

Literature Review on Ship Localization, Classification, and Detection Methods Based on Optical Sensors and Neural Networks

Abstract
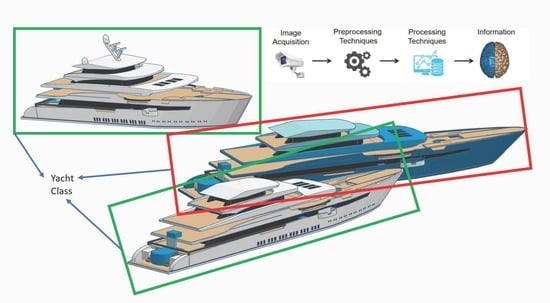
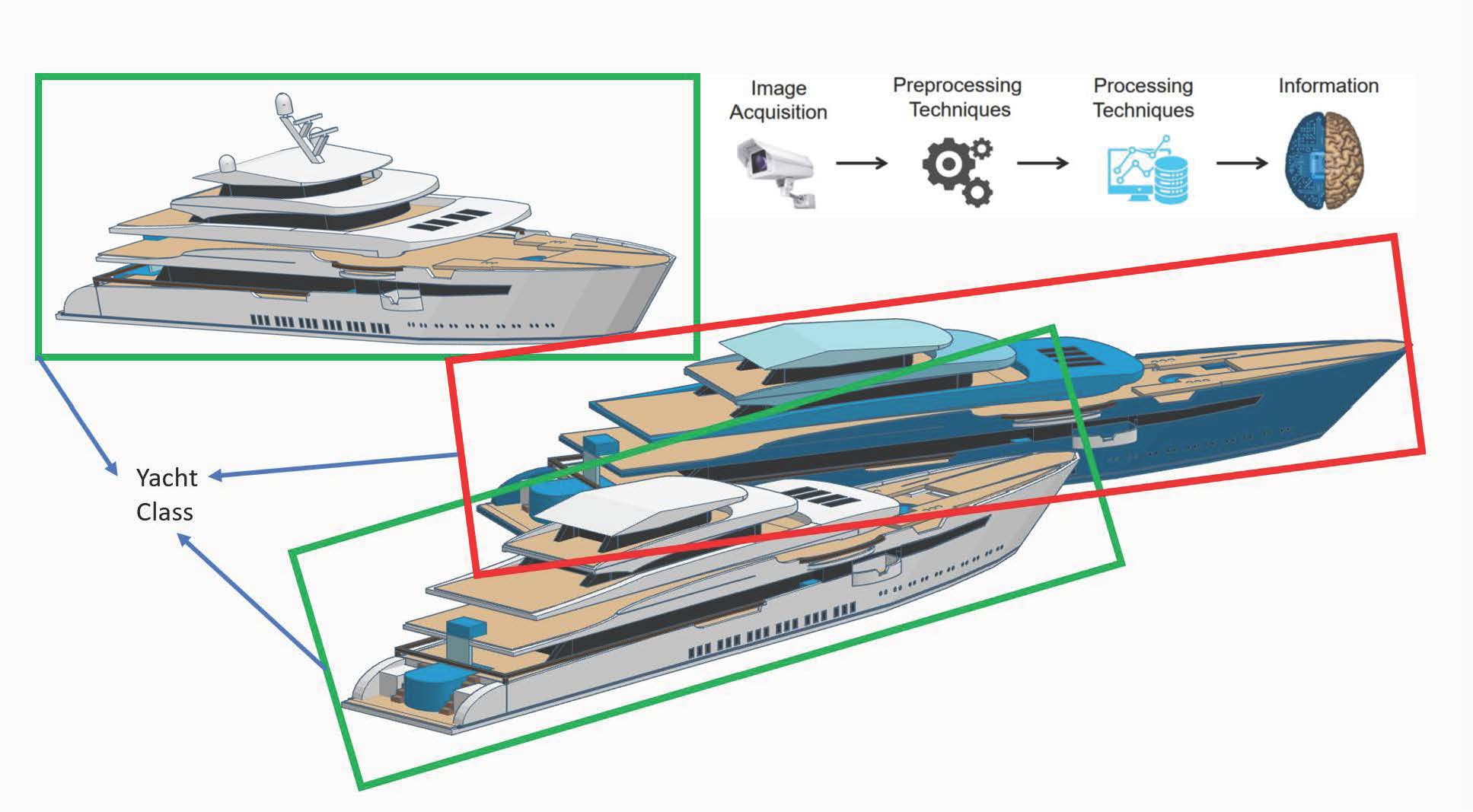
:
1. Introduction
2. Related Works
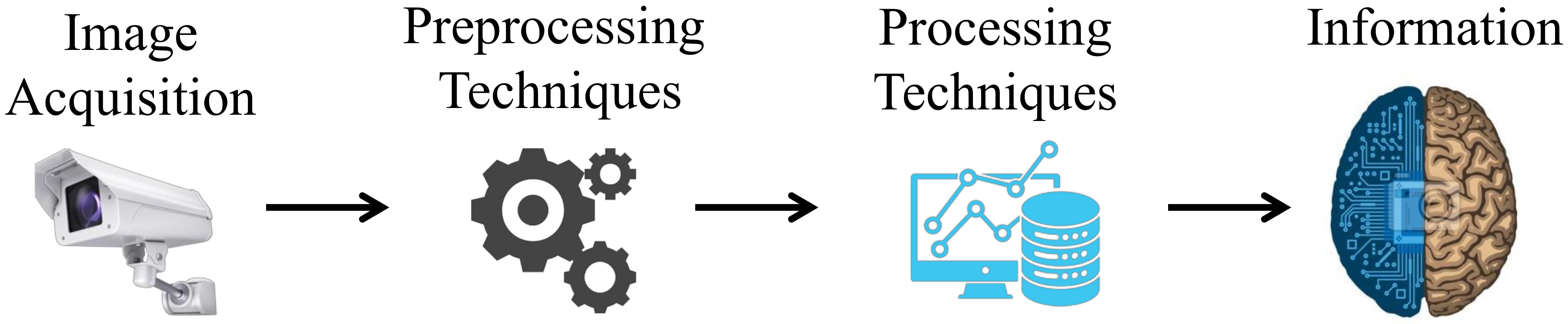
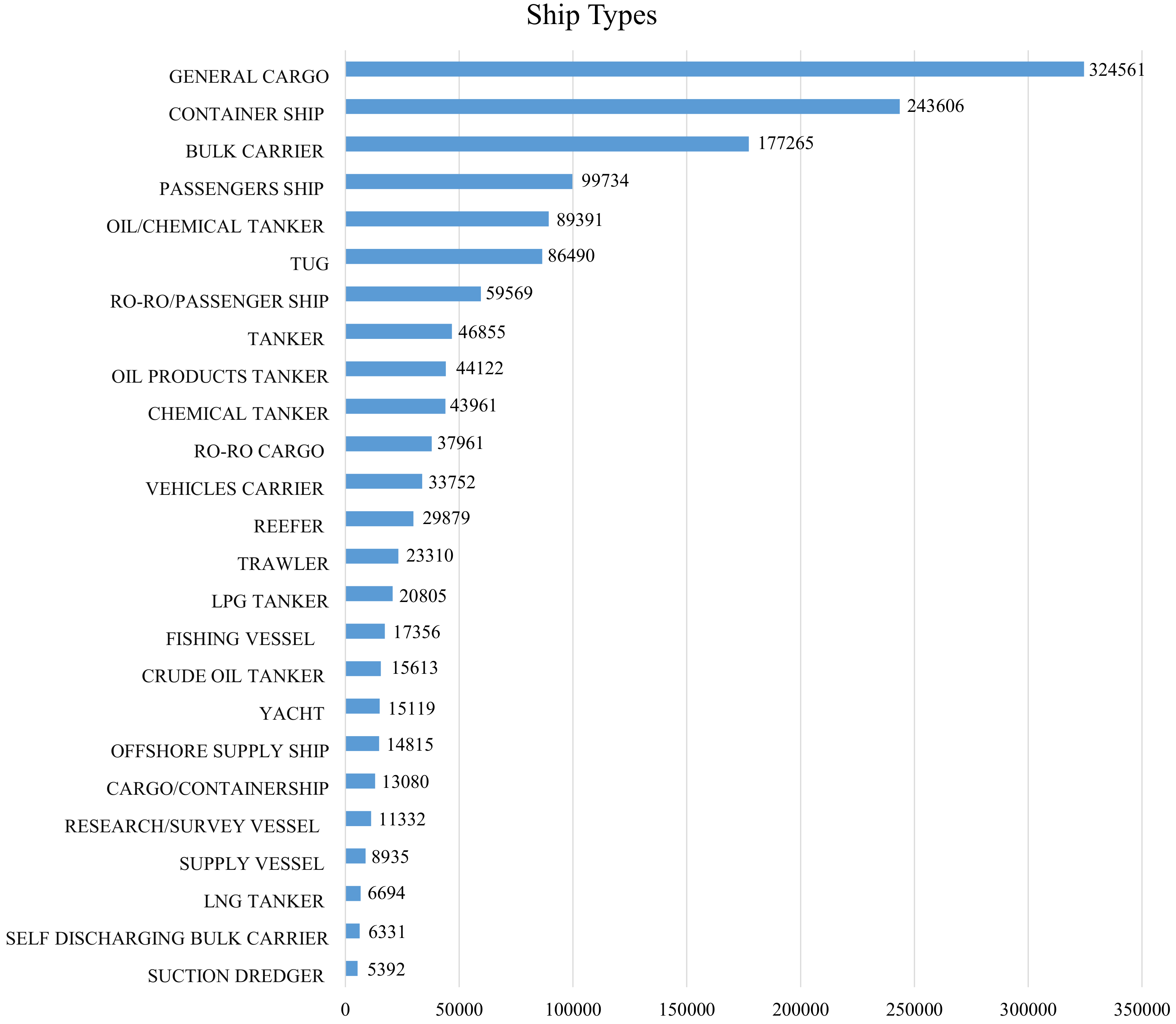
2.1. Image Acquisition
2.2. Preprocessing Techniques
2.2.1. SRCNN
2.2.2. SRResNet
2.2.3. SRGAN
2.2.4. EDSR
2.2.5. MDSR
2.2.6. ESRGAN
2.2.7. RankSRGAN
2.2.8. DBPN
2.2.9. DeblurGAN
2.2.10. DeblurGAN-V2
2.2.11. DeFMO
2.3. Processing Techniques
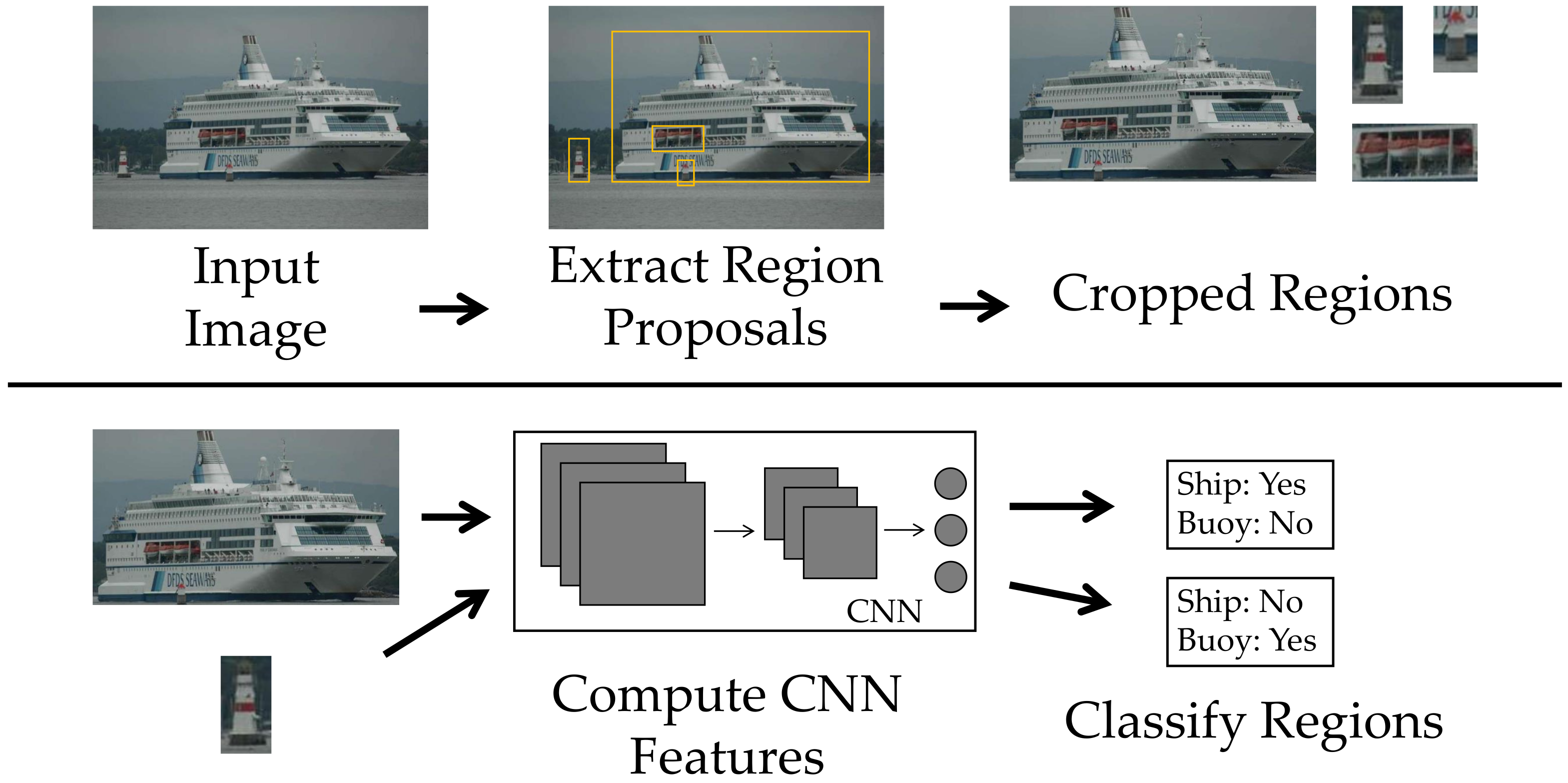
2.3.1. R-CNN
2.3.2. Fast R-CNN
2.3.3. Faster R-CNN
2.3.4. Mask R-CNN

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image View | Approaches | ||||
|---|---|---|---|---|---|
| Papers | Side View | Remote | Localization | Classification | Techniques/Models |
| 2017 [55] | - | x | x | - | FusionNet |
| 2017 [56] | x | - | - | x | VGG16 |
| 2018 [57] | x | - | x | - | Faster R-CNN+ResNet |
| 2018 [58] | - | x | x | - | ResNet-50 |
| 2018 [59] | - | x | x | - | SNN |
| 2018 [60] | - | x | x | x | Faster R-CNN+Inception-ResNet |
| 2018 [61] | - | x | x | - | RetinaNet |
| 2018 [62] | - | x | x | x | R-CNN |
| 2018 [63] | - | x | x | - | R-CNN |
| 2019 [64] | - | x | - | x | VGG19 |
| 2019 [65] | - | x | - | x | VGG16 |
| 2019 [66] | x | - | - | x | Skip-ENet |
| 2019 [67] | - | x | x | x | Cascade R-CNN+B2RB |
| 2019 [68] | - | x | - | x | ResNet-34 |
| 2019 [69] | x | - | x | - | YOLOv3 |
| 2019 [70] | - | x | x | x | VGG16 |
| 2019 [71] | x | - | x | - | Faster R-CNN |
| 2020 [72] | - | x | x | x | SSS-Net |
| 2020 [73] | - | x | x | x | YOLOv3 |
| 2020 [74] | - | x | x | x | CNN |
| 2020 [75] | x | - | x | - | CNN Segmentation |
| 2020 [76] | - | x | x | - | YOLO |
| 2020 [77] | - | x | x | x | ResNet-50+RNP |
| 2020 [78] | x | - | - | x | CNN |
| 2020 [79] | x | - | x | x | YOLOv4 |
| 2020 [80] | - | x | x | - | YOLOv3 |
| 2020 [81] | - | x | - | x | VGG16 |
| 2020 [82] | x | - | x | - | Mask R-CNN+YOLOv1 |
| 2021 [83] | - | x | x | x | Mask RPN+DenseNet |
| 2021 [84] | - | x | x | - | VGG16 |
| 2021 [85] | x | - | x | x | SSD MobileNetV2 |
| 2021 [86] | x | - | x | x | YOLOv3 |
| 2021 [87] | x | - | x | - | Faster R-CNN |
| 2021 [88] | x | - | x | - | R-CNN |
| 2021 [89] | x | - | x | x | BLS |
| 2021 [90] | x | - | x | - | YOLOv5 |
| 2021 [3] | x | - | x | x | MobileNet+YOLOv4 |
| 2021 [91] | - | x | x | x | Cascade R-CNN |
| 2021 [92] | x | - | x | x | YOLOv3 |
| 2021 [93] | - | x | x | x | YOLOv3 |
| 2021 [94] | x | - | x | x | YOLOv3 |
| 2021 [95] | - | x | x | x | YOLOv4 |
| 2021 [96] | x | - | x | x | ResNet-152 |
| 2021 [97] | - | x | x | - | Faster R-CNN |
| 2022 [92] | x | - | x | x | YOLOv4 |
| 2022 [98] | - | x | x | - | YOLOv3 |
| 2022 [99] | x | - | x | x | MobileNetV2+YOLOv4 |
| 2022 [100] | - | x | x | x | YOLOv5 |
2.3.5. SSD
2.3.6. YOLO
3. Datasets
3.1. Dataset Diversity
3.1.1. Background and Lighting
3.1.2. Scale and Spatial Vision
3.1.3. Size, Quality, and Resolution
3.1.4. Occlusion and Position
3.1.5. Annotations and Labels
4. Challenges and Issues
4.1. Datasets
4.2. Image Processing Techniques
4.3. Data Fusion
4.4. Practical Applications
5. Conclusions and Future Work
- 1
- Creating large-scale fine-grained datasets with higher diversity and already labeled samples, using synthetic data, and improving the balance between classes.
- 2
- Creating, optimizing, and combining image processing techniques, including preprocessing and the use of transfer learning or similar techniques.
- 3
- Usage of different sensors and data sources to operate in conjunction with the optical sensors, thereby generating a situational awareness of the monitored maritime region.
- 4
- Practical analysis of the systems, indicating their performance and speed in real scenarios, where the complexity may be higher than in the datasets.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ATR | Automatic Target Recognition |
| AIS | Automatic Identification System |
| B2RB | Bounding-Box to Rotated Bounding-Box |
| BLS | Broad Learning System |
| BN | Batch Normalization |
| CNN | Convolutional Neural Network |
| DCT | Discrete Cosine Transform |
| DeFMO | Deblurring and Shape Recovery of Fast Moving Objects |
| DeblurGAN | Deblur Generative Adversarial Network |
| EDSR | Enhanced Deep Super-Resolution Network |
| ESRGAN | Enhanced Super-Resolution Generative Adversarial Network |
| FPN | Feature Pyramid Network |
| FusionNet | Fusion Network |
| GAN | Generative Adversarial Network |
| HOG | Histograms of Oriented Gradients |
| IACS | International Association of Classification Societies |
| IALA | International Association of Marine Aids to Navigation and Lighthouse Authorities |
