1. Introduction
Emotions are unintended responses that occur automatically when humans are stimulated by stimuli such as an event or interaction. Emotion recognition is the classification of the emotions of a person that appear in various multimedia content such as images, videos, speech, and text, or in the context of such multimedia content [
1]. It provides an adaptive approach that aids in better understanding the events or interactions in a complex and changing world through the detection of psychological changes in people.
Facial expression shown in the images of people is among the key methods for recognizing emotions. These visual responses are extended to application programs to provide important clues for more accurate emotional interactions in human–computer interactions (HCI). Further, studies on recognizing emotions using speech, which is the foundation of human communication, have also been conducted for a long period. Facial expression recognition (FER) [
2,
3,
4,
5,
6,
7,
8] and speech emotion recognition (SER) [
9,
10,
11,
12,
13] have existed for over 20 years. However, with recent advances in deep neural networks, FER and SER have once again gained attention.
In recent years, powerful and reusable deep learning technologies based on large-scale training data and the power of high-performance computation have been suggested as alternatives to existing technologies in almost all fields, including emotion recognition. As convolutional neural networks (CNNs) have outperformed humans in various pattern recognition tasks by learning advanced features in image big data, researchers have begun reviewing CNN extensively from various perspectives [
14,
15,
16,
17,
18]. Recurrent neural networks (RNN) can effectively classify speech and text owing to their ability to handle sequential sequence data of a long distance [
19,
20,
21]. Consequently, many researchers have adopted RNN and CNN models to achieve excellent results in application programs for FER [
8,
22,
23,
24,
25,
26] and SER [
27,
28]. In addition, emotion recognition multimedia application programs based on these research results have been utilized as one of the major or minor functions throughout society, including robots, entertainment, social media industry, healthcare, and welfare.
However, there has been a recent emergence of a massive amount of video data in the visual world. Videos are being created continuously at places such as public facilities to everyday lives through CCTVs, home cameras, online lectures, social media, and medical video. Therefore, video-based emotion recognition has become a necessity. Many researchers have begun focusing on fusion networks based on multimodal data to detect more complex structures and features by exploiting the features of videos [
29,
30], which contain both images and speech. Further, the DeepBlueAI research team [
31], which achieved third place in the eighth Emotion Recognition in the Wild (EmotiW) 2020 challenge [
32], fused up to 14 models. In addition, the SituTech research team [
33] achieved first place with a hybrid network wherein seven types of data streams were fused.
Based on several empirical evidence, the multimodal approach, which fuses various types of data, has been confirmed to outperform existing single method models. However, the applicability of this approach in the real-world application domains needs to be discussed. In computer-aided diagnosis systems, image analysis and processing are essential parts of interpreting and detecting most diseases from medical video. From a crime prevention perspective, emotions and situations must be captured through facial expressions rather than voice to determine the situation for emotion recognition that can be used to prevent crimes through CCTV, arrest a suspect or a criminal, or detect digital sex crimes through social media. In addition, another problem from the perspective of an individual’s identity is encountered in the real world. It stems from the fact that facial expressions may appear differently according to various races, cultures, looks, gender, and age. Furthermore, the detection of subtle facial motions and head movements within natural expressions is challenging. These problems can only be solved through research on recognizing facial expressions from image sequences that have been extracted from a video, excluding speech, which is one form of data among components of a video. However, even the team [
34] that accomplished the best result at EmotiW challenge [
35] using the Acted Facial Expressions in The Wild (AFEW) dataset [
36,
37] (widely known as a wild video emotion dataset) achieved low-quality results when using only image sequences. They achieved a best performance of 49.30% using a multimodal fusion model and only 39.69% with the model employing only facial images [
38]. This result indicates the prevalent low accuracy of an individual performance on image sequence.
An image sequence has both spatial and temporal information. Therefore, the CNN–RNN architecture [
39], which employs a combination of CNN and RNN, was used in many of the previous studies. However, CNN is a process of finding a type of template filter that operates universally on image data. In addition, covering all identities of an individual is challenging because parameters such as the input and weights are fixed after training completion. Moreover, RNN renders the performing of data parallelism challenging because it can learn only through sequential receival of sequence data as the input.
