
Unified End-to-End YOLOv5-HR-TCM Framework for Automatic 2D/3D Human Pose Estimation for Real-Time Applications


Abstract
:1. Introduction
- We propose a unified end-to-end framework for automatic 3D human pose estimation. The framework is a combination of high-performance CNNs to perform sequential tasks: human detection, 2D human pose estimation, and 3D human pose estimation.
- We embedded efficient contextual constraints (CCs) into YOLOv5 for human detection and HR for 2D keypoint estimation/2D human pose estimation in images or video, called YOLOv5 + CC + HR combined. We also evaluated the results in detail at this stage on the Human 3.6M dataset.
- We applied the TCM and semi-supervised training method in our framework using the 2D human pose estimation results in the fine-tuning 3D human pose estimation model on the Human 3.6M dataset. The 3D human pose estimation results were also evaluated and compared with the baseline methods.
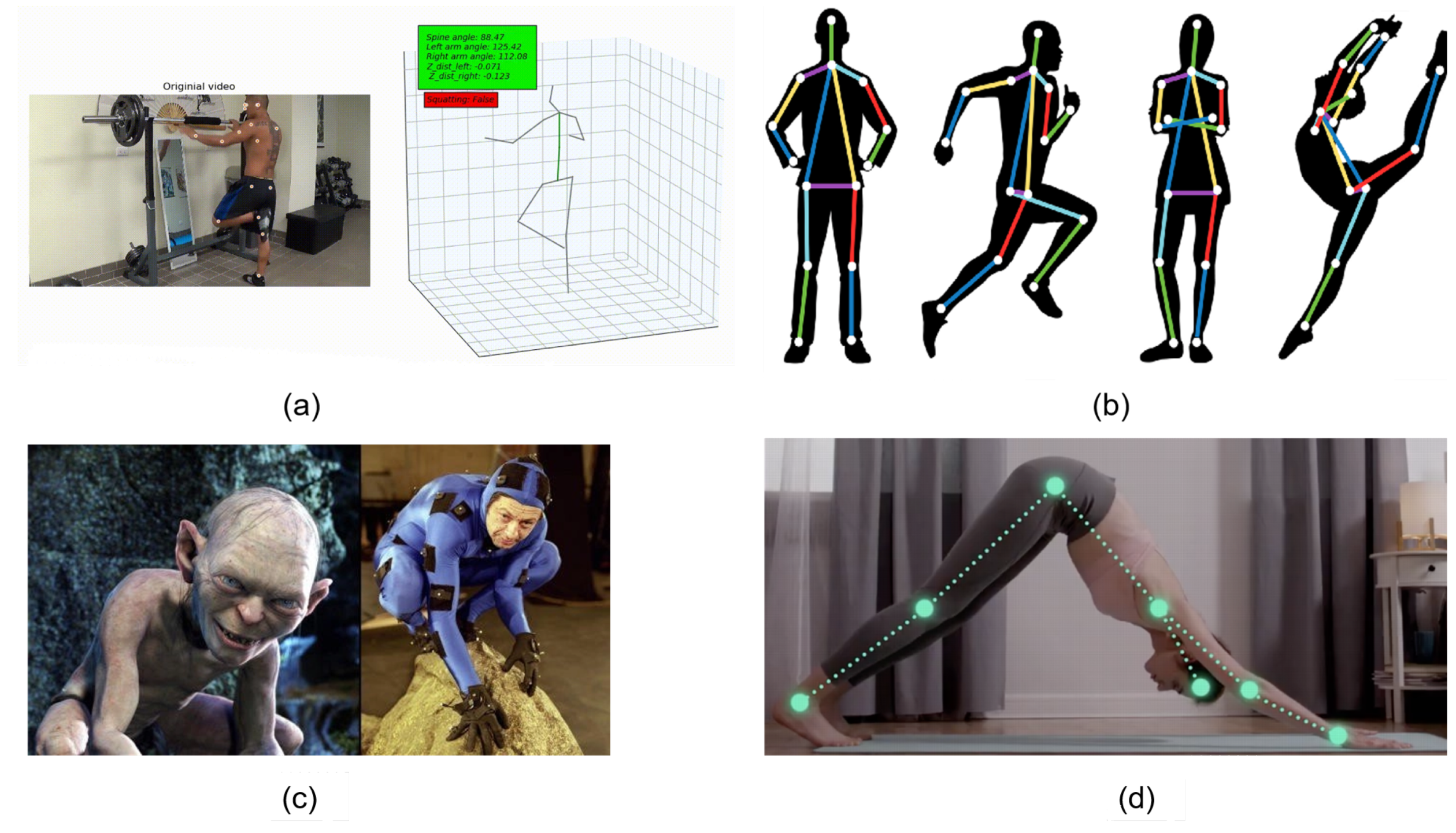
- We combined and integrated the proposed framework into a practical application for computing the angle of deviation of human poses in 3D space. This was applied for assessment and scoring in artistic gymnastics and training and dance assessment. Moreover, it operates in real-time on a PC with a low configuration.
