
Synthesising 2D Video from 3D Motion Data for Machine Learning Applications
 , , , and
, , , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
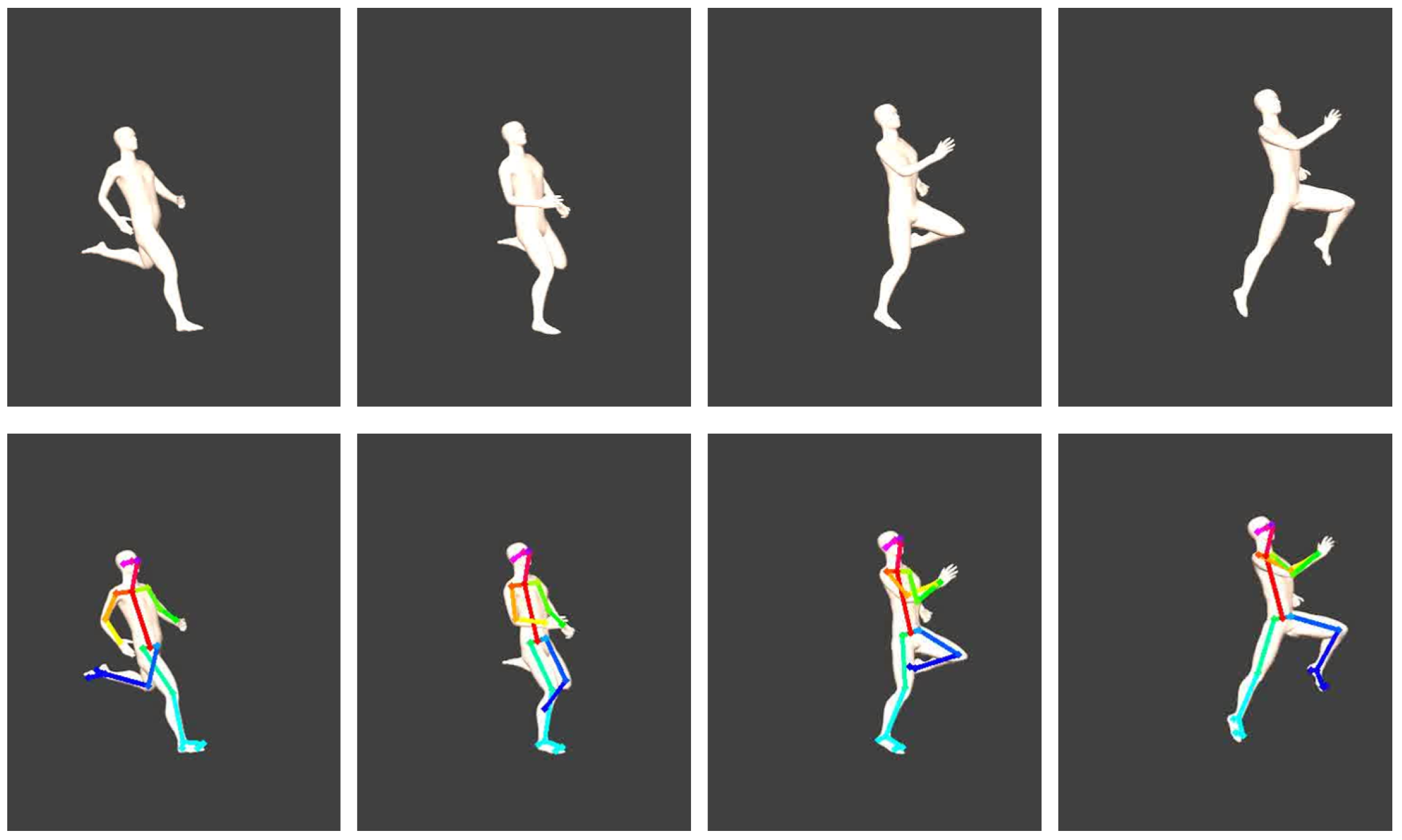{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
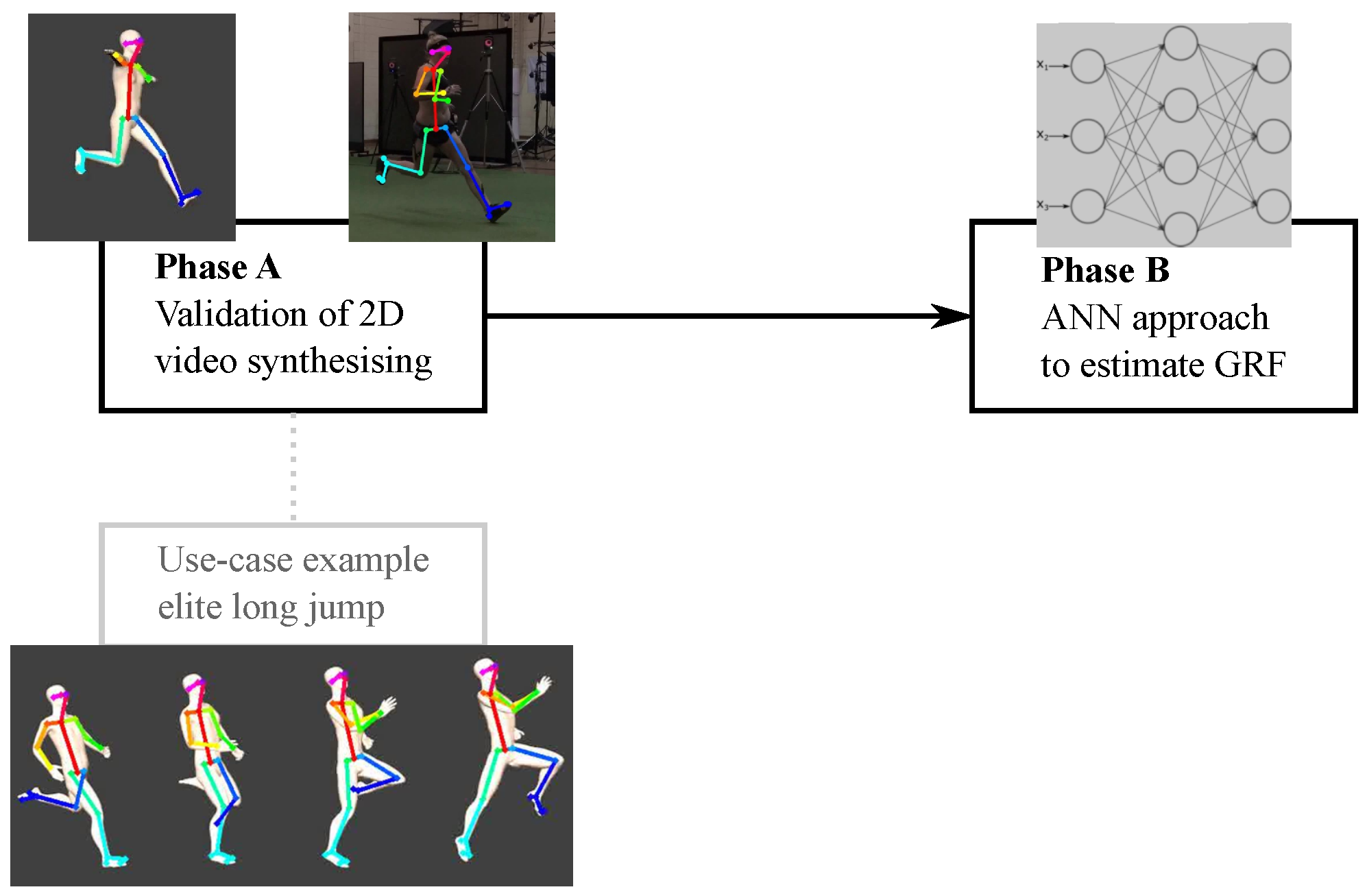
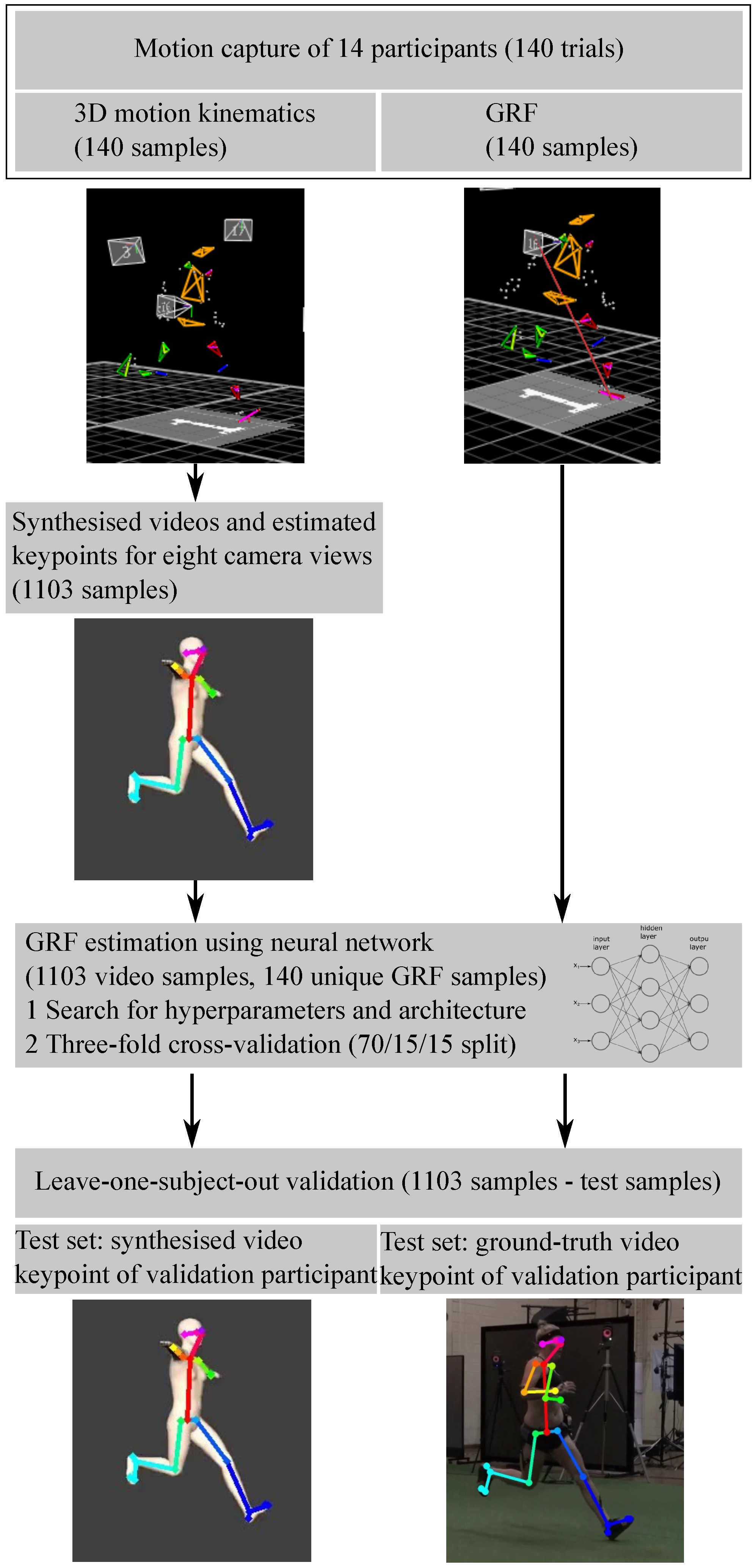
2. General Design
3. Phase A Methods and Results
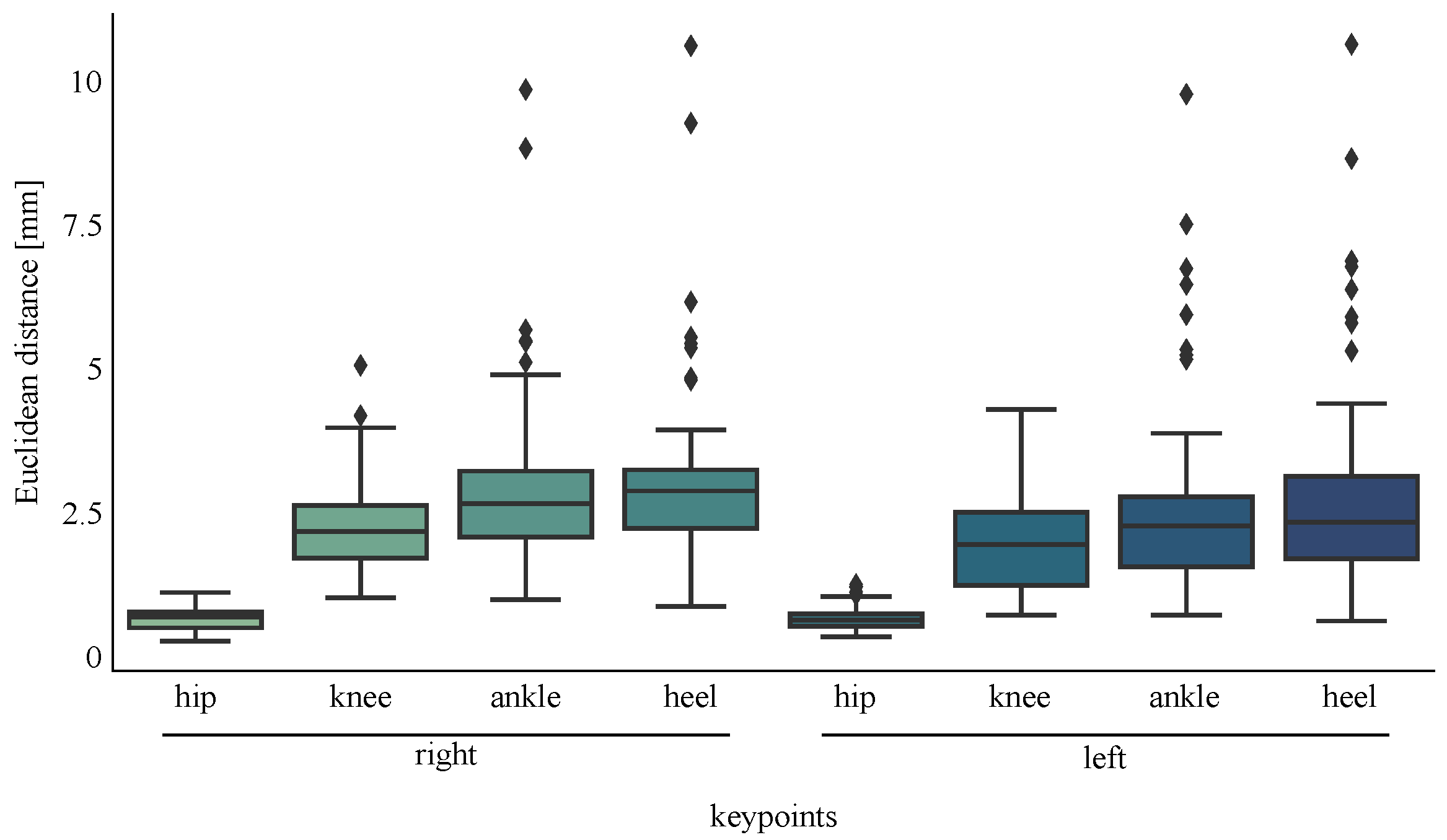
3.1. Development and Validation of a Novel 2D Video Synthesis Method
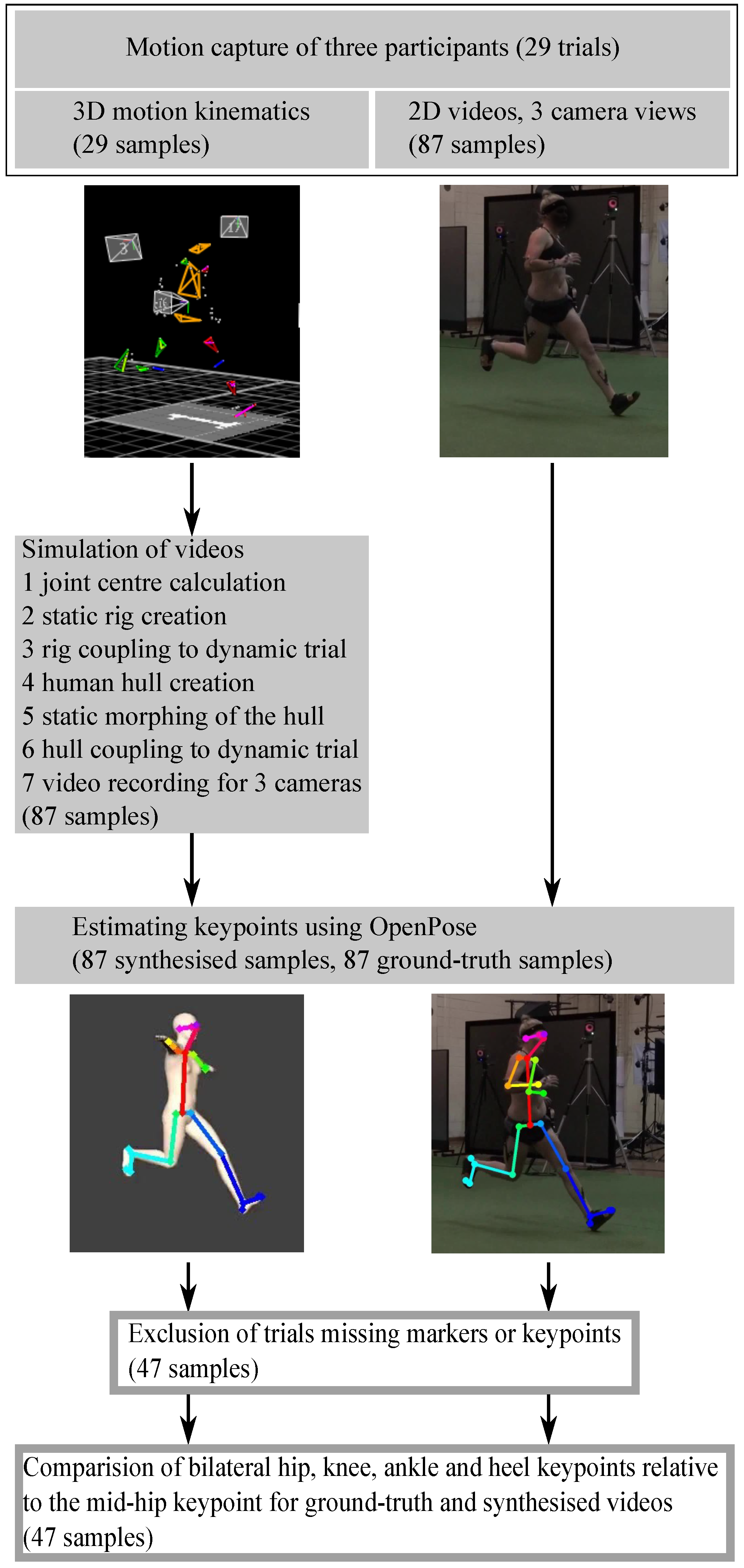
3.1.1. Dataset
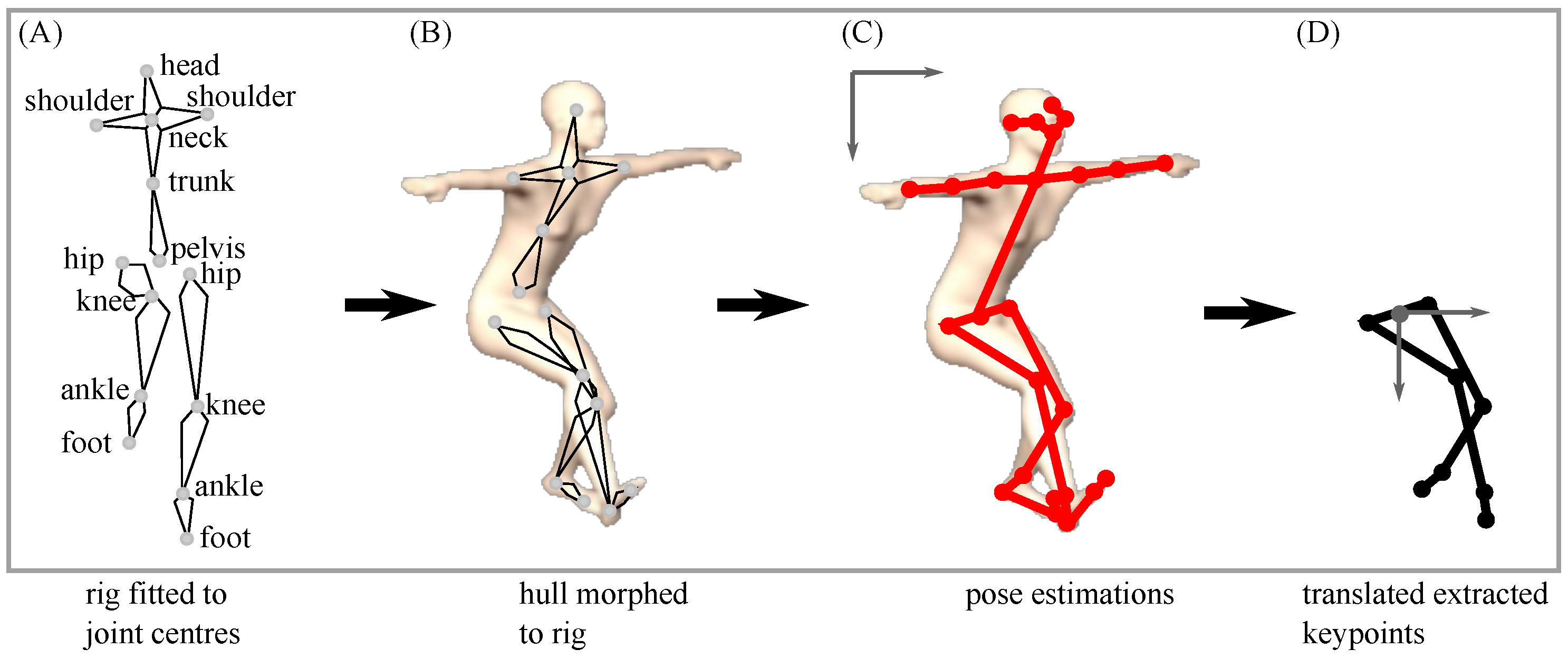
3.1.2. Synthesising 2D Videos
3.1.3. 2D Pose Estimation Using OpenPose
3.1.4. Data Processing
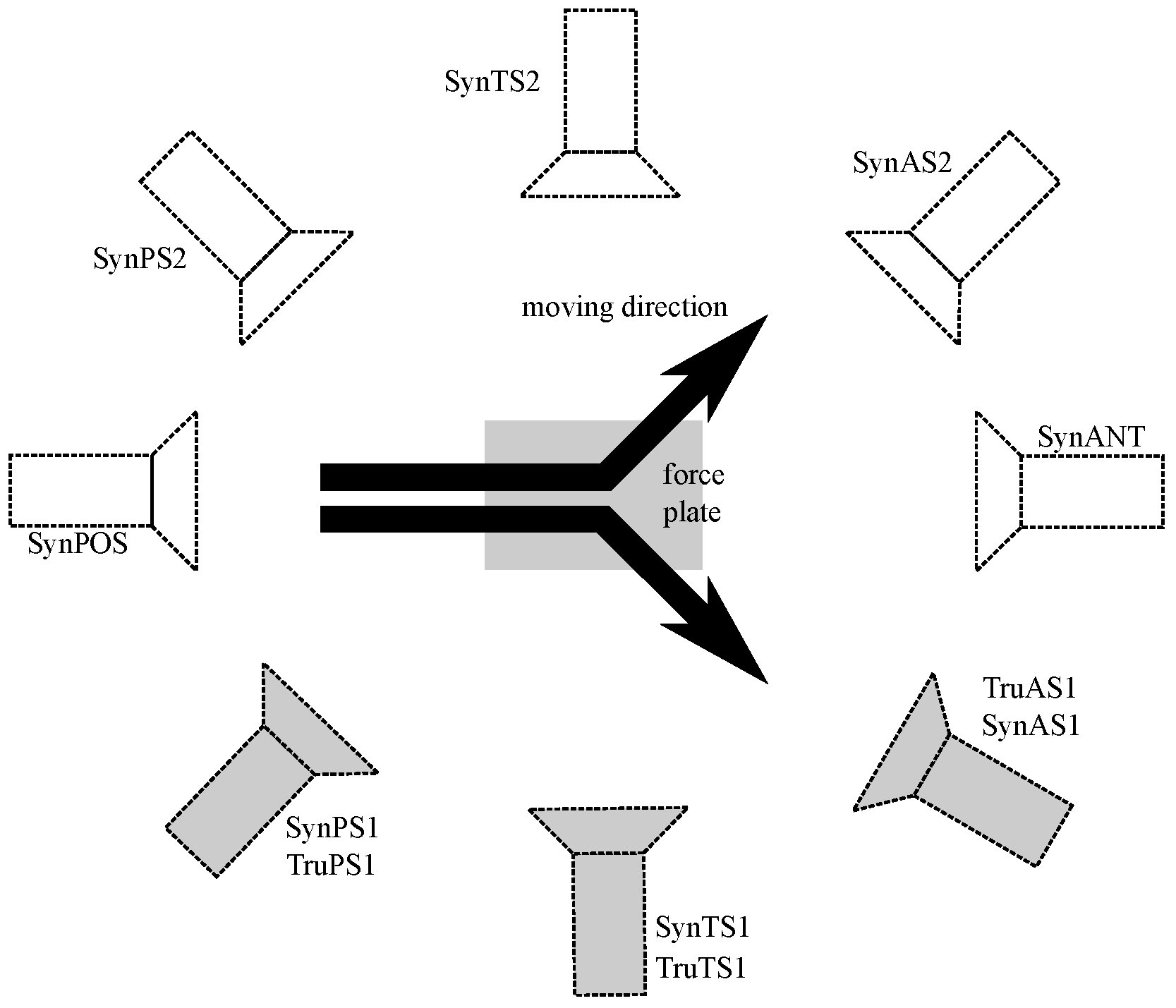
3.1.5. Results
3.2. Elite Long Jump Data Applied Use-Case
4. Phase B Methods and Results
4.1. Phase B: Training and Validating an ANN for Ground Reaction Force Estimation Using Synthesised Video Images
4.1.1. Dataset
4.1.2. 2D Video Data and 3D GRF Data Processing
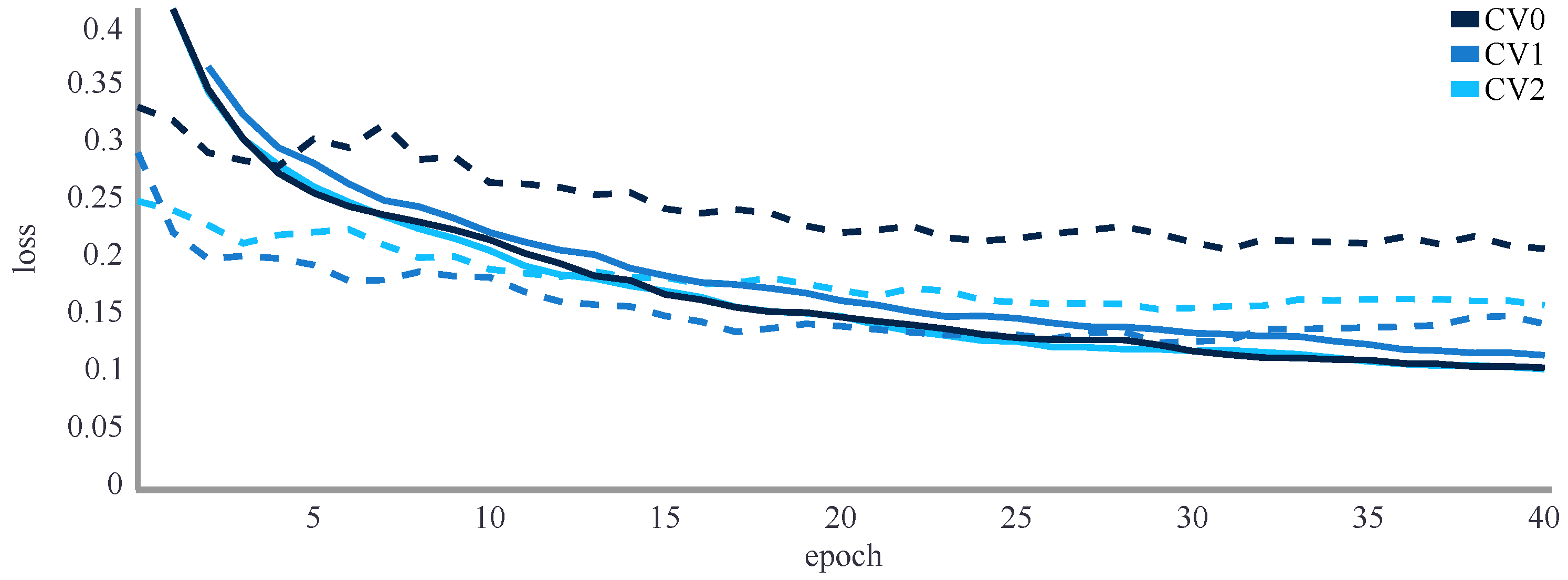
