
Assessment of Various Machine Learning Models for Peach Maturity Prediction Using Non-Destructive Sensor Data

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Physico-Chemical Properties of Fruits
2.1.1. Ground (GC) and Additional (AC) Fruit Skin Color
2.1.2. Fruit Weight, Width, Length, Shape Index, Diameter, Volume, and Density
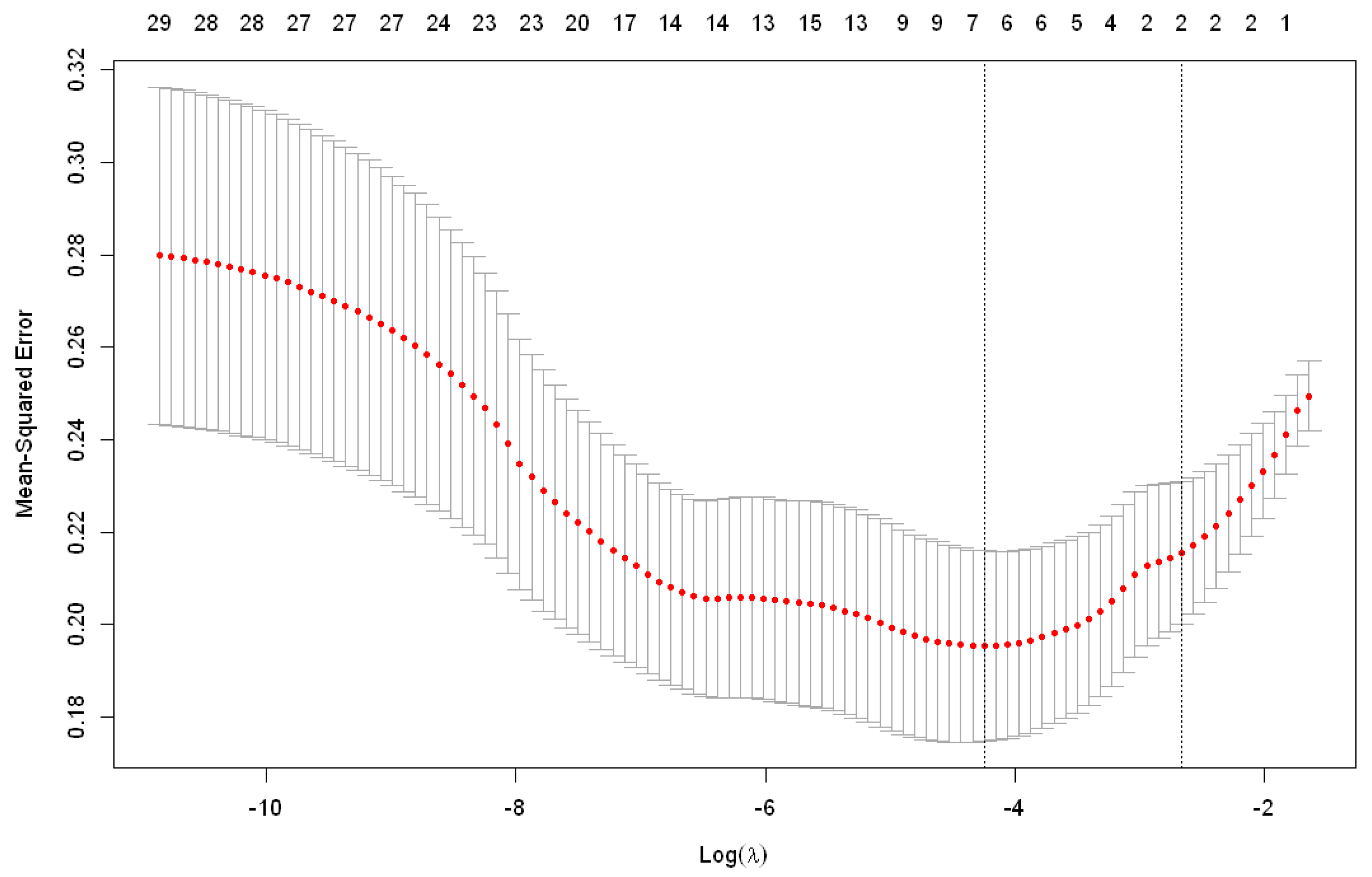
2.2. Dataset and LASSO
2.2.1. LASSO
2.2.2. Dimension Reduction Using Group LASSO
2.3. Training the Machine Learning Models
- LR and LDA (simple linear models),
- KNN and CART (nonlinear models),
- SVM, RF, and GBM (complex nonlinear models), and
- ANN (deep learning model).
