
Crop Mapping Using the Historical Crop Data Layer and Deep Neural Networks: A Case Study in Jilin Province, China


Abstract
:1. Introduction
- (1)
- Which algorithm has the highest classification accuracy for crop mapping, thus comparing four classification algorithms namely SVM, DT, RF, and DNN?
- (2)
- Which month of the crop’s entire growing period has the highest crop mapping accuracy?
- (3)
- What is the accuracy of crop mapping during the entire growing period of the crop?
- (4)
- How consistent is the generated product compared to the existing product?
2. Materials and Methods
2.1. Study Area
2.2. Material
2.2.1. Remote Sensing Data
2.2.2. Ground Truth Data
2.2.3. Validation Data
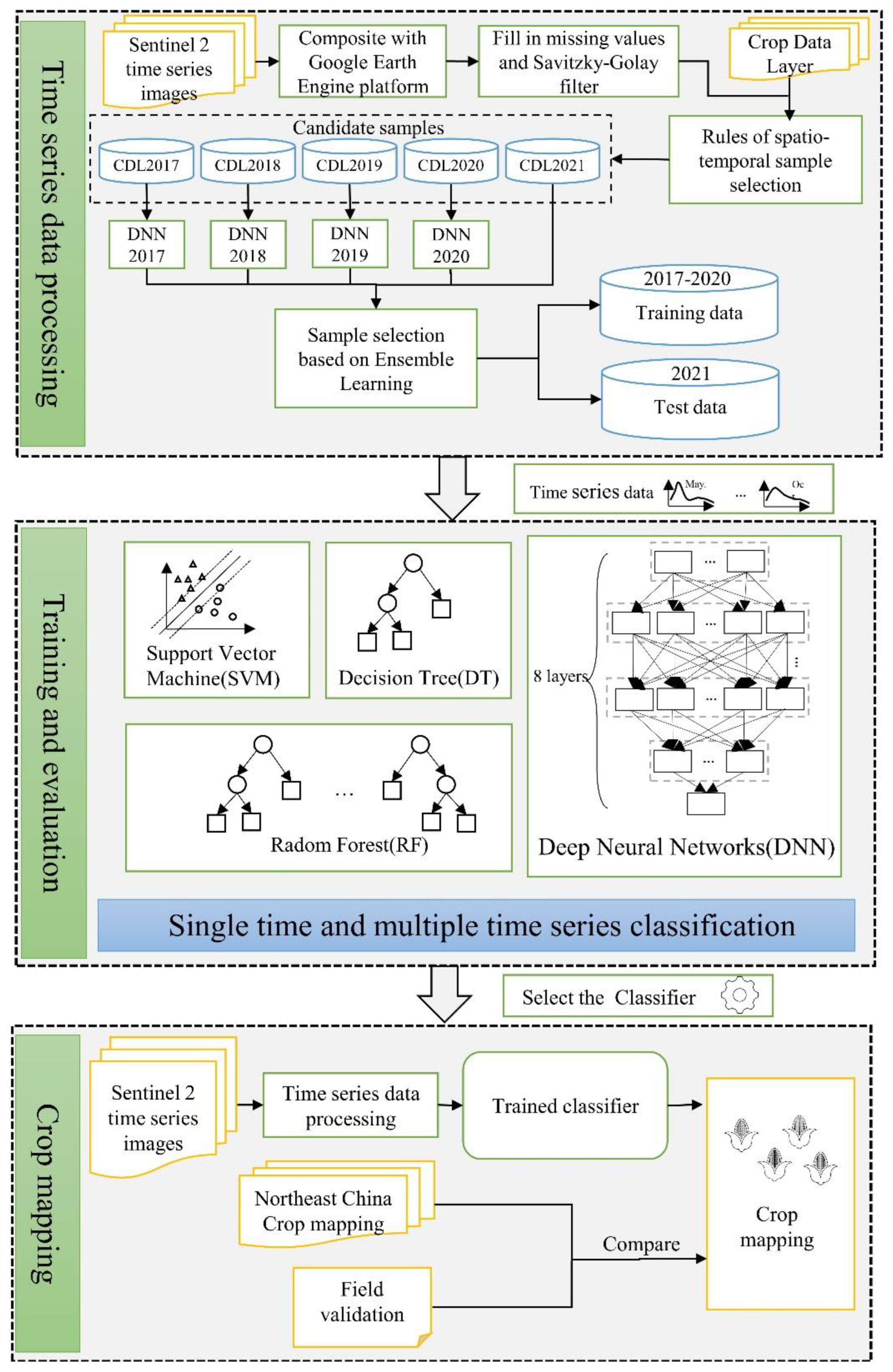
2.3. Methodology
2.3.1. Time Series Data Processing
2.3.2. Training and Accuracy Evaluation
2.3.3. Crop Mapping
3. Results
3.1. Generating Sample Data Sets Based on Ensemble Learning
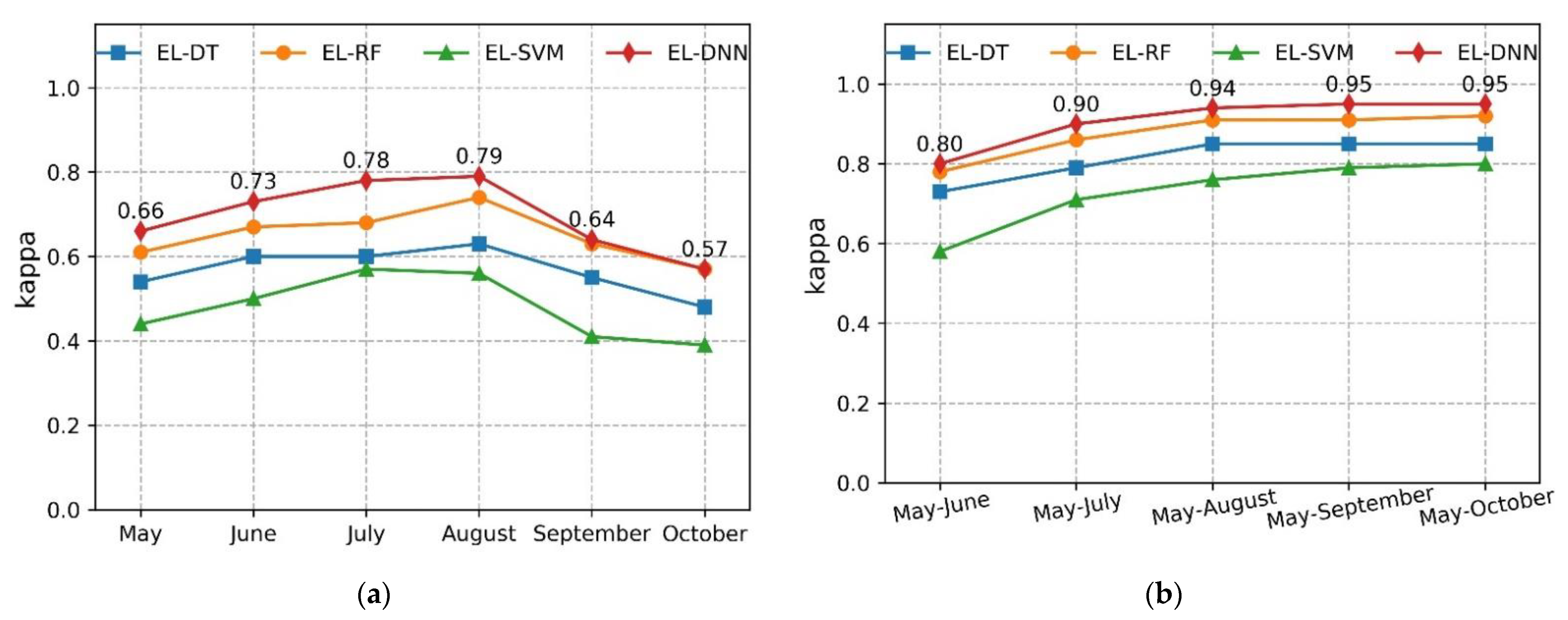
3.2. Comparison of the Accuracy of Different Classifiers
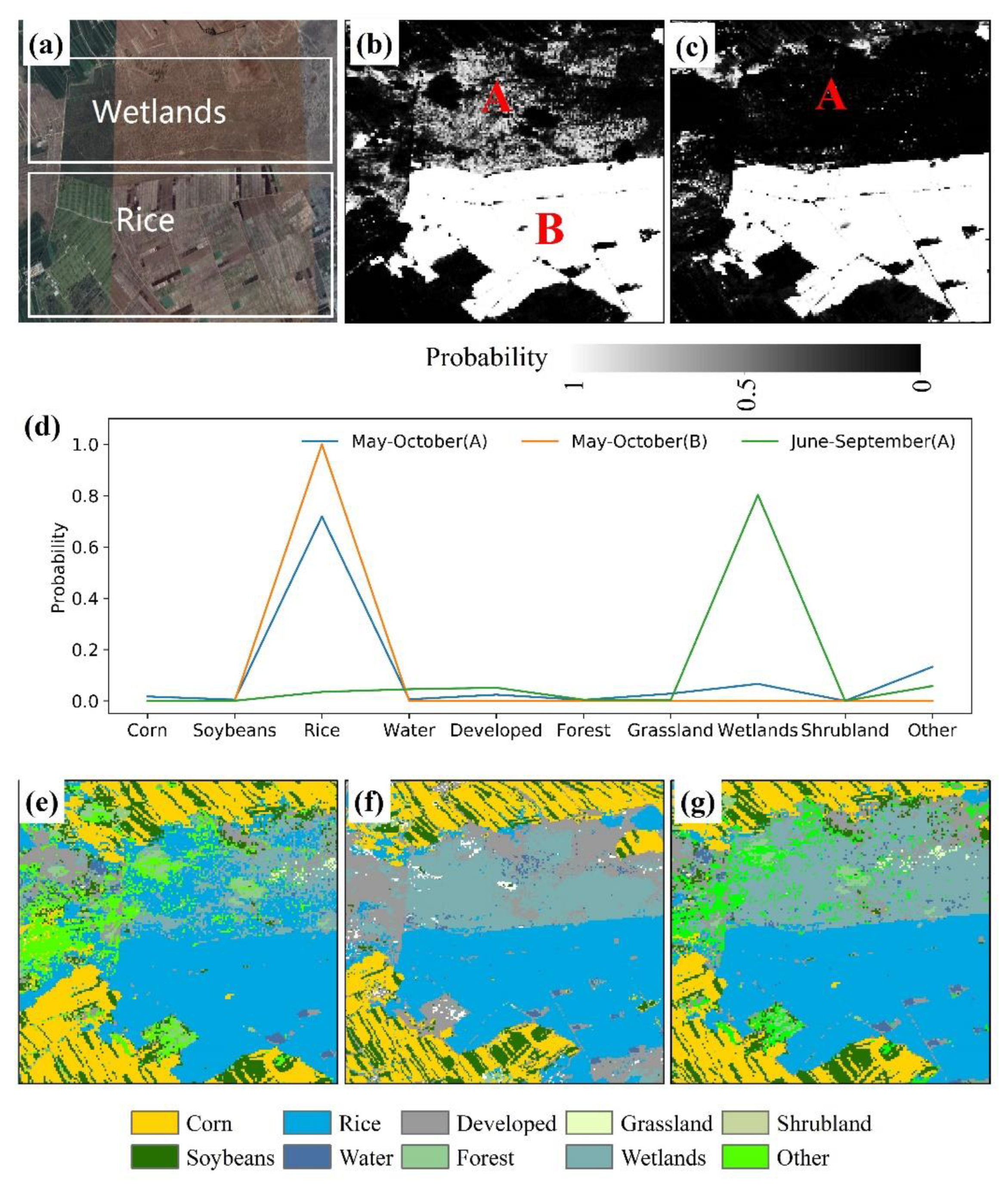
3.3. Comparison between EL-DNN and Northeast China Products
4. Discussion
5. Conclusions
- The error of data labeling is the main factor affecting classification accuracy. The kappa coefficient of the classification accuracy of the samples selected by ensemble learning in the whole growth period is improved from 0.85 to 0.95. Most of the removed samples are non-agricultural land covers with large errors. This shows that the ensemble learning method can obtain high-precision samples and remove most of the mislabeled samples.
