1. Introduction
Smart water distribution systems (WDSs) produce a large amount of information during their operation. This information contains sensor readings, actuator status, and transitions between controllers and programmable logic controllers (PLCs). In WDSs, these data are gathered and synchronized under the supervisory control and data acquisition (SCADA) system. SCADA systems facilitate advanced automation for increasing the system’s efficiency via real-time management and, thus, achieve cost and labor savings while meeting consumers’ demands with higher reliability. However, with the advantages of smart WDSs, a new vulnerability to cyber-attacks has emerged. Due to the automated nature of these systems, communication can be compromised, and operational information and mechanisms might leak. A critical review done by [
1] reveals cyber-attack incidents in the water sector in different regions around the globe, including the United States, Europe, the United Kingdom, and Australia. In their review, the authors found that attackers infiltrated the system through different components of the smart WDS, such as routers, PLCs, mail servers, and SCADA systems. The attacks involved data manipulation, data theft, computational resource theft, water theft, and environmental pollution. The study in [
1] highlights that only reliable and well-documented resources were reviewed, implying that further undocumented attacks might have occurred.
Cyber protection is needed to overcome this potential vulnerability. Traditional information protection (e.g., firewalls) is vital for isolating the operational network from the business network. Still, an additional protection layer can be gained by analyzing the system’s operational data to identify anomalous behavior, which the attacker is expected to leave in the system [
2]. That is, the operational data of the smart WDSs can be used for anomaly detection and specifically for cyber-attack detection. While anomaly detection can help operators detect operational anomalies, like equipment failure or pattern changes, detecting cyber-attacks is more challenging since, unlike normal failures, attackers might try to conceal their actions by altering various parameters. Hence, detecting cyber-attacks has been an active research topic in recent years, as detailed below.
Tuptuk et al. [
3] report that researchers’ awareness of cyber-attacks on water systems has significantly increased worldwide in recent years. This is also emphasized in a recent study by Shapira et al. [
4], which reviewed stakeholders’ perspectives on cyber risks in the water sector. One notable benchmark is the BATADAL competition [
5], in which research teams were challenged to develop the best detection algorithm for detecting cyber-attacks on a given simulated WDS. The datasets provided to the teams included sensor readings from normal operations and a second dataset with operation readings under simulated cyber-attacks (simulated using the epanetCPA toolbox [
6]). Seven teams participated in the competition and presented different cyber detection systems. Six out of seven teams in the competition [
7,
8,
9,
10,
11,
12] developed detection algorithms based on statistical methods and supervised machine learning (ML) techniques.
Nonetheless, supervised methods require labeled attack records which are rarely available in real-world applications. One team (the winning team) used a model-based approach that simulated the entire physical system using a hydraulic simulator [
13]. It then used a supervised ML method to identify outliers. As such, the proposed model-based approach was impractical for two reasons: (1) it is a supervised method, and (2) it requires a detailed hydraulic model of WDSs, which is often unavailable in real-world systems. It is noteworthy that using simulated cyber events is not a remedy for supervised ML approaches since simulating the cyber events will require a calibrated epanetCPA model [
6], which, as explained previously, is often unavailable in the real world. In addition, in the case of producing such attacks, these will only be a few scenarios out of infinite possibilities. Thus, for a detection model to be practical, it should be able to learn the abnormality in WDSs without referring to a predetermined list of labeled attacks. None of the aforementioned studies meets this condition.
In general, anomaly detection over a time series is a challenging problem where the detection system is asked to pinpoint anomalous samples from a real-time data stream. Anomaly detection problems are typically characterized by unbalanced data, meaning most of the samples in the data belong to the ‘normal’ state. In contrast, ‘anomalous’ samples are rare, making detecting these anomalies an even more complex problem. ML algorithms were found suitable to deal with such problems [
14]. These algorithms, which are usually named classifiers, will first learn a representation of the system’s state(s) from training samples, and then the trained classifier will be used to classify (or predict) the classes of the new samples. In the context of cyber-attack detection in WDSs, most of the records from the water system represent normal hydraulic behavior, while the records at the time of the cyber-attack represent anomalous behavior. The classifier aims to infer abnormal records from the data stream in real-time.
In general, there are three paradigms that differ in the level of required information during the training stage: (a) supervised-learning classifiers require labels from the classes we wish to predict; in our context, the training data should include a flag for normal/under-attack for each observation in the training dataset, and based on these labels the supervised classifier learns the relation between the samples and the labels; (b) unsupervised-learning classifiers are designed to learn the state of the data without the need of labeled samples. These classifiers attempt to predict the class of new samples based on the learned characteristics of the system in the training stage and (c) semi-supervised learning, which takes advantage of both supervised and unsupervised learning methods. In semi-supervised learning, the classifier requires training datasets that are guaranteed to be clean from anomalies; thus, unlike supervised learning, it does not require flags of normal/under-attack for each observation. Instead, in the semi-supervised learning paradigm, new samples are introduced to a classifier, which only learned the characteristics of the clean samples and so can distinguish anomalous samples when they do not fit the learned patterns [
15].
Following the BATADAL competition, several papers suggested using deep learning (DL) techniques for the cyber-attack detection problem in smart WDSs. DL is a research field in ML, which generally aims to learn complex problems using stacked artificial neural networks (ANNs) in multiple layers. These multilayer ANNs are referred to as deep neural networks (DNNs). DL techniques can perform under supervised, unsupervised, and semi-supervised learning conditions [
16]. Taormina and Galelli, [
17], proposed the use of auto-encoder (AE), a DNN architecture that aims to learn the decompressed representation of the data by encoding and then decoding the input data. This method allows us to learn the normal operation of the WDS by minimizing the reconstruction error between the input and output layers. Then, when the new samples are introduced to the AE, the reconstruction error is used to decide if the sample is normal or not. It is expected that anomalous samples will produce higher reconstruction errors since the model has never seen them before; thus, the decoded output of the samples will be very different from the input samples for the anomalous input. The authors conducted a thorough sensitivity analysis using labeled attack datasets to choose the optimal compression factor, hidden layers’ dimensions, and ANN’s depth. The detection method requires two tuning parameters: error threshold and smoothing window size. Utilizing sensitivity analysis, the authors showed that several selections of tuning parameters performed well under the two different labeled datasets provided in the BATADAL competition. Following this observation, the authors recommended tuning parameters. If the values of the recommended tuning parameters are adopted without change, the suggested method could be classified as a semi-supervised method since it relies solely on the clean training dataset.
Nonetheless, the sensitivity analysis was performed on the two labeled datasets that belong to the same WDS network (C-Town). As such, it is unclear whether the recommended tuning parameters generalize to other networks. If not, a new tuning will be required, and the suggested method will be supervised. Additionally, the study in [
17] proposed a scheme for event localization, but part of this scheme requires manual intervention of expert analysis.
Another DL algorithm, suggested in [
10], proposed using a variational autoencoder (VAE). Unlike the auto-encoder used in [
17], which learns the compressed representation of the data, the VAE learns the distribution of the data. The suggested ANN architecture is more complex and deeper. The authors use the log-reconstruction probability function (LPR) to identify anomalies. The authors set their LPR thresholds using an enumeration process to maximize the performance, which puts the method under the supervised learning category.
Kadosh et al. [
18] suggested the one class detection system (OCDS), which uses one class of classifier (support vector data description (SVDD)) trained on normal data. The output of the SVDD is classified into abnormal/normal data while utilizing a decision rule which requires two tuning parameters. These parameters are calibrated using labeled datasets. As such, this approach is classified as supervised learning. Hence, as a supervised approach, the OCDS might be impractical for real-world applications which lack labeled-attacks datasets.
In this study, we propose the semi-supervised detection system (SSDS), which is fully automatic and can be generalized to different water networks and datasets without needing labeled attacks. Unlike previous studies, we show one configuration of the classification process, which yields high performance in different networks and datasets. Furthermore, most previous studies have developed detection methods without considering the localization problem [
3]. This study addresses this gap by developing a localization methodology that almost guarantees that the attacked network zone is identified.