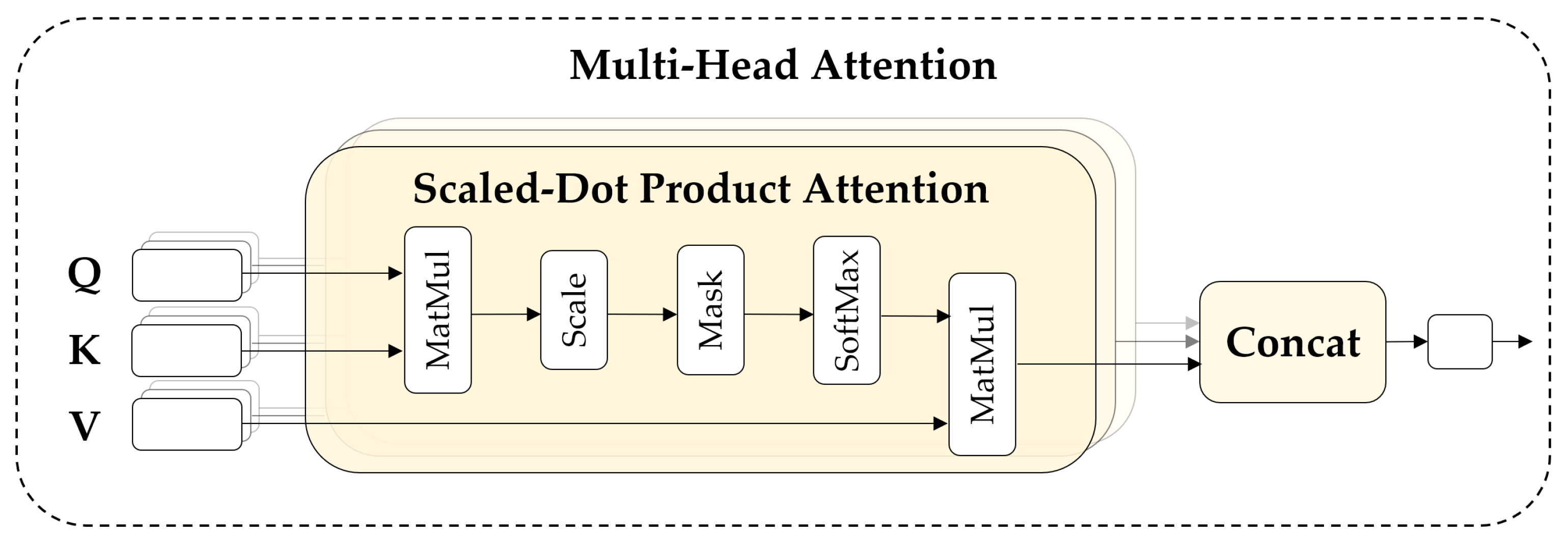
Therefore, this study proposes a segment-level feature mixing and temporal encoding (SMaTE) framework, in an attempt to tackle these problems. First, the SMaTE framework was designed based on a reusable vision transformer (ViT) [
40] to facilitate easy application to real-world facial expression recognition application programs. The proposed model comprised two separate transformer encoders to enable the learning of spatial and temporal information. As this model first extracted the spatial information and then modeled the interactions between temporal indices, it is similar to the CNN–RNN architecture that was widely used in previous studies. However, the proposed model can process image sequence data in parallel because it is based on the transformer [
41] model. Moreover, it was designed to facilitate augmentation of image sequences using several effective methods and subsequently fuse them within the FER transformer model. Furthermore, the proposed method applied the position embedding technique, which primarily focused on temporal information compared to spatial information, in a temporal encoder that modeled the temporal interactions.
The primary contributions of this study are as follows:
A new framework referred to as SMaTE is proposed for facial expression recognition based on the video vision transformer model.
Data augmentation and feature extraction were performed, with the aim being for the model to learn useful representations of FER more effectively. Various data enhancements were decomposed into patch units and converted into token sequence through linear projection. Subsequently, these were randomly aggregated into one token architecture and thus improved the modeling of FER.
