

Multi-Agent Multi-View Collaborative Perception Based on Semi-Supervised Online Evolutive Learning


Abstract
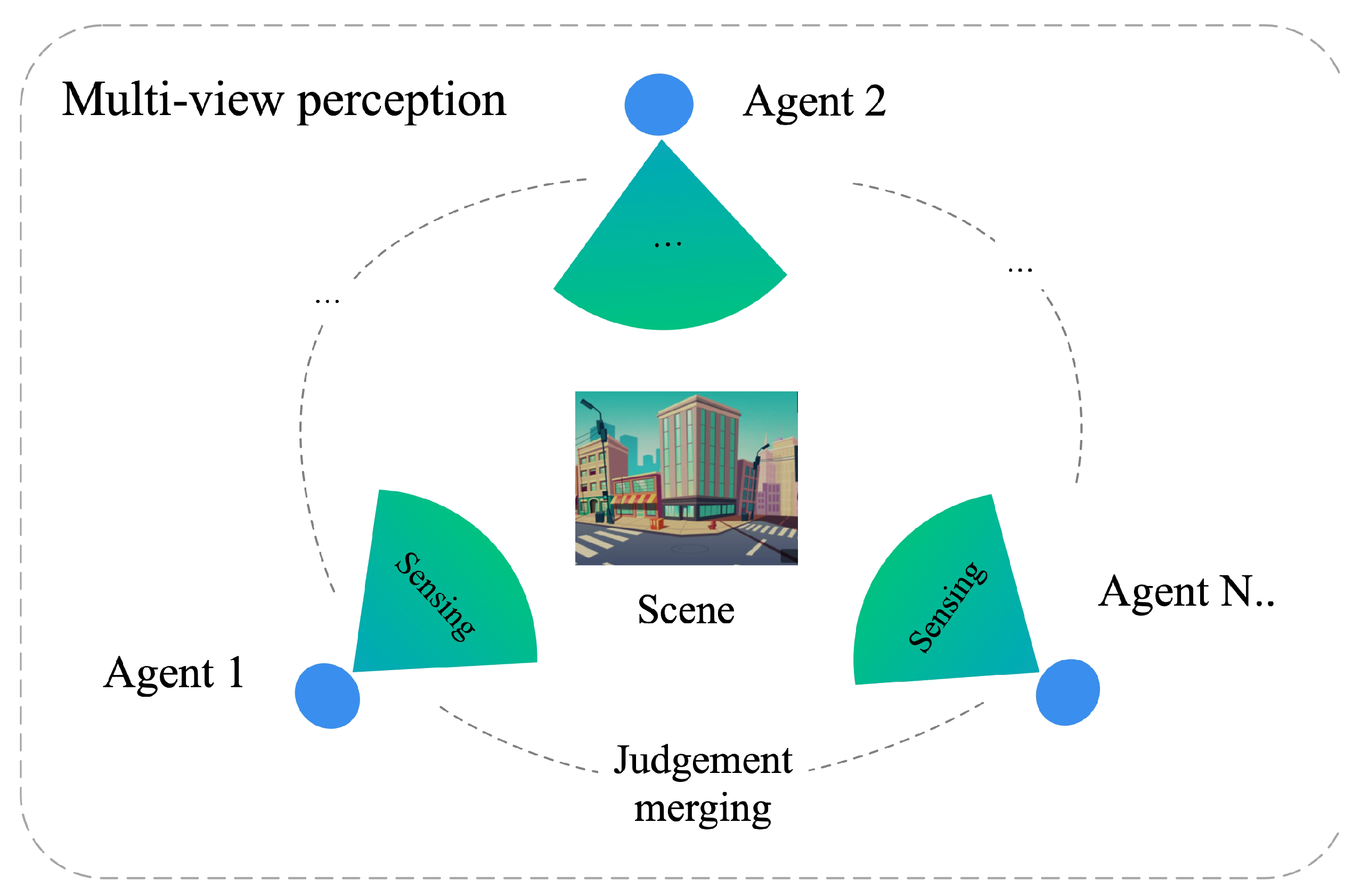
:1. Introduction
- We analyze the existing problems of multi-agent collaboration and data-distribution adaptation in the multi-view sensing environment. We propose the multi-view agent’s collaborative perception (MACP) semi-supervised online evolutive learning method. MACP can reduce the task complexity of multi-model SSL when processing multi-view perception data and realize real-time tuning of the local perception system.