2. Related Works
3. The Unified End-to-End YOLOv5-HR-TCM Framework
3.1. Human Detection
3.2. Two-Dimensional Human Pose and 2D Keypoint Estimation

3.3. Three-Dimensional Human Pose Estimation from Estimated 2D Human Poses
4. Experimental Results
4.1. Data Collection, Implementations, and Evaluations
4.2. Results and Discussions
5. Pose-Based Application
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Stenum, J.; Cherry-Allen, K.M.; Pyles, C.O.; Reetzke, R.D.; Vignos, M.F.; Roemmich, R.T. Applications of pose estimation in human health and performance across the lifespan. Sensors 2021, 21, 7315. [Google Scholar] [CrossRef] [PubMed]
- Sawant, C. Human activity recognition with openpose and Long Short-Term Memory on real time images. EasyChair Preprint no. 2297, EasyChair. 2020. Available online: https://www.semanticscholar.org/paper/Human-activity-recognition-with-openpose-and-Long-Sawant/e7503d2a381a4de534b9ece7d520435370ae517a (accessed on 12 December 2021).
- Minds, B. An Overview of Human Pose Estimation with Deep Learning. 2021. Available online: https://beyondminds.ai/blog/an-overview-of-human-pose-estimation-with-deep-learning/ (accessed on 12 December 2021).
- Barla, N. A Comprehensive Guide to Human Pose Estimation. 2021. Available online: https://www.v7labs.com/blog/human-pose-estimation-guide (accessed on 12 December 2021).
- Tatariants, M. Human Pose Estimation Technology 2021 Guide. 2020. Available online: https://mobidev.biz/blog/human-pose-estimation-ai-personal-fitness-coach (accessed on 12 December 2021).
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the Wild: A Weakly-Supervised Approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar] [CrossRef] [Green Version]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera. ACM Trans. Graph. 2017, 26, 44. [Google Scholar] [CrossRef] [Green Version]
- Babu, S.C. A 2019 guide to Human Pose Estimation with Deep Learning. 2019. Available online: https://nanonets.com/blog/human-pose-estimation-2d-guide/ (accessed on 5 December 2021).
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human Pose Estimation with Iterative Error Feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple Baselines for Human Pose Estimation and Tracking. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 1–16. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the 14th European Conference ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. Available online: https://arxiv.org/abs/1908.07919 (accessed on 5 December 2021).
- Toshev, A.; Szegedy, C. DeepPose: Human Pose Estimation via Deep Neural Networks. In Proceedings of the IEEE Conference on CVPR, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Li, S.; Ke, L.; Pratama, K.; Tai, Y.W.; Tang, C.K.; Cheng, K.T. Cascaded Deep Monocular 3D Human Pose Estimation with Evolutionary Training Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. TPAMI 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Tan, S.; Zhen, X.; Xu, S.; Zheng, F.; He, Z.; Shao, L. Deep 3D human pose estimation: A review. Comput. Vis. Image Underst. 2021, 210, 103225. [Google Scholar] [CrossRef]
- Ji, X.; Fang, Q.; Dong, J.; Shuai, Q.; Jiang, W.; Zhou, X. A survey on monocular 3D human pose estimation. Virtual Real. Intell. Hardw. 2020, 2, 471–500. [Google Scholar] [CrossRef]
- Dang, Q.; Yin, J.; Wang, B.; Zheng, W. Deep learning based 2D human pose estimation: A survey. Tsinghua Sci. Technol. 2019, 24, 663–676. Available online: https://arxiv.org/abs/2012.13392 (accessed on 5 December 2021). [CrossRef]
- Le, V.H.; Nguyen, H.C. A survey on 3D hand skeleton and pose estimation by convolutional neural network. Adv. Sci. Technol. Eng. Syst. 2020, 5, 144–159. [Google Scholar] [CrossRef]
- Chen, X.; Lin, K.Y.; Liu, W.; Qian, C.; Lin, L. Weakly-supervised discovery of geometry-aware representation for 3D human pose estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10887–10896. [Google Scholar] [CrossRef] [Green Version]
- Glenn Jocher. YOLOv5 Torials. 2021. Available online: https://github.com/ultralytics/yolov5#tutorials (accessed on 6 December 2021).
