
Motor Imagery Analysis from Extensive EEG Data Representations Using Convolutional Neural Networks


Abstract
:1. Introduction
- Novel EEG signal transformations to account for spatial distributions of electrode placements.
- Novel DL models that were explicitly designed to address the strengths of each of the different EEG data representations, with results that exceed those presented previously in the state of the art.
2. Materials and Methods
2.1. Dataset Description and Preparation
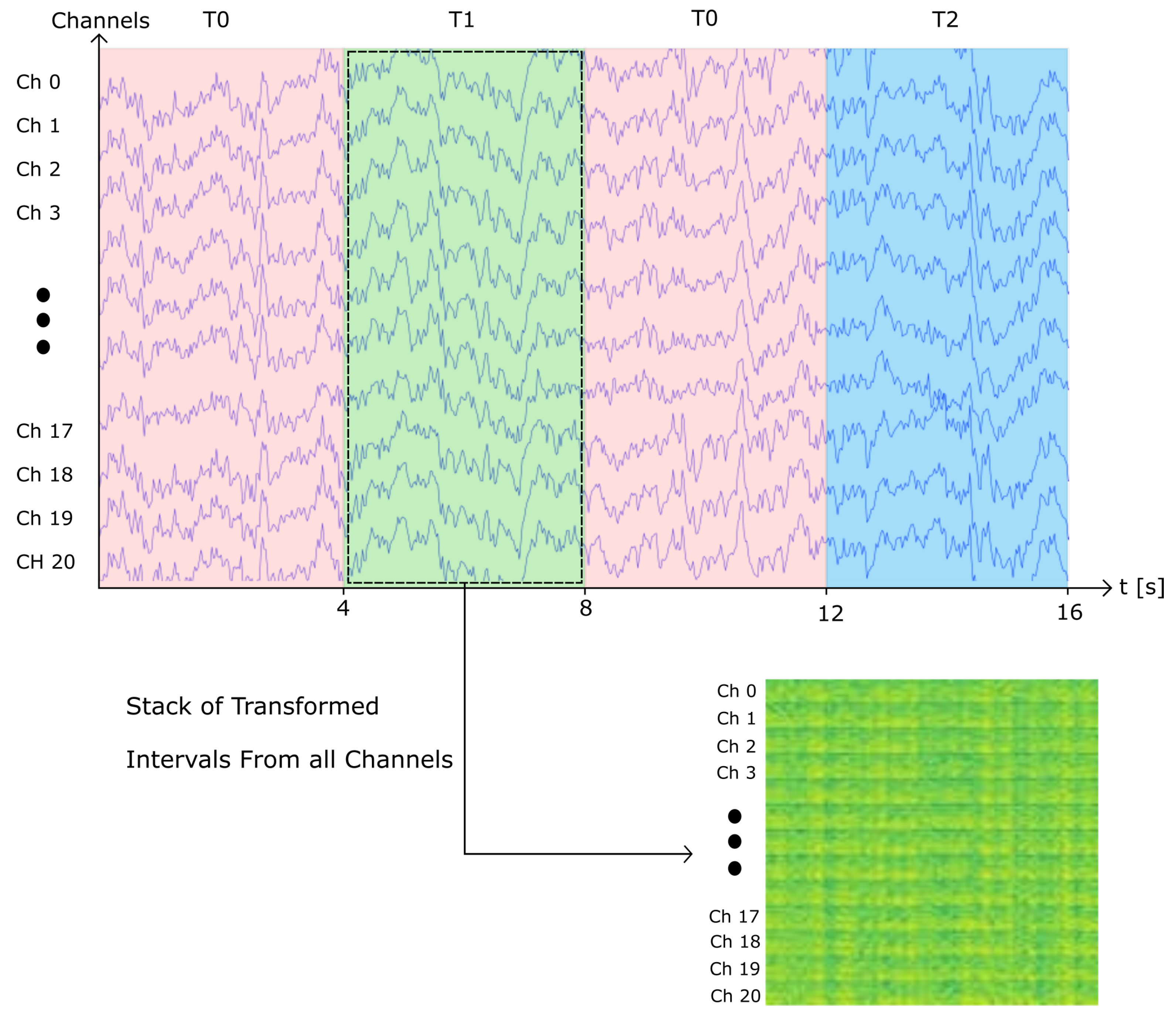
2.2. Spectrogram Image
2.2.1. Single EEG Channel Spectrogram Images
2.2.2. Vertically Stacked Spectrograms
2.2.3. 21-Channel Vertically Stacked Spectrogram
2.2.4. 13-Channel Vertically Stacked Spectrograms
2.2.5. 9-Channel Vertically Stacked Spectrograms
2.2.6. 5-Channel Vertically Stacked Spectrograms
2.3. Raw EEG Signal Data Preparation
2.3.1. 64-Channel Raw EEG Signal Data
2.3.2. 21-Channel Raw EEG Signal Data
2.3.3. 21-Channel Raw EEG Signal: Volume Representation