- In MACP, we enable each model to learn a differentiated feature-extraction mode through a self-supervised model-initialization method, which enhances the discriminative independence of each model. By applying the discriminative information-fusion approach to the predictions of each view model, the reliability of the discriminant results is improved, and continuous consistency regularization training is realized. Through further regularization constraints on the parameters of each model in the training process, the model can continue to maintain a relatively independent discriminative ability, and the stability of the entire OEL system is improved.
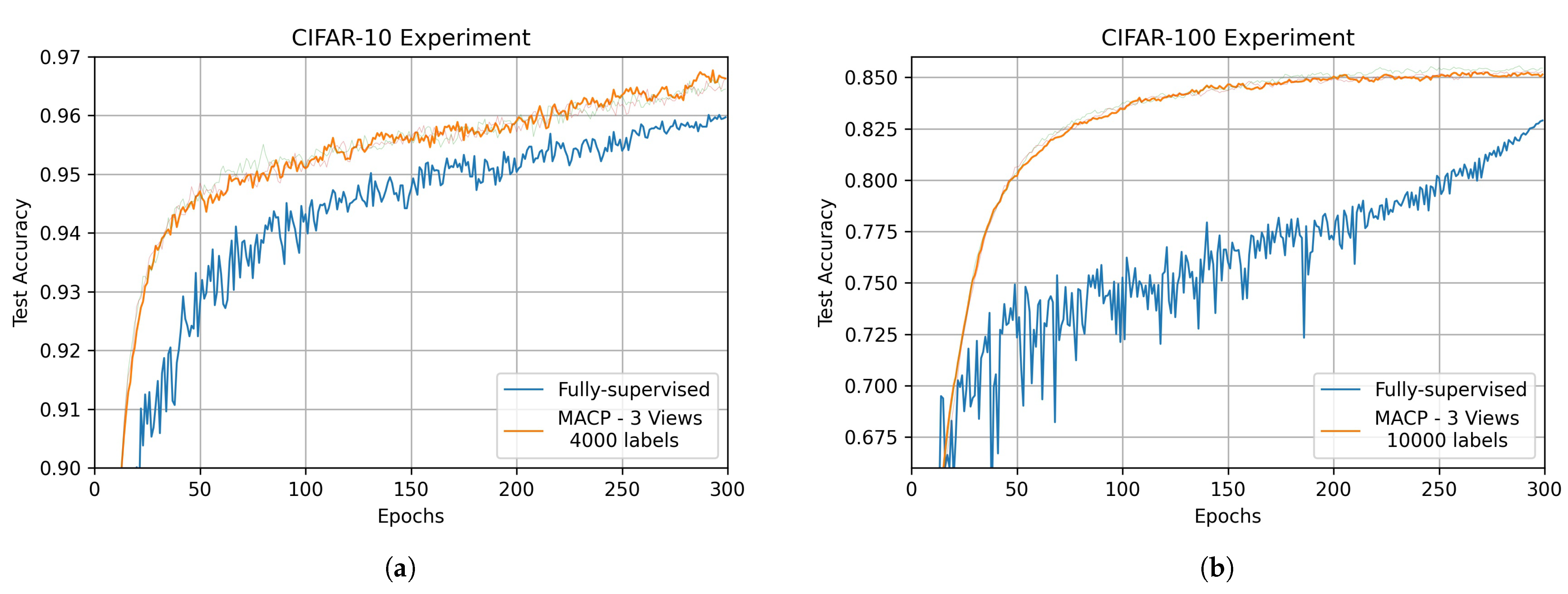
- The proposed MACP achieves a better performance than the comparison methods on multiple datasets. In an ideal multi-view agent collaborative perception experiment, MACP exceeds the performance of the fully supervised learning method, which proves the applicability of the proposed method in practical multi-view sensing scenarios.