The distinct feature of the SSDS is that it relies on semi-supervised learning; thus, it does not require labeled attacks in the training dataset. The SSDS relies on the multivariate correlation between different sensor types using maximum canonical correlation analysis (MCCA) to achieve a dimensional reduction of the problem. This reduced representation is then classified using a semi-supervised method such that the entire learning process depends solely on the attack-free training dataset. The methodology depends on three modules that test different aspects of the WDS governing physics. The first module analyzes the physical relationships within a specific zone in the WDS (e.g., DMA), the second analyzes the temporal trends of the data, and the third examines the relationships between the different zones. The insights from the three modules are synthesized to detect and localize cyber-attacks.
To demonstrate the generalized applicability of the proposed solution, it was tested on two different WDSs and different datasets. In the following sections, we will discuss each building block of the SSDS, our results on the different datasets, and the localization abilities of the SSDS. Finally, in
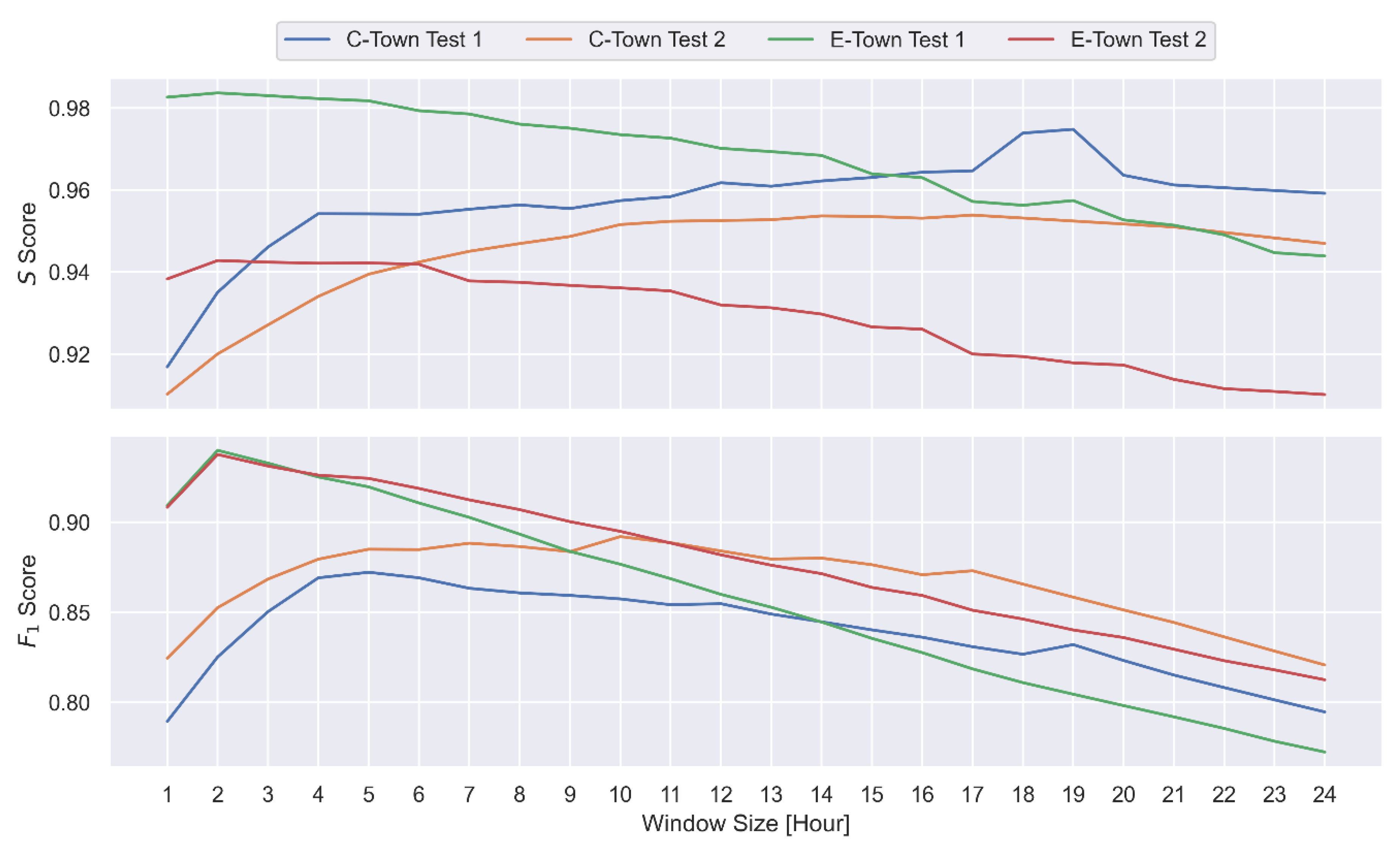
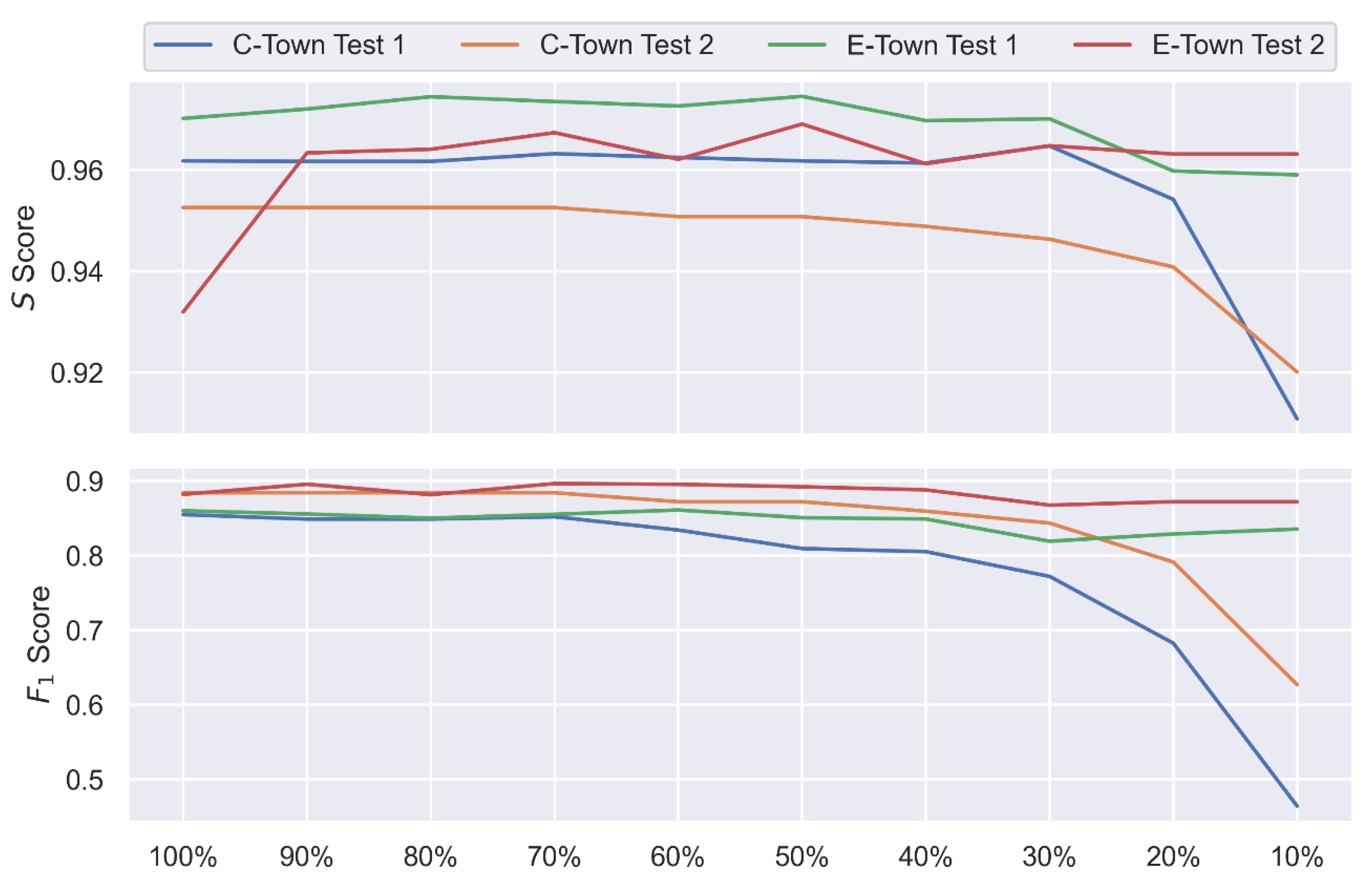
Appendix A,
Appendix B and
Appendix C, we provide a thorough sensitivity analysis that demonstrates the individual contribution of each module, the impact of parameter change, and data exposure percentage on the overall performance of the SSDS.
