4.1. Datasets and Evaluation Measures
To verify the performance of the proposed method, we evaluated it on several public datasets, including the NTU dataset, UR Fall Detection Dataset (URFD), and UP-Fall detection dataset. We collected a part of fall data and non-fall data in NTU RGB and extracted the skeleton of the URFD and UP-FALL detection dataset using the OpenPose algorithm to obtain the corresponding 3D skeleton data.
The NTU dataset was captured simultaneously by 3 Kinect v2 cameras. It contains 60 types of actions, usually also known as NTU 60. In this dataset, the proposed method is usually evaluated using two protocols: cross-subject (X-sub) and cross-view (X-view). The X-sub contains 40,320 training samples and 16,560 test samples, and the partitioning rule is based on 40 subjects, indicating that the behaviors in the training and test sets are from different actors. The X-view takes the ones collected by camera 2 and 3 as the training set (37,920 samples) and those collected by camera 1 as the test set (18,960 samples). The names and numbers of specific nodes correspond to each other, e.g., 3 for neck, 16 for left foot, 25 for right thumb, and so on. We collected some fall datasets from NTU and selected the fall behaviors and fall-like behaviors as the sample data, containing 948 items and 4506 items, respectively, including drop, pick up, sit down, wear a shoe, take off a shoe, and fall. We refer to the dataset consisting of these six types of actions as the NTU fall dataset. When the other five actions occur, such as drop and sit, the overall center of gravity of the body changes, which is similar to fall behavior, has a certain interference in the fall recognition task, and improves the recognition ability of the model.
The UR Fall Detection Dataset is a collection of human activity sequences captured by outdoor cameras installed at different viewpoints, including 30 falls and 40 video clips of daily living activities. In this paper, we only use RGB images of 30 fall sequences and 30 normal activity sequences. We used the OpenPose algorithm to extract the skeleton of this pair of datasets.
The UP-Fall datasets are collected from 17 young healthy subjects during 11 activities (5 falls and 6 daily activities) in 3 trials, including two datasets, i.e., a sensor-based dataset and a vision-based dataset. Especially, this dataset does not reflect the reality of a fall of an elderly person. The vision-based dataset is collected by fixing a front camera and a lateral camera in the room, which provides a front view and side view of the subject, respectively. In the proposed method, we only utilize the lateral camera view, which in turn reduces the computational complexity. The experiment proves it is sufficient to reach the comparable performance compared with the state-of-the-art methods using two camera angles. Similar to URFD, OpenPose is utilized to extract the skeleton information of the UP-Fall detection dataset.
To evaluate the performance of the proposed method, some metrics like sensitivity (recall), specificity, and model accuracy are calculated, which are shown as follows.
In the above equations, TP means the number of falls that have been predicted as fall correctly, FP means the number of activities of daily living (ADL) that are predicted as falls, and TN means the number of normal activities that are predicted as normal activities. Similarly, FN means predicting a normal activity as a fall.
4.3. Results’ Comparison
We tested the proposed method and other classical methods on the UR Fall dataset. These methods are divided into two groups. The first two groups of methods are designed based on hand-crafted features [
30,
31,
32] and the second group of methods employs deep learning [
33,
34].
Table 1 provides the comparison results of the proposed method and the other five methods on the UR Fall dataset. It can be seen from
Table 1 that, compared with the other four methods, the proposed method has the best accuracy. Our proposed method fully leverages skeleton information and does not require handcrafted features, which significantly improves the performance of fall recognition. This work also performs better with the help of the GCN network and sub-graph division compared with the CNN-based methods [
33,
34]. The GCN network helps capture spatial-temporal information of the human body and the sub-graph attention helps enhance the feature representativeness, which improves the performance of the fall recognition task.
We also tested the proposed method on the UP-Fall dataset and compared it with several existing methods, as shown in
Table 2. In method [
35], the author conducts a case study on the lateral and frontal cameras respectively. We can see that, in our proposed method, all of the evaluation parameters, i.e., sensitivity, specificity, and accuracy, are relatively good. The author in method [
7] applies some machine learning algorithms to the UP-Fall datasets, such as random forest (RF), support vector machine (SVM), multilayer perceptron (MLP), K-nearest neighbours (KNN), and CNN. Compared with the machine learning algorithm, our proposed method displays very high performance. The method [
36] also uses CNN on the UP-Fall dataset, but compared with our method, it has achieved significantly lower accuracy. The method [
37] also adopts RF, SVM, MLP, KNN, and other machine learning algorithms on the dataset using data from two camera inputs. However, our proposed method achieves similar accuracy only utilizing input from a single lateral camera. Based on this fact, it can be inferred that the proposed method is very effective. The method [
38] employs CNN and LSTM on the UP-Fall dataset on the lateral camera, but compared with the proposed method, it has achieved lower sensitivity, specificity, and accuracy. Therefore, our proposed method can achieve similar or even better results than those works that use two or only one camera input to identify falls.
