1. Introduction
An indoor map is crucial for user-end localization [
1], indoor navigation [
2], and the drift constraint of inertial sensors [
3,
4]. However, because the geometric features and signal sources in indoor environments tend to change dynamically over time, traditional manual operation-based map construction methods encounter difficulties in updating. Additionally, digital or computer-aided design (CAD) maps describing environments are usually unavailable due to commercial interest or privacy [
5,
6]. Therefore, in both industry and academia, the autonomous construction and updating of a high-precision and robust venue map in unknown indoor environments has been a hot topic.
Scholars have proposed many sensor-based mapping solutions, such as lidar-based [
7], camera-based [
8], Wi-Fi-based, inertial measurement unit (IMU)-based, and magnetic-based [
9], to solve the mapping problem in unknown indoor environments. Due to these sensors’ inherent characteristics, single-sensor-based map construction methods have limited application scopes. Multipath interference and packet loss, for instance, significantly impact the stability of Wi-Fi signals, which can result in the loss or misidentification of Wi-Fi fingerprints. Furthermore, it is time-consuming and labor-intensive to construct a radio map based on offline-collected Wi-Fi data at reference points (RPs) [
10,
11]. The construction of high-accuracy maps is feasible with multi-sensor fusion-based solutions that leverage sensor complementarity. However, a single-track map based on multi-sensor fusion contains limited space-related information about the entire scene. Three factors have a significant effect on the accuracy of a single-track map: (1) signal stability, (2) trajectory length, and (3) the stability of hardware devices (such as robots, smartphones, and unmanned aerial vehicles (UAVs)). Fusing multiple single-track maps is a feasible solution for constructing high-accuracy and wide-coverage venue maps, where the raw sensor data are collected by a new sensing paradigm, crowdsourcing [
12]. Smartphones, which are portable smart terminals, have superior environmental perception thanks to an array of built-in sensors, including cameras [
13], IMUs, Wi-Fi signal receivers, magnetometers [
9], and photoelectric encoders. Due to the prevalence of smartphones, the efficiency of crowdsourcing data collection is also enhanced. In complex environments, numerous smartphone-based map construction and localization methods via crowdsourcing have been proposed [
14], such as CrowdInside [
15], SISE [
16], and Zhou et al. also proposed methods [
17,
18,
19]. By processing smartphone-collected crowdsourcing data, a map is constructed by combining semantic/feature information with the estimated trajectories. Trajectories are estimated using pedestrian dead reckoning (PDR) [
18,
20] or visual SLAM [
21].
Landmarks play a crucial role in crowdsourcing-based or multi-robot cooperative mapping, which can be used for trajectory alignment and venue characterization [
22]. Semantic landmarks, such as elevators, corners, stairs, and escalators, are detected by activity detection algorithms [
17] based on inertial sensors or barometers. However, an indoor environment typically contains more than the predefined number of semantic landmarks, such as ashcans, windows, and doors. Theoretically, as the variety of landmarks available for object detection increases, so does the density of landmarks. Rich low- (such as colors, contexts, and points) and high-level visual features (e.g., semantics) are presented in an image. Moreover, due to the development of deep learning, increasingly precise object detectors [
23,
24] and semantic segmentation models [
25,
26] are being used for semantic landmark recognition. Landmarks can also be used as nodes of an optimization graph, such as [
17,
18,
27]. Since the single-track semantic maps consist of waypoints, semantic landmarks, and Wi-Fi landmarks, we construct a novel optimization graph for map optimization instead of other classic optimization methods, such as particle swarm optimization [
28], hybrid grey wolf optimizer [
29], artificial bee colony optimization algorithm [
30], and genetic algorithm [
31].