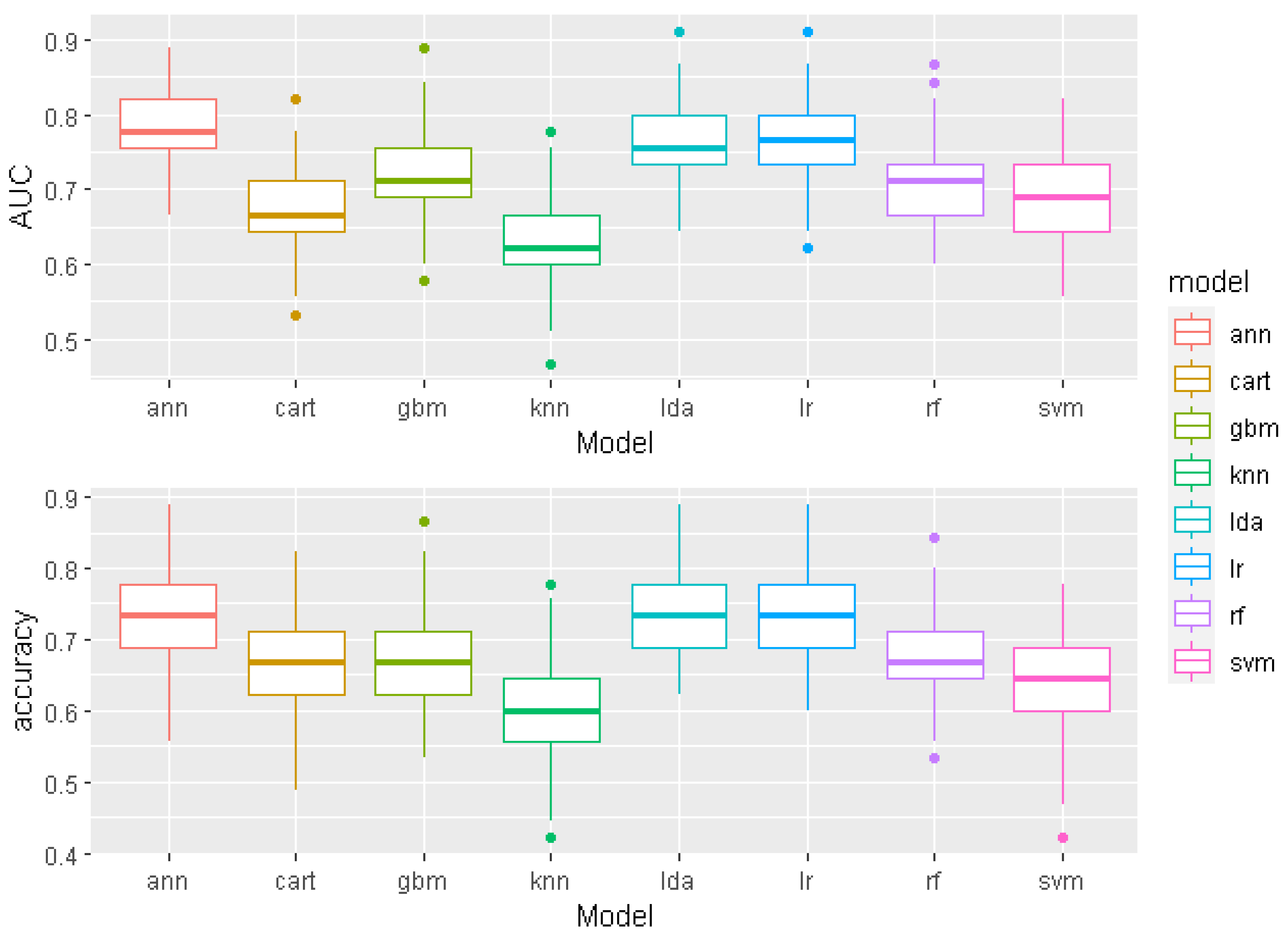
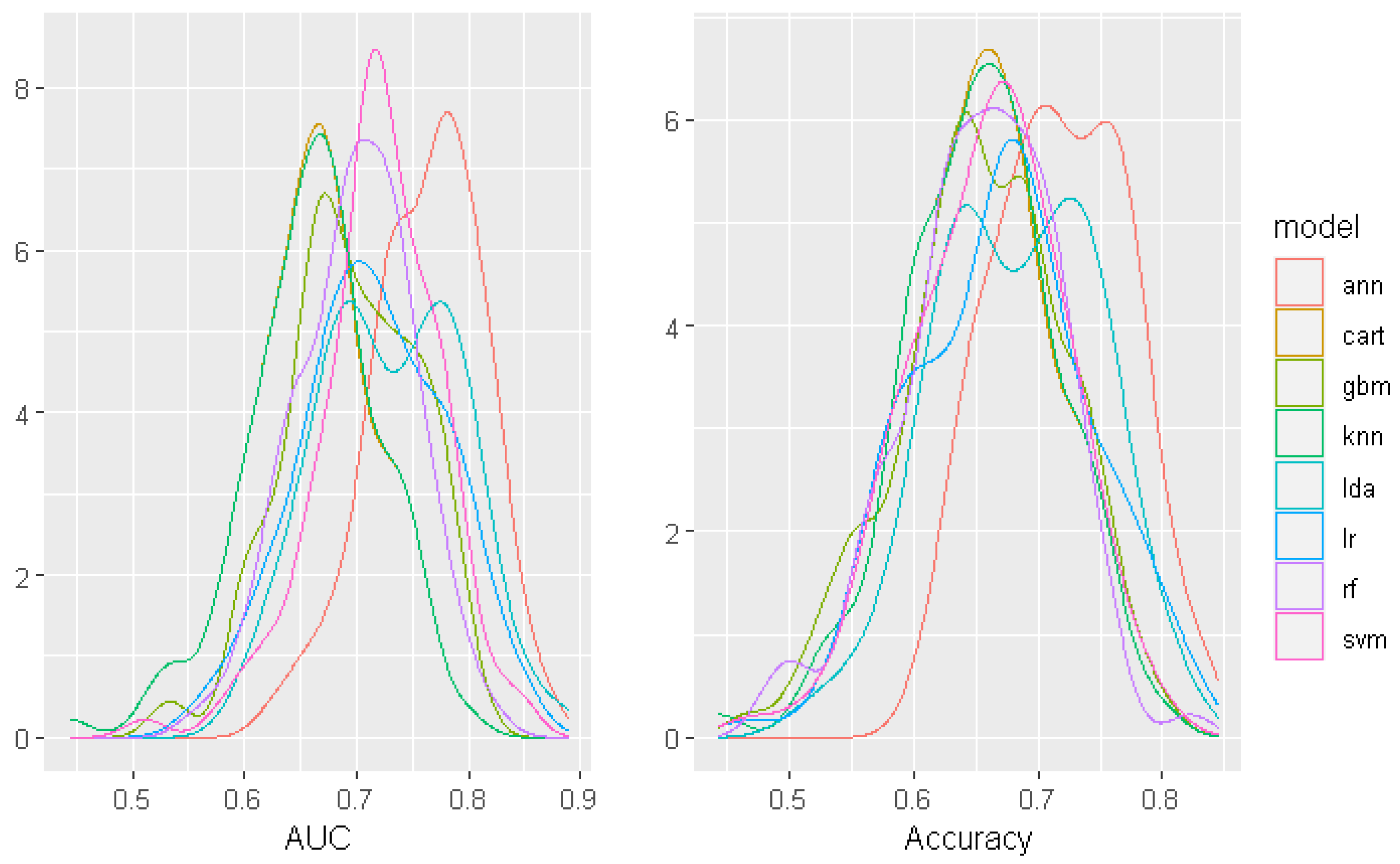
3. Results
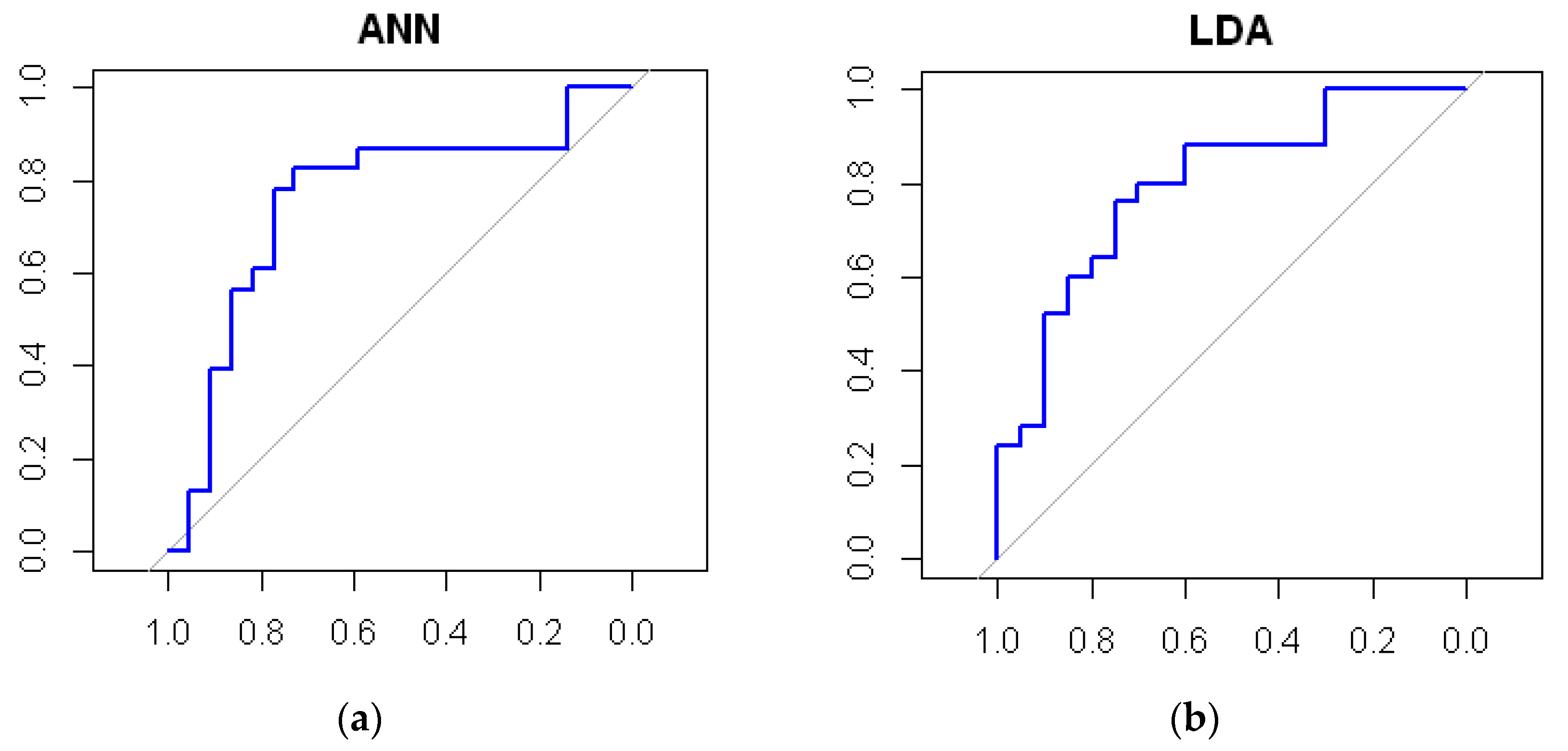
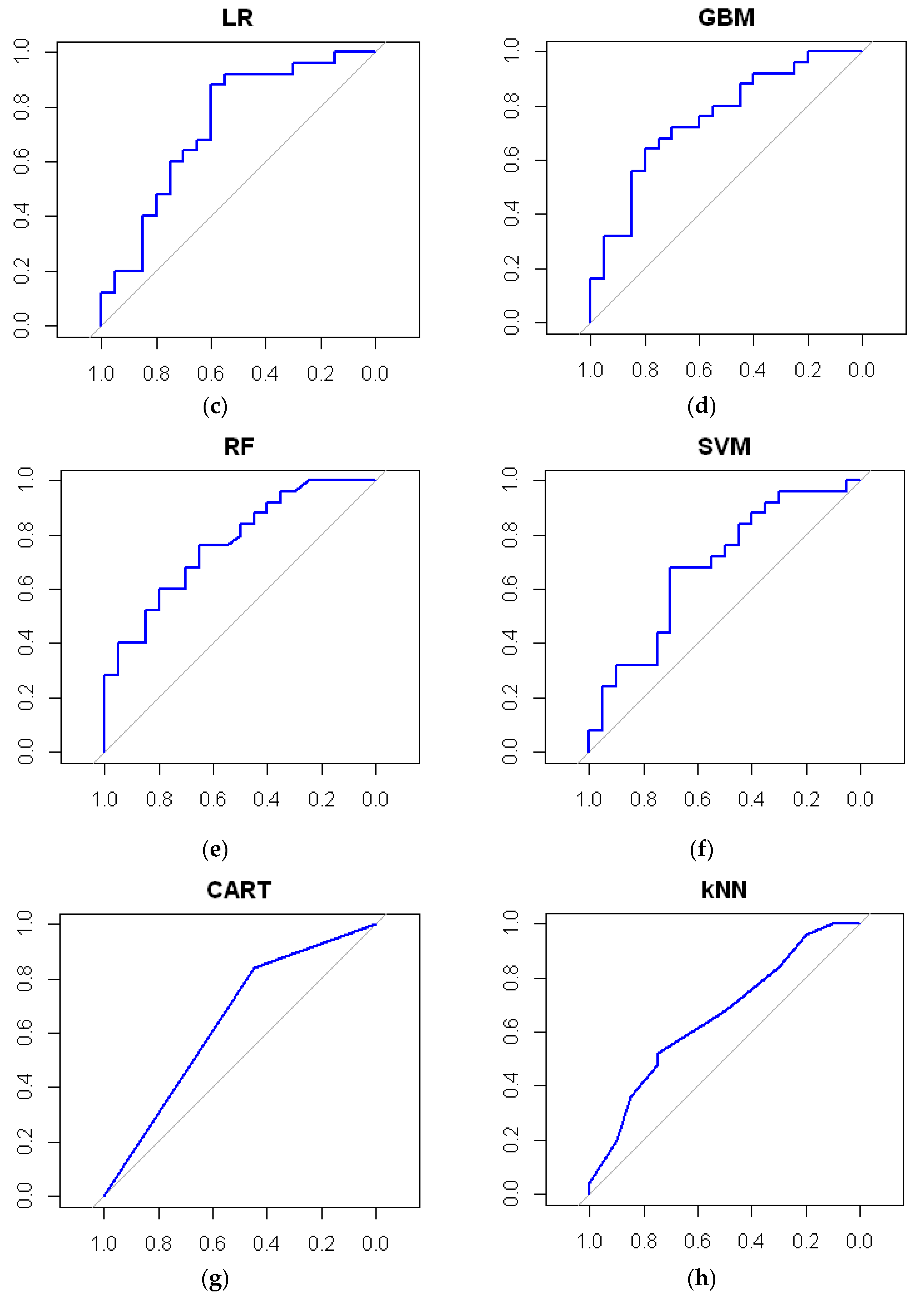
3.1. Representative Models
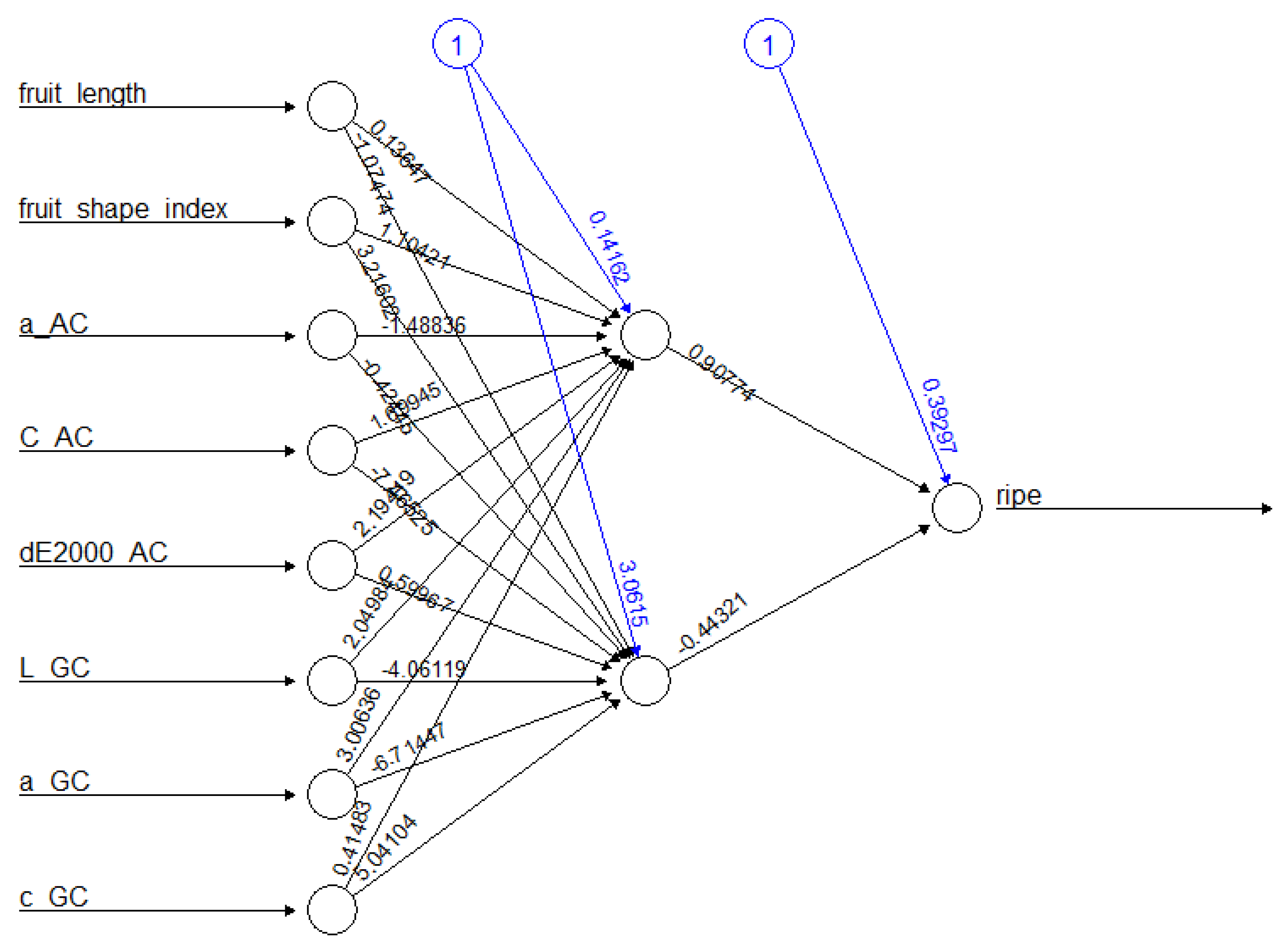
3.2. The Best Model—ANN
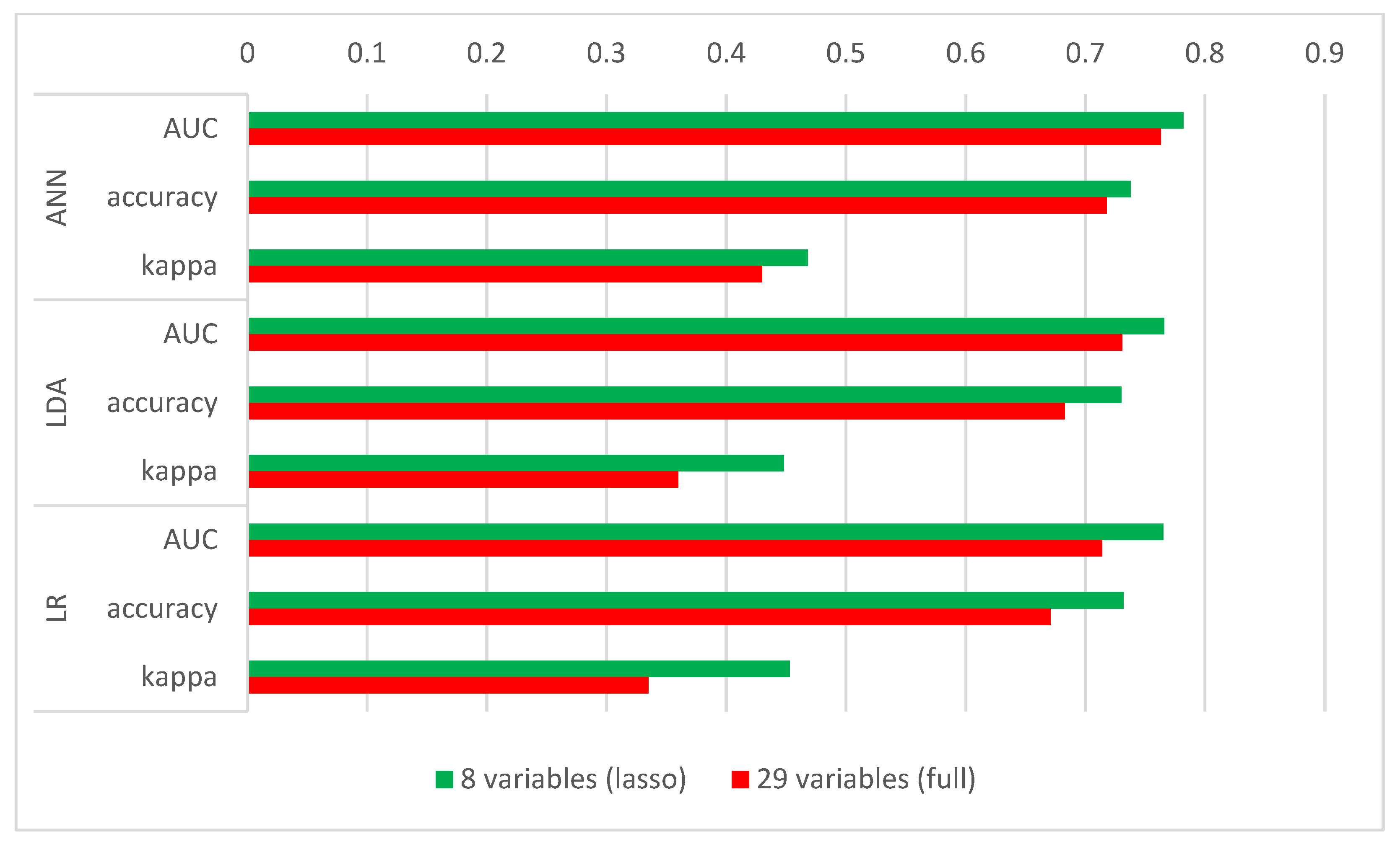
3.3. Training the Model on the Entire Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Variable Name | Description | Group |
|---|---|---|---|
| fruit firmness | firmness | peach firmness | output var. |
| fruit weight | fruit_weight | peach weight | 1 |
| fruit width | fruit_width | peach width | 1 |
| fruit length | fruit_length | peach length | 1 |
| fruit shape index | fruit_shape_index | peach shape index | 1 |
| fruit diameter | fruit_diameter | peach diameter | 1 |
| fruit volume | fruit_volume | peach volume | 1 |
| fruit density | fruit_density | peach density | 1 |
| L*-AC | L_AC | L* variable of additional fruit color | 2 |
| a*-AC | a_AC | a* variable of additional fruit color | 2 |
| b*-AC | b_AC | b* variable of additional fruit color | 2 |
| C*-AC | C_AC | C* variable of additional fruit color | 2 |
| h°-AC | h_AC | h° variable of additional fruit color | 2 |
| a*/b*-AC | a.b_AC | a*/b* additional color index | 2 |
| CCI-AC | CCI_AC | CCL additional color index | 2 |
| COL-AC | COL_AC | COL additional color index | 2 |
| CIRG1-AC | CIRG1_AC | CIRG1 additional color index | 2 |
| CIRG2-AC | CIRG2_AC | CIRG2 additional color index | 2 |
| dE2000-AC | dE2000_AC | dE2000 for additional color | 2 |
| L*-GC | L_GC | L* variable of ground fruit color | 3 |
| a*-GC | a_GC | a* variable of ground fruit color | 3 |
| b*-GC | b_GC | b* variable of ground fruit color | 3 |
| C*-GC | c_GC | C* variable of ground fruit color | 3 |
| h°-GC | h_GC | h° variable of ground fruit color | 3 |
| a*/b*-GC | a.b_GC | a*/b* ground color index | 3 |
| CCI-GC | CCI_GC | CCL ground color index | 3 |
| COL-GC | COL_GC | COL ground color index | 3 |
| CIRG1-GC | CIRG1_GC | CIRG1 ground color index | 3 |
| CIRG2-GC | CIRG2_GC | CIRG2 ground color index | 3 |
| dE2000-GC | dE2000_GC | dE2000 for ground color | 3 |
References
- Crisosto, C.H.H.; Costa, G. Preharvest factors affecting peach quality. In The Peach: Botany, Production and Uses; Layne, D.R., Bassi, D., Eds.; CAB International: Oxford, UK, 2008; pp. 536–549. [Google Scholar] [CrossRef] [Green Version]
- Shinya, P.; Contador, L.; Predieri, S.; Rubio, P.; Infante, R. Peach ripening: Segregation at harvest and postharvest flesh softening. Postharvest Biol. Technol. 2013, 86, 472–478. [Google Scholar] [CrossRef]
