavy-workload scenario.
The results in
Figure 3 show that the proposed SMUA outperforms all baseline schemes in both low- and high-workload scenarios. Such results can be attributed to two main reasons: (1) In this paper, rather than adopting traditional techniques for defining the HN preference profile, we used the metric of the percentage improvement in time to rank TN tasks. With this objective function, HNs prefer lonely tasks and seek to improve network time efficiency. The results show that our preference-profiling technique generates a matching trend that consistently outperforms all baseline schemes in both low- and high-workload scenarios, and (2) when we solve the externalities problem for POMH resource allocation, HNs become more agile in pursuit of their defined objective function. When solving the externalities problem, HNs make informed matching decisions based on the status of matches held with TNs; therefore, they can produce the most time-efficient results.
Among the baseline schemes, we observe that the objective of POST is time efficiency, whereas the objective of other schemes is energy efficiency. This disparity in HN objective functions impacts the time efficiency results in
Figure 3. The results show that POST has a shorter task computation time than other baseline schemes. In low-workload scenarios, POST and SMRETO perform similar to SMUA until the number of HNs decreases in proportion to the maximum number of possible sub-tasks. FEMTO, on the other hand, seeks only one match to offload a portion of its task to a single HN, resulting in consistent performance in the current simulation settings.
5.4. Number of Non-Beneficial TNs
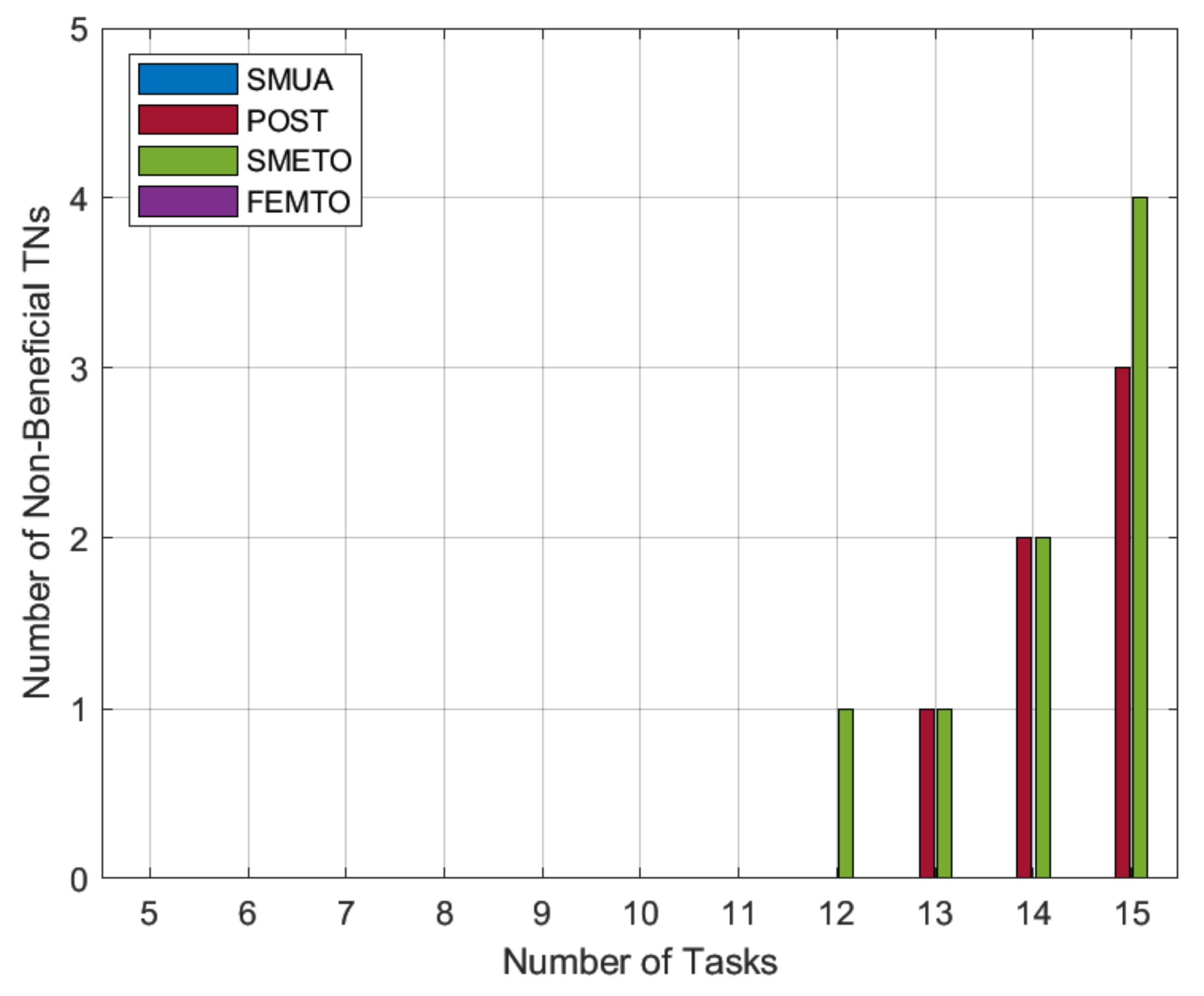
Figure 4 gives the number of TNs that did not benefit from the offloading process. This benefit is in terms of reduced task completion time as compared to local task computation time. This reflects the case where a TN task receives no matches and must compute the entire task
locally. The results in
Figure 4 reflect the dominance of our preference-profiling technique for HNs, in which a maximum number of TN tasks takes advantage of HN free computation resources. This happens because with our preference-profile technique, HNs favor lonely tasks, and hence serve the maximum number of TN tasks. On the other hand, the baseline schemes POST and SMRETO do not prioritize maximizing the number of beneficial TN tasks; the number of un-served TN tasks increases as the proportionate number of HNs decreases. The results also show that there is no non-beneficial TN task for FEMTO. This happens because FEMTO only offloads to a single HN, and when we map this requirement to present simulation settings, the number of available HNs is always more than the number of sub-tasks to be offloaded. As a result, FEMTO has no un-served TN task.
5.5. In-Depth Analysis of POMH Externalities