- Compared with the four main machine learning algorithms, DNN is higher than DT, RF, and SVM. This proves that DNN can learn more complex features and has significant advantages in processing massive data.
- Comparing the results of single-phase and multi-phase classification, July and August have the highest accuracy, which can be used as the key period for crop classification. During the whole growing period of crops, with the growth of the time series, the classification accuracy of the three crop types was higher than 95% until August, and with the growth of the time series, the overall accuracy did not improve significantly.
- The crop distribution products generated by our method can achieve relatively consistent accuracy with the existing products. Rice and corn have higher consistency, and soybean consistency is poor. Wetlands may be misclassified as rice due to the influence of precipitation, which can be corrected by combining the classification results of sequences of different lengths. Soybeans are more difficult to distinguish from other crop types.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stevens, T.; Madani, K. Future climate impacts on maize farming and food security in Malawi. Sci. Rep. 2016, 6, 36241. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, F.; Anderson, M.; Daughtry, C.; Johnson, D. Assessing the Variability of Corn and Soybean Yields in Central Iowa Using High Spatiotemporal Resolution Multi-Satellite Imagery. Remote Sens. 2018, 10, 1489. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, P.; Nendel, C.; Hostert, P. Intra-annual reflectance composites from Sentinel-2 and Landsat for national-scale crop and land cover mapping. Remote Sens. Environ. 2019, 220, 135–151. [Google Scholar] [CrossRef]
- Boryan, C.; Yang, Z.W.; Mueller, R.; Craig, M. Monitoring US agriculture: The US Department of Agriculture, National Agricultural Statistics Service, Cropland Data Layer Program. Geocarto Int. 2011, 26, 341–358. [Google Scholar] [CrossRef]
- Blaes, X.; Vanhalle, L.; Defourny, P. Efficiency of crop identification based on optical and SAR image time series. Remote Sens. Environ. 2005, 96, 352–365. [Google Scholar] [CrossRef]
- Allen, J.D.; Hanuschak, G.A. The remote sensing applications program of the National Agricultural Statistics Service: 1980–1987. J. Off. Stat. 1990, 6, 1–47. [Google Scholar]
- Zhang, D.Y.; Fang, S.M.; She, B.; Zhang, H.H.; Jin, N.; Xia, H.M.; Yang, Y.Y.; Ding, Y. Winter Wheat Mapping Based on Sentinel-2 Data in Heterogeneous Planting Conditions. Remote Sens. 2019, 11, 2647. [Google Scholar] [CrossRef] [Green Version]
- Fisette, T.; Rollin, P.; Aly, Z.; Campbell, L.; Daneshfar, B.; Filyer, P.; Smith, A.; Davidson, A.; Shang, J.; Jarvis, I. AAFC Annual Crop Inventory. In Proceedings of the 2013 Second International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Fairfax, VA, USA, 12–16 August 2013; pp. 270–274. [Google Scholar]
- You, N.; Dong, J.; Huang, J.; Du, G.; Zhang, G.; He, Y.; Yang, T.; Di, Y.; Xiao, X. The 10-m crop type maps in Northeast China during 2017–2019. Sci. Data 2021, 8, 41. [Google Scholar] [CrossRef]
- Johnson, D.M. Using the Landsat archive to map crop cover history across the United States. Remote Sens. Environ. 2019, 232, 111286. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.G.; Dungan, J.L.; Vermote, E.F.; Roger, J.C.; Skakun, S.V.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Yang, C.; Everitt, J.; Murden, D. Evaluating high resolution SPOT 5 satellite imagery for crop identification. Comput. Electron. Agric. 2011, 75, 347–354. [Google Scholar] [CrossRef]