| IEC | International Electrotechnical Commission |
| IEEE | Institute of Electrical Electronic Engineers |
| IMO | International Maritime Organization |
| IR | Infrared |
| ISO | International Organization for Standardization |
| ITU | International Telecommunication Union |
| LBP | Local Binary Pattern |
| LFW | Labeled Faces in the Wild |
| LiDAR | Light Detection and Ranging |
| mAP | Mean Average Precision |
| MobileNet-DSC | Mobile Network-Depthwise Separable Convolution |
| MDSR | Multi-Scale Deep Super-Resolution |
| MLP | Multi-Layer Perceptron |
| MOS | Mean Opinion Score |
| MSE | Mean Squared Error |
| NIQE | Natural Image Quality Evaluator |
| PIRM-SR | Perceptual Image Restoration and Manipulation—Super Resolution |
| PSNR | Peak Signal-to-Noise Ratio |
| RADAR | Radio Detection And Ranging |
| RaGAN | Relativistic average GAN |
| RankSRGAN | Rank Super-Resolution Generative Adversarial Network |
| ResNet | Residual Network |
| ResBlock | Residual Block |
| RetinaNet | Retina Network |
| RNN | Recurrent Neural Network |
| RoI | Region of Interest |
| RRDB | Residual-in-Residual Dense Block |
| RPN | Region Proposal Network |
| R-CNN | Region Based Convolutional Neural Network |
| LiDAR | Light Detection and Ranging |
| SIFT | Scale-Invariant Feature Transform |
| Skip-ENet | Skip Efficient Neural Network |
| SNN | Spiking Neural Networks |
| SR | Super-Resolution |
| SRCNN | Super-Resolution Convolutional Neural Network |
| SRGAN | Super-Resolution Generative Adversarial Network |
| SS | Selective Search |
| SSD | Single-Shot Detector |
| SSIM | Structural Similarity Index Measure |
| SSS-Net | Single-Shot Network Structure |
| SRResNet | Super-Resolution Residual Network |
| SVM | Support Vector Machine |
| VGG | Visual Geometry Group |
| YOLO | You Only Look Once |
References
- Park, J.; Cho, Y.; Yoo, B.; Kim, J. Autonomous collision avoidance for unmanned surface ships using onboard monocular vision. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Dumitriu, A.; Miceli, G.E.; Schito, S.; Vertuani, D.; Ceccheto, P.; Placco, L.; Callegaro, G.; Marazzato, L.; Accattino, F.; Bettio, A.; et al. OCEANS-18: Monitoring undetected vessels in high risk maritime areas. In Proceedings of the 2018 5th IEEE International Workshop on Metrology for AeroSpace (MetroAeroSpace), Rome, Italy, 20–22 June 2018; pp. 669–674. [Google Scholar] [CrossRef]
- Yue, T.; Yang, Y.; Niu, J.M. A Light-weight Ship Detection and Recognition Method Based on YOLOv4. In Proceedings of the 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Changsha, China, 26–28 March 2021; pp. 661–670. [Google Scholar] [CrossRef]
- Liu, H.; Xu, X.; Chen, X.; Li, C.; Wang, M. Real-Time Ship Tracking under Challenges of Scale Variation and Different Visibility Weather Conditions. J. Mar. Sci. Eng. 2022, 10, 444. [Google Scholar] [CrossRef]
- Shan, Y.; Zhou, X.; Liu, S.; Zhang, Y.; Huang, K. SiamFPN: A Deep Learning Method for Accurate and Real-Time Maritime Ship Tracking. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 315–325. [Google Scholar] [CrossRef]
- Duan, Y.; Li, Z.; Tao, X.; Li, Q.; Hu, S.; Lu, J. EEG-Based Maritime Object Detection for IoT-Driven Surveillance Systems in Smart Ocean. IEEE Internet Things J. 2020, 7, 9678–9687. [Google Scholar] [CrossRef]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing From Electro-Optical Sensors for Object Detection and Tracking in a Maritime Environment: A Survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef]
- Mandalapu, H.; Reddy P N, A.; Ramachandra, R.; Rao, K.S.; Mitra, P.; Prasanna, S.R.M.; Busch, C. Audio-Visual Biometric Recognition and Presentation Attack Detection: A Comprehensive Survey. IEEE Access 2021, 9, 37431–37455. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, F.; Dong, H.; Guo, Y. A Deep Encoder-Decoder Networks for Joint Deblurring and Super-Resolution. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1448–1452. [Google Scholar] [CrossRef]
- Talab, M.A.; Awang, S.; Najim, S.A.d.M. Super-Low Resolution Face Recognition using Integrated Efficient Sub-Pixel Convolutional Neural Network (ESPCN) and Convolutional Neural Network (CNN). In Proceedings of the 2019 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Selangor, Malaysia, 29 June 2019; pp. 331–335. [Google Scholar] [CrossRef]
- Robey, A.; Ganapati, V. Optimal physical preprocessing for example-based super-resolution. Opt. Express 2018, 26, 31333. [Google Scholar] [CrossRef]
- Yang, Z.; Shi, P.; Pan, D. A Survey of Super-Resolution Based on Deep Learning. In Proceedings of the 2020 International Conference on Culture-oriented Science Technology (ICCST), Beijing, China, 30–31 October 2020; pp. 514–518. [Google Scholar] [CrossRef]
