
Federated Deep Reinforcement Learning-Based Task Offloading and Resource Allocation for Smart Cities in a Mobile Edge Network


Abstract
:1. Introduction
- We investigate the joint optimization problem of task offloading and resource allocation subject to the delay threshold and the limited resources. In the existing literature, the joint optimization problem is generally decomposed into multiple sub-problems. Therefore, a deep reinforcement learning algorithm based on DDPG framework is proposed to solve the joint problem. The DDPG is the combination of DQN and Actor-Critic (AC), which can solve the decision-making problem of continuous action space.
- The federated learning is introduced into the deep reinforcement learning to enhance the training performance while protecting privacy and security. In terms of privacy and security, the federated learning only needs to upload the network parameters without the raw data. In terms of training performance, the federated learning is a distributed machine learning algorithm, which can obtain a better convergence.
- Extensive numerical experiments demonstrate that our proposed algorithm has better convergence than the centralized algorithm, and obtains better performance gain than other comparison algorithms.
2. Related Work
3. System Model
3.1. Task Model
3.2. Communication Model
3.3. Computation Model
3.3.1. Processing at MEC Server
3.3.2. Processing at IoT Device
4. Two-Timescale Joint Optimization of Task Offloading and Resource Allocation
4.1. Problem Formulation
4.2. Small Timescale Policy Based on Deep Reinforcement Learning
4.2.1. State Space
4.2.2. Action Space
4.2.3. Reward
| Algorithm 1: Reward calculation algorithm |
 |
4.2.4. DDPG-Based Solution
4.2.5. Computational Complexity Analysis
4.3. Large Timescale Policy Based on Federated Learning
| Algorithm 2: Training process |
 |
5. Performance Evaluation
5.1. Parameter Setting
- Random Offload:the offloading scheme of each IoT device is determined randomly. If the task of IoT device is offloaded to the MEC server, the computing and communication resources are allocated according to the proportion of data size and computing workload, respectively. If the task is executed on the IoT device, the computing resource is allocated according to the delay threshold.
- Greedy: the task of the IoT device with good channel status is offloaded to the MEC server sequentially. Each IoT device occupies the least resources to ensure that more tasks can be offloaded to the MEC server subject to the delay threshold.
- DDPG: DDPG is the basic algorithm of this article. It is a continuous reinforcement learning algorithm, which is composed of DQN and AC.
- FL-DDPG: FL-DDPG is an algorithm proposed in this article. Federated learning is introduced into reinforcement learning to solve the problem of resource allocation and offloading decision. Since FL-DDPG has the distributed characteristic, it can improve training performance while ensuring privacy and security.
5.2. Convergence Analysis
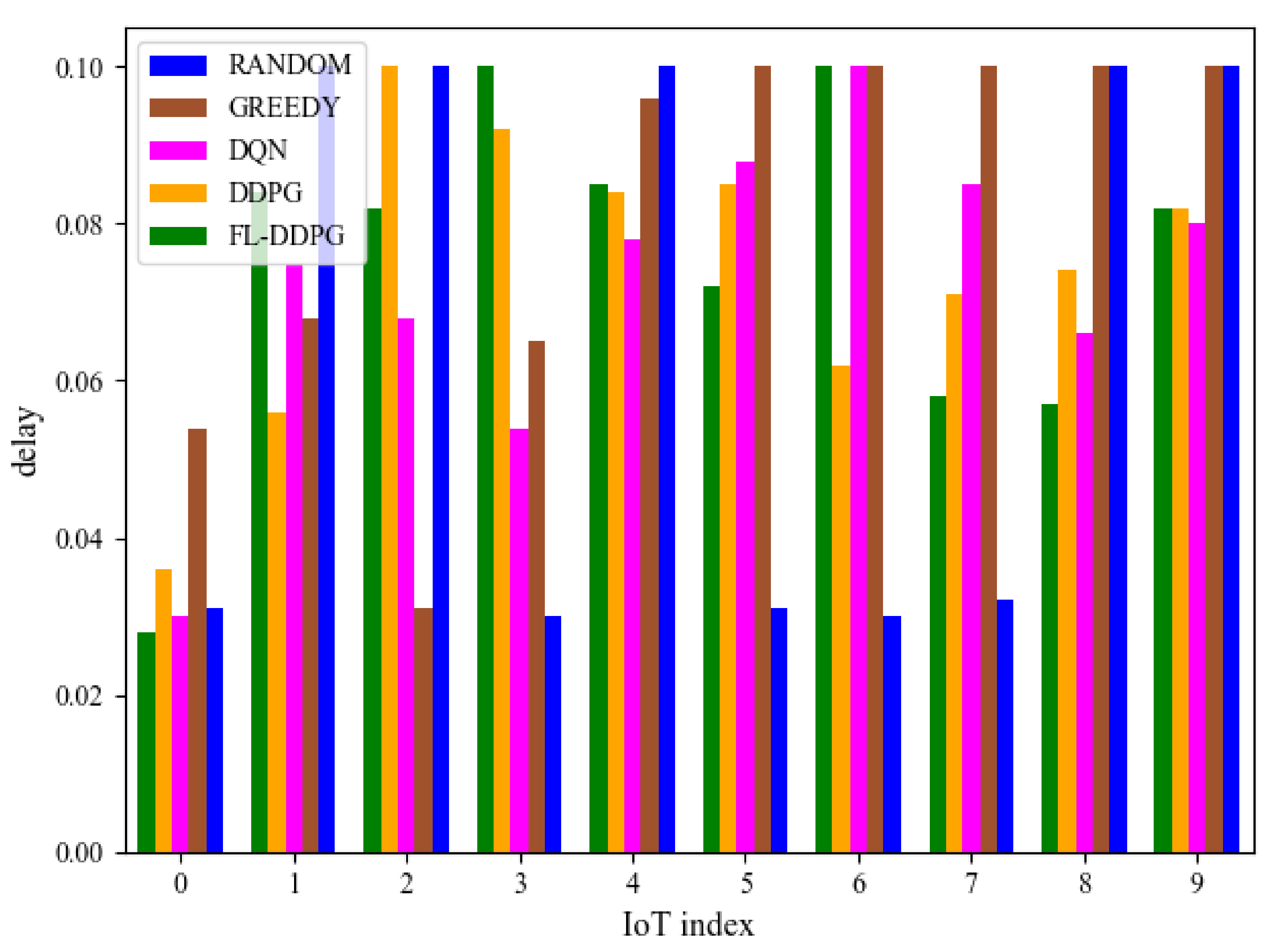
5.3. Performance Comparison
5.4. Analysis of Offload Location
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MEC | Mobile Edge Computing |
| IoT | Internet of Things |
| DDPG | Deep Deterministic Policy Gradient |
| FL-DDPG | Federated learning-Deep Deterministic Policy Gradient |
| OFDMA | Orthogonal Frequency Division Multiple Access |
