
Dual-Branch Discrimination Network Using Multiple Sparse Priors for Image Deblurring


Abstract
:1. Introduction
- We propose a dual-branch GAN, one branch to distinguish the fake and real image with the other to describe the sparsity of the fake and real image for more realistic image deblurring. In the multiple sparse priors discriminator, we build a sparse constrain model which can have the same optimization with the other branch.
- We design a new training strategy by sharing the network architectures and weights in the dual-branch discriminator to solve the convergence inconsistency between the generator and the discriminator. Furthermore, we alternately iterate the two branches of the discriminator to balance the game between the generator and the discriminator.
- We evaluate our proposed method on both synthetic dataset GOPRO and real-world dataset RealBlur. Extensive experiments demonstrate the superiority of the proposed method over the compared state-of-the-art methods.
2. Related Work
2.1. Sparse Prior-Based Image Deblurring
2.2. Deep-Learning-Based Image Deblurring
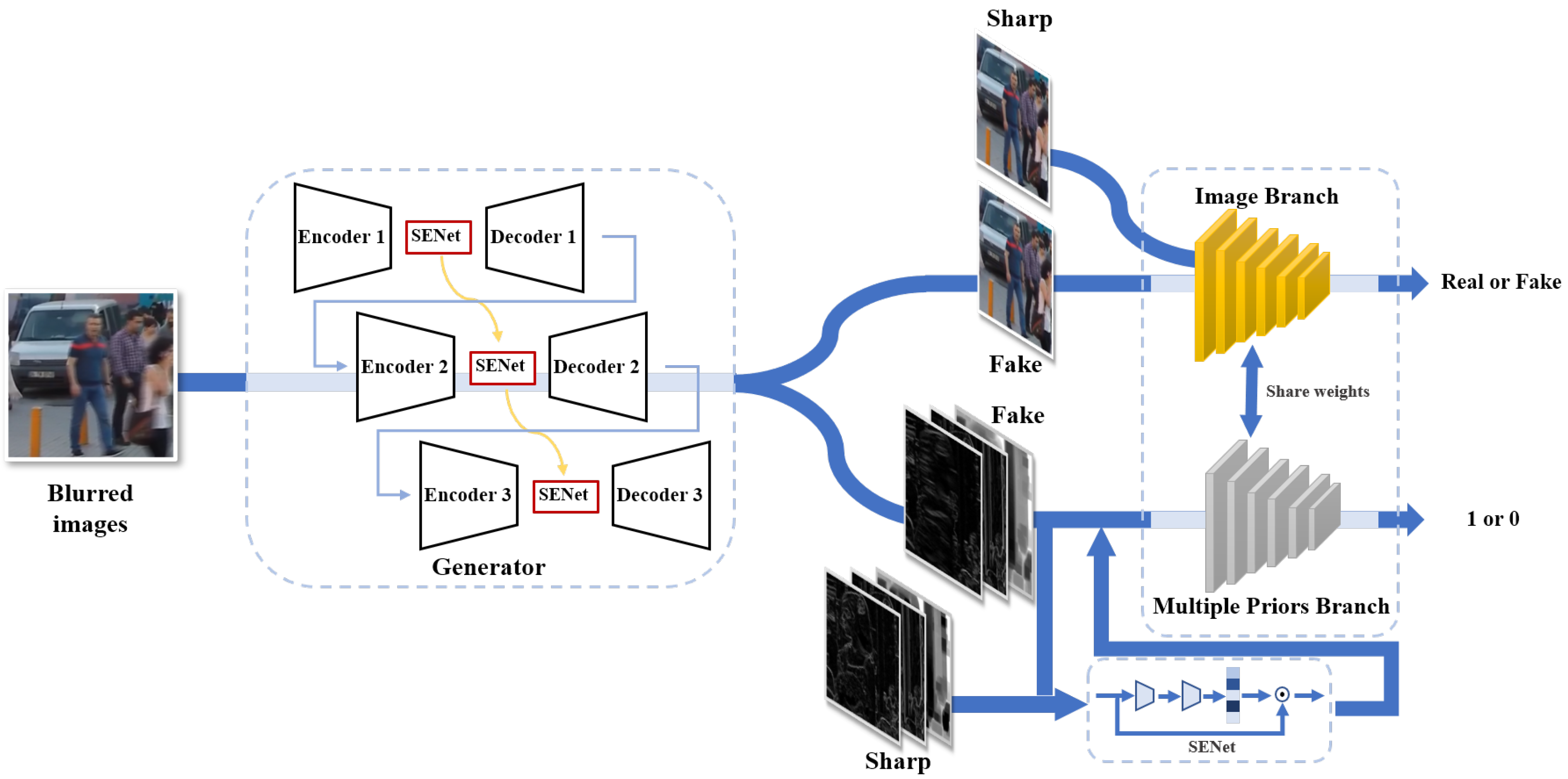
3. Our Approach
3.1. Our Framework
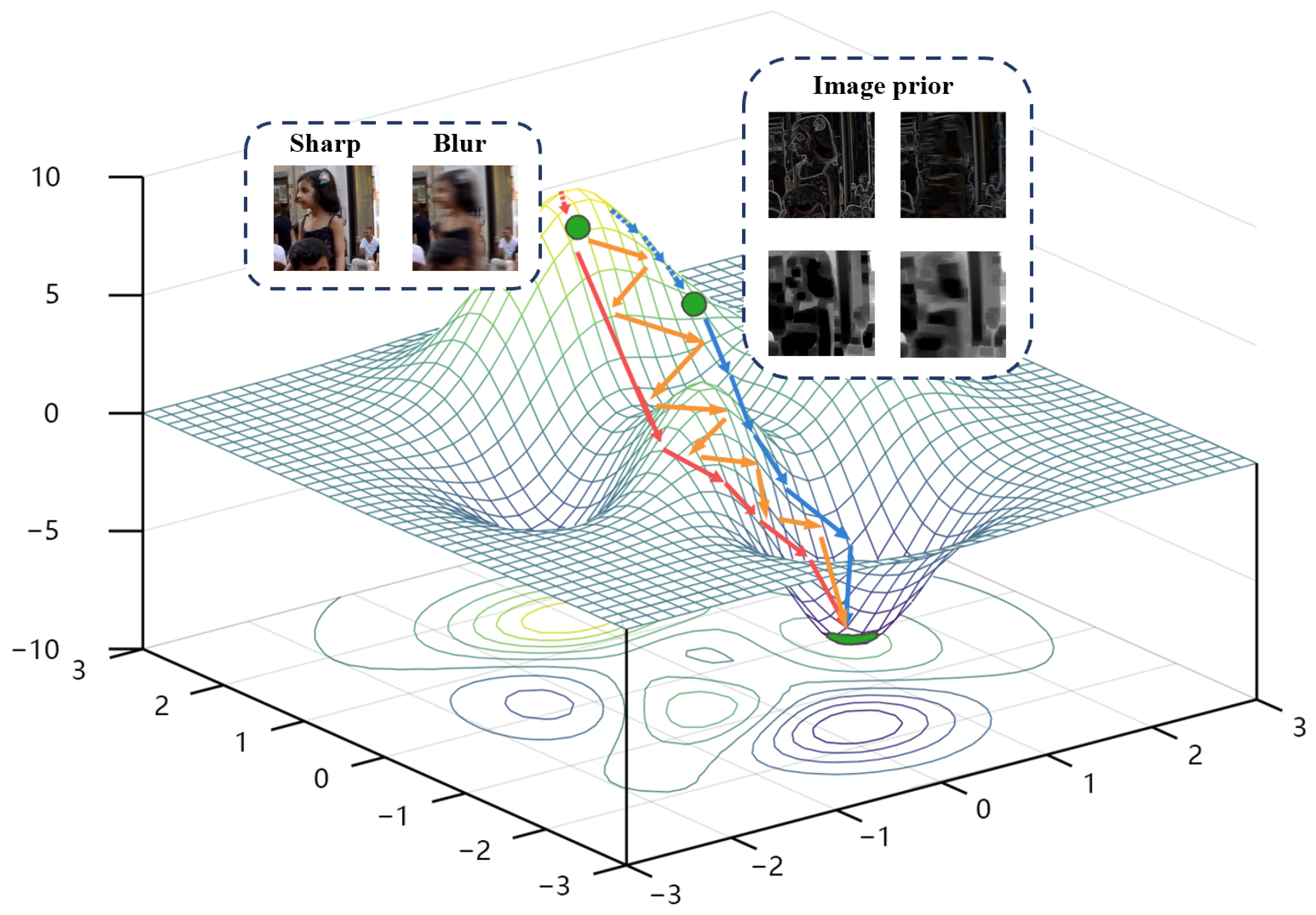
3.2. Dual-Branch Discriminator with Multiple Sparse Priors
3.3. Training Loss and Strategies
- In our dual-branch discriminator, the two branches adopt the same network architectures and share the weights to complicate the discriminator task;
- We alternately optimize the two branches to decrease the discriminator’s convergence rate. Further, we balance the game between the discriminator and the generator.
| Algorithm 1: The training processing of DBSGAN |
| Require: Dataset , , Learnable parameters , . |