- Xie, J.; Xu, L.; Chen, E. Image Denoising and Inpainting with Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25. [Google Scholar]
- Sada, M.; Goyani, M. Image Deblurring Techniques—A Detail Review. In Proceedings of the National Conference on Advanced Research Trends in Information and Computing Technologies (NCARTICT-2018), Ahmedabad, Gujarat, India, 20 January 2018; pp. 176–188. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Data Preprocessing for Supervised Learning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.H.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimed. 2019, 21, 3106–3121. [Google Scholar] [CrossRef]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM challenge on perceptual image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Zabalza, M.; Bernardini, A. Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism. Remote Sens. 2022, 14, 2890. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep Back-ProjectiNetworks for Single Image Super-Resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4323–4337. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. Ranksrgan: Generative adversarial networks with ranker for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3096–3105. [Google Scholar]
- Chen, W.; Liu, C.; Yan, Y.; Jin, L.; Sun, X.; Peng, X. Guided Dual Networks for Single Image Super-Resolution. IEEE Access 2020, 8, 93608–93620. [Google Scholar] [CrossRef]
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]
- Ieremeiev, O.; Lukin, V.; Okarma, K.; Egiazarian, K. Full-reference quality metric based on neural network to assess the visual quality of remote sensing images. Remote Sens. 2020, 12, 2349. [Google Scholar] [CrossRef]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. NTIRE 2017 Challenge on Single Image Super-Resolution: Methods and Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, N.; Ma, D.; Ren, G.; Huang, Y. BM-IQE: An image quality evaluator with block-matching for both real-life scenes and remote sensing scenes. Sensors 2020, 20, 3472. [Google Scholar] [CrossRef]
- Zhang, K.; Ren, W.; Luo, W.; Lai, W.S.; Stenger, B.; Yang, M.H.; Li, H. Deep image deblurring: A survey. Int. J. Comput. Vis. 2022, 1–28. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 2018 IEEE/CVF International Conference on Computer Vision (ICCV), Salt Lake City, UT, USA, 18–23 December 2018; pp. 8183–8192. [Google Scholar] [CrossRef]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8877–8886. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Rozumnyi, D.; Oswald, M.R.; Ferrari, V.; Matas, J.; Pollefeys, M. DeFMO: Deblurring and Shape Recovery of Fast Moving Objects. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Rahmani, N.; Behrad, A. Automatic marine targets detection using features based on Local Gabor Binary Pattern Histogram Sequence. In Proceedings of the 2011 1st International eConference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 13–14 October 2011; pp. 195–201. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean. Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Mutalikdesai, A.; Baskaran, G.; Jadhav, B.; Biyani, M.; Prasad, J.R. Machine learning approach for ship detection using remotely sensed images. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 1064–1068. [Google Scholar] [CrossRef]
- Shuai, T.; Sun, K.; Shi, B.; Chen, J. A ship target automatic recognition method for sub-meter remote sensing images. In Proceedings of the 2016 4th International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Guangzhou, China, 4–6 July 2016; pp. 153–156. [Google Scholar] [CrossRef]
- Yang, F.; Xu, Q.; Li, B. Ship Detection From Optical Satellite Images Based on Saliency Segmentation and Structure-LBP Feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606. [Google Scholar] [CrossRef]
- Song, Z.; Sui, H.; Hua, L. How to Quickly Find the Object of Interest in Large Scale Remote Sensing Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4843–4845. [Google Scholar] [CrossRef]
- Li, W.; Fu, K.; Sun, H.; Sun, X.; Guo, Z.; Yan, M.; Zheng, X. Integrated Localization and Recognition for Inshore Ships in Large Scene Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 936–940. [Google Scholar] [CrossRef]
- Thombre, S.; Zhao, Z.; Ramm-Schmidt, H.; Vallet García, J.M.; Malkamäki, T.; Nikolskiy, S.; Hammarberg, T.; Nuortie, H.; Bhuiyan, M.Z.H.; Särkkä, S.; et al. Sensors and AI Techniques for Situational Awareness in Autonomous Ships: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 64–83. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision – ECCV 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Cheng, D.; Meng, G.; Xiang, S.; Pan, C. FusionNet: Edge Aware Deep Convolutional Networks for Semantic Segmentation of Remote Sensing Harbor Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5769–5783. [Google Scholar] [CrossRef]
