
Sparse Sliding-Window Kernel Recursive Least-Squares Channel Prediction for Fast Time-Varying MIMO Systems

Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- We propose a novel sparse sliding-window KRLS algorithm. To precisely control the size of samples, we introduce a sample budget as a size restriction. When the dictionary was smaller than the sample budget, we directly added the new sample to the dictionary. Otherwise, we chose the best sample to discard according to our proposed new criterion.
- To differentiate the sample value collected at different times, we introduced a forgetting matrix. By setting different forgetting values for samples collected at different times, we quantified the time value of the samples. The older sample had a smaller forgetting value, which means that its time value was smaller. In this way, we considered both the correlation of samples and the time value when discarding old samples.
- Regarding our new method for discarding old samples, we set a candidate set where we decided which sample to discard. The candidate set was obtained by adding the samples that had larger kernel functions of the new sample than a threshold and were highly correlated with the new sample. Then, we conducted a weighted estimation of the output value of these samples. We decided which sample to discard on the basis of the deviation between its output and the estimated value.
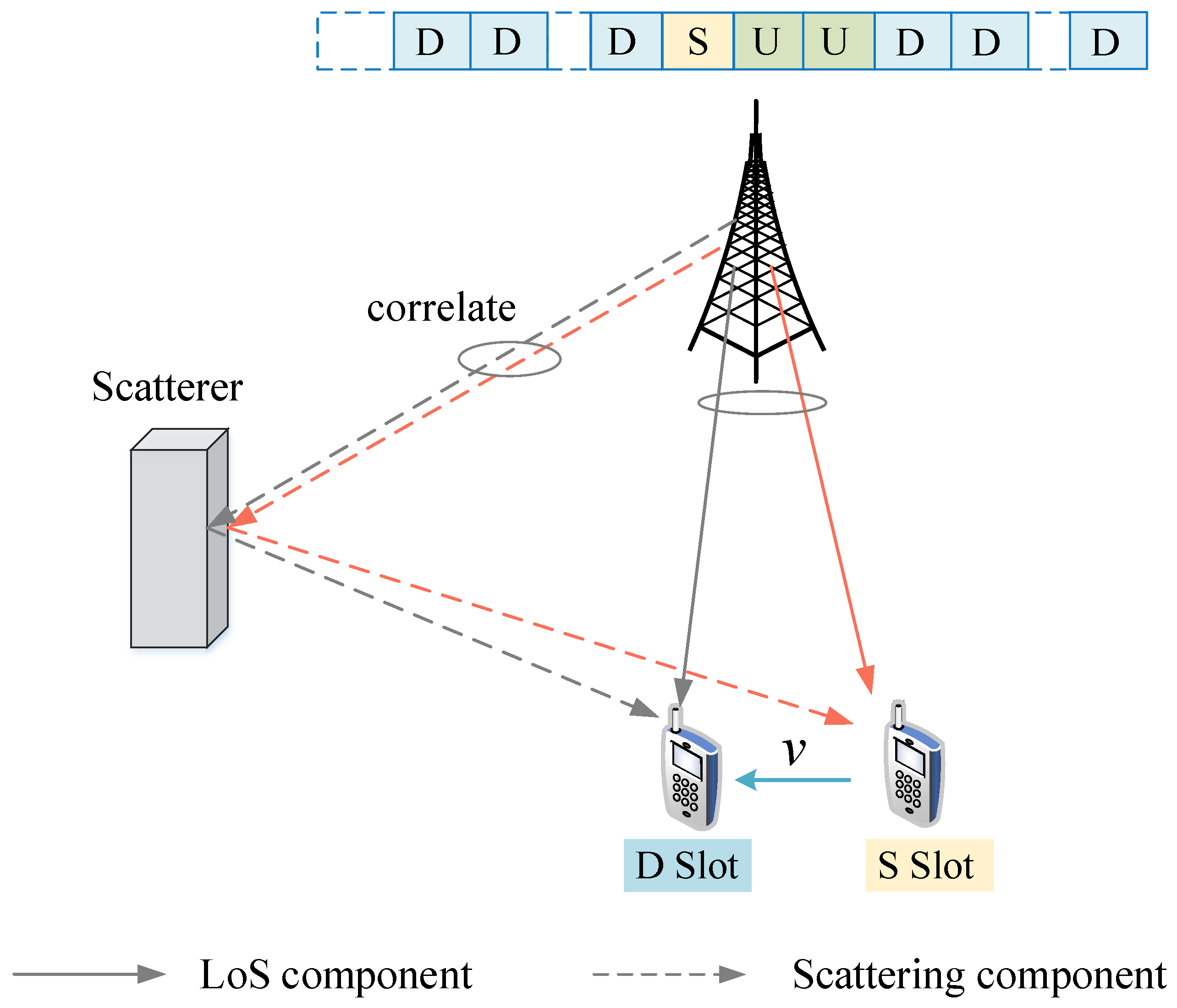
2. System Model
3. Traditional KRLS Algorithm
3.1. Traditional KRLS Algorithm
| Algorithm 1 Traditional KRLS algorithm. |
|
3.2. Extensions to KRLS Algorithm
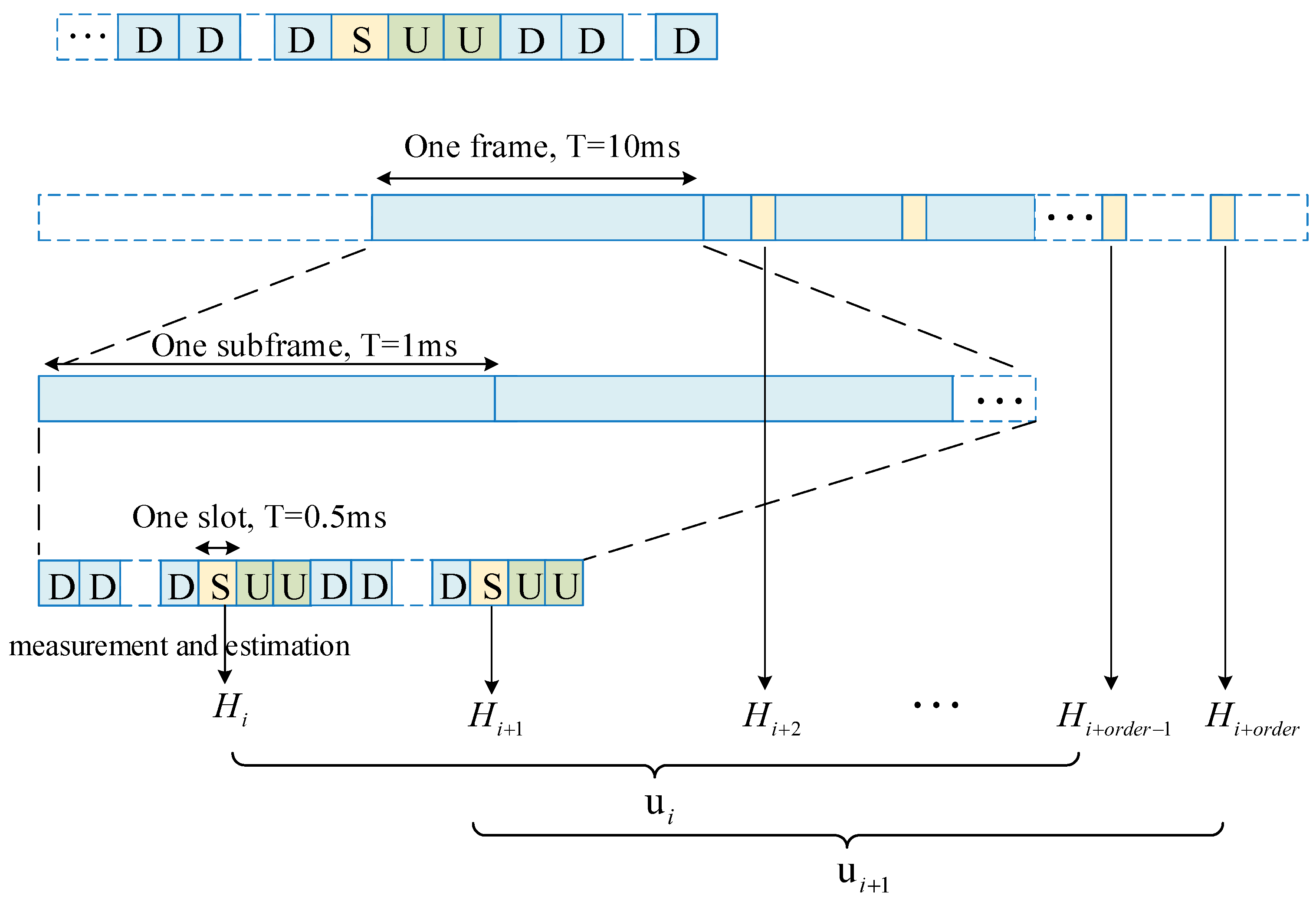
4. Proposed SSW-KRLS Algorithm
4.1. How to Optimally Discard an Old Sample
4.2. Case I: The Size of Is Changed