4.1.3. ANN Model Training
4.1.4. ANN Validation
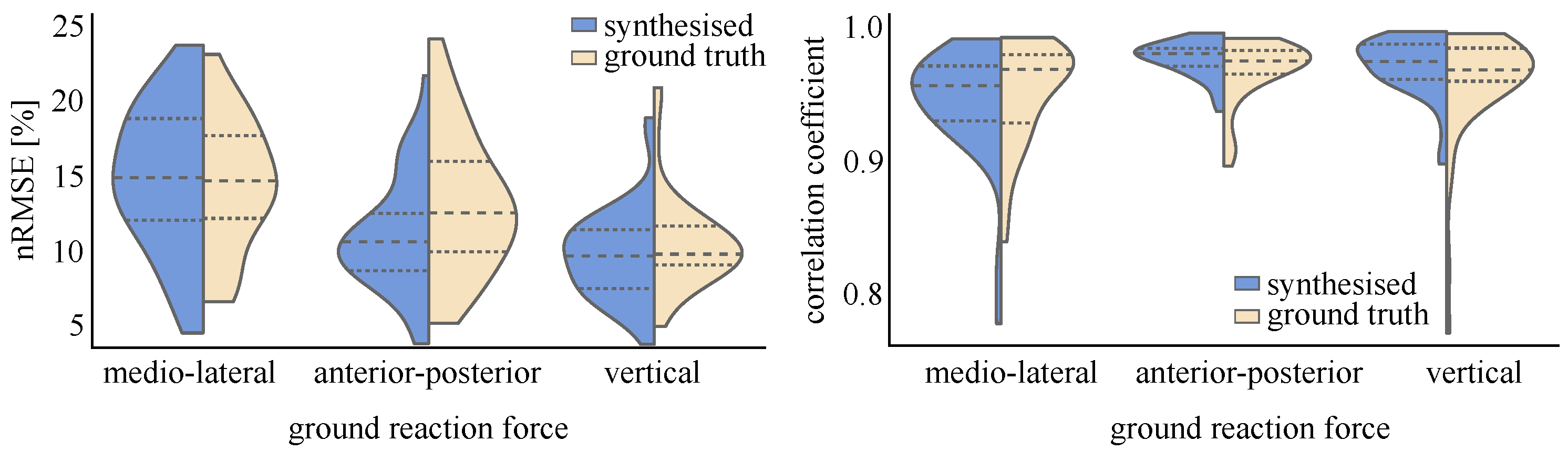
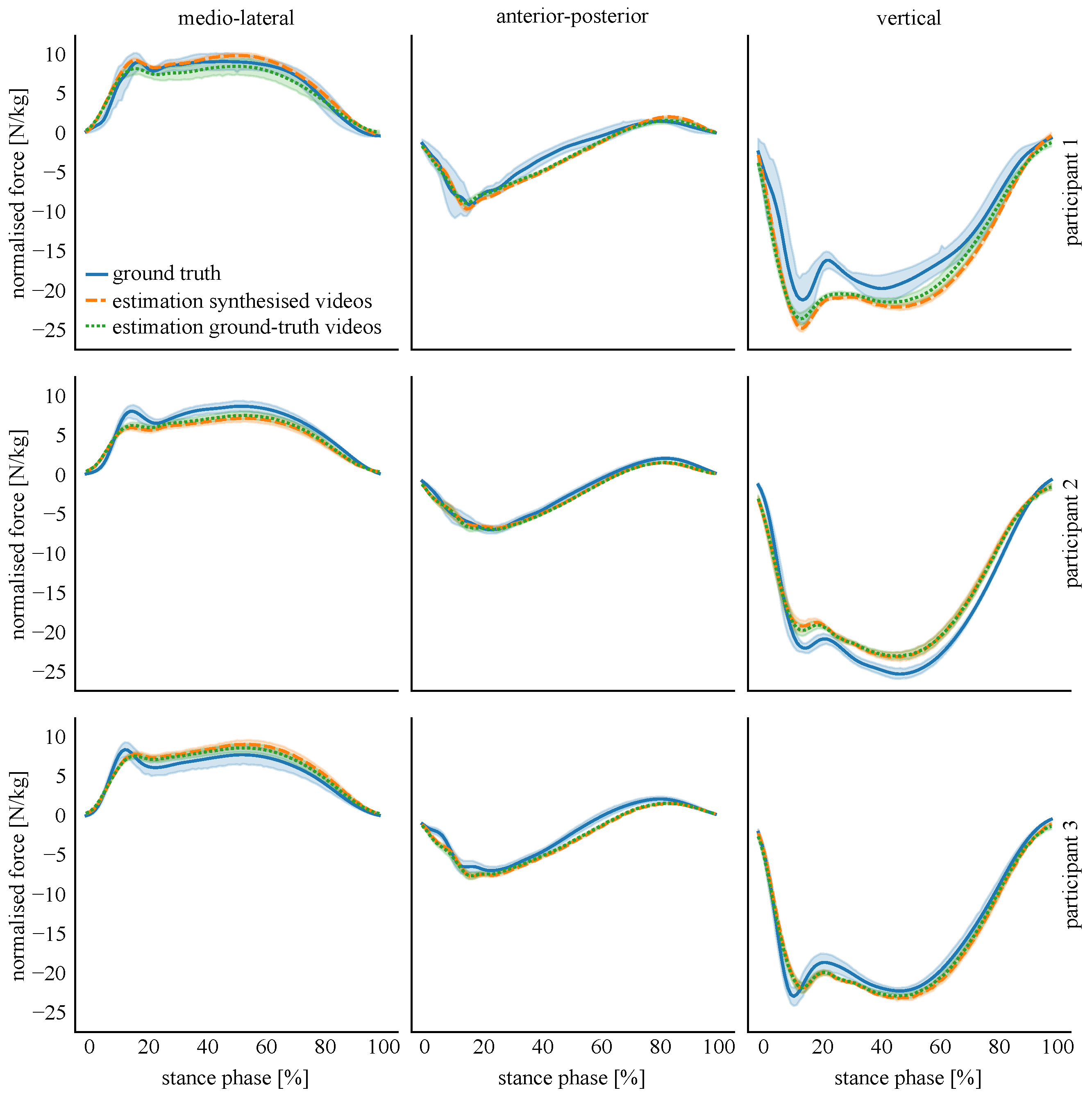
4.1.5. Results
5. Discussion
Broader Context
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Winter, D. The Biomechanics and Motor Control of Human Gait: Normal, Elderly, and Pathological, 2nd ed.; University of Waterloo Press: Waterloo, ON, Canada, 1991. [Google Scholar]
- Rapp, E.; Shin, S.; Thomsen, W.; Ferber, R.; Halilaj, E. Estimation of kinematics from inertial measurement units using a combined deep learning and optimization framework. J. Biomech. 2021, 116, 110229. [Google Scholar] [CrossRef] [PubMed]
- Clermont, C.A.; Phinyomark, A.; Osis, S.T.; Ferber, R. Classification of higher- and lower-mileage runners based on running kinematics. J. Sport Health Sci. 2019, 8, 249–257. [Google Scholar] [CrossRef] [PubMed]
- Johnson, W.R.; Mian, A.S.; Donnelly, C.J.; Lloyd, D.; Alderson, J. Predicting athlete ground reaction forces and moments from motion capture. Med. Biol. Eng. Comput. 2018, 56, 1781–1792. [Google Scholar] [CrossRef]