2.3.4. 13-Channel Raw EEG Signal Data
2.3.5. 13-Channel Raw EEG Signal Data: Volume Representation
2.3.6. 9-Channel Raw EEG Signal Data
2.3.7. 9-Channel Raw EEG Signal Data: Volume Representation
2.3.8. 5-Channel Raw EEG Signal Data
2.3.9. 5-Channel Raw EEG Signal Data: Volume Representation
2.3.10. Single-Channel Array of Raw EEG Signal
2.4. 2D CNN Models
2.4.1. Single-Layer 2D-CNN
2.4.2. Two-Layered 2D-CNN
2.4.3. Three-Layered 2D-CNN
2.4.4. Transfer Learning
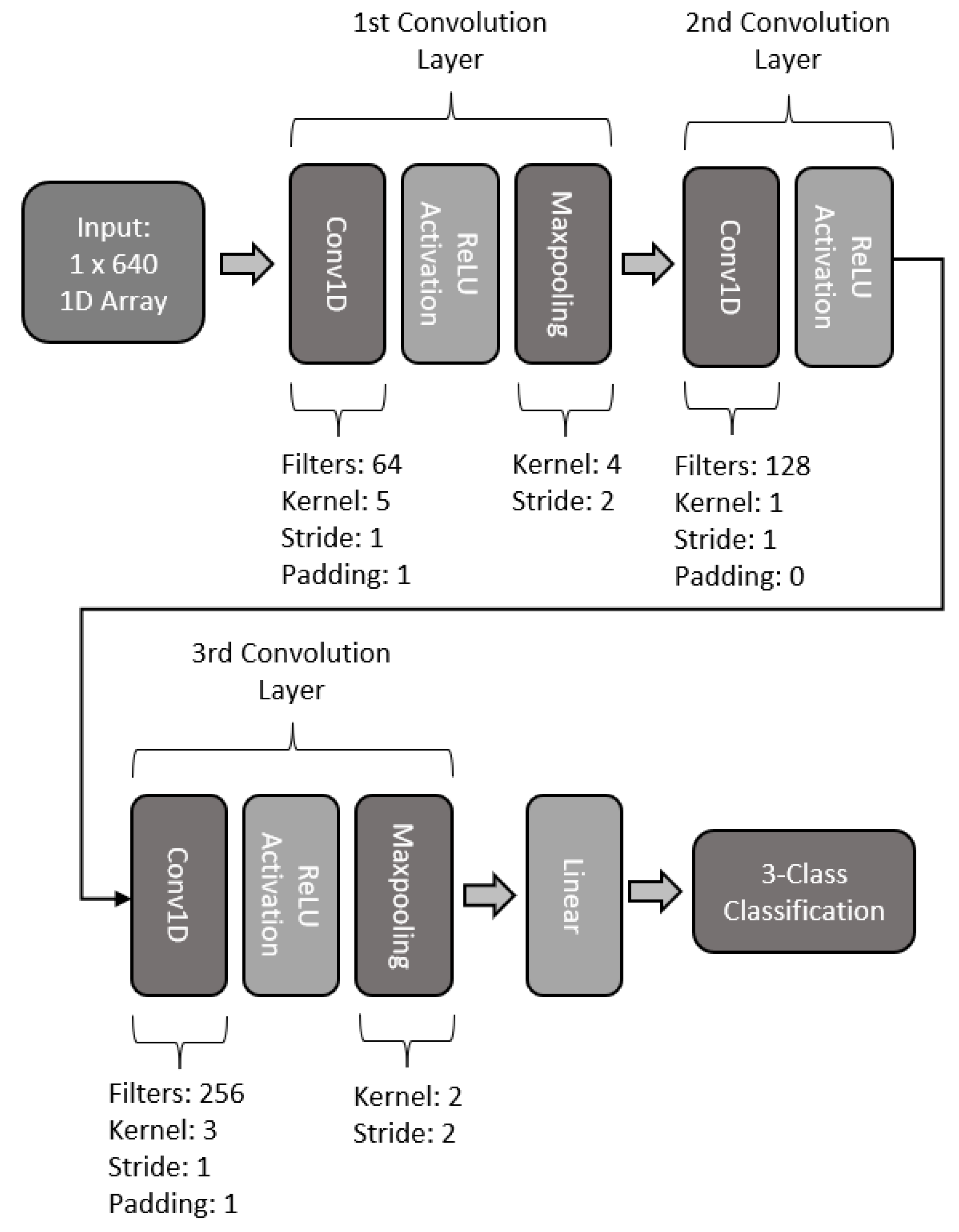
2.5. 1D CNN Models
2.5.1. 1D-CNN
2.5.2. Two-Layered 1D-CNN
2.5.3. Three-Layered 1D-CNN
2.5.4. Four-Layered 1D-CNN
2.5.5. Five-Layered 1D-CNN
2.6. Hardware and Software
3. Results and Discussion
3.1. Results: Image-Based Experiments
3.2. Results: 2D Matrix Raw EEG Signal
3.3. Results: 3D Matrix Raw EEG Signal
3.4. Results: 1D Raw Signal
4. Conclusions
- Extensive experimentation with different EEG representation modalities using single-channel spectrograms, 3D raw EEG signal, and 1D raw EEG signal analysis.