2. Methodology
2.1. Problem Statement
Real-time SCADA records in modern WDSs can be used to develop anomaly-detection algorithms, where historical SCADA data can be used for training the detection model. Often, these historical data contain no records of labeled cyber-attacks; thus, it is impractical to assume the availability of labeled cyber-attack datasets for the training phase. Furthermore, it is impractical to assume that datasets with labeled cyber-attacks could be synthetically simulated because such a process will require a calibrated hydraulic model, which is rarely available in real-life systems. In light of the above, there is a need to develop a practical detection model that only relies on attack-free datasets in the training phase.
2.2. Data Preparation
In the semi-supervised learning paradigm, the collected attack-free historical readings are used to train the classification model, and the trained model is then used to classify future readings into normal and under-attack states. Here we considered that the sensors could measure water levels in the storage tanks, water flows in the pumps and valves, and pressure in chosen junctions (e.g., before and after the pumping station). Let represents attack-free historical readings that will be used for training the model, where is the number of historical records and is the number of sensors. Let be a matrix that contains new SCADA readings after the training stage, where and are time (dynamic) indices representing timesteps from the beginning of the system implementation to the current timestep . New samples are added to at each timestep, and thus rows’ dimension of grows over time. It is noteworthy that the samples in are considered as testing samples, which are not used to train classifiers or tune any parameter in the methodology.
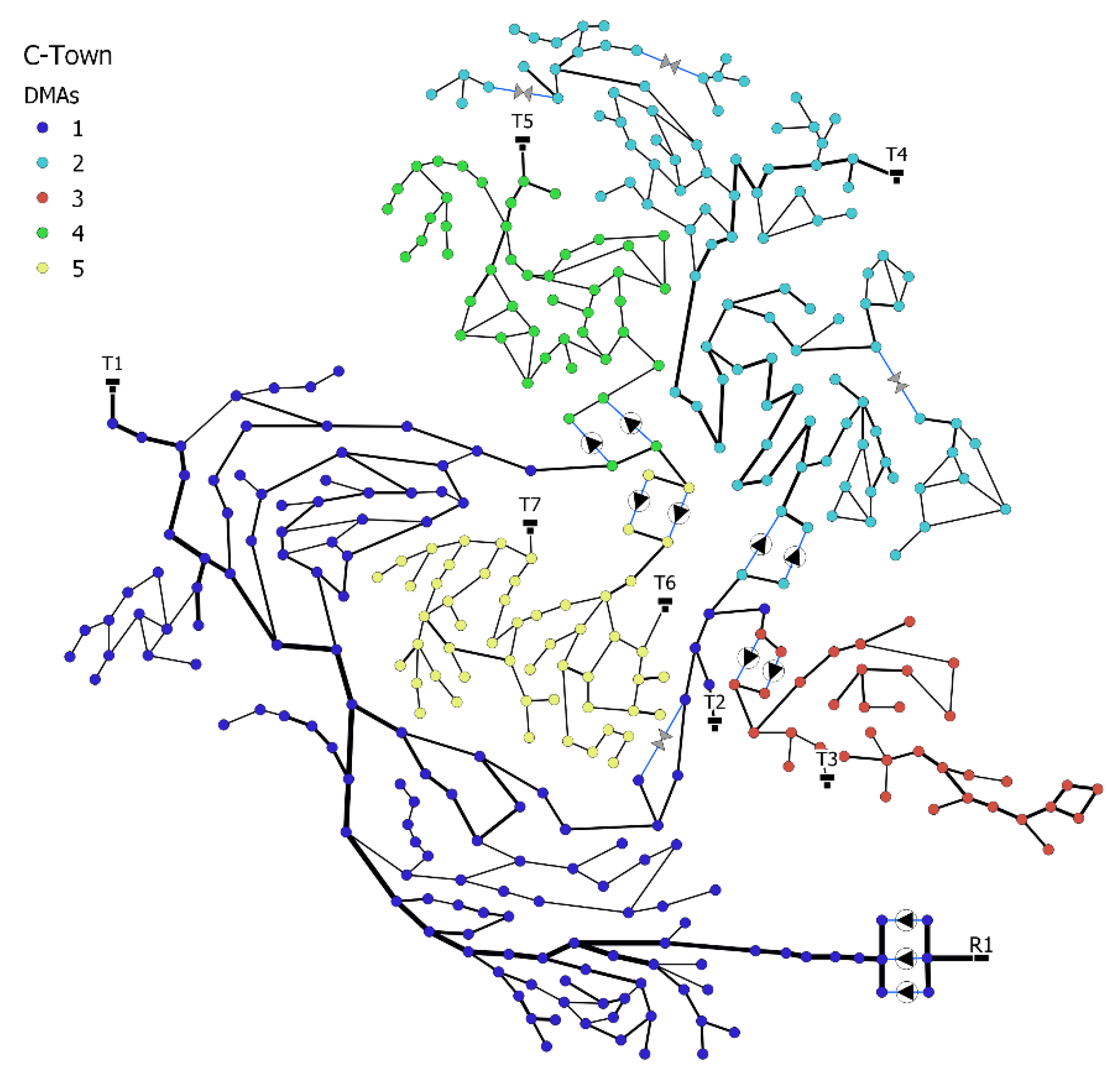
Modern WDSs are usually divided into district metering areas (DMAs) that allow for efficient water loss management and monitoring [
19]. Moreover, DMA design allows for efficient management of failure situations, for example, by isolating certain regions and reconfiguring water routes in case of low pressure due to pipe bursts. Kadosh et al. [
18] showed that the DMA structure could be utilized to design ML anomaly detection, which accounts for some of the physical properties of WDSs. More specifically, assume we have a set of
, where
, then we can define
and
, which contain train and test data from a specific DMA.