This paper proposes a crowdsourcing-based semantic map construction and updating method for unknown indoor environments, such as office buildings, shopping malls, and disaster-stricken houses. The constructed map can be used as a localization map for estimating a client’s location. The proposed method combines the idea of PDR-aided VI-SLAM [
32], object detection and crowdsourcing, and uses the optimization technique to fuse crowdsourced trajectories collected by different clients. Using images, inertial measurements, and Wi-Fi signals constructs a single-track semantic map composed of waypoints, semantic landmarks, and Wi-Fi landmarks. The highest-quality single-track map is used to initialize the venue map to ensure mapping precision and efficacy. A candidate map for map fusion is the single-track semantic map with the highest degree of similarity to the venue map. Due to the vacancy of the actual azimuth of starting points, trajectories estimated by PDR-aided visual-inertial simultaneous mapping and localization (PDR-aided VI-SLAM) are in an inconsistent coordinate system. Consequently, the candidate and venue maps are aligned using corresponding landmarks before employing graph optimization. The nodes of the optimization graph are waypoints, semantic landmarks, and Wi-Fi landmarks. And the edges are association constraints (such as waypoint–waypoint, waypoint–Wi-Fi, and waypoint–semantic) and matching constraints (such as semantic–semantic and Wi-Fi–Wi-Fi). The lightweight venue map is updated after graph optimization with respect to waypoints, semantic landmarks, and Wi-Fi landmarks. To estimate the location of a pedestrian in relation to the venue map, a local map is compared to the venue map. The proposed method has broad application prospects, such as indoor navigation in unknown environments, big data intelligent recommendation, and post-disaster search and rescue. Taking indoor navigation in unknown environments as an example, the proposed method solves the problem of map construction for unknown indoor environments and indoor positioning drift. By processing the data collected by different mall shoppers, a venue map describing the whole shopping mall is constructed without any prior knowledge. Using the proposed localization methods, a pedestrian’s location on the venue map is estimated. After that, possible pathways from the current position to the destination are accessible. The multi-landmark matching-based localization method improves the localization robustness significantly.
To summarize, the main contributions of the proposed method are:
A crowdsourcing-based semantic map construction and updating method are proposed for unknown indoor environments, which can significantly reduce the cost of map construction and updating. Particularly, the crowdsourcing data is collected using smartphones’ built-in sensors.
An optimization graph is constructed using waypoints, semantic landmarks, and Wi-Fi landmarks as nodes, and the relevance between waypoints and landmarks as edges, which improves the accuracy of venue maps.
The real-world experimental results demonstrate that the proposed map construction and updating method is suitable for office building and shopping mall scenes. Additionally, venue maps have higher accuracy than single-track semantic maps when used for localization.
The remainder of this paper is organized as follows.
Section 2 reviews the related works of the proposed method.
Section 3 describes the main contexts in detail, while
Section 3.1 provides an overview of the system.
Section 4 presents an analysis of experiment results. Finally,
Section 5 concludes the paper with a summary and a discussion of future research directions.
3. The Main Context
3.1. System Overview
The map construction and localization method are depicted in
Figure 1 with a general overview. It relies on smartphone-collected sensor data, including visual images, inertial measurements (i.e., accelerometer and gyroscope measurements), and raw Wi-Fi fingerprints. Specifically, Wi-Fi fingerprints contain the media address control (MAC) and RSS values of access points (APs).
Data preprocessing is the first step of the crowdsourcing-based indoor semantic map construction and localization method. After fusing multi-sensor data, a group of single-track semantic maps comprised of waypoints, semantic landmarks, and Wi-Fi landmarks is constructed.
The second component involves map fusion and venue map updates. First, the transformation matrix between the candidate and venue maps is estimated using semantic and Wi-Fi landmarks that match. Then, optimize the aligned maps under the constraints of association and matching. The waypoints, semantic landmarks, and Wi-Fi landmarks serve as nodes in the optimization graph, while the association and matching relationships between waypoints and landmarks serve as constraint edges. To reduce venue map redundancy, the optimized venue map is updated with respect to waypoints, semantic landmarks, Wi-Fi landmarks, and the association between them. Notably, map alignment and fusion are performed incrementally. When a new candidate map is selected, a new map alignment and venue map update iteration is initiated.
The final component is localization. A localization method based on landmark matching is utilized to estimate a pedestrian’s location on a venue map. Wi-Fi fingerprinting specifically determines the relationship between semantic landmarks in the local and venue maps.
3.2. Crowdsourcing Data Preprocessing
Smartphone-collected crowdsourcing data is preprocessed to construct single-track semantic maps containing waypoints, semantic landmarks, and Wi-Fi landmarks.