|
4. Experimental Evaluation
4.1. Experiment Settings
4.1.1. Datasets
4.1.2. Implementation Details
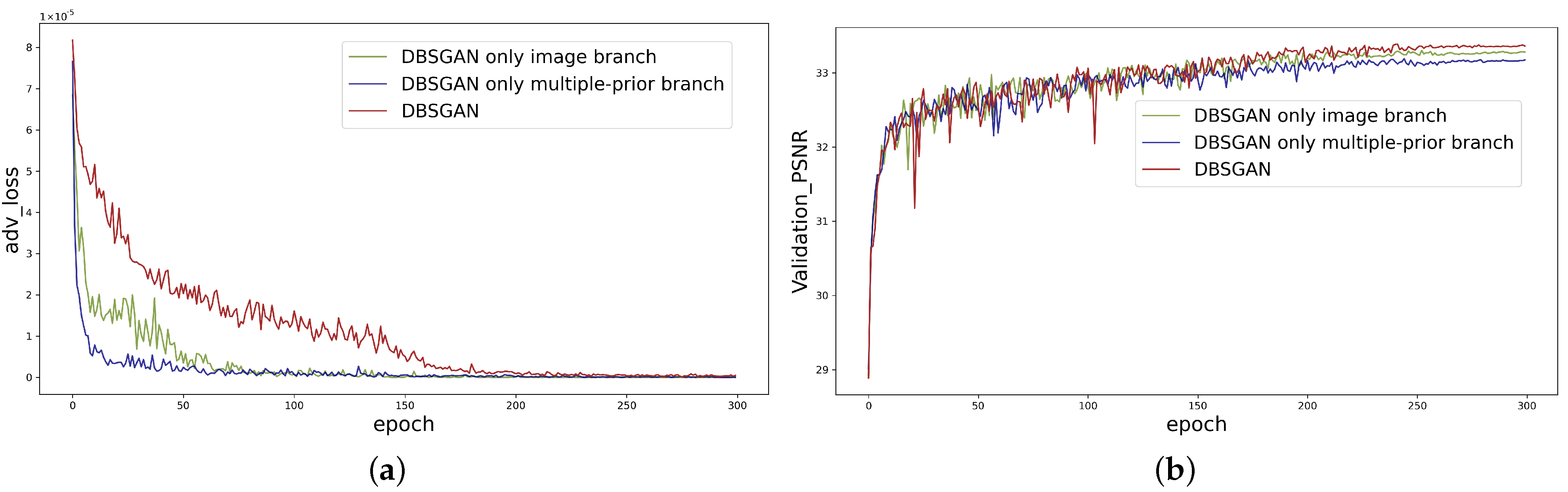
4.2. Ablation Analysis
4.3. Performance on GoPro Dataset
4.4. Performance on RealBlur Dataset
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Fan, D.P.; Cheng, M.M.; Shen, J.; Shao, L. RGB-D salient object detection: A survey. Comput. Vis. Media 2021, 7, 37–69. [Google Scholar] [CrossRef]
- Joseph, K.; Khan, S.; Khan, F.S.; Balasubramanian, V.N. Towards open world object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5830–5840. [Google Scholar]
- Meinhardt, T.; Kirillov, A.; Leal-Taixe, L.; Feichtenhofer, C. Trackformer: Multi-object tracking with transformers. arXiv 2021, arXiv:2101.02702. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Wang, Q.; Zheng, Y.; Pan, P.; Xu, Y. Multiple object tracking with correlation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3876–3886. [Google Scholar]
- Oliveira, J.P.; Bioucas-Dias, J.M.; Figueiredo, M.A. Adaptive total variation image deblurring: A majorization–minimization approach. Signal Process. 2009, 89, 1683–1693. [Google Scholar] [CrossRef]
- Xu, Y.; Hu, X.; Peng, S. Robust image deblurring using hyper Laplacian model. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; pp. 49–60. [Google Scholar]
- Pan, J.; Sun, D.; Pfister, H.; Yang, M.H. Deblurring images via dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2315–2328. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 3883–3891. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 5978–5986. [Google Scholar]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3848–3856. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2737–2746. [Google Scholar]