| QoE | Quality of Experience |
| QoS | Quality of Service |
| DQN | Deep Q Network |
| AC | Actor-Critic |
| MDP | Markov Decision Process |
| FLOPs | Floating Point Operations |
| AI | Artificial Intelligence |
References
- Hu, Y.C.; Patel, M.; Sabella, D.; Sprecher, N.; Young, V. Mobile edge computing—A key technology towards 5G. ETSI White Pap. 2015, 11, 1–16. [Google Scholar]
- ETSI; MECISG. Mobile Edge Computing-Introductory Technical White Paper; ETSI: Sophia Antipolis, France, 2014. [Google Scholar]
- Ding, Y.; Liu, C.B.; Zhou, X.; Liu, Z.; Tang, Z. A code-oriented partitioning computation offloading strategy for multiple users and multiple mobile edge computing servers. IEEE Trans. Ind. Inform. 2019, 16, 4800–4810. [Google Scholar] [CrossRef]
- Dab, B.; Aitsaadi, N.; Langar, R. Joint optimization of offloading and resource allocation scheme for mobile edge computing. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakech, Morocco, 15–18 April 2019; pp. 1–7. [Google Scholar]
- Zhang, Z.Y.; Zhou, H.; Li, D.W. Joint Optimization of Multi-user Computing Offloading and Service Caching in Mobile Edge Computing. In Proceedings of the 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), Virtual Conference. 10–12 June 2022; pp. 1–2. [Google Scholar]
- Jin, Z.L.; Zhang, C.B.; Jin, Y.F.; Zhang, L.J.; Su, J. A Resource Allocation Scheme for Joint Optimizing Energy-Consumption and Delay in Collaborative Edge Computing-Based Industrial IoT. IEEE Trans. Ind. Inform. 2022, 18, 6236–6243. [Google Scholar] [CrossRef]
- Zhang, Q.; Gui, L.; Hou, F.; Chen, J.C.; Zhu, S.C.; Tian, F. Dynamic task offloading and resource allocation for mobile-edge computing in dense cloud RAN. IEEE Internet Things J. 2020, 7, 3282–3299. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, Y.; Lok, T.M.; Huang, K.B. Multi-cell mobile edge computing: Joint service migration and resource allocation. IEEE Trans. Wirel. Commun. 2021, 20, 5898–5912. [Google Scholar] [CrossRef]
- Li, J.H.; Zhao, J.H.; Sun, X.K. Deep Reinforcement Learning Based Wireless Resource Allocation for V2X Communications. In Proceedings of the 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP), Changsha, China, 20–22 October 2021; pp. 1–5. [Google Scholar]
- Chen, L.; Wu, J.G.; Zhang, J.; Dai, H.N.; Long, X.; Yao, M.Y. Dependency-aware computation offloading for mobile edge computing with edge-cloud cooperation. IEEE Trans. Cloud Comput. 2020. accepted. [Google Scholar] [CrossRef]
- Wu, H.M.; Wolter, K.; Jiao, P.F.; Deng, Y.J.; Zhao, Y.B.; Xu, M.X. EEDTO: An energy-efficient dynamic task offloading algorithm for blockchain-enabled IoT-edge-cloud orchestrated computing. IEEE Internet Things J. 2020, 8, 2163–2176. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Kulkarni, V.; Kulkarni, M.; Pant, A. Survey of personalization techniques for federated learning. In Proceedings of the 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), London, UK, 1 October 2020; pp. 794–797. [Google Scholar]
- Messaoud, S.; Bradai, A.; Ahmed, O.B.; Quang, P.T.A.; Atri, M.; Hossain, M.S. Deep federated Q-learning-based network slicing for industrial IoT. IEEE Trans. Ind. Inform. 2020, 17, 5572–5582. [Google Scholar] [CrossRef]
- Zhan, Y.F.; Zhang, J.; Hong, Z.C.; Wu, L.J.; Li, P.; Guo, S. A survey of incentive mechanism design for federated learning. IEEE Trans. Emerging Top. Comput. 2022, 10, 1035–1044. [Google Scholar] [CrossRef]