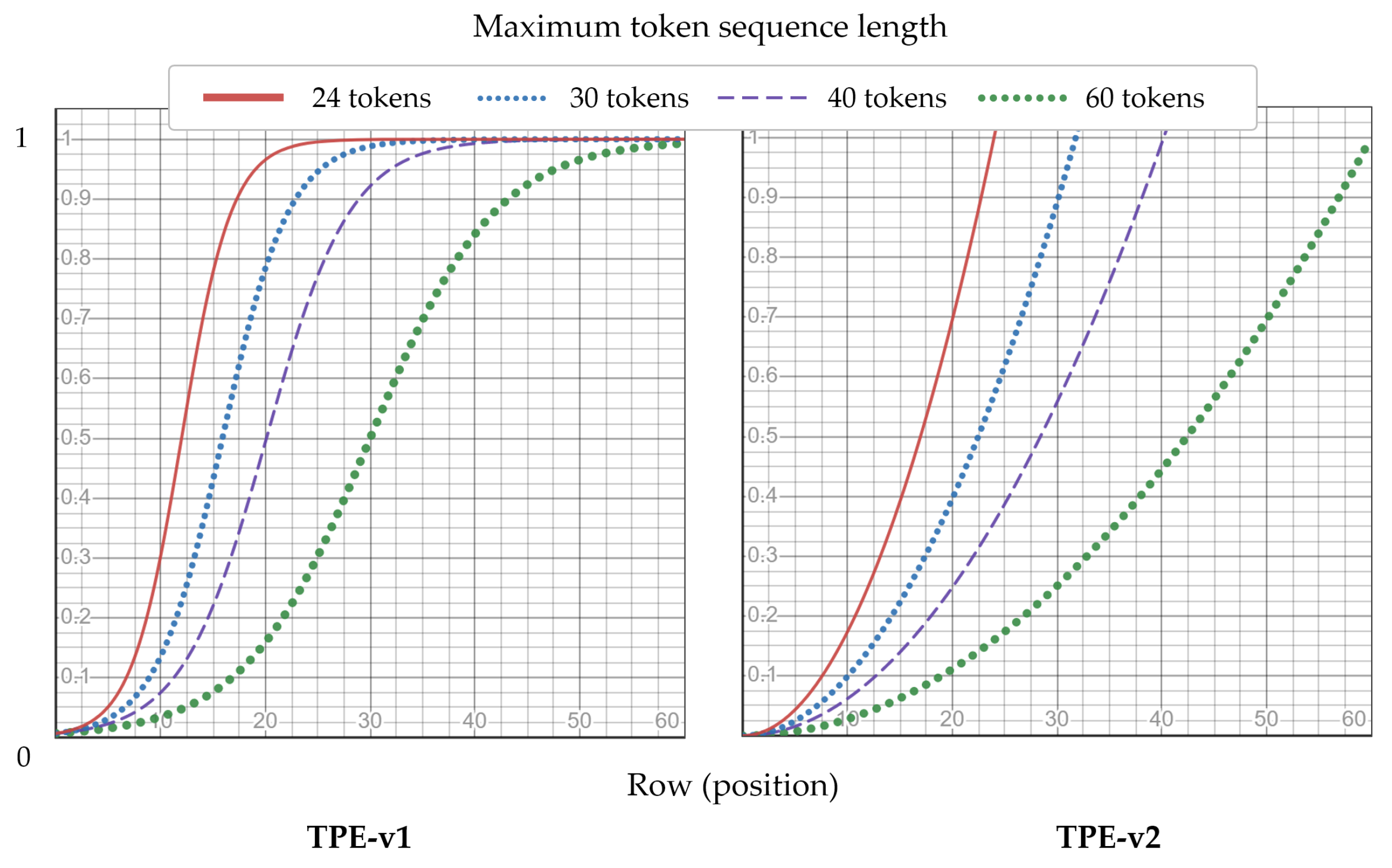
Temporal position encoding is proposed for FER instead of the learned position embedding used in the existing work [
42]. This encourages increase in the interaction between data and position encoding in temporal transformer encoder. This study shows that the proposed encoding methods outperform existing position embeddings on the Extended Cohn–Kanade (CK+) and AFEW.