- Infante, R.; Aros, D.; Contador, L.; Rubio, P. Does the maturity at harvest affect quality and sensory attributes of peaches and nectarines? N. Z. J. Crop Hortic. Sci. 2012, 40, 103–113. [Google Scholar] [CrossRef]
- Ferrer, A.; Remón, S.; Negueruela, A.I.; Oria, R. Changes during the ripening of the very late season Spanish peach cultivar Calanda: Feasibility of using CIELAB coordinates as maturity indices. Sci. Hortic. 2005, 105, 435–446. [Google Scholar] [CrossRef]
- Crisosto, C.H. How do we increase peach consumption? Acta Hortic. 2002, 592, 601–605. [Google Scholar] [CrossRef]
- Minas, I.S.; Tanou, G.; Molassiotis, A. Environmental and orchard bases of peach fruit quality. Sci. Hortic. 2018, 235, 307–322. [Google Scholar] [CrossRef]
- Ramina, A.; Tonutti, P.; McGlasson, W.; McGlasson, B. Ripening, nutrition and postharvest physiology. In The Peach, Botany, Production and Uses; Layne, D.R., Bassi, D., Eds.; CAB International: Oxford, UK, 2008; pp. 550–574. [Google Scholar] [CrossRef]
- Ceccarelli, A.; Farneti, B.; Frisina, C.; Allen, D.; Donati, I.; Cellini, A.; Costa, G.; Spinelli, F.; Stefanelli, D. Harvest maturity stage and cold storage length influence on flavour development in peach fruit. Agronomy 2019, 9, 10. [Google Scholar] [CrossRef] [Green Version]
- Kao, M.W.S.; Brecht, J.K.; Williamson, J.G. Optimum harvest of low-chill melting and non-melting flesh peach cultivars for direct ripening and ripening following low temperature storage. HortScience 2020, 55, 487–495. [Google Scholar] [CrossRef]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Ljubobratović, D.; Matetić, M.; Vuković, M.; Brkić Bakarić, M.; Jemrić, T. Utilization of Explainable Machine Learning Algorithms for Determination of Important Features in ‘Suncrest’ Peach. Electronics 2021, 10, 3115. [Google Scholar] [CrossRef]
- Scalisi, A.; Pelliccia, D.; O’connell, M.G. Maturity prediction in yellow peach (Prunus persica l.) cultivars using a fluorescence spectrometer. Sensors 2020, 20, 6555. [Google Scholar] [CrossRef]
- Shah, A.S.S.; Zeb, A.; Qureshi, W.S.; Arslan, M.; Malik, A.U.; Alasmary, W.; Alanazi, E. Towards fruit maturity estimation using NIR spectroscopy. Infrared Phys. Technol. 2020, 111, 103479. [Google Scholar] [CrossRef]
- Ljubobratović, D.; Zhang, G.; Brkić Bakarić, M.; Jemrić, T.; Matetić, M. Predicting peach fruit ripeness using explainable machine learning. In Proceedings of the 31st International DAAAM Symposium, Mostar, Bosnia and Herzegovina, 21–24 October 2020; pp. 717–723. [Google Scholar] [CrossRef]