We also verified the performance of the proposed method on our collected NTU dataset, which consists of six types of actions. The sensitivity, specificity, and accuracy are 97.5%, 89.6%, and 94.5%, respectively, as shown in
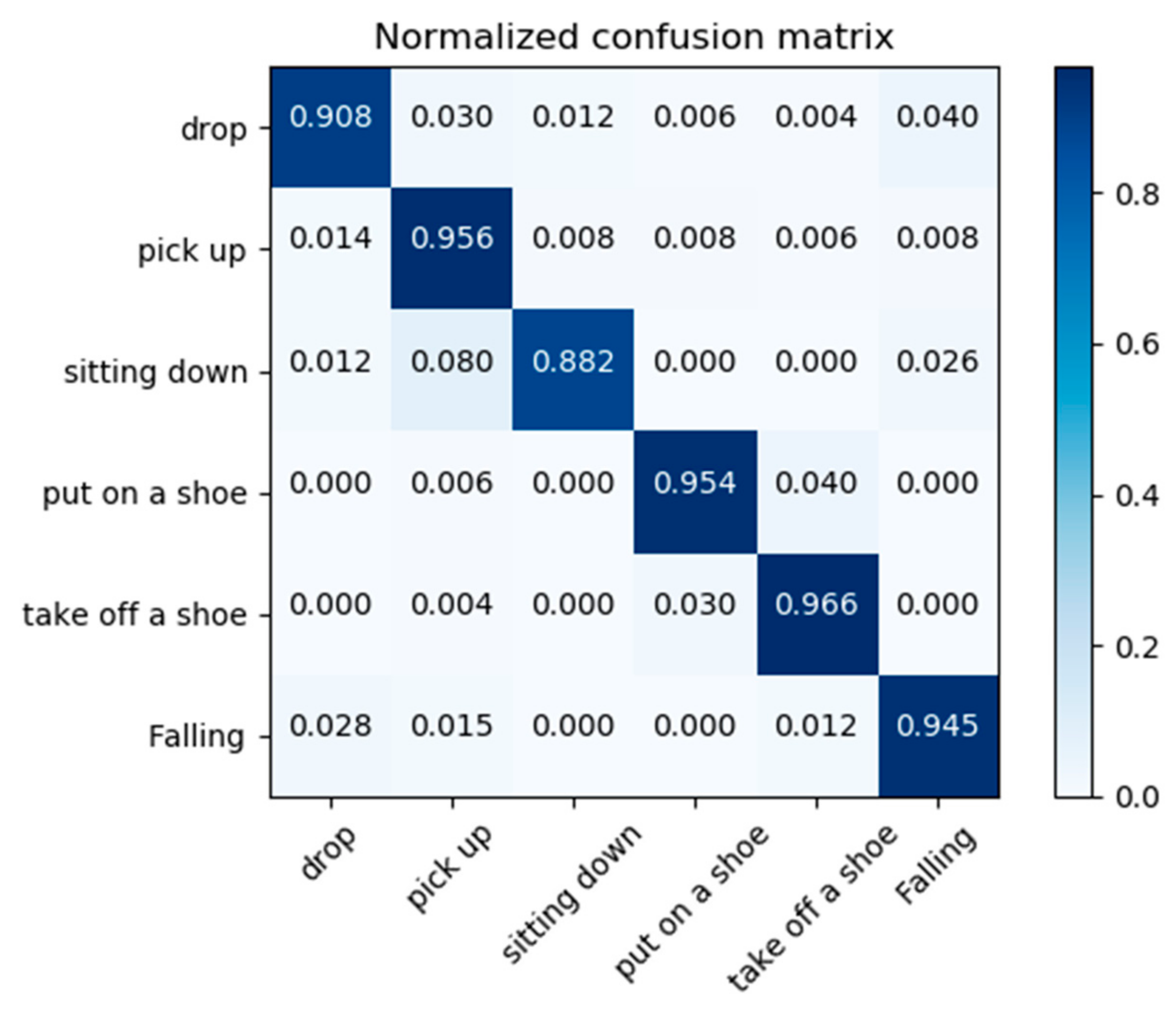
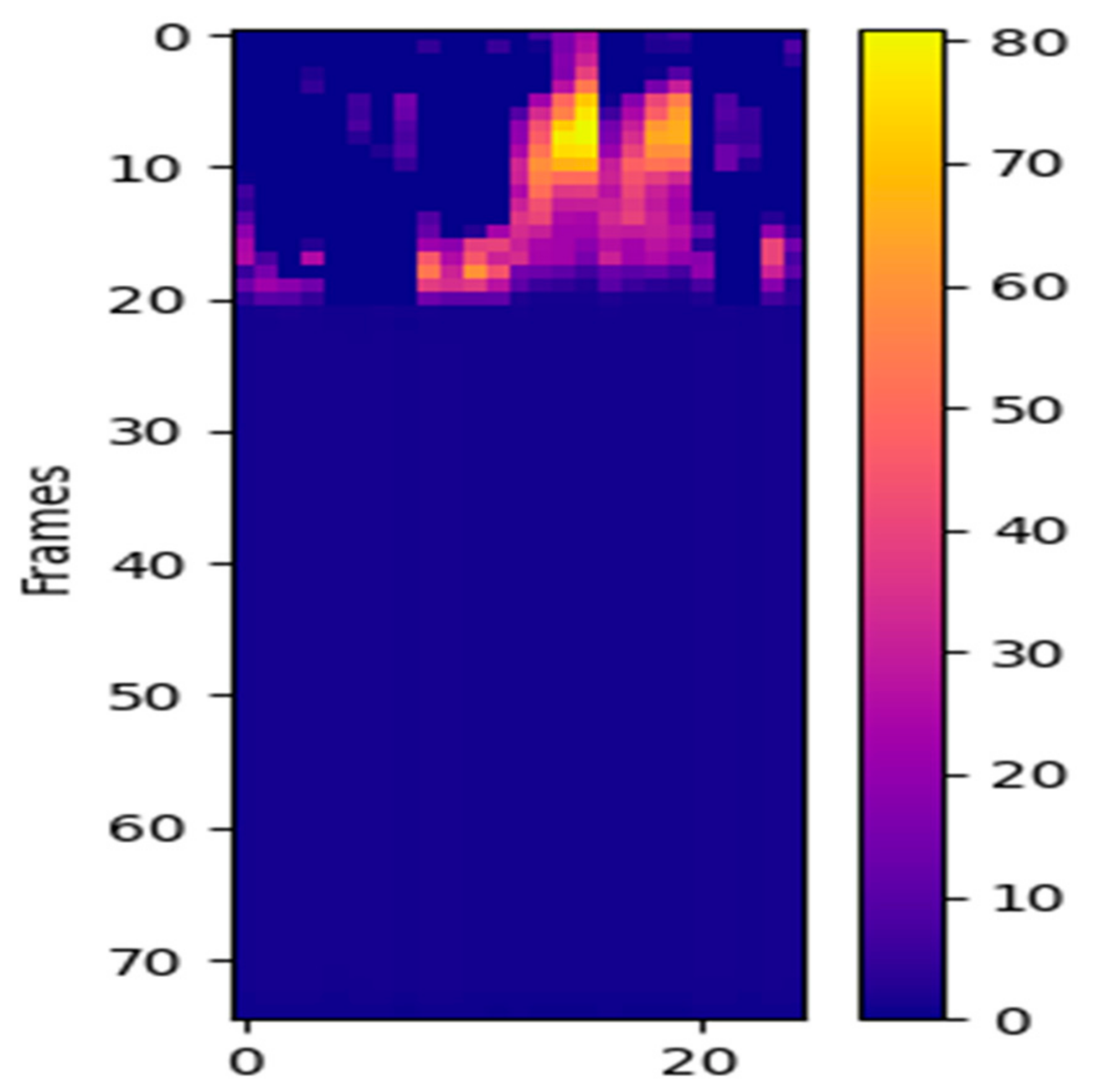
Table 3. In addition, we also draw a confusion matrix, including five behaviors that identify falls and are similar to falls, as shown in
Figure 5. It can be seen from the figure that the methods in this chapter can better distinguish six actions on the NTU dataset, in which fall and drop are the most likely to be confused. For non-fall behaviors, such as put on a shoe and sit down, special analysis is needed. We analyze that the causes of false discrimination are as follows: (a) In pose estimation, the lack of joint points leads to data incompleteness, which reduces the final recognition results. (b) During the experiment, there is still a difference between real falls and recorded falls owing to the self-protection of the experimenter.