The proposed framework was demonstrated to be the best choice for improving FER performance with only a few adjustments of pure-transformer architectures [
42] through ablation analysis of the position encodings, data augmentation and feature extraction methods, tokenization strategies, and a model architecture.
The Extended Cohn–Kanade (CK+) dataset [
43,
44] is a laboratory-based dataset, whereas the AFEW dataset is a wild environment dataset for video-based FER. The experiments conducted using two types of facial expression recognition datasets demonstrated that the SMaTE model can improve the recognition rate of facial expression sequences in both laboratory and wild environments. It also showed that the SMaTE model can achieve better results than the existing methods.
The remainder of this paper is organized as follows:
Section 2 introduces the related motivations and tasks, and
Section 3 describes the SMaTE model in detail. Further,
Section 4 introduces the details of the experiment and evaluates the performance. Finally,
Section 5 presents the conclusions.
2. Related Works
Researchers have proposed effective previous methods such as data preprocessing and feature extraction to solve classification problems for images that are difficult to interpret, such as vague boundaries in skin lesions detection and appearance bias in FER. Data preprocessing removes unwanted parts of the image that can be misinterpreted to classify the target. Feature extraction extracts distinct features from images that play an important role in classification tasks. Handcrafted features manually design and extract elements of the image that are relevant to the target through prior knowledge [
45]. On the other hand, non-handcrafted features were optimized features extracted through deep learning and showed excellent detection accuracy in various fields [
46].
In previous FER works, to address the problems discussed, fusion models such as multiple modalities that combine various data (e.g., speech, brain, and peripheral signals) [
31,
33,
34,
38] and multi-task learning that utilizes commonalities and differences across tasks at the same time [
47,
48,
49,
50] have been studied. Reference [
49] proposed a fusion model that combined the two tasks to determine the optimized final loss from individual identity-based face recognition and FER architecture. Further, references [
51,
52] proposed fusion networks wherein features of face and semantic context were extracted from input images and combined.
Deep neural networks, combining CNN and RNN, have mostly been used to classify image sequences. CNNs [
14,
15,
16,
17,
18] can effectively model the spatial relations of image components, whereas RNNs [
19,
20] are advantageous in learning relationships within a sequence [
53,
54,
55,
56]. These models are used via the combination of CNN as an encoder and RNN as a decoder to extract features of frames and spatiotemporal features.
CNNs can learn and share several similar patterns by extracting features from various portions while multiple convolution filters slice the image area based on the common assumption of translation equivariance. These filters can efficiently learn the model by sharing parameters for each target class [
57,
58].
While multiple convolution filters slice the image area based on the property of translation equivariance, CNNs can learn several similar patterns through the extraction of features from various portions. These filters can efficiently learn the model by sharing parameters for each target class. Therefore, a CNN is translation-invariant and the output does not change regardless of changes in position of the target object (e.g., facial expression) or variation in its appearance in the input image. CNN exhibits superior performance in image classification because it has correct assumptions regarding the following nature of images [
59]: locality assumption, which tends to have a stronger relationship with adjacent pixels, and stationarity assumption, where the same patterns are repeated.
Nevertheless, appearance biases still influence prediction. Further, performance decline due to individual characteristics (appearance, culture, gender, age, etc.) is a problem that often occurs in classification using face images such as facial recognition and facial expression recognition. Classification of even a well-generalized FER CNN model can be challenging if facial expression intensity or patterns differ due to its appearance bias across race and region, and response bias across cultures [
60,
61,
62]. A person whose neutral expression is similar to that of a smiling face or angry face can cause a CNN-based FER model to yield incorrect results. This problem is particularly pronounced in video FER, where movement and facial expression intensity are not constant.