- Zhong, Y.; Bao, Y.; Ye, J.; Liu, J.; Liu, H. Combination of unsupervised and supervised models to predict the maturity of peaches during shelf-life. J. Food Process. Preserv. 2021, 45, e15624. [Google Scholar] [CrossRef]
- Voss, H.G.J.; Ayub, R.A.; Stevan, S.L. E-nose Prototype to Monitoring the Growth and Maturation of Peaches in the Orchard. IEEE Sens. J. 2020, 20, 11741–11750. [Google Scholar] [CrossRef]
- Furferi, R.; Governi, L.; Volpe, Y. ANN-based method for olive Ripening Index automatic prediction. J. Food Eng. 2010, 101, 318–328. [Google Scholar] [CrossRef] [Green Version]
- Mazen, F.M.A.; Nashat, A.A. Ripeness Classification of Bananas Using an Artificial Neural Network. Arab. J. Sci. Eng. 2019, 44, 6901–6910. [Google Scholar] [CrossRef]
- Hambali, H.A.; Abdullah, S.L.S.; Jamil, N.; Harun, H. Fruit classification using neural network model. J. Telecommun. Electron. Comput. Eng. 2017, 9, 43–46. [Google Scholar]
- Brezmes, J.; Fructuoso, M.L.L.; Llobet, E.; Vilanova, X.; Recasens, I.; Orts, J.; Saiz, G.; Correig, X. Evaluation of an electronic nose to assess fruit ripeness. IEEE Sens. J. 2005, 5, 97–108. [Google Scholar] [CrossRef] [Green Version]
- Rajkumar, P.; Wang, N.; Imasry, G.E.; Raghavan, G.S.V.; Gariepy, Y. Studies on banana fruit quality and maturity stages using hyperspectral imaging. J. Food Eng. 2012, 108, 194–200. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2021; 621p. [Google Scholar]
- Versari, A.; Castellari, M.; Parpinello, G.P.; Riponi, C.; Galassi, S. Characterisation of peach juices obtained from cultivars Redhaven, Suncrest and Maria Marta grown in Italy. Food Chem. 2002, 76, 181–185. [Google Scholar] [CrossRef]
- Krpina, I. Voćarstvo; Nakladni zavod Globus: Zagreb, Croatia, 2004. [Google Scholar]
- Miljković, I. Suvremeno Voćarstvo; Nakladni zavod Znanje: Zagreb, Croatia, 1991. [Google Scholar]
- Fruk, G.; Fruk, M.; Vuković, M.; Buhin, J.; Jatoi, M.A.; Jemrić, T. Colouration of apple cv. ‘Braeburn’ grown under anti-hail nets in Croatia. Acta Hortic. Et Regiotect. 2016, 19, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Carreño, J.; Martínez, A.; Almela, L.; Fernández-López, J.A. Proposal of an index for the objective evaluation of the colour of red table grapes. Food Res. Int. 1995, 28, 373–377. [Google Scholar] [CrossRef]
- Pedisić, S.; Levaj, B.; Verica, D.U.; Škevin, D.; Babojelić, M.S. Color parameters and total anthocyanins of sour cherries (Prunus Cerasus L.) during ripening. Agric. Conspec. Sci. 2009, 74, 259–262. [Google Scholar]