2. Related Work
3. Proposed Methods
3.1. Problem Definition
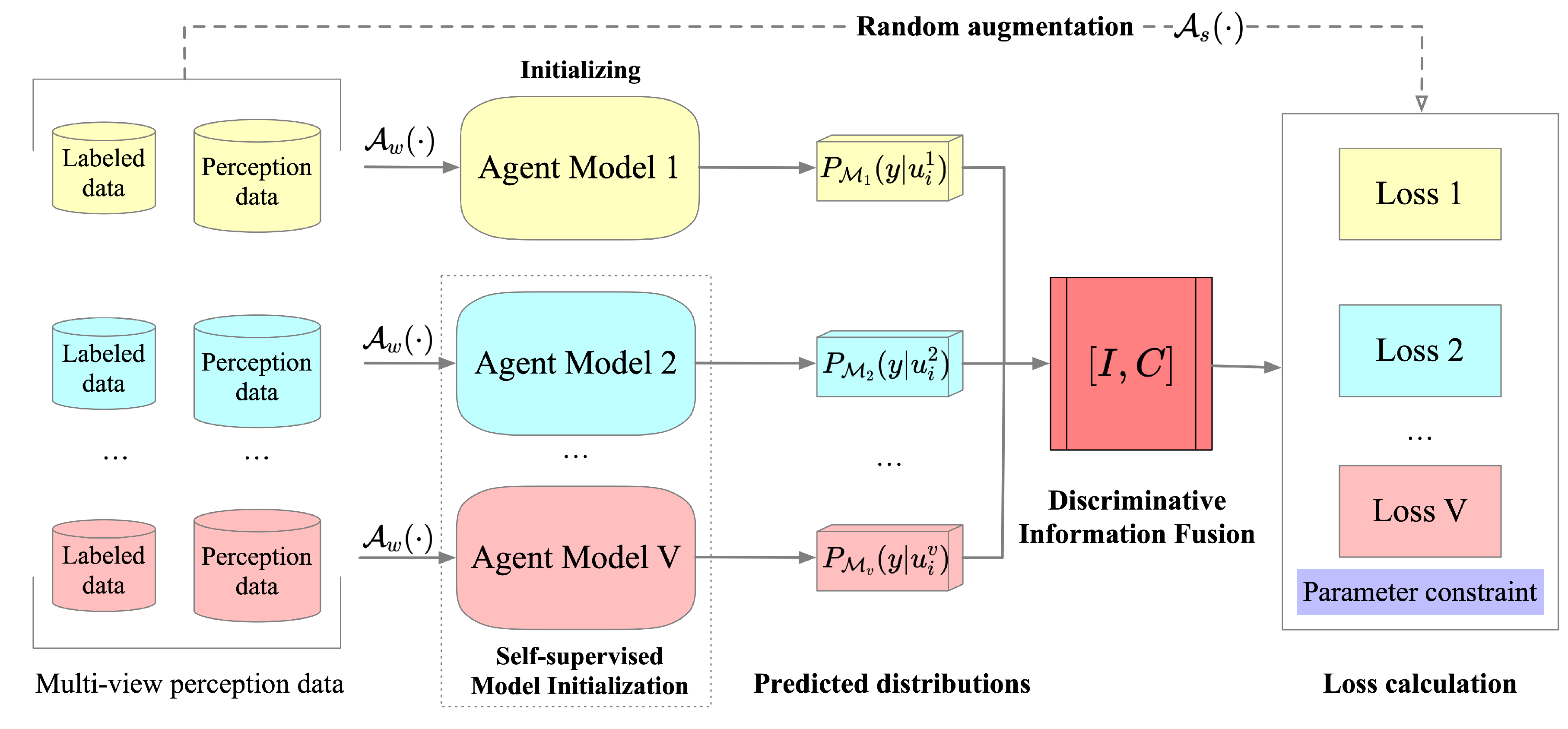
3.2. Overall Framework
3.3. Self-Supervised Model Initialization
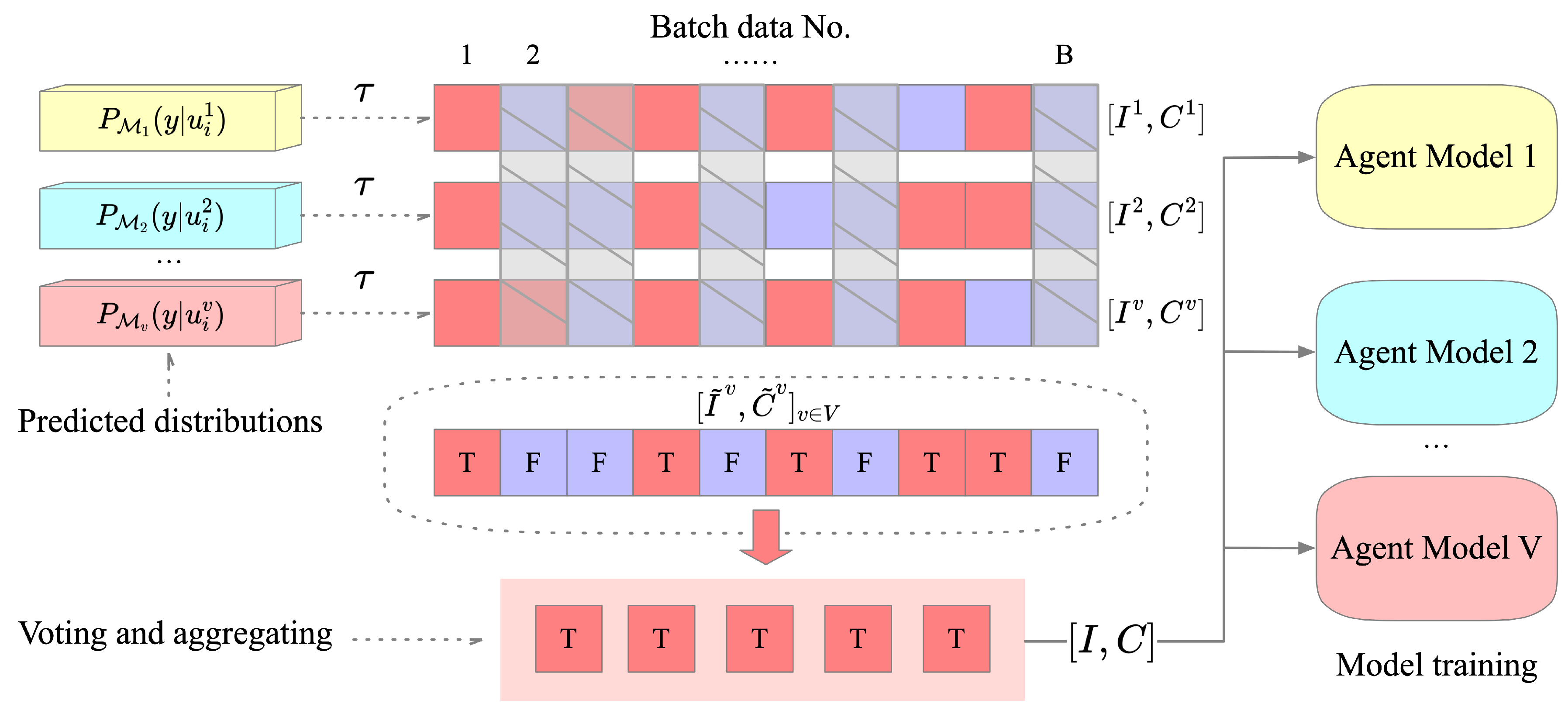
3.4. Discriminative Information-Fusion
3.5. Parameter Constraint
4. Experiments
4.1. Implementation Details
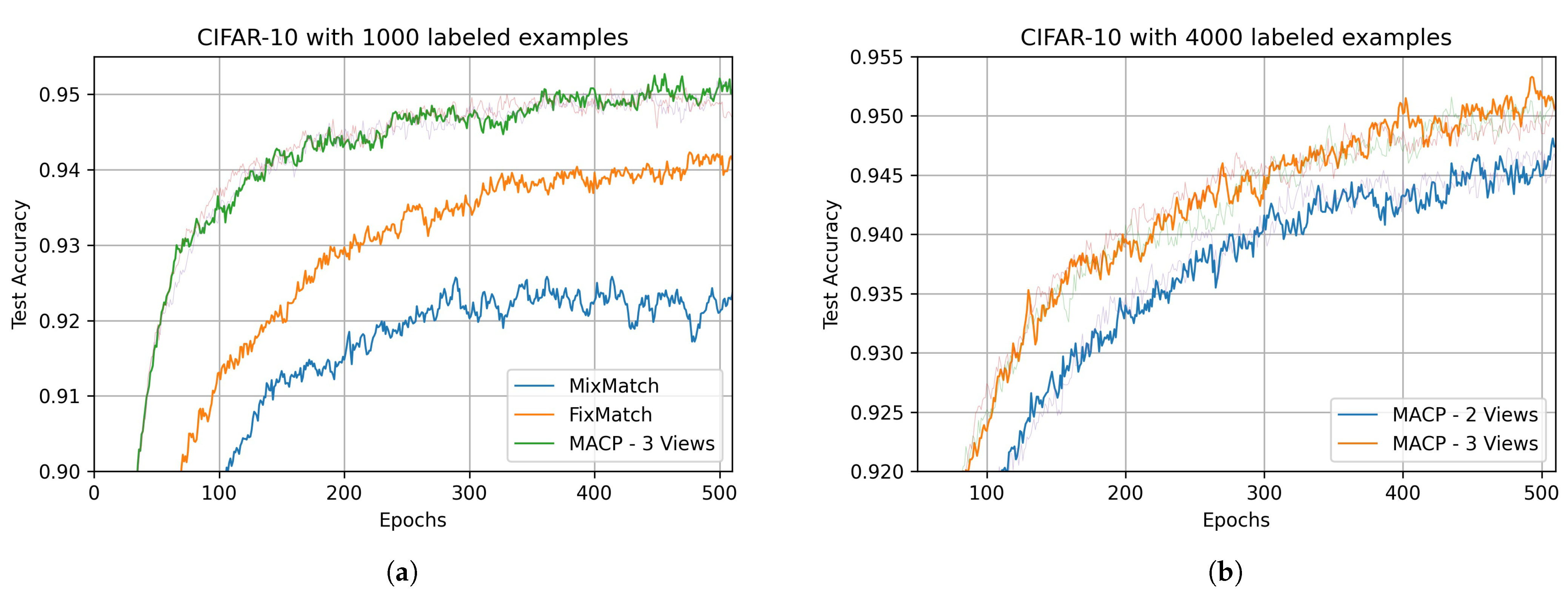
4.2. Main Results
4.3. Ideal Multi-View Perception Experiments
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge intelligence: The confluence of edge computing and artificial intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Li, E.; Zhou, Z.; Chen, X. Edge intelligence: On-demand deep learning model co-inference with device-edge synergy. In Proceedings of the 2018 Workshop on Mobile Edge Communications, Budapest, Hungary, 20 August 2018; pp. 31–36. [Google Scholar]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. Adv. Neural Inf. Process. Syst. 2020, 33, 22243–22255. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Song, L.; Hu, X.; Zhang, G.; Spachos, P.; Plataniotis, K.; Wu, H. Networking Systems of AI: On the Convergence of Computing and Communications. IEEE Internet Things J. 2022. [Google Scholar] [CrossRef]
- Li, D.; Zhu, X.; Song, L. Mutual match for semi-supervised online evolutive learning. Appl. Intell. 2022, 1–15. [Google Scholar] [CrossRef]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Introduction to Semi-Supervised Learning; Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2009. [Google Scholar]
