
Multi-Model Running Latency Optimization in an Edge Computing Paradigm



Abstract
:1. Introduction
- (1)
- Running latency. In many cases, the tasks are related and aim to collaboratively reach one goal instead of obtaining high quality in each standalone task. Therefore, one critical question in autonomous systems is how to reduce the overall running latency to meet the safety requirement.
- (2)
- Hardware heterogeneity. The computing devices are heterogeneous, consisting of CPUs, GPUs, FPGAs, and dedicated accelerators [14]. Therefore, the portability of AI models across different platforms is crucial.
- (3)
- AI on embedded edge. The DL model inference requires high memory and computational requirements. Fitting these algorithms onto embedded devices is a challenge in itself.
- (1)
- A real-time tasks scheduling strategy is proposed, in which multi-model tasks can be scheduled using a collaborative decision-making algorithm aiming to reduce the overall running latency without compromising the performance.
- (2)
- A DL model convert solution is proposed that can convert trained models from Tensorflow/Pytorch to ONNX to make an edge device able to concurrently run multiple DL workloads.
- (3)
- To address the heterogeneity of the edge computing system, a concurrent containerization scheme over the ONNX architecture is introduced for application.
2. Related Work
2.1. AI Inference from Cloud to Edge
2.2. The Deployment of AI Model on Embedded System
2.3. Multi-Model Data Fusion
2.4. Optimization of Latency
3. Problem Formulation
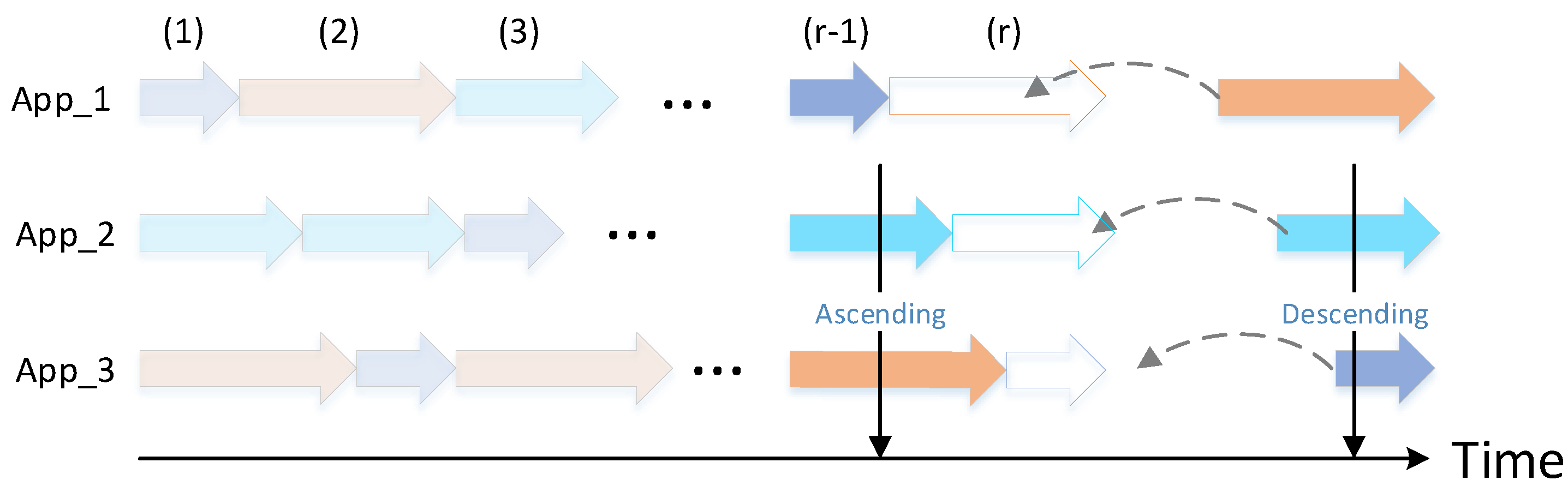
3.1. The Scenario
3.2. Problem Formulation
4. System Design
4.1. Optimal Selection Method
| Algorithm 1 Scheduling strategy 1 |
| Input: Initialization: L, A, |
| Output: Selection of scheduling combination |
| for do |
| end for |
| repeat |
| for do |
| for do |
| Update based on Equation (9) |
| end for |
| Update based on Equation (10) |
| end for |
| Update based on Equation (11) |
| for do |
| Update based on Equation (12) |
| end for |
| until Scheduling finished |
4.2. Simplest Allocation Method
| Algorithm 2 Scheduling strategy 2 |
| Input: Initialization: L, A, |
| Output: Selection of scheduling combination |
| for do |
| end for |
| Update based on Equation (16) |
| repeat |
| Update based on Equation (17) |
| for do |
| end for |
| until Scheduling finished |
4.3. Overall System Description
5. Experiment
5.1. Experimental Setup
5.1.1. Hardware
5.1.2. Software
- (1)
- MobileNet: As a lightweight deep neural network, MobileNet models are very efficient in terms of speed and size and hence are ideal for embedded and mobile applications.
