

Low-Light Image Enhancement Using Photometric Alignment with Hierarchy Pyramid Network
Abstract
:1. Introduction
- We propose a novel coarse-to-fine adaptive low-light image enhancement network (CFANet) that seamlessly combines coarse global photometric alignment with finer perceptual information promotion. The coarse-to-fine pipeline is trained in a data-driven manner within a unified framework to avoid error accumulation.
- The built MRCAB is embedded into a hierarchy pyramid network, which can change the perceptual fields and highlight notable features for each network layer. Furthermore, the polarized self-attention mechanism of the block can preserve high-resolution information to achieve better enhancement performance.
- Experiments show that our method can generalize well across different real low-light datasets. Specially, we restore less noise normal-light images with rich detail and vivid colors compared to other low-light enhancement methods.
2. Related Work
2.1. Traditional Methods
2.2. Learning-Based Methods
3. Coarse-to-Fine Enhancement Pipeline
3.1. Motivation
3.2. CFANet
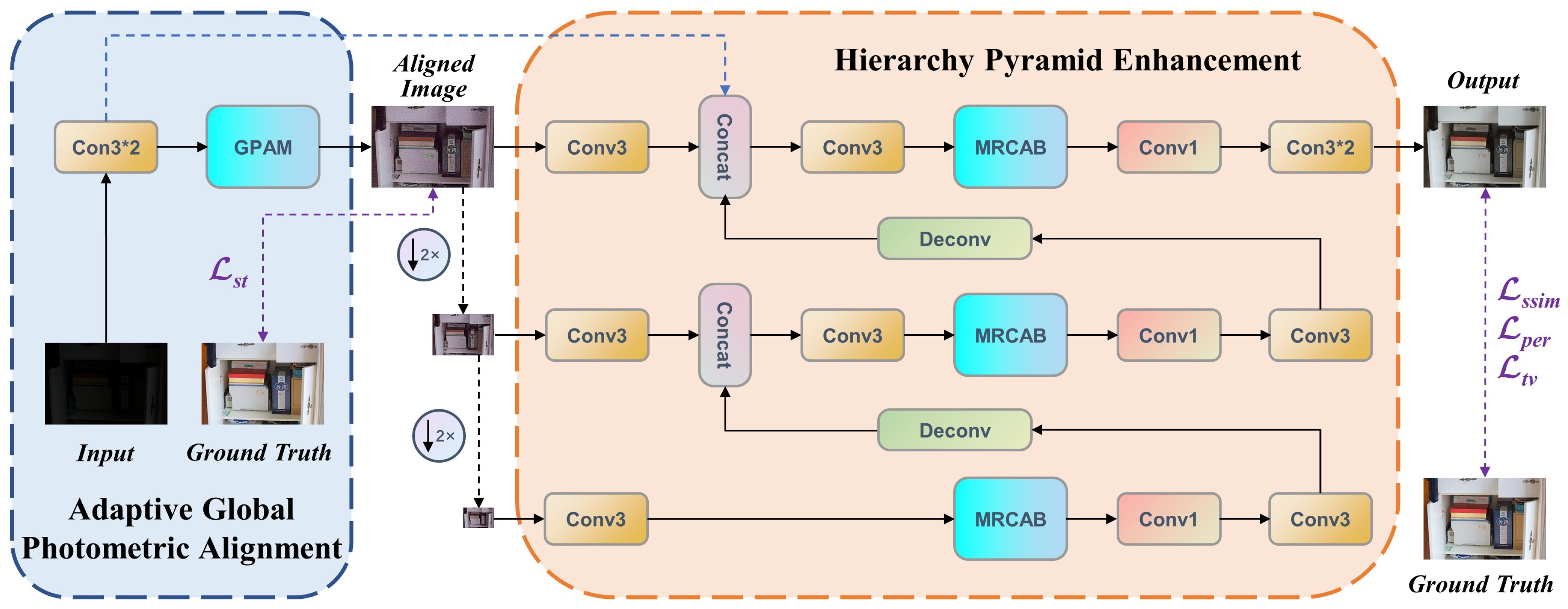
3.2.1. Network Architecture
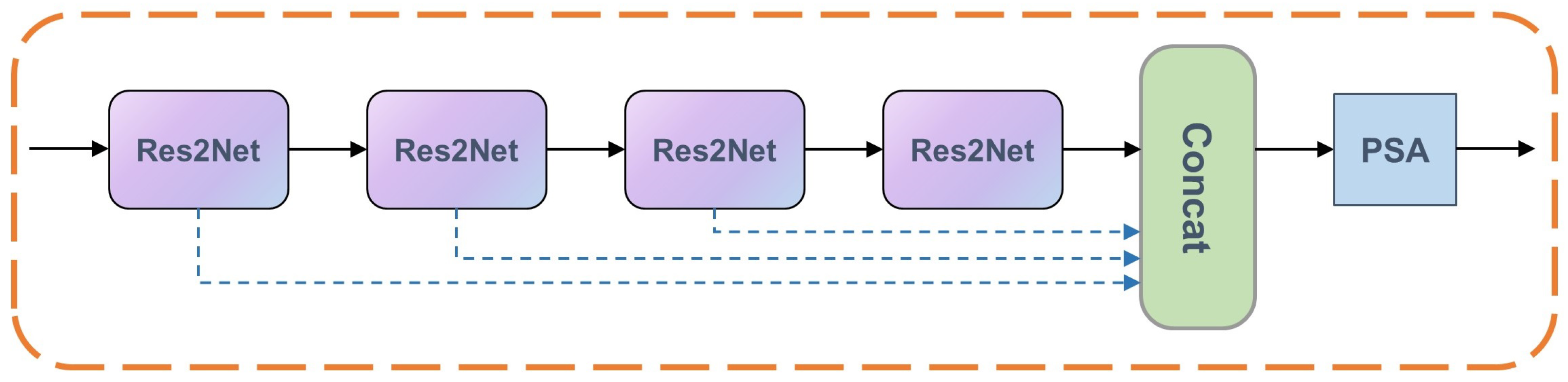
3.2.2. Multi-Residual Cascade Attention Block (MRCAB)
3.3. Loss Function
4. Experiments
4.1. Datasets and Evaluate Metrics
4.2. Experimental Settings
4.3. Enhancement Results
4.3.1. Quantitative Evaluation
4.3.2. Qualitative Evaluation
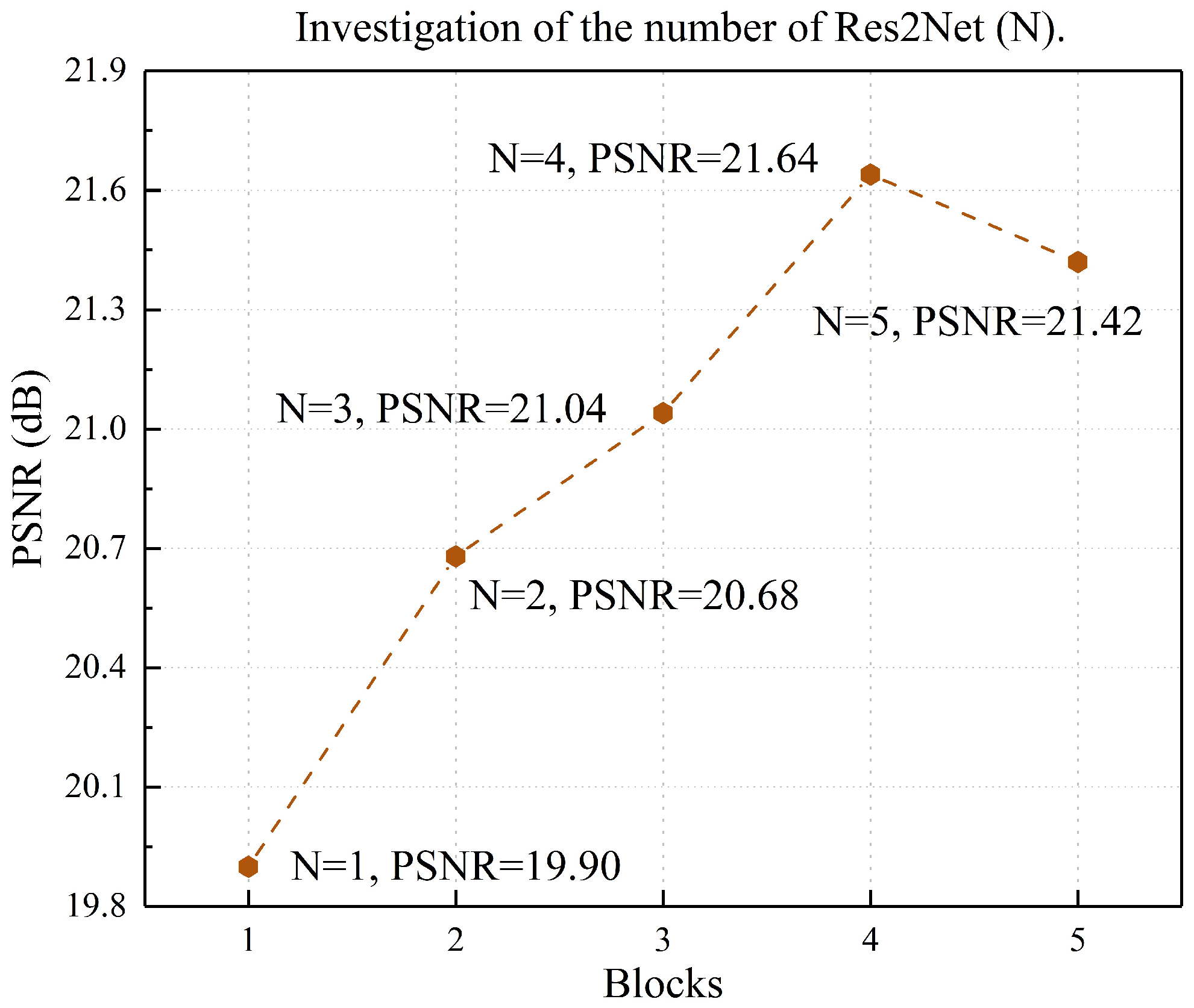
5. Ablation Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, S.D.; Ramli, A.R. Contrast enhancement using recursive mean-separate histogram equalization for scalable brightness preservation. IEEE Trans. Consum. Electron. 2003, 49, 1301–1309. [Google Scholar] [CrossRef]
- Celik, T.; Tjahjadi, T. Contextual and variational contrast enhancement. IEEE Trans. Image Process. 2011, 20, 3431–3441. [Google Scholar] [CrossRef] [PubMed]
- Celik, T.; Tjahjadi, T. Automatic image equalization and contrast enhancement using Gaussian mixture modeling. IEEE Trans. Image Process. 2011, 21, 145–156. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.F.; Guo, J.M.; Lai, B.S.; Lee, J.D. High efficient contrast enhancement using parametric approximation. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 2444–2448. [Google Scholar]