- Klayman, J. Varieties of confirmation bias. Psychol. Learn. Motiv. 1995, 32, 385–418. [Google Scholar]
- Nassar, I.; Herath, S.; Abbasnejad, E.; Buntine, W.L.; Haffari, G. All Labels Are Not Created Equal: Enhancing Semi-Supervision via Label Grouping and Co-Training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7241–7250. [Google Scholar]
- Sellars, P.; Aviles-Rivero, A.I.; Schönlieb, C.B. LaplaceNet: A Hybrid Energy-Neural Model for Deep Semi-Supervised Classification. arXiv 2021, arXiv:2106.04527. [Google Scholar]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A survey on deep semi-supervised learning. arXiv 2021, arXiv:2103.00550. [Google Scholar]
- Shi, C.; Lv, Z.; Yang, X.; Xu, P.; Bibi, I. Hierarchical multi-view semi-supervised learning for very high-resolution remote sensing image classification. Remote Sens. 2020, 12, 1012. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Bachman, P.; Alsharif, O.; Precup, D. Learning with Pseudo-Ensembles. Adv. Neural Inf. Process. Syst. 2014, 2, 3365–3373. [Google Scholar]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization With Stochastic Transformations and Perturbations for Deep Semi-Supervised Learning. Adv. Neural Inf. Process. Syst. 2016, 29, 1163–1171. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.J.; Papernot, N.; Oliver, A.; Raffel, C. MixMatch: A Holistic Approach to Semi-Supervised Learning. Adv. Neural Inf. Process. Syst. 2019, 32, 5050–5060. [Google Scholar]
