
A Universal Decoupled Training Framework for Human Parsing


Abstract
:1. Introduction
- A pixel resampling method in the field of semantic segmentation is proposed, which facilitates the realization of balanced sampling in semantic segmentation;
- Based on the pixel-oriented resampling method, a decoupling training framework for semantic segmentation tasks is proposed, which can be applied to various human parsing models without changing the structure of the model. The training framework not only retains the powerful feature extraction ability of the model, but also alleviates the problem of the degradation of segmentation accuracy due to imbalanced dataset, which can additionally improve the segmentation performance of the model.
2. Related Work
2.1. Human Parsing
2.2. Long-Tailed Distribution
3. Methods
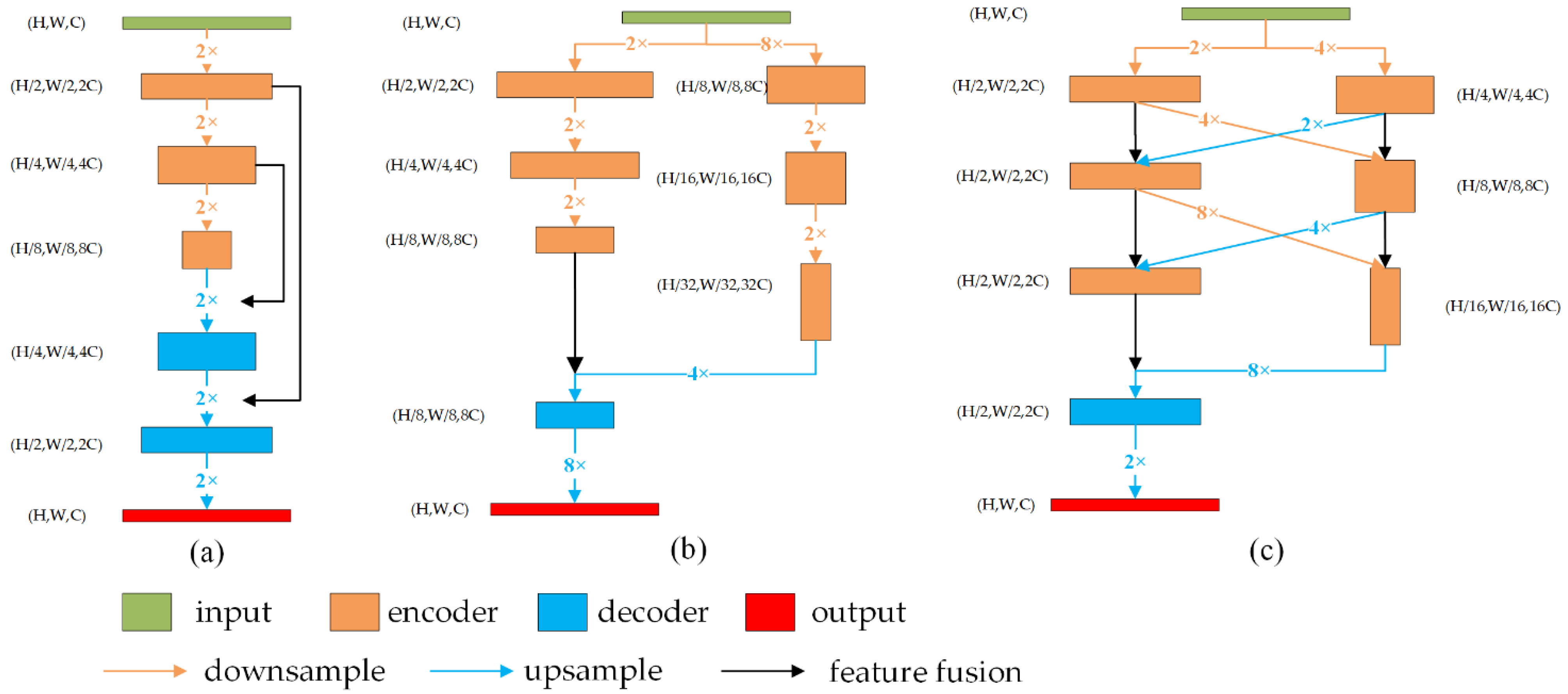
3.1. Overview
3.2. Pixel Resampling
4. Experimental Result
4.1. Dataset
4.2. Evaluation Protocols
4.3. Implementation Details
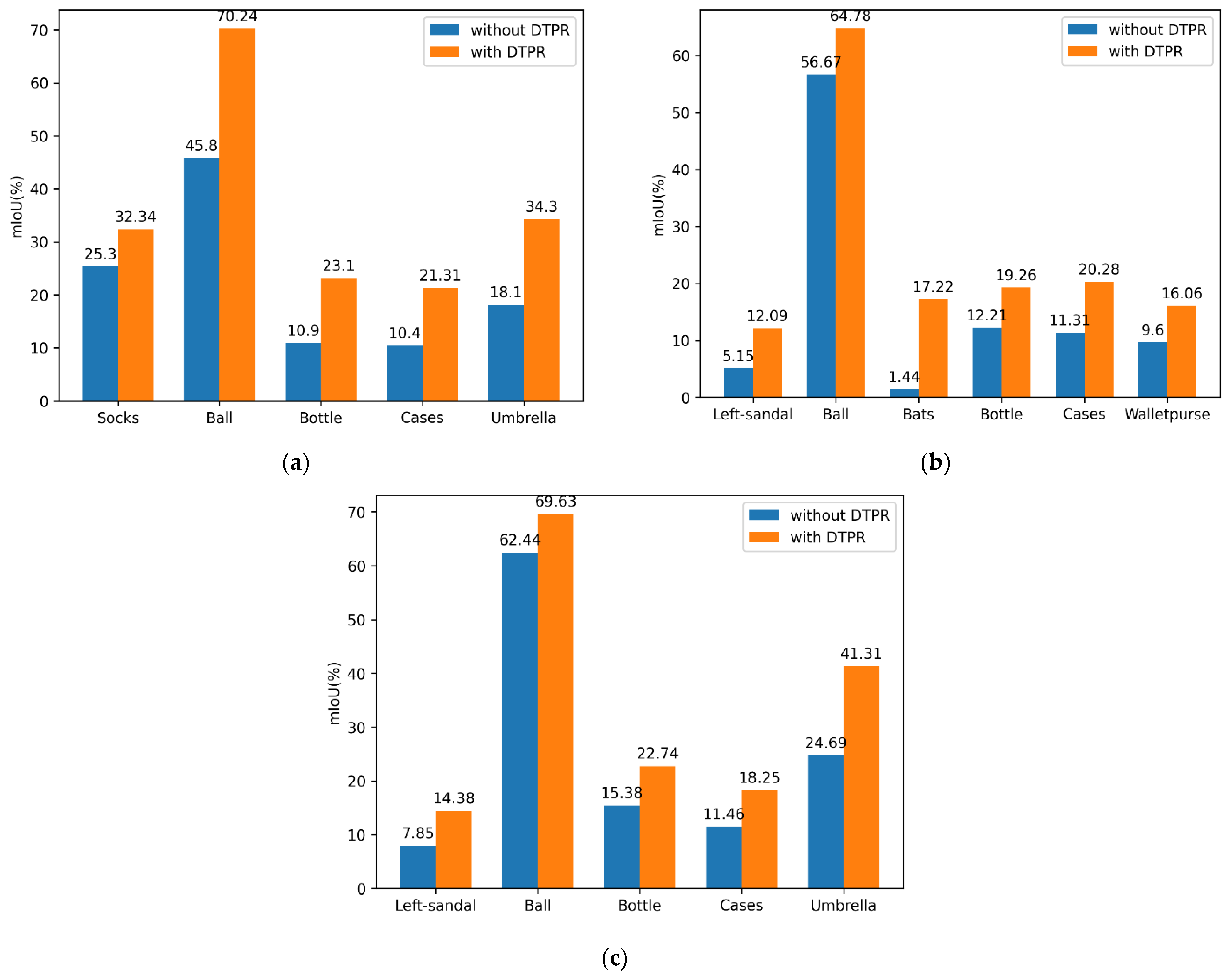
4.4. Experimental Results and Analysis
4.4.1. Comparison of Pixel Sampling Methods
4.4.2. Performance on the MHPv2.0 Dataset
High Accuracy Model
Lightweight Model
4.4.3. Performance on the LIP Dataset
High-Accuracy Model
Lightweight Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Processing Syst. 2015, 28, 1972. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liang, X.; Gong, K.; Shen, X.; Lin, L. Look into person: Joint body parsing & pose estimation network and a new benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 871–885. [Google Scholar]
- Ruan, T.; Liu, T.; Huang, Z.; Wei, Y.; Wei, S.; Zhao, Y. Devil in the details: Towards accurate single and multiple human parsing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4814–4821. [Google Scholar]
- Liang, X.; Xu, C.; Shen, X.; Yang, J.; Liu, S.; Tang, J.; Lin, L.; Yan, S. Human parsing with contextualized convolutional neural network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1386–1394. [Google Scholar]