2.3. Support Vector Data Description
Support vector data description (SVDD) is a one-class classifier algorithm suggested by Tax and Duin [
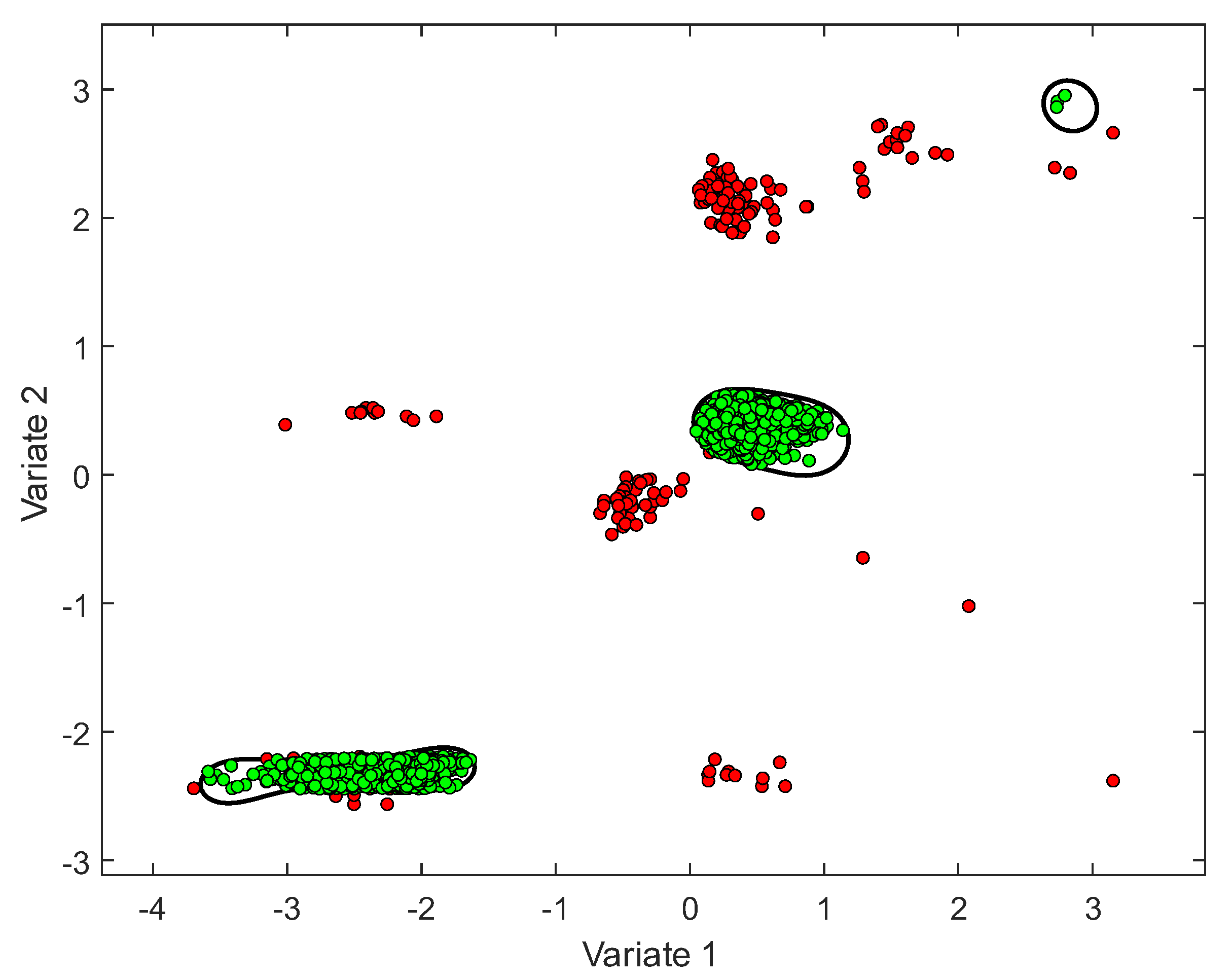
20]. The SVDD fits a boundary around one predefined class (e.g., normal observations class). When new data are introduced, this boundary can be used later for classification purposes. That is, samples that fall outside the boundary can be considered outliers by the SVDD classifier (
Figure 1). To construct the boundary, the SVDD uses a radial-basis-function (RBF) kernel, which is parametrized by the tuning parameter
. Another parameter that impacts the shape of the boundary is the
parameter, which is known as the penalty constant, where
, and
is the number of samples in the training set [
21]. The
parameter controls the trade-off between the volume inside the boundary and the excepted outliers. Setting
means that we assume all samples belong to the normal class and there are no anomalous samples present in the training data. Thus, setting
agrees with our previous assumption regarding the attack-free training dataset. Under this setting, the SVDD solves the following optimization problem to construct the boundary [
21]:
where
is the radius of the boundary,
is the center’s coordinates, and
is the mapping function (e.g., RBF). When no outliers are expected, the inequality constraint is treated as an equality constraint, and the Lagrange multipliers method can be used to solve the problem.
After constructing a data boundary by solving the optimization problem in Equation (1), a decision value (DV) could be obtained for any sample. The sample is on the boundary when , inside the boundary when , and outside the boundary when .
In light of the above, we are left with the parameter
as the only tuning parameter for the SVDD. The
parameter controls the bandwidth of the SVDD boundary when using the RBF kernel. As opposed to
, the tuning process for this parameter is not trivial. Setting it to a large value can lead to overfitting, and setting it to a small value can lead to underfitting (i.e., the boundary will be far away from the data cloud). The studies in [
22,
23,
24] explored unsupervised tuning methods for
selection when using SVDD with RBF kernel. We adopted the modified mean criterion method as suggested by [
24] since it can be computed fast and has been validated on different datasets [
24]. The modified mean criterion is given in Equation (2):
where
is the number of samples,
is the number of learned features,
is the variance of the
feature, and
is a tolerance factor. As suggested by [
24], the value of the tolerance factor
is the root of the function
, as given in Equation (3):
2.4. Ensemble Classification
Assigning only one SVDD classifier to learn the entire SCADA readings can lead to misclassification. We found that as the dimensionality of the data grows and the number of samples gets higher, the performance of the SVDD drops. To overcome this issue, we used ensemble learning [
25,
26]. The idea of ensemble methods in ML is to combine more than one classifier to handle the same problem. Later, in the prediction phase, predictions from individual classifiers are combined using a fusion operator. We rely on the previous observations of Kadosh et al. [
18], in which they suggest using the physical understanding of the water network to train different classifiers. Kadosh et al. [
18] suggested that assigning an SVDD classifier to each DMA separately can dramatically improve the results; thus, a specific classifier is trained for each DMA. In this paper, we extend this idea by assigning dedicated classifiers that examine the physical relationships between flow, storage, and pressure, which are known to exist in WDSs. Specifically, for each DMA, we perform within-DMA spatial analysis (WSA), which trains different classifiers for detecting anomalies between different combinations of physical variables. For example, we train a specific classifier for the interaction between flow-pressure variables, a different one for the interaction between flow-storage variables, etc. In addition to the WSA, we perform between-DMAs spatial analysis (BSA). This analysis trains dedicated classifiers that check anomalies between pairs of DMAs. As such, the analysis will be capable of detecting anomalies when one of the DMAs behaves abnormally compared to other DMAs.
Moreover, it is expected that WDSs will have normal temporal trends that can be used to detect anomalies when the operational data deviate from previously observed temporal patterns. To capture this deviation, we perform within-DMA temporal analysis (WTA), in which dedicated classifiers are trained to detect anomalies between DMA features and temporal regime curves that characterize the expected temporal pattern in the DMA. As such, an Ensemble of classifications will be obtained from the three modules (WSA, BSA, and WTA). These classifications are used to predict the system’s final state as being under attack or not. To perform the attack detection and localization synthesis, we rely on the fusion operators described in
Section 2.9. Following the framework above, one needs to train a large number of different classifiers in the three modules while focusing on the physical relationships between flow, pressure, and storage variables. To capture these physical relationships, we propose maximum canonical correlation analysis (MCCA).
2.5. Maximum Canonical Correlation Analysis
The WDS’s water mass and energy balance govern the relationship between flow, pressure, and storage variables. This relationship is complex (nonlinear and discontinuous) and depends on the hydraulic properties of the network (pipe resistance, pump curves, etc.). A good approximation can be obtained by hydraulic simulators such as EPANET [
27], but this requires a calibrated simulator, which is often unavailable in real-life systems [
13]. Previous studies suggested using deep learning methods to characterize the hydraulic variables’ nonlinearity and complexity [
10,
17,
28]. Here, we suggest a more straightforward approach that relies on dimensionality reduction and linear approximation using MCCA coupled with SVDD classifiers. Specifically, we seek the best linear association between the two groups of variables (for example, flow vs. pressure) by linearly projecting the features from high dimension to 2D. Classifiers will then be trained to classify the 2D projections of the features.
MCCA could be considered as the multivariate extension of correlation analysis. For example, when we have two scalar random variables, each with
observations (i.e.,
,
), then Pearson correlation could be calculated as
to measure the degree of linear association between them. However, when having two vectors of random variables, each with
observations (i.e.,
,
), then MCCA seeks linear combinations of
and
which have a maximum correlation with each other. That is, we solve the optimization problem in Equation (4):
where
and
are vectors of coefficients to project the correlation problem from dimensions
and
to a classical 2D correlation problem. The above problem could be solved using singular value decomposition on a correlation matrix [
29] and is implemented in many programming languages such as MATLAB and R.
Upon finding the optimal
and
, we can linearly project the high dimensional data into the 2D domain [
30]. In canonical correlation terminology, we distinguish between the terms ‘variables’ and ‘variates’. The term ‘variables’ refers to the original variables, while the term ‘variates’ refers to the projected variables.