- Novel deep learning algorithms are designed specifically for each of the data representation modalities.
- Analysis of the selection of distinct EEG channels for optimal MI representation.
5. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Miao, Y.; Chen, S.; Zhang, X.; Jin, J.; Xu, R.; Daly, I.; Jia, J.; Wang, X.; Cichocki, A.; Jung, T.P. BCI-based rehabilitation on the stroke in sequela stage. Neural Plast. 2020, 2020, 8882764. [Google Scholar] [CrossRef]
- Burgold, J.; Schulz-Trieglaff, E.K.; Voelkl, K.; Gutiérrez-Ángel, S.; Bader, J.M.; Hosp, F.; Mann, M.; Arzberger, T.; Klein, R.; Liebscher, S.; et al. Cortical circuit alterations precede motor impairments in Huntington’s disease mice. Sci. Rep. 2019, 9, 6634. [Google Scholar] [CrossRef] [PubMed]
- Saha, S.; Baumert, M. Intra-and inter-subject variability in EEG-based sensorimotor brain computer interface: A review. Front. Comput. Neurosci. 2020, 13, 87. [Google Scholar] [CrossRef] [PubMed]
- Byrne, J.H.; Heidelberger, R.; Waxham, M.N. From Molecules to Networks: An Introduction to Cellular and Molecular Neuroscience; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Gao, Z.; Dang, W.; Wang, X.; Hong, X.; Hou, L.; Ma, K.; Perc, M. Complex networks and deep learning for EEG signal analysis. Cogn. Neurodynamics 2021, 15, 369–388. [Google Scholar] [CrossRef] [PubMed]
- Craik, A.; He, Y.; Contreras-Vidal, J.L. Deep Learning for electroencephalogram (EEG) classification tasks: A review. J. Neural Eng. 2019, 16, 031001. [Google Scholar] [CrossRef] [PubMed]
- Foong, R.; Ang, K.K.; Quek, C.; Guan, C.; Phua, K.S.; Kuah, C.W.K.; Deshmukh, V.A.; Yam, L.H.L.; Rajeswaran, D.K.; Tang, N.; et al. Assessment of the efficacy of EEG-based MI-BCI with visual feedback and EEG correlates of mental fatigue for upper-limb stroke rehabilitation. IEEE Trans. Biomed. Eng. 2019, 67, 786–795. [Google Scholar] [CrossRef] [PubMed]
- Pfurtscheller, G.; Neuper, C. Motor imagery and direct Brain-Computer communication. Proc. IEEE 2001, 89, 1123–1134. [Google Scholar] [CrossRef]
- Singh, A.; Hussain, A.A.; Lal, S.; Guesgen, H.W. A comprehensive review on critical issues and possible solutions of motor imagery based electroencephalography brain-computer interface. Sensors 2021, 21, 2173. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Luo, J.; Guo, Y.; Du, Q.; Cheng, Q.; Wang, H. Changes in EEG brain connectivity caused by short-term bci neurofeedback-rehabilitation training: A case study. Front. Hum. Neurosci. 2021, 15, 345. [Google Scholar] [CrossRef]
- Li, G.; Lee, C.H.; Jung, J.J.; Youn, Y.C.; Camacho, D. Deep learning for EEG data analytics: A survey. Concurr. Comput. Pract. Exp. 2020, 32, e5199. [Google Scholar] [CrossRef]
- Yang, J.; Gao, S.; Shen, T. A Two-Branch CNN Fusing Temporal and Frequency Features for Motor Imagery EEG Decoding. Entropy 2022, 24, 376. [Google Scholar] [CrossRef]
- Torres, E.P.; Torres, E.A.; Hernández-Álvarez, M.; Yoo, S.G. EEG-based BCI emotion recognition: A survey. Sensors 2020, 20, 5083. [Google Scholar] [CrossRef] [PubMed]