- Kumar, A.S.; Sherly, E. A convolutional neural network for visual object recognition in marine sector. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 304–307. [Google Scholar] [CrossRef]
- Fu, H.; Li, Y.; Wang, Y.; Han, L. Maritime Target Detection Method Based on Deep Learning. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 878–883. [Google Scholar] [CrossRef]
- Li, M.; Guo, W.; Zhang, Z.; Yu, W.; Zhang, T. Rotated Region Based Fully Convolutional Network for Ship Detection. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 673–676. [Google Scholar] [CrossRef]
- Liu, Y.; Cai, K.; Zhang, M.h.; Zheng, F.b. Target detection in remote sensing image based on saliency computation of spiking neural network. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2865–2868. [Google Scholar] [CrossRef]
- Voinov, S.; Krause, D.; Schwarz, E. Towards Automated Vessel Detection and Type Recognition from VHR Optical Satellite Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4823–4826. [Google Scholar] [CrossRef]
- Wang, Y.; Li, W.; Li, X.; Sun, X. Ship Detection by Modified RetinaNet. In Proceedings of the 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS), Beijing, China, 19–20 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, Y.; You, Y.; Wang, R.; Liu, F.; Liu, J. Nearshore vessel detection based on Scene-mask R-CNN in remote sensing image. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018; pp. 76–80. [Google Scholar] [CrossRef]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection With Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Hui, Z.; Na, C.; ZhenYu, L. Combining a Deep Convolutional Neural Network with Transfer Learning for Ship Classification. In Proceedings of the 2019 12th International Conference on Intelligent Computation Technology and Automation (ICICTA), Xiangtan, China, 26–27 October 2019; pp. 16–19. [Google Scholar] [CrossRef]
- Jiang, B.; Li, X.; Yin, L.; Yue, W.; Wang, S. Object Recognition in Remote Sensing Images Using Combined Deep Features. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 606–610. [Google Scholar] [CrossRef]
- Kim, H.; Koo, J.; Kim, D.; Park, B.; Jo, Y.; Myung, H.; Lee, D. Vision-Based Real-Time Obstacle Segmentation Algorithm for Autonomous Surface Vehicle. IEEE Access 2019, 7, 179420–179428. [Google Scholar] [CrossRef]
- Sun, J.; Zou, H.; Deng, Z.; Cao, X.; Li, M.; Ma, Q. Multiclass Oriented Ship Localization and Recognition In High Resolution Remote Sensing Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1288–1291. [Google Scholar] [CrossRef]
- Ward, C.M.; Harguess, J.; Hilton, C. Ship Classification from Overhead Imagery using Synthetic Data and Domain Adaptation. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zheng, R.; Zhou, Q.; Wang, C. Inland River Ship Auxiliary Collision Avoidance System. In Proceedings of the 2019 18th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES), Wuhan, China, 8–10 November 2019; pp. 56–59. [Google Scholar] [CrossRef]
- Zong-ling, L.; Lu-yuan, W.; Ji-yang, Y.; Bo-wen, C.; Liang, H.; Shuai, J.; Zhen, L.; Jian-feng, Y. Remote Sensing Ship Target Detection and Recognition System Based on Machine Learning. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1272–1275. [Google Scholar] [CrossRef]
- Zou, J.; Yuan, W.; Yu, M. Maritime Target Detection Of Intelligent Ship Based On Faster R-CNN. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 4113–4117. [Google Scholar] [CrossRef]
- Huang, Z.; Sun, S.; Li, R. Fast Single-Shot Ship Instance Segmentation Based on Polar Template Mask in Remote Sensing Images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1236–1239. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, S.; Suo, Y.; Chen, W. Research on Recognition of Marine Ships under Complex Conditions. In Proceedings of the 2020 Chinese Automation Congress (CAC), Guangzhou, China, 27–30 August 2020; pp. 5748–5753. [Google Scholar] [CrossRef]
- Jin, L.; Liu, G. A Convolutional Neural Network for Ship Targets Detection and Recognition in Remote Sensing Images. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 139–143. [Google Scholar] [CrossRef]
- Kelm, A.P.; Zölzer, U. Walk the Lines: Object Contour Tracing CNN for Contour Completion of Ships. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3993–4000. [Google Scholar] [CrossRef]
- Li, X.; Cai, K. Method research on ship detection in remote sensing image based on YOLO algorithm. In Proceedings of the 2020 International Conference on Information Science, Parallel and Distributed Systems (ISPDS), Xi’an, China, 14–16 August 2020; pp. 104–108. [Google Scholar] [CrossRef]