- (2)
- ShuffleNet: An extremely computation-efficient CNN model designed specifically for mobile devices with very limited computing power.
- (3)
- SqueezeNet: SqueezeNet models are highly efficient in terms of size and speed while providing good accuracy. This makes them ideal for platforms with strict constraints on size.
5.1.3. Model Deployment
- (1)
- Model inference is executed based on ONNX Runtime Environment. ONNX Runtime is a cross-platform inference and training machine-learning accelerator, which supports models from various deep learning frameworks and is compatible with different hardware [34].
- (2)
- Containerized app deployment. Each application served for model inference on edge devices is packaged and run as containers. Containerization technology can naturally shield hardware heterogeneity and bring great convenience to deployment and management.
- (3)
- In this experiment, only the CPU is used to perform the model inference task. On the one hand, CPUs are ubiquitous and can be more cost-effective than GPUs for running AI-based tasks on resource-constrained embedded edge devices. On the other hand, we proposed using the ONNX runtime framework for model inference, which uses CPU and can speed up the model inference and result in lower costs, faster response times, and a more portable algorithm.
5.2. Performance Evaluation
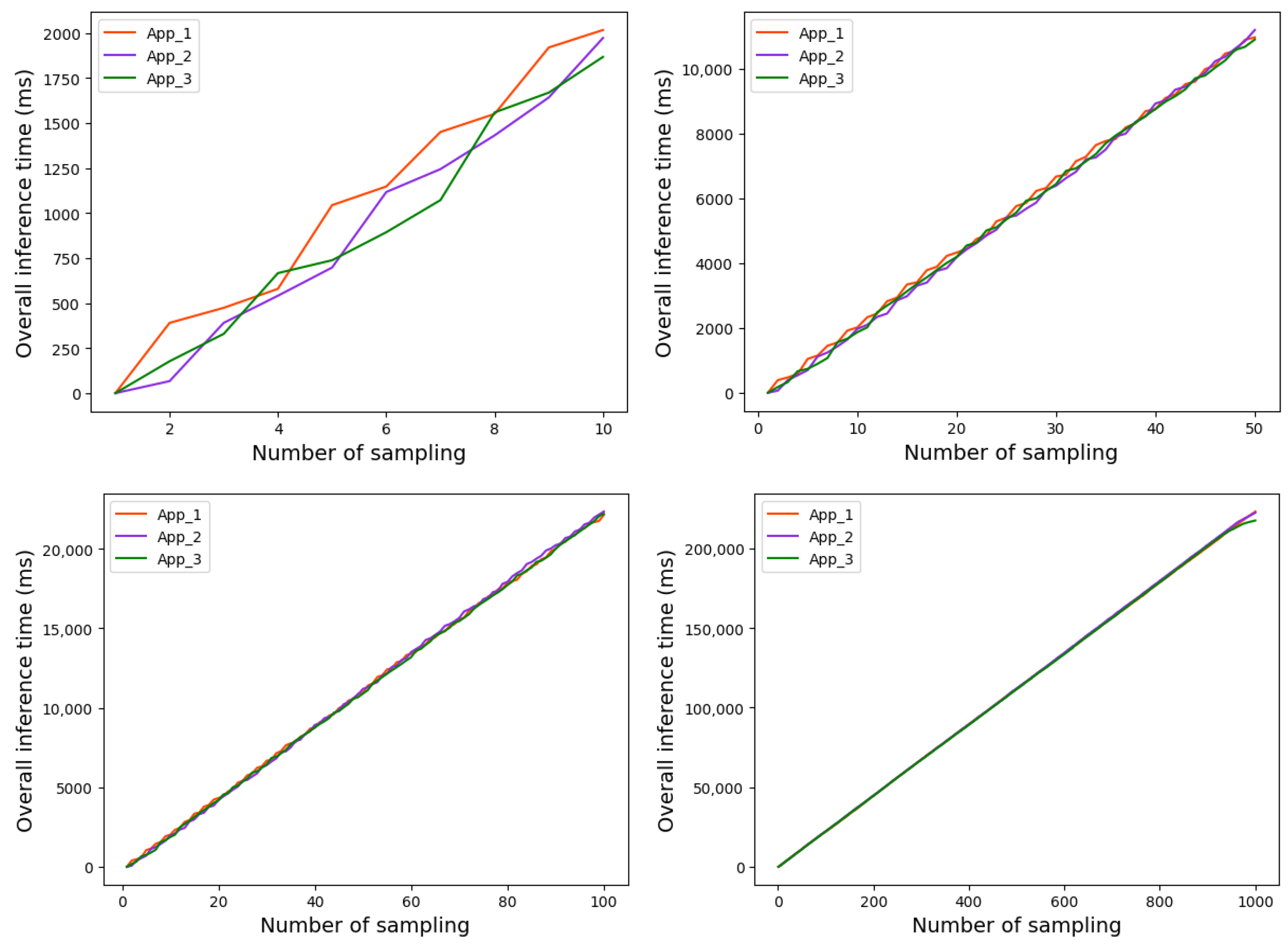
5.2.1. Overall Running Time
5.2.2. Model Inference Time
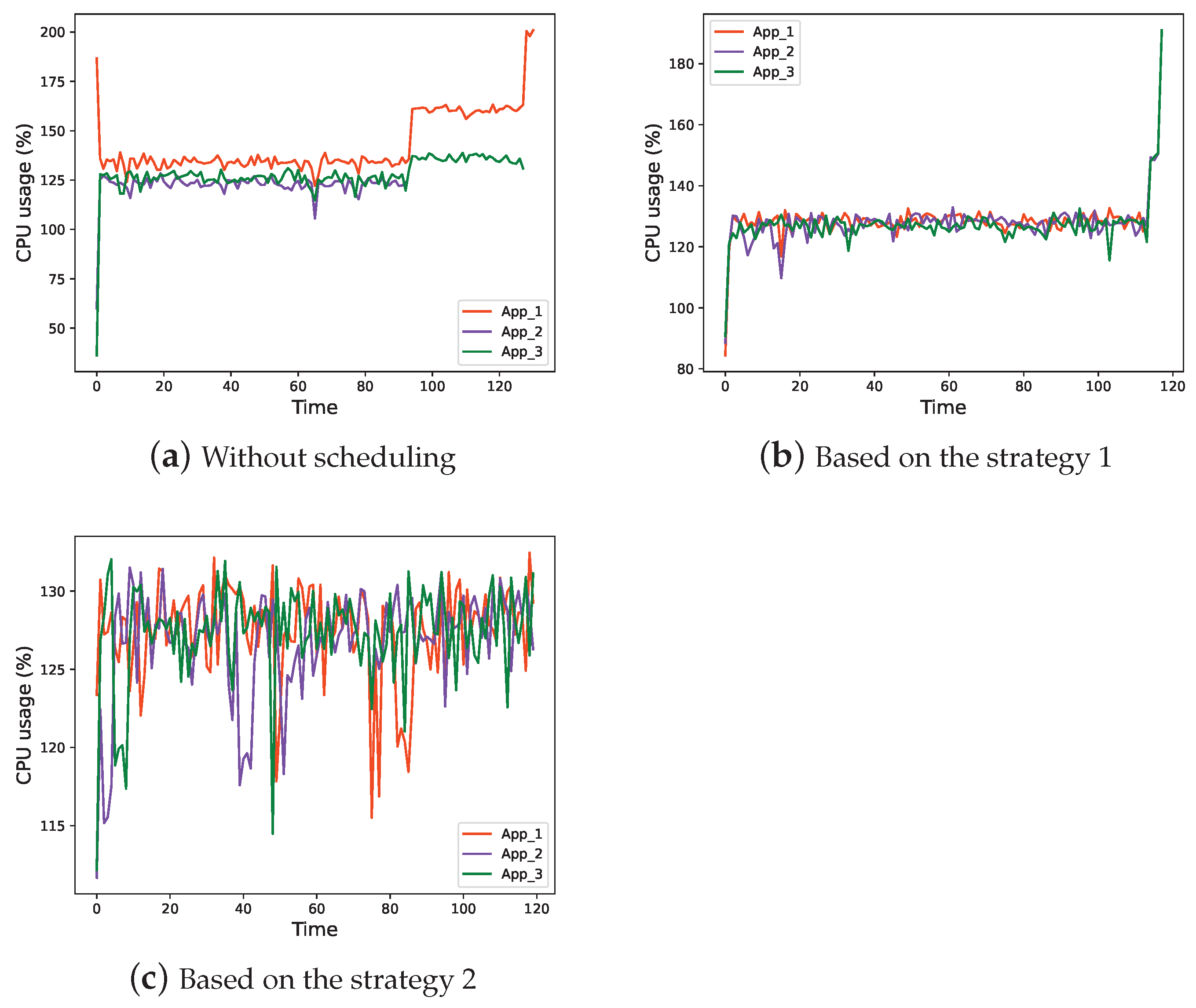
5.2.3. Cpu Usage
5.2.4. Memory Usage
5.2.5. Inference Accuracy
5.2.6. Overhead Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, Q.; Hu, S.; Li, C.; Li, G.; Shi, W. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar] [CrossRef]
- Holler, J.; Tsiatsis, V.; Mulligan, C.; Karnouskos, S.; Avesand, S.; Boyle, D. Internet of Things; Academic Press: Waltham, MA, USA, 2014. [Google Scholar]
- Munir, A.; Blasch, E.; Kwon, J.; Kong, J.; Aved, A. Artificial intelligence and data fusion at the edge. IEEE Aerosp. Electron. Syst. Mag. 2021, 36, 62–78. [Google Scholar] [CrossRef]
- Li, E.; Zeng, L.; Zhou, Z.; Chen, X. Edge AI: On-demand accelerating deep neural network inference via edge computing. IEEE Trans. Wirel. Commun. 2019, 19, 447–457. [Google Scholar] [CrossRef]
- Brandalero, M.; Ali, M.; Le Jeune, L.; Hernandez, H.G.M.; Veleski, M.; da Silva, B.; Lemeire, J.; Van Beeck, K.; Touhafi, A.; Goedemé, T.; et al. AITIA: Embedded AI Techniques for Embedded Industrial Applications. In Proceedings of the International Conference on Omni-layer Intelligent Systems (COINS), Barcelona, Spain, 23–25 August 2020; pp. 1–7. [Google Scholar]
- Sleight, M. How Do Self-Driving Cars Work? Available online: https://www.bankrate.com/insurance/car/how-do-self-driving-cars-work/ (accessed on 22 June 2021).
- Gupta, A. Machine Learning Algorithms in Autonomous Driving. Available online: https://www.iiot-world.com/artificial-intelligence-ml/machine-learning/machine-learning-algorithms-in-autonomous-driving/ (accessed on 4 April 2021).