We aim to test the efficacy of our preference-profiling technique and test the factors that contribute positively and negatively to the effectiveness of solving externalities problems for resource allocation in POMH. As a result, we compare the performance of the proposed SMUA to (1) a non-externalities-based matching technique based on our preference-profiling technique for HNs (referred to as NEMA) and (2) a non-externalities-based matching technique based on the traditional preference-profiling technique for HNs (referred to as Gr-NEMA).
5.5.1. Task Latency
Before delving into the results of the baseline schemes under review, let us first understand the types of preference profiles and their expected matching patterns that affect the simulation results. The traditional preference-profiling technique, Gr-NEMA, sets HN preference order in ascending order based on the amount of time required to complete the task. This preference-profiling technique is expected to generate a matching trend in which HNs prefer smaller tasks and tasks with more matches, potentially reducing the workload that HNs may need to perform. This means that HNs shy away from TN tasks, saving their own computation time while increasing network computation time. By contrast, we use the metric of the percentage improvement in time to rank TN tasks for HNs. With this preference profile, HNs prefer lonely tasks and seek to improve network time efficiency. When we solve the externalities problem with this preference trend, HNs become more agile in pursuit of their defined objective function and can produce the most time-efficient results.
The task latency results in
Figure 5 are consistent with the corresponding matching trends, and we can observe that Gr-NEMA has the worst performance, since HNs were solely concerned with saving their own time and effort. We may reasonably deduce from the results that in Gr-NEMA, all HNs seek to lower their task completion time but end up working for longer periods. NEMA, on the other hand, has better task latency results due to a superior preference-profiling technique. We get the best time–task latency result when we solve the externalities problem and allow every HN to make an informed matching-update decision based on the matches held with TN tasks.
Though the proposed SMUA gives better results, it is important to note that from TN-5 to TN-9 in a low-workload scenario, there is a chance that non-externality-based matching techniques may give better time reduction. This is because the JM algorithm is derived from the Roth and Vande algorithm [
31], and we know that the RV algorithm always produces different stable matching results depending on the sequence in which externalities are solved. Therefore, there is a chance that a sequence order may appear in a low-workload scenario when a non-externalities-based matching algorithm performs better than the proposed SMUA.