4.4. Ablation Study
The proposed method uses multiple strategies to deal with the fall recognition problem. To study the effectiveness of each strategy, we conducted several ablation experiments on the NTU dataset. The following is the main content.
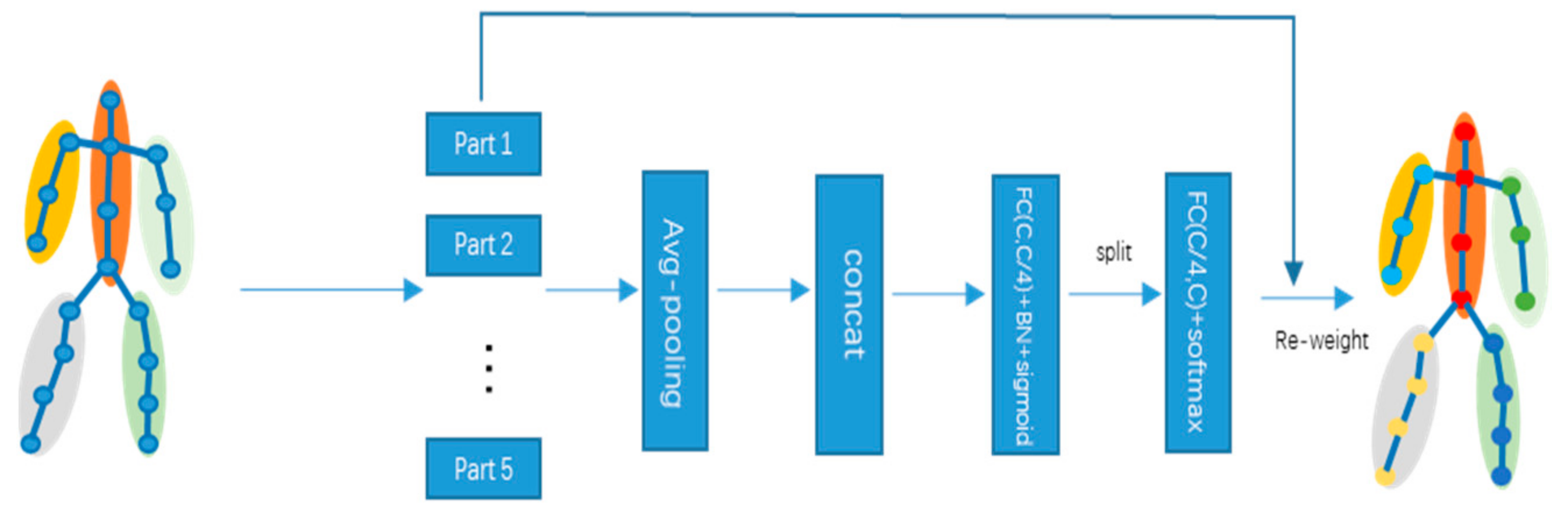
Sub-Graph Division and Sub-Graph Attention. In our proposed method, sub-graphs are introduced to distinguish the various parts of the fall. To demonstrate the effectiveness of sub-graph division and sub-graph attention on fall recognition, we conducted several sets of comparison experiments on the collected NTU dataset (six types), including three groups, i.e., with only sub-graph division, with only sub-graph attention, and with both of them. As shown in
Table 4, the results show that both sub-graph division and sub-graph attention in the collected NTU fall dataset effectively improve the recognition accuracy, effectively gather the features in the fall behavior, and fully explore the differences in the movement and change magnitude of each part of the human body during the fall.
The Importance of MTCN. In order to compare the effectiveness of the multi-scale temporal convolution network (MTCN), we conducted combined experiments on temporal convolution of different scale sizes. To evaluate the generalization ability of the model, the experiments were conducted on the NTU X-sub dataset instead of the collected fall dataset. As shown in
Table 5, the proposed method is the least effective when the MTCN module is not used, reaching 85.7%. When the temporal convolution with a single convolutional kernel is taken, the recognition accuracy reaches 87.5%, 87.6%, and 87.2%, respectively. When the convolution kernels are combined two by two, the recognition accuracy reaches 88.9%, 88.4%, and 88.7%, respectively. When three scales are adopted, the accuracy reaches 89.8%. The results show that multi-scale temporal convolution is beneficial to extract richer temporal context information, which in turn improves the feature representation capability of the model and allows better modeling of temporal sequences.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}