- Zhou, S.; Xie, M.; Jin, Y.; Miao, F.; Ding, C. An End-to-end Multi-task Object Detection using Embedded GPU in Autonomous Driving. In Proceedings of the 22nd International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 7–8 April 2021; pp. 122–128. [Google Scholar]
- Liu, L.; Lu, S.; Zhong, R.; Wu, B.; Yao, Y.; Zhang, Q.; Shi, W. Computing Systems for Autonomous Driving: State of the Art and Challenges. IEEE Internet Things J. 2020, 8, 6469–6486. [Google Scholar] [CrossRef]
- Collin, A.; Siddiqi, A.; Imanishi, Y.; Rebentisch, E.; Tanimichi, T.; de Weck, O.L. Autonomous driving systems hardware and software architecture exploration: Optimizing latency and cost under safety constraints. Syst. Eng. 2020, 23, 327–337. [Google Scholar] [CrossRef]
- Dong, Z.; Shi, W.; Tong, G.; Yang, K. Collaborative autonomous driving: Vision and challenges. In Proceedings of the International Conference on Connected and Autonomous Driving (MetroCAD), Detroit, MI, USA, 27–28 February 2020; pp. 17–26. [Google Scholar]
- Verucchi, M.; Brilli, G.; Sapienza, D.; Verasani, M.; Arena, M.; Gatti, F.; Capotondi, A.; Cavicchioli, R.; Bertogna, M.; Solieri, M. A systematic assessment of embedded neural networks for object detection. In Proceedings of the 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 937–944. [Google Scholar]
- Lin, C.; Zhang, Z.; Li, H.; Liu, J. ECSRL: A Learning-Based Scheduling Framework for AI Workloads in Heterogeneous Edge-Cloud Systems. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra, Portugal, 15–17 November 2021; pp. 386–387. [Google Scholar]
- Hao, C.; Chen, D. Software/Hardware Co-design for Multi-modal Multi-task Learning in Autonomous Systems. In Proceedings of the IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–5. [Google Scholar]
- Wang, X.; Han, Y.; Leung, V.C.; Niyato, D.; Yan, X.; Chen, X. Edge AI: Convergence of Edge Computing and Artificial Intelligence; Springer Nature: Singapore, 2020. [Google Scholar]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Calo, S.B.; Touna, M.; Verma, D.C.; Cullen, A. Edge computing architecture for applying AI to IoT. In Proceedings of the IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 3012–3016. [Google Scholar]
- Campolo, C.; Genovese, G.; Iera, A.; Molinaro, A. Virtualizing AI at the distributed edge towards intelligent IoT applications. J. Sens. Actuator Netw. 2021, 10, 13. [Google Scholar] [CrossRef]
- Chen, J.; Li, K.; Deng, Q.; Li, K.; Philip, S.Y. Distributed deep learning model for intelligent video surveillance systems with edge computing. IEEE Trans. Ind. Inform. 2019. [Google Scholar] [CrossRef]
- Gong, C.; Lin, F.; Gong, X.; Lu, Y. Intelligent cooperative edge computing in internet of things. IEEE Internet Things J. 2020, 7, 9372–9382. [Google Scholar] [CrossRef]
- Bi, J. Improving Training and Inference for Embedded Machine Learning. Ph.D. Thesis, University of Southampton, Southampton, UK, 2020. [Google Scholar]
- Wu, R.T.; Singla, A.; Jahanshahi, M.R.; Bertino, E.; Ko, B.J.; Verma, D. Pruning deep convolutional neural networks for efficient edge computing in condition assessment of infrastructures. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 774–789. [Google Scholar] [CrossRef]
- Tonellotto, N.; Gotta, A.; Nardini, F.M.; Gadler, D.; Silvestri, F. Neural network quantization in federated learning at the edge. Inf. Sci. 2021, 575, 417–436. [Google Scholar] [CrossRef]
- Minakova, S.; Tang, E.; Stefanov, T. Combining task-and data-level parallelism for high-throughput cnn inference on embedded cpus-gpus mpsocs. In Proceedings of the International Conference on Embedded Computer Systems, Samos, Greece, 5–9 July 2020; Springer: Cham, Switzerland, 2020; pp. 18–35. [Google Scholar]