4.3. Case II: The Size of Is Unchanged
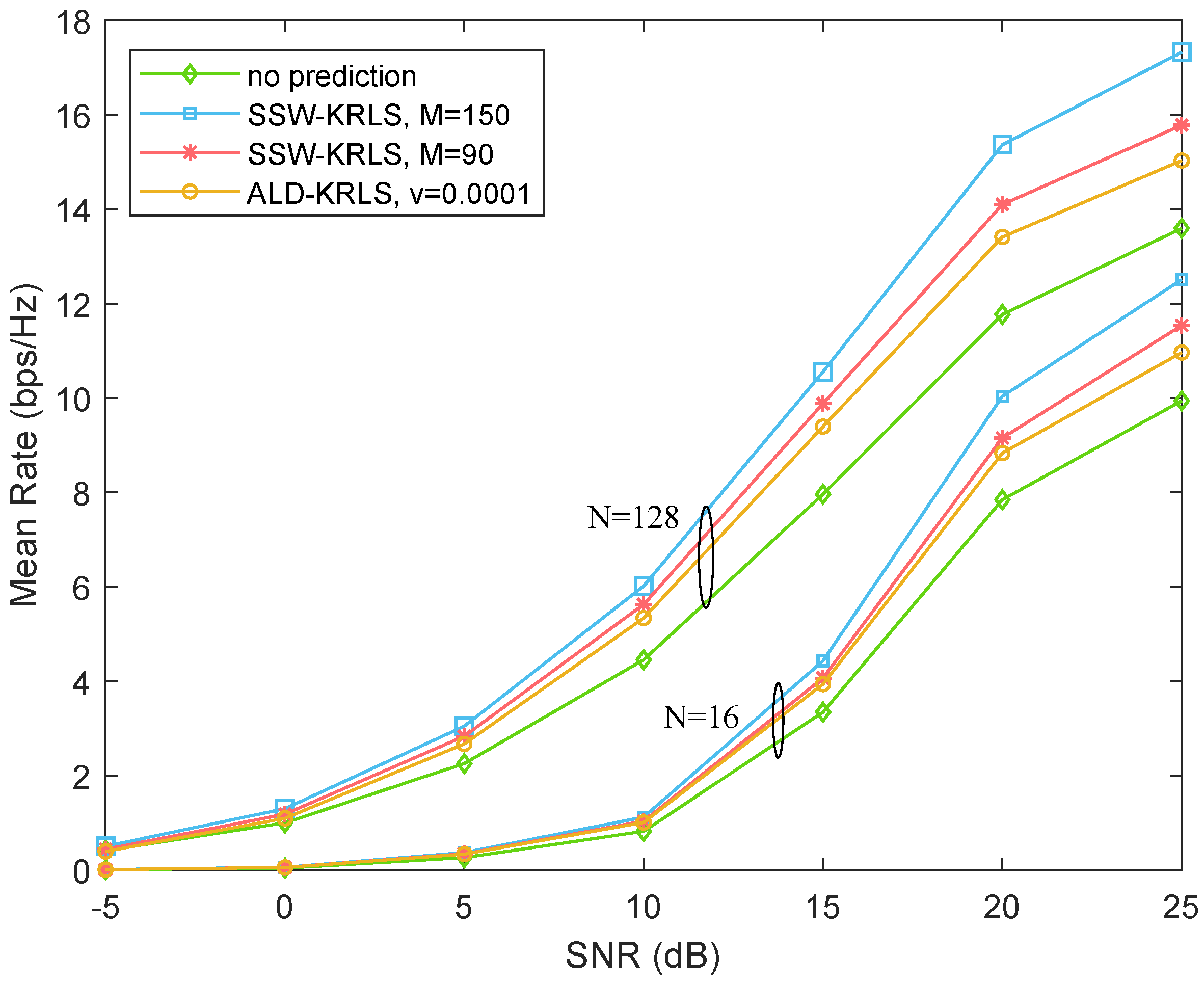
5. Performance Evaluation
| Algorithm 2 Proposed SSW-KRLS algorithm. |
|
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
Appendix B
References
- Li, M.; Collings, I.B.; Hanly, S.V.; Liu, C.; Whiting, P. Multicell Coordinated Scheduling with Multiuser Zero-Forcing Beamforming. IEEE Trans. Wirel. Commun. 2016, 15, 827–842. [Google Scholar] [CrossRef]
- Yin, H.; Wang, H.; Liu, Y.; Gesbert, D. Addressing the Curse of Mobility in Massive MIMO with Prony-Based Angular-Delay Domain Channel Predictions. IEEE J. Sel. Areas Commun. 2020, 38, 2903–2917. [Google Scholar] [CrossRef]
- Li, X.; Jin, S.; Suraweera, H.A.; Hou, J.; Gao, X. Statistical 3-D Beamforming for Large-Scale MIMO Downlink Systems over Rician Fading Channels. IEEE Trans. Commun. 2016, 64, 1529–1543. [Google Scholar] [CrossRef]
- Sapavath, N.N.; Rawat, D.B.; Song, M. Machine Learning for RF Slicing Using CSI Prediction in Software Defined Large-Scale MIMO Wireless Networks. IEEE Trans. Netw. Sci. Eng. 2020, 7, 2137–2144. [Google Scholar] [CrossRef]
- Huang, C.; Liu, L.; Yuen, C.; Sun, S. Iterative Channel Estimation Using LSE and Sparse Message Passing for MmWave MIMO Systems. IEEE Trans. Signal Process. 2019, 67, 245–259. [Google Scholar] [CrossRef]
- Bellili, F.; Sohrabi, F.; Yu, W. Generalized Approximate Message Passing for Massive MIMO mmWave Channel Estimation With Laplacian Prior. IEEE Trans. Commun. 2019, 67, 3205–3219. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, H. Tractable Modelling and Robust Coordinated Beamforming Design with Partially Accurate CSI. IEEE Wirel. Commun. Lett. 2021, 10, 2384–2387. [Google Scholar] [CrossRef]