- Johnson, W.R.; Alderson, J.; Lloyd, D.; Mian, A.S. Predicting athlete ground reaction forces and moments from spatio-temporal driven CNN models. IEEE Trans. Biomed. Eng. 2019, 66, 689–694. [Google Scholar] [CrossRef] [PubMed]
- Funken, J.; Heinrich, K.; Willwacher, S.; Müller, R.; Böcker, J.; Hobara, H.; Brüggemann, G.P.; Potthast, W. Leg amputation side determines performance in curve sprinting: A case study on a Paralympic medalist. Sport. Biomech. 2017, 18, 75–87. [Google Scholar] [CrossRef]
- Willwacher, S.; Funken, J.; Heinrich, K.; Müller, R.; Hobara, H.; Grabowski, A.M.; Brüggemann, G.P.; Potthast, W. Elite long jumpers with below the knee prostheses approach the board slower, but take-off more effectively than non-amputee athletes. Sci. Rep. 2017, 7, 16058. [Google Scholar] [CrossRef]
- Felton, P.J.; Lister, S.L.; Worthington, P.J.; King, M.A. Comparison of biomechanical characteristics between male and female elite fast bowlers. J. Sport. Sci. 2019, 37, 665–670. [Google Scholar] [CrossRef]
- Spratford, W.; Elliott, B.; Portus, M.; Brown, N.; Alderson, J. Illegal bowling actions contribute to performance in cricket finger-spin bowlers. Scand. J. Sport. Sci. 2018, 28, 1691–1699. [Google Scholar] [CrossRef] [PubMed]
- Ng, L.; Rosalie, S.M.; Sherry, D.; Loh, W.B.; Sjurseth, A.M.; Iyengar, S.; Wild, C.Y. A biomechanical comparison in the lower limb and lumbar spine between a hit and drag flick in field hockey. J. Sport. Sci. 2018, 36, 2210–2216. [Google Scholar] [CrossRef]
- Cerrito, A.; Milburn, P.; Adams, R.; Evans, K. Cervical spine kinematics measured during rugby union scrums: Reliability of optoelectronic and electromagnetic tracking systems. Cogent Med. 2018, 5, 1526758. [Google Scholar] [CrossRef]
- Teufl, W.; Miezal, M.; Taetz, B.; Fröhlich, M.; Bleser, G. Validity, test-retest reliability and long-term stability of magnetometer free inertial sensor based 3D joint kinematics. Sensors 2018, 18, 1980. [Google Scholar] [CrossRef] [PubMed]