- Gao, Y.; Liu, Y.; Kan, C.; Chen, M.; Chen, J. Changes of peel color and fruit quality in navel orange fruits under different storage methods. Sci. Hortic. 2019, 256, 108522. [Google Scholar] [CrossRef]
- Camelo, A.F.L.; Gómez, P.A. Comparison of color indexes for tomato ripening. Hortic. Bras. 2004, 22, 534–537. [Google Scholar] [CrossRef]
- Little, A.C. A Research note: Off on a Tangent. J. Food Sci. 1975, 40, 410–411. [Google Scholar] [CrossRef]
- Jimenez-Cuesta, M.; Cuquerella, J.; Martinez-Javaga, J.M. Determination of a color index for citrus fruit degreening. In Proceedings of the International Society of Citriculture, Tokyo, Japan, 9–12 November 1981; pp. 750–753. [Google Scholar]
- Hobson, G.E. Low-temperature injury and the storage of ripening tomatoes. J. Hortic. Sci. 1987, 62, 55–62. [Google Scholar] [CrossRef]
- Neri, F.; Brigati, S. Sensory and objective evaluation of peaches. In Cost 94: The Postharvest Treatment of Fruit and Vegetables; Commission of the European Communities: Brussels, Belgium, 1994; pp. 107–115. [Google Scholar]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Huang, H.D.S. Scalability LASSO & PCA. In Data Analytics—A Small Data Approach; Chapman and Hall/CRC: Boca Raton, FL, USA, 2021; p. 26. [Google Scholar] [CrossRef]
- Muthukrishnan, R.; Rohini, R. LASSO: A feature selection technique in predictive modeling for machine learning. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications, ICACA 2016, Coimbatore, India, 24 October 2016; IEEE: New York, NY, USA, 2016; pp. 18–20. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model Selection and Estimation in Regression with Grouped Variables. J. R. Stat. Soc. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H.; Angeles, L.; Scientist, C.D. Cross validation. In Encyclopedia of Database Systems; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Chinchor, N. MUC-4 Evaluation Metrics. In Proceedings of the 4th Conference on Message Understanding, McLean, VA, USA, 16–18 June 1992; pp. 22–29. [Google Scholar] [CrossRef] [Green Version]
- Sasaki, Y.; Fellow, R. The truth of the F-measure. Teach Tutor Mater 2007, 1, 1–5. [Google Scholar]
- van Rijsbergen, C.J. Information Retrieval; Butterworths: Oxford, UK, 1975; Available online: https://books.google.hr/books?id=EJ2PQgAACAAJ (accessed on 12 March 2022).