The PDR-aided VI-SLAM outputs keyframes, keyframe-rate feature points, and IMU-rate waypoints using time-synchronized monocular visual and inertial measurements as inputs. The PDR-aided VI-SLAM uses the PDR’s velocity as an external observation to constrain the scale drift of the conventional VI-SLAM systems [
32], which is defined as Equation (1):
where
,
, and
denote a pedestrian’s velocity at time
, which are estimated by the PDR-aided VI-SLAM (abbreviated, PAM), PDR, and visual and inertial odometry (abbreviated, VIO), respectively.
and
denote the weight factor of the velocity estimated by the PDR and VIO, respectively. Visual tracking may fail due to a change in lighting or a lack of texture, where PDR has the greatest weight in velocity estimation, i.e.,
.
The PDR-aided VI-SLAM is applicable to closed-loop and non-closed-loop trajectory scale correction. Experiments conducted on the self-collected and public ADVIO datasets [
32,
46,
47] confirmed that PDR-aided VI-SLAM provides more accurate pose estimation than traditional VI-SLAM systems [
32]. The front-end visual processing outputs keyframes based on the average parallax and tracking quality principles [
48]. When YOLO V4 only detects semantic objects in the selected keyframes, the object detector’s performance is significantly enhanced.
As summarized in
Table 1, YOLO V4, a pretrained object detector, outputs the attributes of semantic objects in the selected keyframes with high precision. Additionally, it summarizes the attributes of the PDR-aided VI-SLAM-estimated feature points. By analyzing their attributes, it is possible to conclude that a semantic landmark can be created using the shared attribute of semantic objects and feature points, namely, 2D pixel coordinates.
For the
keyframe, feature points satisfying the constraint of Equation (2) correspond to the
semantic object:
where
is the upper left vertex of the semantic bounding box, and
is the lower right vertex.
is the pixel coordinate of a feature point.
The intersection over union (IOU) metric evaluates the coincidence degree of the semantic object with those objects having the same class label in previously keyframes. If the IOU score of the semantic object exceeds the set threshold, the semantic object and corresponding feature points are labeled with an index, which is the same as that of the matched semantic objects in previously keyframes. Since the bounding box is rectangular and semantic objects are typical of irregular shapes, the bounding box contains outliers. The R-DBSCAN algorithm is applied to filter outliers from randomly selected feature points. The final step involves calculating the location of a semantic object relative to the corresponding trajectory as the centroid of filtered feature points with the same index.
Wi-Fi fingerprint stability is significantly impacted by the signal multipath effect, air humidity, and access channel occupancy [
34]. Therefore, we employ a sliding window-based Wi-Fi fusion algorithm to improve the stability of the AP. In a sliding window, APs collected more than once are defined as shared APs, while others are defined as unique APs. The shared and unique APs in a sliding window form a Wi-Fi landmark, with the shared APs, fused in terms of RSS values and maturity. RSS values are used to sort all the APs belonging to a Wi-Fi landmark. The sliding window-based Wi-Fi fusion algorithm is an offline and efficient Wi-Fi fingerprint construction method as compared to the manual-based method. The Wi-Fi landmark can also be used as a localization feature.
A single-track semantic map is a map that depicts the environment’s spatial characteristics.
Figure 2 depicts the association relationship between waypoints, semantic landmarks, and Wi-Fi landmarks, where Wi-Fi landmarks have no direct association relationship with semantic landmarks. As a result, waypoints are employed as a link between semantic and Wi-Fi landmarks. Only waypoints, semantic landmarks, and Wi-Fi landmarks are saved in a map file to reduce storage requirements.
3.3. Map Alignment
All single-track semantic maps are constructed following the crowdsourcing data preprocessing. To avoid the effect of low-quality single-track semantic maps on map fusion, the quality of a map is evaluated using the function shown in Equation (3). Low-quality single-track semantic maps are filtered out, and the map with the highest quality score is chosen as the initial venue map. In Equation (3), a map quality
is positively correlated with the landmarks’ quality on a map. For conciseness, the abbreviated alphabets in the following equations are defined as follows: the waypoints are denoted as “P”, the semantic landmarks are denoted as “S”, the Wi-Fi landmarks are denoted as “W”, the association relationship is denoted as “A”, the matching relationship is denoted as “M”, the venue map is denoted as “V”, the candidate map is denoted as “C”, and the local map is denoted as “L”.
where
and
denote the importance of the semantic and Wi-Fi landmarks in evaluating the map quality, respectively. Compared to environmentally sensitive Wi-Fi landmarks, semantic landmarks are more stable and reliable. Therefore,
is twice as large as
. We also take the number of semantic landmarks
and Wi-Fi landmarks
into consideration. The map’s confidence
is defined as:
For the semantic landmark of a single-track semantic map, the confidence value reflects how confident the detector is that the bounding box contains an object and how accurate it thinks the bounding box is that it predicts.