- Liang, X.; Liu, S.; Shen, X.; Yang, J.; Liu, L.; Dong, J.; Lin, L.; Yan, S. Deep human parsing with active template regression. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2402–2414. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gong, K.; Liang, X.; Zhang, D.; Shen, X.; Lin, L. Look into person: Self-supervised structure-sensitive learning and a new benchmark for human parsing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 932–940. [Google Scholar]
- Gong, K.; Liang, X.; Li, Y.; Chen, Y.; Yang, M.; Lin, L. Instance-level human parsing via part grouping network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 770–785. [Google Scholar]
- Yamaguchi, K.; Kiapour, M.H.; Ortiz, L.E.; Berg, T.L. Parsing clothing in fashion photographs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3570–3577. [Google Scholar]
- Zhao, J.; Li, J.; Cheng, Y.; Sim, T.; Yan, S.; Feng, J. Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 792–800. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of road scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Xia, F.; Wang, P.; Chen, X.; Yuille, A.L. Joint multi-person pose estimation and semantic part segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6769–6778. [Google Scholar]
- Nie, X.; Feng, J.; Yan, S. Mutual learning to adapt for joint human parsing and pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 502–517. [Google Scholar]
- Gong, K.; Gao, Y.; Liang, X.; Shen, X.; Wang, M.; Lin, L. Graphonomy: Universal human parsing via graph transfer learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7450–7459. [Google Scholar]
- Li, J.; Zhao, J.; Wei, Y.; Lang, C.; Li, Y.; Sim, T.; Yan, S.; Feng, J. Multiple-human parsing in the wild. arXiv 2017, arXiv:1705.07206. [Google Scholar]
- Liu, S.; Liang, X.; Liu, L.; Lu, K.; Lin, L.; Cao, X.; Yan, S. Fashion parsing with video context. IEEE Trans. Multimed. 2015, 17, 1347–1358. [Google Scholar] [CrossRef]