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Ling, C.; Huang, J.; Zhang, H. AUC: A Better Measure Than Accuracy in Comparing Learning Algorithms; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2671, pp. 29–341. [Google Scholar] [CrossRef]
- Menard, S. Applied Logistic Regression Analysis; Sage: Thousand Oaks, CA, USA, 2002; Volume 106. [Google Scholar]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, X.R. Assessing the Fit of the Model. In Applied Logistic Regression, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013; pp. 153–225. [Google Scholar] [CrossRef]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear discriminant analysis: A detailed tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef] [Green Version]
- Xanthopoulos, P.; Pardalos, P.M.; Trafalis, T.B. Linear discriminant analysis. In Robust Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 27–33. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2888, pp. 86–996. [Google Scholar] [CrossRef]
- Timofeev, R. Classification and Regression Trees (CART) Theory and Applications Ferda; Humboldt University: Berlin, Germany, 2004. [Google Scholar]
- Yu, H.; Kim, S. SVM tutorial-classification, regression and ranking. Handb. Nat. Comput. 2012, 1–4, 479–506. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Kangas, L.J.; Rasco, B.A. Applications of Artificial Neural Networks (ANNs) in food science. Crit. Rev. Food Sci. Nutr. 2007, 47, 113–126. [Google Scholar] [CrossRef]
- Mohammadhassani, M.; Nezamabadi-Pour, H.; Jumaat, M.Z.; Jameel, M.; Arumugam, A.M.S. Application of artificial neural networks (ANNs) and linear regressions (LR) to predict the deflection of concrete deep beams. Comput. Concr. 2013, 11, 237–252. [Google Scholar] [CrossRef]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial neural networks: A tutorial. Computer 1996, 29, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Upadhye, S.; Worster, A. Understanding receiver operating characteristic (ROC) curves. Can. J. Emerg. Med. 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Cirilli, M.; Baccichet, I.; Chiozzotto, R.; Silvestri, C.; Rossini, L.; Bassi, D. Genetic and phenotypic analyses reveal major quantitative loci associated to fruit size and shape traits in a non-flat peach collection (P. persica L. Batsch). Hortic. Res. 2021, 8, 232. [Google Scholar] [CrossRef]
- do Nunes, M.C.N. Color Atlas of Postharvest Quality of Fruits and Vegetables; Blackwell Pub: Hoboken, NJ, USA, 2008. [Google Scholar]
- Matsumoto, M.; Nishimura, T. Mersenne Twister: A 623-Dimensionally Equidistributed Uniform Pseudo-Random Number Generator. ACM Trans. Modeling Comput. Simul. 1998, 8, 3–30. [Google Scholar] [CrossRef] [Green Version]