- Cho, S.; Lee, S. Fast Motion Deblurring. In Proceedings of the 2009 SIGGRAPH Asia Conference, Yokohama, Japan, 16–19 December 2009; Volume 28, pp. 145:1–145:8. [Google Scholar]
- Levin, A.; Weiss, Y.; Durand, F.; Freeman, W.T. Efficient marginal likelihood optimization in blind deconvolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2657–2664. [Google Scholar]
- Krishnan, D.; Tay, T.; Fergus, R. Blind deconvolution using a normalized sparsity measure. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 233–240. [Google Scholar]
- Zhang, H.; Wipf, D.; Zhang, Y. Multi-image blind deblurring using a coupled adaptive sparse prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1051–1058. [Google Scholar]
- Xu, L.; Lu, C.; Xu, Y.; Jia, J. Image smoothing via L0 gradient minimization. In Proceedings of the 2011 SIGGRAPH Asia Conference, Hong Kong, 12–15 December 2011; pp. 174–178. [Google Scholar]
- Perrone, D.; Favaro, P. Total variation blind deconvolution: The devil is in the details. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2909–2916. [Google Scholar]
- Pan, J.; Hu, Z.; Su, Z.; Yang, M.H. l_0-regularized intensity and gradient prior for deblurring text images and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 342–355. [Google Scholar] [CrossRef]
- Chen, L.; Fang, F.; Lei, S.; Li, F.; Zhang, G. Enhanced sparse model for blind deblurring. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 631–646. [Google Scholar]
- Zuo, W.; Ren, D.; Zhang, D.; Gu, S.; Zhang, L. Learning iteration-wise generalized shrinkage—Thresholding operators for blind deconvolution. IEEE Trans. Image Process. 2016, 25, 1751–1764. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Cho, S.; Wang, J.; Hays, J. Edge-based blur kernel estimation using patch priors. In Proceedings of the IEEE International Conference on Computational Photography, Cambridge, MA, USA, 19–21 April 2013; pp. 1–8. [Google Scholar]