Figure 3 illustrates the schematic diagram of map alignment. For map alignment, the semantic landmarks (diamonds) and Wi-Fi landmarks (circles) on a candidate map (colored green) are matched with those on a venue map (colored yellow). Map alignment is performed in an incremental method; when a candidate map is chosen, a standalone map alignment and venue map update are generated in one iteration.
The matching quality of venue and candidate maps
relies on the matched Wi-Fi and semantic landmarks, as defined in Equation (5):
The weight factor of the Wi-Fi landmarks
and semantic landmarks
are preset for evaluating the map matching quality. Considering the
Wi-Fi fingerprint in a venue map has
APs, the RSS values of the
APs are
, and considering the
Wi-Fi fingerprint in the single-track semantic map to be matched has
APs, the RSS values of the
APs are
. Suppose there are
shared APs,
, the Wi-Fi Euclidean distance
is calculated as follows:
For the unique APs in the Wi-Fi fingerprint, and the unique APs in the Wi-Fi fingerprint, the RSS value is unknown. Therefore, to unify RSS sequence length, the missing RSS values of unique APs in the , and Wi-Fi fingerprints are set as .
To reduce the effect of moving APs on the Wi-Fi landmark matching, the Wi-Fi sequence distance
is calculated as [
49]:
The Wi-Fi landmark distance between the venue map and single-track semantic map to be matched
is determined by the Wi-Fi Euclidean distance
and Wi-Fi sequence distance
simultaneously, as defined in Equation (7):
The moving APs can be detected by an AP selection algorithm [
50]. Therefore, the weight factor of Wi-Fi Euclidean distance
and Wi-Fi sequence distance
can be dynamically adjusted based on the corresponding AP quality. Additionally, the matching score can be used as prior knowledge for the subsequent iteration of selecting a candidate map.
The semantic landmarks are pre-matched based on their class attributes, establishing a one-to-many association. Since semantic landmarks are associated with Wi-Fi landmarks, Wi-Fi fingerprinting is used to determine a one-to-one association between semantic landmarks. Additionally, the distance between semantic landmarks is calculated using Equations (6)–(8). Utilizing pre-matching significantly improves the efficiency of matching landmarks.
As shown in
Figure 3a, a topological matching relationship is established between the venue and candidate maps using the matched landmark pairs (i.e., Wi-Fi and semantic landmark pairs). To align the candidate and venue maps, a transformation matrix
is estimated by minimizing the Equation (9):
where
and
denote the matched semantic and Wi-Fi landmarks in a venue map, respectively;
and
are the matched semantic and Wi-Fi landmarks in a candidate map, respectively; The weight factor of the matched semantic landmarks
is higher than that of Wi-Fi landmarks
in transformation matrix estimation, which is consistent with the map quality evaluation and map matching score calculation.
3.4. Graph Optimization
Graph optimization aims to improve the maximum fit of aligned maps by optimizing the position of waypoints and associated landmarks while satisfying association and matching constraints.