- Dong, J.; Chen, Q.; Huang, Z.; Yang, J.; Yan, S. Parsing based on parselets: A unified deformable mixture model for human parsing. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 88–101. [Google Scholar] [CrossRef] [PubMed]
- Yamaguchi, K.; Kiapour, M.H.; Ortiz, L.E.; Berg, T.L. Retrieving similar styles to parse clothing. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1028–1040. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, P.; Xu, Y.; Wei, Y.; Yang, Y. Self-Correction for Human Parsing. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3260–3271. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Jia, M.; Lin, T.-Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- Wang, J.; Zhang, W.; Zang, Y.; Cao, Y.; Pang, J.; Gong, T.; Chen, K.; Liu, Z.; Loy, C.C.; Lin, D. Seesaw loss for long-tailed instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Conference, 19–25 June 2021; pp. 9695–9704. [Google Scholar]
- Bulo, S.R.; Neuhold, G.; Kontschieder, P. Loss max-pooling for semantic image segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7082–7091. [Google Scholar]
- Zhou, B.; Cui, Q.; Wei, X.-S.; Chen, Z.-M. Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9719–9728. [Google Scholar]
- Kang, B.; Xie, S.; Rohrbach, M.; Yan, Z.; Gordo, A.; Feng, J.; Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. arXiv 2019, arXiv:1910.09217. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Boston, MA, USA, 7–12 June 2015; pp. 234–241. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PA | MPA | mIoU |
|---|---|---|---|
| PSPNet | 71.84 | 45.18 | 35.92 |
| PSPNet+PRN | 72.02 | 53.06 | 36.77 |
| PSPNet+PRA | 72.69 | 52.22 | 37.57 |
| Method | PA | MPA | mIoU | |||
|---|---|---|---|---|---|---|
| No DTPR | With DTPR | No DTPR | With DTPR | No DTPR | With DTPR | |
| PSPNet | 71.84 | 72.69 | 45.18 | 52.22 | 35.92 | 37.57 |
| DeepLabv3+ | 71.67 | 72.42 | 44.56 | 51.19 | 34.98 | 36.76 |
| DANet | 72.06 | 72.63 | 45.92 | 52.22 | 36.51 | 37.70 |
| Method | PA | MPA | mIoU |
|---|---|---|---|
| Focal Loss [31] | 71.51 | 44.89 | 35.57 |
| CB Loss [30] | 72.02 | 48.52 | 36.77 |