- IBM. IBM and Nokia Siemens Networks Announce World’s First Mobile Edge Computing Platform. 2013. Available online: http://www-03.ibm.com/press/us/en/pressrelease/40490.wss (accessed on 4 March 2013).
- Dhelim, S.; Ning, H.S.; Farha, F.; Chen, L.M.; Atzori, L.; Daneshmand, M. IoT-enabled social relationships meet artificial social intelligence. IEEE Internet Things J. 2021, 8, 17817–17828. [Google Scholar] [CrossRef]
- Aung, N.; Dhelim, S.; Chen, L.M.; Zhang, W.Y.; Lakas, A.; Ning, H.S. VeSoNet: Traffic-Aware Content Caching for Vehicular Social Networks based on Path Planning and Deep Reinforcement Learning. arXiv 2021, arXiv:2111.05567. [Google Scholar]
- Li, Y.Q.; Wang, X.; Gan, X.Y.; Jin, H.M.; Fu, L.Y.; Wang, X.B. Learning-aided computation offloading for trusted collaborative mobile edge computing. IEEE Trans. Mob. Comput. 2019, 19, 2833–2849. [Google Scholar] [CrossRef]
- Apostolopoulos, P.A.; Tsiropoulou, E.E.; Papavassiliou, S. Cognitive data offloading in mobile edge computing for internet of things. IEEE Access 2020, 8, 55736–55749. [Google Scholar] [CrossRef]
- Abd, E.M.; Abualigah, L.; Ibrahim, R.A.; Attiya, I. IoT Workflow Scheduling Using Intelligent Arithmetic Optimization Algorithm in Fog Computing. Comput. Intell. Neurosci. 2021, 2021, 9114113. [Google Scholar]
- Attiya, I.; Abd, E.M.; Abualigah, L.; Nguyen, T.N.; Abd, E.; Ahmed, A. An improved hybrid swarm intelligence for scheduling iot application tasks in the cloud. IEEE Trans. Ind. Inform. 2022, 18, 6264–6272. [Google Scholar] [CrossRef]
- Ning, Z.L.; Wang, X.J.; Rodrigues, J.J.; Xia, F. Joint computation offloading, power allocation, and channel assignment for 5G-enabled traffic management systems. IEEE Trans. Ind. Inform. 2019, 15, 3058–3067. [Google Scholar] [CrossRef]
- Zhao, M.X.; Yu, J.J.; Li, W.T.; Liu, D.; Yao, S.W.; Feng, W.; She, C.Y.; Quek, T.Q.S. Energy-aware task offloading and resource allocation for time-sensitive services in mobile edge computing systems. IEEE Trans. Veh. Technol. 2021, 70, 10925–10940. [Google Scholar] [CrossRef]
- Tan, L.; Kuang, Z.F.; Zhao, L.; Liu, A.F. Energy-Efficient Joint Task Offloading and Resource Allocation in OFDMA-based Collaborative Edge Computing. IEEE Trans. Wirel. Commun. 2022, 21, 1960–1972. [Google Scholar] [CrossRef]
- Masoudi, M.; Cavdar, C. Device vs edge computing for mobile services: Delay-aware decision making to minimize power consumption. IEEE Trans. Mob. Comput. 2020, 20, 3324–3337. [Google Scholar] [CrossRef]
- Ding, C.F.; Wang, J.B.; Zhang, H.; Lin, M.; Wang, J.Z. Joint MU-MIMO Precoding and Resource Allocation for Mobile-Edge Computing. IEEE Trans. Wirel. Commun. 2020, 20, 1639–1654. [Google Scholar] [CrossRef]
- Suh, K.J.; Kim, S.W.; Ahn, Y.J.; Kim, S.Y.; Ju, H.Y.; Shim, B.H. Deep Reinforcement Learning-based Network Slicing for Beyond 5G. IEEE Access 2022, 10, 7384–7395. [Google Scholar] [CrossRef]
- Naouri, A.; Wu, H.X.; Nouri, N.A.; Dhelim, S.; Ning, H.S. A Novel Framework for Mobile-Edge Computing by Optimizing Task Offloading. IEEE Internet Things J. 2021, 8, 13065–13076. [Google Scholar] [CrossRef]
- Chen, X.; Liu, G.Z. Energy-Efficient Task Offloading and Resource Allocation via Deep Reinforcement Learning for Augmented Reality in Mobile Edge Networks. IEEE Internet Things J. 2021, 8, 10843–10856. [Google Scholar] [CrossRef]
- Hamdi, M.; Hamed, A.B.; Yuan, D.; Zaied, M. Energy-Efficient Joint Task Assignment and Power Control in Energy Harvesting D2D Offloading Communications. IEEE Internet Things J. 2021, 9, 6018–6031. [Google Scholar] [CrossRef]