- Li, J.; Tian, J.; Gao, P.; Li, L. Ship Detection and Fine-Grained Recognition in Large-Format Remote Sensing Images Based on Convolutional Neural Network. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2859–2862. [Google Scholar] [CrossRef]
- Syah, A.; Wulandari, M.; Gunawan, D. Fishing and Military Ship Recognition using Parameters of Convolutional Neural Network. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; pp. 286–290. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Jiang, Y.; Li, T. Detection of Self-Build Data Set Based on YOLOv4 Network. In Proceedings of the 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 27–29 September 2020; pp. 640–642. [Google Scholar] [CrossRef]
- Yulin, T.; Jin, S.; Bian, G.; Zhang, Y. Shipwreck Target Recognition in Side-Scan Sonar Images by Improved YOLOv3 Model Based on Transfer Learning. IEEE Access 2020, 8, 173450–173460. [Google Scholar] [CrossRef]
- Zhang, X.; Lv, Y.; Yao, L.; Xiong, W.; Fu, C. A New Benchmark and an Attribute-Guided Multilevel Feature Representation Network for Fine-Grained Ship Classification in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1271–1285. [Google Scholar] [CrossRef]
- Zhao, D.; Li, X. Ocean ship detection and recognition algorithm based on aerial image. In Proceedings of the 2020 Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2020; pp. 218–222. [Google Scholar] [CrossRef]
- Han, Y.; Yang, X.; Pu, T.; Peng, Z. Fine-Grained Recognition for Oriented Ship Against Complex Scenes in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Gong, P.; Zheng, K.; Jiang, Y.; Liu, J. Water Surface Object Detection Based on Neural Style Learning Algorithm. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 8539–8543. [Google Scholar] [CrossRef]
- Boyer, A.; Abiemona, R.; Bolic, M.; Petriu, E. Vessel Identification using Convolutional Neural Network-based Hardware Accelerators. In Proceedings of the 2021 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Virtual, 18–20 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Chang, L.; Chen, Y.T.; Hung, M.H.; Wang, J.H.; Chang, Y.L. YOLOv3 Based Ship Detection in Visible and Infrared Images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3549–3552. [Google Scholar] [CrossRef]
- Zhou, J.; Jiang, P.; Zou, A.; Chen, X.; Hu, W. Ship Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2021, 9, 908. [Google Scholar] [CrossRef]
- Sali, S.M.; Manisha, N.L.; King, G.; Vidya Mol, K. A Review on Object Detection Algorithms for Ship Detection. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 1–5. [Google Scholar] [CrossRef]
- Su, H.; Zuo, Y.; Li, T. Ship detection in navigation based on broad learning system. In Proceedings of the 2021 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Chengdu, China, 18–20 June 2021; pp. 318–322. [Google Scholar] [CrossRef]
- Ting, L.; Baijun, Z.; Yongsheng, Z.; Shun, Y. Ship Detection Algorithm based on Improved YOLO V5. In Proceedings of the 2021 6th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 15–17 July 2021; pp. 483–487. [Google Scholar] [CrossRef]
- Zhang, C.; Xiong, B.; Kuang, G. Ship Detection and Recognition in Optical Remote Sensing Images Based on Scale Enhancement Rotating Cascade R-CNN Networks. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3545–3548. [Google Scholar] [CrossRef]
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced YOLO v3 Tiny Network for Real-Time Ship Detection From Visual Image. IEEE Access 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Chen, L.; Shi, W.; Deng, D. Improved YOLOv3 Based on Attention Mechanism for Fast and Accurate Ship Detection in Optical Remote Sensing Images. Remote Sens. 2021, 13, 660. [Google Scholar] [CrossRef]
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean. Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Hu, J.; Zhi, X.; Shi, T.; Zhang, W.; Cui, Y.; Zhao, S. PAG-YOLO: A Portable Attention-Guided YOLO Network for Small Ship Detection. Remote Sens. 2021, 13, 3059. [Google Scholar] [CrossRef]
- Leonidas, L.A.; Jie, Y. Ship Classification Based on Improved Convolutional Neural Network Architecture for Intelligent Transport Systems. Information 2021, 12, 302. [Google Scholar] [CrossRef]
- Dong, Y.; Chen, F.; Han, S.; Liu, H. Ship Object Detection of Remote Sensing Image Based on Visual Attention. Remote Sens. 2021, 13, 3192. [Google Scholar] [CrossRef]
- Su, N.; Huang, Z.; Yan, Y.; Zhao, C.; Zhou, S. Detect Larger at Once: Large-Area Remote-Sensing Image Arbitrary-Oriented Ship Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Xie, P.; Tao, R.; Luo, X.; Shi, Y. YOLOv4-MobileNetV2-DW-LCARM: A Real-Time Ship Detection Network. In Proceedings of the Knowledge Management in Organisations, Hagen, Germany, 11–14 July 2022; Uden, L., Ting, I.H., Feldmann, B., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 281–293. [Google Scholar]