- Jocher, G. Head and Person Detection Model. 2021. Available online: https://github.com/deepakcrk/yolov5-crowdhuman (accessed on 6 December 2021).
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, Y.; Tian, Y.; He, M. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 2020, 192, 1–23. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Tuli, S.; Dasgupta, I.; Grant, E.; Griffiths, T.L. Are Convolutional Neural Networks or Transformers More Like Human vision? Available online: https://arxiv.org/abs/2105.07197 (accessed on 6 December 2021).
- Rhodin, H.; Meyer, F.; Spörri, J. Learning Monocular 3D Human Pose Estimation from Multi-view Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8437–8446. [Google Scholar]
- Tome, D.; Russell, C.; Agapito, L. Lifting from the deep: Convolutional 3D pose estimation from a single image. In Proceedings of the CVPR 2017: 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5689–5698. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Lin, L.; Jiang, C.; Qian, C.; Wei, P. 3D Human Pose Machines with Self-supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1069–1082. [Google Scholar] [CrossRef] [Green Version]
- Véges, M.; Varga, V.; Lőrincz, A. 3D Human Pose Estimation with Siamese Equivariant Embedding. arXiv 2018, arXiv:1809.07217. [Google Scholar] [CrossRef]
- Fang, H.s.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S.c. Learning Pose Grammar to Encode Human Body Configuration for 3D Pose Estimation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Omran, M.; Lassner, C.; Pons-Moll, G.; Gehler, P.; Schiele, B. Neural body fitting: Unifying deep learning and model based human pose and shape estimation. In Proceedings of the 2018 International Conference on 3D Vision, Verona, Italy, 5–8 September 2018; pp. 484–494. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Peng, X.; Tian, Y.; Kapadia, M.; Metaxas, D.N. Semantic graph convolutional networks for 3D human pose regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3420–3430. [Google Scholar] [CrossRef] [Green Version]
- Nibali, A.; He, Z.; Morgan, S.; Prendergast, L. 3D human pose estimation with 2D marginal heat maps. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, WACV 2019, Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1477–1485. [Google Scholar] [CrossRef] [Green Version]
- Moon, G.; Chang, J.Y.; Lee, K.M. Camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10132–10141. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Lee, I.; Lee, S. Propagating LSTM: 3D pose estimation based on joint interdependency. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 123–141. [Google Scholar] [CrossRef]
- Li, C.; Lee, G.H. Generating Multiple Hypotheses for 3D Human Pose Estimation with Mixture Density Network. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-fine volumetric prediction for single-image 3D human pose. In Proceedings of the CVPR 2017: 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 1263–1272. [Google Scholar] [CrossRef] [Green Version]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-Supervised Learning of 3D Human Pose using Multi-view Geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1077–1086. [Google Scholar]
- Wandt, B.; Rosenhahn, B. RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tekin, B.; Marquez-Neila, P.; Salzmann, M.; Fua, P. Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation. In Proceedings of the IEEE Conference on CVPR, Honolulu, HI, USA, 21–26 July 26 2017; pp. 3961–3970. [Google Scholar] [CrossRef] [Green Version]
- Iskakov, K.; Burkov, E.; Lempitsky, V.S.; Malkov, Y. Learnable Triangulation of Human Pose. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Sun, X.; Li, C.; Lin, S. An Integral Pose Regression System for the ECCV2018 PoseTrack Challenge. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 1–5. [Google Scholar]
- Rhodin, H.; Constantin, V.; Katircioglu, I.; Salzmann, M.; Fua, P. Neural scene decomposition for multi-person motion capture. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7695–7705. [Google Scholar] [CrossRef] [Green Version]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A Simple Yet Effective Baseline for 3d Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2659–2668. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Liu, H.; Ding, R.; Liu, M.; Wang, P.; Yang, W. Exploiting Temporal Contexts with Strided Transformer for 3D Human Pose Estimation. IEEE Transactions on Multimedia. 2022. Available online: https://arxiv.org/abs/2103.14304 (accessed on 6 June 2022).