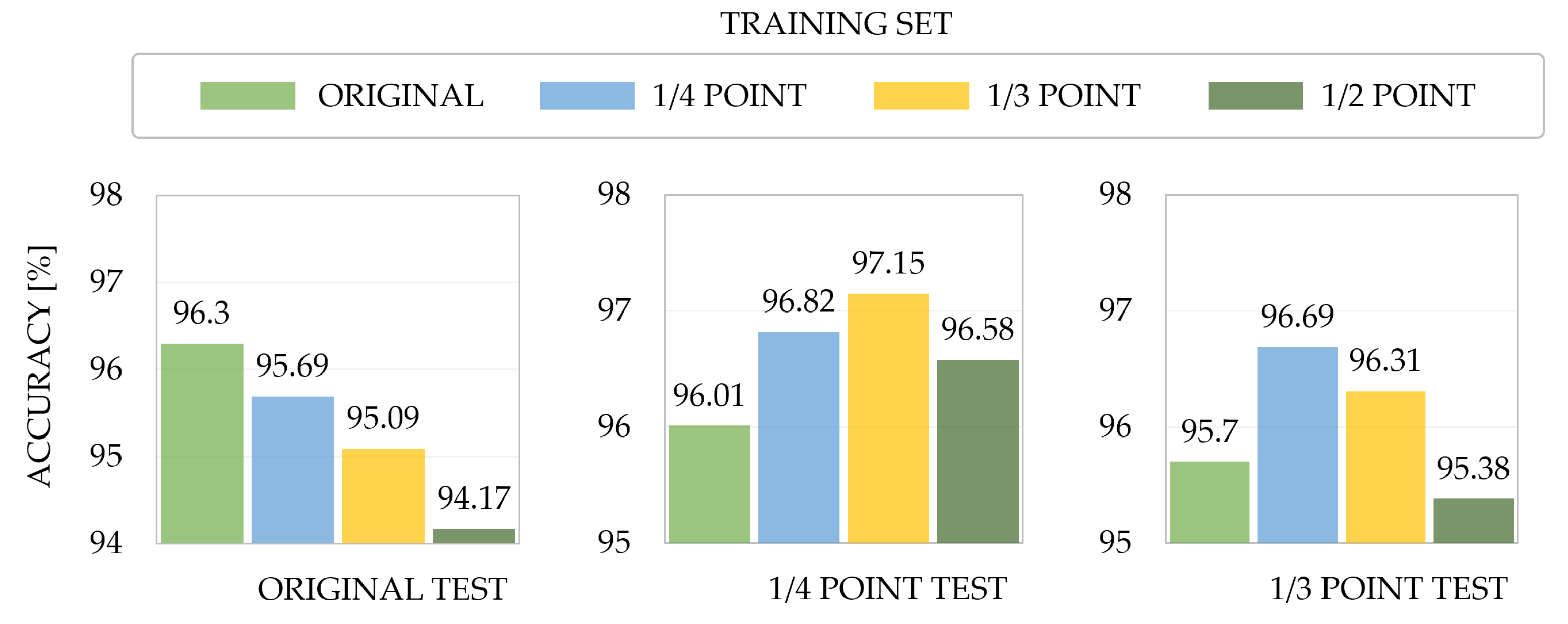
This study transformed the CK+ dataset, traditionally used for FER, to measure accuracy according to human appearance bias. The CK+ dataset is a dataset representing a sequence of images from
to the maximum intensity of seven categorical emotions for each subject. As shown in
Figure 1, image sequences that changed the starting frame to
,
, and
points were added for the training set. Thus, the impact of the appearance bias was evaluated by training data that changed the unique neutral expression of a person.
To perform the experiments, a face-related multi-task model based on EfficientNet [
63] was used. It has an acceptable accuracy while having a relatively small size.
Figure 2 shows the results following 10-fold validation under different neutral expression data. The model, which learned with
point and
point data, exhibited higher performance in all test sets, including appearance biases, than the model that learned only with the original data. Thus, based on the above observations, this study emphasizes the need for a robust FER framework including data preprocessing, combination of handcrafted features and deep learning-based features, and a transformer-based model to consider appearance biases with diverse backgrounds.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}