| Our Method | 72.69 | 52.22 | 37.57 |
| Method | PA | MPA | mIoU | |||
|---|---|---|---|---|---|---|
| NoDTPR | With DTPR | No DTPR | With DTPR | No DTPR | With DTPR | |
| BiSeNetv2 | 59.14 | 59.88 | 25.96 | 34.28 | 20.28 | 22.86 |
| STDC | 63.47 | 63.89 | 29.77 | 36.49 | 23.34 | 24.88 |
| DDRNet | 61.91 | 62.26 | 25.74 | 33.96 | 19.96 | 23.03 |
| Method | PA | MPA | mIoU | |||
|---|---|---|---|---|---|---|
| No DTPR | With DTPR | No DTPR | With DTPR | No DTPR | With DTPR | |
| PSPNet | 70.80 | 74.95 | 49.58 | 54.20 | 42.23 | 44.22 |
| DeepLabv3+ | 70.57 | 73.70 | 44.56 | 51.19 | 34.98 | 36.76 |
| DANet | 71.26 | 74.10 | 50.39 | 54.11 | 42.86 | 44.29 |
| PSPNet | DTPR (PSPNet) | DeepLabv3+ | DTPR (DeepLabv3+) | DANet | DTPR (DANet) | |
|---|---|---|---|---|---|---|
| Hat | 55.08 | 57.33 | 52.02 | 57.55 | 57.08 | 57.52 |
| Hair | 66.41 | 69.58 | 62.75 | 68.64 | 67.33 | 69.23 |
| Glove | 34.14 | 41.07 | 33.60 | 40.70 | 36.85 | 40.68 |
| S-glasses | 31.49 | 32.16 | 26.06 | 32.01 | 31.17 | 33.97 |
| Up-Cloth | 65.59 | 66.88 | 64.32 | 66.96 | 65.77 | 66.38 |
| Dress | 20.77 | 21.66 | 20.37 | 23.16 | 18.66 | 26.44 |
| Coat | 51.41 | 51.69 | 49.34 | 51.54 | 50.92 | 51.79 |
| Socks | 40.43 | 41.67 | 37.68 | 38.88 | 41.23 | 41.91 |
| Pants | 71.05 | 72.42 | 72.70 | 73.84 | 71.27 | 73.17 |
| Jumpsuits | 26.96 | 27.88 | 27.94 | 27.93 | 28.14 | 27.42 |
| Scarf | 12.88 | 16.17 | 13.89 | 17.95 | 15.83 | 15.06 |
| Skirt | 15.59 | 17.73 | 14.64 | 17.72 | 16.09 | 15.30 |
| Face | 78.03 | 80.13 | 74.10 | 77.50 | 79.07 | 76.70 |
| L arm | 57.84 | 60.61 | 59.73 | 60.73 | 59.15 | 60.43 |
| R arm | 61.43 | 63.73 | 61.97 | 62.47 | 61.97 | 62.99 |
| L leg | 47.93 | 49.37 | 48.36 | 51.59 | 47.90 | 51.75 |
| R leg | 49.76 | 50.35 | 49.26 | 49.88 | 49.89 | 52.25 |
| L shoe | 29.27 | 32.61 | 38.03 | 33.19 | 29.67 | 32.01 |
| R shoe | 28.28 | 31.35 | 29.59 | 29.78 | 29.23 | 30.78 |
| Avg | 42.23 | 44.22 | 41.32 | 44.10 | 42.86 | 44.29 |
| Method | PA | MPA | mIoU | |||
|---|---|---|---|---|---|---|