- Cai, Y.P.; Guan, K.Y.; Peng, J.; Wang, S.W.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Zhong, L.; Gong, P.; Biging, G. Efficient corn and soybean mapping with temporal extendability: A multi-year experiment using Landsat imagery. Remote Sens. Environ. 2014, 140, 1–13. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of Hyperspectral Remote Sensing Images with Support Vector Machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.D.; Liao, C.H.; Xing, M.F.; Ziniti, B.; Wang, J.F.; Shang, J.L.; Liu, J.G.; Dong, T.F.; Xie, Q.H.; Torbick, N. A multi-temporal binary-tree classification using polarimetric RADARSAT-2 imagery. Remote Sens. Environ. 2019, 235, 111478. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Wardlow, B.; Egbert, S. Large-area crop mapping using time-series MODIS 250 m NDVI data: An assessment for the U.S. Central Great Plains. Remote Sens. Environ. 2008, 112, 1096–1116. [Google Scholar] [CrossRef]
- Tang, K.; Zhu, W.; Zhan, P.; Ding, S. An Identification Method for Spring Maize in Northeast China Based on Spectral and Phenological Features. Remote Sens. 2018, 10, 193. [Google Scholar] [CrossRef] [Green Version]
- Xi, W.; Du, S.; Wang, Y.-C.; Zhang, X. A spatiotemporal cube model for analyzing satellite image time series: Application to land-cover mapping and change detection. Remote Sens. Environ. 2019, 231, 111212. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Zhang, H.K.; Roy, D.P. Using the 500m MODIS land cover product to derive a consistent continental scale 30 m Landsat land cover classification. Remote Sens. Environ. 2017, 197, 15–34. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. DeepCropMapping: A multi-temporal deep learning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.C.; Zhao, Y.Y.; Liang, L.; Niu, Z.G.; Huang, X.M.; Fu, H.H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Lin, C.; Zhong, L.; Song, X.-P.; Dong, J.; Lobell, D.B.; Jin, Z. Early- and in-season crop type mapping without current-year ground truth: Generating labels from historical information via a topology-based approach. Remote Sens. Environ. 2022, 274, 112994. [Google Scholar] [CrossRef]
- Dai, X.Y.; Wu, X.F.; Wang, B.; Zhang, L.M. Semisupervised Scene Classification for Remote Sensing Images: A Method Based on Convolutional Neural Networks and Ensemble Learning. IEEE Geosci. Remote Sens. Lett. 2019, 16, 869–873. [Google Scholar] [CrossRef]
- Han, M.; Liu, B. Ensemble of extreme learning machine for remote sensing image classification. Neurocomputing 2015, 149, 65–70. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Pal, M. Ensemble Learning with Decision Tree for Remote Sensing Classification. World Acad. Sci. Eng. Technol. 2007, 26, 735–737. [Google Scholar]
- Raudys, Š.; Roli, F. The Behavior Knowledge Space Fusion Method: Analysis of Generalization Error and Strategies for Performance Improvement. In Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2003; pp. 55–64. [Google Scholar]
- Zhao, J.; Yang, X.; Liu, Z.; Lv, S.; Wang, J.; Dai, S. Variations in the potential climatic suitability distribution patterns and grain yields for spring maize in Northeast China under climate change. Clim. Chang. 2016, 137, 29–42. [Google Scholar] [CrossRef]
- Zhao, J.; Li, K.; Rui, W.; Tong, Z.; Zhang, J. Yield Data Provide New Insight into the Dynamic Evaluation of Maize’s Climate Suitability: A Case Study in Jilin Province, China. Atmosphere 2019, 10, 305. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Qin, L.; He, H. Characteristics of the water footprint of rice production under different rainfall years in Jilin Province, China. J. Sci. Food Agric. 2018, 98, 3001–3013. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Xie, S.; Liu, L.; Zhang, X.; Yang, J.; Chen, X.; Gao, Y. Automatic Land-Cover Mapping using Landsat Time-Series Data based on Google Earth Engine. Remote Sens. 2019, 11, 3023. [Google Scholar] [CrossRef] [Green Version]