We used the above MCCA procedure to find the best linear association between groups of physical variables based on governing physical rules. The definition of and in our context will change based on the physical relationship we are trying to capture. For example, if we want to capture the energy-balance relationship between flow and pressure inside a given DMA, then will be defined as the samples from the flow sensors and will be defined as the samples from the pressure sensors of the DMA. On the other hand, if we want to capture the water-balance relationship between flow and storage inside a given DMA, then will be defined as the samples from the flow sensors and will be defined as the samples from the tank storage sensors of the DMA. We also consider other combinations, as detailed in the following sections. It is expected that the linear approximation will not yield high accuracy when high nonlinearity exists. Yet, our methodology does not require the linear approximation to be very accurate since the SVDD will be able to characterize the expected error level in the linear approximation, as we will demonstrate in the application.
In the following sections, we present the offline stage in which the variates of the MCCA are derived and used to train the SVDD classifiers based on historical data. The offline stage is followed by an online stage where the variates are used in the classifiers to predict the system state. Finally, in
Section 2.9, we show how we can synthesize the different classifiers’ predictions to identify the anomalous behavior of the system.
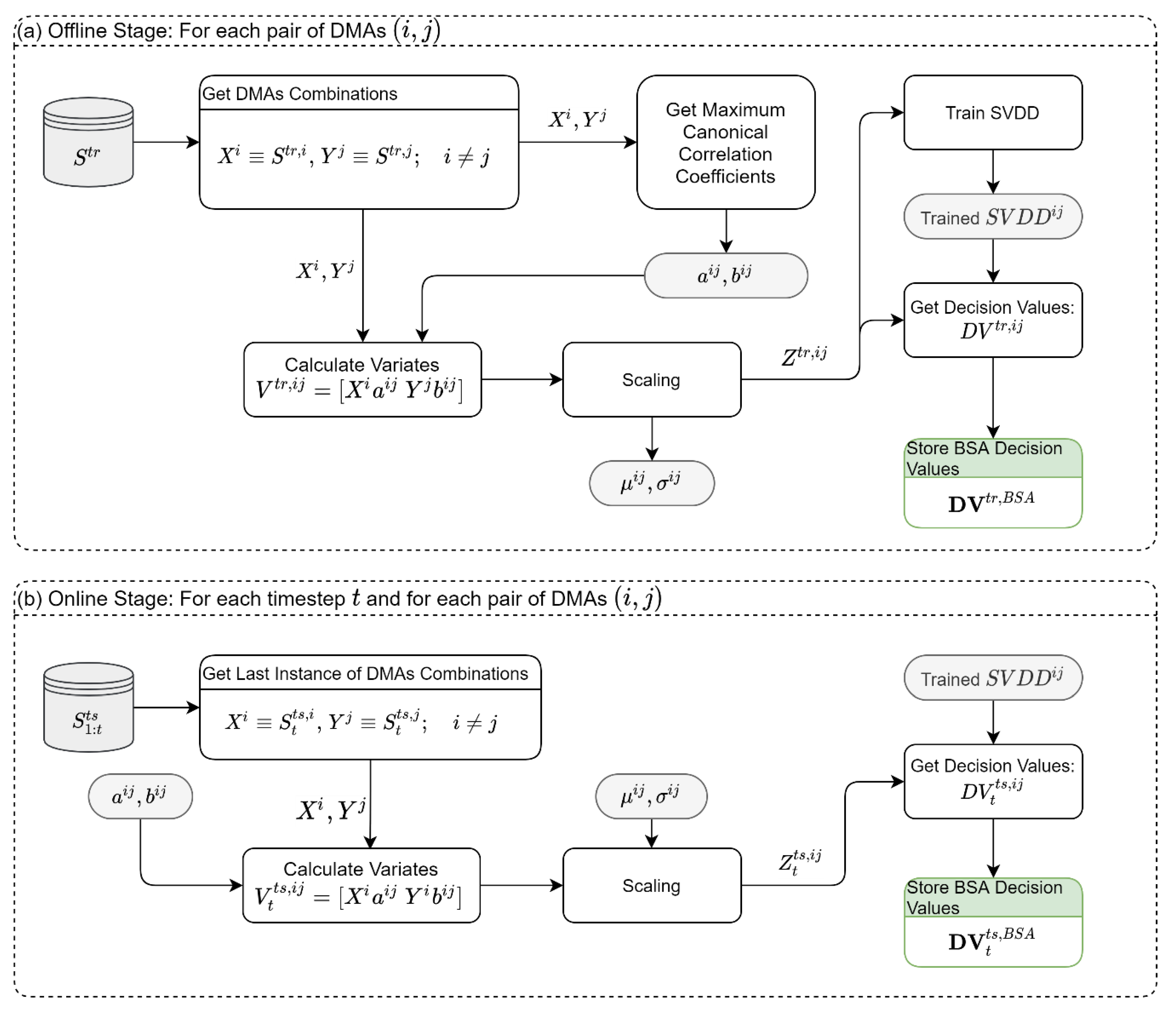
2.6. Module 1: Within-DMA Spatial Analysis (WSA)
The WSA module aims to find anomalies between three sensor types inside a DMA
: (1) water level (storage) sensors
, (2) flow sensors
, and (3) pressure sensors
. The WSA module operates in offline and online modes. In the offline mode, we rely on the attack-free dataset
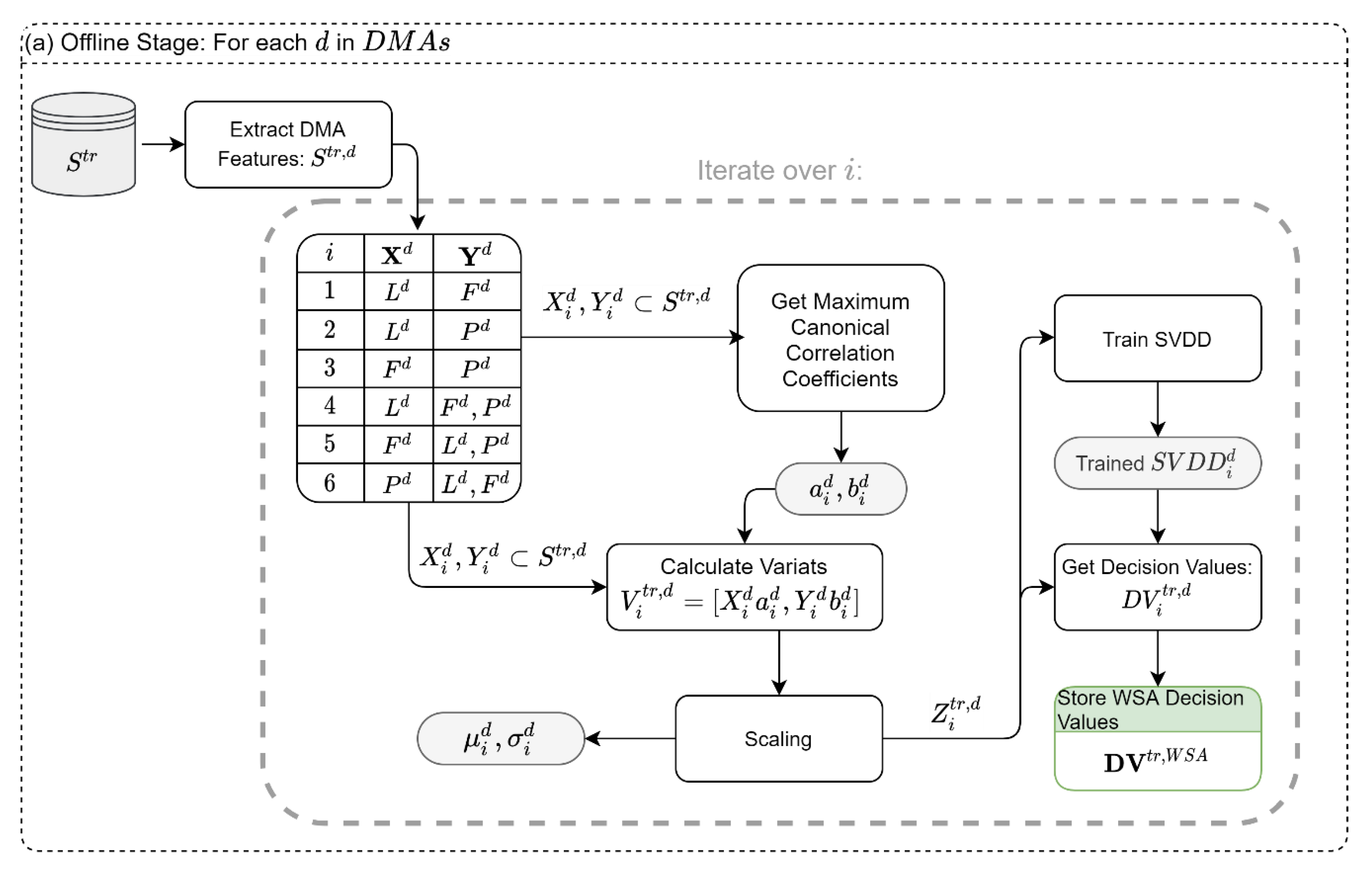
to find the variates that yield the maximum correlations between sensor types, and then based on these variates, a 2D-SVDD classifier is trained (
Figure 2a). The steps of the offline module are as follows: first, the historical sensor readings of a specific DMA,
, are loaded from the training set
; then, the sensors are divided into six possible type-combinations (interactions between sensors type),
. The six combinations are the result of one sensor type against a different sensor type (three combinations,
,
,
) and one sensor type against the rest of the types (three combinations,
,
,
). Then, MCCA is used to extract the maximum correlation between each set, and the coefficient vectors,
, are stored for later use. The variates of the MCCA are then scaled to a zero mean and unit standard deviation and used to train a 2D-SVDD model for each combination,
. The trained SVDDs, the mean, and the standard deviation values of the scaling process are stored for later use in the online stage.