- Lu, A.; Gao, X.; Xiao, C. Free Deterministic Equivalents for the Analysis of MIMO Multiple Access Channel. IEEE Trans. Inf. Theory 2016, 62, 4604–4629. [Google Scholar] [CrossRef]
- Wu, C.; Yi, X.; Zhu, Y.; Wang, W.; You, L.; Gao, X. Channel Prediction in High-Mobility Massive MIMO: From Spatio-Temporal Autoregression to Deep Learning. IEEE J. Sel. Areas Commun. 2021, 39, 1915–1930. [Google Scholar] [CrossRef]
- Chen, M.; Viberg, M. Long-Range Channel Prediction Based on Nonstationary Parametric Modeling. IEEE Trans. Signal Process. 2009, 57, 622–634. [Google Scholar] [CrossRef]
- Liu, L.; Feng, H.; Yang, T.; Hu, B. MIMO-OFDM Wireless Channel Prediction by Exploiting Spatial-Temporal Correlation. IEEE Trans. Wirel. Commun. 2014, 13, 310–319. [Google Scholar] [CrossRef]
- Lv, C.; Lin, J.-C.; Yang, Z. Channel Prediction for Millimeter Wave MIMO-OFDM Communications in Rapidly Time-Varying Frequency-Selective Fading Channels. IEEE Access 2019, 7, 15183–15195. [Google Scholar] [CrossRef]
- Yuan, J.; Ngo, H.Q.; Matthaiou, M. Machine Learning-Based Channel Prediction in Massive MIMO with Channel Aging. IEEE Trans. Wirel. Commun. 2020, 19, 2960–2973. [Google Scholar] [CrossRef]
- Zhao, J.; Tian, H.; Li, D. Channel Prediction Based on BP Neural Network for Backscatter Communication Networks. Sensors 2020, 20, 300. [Google Scholar] [CrossRef]
- Ahrens, J.; Ahrens, L.; Schotten, H.D. A Machine Learning Method for Prediction of Multipath Channels. ZTE Commun. 2019, 17, 12–18. [Google Scholar]
- Sanchez-Fernandez, M.; de-Prado-Cumplido, M.; Arenas-Garcia, J.; Perez-Cruz, F. SVM multiregression for nonlinear channel estimation in multiple-input multiple-output systems. IEEE Trans. Signal Process. 2004, 52, 2298–2307. [Google Scholar] [CrossRef]
- Engel, Y.; Mannor, S.; Meir, R. The kernel recursive least-squares algorithm. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar] [CrossRef]