- Goodfellow, I.J.; Bengio, Y.; Courville, A.C. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Li, D.; Liu, Y.; Song, L. Adaptive Weighted Losses with Distribution Approximation for Efficient Consistency-based Semi-supervised Learning. IEEE Trans. Circuits Syst. Video Technol. 2022. [Google Scholar] [CrossRef]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison, WI, USA, 24–26 July 1998; pp. 92–100. [Google Scholar]
- Qiao, S.; Shen, W.; Zhang, Z.; Wang, B.; Yuille, A. Deep co-training for semi-supervised image recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–152. [Google Scholar]
- Zhou, Z.H.; Li, M. Tri-training: Exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 2005, 17, 1529–1541. [Google Scholar] [CrossRef]
- Dong-DongChen, W.; WeiGao, Z.H. Tri-net for semi-supervised deep learning. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 2014–2020. [Google Scholar]
- Breiman, L. Randomizing outputs to increase prediction accuracy. Mach. Learn. 2000, 40, 229–242. [Google Scholar] [CrossRef] [Green Version]
- Jia, X.; Jing, X.Y.; Zhu, X.; Chen, S.; Du, B.; Cai, Z.; He, Z.; Yue, D. Semi-supervised multi-view deep discriminant representation learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2496–2509. [Google Scholar] [CrossRef]
- Zhang, B.; Qiang, Q.; Wang, F.; Nie, F. Fast multi-view semi-supervised learning with learned graph. IEEE Trans. Knowl. Data Eng. 2020, 34, 286–299. [Google Scholar] [CrossRef]