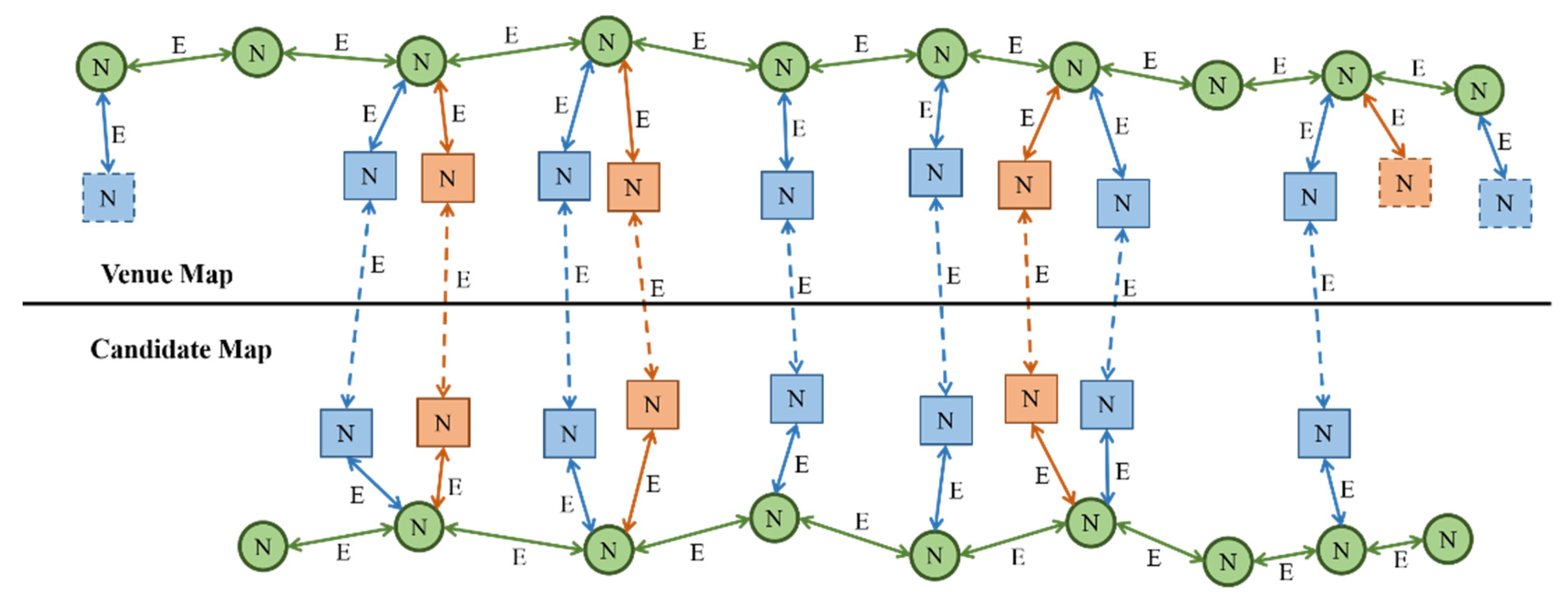
Figure 4 elaborates on the relationship between optimization graph nodes and edges. The association constraints (solid lines) in the optimization graph are the edges connecting waypoints and waypoints (solid green lines), waypoints and semantic landmarks (solid red lines), and waypoints and Wi-Fi landmarks (solid blue lines). Compared to the association constraint within one single map, the matching constraint edges (dotted lines) connect the matched landmarks between the venue and candidate maps, including semantic–semantic (dotted red lines) and Wi-Fi–Wi-Fi (dotted blue lines). Nodes are the “N”-marked groups of waypoints, semantic landmarks, and Wi-Fi landmarks observed on maps. All the edges are marked with “E”. There are also unmatched landmarks on the candidate and venue maps, as indicated by the dotted boxes.
For the
and
landmarks in a venue or candidate map, their absolute poses
and
are denoted by Equations (10) and (11), respectively [
18]:
where
and
denote the rotation matrix of the
and
landmarks relative to the initial pose point, respectively.
and
denote the translation vector of the
and
landmarks relative to the initial pose point, respectively.
Therefore, the pose of the
landmark relative to the
landmark
is calculated as follows:
where
and
are the angle of the
and
landmark relative to the initial pose point, respectively.
There are two types of relationships between the
and
landmarks: the association relationship and the matching relationship. If the
landmark is associated with the
landmark, relative pose measurement
is:
The cost function in terms of position and angle for the associated landmarks
is defined as:
If the
landmark is matched with the
landmark, the relative pose measurement
is:
The cost function in terms of position and angle for the matched landmarks
is defined as:
Therefore, the total error estimation function
is defined as follows [
40]:
The importance of the association and matching constraints on map optimization is reflected by the information matrices
,
,
,
, and
, respectively. Particularly, the matching constraints’ information matrix satisfies the following constraint:
The graph optimization aims at finding a
that minimize the error function
:
Then, a Gauss–Newton algorithm [
51] is used here to solve the optimization problem, as presented in Equation (22):
where
is a Hesse matrix of function
and
is the value of function
’s gradient vector at point
.