- You, C.S.; Huang, K.B.; Chae, H.J.; Kim, B.-H. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2016, 16, 1397–1411. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Tao, X.M.; Li, Y. Latency minimization for D2D-enabled partial computation offloading in mobile edge computing. IEEE Trans. Veh. Technol. 2020, 69, 4472–4486. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Li, Y. Performance guaranteed partial offloading for mobile edge computing. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Zhao, F.J.; Chen, Y.; Zhang, Y.C.; Liu, Z.Y.; Chen, X. Dynamic Offloading and Resource Scheduling for Mobile-Edge Computing With Energy Harvesting Devices. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2154–2165. [Google Scholar] [CrossRef]
- Li, S.; Sun, W.B.; Sun, Y.; Huo, Y. Energy-Efficient Task Offloading Using Dynamic Voltage Scaling in Mobile Edge Computing. IEEE Trans. Netw. Sci. Eng. 2020, 8, 588–598. [Google Scholar] [CrossRef]
- Jiang, H.B.; Dai, X.X.; Xiao, Z.; Iyengar, A.K. Joint Task Offloading and Resource Allocation for Energy-Constrained Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022. [Google Scholar] [CrossRef]
- Hao, Y.X.; Chen, M.; Hu, L.; Hossain, M.S.; Ghoneim, A. Energy efficient task caching and offloading for mobile edge computing. IEEE Access 2018, 6, 11365–11373. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Central cloud | |
| k | Index of MEC server |
| n | Index of IoT device |
| Data size of IoT device n | |
| Total computing workload of IoT device n | |
| Computing workload of IoT device n per bit | |
| Offloading decision of IoT device n | |
| Number of sub-bandwidth allocated to IoT device n | |
| B | System bandwidth |
| D | Number of sub-bands |
| Uplink channel gain between the base station and IoT device n | |
| Transmission power of IoT device n | |
| Computing resources allocated by the MEC server to IoT device n | |
| T | Delay threshold of all IoT device |
| Parameter | Value |
|---|---|
| Number of IoT devices | 30 |
| Number of base stations | 3 |
| Number of MEC servers | 3 |
| Uplink/Downlink system Bandwidth | 10 MHz |
| Transmission powers of user terminal | 1 W |
| Noise power | −100 dB |
| Size of task | [5, 90] Kb |
| Computing workload density | [200, 700] CPU cycles/bit |
| Path loss model | |
| Computing resources of local device | [2, 2.5] GHz |
| Computing resources of MEC server | 15 GHz |
| Delay threshold of IoT task | 100 ms |
| episode | 240,000 |
| Mini batch | 100 |
| Buffer size | 20,000 |
| Critic network learning rate | 0.001 |
| Actor network learning rate | 0.0001 |
| Optimizer | Adam |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Liu, G. Federated Deep Reinforcement Learning-Based Task Offloading and Resource Allocation for Smart Cities in a Mobile Edge Network. Sensors 2022, 22, 4738. https://doi.org/10.3390/s22134738
Chen X, Liu G. Federated Deep Reinforcement Learning-Based Task Offloading and Resource Allocation for Smart Cities in a Mobile Edge Network. Sensors. 2022; 22(13):4738. https://doi.org/10.3390/s22134738
Chicago/Turabian StyleChen, Xing, and Guizhong Liu. 2022. "Federated Deep Reinforcement Learning-Based Task Offloading and Resource Allocation for Smart Cities in a Mobile Edge Network" Sensors 22, no. 13: 4738. https://doi.org/10.3390/s22134738