- Li, L.; Jiang, L.; Zhang, J.; Wang, S.; Chen, F. A Complete YOLO-Based Ship Detection Method for Thermal Infrared Remote Sensing Images under Complex Backgrounds. Remote Sens. 2022, 14, 1534. [Google Scholar] [CrossRef]
- Gao, H.; Cheng, B.; Wang, J.; Li, K.; Zhao, J.; Li, D. Object Classification Using CNN-Based Fusion of Vision and LIDAR in Autonomous Vehicle Environment. IEEE Trans. Ind. Inform. 2018, 14, 4224–4231. [Google Scholar] [CrossRef]
- Yan, Z.; Zhang, H.; Piramuthu, R.; Jagadeesh, V.; DeCoste, D.; Di, W.; Yu, Y. HD-CNN: Hierarchical Deep Convolutional Neural Networks for Large Scale Visual Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Gundogdu, E.; Solmaz, B.; Yücesoy, V.; Koç, A. MARVEL: A Large-Scale Image Dataset for Maritime Vessels. In Computer Vision – ACCV 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 165–180. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Doon, R.; Kumar Rawat, T.; Gautam, S. Cifar-10 Classification using Deep Convolutional Neural Network. In Proceedings of the 2018 IEEE Punecon, Pune, India, 30 November–2 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. (IJCV) 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Iancu, B.; Soloviev, V.; Zelioli, L.; Lilius, J. ABOships—An Inshore and Offshore Maritime Vessel Detection Dataset with Precise Annotations. Remote Sens. 2021, 13, 988. [Google Scholar] [CrossRef]
- Zhang, M.M.; Choi, J.; Daniilidis, K.; Wolf, M.T.; Kanan, C. VAIS: A dataset for recognizing maritime imagery in the visible and infrared spectrums. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 10–16. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, S. Mcships: A Large-Scale Ship Dataset For Detection And Fine-Grained Categorization In The Wild. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. SeaShips: A Large-Scale Precisely Annotated Dataset for Ship Detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Kaggle. High Resolution Ship Collections 2016 (HRSC2016). 2016. Available online: https://www.kaggle.com/datasets/guofeng/hrsc2016 (accessed on 22 December 2021).
- Kaggle. Airbus Ship Detection Challenge. 2018. Available online: https://www.kaggle.com/c/airbus-ship-detection (accessed on 22 December 2021).
- Rainey, K.; Parameswaran, S.; Harguess, J.; Stastny, J. Vessel classification in overhead satellite imagery using learned dictionaries. In Proceedings of the Applications of Digital Image Processing XXXV, San Diego, CA, USA, 13–16 August 2012. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Wang, Y.; Feng, P.; He, R. ShipRSImageNet: A Large-Scale Fine-Grained Dataset for Ship Detection in High-Resolution Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8458–8472. [Google Scholar] [CrossRef]
- Zou, W.; Lu, Y.; Chen, M.; Lv, F. Rapid Face Detection in Static Video Using Background Subtraction. In Proceedings of the 2014 Tenth International Conference on Computational Intelligence and Security, Kunming, China, 15–16 November 2014; pp. 252–255. [Google Scholar] [CrossRef]
- Hosang, J.; Benenson, R.; Schiele, B. Learning Non-maximum Suppression. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6469–6477. [Google Scholar] [CrossRef]
- You, J.; Hu, Z.; Peng, C.; Wang, Z. Generation and Annotation of Simulation-Real Ship Images for Convolutional Neural Networks Training and Testing. Appl. Sci. 2021, 11, 5931. [Google Scholar] [CrossRef]
- NaturalIntelligence. ImgLab. 2020. Available online: https://github.com/NaturalIntelligence/imglab (accessed on 22 December 2021).
- Microsoft. Visual Object Tagging Tool (VoTT). 2019. Available online: https://github.com/microsoft/VoTT (accessed on 22 December 2021).
- Sekachev, B. Computer Vision Annotation Tool (CVAT). 2020. Available online: https://github.com/openvinotoolkit/cvat (accessed on 22 December 2021).
- Lin, T. LabelImg. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 22 December 2021).
- Wada, K. Labelme. 2021. Available online: https://github.com/wkentaro/labelme (accessed on 23 December 2021).
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar] [CrossRef]
- SuperAnnotate. 2018. Available online: https://www.superannotate.com/ (accessed on 23 December 2021).
- Supervisely. 2021. Available online: https://github.com/supervisely/supervisely (accessed on 23 December 2021).
- Skalski, P. Make-Sense. 2019. Available online: https://github.com/SkalskiP/make-sense/ (accessed on 23 December 2021).
- LabelBox. 2021. Available online: https://labelbox.com/ (accessed on 27 December 2021).
- DarkLabel. 2020. Available online: https://github.com/darkpgmr/DarkLabel (accessed on 27 December 2021).