Similar to the map alignment, the graph optimization is performed incrementally.
3.5. Venue Map Updating
In the overlapped areas of the candidate and venue maps, the optimized results are duplication. Additionally, the venue map lacks the context that is exclusive to the candidate map. Once a new iteration of graph optimization is complete, the venue map is updated in terms of the waypoints, semantic landmarks, Wi-Fi landmarks, and the association relationship between them.
The waypoints on a candidate map that matches the venue map adhere to the Euclidean distance principle [
2] and heading principle, as shown in Equations (23) and (24):
where
represents the position of a waypoint/landmark in a venue map and
denotes the position of a waypoint/landmark in a candidate map.
denotes the threshold of the Euclidean distance and
denotes the heading threshold of a camera. Once a waypoint in a candidate map satisfies Equations (23) and (24), the maturity of the corresponding waypoint on the venue map,
, is incremented by one, and its location is updated according to Equation (25). Otherwise, the unmatched waypoints from the candidate map are added directly to the venue map without modification to their maturity or location.
In Equation (25), and denote the weight factor of the venue and candidate maps, respectively, which are determined by the maturity of waypoints.
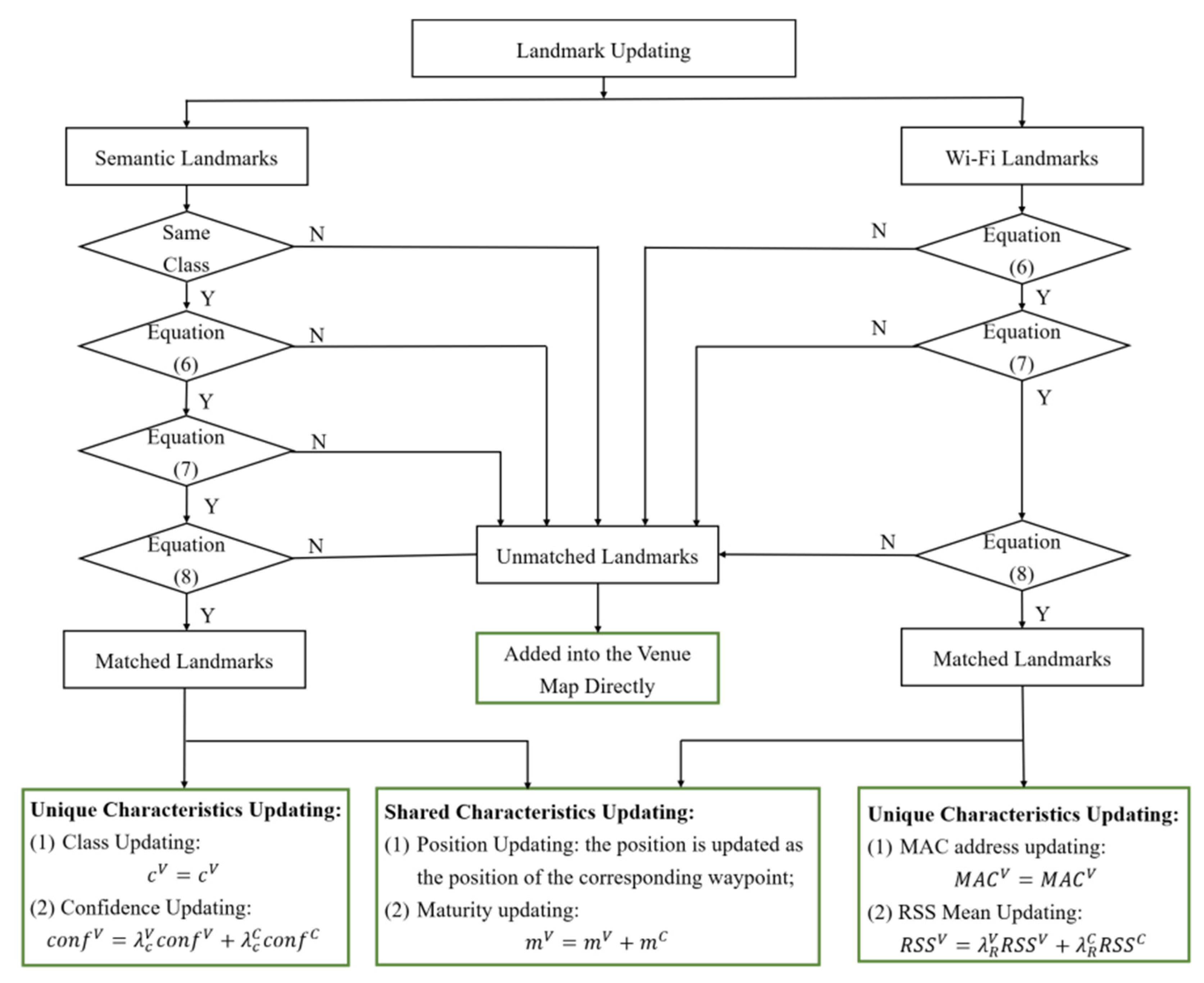
The landmarks on a venue map are updated, as shown in
Figure 5. Similarly, unmatched landmarks from a candidate map are added directly to the venue map with a lower maturity level than landmarks from the previous venue map. Therefore, these landmarks carry less weight in landmark matching-based map construction and localization. The unique and shared characteristics of landmarks that are matched on a venue map are updated. The class of a matched semantic landmark in a venue map
remains unchanged. While its corresponding confidence
is calculated by weighted averaging the original confidence of the venue map
and the candidate map
. The weight factor of the venue and candidate maps are
and
, respectively. Similarly, the RSS mean value of a Wi-Fi landmark on a venue map is updated by weighted averaging the RSS value of the venue map
and the candidate map
. The position of a landmark is updated as the location of the associated waypoint. Particularly, the maturity of a landmark in a venue map
is continuously increased as it is matched with a landmark in a candidate map.
Finally, after updating all of the waypoints and landmarks, the association relationship between the waypoints, semantic landmarks, and Wi-Fi landmarks is updated.
3.6. Localization
Additionally, the updated venue map is utilized for localization. Similar to the preprocessing of crowdsourcing data, a local map is constructed by establishing an association between waypoints, semantic landmarks, and Wi-Fi landmarks. The transformation matrix