5.5.2. Number of Non-Beneficial TNs
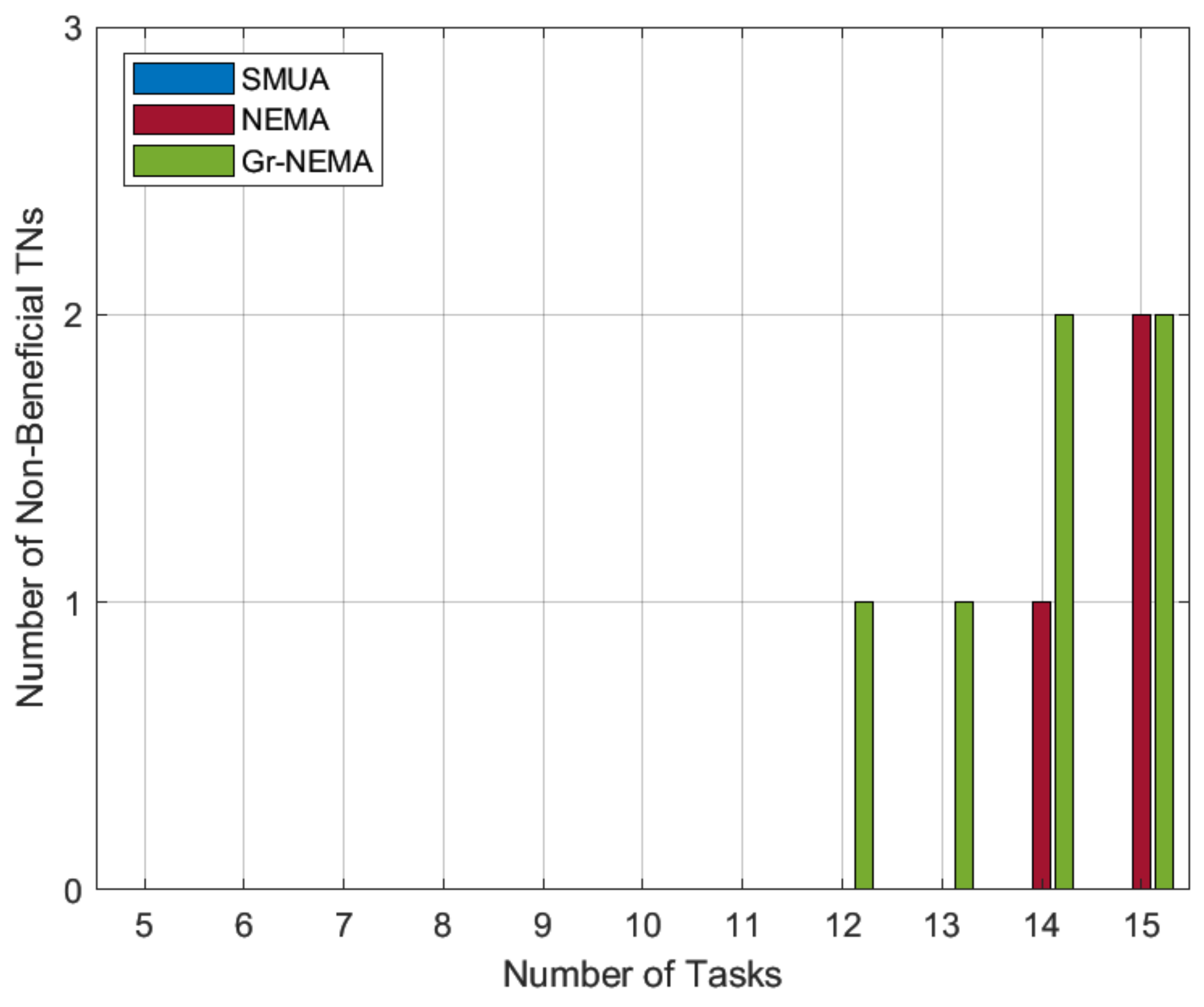
As previously explained, Gr-NEMA generates matching trends in which HNs prefer small tasks with more matches. In this configuration, the likelihood of a large number of non-beneficial TN tasks increases, whereas with the preference profile based on the metric of the percentage improvement in time, HNs prefer lonely tasks and seek to improve network time efficiency. Almost all TN tasks will be served in this configuration. If some are left un-served, it is the result of NEMA’s ill-informed decision-making. In contrast, SMUA always makes informed decisions and is expected to have few to no non-beneficial TN tasks.