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D Human Pose Estimation with Spatial and Temporal Transformers. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; Volume 1, pp. 11636–11645. [Google Scholar] [CrossRef]
- Hossain, M.R.I.; Little, J.J. Exploiting temporal information for 3D human pose estimation. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 69–86. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Chen, Y.; Guo, Z.; Qian, K.; Lin, M.; Li, H.; Ren, J.S. Generalizing Monocular 3D Human Pose Estimation in the Wild. arXiv 2019, arXiv:1904.05512. [Google Scholar]
- Pavllo, D.; Grangier, D.; Auli, M. QuaterNet: A Quaternion-based Recurrent Model for Human Motion. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Zhao, W.; Tian, Y.; Ye, Q.; Jiao, J.; Wang, W. GraFormer: Graph Convolution Transformer for 3D Pose Estimation. 2021, Volume 1. Available online: https://arxiv.org/pdf/2109.08364.pdf (accessed on 6 June 2022).
- Zhao, W.; Wang, W.; Tian, Y. GraFormer: Graph-Oriented Transformer for 3D Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 20438–20447. [Google Scholar]
- Song, L.; Yu, G.; Yuan, J.; Liu, Z. Journal of Visual Communication and Image Representation Human pose estimation and its application to action recognition: A survey. J. Vis. Commun. Image Represent. 2021, 76, 103055. [Google Scholar] [CrossRef]
- Chen, C.H.; Ramanan, D. 3D human pose estimation = 2D pose estimation + matching. In Proceedings of the IEEE Conference on CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 5759–5767. [Google Scholar] [CrossRef] [Green Version]
- Badiola-Bengoa, A.; Mendez-Zorrilla, A. A systematic review of the application of camera-based human pose estimation in the field of sport and physical exercise. Sensors 2021, 21, 5996. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Wang, X.; Ren, J.; Li, H. 3D Human Pose Estimation in the Wild by Adversarial Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sharma, S.; Varigonda, P.T.; Bindal, P.; Sharma, A.; Jain, A. Monocular 3D Human Pose Estimation by Generation and Ordinal Ranking. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 September 2016; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster RCNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the ECCV (1), Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: New York, NY, USA, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the CVPR 2017: 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016, 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Ali, F. YOLOv3: An Incremental Improvement. 2018. Available online: http://arxiv.org/abs/1804.02767 (accessed on 18 April 2021).
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jonathan, H. Object Detection: Speed and Accuracy Comparison (Faster RCNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3). 2018. Available online: https://jonathan-hui.medium.com/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo-5425656ae359 (accessed on 18 December 2021).
- Girshick, R. Fast RCNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask RCNN. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Abdulla, W. Mask RCNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 12 December 2021).
- SSD MobileNet V1 architecture. 2018. Available online: https://iq.opengenus.org/ssd-mobilenet-v1-architecture/ (accessed on 22 December 2021).
- gao hao. Single Shot MultiBox Detector Implementation in Pytorch. 2020. Available online: https://github.com/qfgaohao/pytorch-ssd (accessed on 12 December 2021).
- Krishnan, S. Person-Detection. 2021. Available online: https://github.com/SusmithKrishnan/person-detection (accessed on 12 December 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Openpose. Openpose. 2019. Available online: https://github.com/CMU-Perceptual-Computing-Lab/openpose (accessed on 23 April 2021).