- Gorry, P.A. General least-squares smoothing and differentiation of nonuniformly spaced data by the convolution method. Anal. Chem. 2002, 63, 534–536. [Google Scholar] [CrossRef]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Chang, J.; Hansen, M.C.; Pittman, K.; Carroll, M.; DiMiceli, C. Corn and Soybean Mapping in the United States Using MODIS Time-Series Data Sets. Agron. J. 2007, 99, 1654–1664. [Google Scholar] [CrossRef]
- Lark, T.J.; Mueller, R.M.; Johnson, D.M.; Gibbs, H.K. Measuring land-use and land-cover change using the U.S. department of agriculture’s cropland data layer: Cautions and recommendations. Int. J. Appl. Earth Obs. Geoinform. 2017, 62, 224–235. [Google Scholar] [CrossRef]
- Jamal, P.; Ali, M.; Faraj, R.; Muhammad Ali, P. Data Normalization and Standardization: A Technical Report. Mach. Learn. Tech. Rep. 2014, 1, 1–6. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Proc. Mach. Learn Res. 2015, 37, 448–456. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Strahler, A.; Boschetti, L.; Foody, G.; Friedl, M.; Hansen, M.; Herold, M.; Mayaux, P.; Morisette, J.; Stehman, S.; Woodcock, C. Global Land Cover Validation: Recommendations for Evaluation and Accuracy Assessment of Global Land Cover Maps. Eur. Commun. Luxemb. 2006, 51, 1–60. [Google Scholar]
- Friedl, M.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 Global Land Cover: Algorithm Refinements and Characterization of new Datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Gao, F.; Anderson, M.C.; Zhang, X.; Yang, Z.; Alfieri, J.G.; Kustas, W.P.; Mueller, R.; Johnson, D.M.; Prueger, J.H. Toward mapping crop progress at field scales through fusion of Landsat and MODIS imagery. Remote Sens. Environ. 2017, 188, 9–25. [Google Scholar] [CrossRef] [Green Version]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Tatsumi, K.; Yamashiki, Y.; Canales Torres, M.A.; Taipe, C.L.R. Crop classification of upland fields using Random forest of time-series Landsat 7 ETM+ data. Comput. Electron. Agric. 2015, 115, 171–179. [Google Scholar] [CrossRef]
- Joshi, N.; Baumann, M.; Ehammer, A.; Fensholt, R.; Grogan, K.; Hostert, P.; Jepsen, M.; Kuemmerle, T.; Meyfroidt, P.; Mitchard, E.; et al. A Review of the Application of Optical and Radar Remote Sensing Data Fusion to Land Use Mapping and Monitoring. Remote Sens. 2016, 8, 70. [Google Scholar] [CrossRef] [Green Version]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Juba, B.; Le, H. Precision-Recall versus Accuracy and the Role of Large Data Sets. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4039–4048. [Google Scholar] [CrossRef] [Green Version]
- Wickham, J.D.; Stehman, S.V.; Gass, L.; Dewitz, J.; Sorenson, D.G.; Granneman, B.; Poss, R.V.; Baer, L.A. Thematic accuracy assessment of the 2011 National Land Cover Database (NLCD). Remote Sens. Environ. 2017, 191, 328–341. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CDL Value | New Value | Name |
|---|---|---|
| 1 (Corn), 12 (Sweet Corn), 13 (Pop or Orn Corn) | 1 | Corn |
| 5 (Soybeans) | 2 | Soybeans |
| 3 (Rice) | 3 | Rice |
| 83 (Water), 92 (Aquaculture), 111 (Open Water), 112 (Perennial Ice/Snow) | 4 | Water |
| 121 (Developed/Open Space), 122 (Developed/Low Intensity), 123 (Developed/Med Intensity), 124 (Developed/High Intensity) | 5 | Developed |