- Khan, H.; Naseer, N.; Yazidi, A.; Eide, P.K.; Hassan, H.W.; Mirtaheri, P. Analysis of human gait using hybrid EEG-fNIRS-based BCI system: A review. Front. Hum. Neurosci. 2021, 14, 613254. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef] [PubMed]
- Ha, K.W.; Jeong, J.W. Motor imagery EEG classification using capsule networks. Sensors 2019, 19, 2854. [Google Scholar] [CrossRef]
- Bressan, G.; Cisotto, G.; Müller-Putz, G.R.; Wriessnegger, S.C. Deep learning-based classification of fine hand movements from low frequency EEG. Future Internet 2021, 13, 103. [Google Scholar] [CrossRef]
- Rim, B.; Sung, N.J.; Min, S.; Hong, M. Deep Learning in Physiological Signal Data: A Survey. Sensors 2020, 20, 969. [Google Scholar] [CrossRef]
- Dantas, H.; Warren, D.J.; Wendelken, S.M.; Davis, T.S.; Clark, G.A.; Mathews, V.J. Deep Learning Movement Intent Decoders Trained With Dataset Aggregation for Prosthetic Limb Control. IEEE Trans. Biomed. Eng. 2019, 66, 3192–3203. [Google Scholar] [CrossRef]
- He, Z.; Zhang, X.; Cao, Y.; Liu, Z.; Zhang, B.; Wang, X. LiteNet: Lightweight Neural Network for Detecting Arrhythmias at Resource-Constrained Mobile Devices. Sensors 2018, 18, 1229. [Google Scholar] [CrossRef]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2021, 1–42. [Google Scholar] [CrossRef]
- Tayeb, Z.; Fedjaev, J.; Ghaboosi, N.; Richter, C.; Everding, L.; Qu, X.; Wu, Y.; Cheng, G.; Conradt, J. Validating deep neural networks for online decoding of Motor Imagery movements from EEG signals. Sensors 2019, 19, 210. [Google Scholar] [CrossRef]
- Miao, M.; Hu, W.; Yin, H.; Zhang, K. Spatial-frequency feature learning and classification of motor imagery EEG based on deep convolution neural network. Comput. Math. Methods Med. 2020, 2020, 1981728. [Google Scholar] [CrossRef]
- Xu, B.; Zhang, L.; Song, A.; Wu, C.; Li, W.; Zhang, D.; Xu, G.; Li, H.; Zeng, H. Wavelet Transform Time-Frequency Image and Convolutional Network-Based Motor Imagery EEG Classification. IEEE Access 2019, 7, 6084–6093. [Google Scholar] [CrossRef]
- Alwasiti, H.; Yusoff, M.Z.; Raza, K. Motor Imagery Classification for Brain Computer Interface Using Deep Metric Learning. IEEE Access 2020, 8, 109949–109963. [Google Scholar] [CrossRef]
- Dose, H.; Møller, J.S.; Iversen, H.K.; Puthusserypady, S. An end-to-end deep learning approach to MI-EEG signal classification for BCIs. Expert Syst. Appl. 2018, 114, 532–542. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Lun, X.; Yu, Z.; Chen, T.; Wang, F.; Hou, Y. A simplified CNN classification method for MI-EEG via the electrode pairs signals. Front. Hum. Neurosci. 2020, 14, 338. [Google Scholar] [CrossRef]
- Xu, G.; Shen, X.; Chen, S.; Zong, Y.; Zhang, C.; Yue, H.; Liu, M.; Chen, F.; Che, W. A deep transfer convolutional neural network framework for EEG signal classification. IEEE Access 2019, 7, 112767–112776. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- Pytorch. Pytorch Front Page. Available online: https://pytorch.org/ (accessed on 3 November 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recording 01 | Baseline recording with open eyes |
| Recording 02 | Baseline recording with closed eyes |
| Recording 03 | Task 1: Motor execution of one hand (left or right) |
| Recording 04 | Task 2: Motor imagery of one hand (left or right) |