The results in
Figure 6 confirm our predictions about the matching trends from the two preference-profiling techniques. The results suggest that preference profiling based on percentage improvement of time can also be used to reduce task outages. Reducing task outages refers to the situation in which we maximize the number of tasks served by HNs.
5.5.3. Varying Quota of TN Tasks
The purpose of this simulation is to examine the effect of permissible TN task quota
r on task latency and the number of non-beneficial TN tasks. For this purpose, we let the number of TN tasks range from 5 to 35 with 30 HNs and a TN quota
r ranging from 2 to 5. These numbers depict a wide range of workload scenarios, from very low to very high. The results in
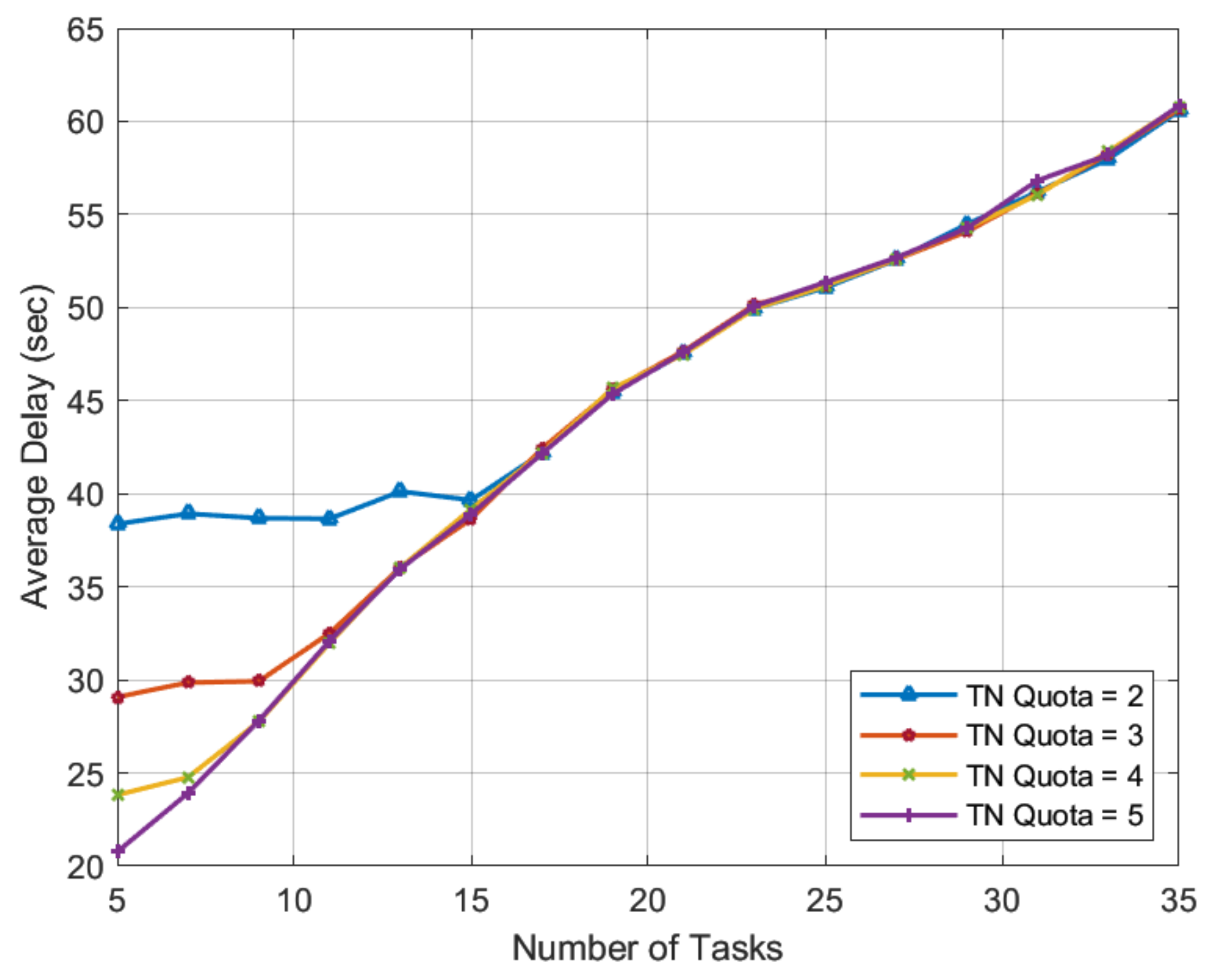
Figure 7 show that with the HN preference-profiling technique proposed in the paper, the TN quota
r has a significant impact on task latency only in low-workload scenarios. The greater the number of HNs that TN tasks can engage with its high quota, the shorter the task completion time. This advantage of the TN task quota is valid until the multiple of the TN task quota and TN tasks equals or exceeds the number of available HNs. This can be seen in
Figure 7, where the impact of different TN task quotas
r on task completion time nearly vanishes once the number of TN tasks reaches 15.