- Nie, F.; Tian, L.; Wang, R.; Li, X. Multiview semi-supervised learning model for image classification. IEEE Trans. Knowl. Data Eng. 2019, 32, 2389–2400. [Google Scholar] [CrossRef]
- Rasmus, A.; Berglund, M.; Honkala, M.; Valpola, H.; Raiko, T. Semi-supervised Learning with Ladder Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 3546–3554. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Ke, Z.; Wang, D.; Yan, Q.; Ren, J.; Lau, R.W. Dual student: Breaking the limits of the teacher in semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6728–6736. [Google Scholar]
- Pham, H.; Dai, Z.; Xie, Q.; Le, Q.V. Meta Pseudo Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11557–11568. [Google Scholar]
- Wei, H.; Feng, L.; Chen, X.; An, B. Combating noisy labels by agreement: A joint training method with co-regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13726–13735. [Google Scholar]
- Wei, C.; Xie, L.; Ren, X.; Xia, Y.; Su, C.; Liu, J.; Tian, Q.; Yuille, A.L. Iterative reorganization with weak spatial constraints: Solving arbitrary jigsaw puzzles for unsupervised representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1910–1919. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 69–84. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 649–666. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Tront, Toronto, ON, Canada, 2009. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. 2011. Available online: http://ufldl.stanford.edu/housenumbers/ (accessed on 24 July 2022).