Moreover, the scaled variates,
, are used to derive the “normal” decision values (DVs) that are expected from each SVDD. The vast majority of the DVs will be negative values (i.e., normal state) since we are predicting the same attack-free data used to construct the SVDD boundary. However, the DVs might include small positive values resulting from a small violation of the SVDD boundary in some samples (for example, because of a precision threshold). As such, it is important to calculate the DVs in the training stage to assess the magnitude of the positive DVs under attack-free conditions. The entire process is looped through all six types of combinations and all DMAs, as shown in
Figure 2a.
To demonstrate the above, let us consider a DMA (
) which has 100 observations from 3 flow sensors, 4 pressure sensors, and 2 water level sensors. In the first combination,
, we use the MCCA to find vectors of the coefficients
and
that maximize the linear association
, where
contains the water level data, and
contains the flow data. In the sixth combination,
, we use the MCCA to find vectors of the coefficients
and
that maximize the linear association
, where
contains the pressure data, and
contains both the water level and flow data. Similarly, we can define the rest of the type combinations (
). Note that regardless of the dimensions of
and
, we will always obtain two variates after projecting the samples using the obtained coefficients from the MCCA. These two variates are used to train a 2D SVDD.
Figure 1 demonstrates the SVDD classification in 2D after projecting the high-dimensional samples into two variates.
It is noteworthy that the WSA (and the BSA that will be discussed later) focuses on the spatial analyses of the data in a single timestep. As such, there is an inherent assumption of time series stationarity for all sensors. If one of the sensors has a nonstationary time series, this can be converted into a stationary one by differentiating it (i.e., the difference of observations in successive timesteps). To check whether differentiation should be performed on the sensor data, the Kolmogorov–Smirnov test [
31] is used to pinpoint situations when the probability distributions of the first and the second half of the training dataset differ.
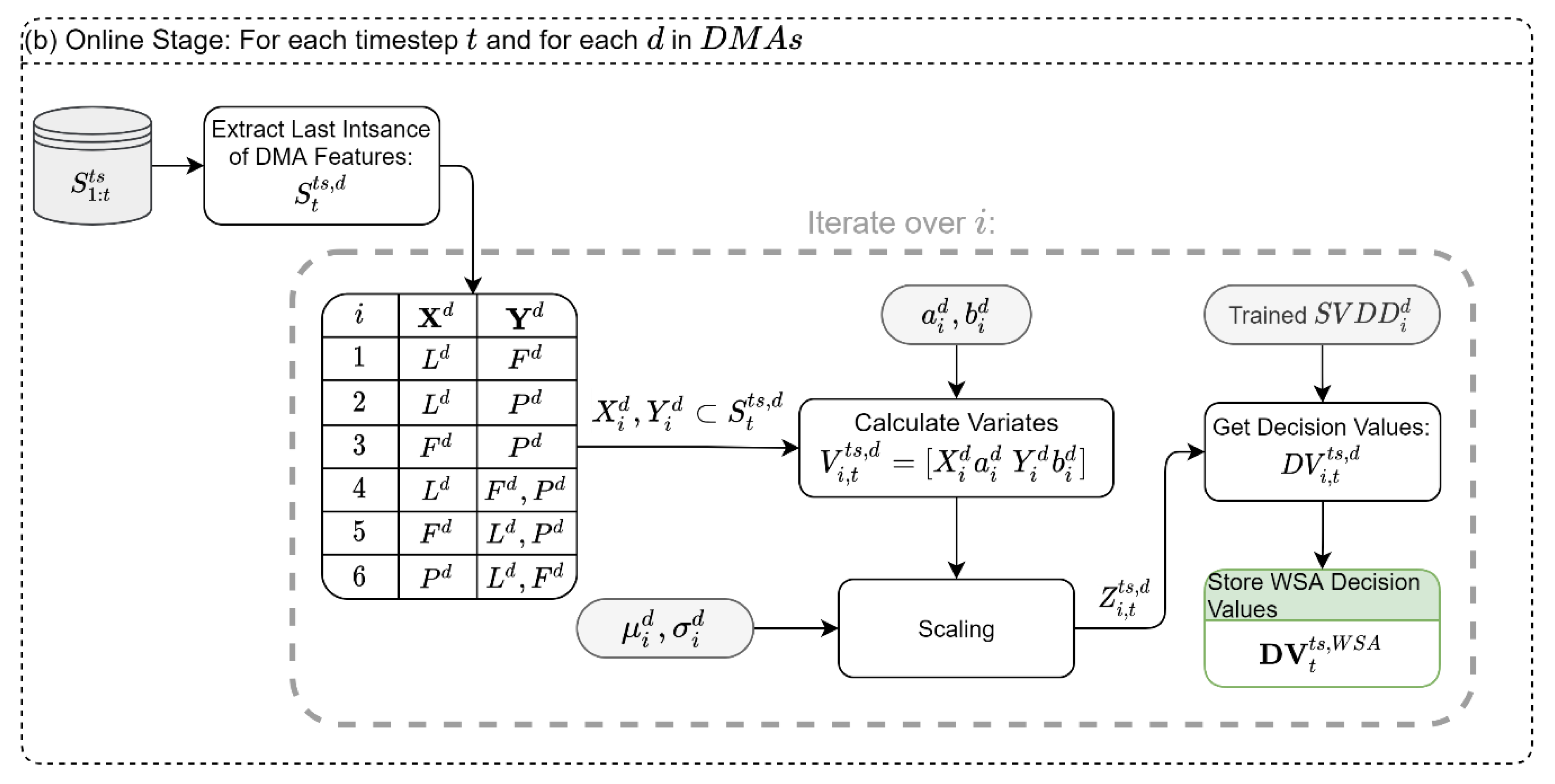
In the online stage of the WSA module, the parameters and the SVDD classifiers obtained in the offline stage are applied to the test dataset,
, as illustrated in
Figure 2b. In this stage, samples are fed to the system in real-time; this is demonstrated in
Figure 2b by the growing index
in the dataset, from which we only rely on the last instance
. Then, using the scaling parameters and the vectors of the MCCA coefficients from the offline stage, the scaled variates,
, are obtained. These variates are then classified using the trained SVDD models,
, and the DVs are stored for the synthesis module. It is noteworthy that for each time instance
, each DMA will result in six DVs corresponding to the six type combinations.