- Patel, V.C.; McClendon, R.W.; Goodrum, J.W. Color Computer Vision and Artificial Neural Networks for the Detection of Defects in Poultry Eggs. Artif. Intell. Rev. 1998, 12, 163–176. [Google Scholar] [CrossRef]
- Jiang, P.; Chen, Y.; Liu, B.; He, D.; Liang, C. Real-Time Detection of Apple Leaf Diseases Using Deep Learning Approach Based on Improved Convolutional Neural Networks. IEEE Access 2019, 7, 59069–59080. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Shah, S.A.A.; Bennamoun, M. A Guide to Convolutional Neural Networks for Computer Vision. In Synthesis Lectures on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1–207. [Google Scholar] [CrossRef]







| Feature | Variable Name | Description |
|---|---|---|
| fruit maturity | ripe | peach maturity (output binary variable) |
| fruit length | fruit_length | peach length |
| fruit shape index | fruit_shape_index | peach shape index |
| a*-AC | a_AC | a* variable of additional fruit color |
| C*-AC | C_AC | C* variable of additional fruit color |
| dE2000-AC | dE2000_AC | dE2000 for additional color |
| L*-GC | L_GC | L* variable of ground fruit color |
| a*-GC | a_GC | a* variable of ground fruit color |
| C*-GC | c_GC | C* variable of ground fruit color |
| Variable | Group | Group Lasso |
|---|---|---|
| fruit_weight | 1 | 0.000000000 |
| fruit_width | 1 | 0.000000000 |
| fruit_length | 1 | 0.000000000 |
| fruit_shape_index | 1 | 0.000000000 |
| fruit_diameter | 1 | 0.000000000 |
| fruit_volume | 1 | 0.000000000 |
| fruit_density | 1 | 0.000000000 |
| L_AC | 2 | 0.000000000 |
| a_AC | 2 | 0.000000000 |
| b_AC | 2 | 0.000000000 |
| C_AC | 2 | 0.000000000 |
| h_AC | 2 | 0.000000000 |
| a.b_AC | 2 | 0.000000000 |
| CCI_AC | 2 | 0.000000000 |
| COL_AC | 2 | 0.000000000 |
| CIRG1_AC | 2 | 0.000000000 |
| CIRG2_AC | 2 | 0.000000000 |
| dE2000_AC | 2 | 0.000000000 |
| L_GC | 3 | −0.003395380 |
| a_GC | 3 | 0.029737581 |
| b_GC | 3 | 0.005994080 |
| c_GC | 3 | 0.014852482 |
| h_GC | 3 | −0.025684634 |
| a.b_GC | 3 | 0.024926216 |
| CCI_GC | 3 | 0.022079283 |
| COL_GC | 3 | 0.022994860 |
| CIRG1_GC | 3 | 0.011642995 |
| CIRG2_GC | 3 | 0.004742768 |
| dE2000_GC | 3 | 0.008545801 |
| Seed | ANN | CART | GBM | LDA | LR | KNN | RF | SVM |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.756 | 0.756 | 0.822 | 0.844 | 0.867 | 0.600 | 0.800 | 0.778 |
| 2 | 0.778 | 0.667 | 0.756 | 0.756 | 0.733 | 0.644 | 0.711 | 0.733 |