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded Pyramid Network for Multi-person Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar] [CrossRef] [Green Version]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A deeper, stronger, and faster multi-person pose estimation model. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2018; Springer: New York, NY, USA; pp. 34–50. [Google Scholar] [CrossRef] [Green Version]
- Chu, X.; Yang, W.; Ouyang, W.; Ma, C.; Yuille, A.L.; Wang, X. Multi-context attention for human pose estimation. In Proceedings of the CVPR 2017: 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5669–5678. [Google Scholar] [CrossRef] [Green Version]
- Chou, C.J.; Chien, J.T.; Chen, H.T. Self Adversarial Training for Human Pose Estimation. In Proceedings of the APSIPA ASC 2018: 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Honolulu, HI, USA, 12–15 November 2018; pp. 17–30. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning Feature Pyramids for Human Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1290–1299. [Google Scholar] [CrossRef] [Green Version]
- Ke, L.; Chang, M.C.; Qi, H.; Lyu, S. Multi-Scale Structure-Aware Network for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 731–746. [Google Scholar] [CrossRef] [Green Version]
- Tang, Z.; Peng, X.; Geng, S.; Wu, L.; Zhang, S.; Metaxas, D. Quantized Densely Connected U-Nets for Efficient Landmark Localization. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 348–364. [Google Scholar] [CrossRef] [Green Version]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep Learning-Based Human Pose Estimation: A Survey. J. ACM 2018, 37, 111. [Google Scholar]
- Burrus, N. Kinect Calibration. 2014. Available online: http://nicolas.burrus.name/index.php/Research/KinectCalibration (accessed on 20 March 2022).
- Li, S.; Zhang, W.; Chan, A.B. Maximum-Margin Structured Learning with Deep Networks for 3D Human Pose Estimation. Int. J. Comput. Vis. 2017, 122, 149–168. [Google Scholar] [CrossRef] [Green Version]
- Liang, S.; Sun, X.; Wei, Y. Compositional Human Pose Regression. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; Volume 176–177, pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the CVPR, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Li, Z.; Wang, X.; Wang, F.; Jiang, P. On boosting single-frame 3D human pose estimation via monocular videos. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2192–2201. [Google Scholar] [CrossRef]
- Echeverria, J.; Santos, O.C. Toward modeling psychomotor performance in karate combats using computer vision pose estimation. Sensors 2021, 21, 8378. [Google Scholar] [CrossRef]
- Thanh, N.T.; Hung, L.V.; Cong, P.T. An Evaluation of Pose Estimation in Video of Traditional Martial Arts Presentation. J. Res. Dev. Inf. Commun. Technol. 2019, 2019, 114–126. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Le, V.H.; Duong, D.L.; Pham, T.C.; Le, D. 3D Human Pose Estimation in Vietnamese Traditional Martial Art Videos. J. Adv. Eng. Comput. 2019, 3, 471. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Liu, Z.; Zhou, L.; Leung, H.; Chan, A.B. Martial Arts, Dancing and Sports dataset: A challenging stereo and multi-view dataset for 3D human pose estimation. Image Vis. Comput. 2017, 61, 22–39. [Google Scholar] [CrossRef]
- Le, V.H.; Sre, R. Human Segmentation and Tracking Survey on Masks for MADS dataset. Sensors 2021, 21, 8397. [Google Scholar] [CrossRef] [PubMed]
- Australia, G. How Does Women’s Artistic Gymnastics Scoring Work? 2022. Available online: https://www.gymnastics.org.au/VIC/Posts/News_Articles/2018/August/How_does_Gymnastics_Scoring_Work__-_WAG_.aspx#:~:text=Each%20skill%20performed%20is%20given,to%20increase%20their%20start%20value (accessed on 20 March 2022).
- Gymnastics, U. FIG Elite/International Scoring. 2022. Available online: https://usagym.org/pages/events/pages/fig_scoring.html (accessed on 20 March 2022).
- Gymnastics, B. Scoring Guide. 2022. Available online: https://www.british-gymnastics.org/scoring-guide (accessed on 20 March 2022).