- van der Kruk, E.; Reijne, M.M. Accuracy of human motion capture systems for sport applications; state-of-the-art review. Eur. J. Sport Sci. 2018, 18, 806–819. [Google Scholar] [CrossRef] [PubMed]
- Mundt, M.; David, S.; Koeppe, A.; Bamer, F.; Markert, B.; Potthast, W. Intelligent prediction of kinetic parameters during cutting manoeuvres. Med. Biol. Eng. Comput. 2019, 57, 1833–1841. [Google Scholar] [CrossRef]
- Camomilla, V.; Bergamini, E.; Fantozzi, S.; Vannozzi, G. Trends supporting the in-field use of wearable inertial sensors for sport performance evaluation: A systematic review. Sensors 2018, 18, 873. [Google Scholar] [CrossRef] [PubMed]
- Adesida, Y.; Papi, E.; McGregor, A.H. Exploring the role of wearable technology in sport kinematics and kinetics: A systematic review. Sensors 2019, 19, 1597. [Google Scholar] [CrossRef] [PubMed]
- Kos, A.; Milutinović, V.; Umek, A. Challenges in wireless communication for connected sensors and wearable devices used in sport biofeedback applications. Future Gener. Comput. Syst. 2019, 92, 582–592. [Google Scholar] [CrossRef]