| 3 | 0.711 | 0.711 | 0.733 | 0.756 | 0.756 | 0.689 | 0.733 | 0.689 |
| 4 | 0.844 | 0.756 | 0.756 | 0.844 | 0.844 | 0.644 | 0.667 | 0.756 |
| 5 | 0.800 | 0.600 | 0.756 | 0.689 | 0.689 | 0.578 | 0.711 | 0.644 |
| Model | AUC | Accuracy | F1 Score | Kappa |
|---|---|---|---|---|
| ANN | 0.782 | 0.738 | 0.765 | 0.468 |
| LDA | 0.766 | 0.730 | 0.765 | 0.448 |
| LR | 0.765 | 0.732 | 0.765 | 0.453 |
| GBM | 0.714 | 0.675 | 0.724 | 0.333 |
| RF | 0.708 | 0.675 | 0.722 | 0.332 |
| SVM | 0.691 | 0.642 | 0.688 | 0.267 |
| CART | 0.670 | 0.663 | 0.719 | 0.301 |
| KNN | 0.626 | 0.605 | 0.653 | 0.197 |
| Model | Representative Model Seed | Average AUC | Representative Model AUC | Average Accuracy | Representative Model Accuracy | Average Kappa | Representative Model Kappa |
|---|---|---|---|---|---|---|---|
| ANN | 6 | 0.782 | 0.778 | 0.738 | 0.733 | 0.468 | 0.467 |
| LDA | 58 | 0.766 | 0.756 | 0.730 | 0.733 | 0.448 | 0.460 |
| LR | 3 | 0.765 | 0.756 | 0.732 | 0.733 | 0.453 | 0.449 |
| GBM | 29 | 0.714 | 0.711 | 0.675 | 0.667 | 0.333 | 0.322 |
| RF | 35 | 0.708 | 0.711 | 0.675 | 0.667 | 0.332 | 0.328 |
| SVM | 63 | 0.691 | 0.689 | 0.642 | 0.644 | 0.267 | 0.273 |
| CART | 18 | 0.670 | 0.667 | 0.663 | 0.667 | 0.301 | 0.301 |
| KNN | 29 | 0.626 | 0.622 | 0.605 | 0.600 | 0.197 | 0.182 |
| Model | AUC (Lasso) | AUC (Full) | AUC Increase | Acc. (Lasso) | Acc. (Full) | Acc. Increase | Kappa (Lasso) | Kappa (Full) | Kappa Increase |
|---|---|---|---|---|---|---|---|---|---|
| ANN | 0.782 | 0.763 | 2.49% | 0.738 | 0.718 | 2.79% | 0.468 | 0.430 | 8.84% |
| LDA | 0.766 | 0.731 | 4.79% | 0.730 | 0.683 | 6.88% | 0.448 | 0.360 | 24.4% |
| LR | 0.765 | 0.714 | 7.14% | 0.732 | 0.671 | 9.09% | 0.453 | 0.335 | 35.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ljubobratović, D.; Vuković, M.; Brkić Bakarić, M.; Jemrić, T.; Matetić, M. Assessment of Various Machine Learning Models for Peach Maturity Prediction Using Non-Destructive Sensor Data. Sensors 2022, 22, 5791. https://doi.org/10.3390/s22155791
Ljubobratović D, Vuković M, Brkić Bakarić M, Jemrić T, Matetić M. Assessment of Various Machine Learning Models for Peach Maturity Prediction Using Non-Destructive Sensor Data. Sensors. 2022; 22(15):5791. https://doi.org/10.3390/s22155791
Chicago/Turabian StyleLjubobratović, Dejan, Marko Vuković, Marija Brkić Bakarić, Tomislav Jemrić, and Maja Matetić. 2022. "Assessment of Various Machine Learning Models for Peach Maturity Prediction Using Non-Destructive Sensor Data" Sensors 22, no. 15: 5791. https://doi.org/10.3390/s22155791