| Recording 05 | Task 3: Motor execution of both hands or both feet |
| Recording 06 | Task 4: Motor imagery of both hands or both feet |
| Recording 07 | Task 1 |
| Recording 08 | Task 2 |
| Recording 09 | Task 3 |
| Recording 10 | Task 4 |
| Recording 11 | Task 1 |
| Recording 12 | Task 2 |
| Recording 13 | Task 3 |
| Recording 14 | Task 4 |
| Model | Input | Accuracy [%] |
|---|---|---|
| [25] | Topographical Map | 65.00% |
| [26] | 2D Raw EEG signal | 69.82% |
| Single-Layer CNN | Single-Channel Spectrogram Image | 62.26% |
| 64-Channel Vertically Stacked Spectrogram Image | 50.37% | |
| 21-Channel Vertically Stacked Spectrogram Image | 50.68% | |
| 13-Channel Vertically Stacked Spectrogram Image | 50.68% | |
| 9-Channel Vertically Stacked Spectrogram Image | 52.92% | |
| 5-Channel Vertically Stacked Spectrogram Image | 52.16% | |
| Two-Layer CNN | Single-Channel Spectrogram Image | 66.38% |
| 64-Channel Vertically Stacked Spectrogram Image | 53.015% | |
| 21-Channel Vertically Stacked Spectrogram Image | 50.68% | |
| 13-Channel Vertically Stacked Spectrogram Image | 56.68% | |
| 9-Channel Vertically Stacked Spectrogram Image | 55.55% | |
| 5-Channel Vertically Stacked Spectrogram Image | 53.61% | |
| Three-Layer CNN | Single-Channel Spectrogram Image | 71.08% |
| 64-Channel Vertically Stacked Spectrogram Image | 50.68% | |
| 21-Channel Vertically Stacked Spectrogram Image | 50.05% | |
| 13-Channel Vertically Stacked Spectrogram Image | 56.68% | |
| 9-Channel Vertically Stacked Spectrogram Image | 54.92% | |
| 5-Channel Vertically Stacked Spectrogram Image | 55.02% | |
| ResNet18 + Single-Layer CNN | Single-Channel Spectrogram Image | 90.55% |
| 64-Channel Vertically Stacked Spectrogram Image | 49.94% | |
| 21-Channel Vertically Stacked Spectrogram Image | 50.15% | |
| 13-Channel Vertically Stacked Spectrogram Image | 50.15% | |
| 9-Channel Vertically Stacked Spectrogram Image | 53.86% | |
| 5-Channel Vertically Stacked Spectrogram Image | 50.19% | |
| ResNet18 + Three-Layer CNN | Single-Channel Spectrogram Image | 93.32% |
| 64-Channel Vertically Stacked Spectrogram Image | 50.15% | |
| 21-Channel Vertically Stacked Spectrogram Image | 50.15% | |
| 13-Channel Vertically Stacked Spectrogram Image | 50.15% | |
| 9-Channel Vertically Stacked Spectrogram Image | 54.70% | |
| 5-Channel Vertically Stacked Spectrogram Image | 49.59% |
| Model | Input | Accuracy [%] |
|---|---|---|
| [25] | Topographical Map | 65.00% |
| [26] | 2D Raw EEG signal | 69.82% |
| Single-Layer CNN | 2D Raw 64-Channel EEG Signal | 55.23% |
| 2D Raw 21-Channel EEG Signal | 53.54% | |
| 2D Raw 13-Channel EEG Signal | 53.75% | |
| 2D Raw 9-Channel EEG Signal | 62.22% | |
| 2D Raw 5-Channel EEG Signal | 63.31% | |
| Two-Layer CNN | 2D Raw 64-Channel EEG Signal | 59.68% |
| 2D Raw 21-Channel EEG Signal | 55.66% | |
| 2D Raw 13-Channel EEG Signal | 52.16% | |
| 2D Raw 9-Channel EEG Signal | 72.87% | |
| 2D Raw 5-Channel EEG Signal | 54.39% | |
| Three-Layer CNN | 2D Raw 64-Channel EEG Signal | 60.42% |
| 2D Raw 21-Channel EEG Signal | 53.12% | |
| 2D Raw 13-Channel EEG Signal | 54.25% | |
| 2D Raw 9-Channel EEG Signal | 63.28% | |