- Colyer, S.L.; Evans, M.; Cosker, D.P.; Salo, A.I. A Review of the Evolution of Vision-Based Motion Analysis and the Integration of Advanced Computer Vision Methods Towards Developing a Markerless System. Sport. Med. Open 2018, 4, 24. [Google Scholar] [CrossRef]
- Worsey, M.T.; Espinosa, H.G.; Shepherd, J.B.; Thiel, D.V. Inertial sensors for performance analysis in combat sports: A systematic review. Sports 2019, 7, 28. [Google Scholar] [CrossRef]
- Robert-Lachaine, X.; Mecheri, H.; Larue, C.; Plamondon, A. Validation of inertial measurement units with an optoelectronic system for whole-body motion analysis. Med. Biol. Eng. Comput. 2016, 55, 609–619. [Google Scholar] [CrossRef]
- Mundt, M.; Thomsen, W.; David, S.; Dupré, T.; Bamer, F.; Potthast, W.; Markert, B. Assessment of the measurement accuracy of inertial sensors during different tasks of daily living. J. Biomech. 2019, 84, 81–86. [Google Scholar] [CrossRef]
- Caruso, M.; Sabatini, A.M.; Laidig, D.; Seel, T.; Knaflitz, M.; Croce, U.D.; Cereatti, A. Analysis of the accuracy of ten algorithms for orientation estimation using inertial and magnetic sensing under optimal conditions: One size does not fit all. Sensors 2021, 21, 2543. [Google Scholar] [CrossRef] [PubMed]
- Margoni, T. The Protection of Sports Events in the EU: Property, Intellectual Property, Unfair Competition and Special Forms of Protection. IIC Int. Rev. Intellect. Prop. Compet. Law 2016, 47, 386–417. [Google Scholar] [CrossRef]
- Hutchins, B.; Andrejevcic, M. Olympian surveillance: Sports stadiums and the normalization of biometric monitoring. Int. J. Commun. 2022, 15, 363–382. [Google Scholar]
- Powles, J.; Walsh, T.; Henne, K.; Weber, J.; Moses, L.; Elliott, A.; Innes, M.; Graham, M.; Starre, K.; Harris, R.; et al. Getting Ahead of the Game: Athlete Data in Professional Sport; White Paper; Australian Academy of Science: Canberra, Australia, 2022; Available online: https://science.org.au/datainsport/ (accessed on 1 July 2022).