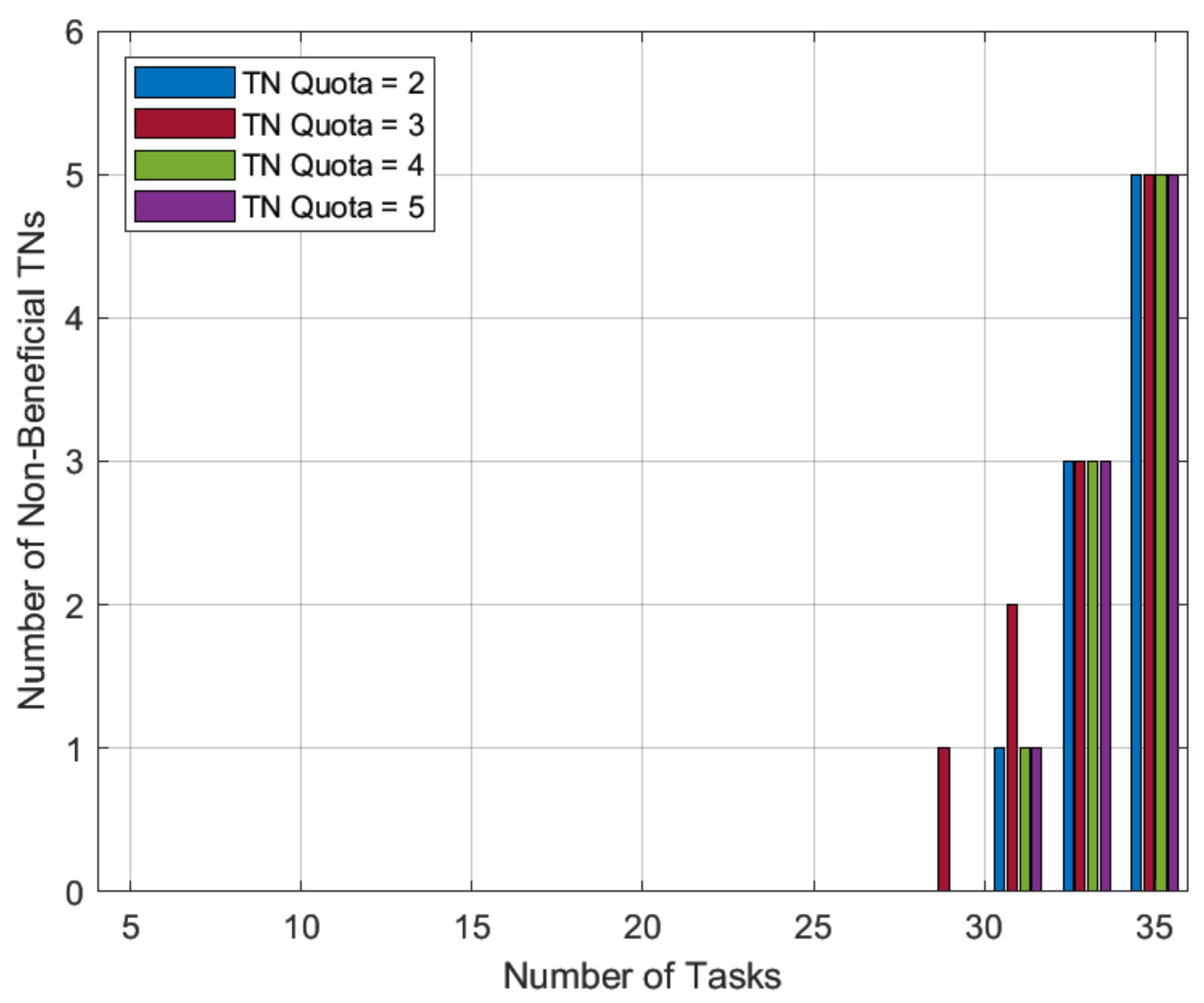
As we approach very-high-workload scenarios, i.e., for TN tasks ranging from 31 to 35, the number of HNs is insufficient to serve all TN tasks even with a single match. In this paper, we used a novel HN preference-profiling technique in the proposed SMUA, which is based on a percentage improvement in task completion time. This HN preference-profiling technique was expected to prefer lonely tasks and serve the greatest number of TN tasks. Except for TN tasks 29 and 31 with quota of 3, the results in
Figure 8 are consistent with the expected matching trend, where we see that despite a wide range of allowable quotas
r for TN tasks, HNs did not converge to match the same TN task. This deviation is a confirmation of RV findings of stable matching depending on the order in which externalities are solved [
31]. Therefore, the occurrence of such an odd incident, especially near the border, is not surprising. We can safely conclude from the results that the proposed algorithm automatically adjusts to serve a maximum number of TN tasks while minimizing task completion time.
6. Conclusions
The paper proposes a new algorithm for parallel task offloading in IoT networks to improve task latency. The proposed technique uses many-to-one matching to solve the problem of mapping between sub-tasks at IoT nodes and computational resources at fog nodes. The proposed work further utilizes the JM algorithm to address externalities and to resolve blocking pairs due to dynamic preference profiles. Detailed performance evaluation is performed for the proposed technique and compared with different recently proposed techniques in the literature. Results highlight that the proposed technique improves task latency by 52% at high task loads. A further detailed evaluation of the proposed technique is presented to highlight the benefits of the algorithm’s key features, such as the preference profile technique, the use of the JM algorithm to resolve externalities, and the number of task-split selections.
Author Contributions
This article was prepared through the collective efforts of all the authors. Conceptualization, U.M.M., M.A.J., J.F., J.R. and W.U.K.; Critical review, U.M.M., M.A.J., J.F., J.R. and W.U.K.; Writing—original draft, U.M.M. and M.A.J.; Writing—review and editing, J.F., J.R. and W.U.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Ministry of Education, Youth and Sports of the Czech Republic under grant SP2022/5 conducted by VSB—Technical University of Ostrava, Czechia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is available from the corresponding author on request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
Notations used in the paper (explanations of sets with multiple values are provided with respect to the order in which the values are presented).