- Arunachalam, A.; Ravi, V.; Acharya, V.; Pham, T.D. Toward Data-Model-Agnostic Autonomous Machine-Generated Data Labeling and Annotation Platform: COVID-19 Autoannotation Use Case. IEEE Trans. Eng. Manag. 2021, 1–12. [Google Scholar] [CrossRef]
- Li, H.; Wang, X. Automatic Recognition of Ship Types from Infrared Images Using Support Vector Machines. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Wuhan, China, 12–14 December 2008; Volume 6, pp. 483–486. [Google Scholar] [CrossRef]
- Zabidi, M.M.A.; Mustapa, J.; Mokji, M.M.; Marsono, M.N.; Sha’ameri, A.Z. Embedded vision systems for ship recognition. In Proceedings of the TENCON 2009—2009 IEEE Region 10 Conference, Singapore, 23–26 November 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Kao, C.H.; Hsieh, S.P.; Peng, C.C. Study of feature-based image capturing and recognition algorithm. In Proceedings of the ICCAS 2010, Gyeonggi-do, Korea, 27–30 October 2010; pp. 1855–1861. [Google Scholar] [CrossRef]
- Ganbold, U.; Akashi, T. The real-time reliable detection of the horizon line on high-resolution maritime images for unmanned surface-vehicle. In Proceedings of the 2020 International Conference on Cyberworlds (CW), Caen, France, 29 September–1 October 2020; pp. 204–210. [Google Scholar]
- Chen, J.; Wang, J.; Lu, H. Ship Detection in Complex Weather Based on CNN. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 1225–1228. [Google Scholar]
- Mu, X.; Lin, Y.; Liu, J.; Cao, Y.; Liu, H. Surface Navigation Target Detection and Recognition based on SSD. In Proceedings of the 2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE), Xiamen, China, 18–20 October 2019; pp. 649–653. [Google Scholar] [CrossRef]
- Prayudi, A.; Sulistijono, I.A.; Risnumawan, A.; Darojah, Z. Surveillance System for Illegal Fishing Prevention on UAV Imagery Using Computer Vision. In Proceedings of the 2020 International Electronics Symposium (IES), Surabaya, Indonesia, 29-30 September 2020; pp. 385–391. [Google Scholar]
- Patel, K.; Bhatt, C.; Mazzeo, P.L. Deep Learning-Based Automatic Detection of Ships: An Experimental Study Using Satellite Images. J. Imaging 2022, 8, 182. [Google Scholar] [CrossRef] [PubMed]
- Dan, Z.; Sang, N.; Wang, R.; Chen, Y.; Chen, X. A Transductive Transfer Learning Method for Ship Target Recognition. In Proceedings of the 2013 Seventh International Conference on Image and Graphics, Qingdao, China, 26–28 July 2013; pp. 418–422. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A Novel Hierarchical Method of Ship Detection from Spaceborne Optical Image Based on Shape and Texture Features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Zerrouk, I.; Moumen, Y.; Khiati, W.; Berrich, J.; Bouchentouf, T. Detection Process of Ships in Aerial Imagery Using Two Convnets. In Proceedings of the 2019 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 3–4 April 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Kitayama, T.; Lu, H.; Li, Y.; Kim, H. Detection of Grasping Position from Video Images Based on SSD. In Proceedings of the 2018 18th International Conference on Control, Automation and Systems (ICCAS), PyeongChang, Korea, 17–20 October 2018; pp. 1472–1475. [Google Scholar]
- Wang, X.; Zhang, T. Clutter-adaptive infrared small target detection in infrared maritime scenarios. Opt. Eng. 2011, 50, 1–13. [Google Scholar] [CrossRef]
- Bian, W.; Zhu, Q. The ship target detection based on panoramic images. In Proceedings of the 2015 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 2–5 August 2015; pp. 2397–2401. [Google Scholar] [CrossRef]
- Liu, W.; Yang, X.; Zhang, J. A Robust Target Detection Algorithm Using MEMS Inertial Sensors for Shipboard Video System. In Proceedings of the 2020 27th Saint Petersburg International Conference on Integrated Navigation Systems (ICINS), Saint Petersburg, Russia, 25–27 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, Y.; Han, Z.; Yang, Z. Ship Target Detection Based on LightGBM Algorithm. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications (CIBDA), Guiyang, China, 17–19 April 2020; pp. 425–429. [Google Scholar] [CrossRef]
- Szpak, Z.L.; Tapamo, J.R. Maritime surveillance: Tracking ships inside a dynamic background using a fast level-set. Expert Syst. Appl. 2011, 38, 6669–6680. [Google Scholar] [CrossRef]
- Chang, J.Y.; Oh, H.; Lee, S.J.; Lee, K.J. Ship Detection for KOMPSAT-3A Optical Images Using Binary Features and Adaboost Classification. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 968–971. [Google Scholar] [CrossRef]
- Sankaraiah, Y.R.; Varadarajan, S. Deblurring techniques—A comprehensive survey. In Proceedings of the 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017; pp. 2032–2035. [Google Scholar] [CrossRef]
- Zheng, H. A Survey on Single Image Deblurring. In Proceedings of the 2021 2nd International Conference on Computing and Data Science (CDS), Stanford, CA, USA, 28–30 January 2021; pp. 448–452. [Google Scholar] [CrossRef]
- Mahalakshmi, A.; Shanthini, B. A survey on image deblurring. In Proceedings of the 2016 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 7–9 January 2016; pp. 1–5. [Google Scholar] [CrossRef]
- van Valkenburg-van Haarst, T.Y.C.; Scholte, K.A. Polynomial background estimation using visible light video streams for robust automatic detection in a maritime environment. In Proceedings of the Electro-Optical Remote Sensing, Photonic Technologies, and Applications III, Berlin, Germany, 1-3 September 2009; Bishop, G.J., Gonglewski, J.D., Lewis, K.L., Hollins, R.C., Merlet, T.J., Kamerman, G.W., Steinvall, O.K., Eds.; International Society for Optics and Photonics, SPIE Digital Library: Bellingham, WA, USA, 2009; Volume 7482, pp. 94–101. [Google Scholar] [CrossRef]
- Pan, M.; Liu, Y.; Cao, J.; Li, Y.; Li, C.; Chen, C.H. Visual Recognition Based on Deep Learning for Navigation Mark Classification. IEEE Access 2020, 8, 32767–32775. [Google Scholar] [CrossRef]
- Li, K.d.; Zhang, Y.y.; Li, Y.j. Researches of Sea Surface Ship Target Auto-recognition Based on Wavelet Transform. In Proceedings of the 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization, Yichang, China, 12–14 November 2010; Volume 1, pp. 193–195. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Du, W.; Wu, W. Saliency-Aware Convolution Neural Network for Ship Detection in Surveillance Video. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 781–794. [Google Scholar] [CrossRef]
- Li, Z.; Yang, D.; Chen, Z. Multi-layer Sparse Coding Based Ship Detection for Remote Sensing Images. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, Francisco, CA, USA, 13–15 August 2015; pp. 122–125. [Google Scholar] [CrossRef]
- van den Broek, S.P.; Schwering, P.B.W.; Liem, K.D.; Schleijpen, R. Persistent maritime surveillance using multi-sensor feature association and classification. In Proceedings of the Signal Processing, Sensor Fusion, and Target Recognition XXI, Baltimore, MD, USA, 17 April 2012; Kadar, I., Ed.; International Society for Optics and Photonics, SPIE Digital Library: Bellingham, WA, USA, 2012; Volume 8392, pp. 341–351. [Google Scholar] [CrossRef] [Green Version]
- Son, N.S. On an Autonomous Navigation System for Collision Avoidance of Unmanned Surface Vehicle. In Proceedings of the ION 2013 Pacific PNT Meeting, Honolulu, HI, USA, 22–25 April 2013; pp. 470–476. [Google Scholar]
- Suzuki, S.; Mitsukura, Y.; Furuya, T. Ship detection based on spatio-temporal features. In Proceedings of the 2014 10th France-Japan/ 8th Europe-Asia Congress on Mecatronics (MECATRONICS2014- Tokyo), Tokyo, Japan, 27–29 November 2014; pp. 93–98. [Google Scholar] [CrossRef]