between the local and venue maps is estimated in real-time using landmark matching. After transformation, a pedestrian’s location at current time
on the venue map
is calculated as follows [
18]:
where
denotes a pedestrian’s location on a local map.
5. Conclusions and Discussions
This paper proposes a crowdsourcing-based method, which solves the problem of indoor map construction and localization for unknown environments. The method utilizes the smartphones’ built-in sensors, such as cameras, IMUs, and Wi-Fi, so the system’s hardware cost is not increased. Smartphone-collected crowdsourcing data is preprocessed to construct single-track semantic maps. Those maps are evaluated using the proposed map quality evaluation function, and the highest quality one is chosen as the initial venue map. A candidate map having the highest matching degree with the selected venue map is selected for map fusion. After map alignment, the candidate and venue maps are optimized while satisfying the constraints. Inspired by the construction of single-track semantic maps, the optimization graph is constructed using waypoints, semantic landmarks, and Wi-Fi landmarks as nodes and the relevance between waypoints and landmarks as constraints. The venue map is lightweight since it is updated with respect to waypoints, semantic landmarks, Wi-Fi landmarks, and the association between them. In this paper, the construction and update of the venue map are performed using an incremental, iterative approach. A series of experiments are conducted in office building and shopping mall scenes. The results indicate that the venue map constructed using crowdsourcing data covers nearly all passed areas and can filter out incorrectly identified semantics to improve the map accuracy. The constructed venue map can also be used for multi-scene localization, with an average localization error of less than 0.5 m in the office building scene and 1.0 m in the shopping mall scene.
Since the proposed method is based on crowdsourcing, it has a high demand for sensor data. Collecting crowdsourcing data with a single smartphone platform is time-consuming and labor-intensive. Therefore, in the future, we will try multi-platform collaborative mapping methods, such as smartphones, robots, and UAVs. Low-quality single-track semantic maps can significantly reduce the venue map accuracy. Therefore, we will propose an efficient semantic map pre-screening mechanism before map fusion. The proposed optimization graph can be improved by using the constraints between semantic landmarks in a single-track semantic map as an added edge. At the same time, the constraint edge between semantic landmarks can also be utilized for landmark matching-based localization.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}