- Lee, C.; Lee, C.; Kim, C.S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Liao, Y.; Ding, X.; Paisley, J. A fusion-based enhancing method for weakly illuminated images. Signal Process. 2016, 129, 82–96. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Fu, X.; Zeng, D.; Huang, Y.; Ding, X.; Zhang, X.P. A variational framework for single low light image enhancement using bright channel prior. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1085–1088. [Google Scholar]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef] [PubMed]
- Ren, X.; Li, M.; Cheng, W.H.; Liu, J. Joint enhancement and denoising method via sequential decomposition. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Wang, Y.; Cao, Y.; Zha, Z.J.; Zhang, J.; Xiong, Z.; Zhang, W.; Wu, F. Progressive retinex: Mutually reinforced illumination-noise perception network for low-light image enhancement. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2015–2023. [Google Scholar]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 10561–10570. [Google Scholar]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, H.; Liu, L.; Men, A.; Wang, H. A switched view of Retinex: Deep self-regularized low-light image enhancement. Neurocomputing 2021, 454, 361–372. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. Band representation-based semi-supervised low-light image enhancement: Bridging the gap between signal fidelity and perceptual quality. IEEE Trans. Image Process. 2021, 30, 3461–3473. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Pan, Z.; Yuan, F.; Lei, J.; Li, W.; Ling, N.; Kwong, S. MIEGAN: Mobile image enhancement via a multi-module cascade neural network. IEEE Trans. Multimed. 2021, 24, 519–533. [Google Scholar] [CrossRef]
- Zhao, Z.; Xiong, B.; Wang, L.; Ou, Q.; Yu, L.; Kuang, F. RetinexDIP: A unified deep framework for low-light image enhancement. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1076–1088. [Google Scholar] [CrossRef]