| 2D Raw 5-Channel EEG Signal | 61.26% |
| Model | Input | Accuracy [%] |
|---|---|---|
| [25] | Topographical Map | 65% |
| [26] | 2D Raw EEG signal | 69.82% |
| Single-Layer CNN | 3D Raw 21-Channel EEG Signal | 57.14% |
| 3D Raw 13-Channel EEG Signal | 56.50% | |
| 3D Raw 9-Channel EEG Signal | 63.70% | |
| 3D Raw 5-Channel EEG Signal | 62.64% | |
| Two-Layer CNN | 3D Raw 21-Channel EEG Signal | 57.14% |
| 3D Raw 13-Channel EEG Signal | 51.21% | |
| 3D Raw 9-Channel EEG Signal | 73.93% | |
| 3D Raw 5-Channel EEG Signal | 69.84% | |
| Three-Layer CNN | 3D Raw 21-Channel EEG Signal | 58.73% |
| 3D Raw 13-Channel EEG Signal | 51.85% | |
| 3D Raw 9-Channel EEG Signal | 68.35% | |
| 3D Raw 5-Channel EEG Signal | 67.37% |
| Model | Input | Accuracy [%] |
|---|---|---|
| [25] | Topographical Map | 65% |
| [26] | 2D Raw EEG signal | 69.82% |
| Single-Layer 1D CNN | 1D Raw EEG Signal Array | 64.69% |
| Two-Layer 1D CNN | 1D Raw EEG Signal Array | 76.29% |
| Three-Layer 1D CNN | 1D Raw EEG Signal Array | 84.87% |
| Four-Layer 1D CNN | 1D Raw EEG Signal Array | 86.12% |
| Five-Layer 1D CNN | 1D Raw EEG Signal Array | 79.58% |
| Model | Input | Accuracy [%] |
|---|---|---|
| [25] | Topographical Map | 65% |
| [26] | 2D Raw EEG signal | 69.82% |
| Single-Layer CNN | 2D Raw 5-Channel EEG Signa | 63.31% |
| 3D Raw 9-Channel EEG Signal | 63.70% | |
| 3D Raw 5-Channel EEG Signal | 62.64% | |
| Two-Layer CNN | 2D Raw 9-Channel EEG Signal | 72.87% |
| 3D Raw 9-Channel EEG Signal | 73.93% | |
| 3D Raw 5-Channel EEG Signal | 69.84% | |
| Three-Layer CNN | Single-Channel Spectrogram Image | 71.08% |
| 3D Raw 9-Channel EEG Signal | 68.35% | |
| 3D Raw 5-Channel EEG Signal | 67.37% | |
| ResNet18 + Single-Layer CNN | Single-Channel Spectrogram Image | 90.55% |
| 9-Channel Vertically Stacked Spectrogram Image | 53.68% | |
| 5-Channel Vertically Stacked Spectrogram Image | 50.19% | |
| ResNet18 + Three-Layer CNN | Single-Channel Spectrogram Image | 93.32% |
| 9-Channel Vertically Stacked Spectrogram Image | 54.70% | |
| 64-Channel Vertically Stacked Spectrogram Image | 50.15% | |
| Single-Layer 1D CNN | 1D Raw EEG Signal Array | 64.69% |
| Two-Layer 1D CNN | 1D Raw EEG Signal Array | 76.29% |
| Three-Layer 1D CNN | 1D Raw EEG Signal Array | 84.87% |
| Four-Layer 1D CNN | 1D Raw EEG Signal Array | 86.12% |
| Five-Layer 1D CNN | 1D Raw EEG Signal Array | 79.58% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lomelin-Ibarra, V.A.; Gutierrez-Rodriguez, A.E.; Cantoral-Ceballos, J.A. Motor Imagery Analysis from Extensive EEG Data Representations Using Convolutional Neural Networks. Sensors 2022, 22, 6093. https://doi.org/10.3390/s22166093
Lomelin-Ibarra VA, Gutierrez-Rodriguez AE, Cantoral-Ceballos JA. Motor Imagery Analysis from Extensive EEG Data Representations Using Convolutional Neural Networks. Sensors. 2022; 22(16):6093. https://doi.org/10.3390/s22166093
Chicago/Turabian StyleLomelin-Ibarra, Vicente A., Andres E. Gutierrez-Rodriguez, and Jose A. Cantoral-Ceballos. 2022. "Motor Imagery Analysis from Extensive EEG Data Representations Using Convolutional Neural Networks" Sensors 22, no. 16: 6093. https://doi.org/10.3390/s22166093