| H, S | Set of HNs and TN tasks |
| k, m | Number of HNs and number of TNs |
| , r | TN task size and number of sub-tasks to offload (quota) |
| , | Percentage of task locally computed and offloaded to HNs |
| , | Task deadline and task local computation time |
| , , | HN CPU speed, TN CPU speed, and CPU cycles to compute one bit of task |
| , | Bandwidth between HN and TN and transmission rate |
| , | White-noise power and channel gain |
| TN transmit power |
| , | Sub-task transmission time and sequence time |
| , | All sub-task transmission time and local computation time |
| , | HN computation time and HN latency for sub-task |
| , q | Task total latency and quota of HN |
| , | HN preference profile and TN task preference profile |
| , | Association set of with TN tasks and TN task with HNs |
References
- Giordani, M.; Polese, M.; Mezzavilla, M.; Rangan, S.; Zorzi, M. Toward 6G Networks: Use Cases and Technologies. IEEE Commun. Mag. 2020, 58, 55–61. [Google Scholar] [CrossRef]
- Khan, W.U.; Javed, M.A.; Nguyen, T.N.; Khan, S.; Elhalawany, B.M. Energy-Efficient Resource Allocation for 6G Backscatter-Enabled NOMA IoV Networks. IEEE Trans. Intell. Transp. Syst. 2021, 23, 9775–9785. [Google Scholar] [CrossRef]
- Malik, U.M.; Javed, M.A.; Zeadally, S.; Islam, S.u. Energy efficient fog computing for 6G enabled massive IoT: Recent trends and future opportunities. IEEE Internet Things J. 2021, 9, 14572–14594. [Google Scholar] [CrossRef]
- Ahmed, M.; Raza, S.; Mirza, M.A.; Aziz, A.; Khan, M.A.; Khan, W.U.; Li, J.; Han, Z. A survey on vehicular task offloading: Classification, issues, and challenges. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 4135–4162. [Google Scholar] [CrossRef]
- Ahmed, M.; Khan, W.U.; Ihsan, A.; Li, X.; Li, J.; Tsiftsis, T.A. Backscatter Sensors Communication for 6G Low-Powered NOMA-Enabled IoT Networks Under Imperfect SIC. IEEE Syst. J. 2022, 1–11. [Google Scholar] [CrossRef]
- Javed, M.A.; Nguyen, T.N.; Mirza, J.; Ahmed, J.; Ali, B. Reliable Communications for Cybertwin driven 6G IoVs using Intelligent Reflecting Surfaces. IEEE Trans. Ind. Inform. 2022. [Google Scholar] [CrossRef]
- Liu, J.; Ahmed, M.; Mirza, M.A.; Khan, W.U.; Xu, D.; Li, J.; Aziz, A.; Han, Z. RL/DRL Meets Vehicular Task Offloading Using Edge and Vehicular Cloudlet: A Survey. IEEE Internet Things J. 2022, 9, 8315–8338. [Google Scholar] [CrossRef]
- Javed, M.A.; Zeadally, S.; Hamida, E.B. Data analytics for Cooperative Intelligent Transport Systems. Veh. Commun. 2019, 15, 63–72. [Google Scholar] [CrossRef]
- Javed, M.A.; Zeadally, S. AI-Empowered Content Caching in Vehicular Edge Computing: Opportunities and Challenges. IEEE Netw. 2021, 35, 109–115. [Google Scholar] [CrossRef]