- Yan, Y.; Ren, W.; Guo, Y.; Wang, R.; Cao, X. Image deblurring via extreme channels prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 6978–6986. [Google Scholar]
- Bai, Y.; Jia, H.; Jiang, M.; Liu, X.; Xie, X.; Gao, W. Single-image blind deblurring using multi-scale latent structure prior. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 2033–2045. [Google Scholar] [CrossRef]
- Ren, D.; Zhang, K.; Wang, Q.; Hu, Q.; Zuo, W. Neural blind deconvolution using deep priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3341–3350. [Google Scholar]
- Cho, S.J.; Ji, S.W.; Hong, J.P.; Jung, S.W.; Ko, S.J. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4641–4650. [Google Scholar]
- Gong, D.; Yang, J.; Liu, L.; Zhang, Y.; Reid, I.; Shen, C.; Hengel, A.V.D.; Shi, Q. From Motion Blur to Motion Flow: A Deep Learning Solution for Removing Heterogeneous Motion Blur. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Wang, Z.; Cun, X.; Bao, J.; Liu, J. Uformer: A general u-shaped transformer for image restoration. arXiv 2021, arXiv:2106.03106. [Google Scholar]
- Yang, D.; Yamac, M. Motion Aware Double Attention Network for Dynamic Scene Deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LO, USA, 21–24 June 2022; pp. 1113–1123. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Rim, J.; Lee, H.; Won, J.; Cho, S. Real-world blur dataset for learning and benchmarking deblurring algorithms. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 184–201. [Google Scholar]