- Liu, W.; Park, I.; Wang, Y.; Principe, J.C. Extended Kernel Recursive Least Squares Algorithm. IEEE Trans. Signal Process. 2009, 57, 3801–3814. [Google Scholar]
- Guo, J.; Chen, H.; Chen, S. Improved Kernel Recursive Least Squares Algorithm Based Online Prediction for Nonstationary Time Series. IEEE Signal Process. Lett. 2020, 27, 1365–1369. [Google Scholar] [CrossRef]
- Platt, J. A Resource-Allocating Network for Function Interpolation. Neural Comput. 1991, 3, 213–225. [Google Scholar] [CrossRef]
- Liu, W.; Park, I.; Principe, J.C. An Information Theoretic Approach of Designing Sparse Kernel Adaptive Filters. IEEE Trans. Neural Netw. 2009, 20, 1950–1961. [Google Scholar] [CrossRef] [PubMed]
- Richard, C.; Bermudez, J.C.M.; Honeine, P. Online Prediction of Time Series Data with Kernels. IEEE Trans. Signal Process. 2009, 57, 1058–1067. [Google Scholar] [CrossRef]
- Yang, M.; Ai, B.; He, R.; Huang, C.; Ma, Z.; Zhong, Z.; Wang, J.; Pei, L.; Li, Y.; Li, J. Machine-Learning-Based Fast Angle-of-Arrival Recognition for Vehicular Communications. IEEE Trans. Veh. Technol. 2021, 70, 1592–1605. [Google Scholar] [CrossRef]
- Cherkassky, V.; Mulier, F.M. Statistical Learning Theory. In Learning from Data: Concepts, Theory, and Methods, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Vaerenbergh, S.V.; Lazaro-Gredilla, M.; Santamaria, I. Kernel Recursive Least-Squares Tracker for Time-Varying Regression. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1313–1326. [Google Scholar] [CrossRef]
- Xiong, K.; Wang, S. The Online Random Fourier Features Conjugate Gradient Algorithm. IEEE Signal Process. Lett. 2019, 26, 740–744. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | Indicators | Handling Method |