- Xie, J.; Jia, Y.; Chen, Z.; Nan, Z.; Liang, L. Efficient task completion for parallel offloading in vehicular fog computing. China Commun. 2019, 16, 42–55. [Google Scholar] [CrossRef]
- Farooq, U.; Shabir, M.W.; Javed, M.A.; Imran, M. Intelligent energy prediction techniques for fog computing networks. Appl. Soft Comput. 2021, 111, 107682. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Kim, D.S. FRATO: Fog Resource Based Adaptive Task Offloading for Delay-Minimizing IoT Service Provisioning. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2491–2508. [Google Scholar] [CrossRef]
- Chiti, F.; Fantacci, R.; Picano, B. A Matching Theory Framework for Tasks Offloading in Fog Computing for IoT Systems. IEEE Internet Things J. 2018, 5, 5089–5096. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, K.; Li, K.; Zhou, M.T.; Yang, Y. Parallel Scheduling of Multiple Tasks in Heterogeneous Fog Networks. In Proceedings of the 2019 25th Asia-Pacific Conference on Communications (APCC), Ho Chi Minh, Vietnam, 6–8 November 2019; pp. 413–418. [Google Scholar] [CrossRef]
- Alimudin, A.; Ishida, Y. Matching-Updating Mechanism: A Solution for the Stable Marriage Problem with Dynamic Preferences. Entropy 2022, 24, 263. [Google Scholar] [CrossRef]
- Knuth, D.E. Stable Marriage and Its Relation to Other Combinatorial Problems: An Introduction to the Mathematical Analysis of Algorithms; American Mathematical Society: Providence, RI, USA, 1997. [Google Scholar]
- Ma, J. On Randomized Matching Mechanisms. Econ. Theory 1996, 8, 377–381. [Google Scholar] [CrossRef]
- Roth, A.E. Deferred Acceptance Algorithms: History, Theory, Practice, and Open Questions; Working Paper 13225; National Bureau of Economic Research: Cambridge, MA, USA, 2007. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, Y.; Lok, T.M.; Huang, K. Multiuser Computation Offloading and Downloading for Edge Computing With Virtualization. IEEE Trans. Wirel. Commun. 2019, 18, 4298–4311. [Google Scholar] [CrossRef]
- Zhang, G.; Shen, F.; Liu, Z.; Yang, Y.; Wang, K.; Zhou, M. FEMTO: Fair and Energy-Minimized Task Offloading for Fog-Enabled IoT Networks. IEEE Internet Things J. 2019, 6, 4388–4400. [Google Scholar] [CrossRef]
- Sahni, Y.; Cao, J.; Yang, L.; Ji, Y. Multi-Hop Multi-Task Partial Computation Offloading in Collaborative Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1133–1145. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Wang, W. Joint optimization of computation cost and delay for task offloading in vehicular fog networks. Trans. Emerg. Telecommun. Technol. 2020, 31, e3818. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, Y.; Huang, X.; Fang, C.; Zhang, P. Ultra-Low Latency Multi-Task Offloading in Mobile Edge Computing. IEEE Access 2021, 9, 32569–32581. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Kong, X.; Xia, F. A Cooperative Partial Computation Offloading Scheme for Mobile Edge Computing Enabled Internet of Things. IEEE Internet Things J. 2019, 6, 4804–4814. [Google Scholar] [CrossRef]