2.7. Module 2: Within-DMA Temporal Analysis (WTA)
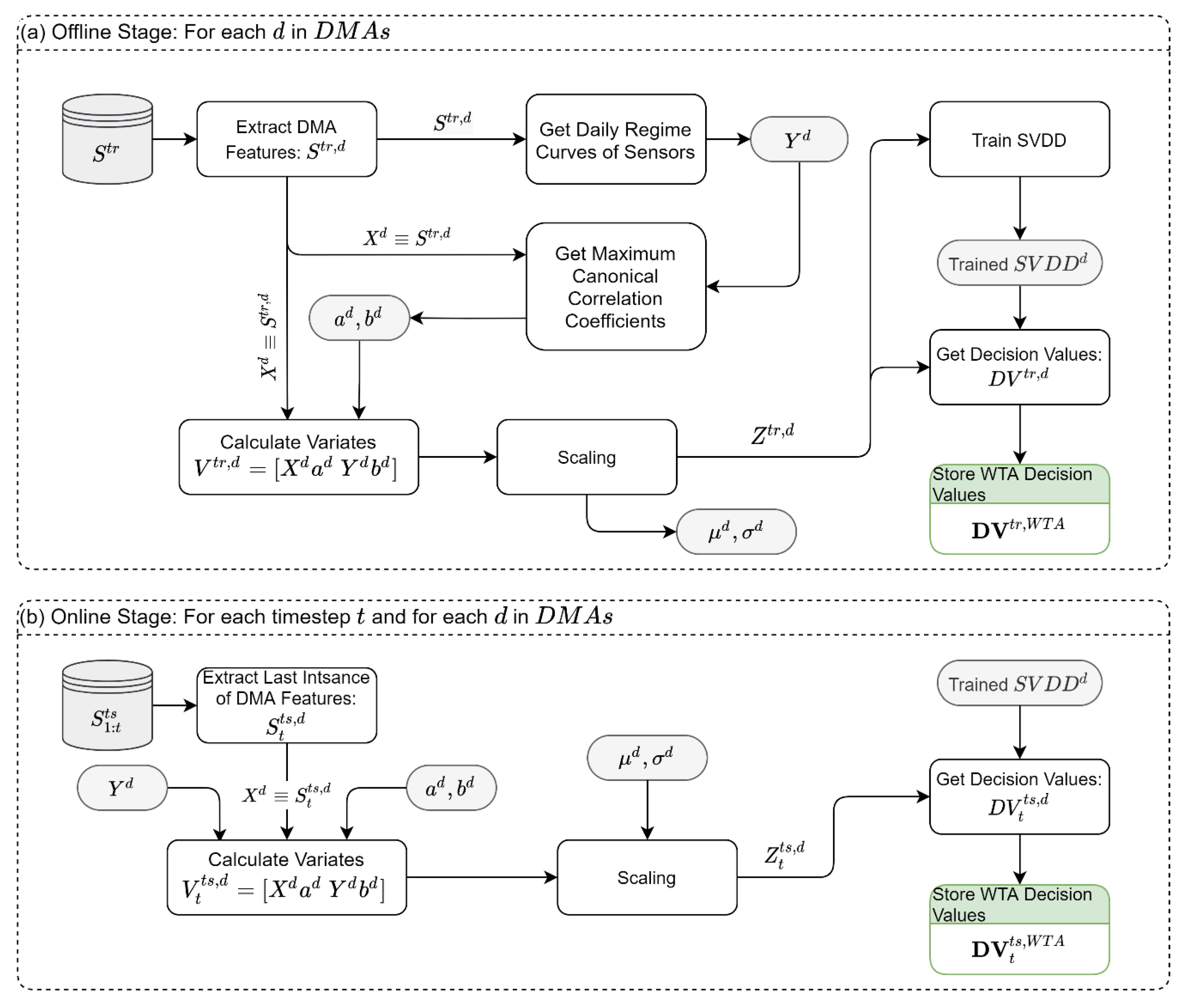
The WTA module aims to detect anomalies in the temporal patterns observed in the historical data (
Figure 3). To capture the time pattern, we use daily regime curves of the sensory data. The daily regime curves are calculated by averaging the sensor data for each hour of the day. That is, each hour in the day (1 to 24) will take a unique representative (reference) value.
In the offline stage of the WTA (
Figure 3a), we compare the sensor readings (of all types) to their respective daily regime curve using the MCCA. Under this setting, the MCCA finds the vectors of coefficients
, that yield the maximum correlation
, where
is all sensor readings from DMA
and
is the corresponding daily regime curves of the sensors. The variates of the MCCA are then scaled to a zero mean and unit standard deviation and used to train a 2D-SVDD model for each DMA,
. The trained SVDDs, the MCCA coefficients, the regime curves, the mean, and the standard deviation values are stored for later use in the online stage. Moreover, the scaled variates,
, are used to derive the “normal” DVs that are expected from each SVDD. In the online stage (
Figure 3b), the samples are fed to the system in real-time, and we only rely on the last observations
. Using the scaling parameters, the regime curves, and the vectors of MCCA coefficients from the offline stage, the scaled variates,
, are obtained. These variates are then classified using the trained SVDD models,
, and the DVs are stored for the synthesis module.
To demonstrate the above, let us consider a DMA () which has 100 observations from 3 flow sensors, 4 pressure sensors, and 2 storage sensors. We use the MCCA to find the vectors of coefficients and that maximize the linear association , where contains all sensory data and contains the daily regime curves of all sensory data. Regardless of the dimensions of and , we will always obtain two variates after projecting the samples using the coefficients from MCCA. These two variates are used to train a 2D SVDD in the offline stage and to predict the classification in the online stage.
2.8. Module 3: Between-DMA Spatial Analysis (BSA)
Unlike the WSA, which focuses on anomalies within DMAs, the BSA focuses on anomalies between pairs of DMAs
as shown in
Figure 4. The BSA module builds on the idea that modern WDSs are usually partitioned into DMAs, and that there is an intrinsic correlation between DMAs due to sharing different hydraulic components. For example, multiple DMAs can share a water tank, or a large DMA can feed nearby DMAs. In this module, we use the MCCA to extract the maximum correlation between the sensory readings (all types) of DMA
,
, and the sensory readings of DMA
,
. Then we follow similar steps as in the previous modules. But unlike the previous modules, in the BSA, the analysis is performed for each pair of DMAs. For example, in a network with five DMAs, we need to apply the MCCA
times to extract 10 vectors of the coefficients
, and to train 10 SVDDs on the variates.
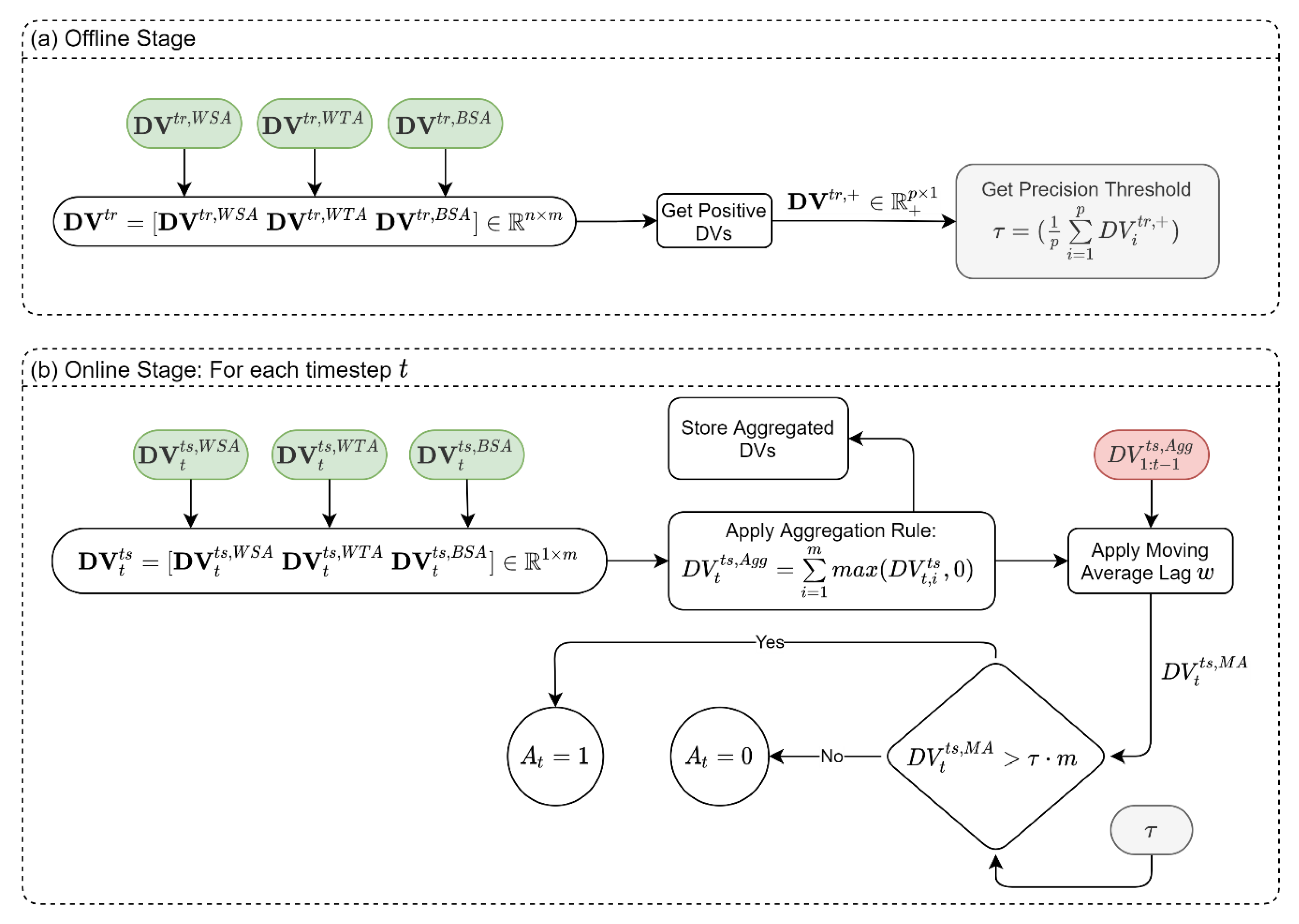
2.9. Synthesis
The previously described modules result in multiple SVDDs, each reporting its own DV, where positive DVs indicate outliers for the performed analysis. In the synthesis stage, we want to reach the final identification of the detection system state (Alarm,
versus not Alarm,
) based on all the DVs obtained from the classifiers ensemble. That is, we need to develop an aggregation rule for all DVs.