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide residual networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. In Proceedings of the ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In Defense of Pseudo-Labeling: An Uncertainty-Aware Pseudo-label Selection Framework for Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CIFAR-10 | SVHN | CIFAR-100 |
|---|---|---|---|
| 0.95 | |||
| V | [2, 3] | ||
| 4 | |||
| B | 64 | ||
| K | |||
| 0.05 | |||
| 0.9 | |||
| Weight decay | 0.0005 | ||
| CIFAR-10 | SVHN | CIFAR-100 | |||||
|---|---|---|---|---|---|---|---|
| Method | 1000 Labels | 2000 Labels | 4000 Labels | 250 Labels | 1000 Labels | 4000 Labels | 10,000 Labels |
| Mean Teacher | 21.55 ± 1.48 | 15.73 ± 0.31 | 12.31 ± 0.28 | 4.35 ± 0.50 | 3.95 ± 0.19 | - | - |
| Dual Student | 14.17 ± 0.38 | 10.72 ± 0.19 | 8.89 ± 0.09 | 4.24 ± 0.10 | - | - | 33.08 ± 0.27 |
| Deep CT | - | - | 8.54 ± 0.12 | - | 3.38 ± 0.05 | - | 34.63 ± 0.14 |
| Tri-net | - | - | 8.30 ± 0.15 | - | 3.45 ± 0.10 | - | - |
| UPS | 8.18 ± 0.15 | - | 6.39 ± 0.02 | - | - | 40.77 ± 0.10 | 32.00 ± 0.49 |
| MixMatch | 7.72 ± 0.37 | 6.89 ± 0.39 | 5.21 ± 0.09 | 4.06 ± 0.18 | 3.49 ± 0.32 | 36.12 ± 0.62 | 29.12 ± 0.34 |
| FixMatch | 6.18 ± 0.56 | 5.92 ± 0.32 | 4.99 ± 0.11 | 3.83 ± 0.45 | 3.08 ± 0.63 | 33.78 ± 0.31 | 25.69 ± 0.61 |
| MACP (2 views) | 6.02 ± 0.39 | 5.69 ± 0.40 | 4.91 ± 0.08 | 3.57 ± 0.34 | 2.99 ± 0.26 | 33.52 ± 0.45 | 25.77 ± 0.83 |
| MACP (3 views) | 5.29 ± 0.37 | 5.12 ± 0.31 | 4.75 ± 0.20 | 3.32 ± 0.51 | 2.72 ± 0.15 | 31.67 ± 0.29 | 24.72 ± 0.11 |
| CIFAR-10 | SVHN | CIFAR-100 | |||
|---|---|---|---|---|---|
| Method | 1000 Labels | 4000 Labels | 250 Labels | 1000 Labels | 10,000 Labels |
| Fully-supervised | 95.98 | 97.72 | 82.82 | ||
| MACP (2 views) | 96.23 ± 0.12 | 96.45 ± 0.07 | 97.82 ± 0.31 | 98.16 ± 0.51 | 83.06 ± 0.18 |
| MACP (3 views) | 96.41 ± 0.21 | 96.75 ± 0.03 | 98.21 ± 0.17 | 98.38 ± 0.34 | 85.39 ± 0.11 |
| Module Combination | Dataset | ||||
|---|---|---|---|---|---|
| SMI | DIF | PC | CIFAR-10 | SVHN | CIFAR-100 |
| 92.10 ± 0.72 | 95.15 ± 0.34 | 72.17 ± 0.53 | |||
| ✓ | 93.17 ± 0.19 | 95.98 ± 0.12 | 73.97 ± 0.43 | ||
| ✓ | ✓ | 94.23 ± 0.09 | 96.53 ± 0.31 | 74.92 ± 0.19 | |
| ✓ | ✓ | 94.93 ± 0.36 | 97.03 ± 0.22 | 74.62 ± 0.25 | |
| ✓ | ✓ | ✓ | 95.25 ± 0.20 | 97.28 ± 0.15 | 75.28 ± 0.11 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, D.; Song, L. Multi-Agent Multi-View Collaborative Perception Based on Semi-Supervised Online Evolutive Learning. Sensors 2022, 22, 6893. https://doi.org/10.3390/s22186893
Li D, Song L. Multi-Agent Multi-View Collaborative Perception Based on Semi-Supervised Online Evolutive Learning. Sensors. 2022; 22(18):6893. https://doi.org/10.3390/s22186893
Chicago/Turabian StyleLi, Di, and Liang Song. 2022. "Multi-Agent Multi-View Collaborative Perception Based on Semi-Supervised Online Evolutive Learning" Sensors 22, no. 18: 6893. https://doi.org/10.3390/s22186893