|---|---|---|
| ALD | Determine whether the kernel function of the new sample can be linearly represented by the kernel function of the existing samples in the dictionary: | If , discard new samples. If , add the new sample to the dictionary. |
| NC | Calculate the minimal distance between the new and existing samples in the kernel dictionary: | If , discard new samples. If , add the new sample to the dictionary. |
| SC | According to information theory, based on prior joint Gaussian distribution, the amount of information brought by the new sample is: , where is posterior probability distribution of | If , add the new sample to the dictionary. If , discard new samples. |
| CC | Calculate the maximal kernel function of the new and existing samples : | If , discard new samples. If , add the new sample to the dictionary. |
| Scenario | 3D Urban Macro (3D UMa) |
|---|---|
| Carrier frequency | 3 kHz |
| Subcarrier spacing | 30 kHz |
| Bandwidth | 20 MHz |
| Channel model | CDL-A |
| Delay spread | 100 ns |
| DL precoder | RZF |
| order | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ai, X.; Zhao, J.; Zhang, H.; Sun, Y. Sparse Sliding-Window Kernel Recursive Least-Squares Channel Prediction for Fast Time-Varying MIMO Systems. Sensors 2022, 22, 6248. https://doi.org/10.3390/s22166248
Ai X, Zhao J, Zhang H, Sun Y. Sparse Sliding-Window Kernel Recursive Least-Squares Channel Prediction for Fast Time-Varying MIMO Systems. Sensors. 2022; 22(16):6248. https://doi.org/10.3390/s22166248
Chicago/Turabian StyleAi, Xingxing, Jiayi Zhao, Hongtao Zhang, and Yong Sun. 2022. "Sparse Sliding-Window Kernel Recursive Least-Squares Channel Prediction for Fast Time-Varying MIMO Systems" Sensors 22, no. 16: 6248. https://doi.org/10.3390/s22166248