- Dey, S.; Mukherjee, A.; Pal, A. Embedded Deep Inference in Practice: Case for Model Partitioning. In Proceedings of the 1st Workshop on Machine Learning on Edge in Sensor Systems, 2019, New York, NY, USA, 10 November 2019; pp. 25–30. [Google Scholar]
- Verma, G.; Gupta, Y.; Malik, A.M.; Chapman, B. Performance evaluation of deep learning compilers for edge inference. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 858–865. [Google Scholar]
- Hao, C.; Sarwari, A.; Jin, Z.; Abu-Haimed, H.; Sew, D.; Li, Y.; Liu, X.; Wu, B.; Fu, D.; Gu, J.; et al. A hybrid GPU+ FPGA system design for autonomous driving cars. In Proceedings of the IEEE International Workshop on Signal Processing Systems (SiPS), Nanjing, China, 20–23 October 2019; pp. 121–126. [Google Scholar]
- Mujica, G.; Rodriguez-Zurrunero, R.; Wilby, M.R.; Portilla, J.; Rodríguez González, A.B.; Araujo, A.; Riesgo, T.; Vinagre Diaz, J.J. Edge and fog computing platform for data fusion of complex heterogeneous sensors. Sensors 2018, 18, 3630. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Tian, D.; Duan, X.; Zhou, J.; Lang, P.; Lin, C.; You, X. A Camera–Radar Fusion Method Based on Edge Computing. In Proceedings of the IEEE International Conference on Edge Computing (EDGE), Beijing, China, 19–23 October 2020; pp. 9–14. [Google Scholar]
- Fadadu, S.; Pandey, S.; Hegde, D.; Shi, Y.; Chou, F.C.; Djuric, N.; Vallespi-Gonzalez, C. Multi-view fusion of sensor data for improved perception and prediction in autonomous driving. arXiv 2020, arXiv:2008.11901. [Google Scholar]
- Mendez, J.; Molina, M.; Rodriguez, N.; Cuellar, M.P.; Morales, D.P. Camera-LiDAR Multi-Level Sensor Fusion for Target Detection at the Network Edge. Sensors 2021, 21, 3992. [Google Scholar] [CrossRef]
- Warakagoda, N.; Dirdal, J.; Faxvaag, E. Fusion of lidar and camera images in end-to-end deep learning for steering an off-road unmanned ground vehicle. In Proceedings of the 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Yang, M.; Wang, S.; Bakita, J.; Vu, T.; Smith, F.D.; Anderson, J.H.; Frahm, J.M. Re-thinking CNN frameworks for time-sensitive autonomous-driving applications: Addressing an industrial challenge. In Proceedings of the IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Montreal, QC, Canada, 16–18 April 2019; pp. 305–317. [Google Scholar]
- Microsoft. ONNX Runtime. Available online: https://microsoft.github.io/onnxruntime/ (accessed on 21 July 2022).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technical Specifications | |
|---|---|
| GPU | 128-core NVIDIA Maxwell |
| CPU | Quad-core ARM A57 @ 1.43 GHz |
| Memory | 2 GB 64-bit LPDDR4 25.6 GB/s |
| Storage | 64 GB |
| Model | Size | Top-1 Accuracy (%) | Top-5 Accuracy (%) |
|---|---|---|---|
| MobileNet | 13.6 MB | 70.94 | 89.99 |
| ShuffleNet | 9.2 MB | 69.36 | 88.32 |
| SqueezeNet | 9 MB | 56.34 | 79.12 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Wang, X.; Huang, K.; Huang, Y.; Li, S.; Iqbal, M. Multi-Model Running Latency Optimization in an Edge Computing Paradigm. Sensors 2022, 22, 6097. https://doi.org/10.3390/s22166097
Li P, Wang X, Huang K, Huang Y, Li S, Iqbal M. Multi-Model Running Latency Optimization in an Edge Computing Paradigm. Sensors. 2022; 22(16):6097. https://doi.org/10.3390/s22166097
Chicago/Turabian StyleLi, Peisong, Xinheng Wang, Kaizhu Huang, Yi Huang, Shancang Li, and Muddesar Iqbal. 2022. "Multi-Model Running Latency Optimization in an Edge Computing Paradigm" Sensors 22, no. 16: 6097. https://doi.org/10.3390/s22166097