- Neff, C.; Sheth, A.; Furgurson, S.; Tabkhi, H. EfficientHRNet: Efficient Scaling for Lightweight High-Resolution Multi-Person Pose Estimation. arXiv 2020, arXiv:2007.08090. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 19–21 June 2022; pp. 2637–2646. Available online: https://arxiv.org/abs/2204.06806 (accessed on 20 June 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Model | Results of Mean per Joint Position Error (MPJPE) (mm) |
|---|---|---|
| Rhodin et al. [31] | DL | Protocol #1: 131.7 |
| Tome et al. [32] | DL | Protocol #1: 88.39; Protocol #2: 70.4 Protocol #3: 79.6 |
| Mehta et al. [7] | DL | ResNet 100: 82.5; ResNet 50: 80.5 |
| Zhou et al. [6] | DL | Protocol #1: 64.9 |
| Wang et al. [33] | DL | Protocol #1: 63.67 |
| Veges et al. [34] | DL | Protocol #1: 61.1 |
| Fang et al. [35] | DL | Protocol #1: 60.4; Protocol #2: 45.7 Protocol #3: 72.8 |
| Omran et al. [36] | DL | Protocol #1: 59.9 |
| Zhao et al. [37] | DL | Protocol #1: 57.6 |
| Nibali et al. [38] | DL | Protocol #1: 57.0; Protocol #2: 40.4 |
| Moon et al. [39] | DL | Protocol #1: 53.3; Protocol #2: 34.0 |
| Lee et al. [40] | DL | Protocol #1: 52.8; Protocol #2: 43.4 |
| Li and Lee et al. [41] | DL | Protocol #1: 52.7; Protocol #2: 42.6 |
| Pavlakos et al. [42] | DL | Protocol #1: 51.9 |
| Kocabas et al. [43] | DL | Protocol #1: 51.83 |
| Bastian et al. [44] | DL | Protocol #1: 50.9 |
| Tekin et al. [45] | DL | Protocol #1: 50.12 |
| Karim et al. [46] | DL | Protocol 1: 49.9 |
| Sun et al. [47] | DL | Protocol #1: 49.6 |
| Rhodin et al. [48] | TranS | Protocol #1: 46.8 |
| Chen et al. [24] | DL | Protocol #1: 46.3; Protocol #2: 37.7 Protocol #3: 50.3 |
| Martinez et al. [49] | DL | Protocol #1: 45.5 |
| Li et al. [50] | TranS | Protocol #1: 43.7; Protocol #2: 35.2 |
| Zheng et al. [51] | TranS | Protocol #1: 44.3; Protocol #2: 34.6 |
| Hossain et al. [52] | DL | Protocol #1: 39.2 |
| Wang et al. [53] | DL | Protocol#1: 37.6 |
| Pavllo et al. [27] | TranS | Protocol #1: 37.2; Protocol #2: 27.2 |
| Pavllo et al. [54] | DL | Protocol #2: 36.0 |
| Zhao et al. [55] | TranS | Protocol #1: 35.2 |
| Zhao et al. [56] | TranS | Protocol #1: 35.2 |
| Measurement/Methods | Number Testing Samples | Number Detected | (%) | (%) | (%) | (%) | (%) | Processing Time (fps) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5 [26] + CC | 548,819 | 548,346 (99.91%) | 99.78 | 99.38 | 98.42 | 97.07 | 94.16 | 55 |
| Mask RCNN [71,72] + CC | 548,819 | 548,819 (100%) | 97.17 | 96.93 | 96.61 | 96.12 | 95.51 | 2 |
| MobilenetV1 SSD [73,74] + CC | 548,819 | 507,991 (92.56%) | 96.87 | 95.66 | 93.59 | 89.52 | 81.38 | 10 |
| VGG SSD [74] + CC | 548,819 | 536,496 (97.75%) | 99.14 | 98.60 | 97.66 | 95.99 | 92.81 | 12 |
| Mobilenet SSD [75] + CC | 548,819 | 548,801 (99.99%) | 77.04 | 75.93 | 73.43 | 68.34 | 59.99 | 4.34 |
| Method | Backbone-Size of Input | OSK (Object Keypoint Similarity) (%) | ||
|---|---|---|---|---|
| OpenPose [77] | VGG-19 | 84.9 | 67.5 | 61.8 |
| Mask-RCNN [71] | Faster RCNN | 87.3 | 68.7 | 63.1 |