- Thai, M.T.; Lin, Y.D.; Lai, Y.C.; Chien, H.T. Workload and Capacity Optimization for Cloud-Edge Computing Systems with Vertical and Horizontal Offloading. IEEE Trans. Netw. Serv. Manag. 2020, 17, 227–238. [Google Scholar] [CrossRef]
- Deb, P.K.; Misra, S.; Mukherjee, A. Latency-Aware Horizontal Computation Offloading for Parallel Processing in Fog-Enabled IoT. IEEE Syst. J. 2021, 16, 2537–2544. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, Y.; Wang, K.; Shao, Z.; Zhang, J. POST: Parallel Offloading of Splittable Tasks in Heterogeneous Fog Networks. IEEE Internet Things J. 2020, 7, 3170–3183. [Google Scholar] [CrossRef]
- Zu, Y.; Shen, F.; Yan, F.; Shen, L.; Qin, F.; Yang, R. SMETO: Stable Matching for Energy-Minimized Task Offloading in Cloud-Fog Networks. In Proceedings of the 2019 IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Kim, D.S. Impact of Task Splitting on the Delay Performance of Task Offloading in the IoT-enabled Fog Systems. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 19–21 October 2021; pp. 661–663. [Google Scholar] [CrossRef]
- Bozorgchenani, A.; Tarchi, D.; Corazza, G. An Energy and Delay-Efficient Partial Offloading Technique for Fog Computing Architectures. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Roth, A.; Vande Vate, J. Random Paths to Stability in Two-Sided Matching. Econometrica 1990, 58, 1475–1480. [Google Scholar] [CrossRef] [Green Version]
- Basir, R.; Qaisar, S.; Ali, M.; Naeem, M. Cloudlet Selection in Cache-Enabled Fog Networks for Latency Sensitive IoT Applications. IEEE Access 2021, 9, 93224–93236. [Google Scholar] [CrossRef]
- Lyu, X.; Tian, H.; Sengul, C.; Zhang, P. Multiuser Joint Task Offloading and Resource Optimization in Proximate Clouds. IEEE Trans. Veh. Technol. 2017, 66, 3435–3447. [Google Scholar] [CrossRef]
- Bertsimas, D.; Tsitsiklis, J.N. Introduction to Linear Optimization; Athena Scientific: Belmont, MA, USA, 1997; Volume 6. [Google Scholar]
- Baïou, M.; Balinski, M. Many-to-many matching: Stable polyandrous polygamy (or polygamous polyandry). Discret. Appl. Math. 2000, 101, 1–12. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, J.; Cai, Z.; Ni, Q.; Zhou, T.; Yu, J.; Chen, H.; Liu, F. Resolving Multi-task Competition for Constrained Resources in Dispersed Computing: A Bilateral Matching Game. IEEE Internet Things J. 2021, 8, 16972–16983. [Google Scholar] [CrossRef]
- Swain, C.; Sahoo, M.N.; Satpathy, A.; Muhammad, K.; Bakshi, S.; Rodrigues, J.J.P.C.; de Albuquerque, V.H.C. METO: Matching-Theory-Based Efficient Task Offloading in IoT-Fog Interconnection Networks. IEEE Internet Things J. 2021, 8, 12705–12715. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}