- Patino, L.; Ferryman, J. Loitering Behaviour Detection of Boats at Sea. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2169–2175. [Google Scholar] [CrossRef]
- Kaido, N.; Yamamoto, S.; Hashimoto, T. Examination of automatic detection and tracking of ships on camera image in marine environment. In Proceedings of the 2016 Techno-Ocean (Techno-Ocean), Kobe, Japan, 6–8 October 2016; pp. 58–63. [Google Scholar] [CrossRef]
- Wei, H.; Nguyen, H.; Ramu, P.; Raju, C.; Liu, X.; Yadegar, J. Automated intelligent video surveillance system for ships. In Proceedings of the Optics and Photonics in Global Homeland Security V and Biometric Technology for Human Identification VI, Orlando, FL, USA, 13–16 April 2009; Volume 7306, pp. 58–63. [Google Scholar] [CrossRef]
- Chen, X.; Ling, J.; Wang, S.; Yang, Y.; Luo, L.; Yan, Y. Ship detection from coastal surveillance videos via an ensemble Canny-Gaussian-morphology framework. J. Navig. 2021, 74, 1252–1266. [Google Scholar] [CrossRef]
- Teixeira, E.H.; Mafra, S.B.; Rodrigues, J.J.P.C.; Da Silveira, W.A.A.N.; Diallo, O. A Review and Construction of a Real-time Facial Recognition System. In Proceedings of the Anais do Simpósio Brasileiro de Computação Ubíqua e Pervasiva (SBCUP), Cuiabá, Mato Grosso, Brazil, 16–20 November 2020; pp. 191–200. [Google Scholar] [CrossRef]
- Lee, J.M.; Lee, K.H.; Nam, B.; Wu, Y. Study on Image-Based Ship Detection for AR Navigation. In Proceedings of the 2016 6th International Conference on IT Convergence and Security (ICITCS), Prague, Czech Republic, 26–29 September 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]









| Dataset | Ship Count |
|---|---|
| COCO [104] | 3146 |
| CIFAR-10 [105] | 6000 |
| PASCAL VOC [106] | 353 |
| OpenImage [107] | 1000 |
| ImageNet [108] | 1071 |
| Dataset | Side View | Remote | Images | Ship Classes |
|---|---|---|---|---|
| VAIS [110] | x | - | 2865 | 15 |
| ABOShips [109] | x | - | 9880 | 9 |
| MCShips [111] | x | - | 14,709 | 13 |
| Singapore [7] | x | - | 17,450 | 6 |
| SeaShips [112] | x | - | 31,455 | 6 |
| MARVEL [103] | x | - | 2,000,000 | 29 |
| HRSC2016 [113] | - | x | 1061 | 19 |
| Airbus Ship Detection [114] | - | x | 208,162 | 1 |
| BCCT200 [115] | - | x | 800 | 4 |
| ShipRSImageNet [116] | - | x | 3435 | 50 |
| Tools | Environment | Conectivity | Processing Data | Annotation Types | Output Data | (Semi)Automatic Labeling | Availability | Remarks |
|---|---|---|---|---|---|---|---|---|
| ImgLab [120] | Browser and local | On/Offline | Images | Points, circles, rectangles, and polygons. | dlib XML, dlib pts, VOC, and COCO | No support | Free | - |
| VoTT [121] | Browser and local | On/Offline | Images and videos | Rectangles and polygons. | CNTK, Azure, VOC, CSV, and VoTT(JSON) | Support | Free | - |
| CVAT [122] | Browser and local | On/Offline | Images and videos | Points, lines, cuboids, rectangles, and polygons. | VOC, COCO, etc. | Support | Free | - |
| Labelimg [123] | Local | Offline | Images | Rectangles. | VOC, YOLO, and CSV. | No support | Free | - |
| Labelme [124] | Local | Offline | Images and videos | Points, circles, lines, rectangles, and polygons. | VOC, COCO, etc. | No support | Free | - |
| VGG Image
Annotator (VIA) [125] | Browser | On/Offline | Images, videos, and audios | Points, circles, lines, ellipses, rectangles, and polygons. | VOC, COCO, and CSV | No support | Free | - |
| SuperAnnotate [126] | Browser and local | On/Offline | Images, videos, and texts | Points, lines, ellipses, cuboids, rectangles, polygons, and brushes. | JSON and COCO | Support | Paid | Online support |
| Supervisely [127] | Browser and local | On/Offline | Images, videos, and 3d point cloud | Points, lines, rectangles, polygons, and brushes. | JSON | Support | Paid | Online support |
| MakeSense [128] | Browser | Online | Images | Points, lines, rectangles, and polygons. | YOLO, VOC, and COCO | Support | Free | - |
| LabelBox [129] | Browser | Online | Images, videos, and text | Points, lines, rectangles, polygons, and brushes. | JSON and CSV | Support | Paid | Online support |
| DarkLabel [130] | Local | Offline | Images and videos | Rectangles. | VOC and YOLO | Support | Free | Online support |
| Autoannotation [131] | Browser | On/offline | Images | Rectangles. | YOLO | Support | Free | - |
| Papers | Type | Classes | Train | Test |
|---|---|---|---|---|
| 2008 [132] | 2 | Aircraft Carrier and Destroyer | - | 270 |
| 2009 [133] | 4 | Carrier, Cruiser, Destroyer and Frigate | - | 98 |
| 2010 [134] | 4 | Ark Royal, Arizona, Arleigh and Connelly | - | 32 |
| 2017 [42] | 12 | Military Ships (Aircraft Carrier, Submarine, San Antonio, Arleigh Burke, Whidbey Island) | 200 | 80 |
| 2017 [56] | 5 | Containers, Fishing Boats, Guards, Tankers, Warships | - | 300 |
| 2018 [60] | 9 | Passenger Ship, Leisure Boat, Sailing Boat, Service Vessel, Fishing Boat, Warship, Generic Cargo Ship, Container Carrier and Tanker. | 30000 | 20 |
| 2018 [62] | 3 | Cargo Ship, Cruise and Yacht | - | - |
| 2019 [68] | 4 | Barge, Cargo, Container and Tanker | - | - |
| 2019 [64] | 3 | Oil Tankers, Bulk Carriers and Container Ships | - | - |
| 2020 [77] | 7 | Aircraft Carrier, Destroyer, Cruiser, Cargo Ship, Medical Ship, Cruise Ship and Transport Ship. | 24 | 6 |
| 2020 [73] | 3 | Passenger Ships, General Cargo Ships and Container Ships | - | - |
| 2020 [74] | 4 | Destroyers, One Bulk Barrier, Submarine and Two Aircraft Carriers | - | 500 |
| 2020 [78] | 2 | Fishing Ships and Military | 398 | 16 |
| 2020 [81] | 23 | Non-ship, Aircraft Carrier, Destroyer, Landing Craft, Frigate, Amphibious Transport Dock, Cruiser, Tarawa-Class Amphibious Assault Ship, Amphibious Assault Ship, Command Ship, Submarine, Medical Ship, Combat Boat, Auxiliary Ship, Container Ship, Car Carrier, Hovercraft, Bulk Carrier, Oil Tanker, Fishing Boat, Passenger Ship, Liquefied Gas Ship and Barge | 5165 | 825 |
| 2021 [83] | 4 | Warcraft, Aircraft Carrier, Merchant Ship and Submarine | - | - |
| 2021 [86] | 6 | Warship, Container Ship, Cruise Ship, Yacht, Sailboat and Fishing Boat | - | - |
| 2021 [91] | 15 | Aircraft Carrier, Oliver Hazard Perry Class frigate, Ticonderoga-class Cruiser, Arleigh Burke Class Destroyer, Independence-class littoral combat ship, Freedom-class littoral Combat Ship, Amphibious Assault Ship, Tanker, Container Ship, Grocery Ship, Amphibious Transport Ship, Small Military Warship, Supply Ship, Submarine and Other. | 4800 | 1200 |
| 2021 [3] | 8 | Bulk Cargo Ships, Engineering Ships, Armed Ships, Refrigerated Ships, Concrete Ships, Fisheries Vessels, Container Ships and Oil Tankers | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teixeira, E.; Araujo, B.; Costa, V.; Mafra, S.; Figueiredo, F. Literature Review on Ship Localization, Classification, and Detection Methods Based on Optical Sensors and Neural Networks. Sensors 2022, 22, 6879. https://doi.org/10.3390/s22186879
Teixeira E, Araujo B, Costa V, Mafra S, Figueiredo F. Literature Review on Ship Localization, Classification, and Detection Methods Based on Optical Sensors and Neural Networks. Sensors. 2022; 22(18):6879. https://doi.org/10.3390/s22186879
Chicago/Turabian StyleTeixeira, Eduardo, Beatriz Araujo, Victor Costa, Samuel Mafra, and Felipe Figueiredo. 2022. "Literature Review on Ship Localization, Classification, and Detection Methods Based on Optical Sensors and Neural Networks" Sensors 22, no. 18: 6879. https://doi.org/10.3390/s22186879