| CPN [79] | ResNet-Inception—384 × 288 | 91.4 | 80.0 | 72.1 |
| Simple Baseline [13] | ResNet-152—384 × 288 | 91.9 | 81.1 | 73.7 |
| HR-W32 [12] | HR-W32—384 × 288 | 92.5 | 82.8 | 74.9 |
| HR-W48 [12] | HR-W48—384 × 288 | 92.5 | 83.3 | 75.5 |
| HR-W48 + extra data [12] | HR-W48—384 × 288 | 92.7 | 84.5 | 77.0 |
| Method | Average of PCK@0.5(%) |
|---|---|
| DeeperCut [80] | 88.5 |
| SHNs [14] | 90.9 |
| Hourglass Residual Units (HRUs) [81] | 91.5 |
| Generative Adversarial Net.-SHNs [82] | 91.8 |
| Adversarial PoseNet [58] | 91.9 |
| Pyramid Residual Module (PRMs) [83] | 92.0 |
| Multi-scale structure-aware CNN [84] | 92.1 |
| Stacked U-Nets [85] | 92.3 |
| SimpleBaseline [13] | 91.5 |
| HR-W32 [12] | 92.3 |
| Method | Number of Parameters (Million(M)) | Input Size of Image | Average Joint Localization Error (A2DLE) (pixels) | Processing Time (fps) |
|---|---|---|---|---|
| HR_w48_384_288 [12] | 63.6M | Full size (1000 × 1002) | 52.4 | 3.144 |
| HR_w32_384_288 [12] | 28.5M | Full size (1000 × 1002) | 54.3 | 3.14 |
| HR_w32_256_192 [12] | 28.5M | Full size (1000 × 1002) | 58.2 | 3.145 |
| HR_w32_256_256 [12] | 28.5M | Full size (1000 × 1002) | 56.7 | 3.14 |
| CPN [79] | - | Bounding-box of detected person | 5.4 | - |
| HR+ U + S [18] | 63.6M | Bounding-box of detected person | 4.4 | - |
| Higher_HR_w48_640 [90] | 63.6M | Full size (1000 × 1002) | 40.0 | 2.5 |
| Higher_HR_w32_640 [90] | 28.6M | Full size (1000 × 1002) | 40.2 | 2.6 |
| Higher_HR_w32_512 [90] | 28.6M | Full size (1000 × 1002) | 40.8 | 2.88 |
| Ours(YOLOv5+CC_HR_384_288) | 63.6M | Full size (1000 × 1002) | 5.14 | 3.15 |
| Method | 2D Keypoints Estimation | BBoxes | Blocks | Receptive Field (frames)/ N. Epochs | MPJPE (mm) (Pro #1) | P-MPJPE (mm) (Pro #2) | N-MPJPE (mm) (Pro #3) |
|---|---|---|---|---|---|---|---|
| TCM + semi-sup. [27] | HR_w48_384_288 | HR_w48_384_288 | 4 | 243/80 | 216.2 | 184.4 | 215.8 |
| TCM + semi-sup. [27] | HR_w32_384_288 | HR_w32_384_288 | 4 | 243/80 | 216.3 | 184.2 | 215.9 |
| TCM + semi-sup. [27] | HR_w32_256_192 | HR_w32_256_192 | 4 | 243/80 | 217.2 | 186.3 | 217.1 |
| TCM + semi-sup. [27] | HR_w32_256_256 | HR_w32_256_256 | 4 | 243/80 | 216.4 | 185.8 | 216.0 |
| TCM + semi-sup. [27] | HR_w48_384_288 | Ground-truth | 4 | 243/80 | 124.6 | 104.3 | 123.8 |
| TCM + semi-sup. [27] | HR_w32_384_288 | Ground-truth | 4 | 243/80 | 125.4 | 107.9 | 124.5 |
| TCM + semi-sup. [27] | HR_w32_256_192 | Ground-truth | 4 | 243/80 | 124.22 | 105.7 | 123.8 |
| TCM + semi-sup. [27] | HR_w32_256_256 | Ground-truth | 4 | 243/80 | 123.7 | 105.3 | 123.5 |
| TCM + semi-sup. [27] | CPN | Mask RCNN | 4 | 243/80 | 46.8 | 36.5 | - |
| TCM + semi-sup. [27] | CPN | Ground-truth | 4 | 243/80 | 47.1 | 36.8 | - |
| TCM + semi-sup. [27] | CPN | Ground-truth | 3 | 81 | 47.7 | 37.2 | |
| TCM + semi-sup. [27] | CPN | Ground-truth | 2 | 27 | 48.8 | 38.0 | |
| TCM + semi-sup. [27] | Mask RCNN | Mask RCNN | 4 | 243/80 | 51.6 | 40.3 | |