- Hu, J.; Guo, X.; Chen, J.; Liang, G.; Deng, F.; Lam, T.L. A two-stage unsupervised approach for low light image enhancement. IEEE Robot. Autom. Lett. 2021, 6, 8363–8370. [Google Scholar] [CrossRef]
- Ma, H.; Lin, X.; Wu, Z.; Yu, Y. Coarse-to-Fine Domain Adaptive Semantic Segmentation with Photometric Alignment and Category-Center Regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4051–4060. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the 2018 British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; Volume 220, pp. 1–13. [Google Scholar]
- Lu, K.; Zhang, L. TBEFN: A two-branch exposure-fusion network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4093–4105. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Fang, F.; Li, F.; Zhang, G. Luminance-aware pyramid network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 3153–3165. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Liu, M.; Tang, L.; Zhong, S.; Luo, H.; Peng, J. Learning noise-decoupled affine models for extreme low-light image enhancement. Neurocomputing 2021, 448, 21–29. [Google Scholar] [CrossRef]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, NY, USA, 7–12 February 2020; Volume 34, pp. 13106–13113. [Google Scholar]
- Lim, S.; Kim, W. Dslr: Deep stacked laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing And Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized self-attention: Towards high-quality pixel-wise regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef]
- Vonikakis, V.; Andreadis, I.; Gasteratos, A. Fast centre–surround contrast modification. IET Image Process. 2008, 2, 19–34. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Ying, Z.; Li, G.; Gao, W. A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv 2017, arXiv:1711.00591. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new low-light image enhancement algorithm using camera response model. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3015–3022. [Google Scholar]
- Nakai, K.; Hoshi, Y.; Taguchi, A. Color image contrast enhacement method based on differential intensity/saturation gray-levels histograms. In Proceedings of the 2013 International Symposium on Intelligent Signal Processing and Communication Systems, Okinawa, Japan, 12–15 November 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 445–449. [Google Scholar]