- Hyun Kim, T.; Ahn, B.; Mu Lee, K. Dynamic scene deblurring. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–9 December 2013; pp. 3160–3167. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generator | ✓ | ✓ | ✓ | ✓ | |
|---|---|---|---|---|---|
| Image Branch | ✓ | ✓ | |||
| Multiple-Prior Branch | ✓ | ✓ | |||
| 1 | PSNR | 30.52 | 30.70 | 30.62 | 30.85 |
| SSIM | 0.938 | 0.939 | 0.938 | 0.942 | |
| 2 | PSNR | 30.43 | 30.64 | 30.55 | 30.77 |
| SSIM | 0.936 | 0.938 | 0.937 | 0.940 | |
| 3 | PSNR | 30.31 | 30.54 | 30.45 | 30.67 |
| SSIM | 0.936 | 0.938 | 0.937 | 0.940 | |
| 4 | PSNR | 30.44 | 30.63 | 30.56 | 30.75 |
| SSIM | 0.937 | 0.939 | 0.938 | 0.941 | |
| 5 | PSNR | 30.71 | 30.91 | 30.84 | 31.04 |
| SSIM | 0.941 | 0.943 | 0.942 | 0.945 | |
| Averaged | PSNR | 30.49 ± 0.1466 | 30.69 ± 0.1421 | 30.61 ± 0.1454 | 30.82 ± 0.1401 |
| SSIM | 0.938 ± 0.0022 | 0.939 ± 0.0020 | 0.938 ± 0.0021 | 0.942 ± 0.0019 | |
| All test data | PSNR | 30.38 | 30.58 | 30.48 | 30.71 |
| SSIM | 0.936 | 0.938 | 0.937 | 0.940 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Cheng, S.; Tao, Y.; Liu, H.; Zhou, J.; Zhang, J. Dual-Branch Discrimination Network Using Multiple Sparse Priors for Image Deblurring. Sensors 2022, 22, 6216. https://doi.org/10.3390/s22166216
Li J, Cheng S, Tao Y, Liu H, Zhou J, Zhang J. Dual-Branch Discrimination Network Using Multiple Sparse Priors for Image Deblurring. Sensors. 2022; 22(16):6216. https://doi.org/10.3390/s22166216
Chicago/Turabian StyleLi, Jialuo, Shichao Cheng, Yueqiang Tao, Huasheng Liu, Junzhe Zhou, and Jianhai Zhang. 2022. "Dual-Branch Discrimination Network Using Multiple Sparse Priors for Image Deblurring" Sensors 22, no. 16: 6216. https://doi.org/10.3390/s22166216