| TCM + semi-sup. [27] | Ground-truth | Ground-truth | 4 | 243/80 | 37.2 | 27.2 | 35.4 |
| 3d-pose-baseline [49] | SHN | SHN (cro. 440 × 440) | - | -/200 | 62.9 | 47.7 | - |
| Cas.(Full-sup.) [18] | HR_w32_384_288 | HR_w32_384_288 | 3 | -/200 | 49.7 | 37.7 | - |
| Adversarial Lea. [60] | SHN | SHN | - | -/90 | 58.6 | 37.7 | - |
| SemGCN [37] | SHN | SHN | - | -/200 | 57.6 | - | - |
| CVAE-based [61] | SHN + 2DPoseNet | SHN + 2DPoseNet | - | -/200 | 58.0 | 40.9 | - |
| RootNet+PoseNet [39] | Mask RCNN | Mask RCNN | - | -/20 | 54.4 | - | - |
| Multi-View Sup. [31] | ResNet-50 | ResNet-50 | - | -/- | - | 64.6 | - |
| Pose SS (PSS) [43] | ResNet-50 | ResNet-50 | - | -/140 | 65.3 | 57.2 | - |
| Cas. (Weakly-sup.) [18] | HR_w32_384_288 | - | 2 | -/200 | 60.8 | 46.2 | - |
| VNect (ResNet-50) [7] | ResNet-50 | ResNet-50 | - | -/- | 80.5 | - | - |
| Vnect (ResNet-100) [7] | ResNet-100 | ResNet-100 | - | -/- | 82.5 | - | - |
| Boosting [91] | SHN | SHN | - | -/2 | 88.8 | 66.5 | - |
| GraFormer [55] | SHN | SHN | - | -/100 | 58.7 | - | - |
| GraFormer [55] | Ground-truth | Ground-truth | - | -/100 | 35.2 | - | - |
| GraFormer [56] | SHN | SHN | - | -/100 | 51.8 | - | - |
| GraFormer [56] | Ground-truth | Ground-truth | - | -/100 | 35.2 | - | - |
| Our | YOLOv5_HR _384_288 | YOLOv5_HR _384_288 | 4 | 243/80 | 50.5 | 37.0 | 45.7 |
| Our | YOLOv5_HR _384_288 | Ground-truth | 4 | 243/80 | 46.5 | 35.0 | 44.4 |
| Method | Processing Time (FPS) |
|---|---|
| VNect [7] | 1.36 |
| Our (YOLOv5-HR-TCM) | 3.146 |
| Error Angle (Degrees) | Score (Points) |
|---|---|
| 0 | 10 |
| 2 | 9.9 |
| 4 | 9.8 |
| ... | ... |
| Error Angle (Degrees) | Score (Points) |
|---|---|
| 0 | 100 |
| 1 | 99 |
| 2 | 98 |
| ... | ... |
| Bone Pairs | Mean Deviation Angle (A_Av_d) (Degrees) |
|---|---|
| Center Hip-Right Hip | 6.2 |
| Right Hip-Right Knee | 6.0 |
| Right Knee-Right Ankle | 6.9 |
| Center Hip-Left Hip | 6.2 |
| Left Hip-Left Knee | 5.1 |
| Left Knee-Left Ankle | 7.9 |
| Center Hip-Thorax | 6.8 |
| Thorax-Neck | 6.0 |
| Neck-Nose | 14.2 |
| Nose -Head | 10.1 |
| Neck-Left Shoulder | 9.0 |
| Left Shoulder-Left Elbow | 8.7 |
| Left Elbow-Left Wrist | 9.9 |
| Neck-Right Shoulder | 9.6 |
| Right Shoulder-Right Elbow | 8.8 |
| Right Elbow-Right Wrist | 10.1 |
| Average | 8.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, H.-C.; Nguyen, T.-H.; Scherer, R.; Le, V.-H. Unified End-to-End YOLOv5-HR-TCM Framework for Automatic 2D/3D Human Pose Estimation for Real-Time Applications. Sensors 2022, 22, 5419. https://doi.org/10.3390/s22145419
Nguyen H-C, Nguyen T-H, Scherer R, Le V-H. Unified End-to-End YOLOv5-HR-TCM Framework for Automatic 2D/3D Human Pose Estimation for Real-Time Applications. Sensors. 2022; 22(14):5419. https://doi.org/10.3390/s22145419
Chicago/Turabian StyleNguyen, Hung-Cuong, Thi-Hao Nguyen, Rafal Scherer, and Van-Hung Le. 2022. "Unified End-to-End YOLOv5-HR-TCM Framework for Automatic 2D/3D Human Pose Estimation for Real-Time Applications" Sensors 22, no. 14: 5419. https://doi.org/10.3390/s22145419