Figure 5 shows the synthesis module, which is also divided into offline and online stages. In the offline stage, we estimate the average precision of the SVDDs. As explained previously, the SVDDs are expected to produce small positive DVs even when tested for “normal” data. This can be attributed to the precision threshold in the SVDD training process. Therefore, we can estimate the mean precision by using the DVs that were stored in the training stage of the three modules (see green boxes in
Figure 2a,
Figure 3a and
Figure 4a). To do so, the DVs from the three modules
are joined together to form a matrix of DVs,
, where
is the number of observations in the training dataset and
is the number of all SVDDs in the three modules. To estimate the average precision,
, we average the positive entries in
, as shown in
Figure 5a. In the online stage, samples are fed to the system in real-time, while we only rely on the last DVs obtained from the three modules, which is a vector,
, that aggregates the last updated DVs of the three modules
. We then use the aggregation rule in Equation (5) to get a single scalar DV for timestep
.
The replacement of negative values with zero is performed to outweigh inlier samples in the aggregation operation. We also store all the aggregated DVs up to time in a vector denoted . In the next step, we perform a moving average with lag on the aggregated DV to obtain the moving average value . Finally, to declare an alarm, is compared to the precision of the SVDDs. If it exceeds the precision, then an alarm is raised. Note that is compared to average precision multiplied by ; this is because the DV values in result from a summation of terms, as can be seen in Equation (5).
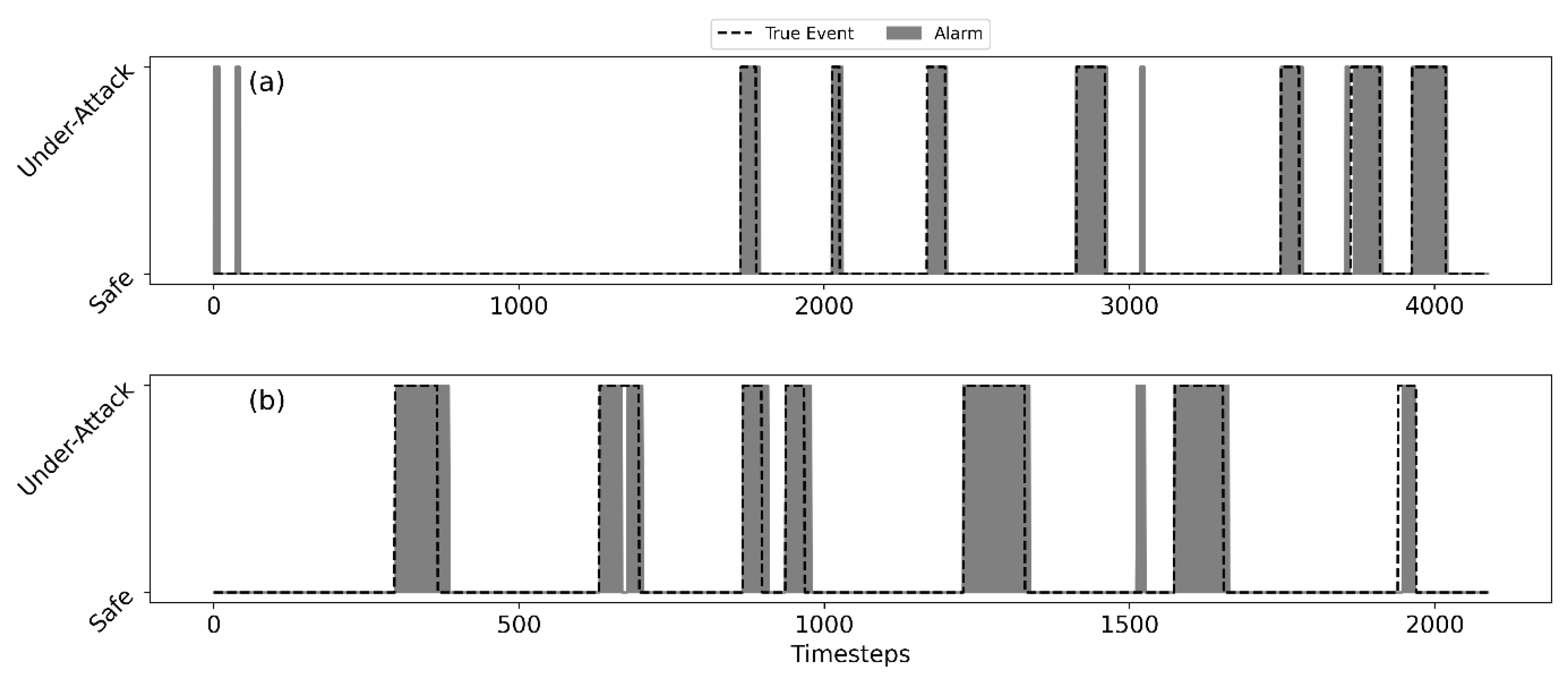
2.10. Performance Measures
Given a vector of alarm indicators,
(a vector that collects
), from a testing dataset, we can examine the system’s performance against labeled attacks. It is noteworthy that, unlike supervised learning methodologies, labeled attacks are only used for testing purposes. First, we consider the score index,
, as defined in BATADAL [
5]:
where
is time-to-detection score, defined as:
where
is the number of attacks contained in the dataset,
is time-to-detection relative to the
ith attack, and
is the duration of the
ith attack.
is the classification score:
where
is the true positive rate or the recall and
is the true negative rate. True positive (
) is the number of under-attack instances detected by the algorithm, true negative (
) is the number of non-event instances (i.e., safe state), which are also reported as safe by the algorithm, false negative (
) is the number of under attack instances missed by the algorithm, and false positive (
) is the number of instances which the algorithm flagged as under attack, but were actually safe.
varies between 0 and 1, with
being the ideal case in which all attacks are detected with no false alarms. The study in [
5] argued that the
score might be biased and suggested the
score. As such, in addition to
score, we measured the performance with
score, which is suitable for imbalanced data [
32].
is defined as follows:
where
is the positive predicted value or precision and defined as
TP/(TP + FP). The advantage of
when scoring the detection of rare events is that it does not depend on the number of
samples, which is expected to be high in unbalanced data with a large number of normal samples. For comparison with previously published studies, we report both
and
.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}