- Wade, L.; Needham, L.; McGuigan, P.; Bilzon, J. Applications and limitations of current markerless motion capture methods for clinical gait biomechanics. PeerJ 2022, 10, e12995. [Google Scholar] [CrossRef]
- Nakano, N.; Sakura, T.; Ueda, K.; Omura, L.; Kimura, A.; Iino, Y.; Fukashiro, S.; Yoshioka, S. Evaluation of 3D markerless motion capture accuracy using OpenPose With multiple video cameras. Front. Sport. Act. Living 2020, 2, 50. [Google Scholar] [CrossRef]
- Payton, C.J.; Burden, A. Biomechanical Evaluation of Movement in Sport and Exercise: The British Association of Sport and Exercise Sciences Guide, 2nd ed.; Routledge: London, UK, 2017. [Google Scholar] [CrossRef]
- Ancillao, A.; Tedesco, S.; Barton, J.; O’flynn, B. Indirect measurement of ground reaction forces and moments by means of wearable inertial sensors: A systematic review. Sensors 2018, 18, 2564. [Google Scholar] [CrossRef]
- Karatsidis, A.; Bellusci, G.; Schepers, H.; de Zee, M.; Andersen, M.S.; Veltink, P. Estimation of ground reaction forces and moments during gait using only inertial motion capture. Sensors 2017, 17, 75. [Google Scholar] [CrossRef]
- Johnson, W.R.; Mian, A.; Robinson, M.A.; Verheul, J.; Lloyd, D.G.; Alderson, J. Multidimensional ground reaction forces and moments from wearable sensor accelerations via deep learning. IEEE Trans. Biomed. Eng. 2020, 68, 289–297. [Google Scholar] [CrossRef]
- Mundt, M.; Koeppe, A.; David, S.; Bamer, F.; Potthast, W. Prediction of ground reaction force and joint moments based on optical motion capture data during gait. Med. Eng. Phys. 2020, 86, 29–34. [Google Scholar] [CrossRef]
- Wouda, F.J.; Giuberti, M.; Bellusci, G.; Maartens, E.; Reenalda, J.; van Beijnum, B.J.F.; Veltink, P.H. Estimation of vertical ground reaction forces and sagittal knee kinematics during running using three inertial sensors. Front. Physiol. 2018, 9, 218. [Google Scholar] [CrossRef]
- Komaris, D.S.; Pérez-Valero, E.; Jordan, L.; Barton, J.; Hennessy, L.; O’flynn, B.; Tedesco, S. Predicting three-dimensional ground reaction forces in running by using artificial neural networks and lower body kinematics. IEEE Access 2019, 7, 156779–156786. [Google Scholar] [CrossRef]
- Morris, C.; Mundt, M.; Goldacre, M.; Weber, J.; Mian, A.; Alderson, J. Predicting 3D ground reaction force from 2D video via neural networks in sidestepping tasks. In Proceedings of the 39th Conference of the International Society of Biomechanics in Sports, Canberra, Australia, 3–7 September 2021. [Google Scholar]
- Besier, T.F.; Sturnieks, D.L.; Alderson, J.; Lloyd, D.G. Repeatability of gait data using a functional hip joint centre and a mean helical knee axis. J. Biomech. 2003, 36, 1159–1168. [Google Scholar] [CrossRef]
- Dempsey, A.R.; Lloyd, D.G.; Elliott, B.C.; Steele, J.R.; Munro, B.J.; Russo, K.A. The effect of technique change on knee loads during sidestep cutting. Med. Sci. Sport. Exerc. 2007, 39, 1765–1773. [Google Scholar] [CrossRef] [PubMed]
- Campbell, A.C.; Alderson, J.A.; Lloyd, D.G.; Elliott, B.C. Effects of different technical coordinate system definitions on the three dimensional representation of the glenohumeral joint centre. Med. Biol. Eng. Comput. 2009, 47, 543–550. [Google Scholar] [CrossRef]
- Harrington, M.E.; Zavatsky, A.B.; Lawson, S.E.M.; Yuan, Z.; Theologis, T.N. Prediction of the hip joint centre in adults, children, and patients with cerebral palsy based on magnetic resonance imaging. J. Biomech. 2007, 40, 595–602. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 1 January 2022).
- Koeppe, A.; Bamer, F.; Markert, B. An efficient Monte Carlo strategy for elasto-plastic structures based on recurrent neural networks. Acta Mech. 2019, 230, 3279–3293. [Google Scholar] [CrossRef]
- Saeb, S.; Lonini, L.; Jayaraman, A.; Mohr, D.C.; Kording, K.P. The need to approximate the use-case in clinical machine learning. GigaScience 2017, 6, gix019. [Google Scholar] [CrossRef]
- Fiorentino, N.M.; Atkins, P.R.; Kutschke, M.J.; Bo Foreman, K.; Anderson, A.E. Soft tissue artifact causes underestimation of hip joint kinematics and kinetics in a rigid-body musculoskeletal model. J. Biomech. 2020, 108, 109890. [Google Scholar] [CrossRef]
- Nissenbaum, H. Privacy in Context: Technology, Policy, and the Integrity of Social Life; Stanford University Press: Stanford, CA, USA, 2009. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mundt, M.; Oberlack, H.; Goldacre, M.; Powles, J.; Funken, J.; Morris, C.; Potthast, W.; Alderson, J. Synthesising 2D Video from 3D Motion Data for Machine Learning Applications. Sensors 2022, 22, 6522. https://doi.org/10.3390/s22176522
Mundt M, Oberlack H, Goldacre M, Powles J, Funken J, Morris C, Potthast W, Alderson J. Synthesising 2D Video from 3D Motion Data for Machine Learning Applications. Sensors. 2022; 22(17):6522. https://doi.org/10.3390/s22176522
Chicago/Turabian StyleMundt, Marion, Henrike Oberlack, Molly Goldacre, Julia Powles, Johannes Funken, Corey Morris, Wolfgang Potthast, and Jacqueline Alderson. 2022. "Synthesising 2D Video from 3D Motion Data for Machine Learning Applications" Sensors 22, no. 17: 6522. https://doi.org/10.3390/s22176522