- Dong, X.; Wang, G.; Pang, Y.; Li, W.; Wen, J.; Meng, W.; Lu, Y. Fast efficient algorithm for enhancement of low lighting video. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo, Barcelona, Spain, 11–15 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–6. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new image contrast enhancement algorithm using exposure fusion framework. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Ystad, Sweden, 22–24 August 2017; Springer: Berlin, Germany, 2017; pp. 36–46. [Google Scholar]
- Wang, R.; Zhang, Q.; Fu, C.W.; Shen, X.; Zheng, W.S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6849–6857. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Xu, K.; Yang, X.; Yin, B.; Lau, R.W. Learning to restore low-light images via decomposition-and-enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2281–2290. [Google Scholar]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Van Gool, L. Dslr-quality photos on mobile devices with deep convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3277–3285. [Google Scholar]
- Zhou, S.; Li, C.; Loy, C.C. LEDNet: Joint Low-light Enhancement and Deblurring in the Dark. arXiv 2022, arXiv:2202.03373. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | LOL-Syn | LOL-Real | ||
|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | |
| BIMEF | 17.20 | 0.7172 | 17.85 | 0.6526 |
| CRM | 18.91 | 0.7864 | 19.65 | 0.6623 |
| DHECE | 17.75 | 0.7800 | 14.64 | 0.4450 |
| Dong | 16.90 | 0.7487 | 17.26 | 0.5270 |
| EFF | 17.20 | 0.7127 | 17.85 | 0.6526 |
| LIME | 16.88 | 0.7762 | 15.24 | 0.4702 |
| MF | 17.50 | 0.7514 | 18.73 | 0.5590 |
| MBLLEN | 17.07 | 0.7301 | 17.86 | 0.7247 |
| JED | 17.48 | 0.7444 | 17.33 | 0.6654 |
| SRIE | 14.50 | 0.6163 | 17.34 | 0.6859 |
| RRM | 17.15 | 0.7277 | 17.33 | 0.5144 |
| DRD | 17.13 | 0.7978 | 15.47 | 0.5672 |
| DeepUPE | 15.08 | 0.6225 | 13.27 | 0.4521 |
| SCIE | 18.50 | 0.7631 | 19.40 | 0.6906 |
| KinD | 17.84 | 0.7971 | 20.73 | 0.8103 |