| 63 (Forest), 141 (Deciduous Forest), 142 (Evergreen Forest), 143 (Mixed Forest) | 6 | Forest |
| 176 (Grassland/Pasture), 59 (Sod/Grass Seed) | 7 | Grassland |
| 87 (Wetlands), 190 (Woody Wetlands), 195 (Herbaceous Wetlands) | 8 | Wetlands |
| 64 (Shrubland), 152 (Shrubland) | 9 | Shrubland |
| Other values | 10 | Other |
| Classifier | Parameters | Description | GridSearch Values | Search Result | OA | Kappa |
|---|---|---|---|---|---|---|
| SVM | C | Regularization parameter | 0.01, 0.1, 1, 5, 10, 50, 100, 500 | 500 | 0.71 | 0.65 |
| DT | Criterion | The function to measure the quality of a split. | Gini, entropy | Gini | 0.81 | 0.76 |
| max_depth | The maximum depth of the tree. | 10, 50, 100, 200 | 50 | |||
| min_samples_leaf | The minimum number of samples required to be at a leaf node. | 10, 50, 100, 200 | 10 | |||
| min_impurity_split | Threshold for early stopping in tree growth. | 0.001, 0.01, 0.1 | 0.001 | |||
| RF | n_estimators | The number of trees in the forest. | 50, 100, 200 | 100 | 0.85 | 0.83 |
| max_depth | The maximum depth of the tree. | 10, 50, 100, 200 | 100 | |||
| min_samples_leaf | The minimum number of samples required to be at a leaf node. | 10, 50, 100, 200 | 10 | |||
| min_impurity_split | Threshold for early stopping in tree growth. | 0.001, 0.01, 0.1 | 0.001 | |||
| DNN | learning_ rate | Learning rate schedule for weight updates. | 0.001, 0.01, 0.1 | 0.001 | 0.88 | 0.85 |
| optimizer | Optimizer algorithm. | SGD, Adam | Adam | |||
| activation | Activation function of the hidden layer. | relu, tanh | Tanh | |||
| layers | Number of network layers. | 5, 7, 8 | 8 | |||
| Batch | Randomly sampled for each training. | 1000, 4000, 8000 | 8000 |
| Year | SVM | DT | RF | DNN |
|---|---|---|---|---|
| 2017 | 42 | 52 | 25 | 24 |
| 2018 | 36 | 45 | 19 | 18 |
| 2019 | 36 | 46 | 18 | 16 |
| 2020 | 37 | 45 | 18 | 17 |
| 2021 | 36 | 48 | 24 | 25 |
| Mean | 37 | 47 | 21 | 20 |
| Year | Corn | Soybeans | Rice | Water | Developed | Forest | Grassland | Wetlands | Shrubland | Other |
|---|---|---|---|---|---|---|---|---|---|---|
| 2017 | 17 | 24 | 12 | 24 | 34 | 39 | 24 | 45 | 30 | 23 |
| 2018 | 8 | 17 | 4 | 14 | 27 | 42 | 32 | 52 | 32 | 15 |
| 2019 | 13 | 9 | 7 | 12 | 30 | 22 | 41 | 27 | 20 | 13 |
| 2020 | 9 | 17 | 6 | 14 | 27 | 27 | 34 | 48 | 32 | 14 |
| 2021 | 15 | 22 | 5 | 13 | 33 | 38 | 28 | 32 | 32 | 30 |
| Mean | 12 | 17 | 6 | 15 | 30 | 33 | 31 | 40 | 29 | 19 |
| Year | Indicators | EL-DNN | Northeast China | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Corn | Soybeans | Rice | Other | Corn | Soybeans | Rice | Other | ||
| 2017 | PA | 79 | 63 | 84 | 98 | 82 | 57 | 90 | 93 |
| UA | 76 | 64 | 98 | 95 | 66 | 37 | 95 | 96 | |
| OA | 93 | 90 | |||||||
| Kappa | 0.84 | 0.78 | |||||||
| 2018 | PA | 86 | 72 | 87 | 98 | 88 | 73 | 82 | 96 |
| UA | 87 | 54 | 96 | 98 | 88 | 48 | 94 | 98 | |
| OA | 93 | 92 | |||||||
| Kappa | 0.87 | 0.84 | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, D.; Chen, S.; Useya, J.; Cao, L.; Lu, T. Crop Mapping Using the Historical Crop Data Layer and Deep Neural Networks: A Case Study in Jilin Province, China. Sensors 2022, 22, 5853. https://doi.org/10.3390/s22155853
Jiang D, Chen S, Useya J, Cao L, Lu T. Crop Mapping Using the Historical Crop Data Layer and Deep Neural Networks: A Case Study in Jilin Province, China. Sensors. 2022; 22(15):5853. https://doi.org/10.3390/s22155853
Chicago/Turabian StyleJiang, Deyang, Shengbo Chen, Juliana Useya, Lisai Cao, and Tianqi Lu. 2022. "Crop Mapping Using the Historical Crop Data Layer and Deep Neural Networks: A Case Study in Jilin Province, China" Sensors 22, no. 15: 5853. https://doi.org/10.3390/s22155853