| No DTPR | With DTPR | No DTPR | With DTPR | No DTPR | With DTPR | |
| BiSeNetv2 | 63.30 | 59.37 | 42.63 | 36.17 | 32.10 | 29.88 |
| STDC | 69.24 | 65.00 | 48.25 | 43.21 | 38.28 | 35.53 |
| DDRNet | 68.42 | 64.75 | 47.41 | 40.32 | 36.48 | 33.80 |
| PSPNet | DTPR (PSPNet) | DeepLabv3+ | DTPR (DeepLabv3+) | DANet | DTPR (DANet) | |
|---|---|---|---|---|---|---|
| Hat | 38.34 | 37.57 | 46.70 | 49.49 | 46.00 | 49.17 |
| Hair | 56.91 | 57.03 | 59.77 | 61.91 | 59.23 | 60.52 |
| Glove | 15.35 | 23.25 | 26.34 | 30.50 | 19.47 | 26.46 |
| S-glasses | 15.32 | 19.72 | 24.42 | 28.68 | 17.65 | 24.30 |
| Up-Cloth | 53.78 | 55.03 | 60.70 | 61.87 | 59.59 | 60.60 |
| Dress | 7.80 | 11.80 | 13.55 | 15.28 | 12.80 | 14.99 |
| Coat | 38.76 | 40.01 | 44.72 | 46.75 | 44.18 | 45.52 |
| Socks | 24.49 | 26.25 | 28.05 | 31.00 | 27.26 | 30.36 |
| Pants | 58.44 | 61.26 | 66.91 | 69.05 | 65.53 | 68.13 |
| Jumpsuits | 18.35 | 16.60 | 22.66 | 21.62 | 18.33 | 20.02 |
| Scarf | 4.03 | 5.21 | 5.07 | 7.69 | 6.35 | 8.02 |
| Skirt | 7.22 | 9.82 | 13.20 | 13.40 | 10.35 | 11.13 |
| Face | 71.20 | 72.85 | 74.61 | 77.17 | 73.12 | 75.71 |
| L arm | 45.13 | 48.54 | 52.84 | 54.95 | 49.76 | 52.72 |
| R arm | 49.26 | 52.32 | 54.66 | 58.36 | 53.40 | 56.30 |
| L leg | 33.34 | 34.28 | 43.20 | 43.68 | 37.26 | 40.55 |
| R leg | 32.67 | 35.24 | 41.72 | 44.27 | 40.08 | 41.66 |
| L shoe | 15.12 | 17.56 | 22.58 | 24.96 | 17.97 | 21.96 |
| R shoe | 12.14 | 17.69 | 21.49 | 25.06 | 17.68 | 21.58 |
| Avg | 29.88 | 32.10 | 35.53 | 38.28 | 33.80 | 36.48 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zuo, H.; Han, P. A Universal Decoupled Training Framework for Human Parsing. Sensors 2022, 22, 5964. https://doi.org/10.3390/s22165964
Li Y, Zuo H, Han P. A Universal Decoupled Training Framework for Human Parsing. Sensors. 2022; 22(16):5964. https://doi.org/10.3390/s22165964
Chicago/Turabian StyleLi, Yang, Huahong Zuo, and Ping Han. 2022. "A Universal Decoupled Training Framework for Human Parsing" Sensors 22, no. 16: 5964. https://doi.org/10.3390/s22165964