| EnlightenGAN | 16.57 | 0.7338 | 18.23 | 0.6165 |
| RetinexNet | 22.05 | 0.9054 | 20.06 | 0.8158 |
| KinD++ | 17.69 | 0.8334 | 21.30 | 0.8226 |
| DRBN | 23.22 | 0.9275 | 20.29 | 0.8310 |
| Our | 24.62 | 0.9314 | 21.64 | 0.8481 |
| Method | PSNR↑ | SSIM↑ |
|---|---|---|
| DSLR | 17.25 | 0.4229 |
| LIME | 17.76 | 0.3506 |
| SCIE | 21.16 | 0.6398 |
| DeepUPE | 21.55 | 0.6531 |
| LRD | 22.13 | 0.7172 |
| Our | 22.60 | 0.6728 |
| Method | NIQE↓ | ||||
|---|---|---|---|---|---|
| LIME | MEF | NPE | DICM | VV | |
| SRIE | 3.3481 | 3.1601 | 3.6930 | 3.4161 | 3.0015 |
| LIME | 3.3176 | 2.9363 | 3.9679 | 3.5289 | 2.4221 |
| RRM | 4.1056 | 4.3742 | 4.3785 | 3.9799 | 4.3785 |
| MBLLEN | 4.1445 | 4.1969 | 4.2200 | 4.0426 | 4.0631 |
| KinD | 4.5086 | 3.3126 | 3.7476 | 3.8037 | 2.9148 |
| DeepUPE | 3.6233 | 3.4051 | 4.0390 | 3.9296 | 3.1807 |
| RetinexNet | 4.0272 | 3.9265 | 4.1013 | 4.1775 | 2.5792 |
| EnlightenGAN | 3.1880 | 2.9440 | 3.6775 | 3.3632 | 2.5875 |
| KinD++ | 4.3394 | 3.3082 | 3.8462 | 3.5727 | 2.5974 |
| Our | 3.6706 | 2.9956 | 3.6124 | 3.3186 | 3.1158 |
| Metric | Module | |||
|---|---|---|---|---|
| ResNet | Res2Net | Res2Net + PSA | CFANet | |
| PSNR | 19.72 | 19.94 | 20.83 | 21.64 |
| SSIM | 0.8037 | 0.8078 | 0.8143 | 0.8481 |
| Loss Configuration | PSNR | SSIM |
|---|---|---|
| 1. with , w/o , w/o , w/o | 20.19 | 0.8225 |
| 2. with , with , w/o , w/o | 21.43 | 0.8341 |
| 3. with , with , with , w/o | 21.40 | 0.8367 |
| 4. default configuration | 21.64 | 0.8481 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, J.; Chen, X.; Qiu, C.; Zhang, Z. Low-Light Image Enhancement Using Photometric Alignment with Hierarchy Pyramid Network. Sensors 2022, 22, 6799. https://doi.org/10.3390/s22186799
Ye J, Chen X, Qiu C, Zhang Z. Low-Light Image Enhancement Using Photometric Alignment with Hierarchy Pyramid Network. Sensors. 2022; 22(18):6799. https://doi.org/10.3390/s22186799
Chicago/Turabian StyleYe, Jing, Xintao Chen, Changzhen Qiu, and Zhiyong Zhang. 2022. "Low-Light Image Enhancement Using Photometric Alignment with Hierarchy Pyramid Network" Sensors 22, no. 18: 6799. https://doi.org/10.3390/s22186799